
In che modo il mio sito Web basato su API mi aiuta a viaggiare per il mondo
Pubblicato: 2022-03-10(Questo è un post sponsorizzato.) Di recente, ho deciso di ricostruire il mio sito Web personale, perché aveva sei anni e sembrava - educatamente parlando - un po' "obsoleto". L'obiettivo era includere alcune informazioni su di me, un'area blog, un elenco dei miei progetti collaterali recenti e dei prossimi eventi.
Dato che di tanto in tanto lavoro con i clienti, c'era una cosa di cui non volevo occuparmi: i database ! In precedenza, ho creato siti WordPress per tutti coloro che lo desideravano. La parte di programmazione di solito era divertente per me, ma i rilasci, lo spostamento di database in ambienti diversi e la pubblicazione effettiva erano sempre fastidiosi. I provider di hosting economici offrono solo interfacce web scadenti per configurare database MySQL e un accesso FTP per caricare i file è sempre stata la parte peggiore. Non volevo occuparmi di questo per il mio sito web personale.
Quindi i requisiti che avevo per la riprogettazione erano:
- Uno stack tecnologico aggiornato basato su JavaScript e tecnologie frontend.
- Una soluzione di gestione dei contenuti per modificare i contenuti da qualsiasi luogo.
- Un buon sito con risultati veloci.
In questo articolo voglio mostrarti cosa ho costruito e come il mio sito web si è sorprendentemente rivelato essere il mio compagno quotidiano.
Definizione di un modello di contenuto
Pubblicare cose sul web sembra essere facile. Scegli un sistema di gestione dei contenuti (CMS) che fornisca un editor WYSIWYG (What You See Is What You Get ) per ogni pagina necessaria e tutti gli editor possono gestire facilmente il contenuto. Questo è tutto, giusto?
Dopo aver creato diversi siti Web di clienti, che vanno dai piccoli caffè alle startup in crescita, ho capito che il santo editore WYSIWYG non è sempre il proiettile d'argento che tutti stiamo cercando. Queste interfacce mirano a semplificare la creazione di siti Web, ma ecco il punto:
Realizzare siti web non è facile
Per costruire e modificare il contenuto di un sito Web senza romperlo costantemente, devi avere una conoscenza approfondita dell'HTML e almeno comprendere un po' di CSS. Non è qualcosa che puoi aspettarti dai tuoi editori.
Ho visto layout orribili e complessi costruiti con editor WYSIWYG e non posso iniziare a nominare tutte le situazioni in cui tutto va in pezzi perché il sistema è troppo fragile. Queste situazioni portano a liti e disagi in cui tutte le parti si incolpano a vicenda per qualcosa che era inevitabile. Ho sempre cercato di evitare queste situazioni e creare ambienti confortevoli e stabili per i redattori per evitare e-mail arrabbiate che urlavano: "Aiuto! Tutto è rotto".
Il contenuto strutturato ti fa risparmiare qualche problema
Ho imparato piuttosto rapidamente che le persone raramente rompono le cose quando divido tutti i contenuti del sito Web necessari in diversi blocchi, ciascuno correlato l'uno all'altro senza pensare a alcuna rappresentazione. In WordPress, questo può essere ottenuto utilizzando tipi di post personalizzati. Ogni tipo di post personalizzato può includere diverse proprietà con il proprio campo di testo di facile comprensione. Ho seppellito completamente il concetto di pensare nelle pagine .
Il mio lavoro era collegare i pezzi di contenuto e creare pagine web da questi blocchi di contenuto. Ciò significava che gli editori erano in grado di apportare solo piccole, se non nessuna, modifiche visive sui loro siti web. Erano responsabili del contenuto e solo del contenuto. Le modifiche visive dovevano essere apportate da me: non tutti potevano modellare il sito e potevamo evitare un ambiente fragile. Questo concetto sembrava un ottimo compromesso e di solito è stato ben accolto.
Più tardi, ho scoperto che quello che stavo facendo era definire un modello di contenuto. Rachel Lovinger definisce, nel suo eccellente articolo "Content Modelling: A Master Skill", un modello di contenuto come segue:
“Un modello di contenuto documenta tutti i diversi tipi di contenuto che avrai per un determinato progetto. Contiene definizioni dettagliate degli elementi di ciascun tipo di contenuto e le loro relazioni reciproche".
A partire dalla modellazione dei contenuti ha funzionato bene per la maggior parte dei clienti, tranne uno.
"Stefan, non sto definendo lo schema del tuo database!"
L'idea di questo progetto era quella di costruire un enorme sito Web che avrebbe dovuto creare molto traffico organico fornendo tonnellate di contenuti, in tutte le varianti visualizzate su diverse pagine e luoghi diversi. Ho organizzato un incontro per discutere la nostra strategia per affrontare questo progetto.
