
Come scegliere un metodo di selezione delle funzionalità per l'apprendimento automatico
Pubblicato: 2021-06-22Sommario
Introduzione alla selezione delle funzioni
Molte funzionalità sono utilizzate da un modello di apprendimento automatico di cui solo alcune sono importanti. L'accuratezza del modello è ridotta se vengono utilizzate funzionalità non necessarie per addestrare un modello di dati. Inoltre, vi è un aumento della complessità del modello e una diminuzione della capacità di generalizzazione risultando in un modello distorto. Il detto "a volte meno è meglio" si sposa bene con il concetto di apprendimento automatico. Il problema è stato affrontato da molti utenti in cui hanno difficoltà a identificare l'insieme di funzionalità rilevanti dai propri dati e ignorare tutti gli insiemi di funzionalità irrilevanti. Le caratteristiche meno importanti sono definite in modo tale da non contribuire alla variabile target.
Pertanto, uno dei processi importanti è la selezione delle funzionalità nell'apprendimento automatico . L'obiettivo è selezionare il miglior set possibile di funzionalità per lo sviluppo di un modello di machine learning. C'è un enorme impatto sulle prestazioni del modello dalla selezione delle funzioni. Insieme alla pulizia dei dati, la selezione delle funzionalità dovrebbe essere il primo passo nella progettazione di un modello.
La selezione delle funzionalità in Machine Learning può essere riassunta come
- Selezione automatica o manuale delle caratteristiche che contribuiscono maggiormente alla variabile di previsione o all'output.
- La presenza di caratteristiche irrilevanti potrebbe portare a una minore accuratezza del modello poiché imparerà dalle caratteristiche irrilevanti.
Vantaggi della selezione delle funzioni
- Riduce l'overfitting dei dati: un numero inferiore di dati porta a una minore ridondanza. Pertanto ci sono meno possibilità di prendere decisioni sul rumore.
- Migliora l'accuratezza del modello: con minori possibilità di dati fuorvianti, aumenta l'accuratezza del modello.
- Il tempo di addestramento è ridotto: la rimozione di funzionalità irrilevanti riduce la complessità dell'algoritmo poiché sono presenti solo meno punti dati. Pertanto, gli algoritmi si addestrano più velocemente.
- La complessità del modello viene ridotta con una migliore interpretazione dei dati.
Metodi supervisionati e non supervisionati per la selezione delle funzioni
L'obiettivo principale degli algoritmi di selezione delle caratteristiche è selezionare un insieme di migliori caratteristiche per lo sviluppo del modello. I metodi di selezione delle funzionalità nell'apprendimento automatico possono essere classificati in metodi supervisionati e non supervisionati.
- Metodo supervisionato: il metodo supervisionato viene utilizzato per la selezione delle caratteristiche dai dati etichettati e utilizzato anche per la classificazione delle caratteristiche rilevanti. Quindi, c'è una maggiore efficienza dei modelli che vengono costruiti.
- Metodo non supervisionato : questo metodo di selezione delle funzioni viene utilizzato per i dati senza etichetta.
Elenco dei metodi nell'ambito dei metodi supervisionati
I metodi supervisionati di selezione delle funzionalità nell'apprendimento automatico possono essere classificati in

1. Metodi di avvolgimento
Questo tipo di algoritmo di selezione delle funzionalità valuta il processo di prestazione delle funzionalità in base ai risultati dell'algoritmo. Conosciuto anche come algoritmo greedy, addestra l'algoritmo utilizzando un sottoinsieme di funzionalità in modo iterativo. I criteri di arresto sono generalmente definiti dalla persona che addestra l'algoritmo. L'aggiunta e la rimozione di funzionalità nel modello avviene in base alla formazione preliminare del modello. Qualsiasi tipo di algoritmo di apprendimento può essere applicato in questa strategia di ricerca. I modelli sono più accurati rispetto ai metodi di filtraggio.
