
Discesa graduale nell'apprendimento automatico: come funziona?
Pubblicato: 2021-01-28Sommario
introduzione
Una delle parti più cruciali del Machine Learning è l'ottimizzazione dei suoi algoritmi. Quasi tutti gli algoritmi in Machine Learning hanno un algoritmo di ottimizzazione alla base che funge da nucleo dell'algoritmo. Come tutti sappiamo, l'ottimizzazione è l'obiettivo finale di qualsiasi algoritmo anche con eventi della vita reale o quando si ha a che fare con un prodotto basato sulla tecnologia sul mercato.
Attualmente ci sono molti algoritmi di ottimizzazione che vengono utilizzati in diverse applicazioni come riconoscimento facciale, auto a guida autonoma, analisi di mercato, ecc. Allo stesso modo, in Machine Learning tali algoritmi di ottimizzazione svolgono un ruolo importante. Uno di questi algoritmi di ottimizzazione ampiamente utilizzato è l'algoritmo di discesa del gradiente che esamineremo in questo articolo.
Cos'è la discesa graduale?
In Machine Learning, l'algoritmo Gradient Descent è uno degli algoritmi più utilizzati e tuttavia stupisce la maggior parte dei nuovi arrivati. Matematicamente, Gradient Descent è un algoritmo di ottimizzazione iterativo del primo ordine utilizzato per trovare il minimo locale di una funzione differenziabile. In parole povere, questo algoritmo di discesa del gradiente viene utilizzato per trovare i valori dei parametri (o coefficienti) di una funzione che vengono utilizzati per ridurre al minimo una funzione di costo il più basso possibile. La funzione di costo viene utilizzata per quantificare l'errore tra i valori previsti e i valori reali di un modello di Machine Learning costruito.
Intuizione della discesa graduale
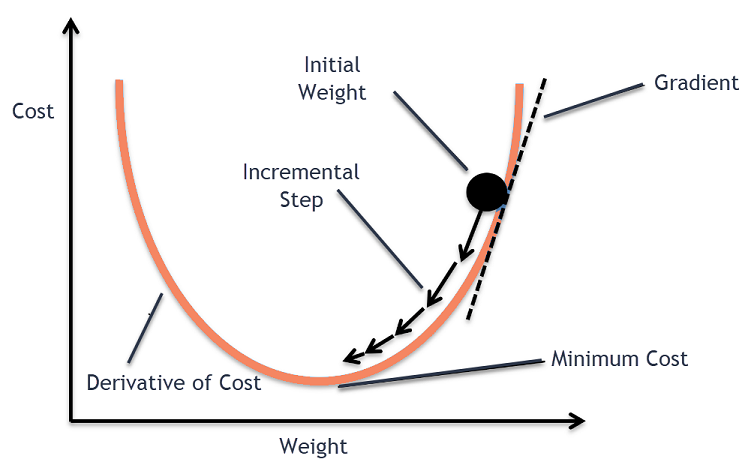
Prendi in considerazione una grande ciotola con la quale normalmente conserveresti frutta o mangeresti cereali. Questa ciotola sarà la funzione di costo (f).
Ora, una coordinata casuale su qualsiasi parte della superficie della ciotola sarà i valori correnti dei coefficienti della funzione di costo. Il fondo della ciotola è il miglior insieme di coefficienti ed è il minimo della funzione.
Qui, l'obiettivo è calcolare i diversi valori dei coefficienti ad ogni iterazione, valutare il costo e scegliere i coefficienti che hanno un valore della funzione di costo migliore (valore inferiore). Su più iterazioni, si troverebbe che il fondo della ciotola ha i migliori coefficienti per ridurre al minimo la funzione di costo.

In questo modo, l'algoritmo Gradient Descent funziona per ottenere un costo minimo.
Partecipa al corso di Machine Learning online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
Procedura di discesa graduale
Questo processo di discesa del gradiente inizia con l'allocazione dei valori inizialmente ai coefficienti della funzione di costo. Questo potrebbe essere un valore vicino a 0 o un piccolo valore casuale.
coefficiente = 0,0
Successivamente, il costo dei coefficienti si ottiene applicandolo alla funzione di costo e calcolando il costo.
costo = f(coefficiente)
Quindi, viene calcolata la derivata della funzione di costo. Questa derivata della funzione di costo è ottenuta dal concetto matematico di calcolo differenziale. Ci dà la pendenza della funzione nel punto dato in cui viene calcolata la sua derivata. Questa pendenza è necessaria per sapere in quale direzione deve essere spostato il coefficiente nell'iterazione successiva per ottenere un valore di costo inferiore. Ciò avviene osservando il segno della derivata calcolata.