Volevo definire tutte le pagine e i modelli di contenuto che dovrebbero essere inclusi. Non importava quale minuscolo widget o quale barra laterale avesse in mente il client, volevo che fosse chiaramente definito. Il mio obiettivo era creare una solida struttura di contenuto che consentisse di fornire un'interfaccia di facile utilizzo per gli editori e fornisse dati riutilizzabili per visualizzarli in qualsiasi formato immaginabile.
Si è scoperto che l'idea di questo progetto non era molto chiara e non riuscivo a ottenere risposte a tutte le mie domande. Il responsabile del progetto non capiva che dovevamo iniziare con un'adeguata modellazione dei contenuti (non progettazione e sviluppo). Per lui, questa era solo una tonnellata di pagine. Il contenuto duplicato e le enormi aree di testo per aggiungere un'enorme quantità di testo non sembravano essere un problema. Nella sua mente, le domande che avevo sulla struttura erano tecniche e loro non avrebbero dovuto preoccuparsene. Per farla breve, non ho realizzato il progetto.
La cosa importante è che la modellazione dei contenuti non riguarda i database.
Si tratta di rendere i tuoi contenuti accessibili e a prova di futuro. Se non riesci a definire le esigenze dei tuoi contenuti all'inizio del progetto, sarà molto difficile, se non impossibile, riutilizzarli in seguito.
La corretta modellazione dei contenuti è la chiave per i siti Web presenti e futuri.
Contentful: un CMS senza testa
Era chiaro che volevo seguire una buona modellazione dei contenuti anche per il mio sito. Tuttavia, c'era un'altra cosa. Non volevo occuparmi del livello di archiviazione per costruire il mio nuovo sito Web, quindi ho deciso di utilizzare Contentful, un CMS headless, su cui sto attualmente lavorando (disclaimer completo!). "Headless" significa che questo servizio offre un'interfaccia web per gestire il contenuto nel cloud e fornisce un'API che mi restituirà i miei dati in formato JSON. La scelta di questo CMS mi ha aiutato a essere subito produttivo poiché avevo un'API disponibile in pochi minuti e non dovevo occuparmi di alcuna configurazione infrastrutturale. Contentful fornisce anche un piano gratuito perfetto per piccoli progetti, come il mio sito web personale.
Una query di esempio per ottenere tutti i post del blog è simile alla seguente:
<a href="https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post">https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post</a>E la risposta, in una versione abbreviata, è simile a questa:
{ "sys": { "type": "Array" }, "total": 7, "skip": 0, "limit": 100, "items": [ { "sys": { "space": {...}, "id": "455OEfg1KUskygWUiKwmkc", "type": "Entry", "createdAt": "2016-07-29T11:53:52.596Z", "updatedAt": "2016-11-09T21:07:19.118Z", "revision": 12, "contentType": {...}, "locale": "en-US" }, "fields": { "title": "How to React to Changing Environments Using matchMedia", "excerpt": "...", "slug": "how-to-react-to-changing-environments-using-match-media", "author": [...], "body": "...", "date": "2014-12-26T00:00+02:00", "comments": true, "externalUrl": "https://4waisenkinder.de/blog/2014/12/26/handle-environment-changes-via-window-dot-matchmedia/" }, {...}, {...}, {...}, {...}, {...}, {...} ] } }La parte migliore di Contentful è che è eccezionale nella modellazione dei contenuti, cosa che richiedevo. Utilizzando l'interfaccia web fornita, posso definire rapidamente tutti i contenuti necessari. La definizione di un particolare modello di contenuto in Contentful è chiamata tipo di contenuto. Un'ottima cosa da sottolineare qui è la capacità di modellare le relazioni tra gli elementi di contenuto. Ad esempio, posso collegare facilmente un autore con un post sul blog. Ciò può comportare alberi di dati strutturati, perfetti da riutilizzare per vari casi d'uso.
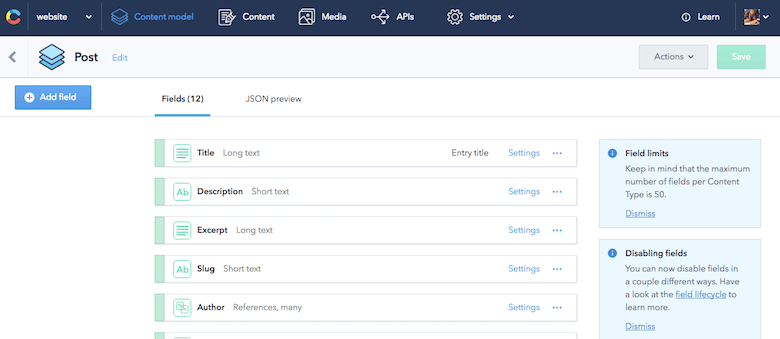
Quindi, ho impostato il mio modello di contenuto senza pensare a nessuna pagina che potrei voler costruire in futuro.