Le tecniche utilizzate nei metodi Wrapper sono:
- Selezione in avanti: il processo di selezione in avanti è un processo iterativo in cui vengono aggiunte nuove funzionalità che migliorano il modello dopo ogni iterazione. Inizia con un insieme vuoto di funzionalità. L'iterazione continua e si interrompe finché non viene aggiunta una funzionalità che non migliora ulteriormente le prestazioni del modello.
- Selezione/eliminazione all'indietro: il processo è un processo iterativo che inizia con tutte le funzionalità. Dopo ogni iterazione, le caratteristiche meno significative vengono rimosse dall'insieme delle caratteristiche iniziali. Il criterio di arresto per l'iterazione è quando le prestazioni del modello non migliorano ulteriormente con la rimozione della funzionalità. Questi algoritmi sono implementati nel pacchetto mlxtend.
- Eliminazione bidirezionale : entrambi i metodi di selezione in avanti e la tecnica di eliminazione all'indietro vengono applicati contemporaneamente nel metodo di eliminazione bidirezionale per raggiungere un'unica soluzione.
- Selezione esauriente delle funzionalità: è anche noto come approccio di forza bruta per la valutazione dei sottoinsiemi di funzionalità. Viene creato un insieme di possibili sottoinsiemi e viene creato un algoritmo di apprendimento per ogni sottoinsieme. Viene scelto quel sottoinsieme il cui modello offre le migliori prestazioni.
- Eliminazione delle funzionalità ricorsive (RFE): il metodo è definito avido in quanto seleziona le funzionalità considerando in modo ricorsivo il set di funzionalità sempre più piccolo. Un insieme iniziale di caratteristiche viene utilizzato per addestrare lo stimatore e la loro importanza viene ottenuta utilizzando feature_importance_attribute. Viene quindi seguita attraverso la rimozione delle funzionalità meno importanti lasciando solo il numero richiesto di funzionalità. Gli algoritmi sono implementati nel pacchetto scikit-learn.
Figura 4: un esempio di codice che mostra la tecnica di eliminazione delle caratteristiche ricorsive
2. Metodi incorporati
I metodi di selezione delle funzionalità incorporati nell'apprendimento automatico hanno un certo vantaggio rispetto ai metodi di filtro e wrapper, includendo l'interazione delle funzionalità e mantenendo anche un costo computazionale ragionevole. Le tecniche utilizzate nei metodi embedded sono:
- Regolarizzazione: il modello evita l'overfitting dei dati aggiungendo una penalità ai parametri del modello. I coefficienti vengono aggiunti con la penalità risultando in alcuni coefficienti zero. Pertanto quelle caratteristiche che hanno un coefficiente zero vengono rimosse dall'insieme delle caratteristiche. L'approccio di selezione delle caratteristiche utilizza Lasso (regolarizzazione L1) e Reti elastiche (regolarizzazione L1 e L2).
- SMLR (Sparse Multinomial Logistic Regression): L'algoritmo implementa una regolarizzazione sparsa mediante ARD prior (Automatic rilevanza determinazione) per la classica regressione logistica multinazionale. Questa regolarizzazione stima l'importanza di ogni caratteristica e pota le dimensioni che non sono utili per la previsione. L'implementazione dell'algoritmo avviene in SMLR.
- ARD (Automatic Relevance Determination Regression): l'algoritmo sposterà i pesi dei coefficienti verso zero e si basa su una regressione bayesiana. L'algoritmo può essere implementato in scikit-learn.
- Importanza della foresta casuale: questo algoritmo di selezione delle caratteristiche è un'aggregazione di un numero specificato di alberi. Le strategie ad albero in questo algoritmo si classificano in base all'aumento dell'impurità di un nodo o alla diminuzione dell'impurità (impurità di Gini). La fine degli alberi è costituita dai nodi con la minor diminuzione di impurità e l'inizio degli alberi è costituita dai nodi con la maggiore diminuzione di impurità. Pertanto, le caratteristiche importanti possono essere selezionate tramite la potatura dell'albero al di sotto di un particolare nodo.
