
Come implementare la classificazione nell'apprendimento automatico?
Pubblicato: 2021-03-12L'applicazione del Machine Learning in vari campi è aumentata a passi da gigante negli ultimi anni e continua a farlo. Una delle attività più popolari del modello di Machine Learning è riconoscere gli oggetti e separarli nelle classi designate.
Questo è il metodo di Classificazione che è una delle applicazioni più popolari del Machine Learning. La classificazione viene utilizzata per separare un'enorme quantità di dati in un insieme di valori discreti che possono essere binari come 0/1, Sì/No o multiclasse come animali, automobili, uccelli, ecc.
Nel seguente articolo, comprenderemo il concetto di Classificazione in Machine Learning, i tipi di dati coinvolti e vedremo alcuni degli algoritmi di classificazione più popolari utilizzati in Machine Learning per classificare diversi dati.
Sommario
Che cos'è l'apprendimento supervisionato?
Mentre ci stiamo preparando ad approfondire il concetto di Classificazione e i suoi tipi, aggiorniamoci rapidamente con ciò che si intende per Supervised Learning e come differisce dall'altro metodo di Unsupervised Learning in Machine Learning.
Cerchiamo di capirlo prendendo un semplice esempio dalla nostra classe di Fisica al liceo. Supponiamo che ci sia un semplice problema che coinvolge un nuovo metodo. Se ci viene presentata una domanda in cui dobbiamo risolvere usando lo stesso metodo, non faremmo tutti riferimento a un problema di esempio con lo stesso metodo e proveremmo a risolverlo. Una volta che siamo sicuri di quel metodo, non dobbiamo fare più riferimento ad esso e continuare a risolverlo.
Fonte

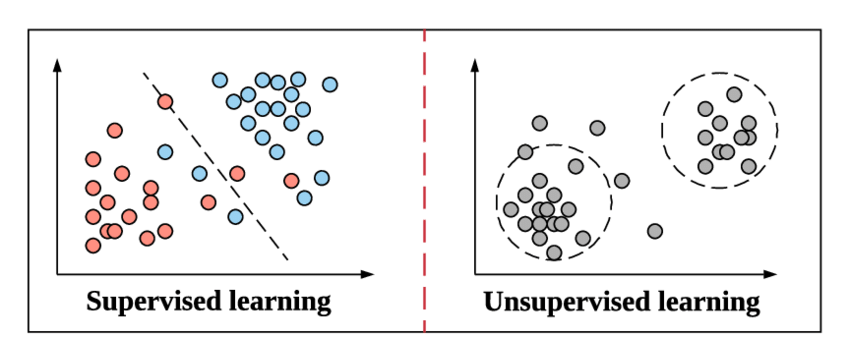
Questo è lo stesso modo in cui l'apprendimento supervisionato funziona in Machine Learning. Impara con l'esempio. Per renderlo ancora più semplice, in Supervised Learning, tutti i dati vengono alimentati con le etichette corrispondenti e quindi durante il processo di addestramento, il modello di Machine Learning confronta il suo output per un dato particolare con il vero output di quegli stessi dati e cerca di ridurre al minimo l'errore tra il valore dell'etichetta previsto e quello reale.
Gli algoritmi di classificazione che esamineremo in questo articolo seguono questo metodo di apprendimento supervisionato, ad esempio, rilevamento dello spam e riconoscimento degli oggetti.
L'apprendimento non supervisionato è un passaggio precedente in cui i dati non vengono alimentati con le relative etichette. Spetta alla responsabilità e all'efficienza del modello di Machine Learning derivare modelli dai dati e fornire l'output. Gli algoritmi di clustering seguono questo metodo di apprendimento senza supervisione.
Cos'è la classificazione?
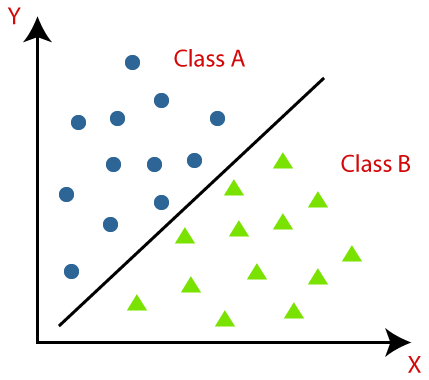
La classificazione è definita come il riconoscimento, la comprensione e il raggruppamento di oggetti o dati in classi preimpostate. Classificando i dati prima del processo di addestramento del modello di Machine Learning, possiamo utilizzare vari algoritmi di classificazione per classificare i dati in diverse classi. A differenza della regressione, un problema di classificazione si ha quando la variabile di output è una categoria, come "Sì" o "No" o "Malattia" o "Nessuna malattia".