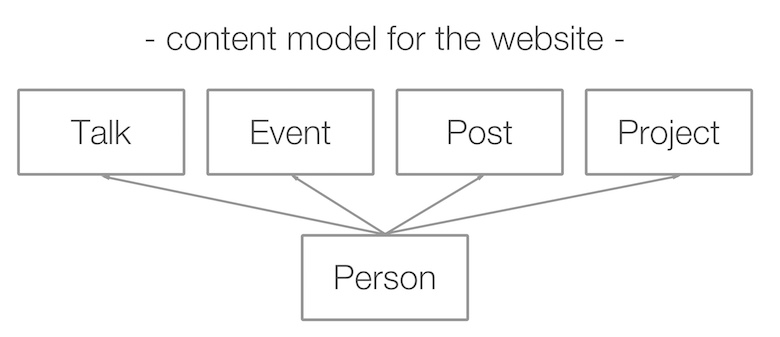
Il passo successivo è stato capire cosa volevo fare con questi dati. Ho chiesto a un designer che conoscevo e mi è venuta in mente una pagina indice del sito web con la seguente struttura.
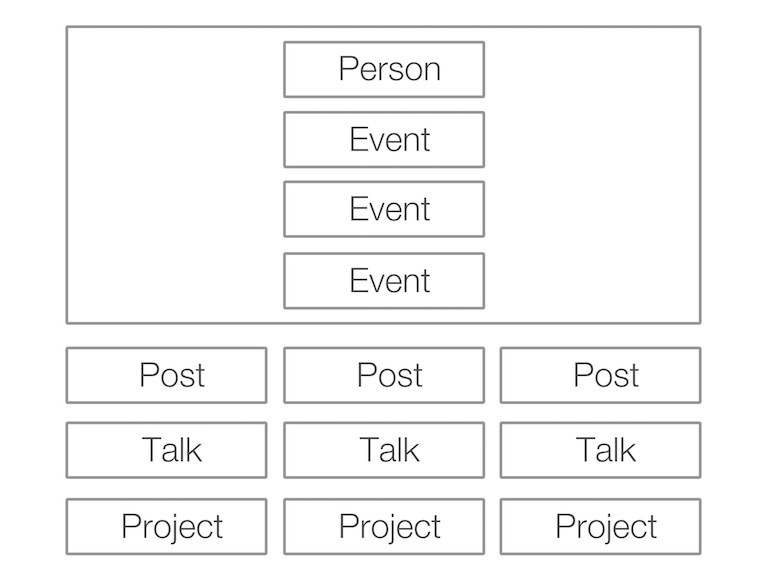
Rendering di pagine HTML utilizzando Node.js
Ora è arrivata la parte difficile. Finora non ho dovuto occuparmi di archiviazione e database, il che è stato un grande risultato per me. Quindi, come posso creare il mio sito Web quando ho solo un'API disponibile?
Il mio primo approccio è stato quello del fai da te. Ho iniziato a scrivere un semplice script Node.js che avrebbe recuperato i dati e visualizzato un po' di HTML.
Il rendering di tutti i file HTML in anticipo ha soddisfatto uno dei miei requisiti principali. L'HTML statico può essere servito molto velocemente.
Quindi, diamo un'occhiata allo script che ho usato.
'use strict'; const contentful = require('contentful'); const template = require('lodash.template'); const fs = require('fs'); // create contentful client with particular credentials const client = contentful.createClient({ space: 'your_space_id', accessToken: 'your_token' }); // cache templates to not read // them over and over again const TEMPLATES = { index : template(fs.readFileSync(`${__dirname}/templates/index.html`)) }; // fetch all the data Promise.all([ // get posts client.getEntries({content_type: 'content_type_post_id'}), // get events client.getEntries({content_type: 'content_type_event_id'}), // get projects client.getEntries({content_type: 'content_type_project_id'}), // get talk client.getEntries({content_type: 'content_type_talk_id'}), // get specific person client.getEntries({'sys.id': 'person_id'}) ]) .then(([posts, events, projects, talks, persons]) => { const renderedHTML = TEMPLATES.index({ posts, events, projects, talks, person : persons.items[0] }) fs.writeFileSync(`${__dirname}/build/index.html`, renderedHTML); console.log('Rendered HTML'); }) .catch(console.error); <!doctype html> <html lang="en"> <head> <!-- ... --> </head> <body> <!-- ... --> <h2>Posts</h2> <ul> <% posts.items.forEach( function( talk ) { %> <li><%- talk.fields.title %> <% }) %> </ul> <!-- ... --> </body> </html>Questo ha funzionato bene. Potrei costruire il mio sito Web desiderato in un modo completamente flessibile, prendendo tutte le decisioni sulla struttura e la funzionalità dei file. Il rendering di diversi tipi di pagina con set di dati completamente diversi non è stato affatto un problema. Tutti coloro che hanno combattuto contro le regole e la struttura di un CMS esistente che viene fornito con il rendering HTML sanno che la completa libertà può essere una cosa eccellente. Soprattutto, quando il modello di dati diventa più complesso nel tempo e include molte relazioni, la flessibilità ripaga.