3. Metodi di filtraggio
I metodi vengono applicati durante le fasi di pre-elaborazione. I metodi sono abbastanza veloci ed economici e funzionano meglio nella rimozione di funzionalità duplicate, correlate e ridondanti. Invece di applicare qualsiasi metodo di apprendimento supervisionato, l'importanza delle caratteristiche viene valutata in base alle loro caratteristiche intrinseche. Il costo computazionale dell'algoritmo è inferiore rispetto ai metodi wrapper di selezione delle caratteristiche. Tuttavia, se non sono presenti dati sufficienti per derivare la correlazione statistica tra le funzionalità, i risultati potrebbero essere peggiori dei metodi wrapper. Pertanto, gli algoritmi vengono utilizzati su dati di dimensioni elevate, il che comporterebbe un costo computazionale più elevato se si applicano i metodi wrapper.

Le tecniche utilizzate nei metodi Filter sono :
- Guadagno di informazioni : il guadagno di informazioni si riferisce alla quantità di informazioni ottenute dalle funzionalità per identificare il valore target. Quindi misura la riduzione dei valori di entropia. Il guadagno di informazioni di ciascun attributo viene calcolato considerando i valori target per la selezione delle caratteristiche.
- Test del chi quadrato: il metodo del chi quadrato (X 2 ) è generalmente utilizzato per verificare la relazione tra due variabili categoriali. Il test viene utilizzato per identificare se esiste una differenza significativa tra i valori osservati da diversi attributi del set di dati rispetto al suo valore atteso. Un'ipotesi nulla afferma che non esiste alcuna associazione tra due variabili.
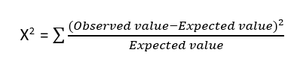
Fonte
La formula per il test del chi quadrato
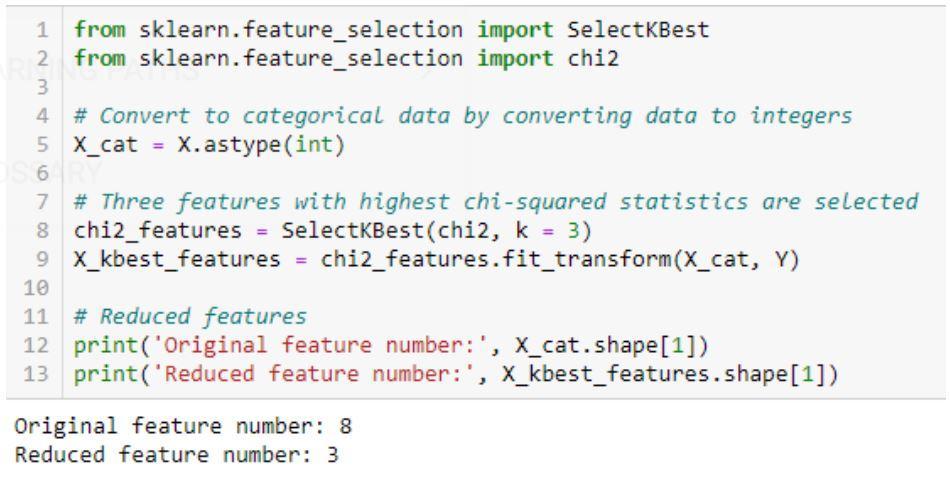
Implementazione dell'algoritmo Chi-Squared: sklearn, scipy
Un esempio di codice per il test del chi quadrato
Fonte
- CFS (selezione delle caratteristiche basata sulla correlazione): il metodo segue " Implementazione di CFS (selezione delle funzionalità basate sulla correlazione): scikit-feature
Partecipa ai corsi di IA e ML online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzata in ML e IA per accelerare la tua carriera.
- FCBF (filtro basato sulla correlazione veloce): rispetto ai metodi sopra menzionati di Relief e CFS, il metodo FCBF è più veloce ed efficiente. Inizialmente, il calcolo dell'incertezza simmetrica viene effettuato per tutte le caratteristiche. Utilizzando questi criteri, le funzionalità vengono quindi ordinate e le funzionalità ridondanti vengono rimosse.