Nella maggior parte dei problemi di Machine Learning, una volta che il set di dati è stato caricato nel programma, prima dell'addestramento, suddividere il set di dati in un set di allenamento e il set di test con un rapporto fisso (di solito 70% set di allenamento e 30% set di test). Questo processo di suddivisione consente al modello di eseguire la backpropagation in cui tenta di correggere l'errore del valore previsto rispetto al valore reale mediante diverse approssimazioni matematiche.
Allo stesso modo, prima di iniziare la Classificazione, viene creato il set di dati di addestramento. L'algoritmo di classificazione viene sottoposto a training su di esso durante il test sul set di dati di test con ogni iterazione, noto come epoch.
Fonte
Una delle applicazioni di algoritmi di classificazione più comuni è il filtraggio delle e-mail in base al fatto che siano "spam" o "non spam". In breve, possiamo definire la Classificazione in Machine Learning come una forma di "Riconoscimento di schemi" in cui questi algoritmi applicati ai dati di addestramento vengono utilizzati per estrarre diversi schemi dai dati (come parole simili o sequenze numeriche, sentimenti, ecc. .).
La classificazione è un processo di categorizzazione di un determinato insieme di dati in classi; può essere eseguita sia su dati strutturati che non strutturati. Inizia prevedendo la classe dei punti dati forniti. Queste classi sono anche denominate variabili di output, etichette di destinazione ecc. Diversi algoritmi hanno funzioni matematiche integrate per approssimare la funzione di mappatura dalle variabili del punto dati di input alla classe di destinazione di output. L'obiettivo principale della classificazione è identificare in quale classe/categoria rientreranno i nuovi dati.
Tipi di algoritmi di classificazione in Machine Learning
A seconda del tipo di dati su cui vengono applicati gli algoritmi di classificazione, esistono due grandi categorie di algoritmi, il modello lineare e il modello non lineare.
Modelli lineari
- Regressione logistica
- Supporta macchine vettoriali (SVM)
Modelli non lineari
- Classificazione K-Nearest Neighbors (KNN).
- SVM del kernel
- Classificazione ingenua di Bayes
- Classificazione dell'albero decisionale
- Classificazione casuale delle foreste
In questo articolo, analizzeremo brevemente il concetto alla base di ciascuno degli algoritmi sopra menzionati.
Valutazione di un modello di classificazione in Machine Learning
Prima di entrare nei concetti di questi algoritmi sopra menzionati, dobbiamo capire come possiamo valutare il nostro modello di Machine Learning basato su questi algoritmi. È essenziale valutare l'accuratezza del nostro modello sia sul set di allenamento che sul set di test.
Perdita di entropia incrociata o perdita di registro
Questo è il primo tipo di funzione di perdita che utilizzeremo per valutare le prestazioni di un classificatore il cui output è compreso tra 0 e 1. Viene utilizzato principalmente per i modelli di classificazione binaria. La formula della perdita logaritmica è data da
Log Loss = -((1 – y) * log(1 – yhat) + y * log(yhat))
Dove quello è il valore previsto e y è il valore reale.
Matrice di confusione
Una matrice di confusione è una matrice NXN, dove N è il numero di classi previste. La matrice di confusione ci fornisce una matrice/tabella come output e descrive le prestazioni del modello. Consiste nel risultato delle previsioni sotto forma di una matrice da cui possiamo derivare diverse metriche di performance per valutare il modello di classificazione. è della forma,
| Effettivamente positivo | Effettivo negativo | |
| Positivo previsto | Vero positivo | Falso positivo |
| Negativo previsto | Falso negativo | Vero negativo |
Di seguito sono riportate alcune delle metriche delle prestazioni che possono essere derivate dalla tabella sopra.
1.Accuracy – la proporzione del numero totale di previsioni corrette.