In questo script Node.js viene creato un client Contentful SDK e tutti i dati vengono recuperati utilizzando il metodo client getEntries . Tutti i metodi forniti dal client sono basati su promesse, il che rende facile evitare callback profondamente nidificati. Per la creazione di modelli, ho deciso di utilizzare il motore di creazione di modelli di lodash. Infine, per la lettura e la scrittura di file, Node.js offre il modulo fs nativo, che viene poi utilizzato per leggere i template e scrivere l'HTML renderizzato.
Tuttavia, c'era un aspetto negativo in questo approccio; era molto scarno. Anche quando questo metodo era completamente flessibile, sembrava di reinventare la ruota. Quello che stavo costruendo era fondamentalmente un generatore di siti statici, e ce ne sono già molti là fuori. Era ora di ricominciare tutto da capo.
Alla ricerca di un vero generatore di siti statici
Famosi generatori di siti statici, ad esempio Jekyll o Middleman, di solito gestiscono file Markdown che verranno renderizzati in HTML. Gli editor lavorano con questi e il sito Web viene creato utilizzando un comando CLI. Tuttavia, questo approccio non stava rispettando uno dei miei requisiti iniziali. Volevo essere in grado di modificare il sito ovunque mi trovassi, senza fare affidamento su file che si trovano sul mio computer privato.

La mia prima idea è stata quella di eseguire il rendering di questi file Markdown utilizzando l'API. Anche se questo avrebbe funzionato, non sembrava giusto. Il rendering dei file Markdown per la successiva trasformazione in HTML erano ancora due passaggi che non offrivano un grande vantaggio rispetto alla mia soluzione iniziale.
Fortunatamente, ci sono integrazioni Contentful, ad esempio Metalsmith e Middleman. Ho scelto Metalsmith per questo progetto, poiché è scritto in Node.js e non volevo inserire una dipendenza da Ruby.
Metalsmith trasforma i file da una cartella di origine e ne esegue il rendering in una cartella di destinazione. Questi file non devono necessariamente essere file Markdown. Puoi anche usarlo per transpilare Sass o ottimizzare le tue immagini. Non ci sono limiti ed è davvero flessibile.
Utilizzando l'integrazione Contentful, sono stato in grado di definire alcuni file di origine che sono stati presi come file di configurazione e quindi ho potuto recuperare tutto il necessario dall'API.
--- title: Blog contentful: content_type: content_type_id entry_filename_pattern: ${ fields.slug } entry_template: article.html order: '-fields.date' filter: include: 5 layout: blog.html description: >- Recent articles by Stefan Judis. --- Questa configurazione di esempio esegue il rendering dell'area del post del blog con un file blog.html padre, inclusa la risposta della richiesta API, ma esegue anche il rendering di diverse pagine figlio utilizzando il modello article.html . I nomi dei file per le pagine figlie sono definiti tramite entry_filename_pattern .
Come vedi, con qualcosa del genere, posso creare facilmente le mie pagine. Questa configurazione ha funzionato perfettamente per garantire che tutte le pagine dipendessero dall'API.
Collega il servizio con il tuo progetto
L'unica parte mancante era collegare il sito al servizio CMS e renderlo nuovamente renderizzato quando qualsiasi contenuto veniva modificato. La soluzione a questo problema sono i webhook, che potresti già conoscere se utilizzi servizi come GitHub.
I webhook sono richieste fatte da software as a service a un endpoint precedentemente definito che ti avvisa che è successo qualcosa. GitHub, ad esempio, può eseguire il ping indietro quando qualcuno ha aperto una richiesta pull in uno dei tuoi repository. Per quanto riguarda la gestione dei contenuti, possiamo applicare lo stesso principio qui. Ogni volta che accade qualcosa con il contenuto, eseguire il ping di un endpoint e fare in modo che un particolare ambiente reagisca ad esso. Nel nostro caso, ciò significherebbe ridisegnare l'HTML usando metalsmith.