Symmetrical Incertainty= il guadagno di informazioni di x | y diviso per la somma delle loro entropie. Implementazione di FCBF: skfeature
- Punteggio Fischer: la razione Fischer (FIR) è definita come la distanza tra le medie campionarie per ciascuna classe per caratteristica divisa per le loro varianze. Ogni caratteristica viene selezionata in modo indipendente in base ai punteggi ottenuti secondo il criterio Fisher. Ciò porta a un insieme di funzionalità non ottimale. Un punteggio di Fisher più grande denota una caratteristica meglio selezionata.
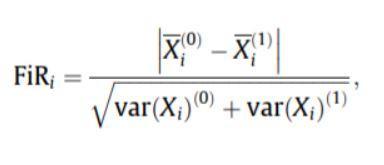
Fonte
La formula per il punteggio Fischer
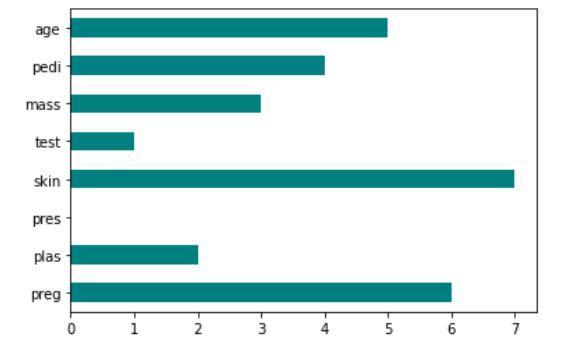
Implementazione del punteggio di Fisher: funzione scikit
L'output del codice che mostra la tecnica del punteggio di Fisher
Fonte
Coefficiente di correlazione di Pearson: è una misura per quantificare l'associazione tra le due variabili continue. I valori del coefficiente di correlazione vanno da -1 a 1 che definisce la direzione della relazione tra le variabili.
- Soglia di varianza: le caratteristiche la cui varianza non soddisfa la soglia specifica vengono rimosse. Le caratteristiche con varianza zero vengono rimosse tramite questo metodo. L'ipotesi considerata è che è probabile che le caratteristiche di varianza più elevate contengano più informazioni.
Figura 15: un esempio di codice che mostra l'implementazione della soglia di varianza
- Differenza media assoluta (MAD): il metodo calcola la media assoluta
differenza dal valore medio.
Un esempio di codice e relativo output che mostra l'implementazione di Mean Absolute Difference (MAD)
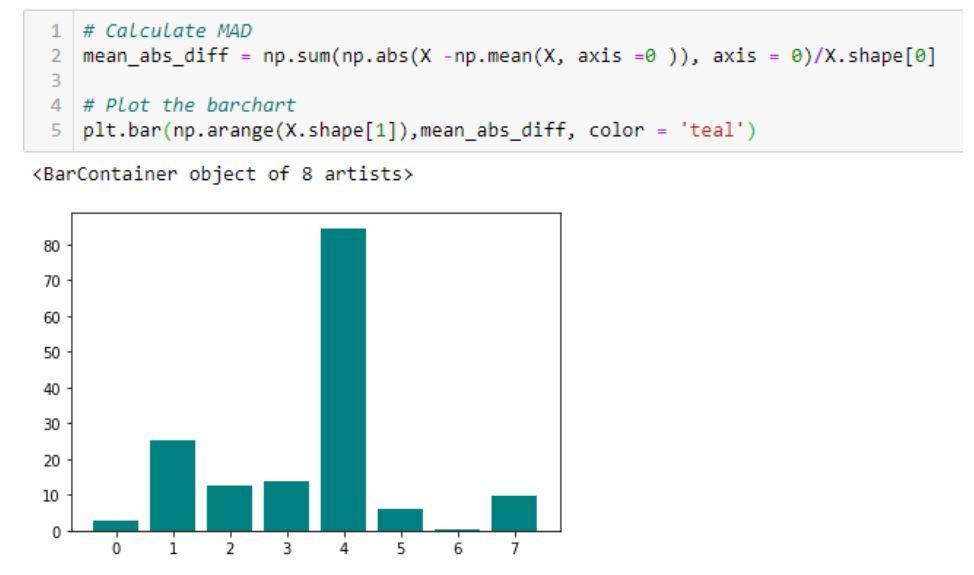
Fonte
- Rapporto di dispersione: il rapporto di dispersione è definito come il rapporto tra la media aritmetica (AM) e quella della media geometrica (GM) per una data caratteristica. Il suo valore varia da +1 a ∞ come AM ≥ GM per una determinata caratteristica.
