
I 10 migliori comandi Hadoop [con usi]
Pubblicato: 2021-01-29In quest'epoca, con enormi quantità di dati, diventa essenziale gestirli. I dati che scaturiscono dalle organizzazioni con clienti in crescita sono molto più grandi di quanto qualsiasi strumento di gestione dei dati tradizionale possa archiviare. Ci lascia con la questione di gestire insiemi di dati più grandi, che potrebbero variare da gigabyte a petabyte, senza utilizzare un singolo computer di grandi dimensioni o uno strumento di gestione dei dati tradizionale.
È qui che il framework Apache Hadoop prende i riflettori. Prima di immergerci nell'implementazione del comando Hadoop, comprendiamo brevemente il framework Hadoop e la sua importanza.
Sommario
Cos'è Hadoop?
Hadoop è comunemente utilizzato dalle principali organizzazioni aziendali per risolvere vari problemi, dall'archiviazione di grandi GB (Gigabyte) di dati ogni giorno alle operazioni di elaborazione sui dati.
Tradizionalmente definito come un framework software open source utilizzato per archiviare dati e applicazioni di elaborazione, Hadoop si distingue in modo piuttosto netto dalla maggior parte degli strumenti di gestione dei dati tradizionali. Migliora la potenza di calcolo ed estende il limite di archiviazione dei dati aggiungendo alcuni nodi nel framework, rendendolo altamente scalabile. Inoltre, i tuoi dati e i processi applicativi sono protetti da vari guasti hardware.
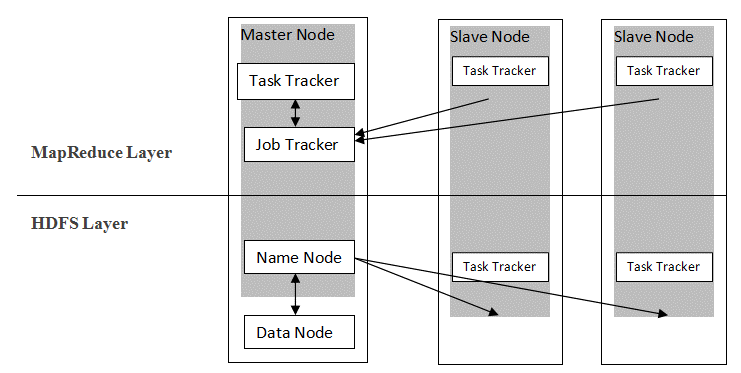
Hadoop segue un'architettura master-slave per distribuire e archiviare dati utilizzando MapReduce e HDFS. Come illustrato nella figura seguente, l'architettura è personalizzata in modo definito per eseguire operazioni di gestione dei dati utilizzando quattro nodi primari, ovvero Nome, Dati, Master e Slave. I componenti principali di Hadoop sono costruiti direttamente sopra il framework. Altri componenti si integrano direttamente con i segmenti.
 Fonte
Fonte

Comandi Hadoop
Le principali caratteristiche del framework Hadoop mostrano una natura coerente e diventa più intuitivo quando si tratta di gestire i big data con l'apprendimento dei comandi Hadoop. Di seguito sono riportati alcuni comodi comandi Hadoop che consentono di eseguire varie operazioni, come la gestione e l'elaborazione dei file dei cluster HDFS. Questo elenco di comandi è spesso richiesto per ottenere determinati risultati del processo.
1. Hadoop Touchz
hadoop fs -touchz /directory/nomefile
Questo comando consente all'utente di creare un nuovo file nel cluster HDFS. La "directory" nel comando si riferisce al nome della directory in cui l'utente desidera creare il nuovo file e il "filename" indica il nome del nuovo file che verrà creato al completamento del comando.
2. Comando di prova Hadoop
hadoop fs -test -[defsz] <percorso>
Questo particolare comando soddisfa lo scopo di verificare l'esistenza di un file nel cluster HDFS. I caratteri di "[defsz]" nel comando devono essere modificati secondo necessità. Ecco una breve descrizione di questi personaggi:
- d -> Controlla se è una directory o meno
- e -> Controlla se è un percorso o meno
- f -> Verifica se si tratta di un file o meno
- s -> Controlla se è un percorso vuoto o meno
- r -> Verifica l'esistenza del percorso e il permesso di lettura
- w -> Verifica l'esistenza del percorso e il permesso di scrittura
- z -> Controlla la dimensione del file
3. Comando di testo Hadoop
hadoop fs -text <src>
Il comando di testo è particolarmente utile per visualizzare il file zip allocato in formato testo. Funziona elaborando i file di origine e fornendo il suo contenuto in un semplice formato di testo decodificato.
4. Comando Trova Hadoop
hadoop fs -find <percorso> … <espressione>