Per accettare webhook sono andato anche con una soluzione JavaScript. La mia scelta di hosting provider (Uberspace) permette di installare Node.js e utilizzare JavaScript lato server.
const http = require('http'); const exec = require('child_process').exec; const server = http.createServer((req, res) => { res.setHeader('Content-Type', 'text/plain'); // check for secret header // to not open up this endpoint for everybody if (req.headers.secret === 'YOUR_SECRET') { res.end('ok'); // wait for the CDN to // invalidate the data setTimeout(() => { // execute command exec('npm start', { cwd: __dirname }, (error) => { if (error) { return console.log(error); } console.log('Rebuilt success'); }); }, 1000 * 120 ); } else { res.end('Not allowed'); } }); console.log('Started server at 8000'); server.listen(8000); Questo script avvia un semplice server HTTP sulla porta 8000. Controlla le richieste in arrivo per un'intestazione corretta per assicurarsi che sia il webhook di Contentful. Se la richiesta viene confermata come webhook, viene eseguito il comando predefinito npm start per eseguire nuovamente il rendering di tutte le pagine HTML. Potresti chiederti perché c'è un timeout in atto. Ciò è necessario per sospendere le azioni per un momento fino a quando i dati nel cloud non vengono invalidati perché i dati archiviati vengono serviti da una rete CDN.
A seconda dell'ambiente, questo server HTTP potrebbe non essere accessibile a Internet. Il mio sito viene servito utilizzando un server Apache, quindi ho dovuto aggiungere una regola di riscrittura interna per rendere il server del nodo in esecuzione accessibile a Internet.
# add node endpoint to enable webhooks RewriteRule ^rerender/(.*) https://localhost:8000/$1 [P]API-First e dati strutturati: i migliori amici per sempre
A questo punto, sono stato in grado di gestire tutti i miei dati nel cloud e il mio sito Web avrebbe reagito di conseguenza dopo le modifiche.
Ripetizione dappertutto
Essere in viaggio è una parte importante della mia vita, quindi era necessario avere a portata di mano informazioni, come l'ubicazione di un determinato luogo o l'hotel che avevo prenotato, solitamente archiviate in un foglio di lavoro di Google. Ora, le informazioni sono state distribuite su un foglio di calcolo, diverse e-mail, il mio calendario e il mio sito Web.
Devo ammettere che ho creato molta duplicazione dei dati nel mio flusso quotidiano.
Il momento dei dati strutturati
Ho sognato un'unica fonte di verità, (preferibilmente sul mio telefono) per vedere rapidamente quali eventi stavano arrivando, ma anche ottenere informazioni aggiuntive su hotel e luoghi. Gli eventi elencati sul mio sito Web non avevano tutte le informazioni a questo punto, ma è davvero facile aggiungere nuovi campi a un tipo di contenuto in Contentful. Quindi, ho aggiunto i campi necessari al tipo di contenuto "Evento".
Inserire queste informazioni nel CMS del mio sito Web non è mai stata mia intenzione, in quanto non dovrebbe essere visualizzato online, ma averlo accessibile tramite un'API mi ha fatto capire che ora potrei fare cose completamente diverse con questi dati.
Creazione di un'app nativa con JavaScript
La creazione di app per dispositivi mobili è un argomento ormai da anni e ci sono diversi approcci a questo. Le Progressive Web Apps (PWA) sono un argomento particolarmente caldo in questi giorni. Utilizzando Service Workers e un manifesto dell'app Web, è possibile creare esperienze complete simili a quelle di un'app, passando da un'icona della schermata iniziale a un comportamento offline gestito utilizzando le tecnologie Web.
C'è un aspetto negativo da menzionare. Le app Web progressive sono in aumento, ma non sono ancora completamente disponibili. I Service Workers, ad esempio, non sono supportati su Safari oggi e finora solo "in considerazione" da parte di Apple. Questo è stato un problema per me perché volevo avere un'app compatibile anche offline su iPhone.
Quindi ho cercato delle alternative. Un mio amico era davvero appassionato di NativeScript e continuava a parlarmi di questa tecnologia abbastanza nuova. NativeScript è un framework open source per la creazione di app mobili veramente native con JavaScript, quindi ho deciso di provarlo.
Conoscere NativeScript
L'installazione di NativeScript richiede del tempo perché devi installare molte cose da sviluppare per ambienti mobili nativi. Verrai guidato attraverso il processo di installazione quando installi lo strumento da riga di comando NativeScript per la prima volta utilizzando npm install nativescript -g .