2. Valore predittivo positivo o precisione: la proporzione di casi positivi correttamente identificati.
3. Valore predittivo negativo: la proporzione di casi negativi correttamente identificati.
4. Sensibilità o Richiamo – la percentuale di casi positivi effettivi che sono stati identificati correttamente.
5. Specificità: la proporzione di casi negativi effettivi correttamente identificati.
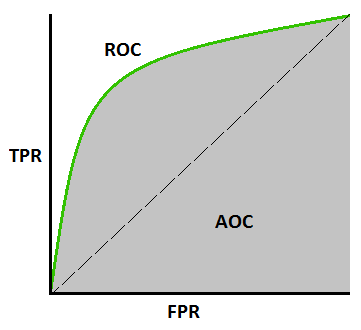
Curva AUC-ROC –
Questa è un'altra importante metrica della curva che valuta qualsiasi modello di Machine Learning. La curva ROC sta per Curve caratteristiche operative del ricevitore e AUC sta per Area sotto la curva. La curva ROC viene tracciata con TPR e FPR, dove TPR (Tasso di veri positivi) sull'asse Y e FPR (Tasso di falsi positivi) sull'asse X. Mostra le prestazioni del modello di classificazione a diverse soglie.
Fonte
1. Regressione logistica
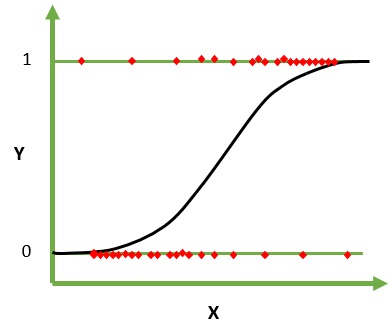
Logistic Regression è un algoritmo di apprendimento automatico per la classificazione. In questo algoritmo, le probabilità che descrivono i possibili risultati di una singola prova sono modellate utilizzando una funzione logistica. Presuppone che le variabili di input siano numeriche e abbiano una distribuzione gaussiana (curva a campana).
La funzione logistica, chiamata anche funzione sigmoidea, è stata inizialmente utilizzata dagli statistici per descrivere la crescita della popolazione in ecologia. La funzione sigmoide è una funzione matematica utilizzata per mappare i valori previsti alle probabilità. La regressione logistica ha una curva a forma di S e può assumere valori compresi tra 0 e 1 ma mai esattamente a quei limiti.

Fonte
La regressione logistica viene utilizzata principalmente per prevedere un risultato binario come Sì/No e Pass/Fail. Le variabili indipendenti possono essere categoriali o numeriche, ma la variabile dipendente è sempre categoriale. La formula per la regressione logistica è data da,
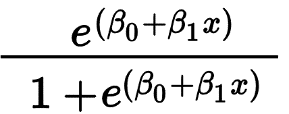
Dove e rappresenta la curva a forma di S che ha valori compresi tra 0 e 1.
2. Supporta le macchine vettoriali
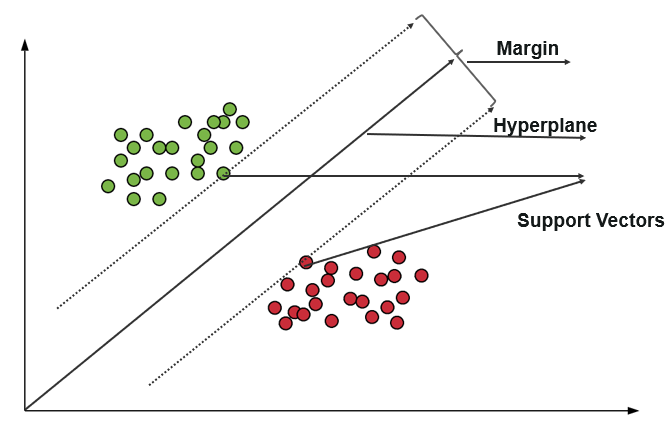
Una macchina vettoriale di supporto (SVM) utilizza algoritmi per addestrare e classificare i dati entro gradi di polarità, portandoli a un livello superiore alla previsione X/Y. In SVM, la riga utilizzata per separare le classi è denominata Hyperplane. I punti dati su entrambi i lati dell'iperpiano più vicini all'iperpiano sono chiamati vettori di supporto utilizzati per tracciare la linea di confine.
Questa Support Vector Machine in Classification rappresenta i dati di addestramento come punti dati in uno spazio in cui molte categorie sono separate nelle categorie Hyperplane. Quando un nuovo punto entra, viene classificato prevedendo in quale categoria rientrano e appartengono a uno spazio particolare.
Fonte
Lo scopo principale della macchina Support Vector è massimizzare il margine tra i due Support Vector.