delta = derivata (costo)
Una volta che sappiamo quale direzione è in discesa rispetto alla derivata calcolata, dobbiamo aggiornare i valori dei coefficienti. Per questo, un parametro è noto come parametro di apprendimento, viene utilizzato alfa (α). Viene utilizzato per controllare fino a che punto i coefficienti possono cambiare ad ogni aggiornamento.
coefficiente = coefficiente – (alfa * delta)
Fonte
In questo modo, questo processo viene ripetuto fino a quando il costo dei coefficienti è uguale a 0,0 o abbastanza vicino a zero. Questa è la procedura per l'algoritmo di discesa del gradiente.
Tipi di algoritmi di discesa del gradiente
Nei tempi moderni, esistono tre tipi di base di Gradient Descent che vengono utilizzati nei moderni algoritmi di machine learning e deep learning. La principale differenza tra ciascuno di questi 3 tipi è il suo costo computazionale e l'efficienza. A seconda della quantità di dati utilizzati, della complessità del tempo e dell'accuratezza, i seguenti sono i tre tipi.
- Discesa gradiente batch
- Discesa a gradiente stocastico
- Discesa gradiente mini batch
Discesa gradiente batch
Questa è la prima versione di base degli algoritmi di discesa del gradiente in cui l'intero set di dati viene utilizzato contemporaneamente per calcolare la funzione di costo e il suo gradiente. Poiché l'intero set di dati viene utilizzato in una volta sola per un singolo aggiornamento, il calcolo del gradiente in questo tipo può essere molto lento e non è possibile con quei set di dati che esauriscono la capacità di memoria del dispositivo.
Pertanto, questo algoritmo di discesa gradiente batch viene utilizzato solo per set di dati più piccoli e quando il numero di esempi di addestramento è elevato, la discesa gradiente batch non è preferita. Vengono invece utilizzati gli algoritmi Stocastico e Mini Batch Gradient Descent.
Discesa a gradiente stocastico
Questo è un altro tipo di algoritmo di discesa del gradiente in cui viene elaborato un solo esempio di addestramento per iterazione. In questo, il primo passaggio consiste nel randomizzare l'intero set di dati di addestramento. Quindi, viene utilizzato un solo esempio di allenamento per aggiornare i coefficienti. Ciò è in contrasto con la Batch Gradient Descent in cui i parametri (coefficienti) vengono aggiornati solo quando vengono valutati tutti gli esempi di allenamento.

Stochastic Gradient Descent (SGD) ha il vantaggio che questo tipo di aggiornamento frequente offre un tasso di miglioramento dettagliato. Tuttavia, in alcuni casi, questo può rivelarsi dispendioso dal punto di vista computazionale poiché elabora solo un esempio per ogni iterazione, il che può causare un numero molto elevato di iterazioni.
Discesa gradiente mini batch
Questo è un algoritmo sviluppato di recente che è più veloce di entrambi gli algoritmi Batch e Stochastic Gradient Descent. È per lo più preferito in quanto è una combinazione di entrambi gli algoritmi precedentemente menzionati. In questo, separa il training set in diversi mini-batch ed esegue un aggiornamento per ciascuno di questi batch dopo aver calcolato il gradiente di quel batch (come in SGD).
Comunemente, la dimensione del lotto varia da 30 a 500 ma non esiste una dimensione fissa in quanto variano per le diverse applicazioni. Quindi, anche se esiste un enorme set di dati di addestramento, questo algoritmo lo elabora in mini-batch "b". Pertanto, è adatto per set di dati di grandi dimensioni con un numero inferiore di iterazioni.
Se 'm' è il numero di esempi di addestramento, se b==m il Mini Batch Gradient Descent sarà simile all'algoritmo Batch Gradient Descent.
Varianti della discesa graduale nell'apprendimento automatico
Con questa base per Gradient Descent, sono stati sviluppati molti altri algoritmi da questo. Alcuni di essi sono riassunti di seguito.