Quindi, puoi utilizzare i comandi di scaffolding per impostare nuovi progetti: tns create MyNewApp
Tuttavia, questo non è quello che ho fatto. Stavo scansionando la documentazione e mi sono imbattuto in un'app di gestione della spesa di esempio costruita in NativeScript. Quindi ho preso questa app, ho scavato nel codice e l'ho modificata passo dopo passo, adattandola alle mie esigenze.
Non voglio immergermi troppo in profondità nel processo, ma per costruire una buona lista con tutte le informazioni che volevo, non ci è voluto molto.
NativeScript funziona molto bene insieme ad Angular 2, cosa che non volevo provare questa volta poiché scoprire NativeScript stesso mi sembrava abbastanza grande. In NativeScript devi scrivere "Viste". Ogni vista è costituita da un file XML che definisce il layout di base e JavaScript e CSS opzionali. Tutti questi sono definiti in una cartella per vista.
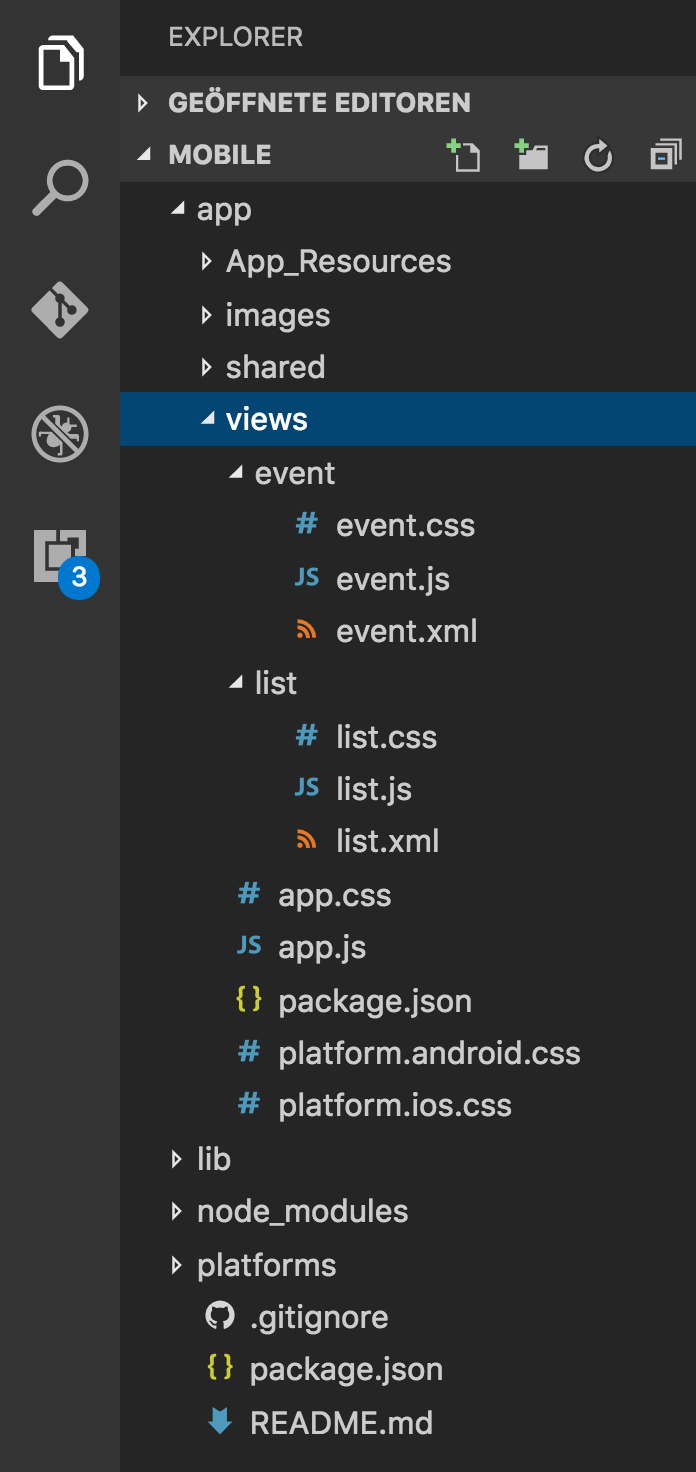
Il rendering di un elenco semplice può essere ottenuto con un modello XML come questo:
<!-- call JavaScript function when ready --> <Page loaded="loaded"> <ActionBar title="All Travels" /> <!-- make it scrollable when going too big --> <ScrollView> <!-- iterate over the entries in context --> <ListView items="{{ entries }}"> <ListView.itemTemplate> <Label text="{{ fields.name }}" textWrap="true" class="headline"/> </ListView.itemTemplate> </ListView> </ScrollView> </Page> La prima cosa che accade qui è definire un elemento di pagina. All'interno di questa pagina, ho definito una ActionBar per darle il classico aspetto Android e un titolo adeguato. Costruire cose per ambienti nativi a volte può essere un po' complicato. Ad esempio, per ottenere un comportamento di scorrimento funzionante è necessario utilizzare un "ScrollView". L'ultima cosa è quindi, scorrere semplicemente i miei eventi usando ListView . Nel complesso, è sembrato piuttosto semplice!