Questo comando viene generalmente utilizzato allo scopo di cercare file nel cluster HDFS. Esegue la scansione dell'espressione data nel comando con tutti i file nel cluster e visualizza i file che corrispondono all'espressione definita.
Leggi: I migliori strumenti Hadoop
5. Comando Hadoop Getmerge
hadoop fs -getmerge <src> <localdest>
Il comando Getmerge consente di unire uno o più file in una directory designata sul cluster del filesystem HDFS. Accumula i file in un unico file situato nel filesystem locale. "src" e "localdest" rappresentano il significato di origine-destinazione e destinazione locale.
6. Comando Conte Hadoop
hadoop fs -count [opzioni] <percorso>
Evidente come il suo nome, il comando Hadoop count conta il numero di file e byte in una determinata directory. Sono disponibili varie opzioni che modificano l'output secondo il requisito. Questi sono i seguenti:
- q -> quota mostra il limite al numero totale di nomi e all'utilizzo dello spazio
- u -> mostra solo la quota e l'utilizzo
- h -> fornisce la dimensione di un file
- v -> visualizza l'intestazione
7. Comando Hadoop AppendToFile
hadoop fs -appendToFile <localsrc> <dest>
Consente all'utente di aggiungere il contenuto di uno o più file in un unico file sul file di destinazione specificato nel cluster del filesystem HDFS. All'esecuzione di questo comando, i file di origine forniti vengono aggiunti all'origine di destinazione secondo il nome file specificato nel comando.
8. Comando Hadoop ls
hadoop fs -ls /percorso
Il comando ls in Hadoop mostra l'elenco di file/contenuti in una directory specificata, cioè il percorso. Aggiungendo "R" prima di /percorso, l'output mostrerà i dettagli del contenuto, come nomi, dimensioni, proprietario e così via per ogni file specificato nella directory specificata.
9. Comando Hadoop mkdir
hadoop fs -mkdir /percorso/nome_directory
La caratteristica unica di questo comando è la creazione di una directory nel cluster del filesystem HDFS se la directory non esiste. Inoltre, se la directory specificata è presente, il messaggio di output mostrerà un errore che indica l'esistenza della directory.
10. Comando Hadoop chmod
hadoop fs -chmod [-R] <modalità> <percorso>
Questo comando viene utilizzato quando è necessario modificare i permessi per accedere a un determinato file. Dando il comando chmod, l'autorizzazione del file specificato viene modificata. Tuttavia, è importante ricordare che l'autorizzazione verrà modificata quando il proprietario del file esegue questo comando.
Leggi anche: Impala Hadoop Tutorial
Conclusione
Partendo dall'importante questione dell'archiviazione dei dati affrontata dalle principali organizzazioni nel mondo di oggi, questo articolo ha discusso la soluzione per l'archiviazione limitata dei dati introducendo Hadoop e il suo impatto sull'esecuzione delle operazioni di gestione dei dati utilizzando i comandi Hadoop. Per i principianti in Hadoop, viene descritta una panoramica del framework insieme ai suoi componenti e all'architettura.

Dopo aver letto questo articolo, ci si può facilmente sentire sicuri della propria conoscenza dell'aspetto del framework Hadoop e dei suoi comandi applicati. Certificazione PG esclusiva di upGrad nei Big Data: upGrad offre un programma di 7,5 mesi specifico del settore per la certificazione PG nei Big Data in cui organizzerai, analizzerai e interpreterai i Big Data con IIIT-Bangalore.
Progettato con attenzione per i professionisti che lavorano, aiuterà gli studenti ad acquisire conoscenze pratiche e favorirà il loro ingresso nei ruoli di Big Data.
Punti salienti del programma:
- Imparare lingue e strumenti rilevanti
- Apprendimento di concetti avanzati di Programmazione Distribuita, Piattaforme Big Data, Database, Algoritmi e Web Mining
- Un certificato accreditato da IIIT Bangalore
- Assistenza al posizionamento per essere assorbiti dalle migliori multinazionali
- Tutoraggio 1:1 per monitorare i tuoi progressi e assisterti in ogni momento
- Lavorare su progetti e incarichi dal vivo
Idoneità : background di matematica/ingegneria del software/statistica/analisi
Controlla i nostri altri corsi di ingegneria del software su upGrad.