Partecipa al corso ML online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
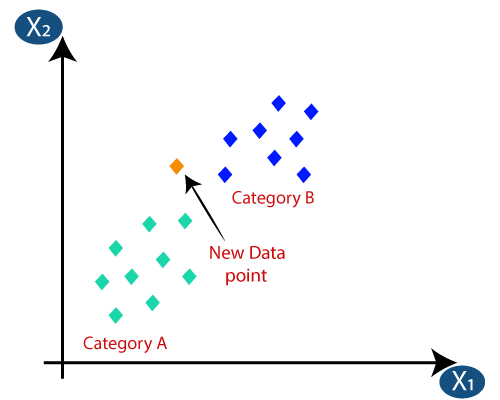
3. Classificazione K-Nearest Neighbors (KNN).
La classificazione KNN è uno degli algoritmi di classificazione più semplici, ma è ampiamente utilizzato grazie alla sua elevata efficienza e facilità d'uso. In questo metodo, l'intero set di dati viene inizialmente memorizzato nella macchina. Quindi, viene scelto un valore – k, che rappresenta il numero di vicini. In questo modo, quando un nuovo punto dati viene aggiunto al set di dati, prende la maggioranza dei voti dell'etichetta di classe k dei vicini più vicini a quel nuovo punto dati. Con questo voto, il nuovo punto dati viene aggiunto a quella particolare classe con il voto più alto.
Fonte
4. SVM del kernel
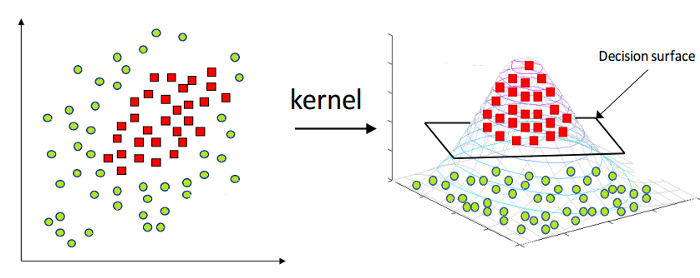
Come accennato in precedenza, la Linear Support Vector Machine può essere applicata solo a dati lineari in natura. Tuttavia, tutti i dati del mondo non sono separabili linearmente. Quindi, abbiamo bisogno di sviluppare una Support Vector Machine per tenere conto dei dati che sono anche separabili in modo non lineare. Ecco il trucco del kernel, noto anche come Kernel Support Vector Machine o Kernel SVM.
In Kernel SVM, selezioniamo un kernel come RBF o Gaussian Kernel. Tutti i punti dati sono mappati su una dimensione superiore, dove diventano linearmente separabili. In questo modo, possiamo creare un confine decisionale tra le diverse classi del set di dati.
Fonte
Quindi, in questo modo, utilizzando i concetti di base delle Support Vector Machines, possiamo progettare una Kernel SVM per non lineare.
5. Classificazione ingenua di Bayes
La classificazione Naive Bayes ha le sue radici appartenenti al teorema di Bayes, assumendo che tutte le variabili indipendenti (caratteristiche) del set di dati siano indipendenti. Hanno uguale importanza nel predire il risultato. Questa ipotesi del teorema di Bayes dà il nome: 'Naive'. Viene utilizzato per varie attività, come il filtro antispam e altre aree di classificazione del testo. Naive Bayes calcola la possibilità se un punto dati appartiene o meno a una determinata categoria.
La formula della classificazione Naive Bayes è data da,
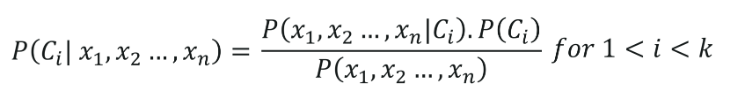
6. Classificazione dell'albero decisionale
Un albero decisionale è un algoritmo di apprendimento supervisionato perfetto per problemi di classificazione, in quanto può ordinare le classi a un livello preciso. Funziona sotto forma di diagramma di flusso in cui separa i punti dati a ciascun livello. La struttura finale sembra un albero con nodi e foglie.

Fonte
Un nodo decisionale avrà due o più rami e una foglia rappresenta una classificazione o una decisione. Nell'esempio sopra di un Albero decisionale, ponendo diverse domande, viene creato un diagramma di flusso, che ci aiuta a risolvere il semplice problema di prevedere se andare o meno al mercato.