Ma da dove provengono queste voci che vengono utilizzate nella vista? Si scopre che esiste un oggetto di contesto condiviso che può essere utilizzato per questo. Durante la lettura dell'XML per la visualizzazione, potresti aver già notato che la pagina ha un set di attributi loaded . Impostando questo attributo, dico alla vista di chiamare una particolare funzione JavaScript quando la pagina viene caricata.
Questa funzione JavaScript è definita nel file JS dipendente. Può essere reso accessibile semplicemente esportandolo utilizzando exports.something . Per aggiungere il data binding, tutto ciò che dobbiamo fare è impostare un nuovo Observable nella proprietà della pagina bindingContext . Gli osservabili in NativeScript emettono eventi propertyChange necessari per reagire alle modifiche dei dati all'interno delle isualizzazioni, ma non devi preoccuparti di questo, poiché funziona immediatamente.
const context = new Observable({ entries: null}); const fetchModule = require('fetch'); // export loaded to be called from // List.xml when everything is loaded exports.loaded = (args) => { const page = args.object; page.bindingContext = context; fetchModule.fetch( `https://cdn.contentful.com/spaces/${config.space}/entries?access_token=${config.cda.token}&content_type=event&order=fields.start`, { method: "GET", headers: { 'Content-Type': 'application/json' } } ) .then(response => response.json()) .then(response => context.set('entries', response.items)); } L'ultima cosa è recuperare i dati e impostarli nel contesto. Questo può essere fatto usando il modulo di fetch di NativeScript. Qui puoi vedere il risultato.
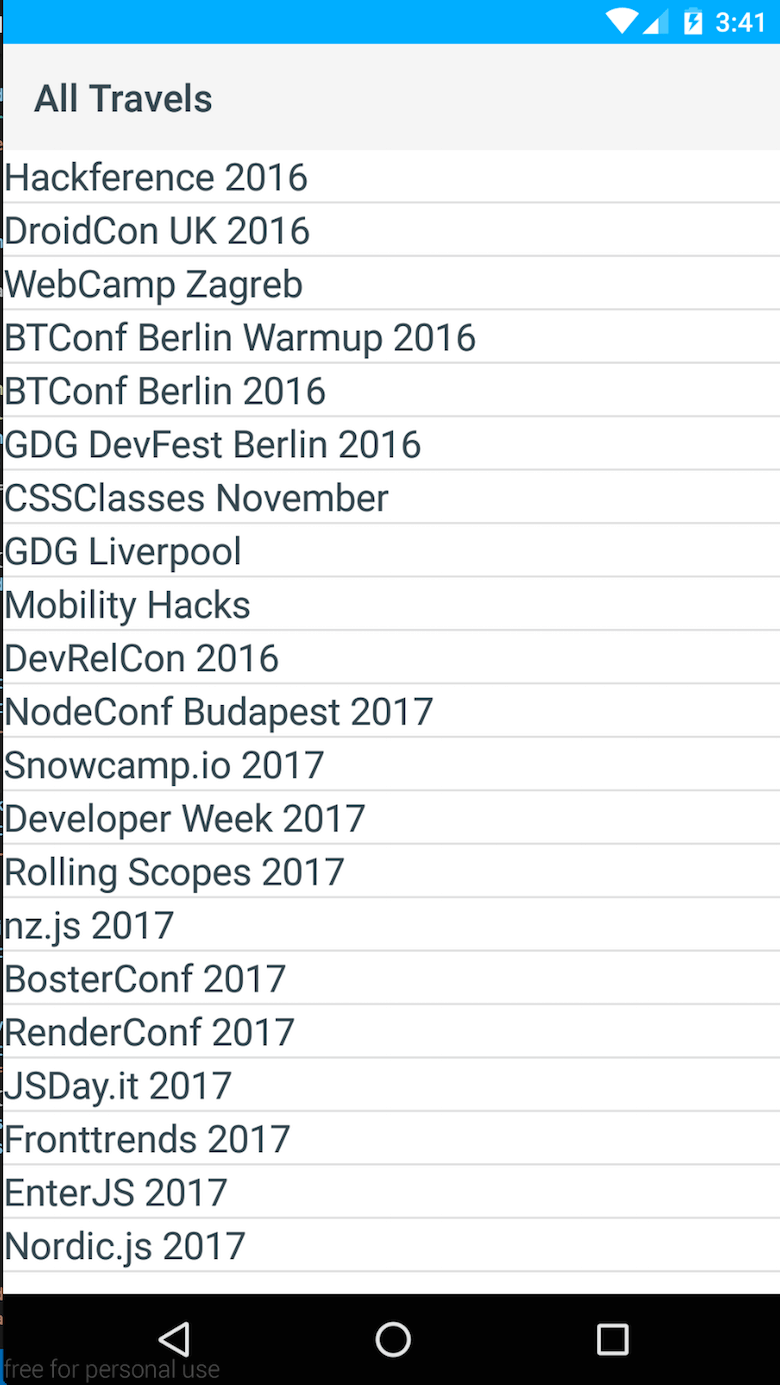
Quindi, come puoi vedere, creare un semplice elenco utilizzando NativeScript non è molto difficile. Successivamente ho esteso l'app con un'altra vista e funzionalità aggiuntive per aprire determinati indirizzi in Google Maps e viste Web per guardare i siti Web degli eventi.