Un rapporto di dispersione più elevato implica un valore di Ri più elevato e quindi una caratteristica più rilevante. Al contrario, quando Ri è vicino a 1, indica una caratteristica di bassa rilevanza.
- Dipendenza reciproca: il metodo viene utilizzato per misurare la dipendenza reciproca tra due variabili. Le informazioni ottenute da una variabile possono essere utilizzate per ottenere informazioni per l'altra variabile.
- Punteggio laplaciano: i dati della stessa classe sono spesso vicini tra loro. L'importanza di una caratteristica può essere valutata dal suo potere di conservazione della località. Viene calcolato il punteggio laplaciano per ciascuna caratteristica. I valori più piccoli determinano dimensioni importanti. Implementazione del punteggio laplaciano: scikit-feature.
Conclusione
La selezione delle funzionalità nel processo di apprendimento automatico può essere riassunta come uno dei passaggi importanti verso lo sviluppo di qualsiasi modello di apprendimento automatico. Il processo dell'algoritmo di selezione delle caratteristiche porta alla riduzione della dimensionalità dei dati con la rimozione di caratteristiche non rilevanti o importanti per il modello in esame. Le caratteristiche rilevanti potrebbero accelerare il tempo di addestramento dei modelli risultando in prestazioni elevate.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT -B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
In che modo il metodo del filtro è diverso dal metodo del wrapper?
Il metodo wrapper aiuta a misurare l'utilità delle funzionalità basate sulle prestazioni del classificatore. Il metodo del filtro, d'altra parte, valuta le qualità intrinseche delle caratteristiche utilizzando statistiche univariate piuttosto che prestazioni di convalida incrociata, implicando che giudichino la rilevanza delle caratteristiche. Di conseguenza, il metodo wrapper è più efficace poiché ottimizza le prestazioni del classificatore. Tuttavia, a causa dei ripetuti processi di apprendimento e della convalida incrociata, la tecnica del wrapper è computazionalmente più costosa del metodo del filtro.
Che cos'è la selezione in avanti sequenziale nell'apprendimento automatico?
È una sorta di selezione sequenziale delle funzioni, sebbene sia molto più costosa della selezione dei filtri. È una tecnica di ricerca avida che seleziona in modo iterativo le funzionalità in base alle prestazioni del classificatore per scoprire il sottoinsieme di funzionalità ideale. Inizia con un sottoinsieme di funzionalità vuoto e continua ad aggiungere una funzionalità in ogni round. Questa caratteristica viene scelta da un pool di tutte le funzionalità che non sono nel nostro sottoinsieme di funzionalità ed è quella che si traduce nelle migliori prestazioni del classificatore se combinata con le altre.
Quali sono i limiti dell'utilizzo del metodo di filtraggio per la selezione delle funzioni?
L'approccio del filtro è computazionalmente meno costoso del wrapper e dei metodi di selezione delle funzionalità incorporate, ma presenta alcuni inconvenienti. Nel caso di approcci univariati, questa strategia spesso ignora l'interdipendenza delle caratteristiche durante la selezione delle caratteristiche e valuta ciascuna caratteristica in modo indipendente. Se confrontato con gli altri due metodi di selezione delle funzionalità, a volte ciò potrebbe comportare prestazioni di elaborazione scadenti.