Discesa sfumata di vaniglia
Questa è una delle forme più semplici della tecnica della discesa graduale. Il nome vaniglia significa pura o senza alcuna alterazione. In questo si fanno piccoli passi nella direzione dei minimi calcolando il gradiente della funzione di costo. Analogamente all'algoritmo sopra menzionato, la regola di aggiornamento è data da,
coefficiente = coefficiente – (alfa * delta)
Discesa graduale con slancio
In questo caso, l'algoritmo è tale che conosciamo i passaggi precedenti prima di passare al passaggio successivo. Questo viene fatto introducendo un nuovo termine che è il prodotto dell'aggiornamento precedente e una costante nota come slancio. In questo, la regola di aggiornamento del peso è data da,
aggiornamento = alfa * delta
velocità = aggiornamento_precedente * quantità di moto
coefficiente = coefficiente + velocità – aggiornamento
ADAGRADO
Il termine ADAGRAD sta per Adaptive Gradient Algorithm. Come dice il nome, utilizza una tecnica adattiva per aggiornare i pesi. Questo algoritmo è più adatto per dati sparsi. Questa ottimizzazione modifica i suoi tassi di apprendimento in relazione alla frequenza degli aggiornamenti dei parametri durante l'allenamento. Ad esempio, i parametri che hanno gradienti più elevati sono fatti per avere un tasso di apprendimento più lento in modo da non finire per superare il valore minimo. Allo stesso modo, gradienti più bassi hanno un tasso di apprendimento più rapido per allenarsi più rapidamente.
ADAMO
Un altro algoritmo di ottimizzazione adattivo che ha le sue radici nell'algoritmo Gradient Descent è l'ADAM che sta per Adaptive Moment Estimation. È una combinazione di ADAGRAD e SGD con algoritmi Momentum. È costruito dall'algoritmo ADAGRAD ed è costruito ulteriormente al ribasso. In parole povere ADAM = ADAGRAD + Momentum.
In questo modo, ci sono molte altre varianti di algoritmi di discesa graduale che sono state sviluppate e sono in fase di sviluppo nel mondo come AMSGrad, ADAMax.
Conclusione
In questo articolo, abbiamo visto l'algoritmo alla base di uno degli algoritmi di ottimizzazione più comunemente usati in Machine Learning, gli algoritmi di discesa del gradiente, insieme ai suoi tipi e varianti che sono stati sviluppati.
upGrad offre un programma Executive PG in Machine Learning e AI e un Master of Science in Machine Learning e AI che potrebbero guidarti verso la costruzione di una carriera. Questi corsi spiegheranno la necessità dell'apprendimento automatico e ulteriori passaggi per raccogliere conoscenze in questo dominio che coprono vari concetti che vanno dalla discesa graduale all'apprendimento automatico.
Dove può contribuire al massimo l'algoritmo di discesa del gradiente?
L'ottimizzazione all'interno di qualsiasi algoritmo di apprendimento automatico è incrementale per la purezza dell'algoritmo. L'algoritmo di discesa del gradiente aiuta a ridurre al minimo gli errori della funzione di costo e a migliorare i parametri dell'algoritmo. Sebbene l'algoritmo Gradient Descent sia ampiamente utilizzato in Machine Learning e Deep Learning, la sua efficacia può essere determinata dalla quantità di dati, dalla quantità di iterazioni e dalla precisione preferita e dalla quantità di tempo disponibile. Per set di dati su piccola scala, la discesa gradiente batch è ottimale. Stochastic Gradient Descent (SGD) si rivela più efficiente per set di dati dettagliati e più estesi. Al contrario, Mini Batch Gradient Descent viene utilizzato per un'ottimizzazione più rapida.
Quali sono le sfide affrontate nella discesa in pendenza?
Gradient Descent è preferito per ottimizzare i modelli di apprendimento automatico per ridurre la funzione di costo. Tuttavia, ha anche i suoi difetti. Supponiamo che il gradiente sia diminuito a causa delle funzioni di output minimo dei livelli del modello. In tal caso, le iterazioni non saranno così efficaci in quanto il modello non verrà riqualificato completamente, aggiornandone i pesi e le distorsioni. A volte un gradiente di errore accumula carichi di pesi e distorsioni per mantenere aggiornate le iterazioni. Tuttavia, questo gradiente diventa troppo grande per essere gestito ed è chiamato gradiente che esplode. È necessario affrontare i requisiti dell'infrastruttura, l'equilibrio del tasso di apprendimento e lo slancio.
La discesa del gradiente converge sempre?
La convergenza è quando l'algoritmo di discesa del gradiente minimizza con successo la sua funzione di costo a un livello ottimale. Gradient Descent Algorithm cerca di ridurre al minimo la funzione di costo attraverso i parametri dell'algoritmo. Tuttavia, può atterrare su uno qualsiasi dei punti ottimali e non necessariamente su quello che ha un punto ottimale globale o locale. Una delle ragioni per non avere una convergenza ottimale è la dimensione del passo. Una dimensione del passo più significativa provoca più oscillazioni e può deviare dall'ottimo globale. Quindi, la discesa del gradiente potrebbe non convergere sempre sulla caratteristica migliore, ma atterra comunque sul punto più vicino.