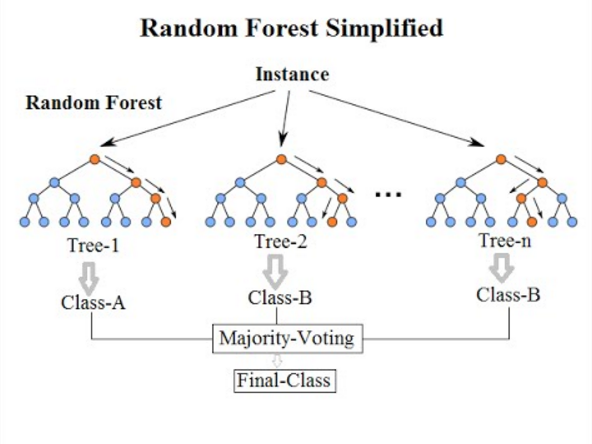
7. Classificazione casuale delle foreste
Venendo all'ultimo algoritmo di classificazione di questo elenco, The Random Forest è solo un'estensione dell'algoritmo Decision Tree. Una foresta casuale è un metodo di apprendimento d'insieme con più alberi decisionali. Funziona allo stesso modo di quello di Decision Trees.
Fonte
L'algoritmo della foresta casuale è un avanzamento dell'attuale algoritmo dell'albero delle decisioni, che soffre di un grave problema di " overfitting ". È anche considerato più veloce e accurato rispetto all'algoritmo dell'albero delle decisioni.
Leggi anche: Idee e argomenti per progetti di apprendimento automatico
Conclusione
Pertanto, in questo articolo sui metodi di Machine Learning per la classificazione, abbiamo compreso le basi della classificazione e dell'apprendimento supervisionato, i tipi e le metriche di valutazione dei modelli di classificazione e, infine, un riepilogo di tutti i modelli di classificazione più comunemente utilizzati Machine Learning.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI , progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT -B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Q1. Quali algoritmi sono più utilizzati nell'apprendimento automatico?
L'apprendimento automatico utilizza molti algoritmi diversi, che possono essere classificati in tre tipi principali: algoritmi di apprendimento supervisionato, algoritmi di apprendimento non supervisionato e algoritmi di apprendimento per rinforzo. Ora, per restringere il campo e nominare alcuni degli algoritmi più comunemente usati, quelli che devono essere menzionati sono regressione lineare, regressione logistica, SVM, alberi decisionali, algoritmo random forest, kNN, teoria di Naive Bayes, K-Means, riduzione della dimensionalità, e algoritmi di aumento del gradiente. Gli algoritmi XGBoost, GBM, LightGBM e CatBoost meritano una menzione speciale negli algoritmi di aumento del gradiente. Questi algoritmi possono essere applicati per risolvere quasi ogni tipo di problema relativo ai dati.
Q2. Che cos'è la classificazione e la regressione nell'apprendimento automatico?
Sia gli algoritmi di classificazione che quelli di regressione sono ampiamente utilizzati nell'apprendimento automatico. Tuttavia, ci sono molte differenze tra loro, che alla fine determinano il loro uso o scopo. La differenza principale è che mentre gli algoritmi di classificazione vengono utilizzati per classificare o prevedere valori discreti come maschio-femmina o vero-falso, gli algoritmi di regressione vengono utilizzati per prevedere valori non discreti e continui come stipendio, età, prezzo, ecc. Alberi decisionali, foresta casuale, Kernel SVM e regressione logistica sono alcuni degli algoritmi di classificazione più comuni, mentre la regressione lineare semplice e multipla, la regressione vettoriale di supporto, la regressione polinomiale e la regressione dell'albero decisionale sono alcuni degli algoritmi di regressione più popolari utilizzati nell'apprendimento automatico.
Q3. Quali sono i prerequisiti per l'apprendimento automatico dell'apprendimento?
Per iniziare con l'apprendimento automatico, non è necessario essere un matematico esperto o un programmatore esperto. Tuttavia, data la vastità del campo, può sembrare intimidatorio quando stai per iniziare il tuo viaggio di apprendimento automatico. In questi casi, conoscere i prerequisiti può aiutarti a iniziare senza intoppi. I prerequisiti sono essenzialmente le competenze di base che devi acquisire per comprendere i concetti di machine learning. Quindi, prima di tutto, assicurati di imparare a programmare usando Python. Successivamente, sarà un ulteriore vantaggio una comprensione di base della statistica e della matematica, in particolare l'algebra lineare e il calcolo multivariabile.