Una cosa da sottolineare qui è che NativeScript è ancora piuttosto nuovo, il che significa che i plugin trovati su npm di solito non hanno molti download o stelle su GitHub. Questo mi ha irritato all'inizio, ma ho usato diversi componenti nativi (nativescript-floatingactionbutton, nativescript-advanced-webview e nativescript-pulltorefresh) che mi hanno aiutato a ottenere un'esperienza nativa e tutto ha funzionato perfettamente.
Puoi vedere il risultato migliorato qui:
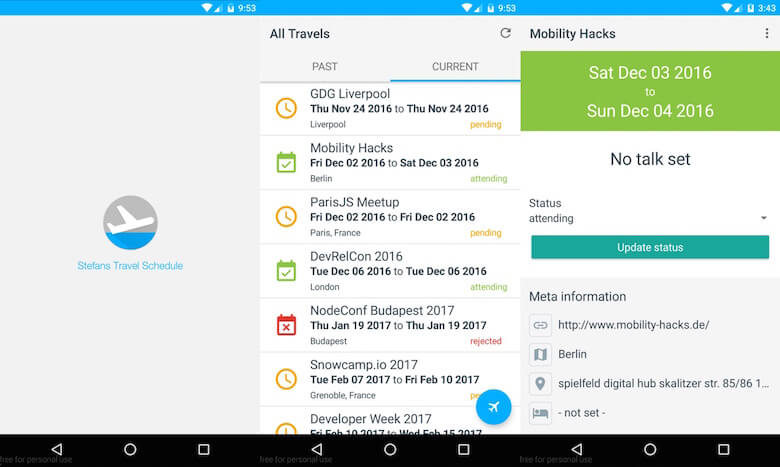
Più funzionalità inserisco in questa app, più mi è piaciuta e più l'ho usata. La parte migliore è che potrei sbarazzarmi della duplicazione dei dati, gestendo i dati tutti in un unico posto, essendo abbastanza flessibile da visualizzarli per vari casi d'uso.
Le pagine sono ieri: lunga vita ai contenuti strutturati!
La creazione di questa app mi ha mostrato ancora una volta che il principio di avere dati in formato pagina appartiene al passato. Non sappiamo dove andranno a finire i nostri dati: dobbiamo essere pronti per un numero illimitato di casi d'uso.
Guardando indietro, quello che ho ottenuto è:
- Avere un sistema di gestione dei contenuti nel cloud
- Non avere a che fare con la manutenzione del database
- Uno stack tecnologico JavaScript completo
- Avere un sito web statico efficiente
- Avere un'app Android per accedere ai miei contenuti sempre e ovunque
E la parte più importante:
Avere i miei contenuti strutturati e accessibili mi ha aiutato a migliorare la mia vita quotidiana.
Questo caso d'uso potrebbe sembrarti banale in questo momento, ma quando pensi ai prodotti che costruisci ogni giorno, ci sono sempre più casi d'uso per i tuoi contenuti su piattaforme diverse. Oggi accettiamo che i dispositivi mobili stiano finalmente superando gli ambienti desktop della vecchia scuola, ma piattaforme come automobili, orologi e persino frigoriferi stanno già aspettando i loro riflettori. Non riesco nemmeno a pensare ai casi d'uso che verranno.
Quindi, proviamo a essere pronti e mettiamo nel mezzo il contenuto strutturato perché alla fine non si tratta di schemi di database, ma di costruire per il futuro.
Ulteriori letture su SmashingMag:
- Web scraping con Node.js
- Sailing With Sails.js: un framework in stile MVC per Node.js
- 40 icone di viaggio per abbellire i tuoi progetti
- Un'introduzione dettagliata al Webpack