
Discesa graduale nella regressione logistica [spiegata per i principianti]
Pubblicato: 2021-01-08In questo articolo, discuteremo del famosissimo algoritmo di discesa del gradiente nella regressione logistica. Esamineremo cos'è la regressione logistica, quindi ci sposteremo gradualmente verso l'equazione per la regressione logistica, la sua funzione di costo e infine l'algoritmo di discesa del gradiente.
Sommario
Che cos'è la regressione logistica?
La regressione logistica è semplicemente un algoritmo di classificazione utilizzato per prevedere categorie discrete, come prevedere se una posta è "spam" o "non spam"; prevedere se una determinata cifra è un "9" o un "non 9" ecc. Ora, guardando il nome, devi pensare, perché si chiama Regressione?
Il motivo è che l'idea di regressione logistica è stata sviluppata modificando alcuni elementi dell'algoritmo di regressione lineare di base utilizzato nei problemi di regressione.
La regressione logistica può essere applicata anche a problemi di classificazione multiclasse (più di due classi). Tuttavia, si consiglia di utilizzare questo algoritmo solo per problemi di classificazione binaria.
Funzione sigmoidea
I problemi di classificazione non sono problemi di funzione lineare. L'output è limitato a determinati valori discreti, ad esempio 0 e 1 per un problema di classificazione binaria. Non ha senso che una funzione lineare preveda i nostri valori di output come maggiori di 1 o minori di 0. Quindi abbiamo bisogno di una funzione adeguata per rappresentare i nostri valori di output.
La funzione Sigmoide risolve il nostro problema. Conosciuta anche come funzione logistica, è una funzione a forma di S che mappa qualsiasi numero di valore reale su un intervallo (0,1), rendendola molto utile per trasformare qualsiasi funzione casuale in una funzione basata sulla classificazione. Una funzione Sigmoid si presenta così:

Funzione sigmoidea
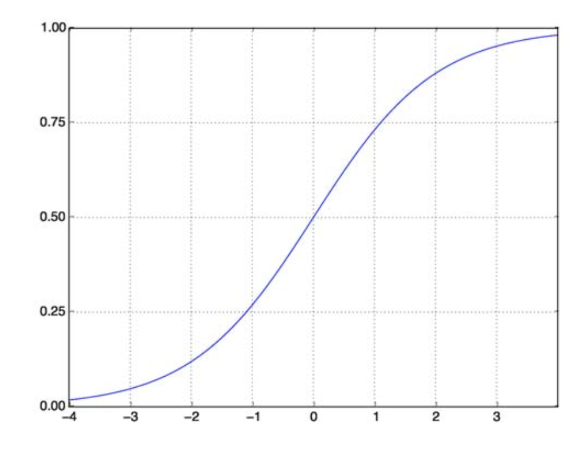
fonte
Ora la forma matematica della funzione sigmoide per il vettore parametrizzato e il vettore di input X è:
(z) = 11+exp(-z) dove z = TX
(z) ci darà la probabilità che l'output sia 1. Come tutti sappiamo, il valore di probabilità varia da 0 a 1. Ora, questo non è l'output che vogliamo per il nostro problema di classificazione a base discreta (solo 0 e 1) . Quindi ora possiamo confrontare la probabilità prevista con 0,5. Se probabilità > 0,5, abbiamo y=1. Allo stesso modo, se la probabilità è < 0,5, abbiamo y=0.
Funzione di costo
Ora che abbiamo le nostre previsioni discrete, è tempo di verificare se le nostre previsioni sono effettivamente corrette o meno. Per fare ciò, abbiamo una funzione di costo. La funzione di costo è semplicemente la somma di tutti gli errori commessi nelle previsioni nell'intero set di dati. Naturalmente, non possiamo utilizzare la funzione di costo utilizzata nella regressione lineare. Quindi la nuova funzione di costo per la regressione logistica è:
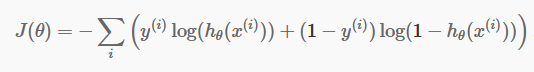 fonte
fonte
Non aver paura dell'equazione. È molto semplice. Per ogni iterazione i , calcola l'errore che abbiamo commesso nella nostra previsione e quindi somma tutti gli errori per definire la nostra funzione di costo J().
I due termini all'interno della parentesi sono in realtà per i due casi: y=0 e y=1. Quando y=0, il primo termine svanisce e rimane solo il secondo termine. Allo stesso modo, quando y=1, il secondo termine svanisce e ci rimane solo il primo termine.
Algoritmo di discesa graduale
Abbiamo calcolato con successo la nostra funzione di costo. Ma dobbiamo ridurre al minimo la perdita per creare un buon algoritmo di previsione. Per farlo, abbiamo l'algoritmo di discesa del gradiente.
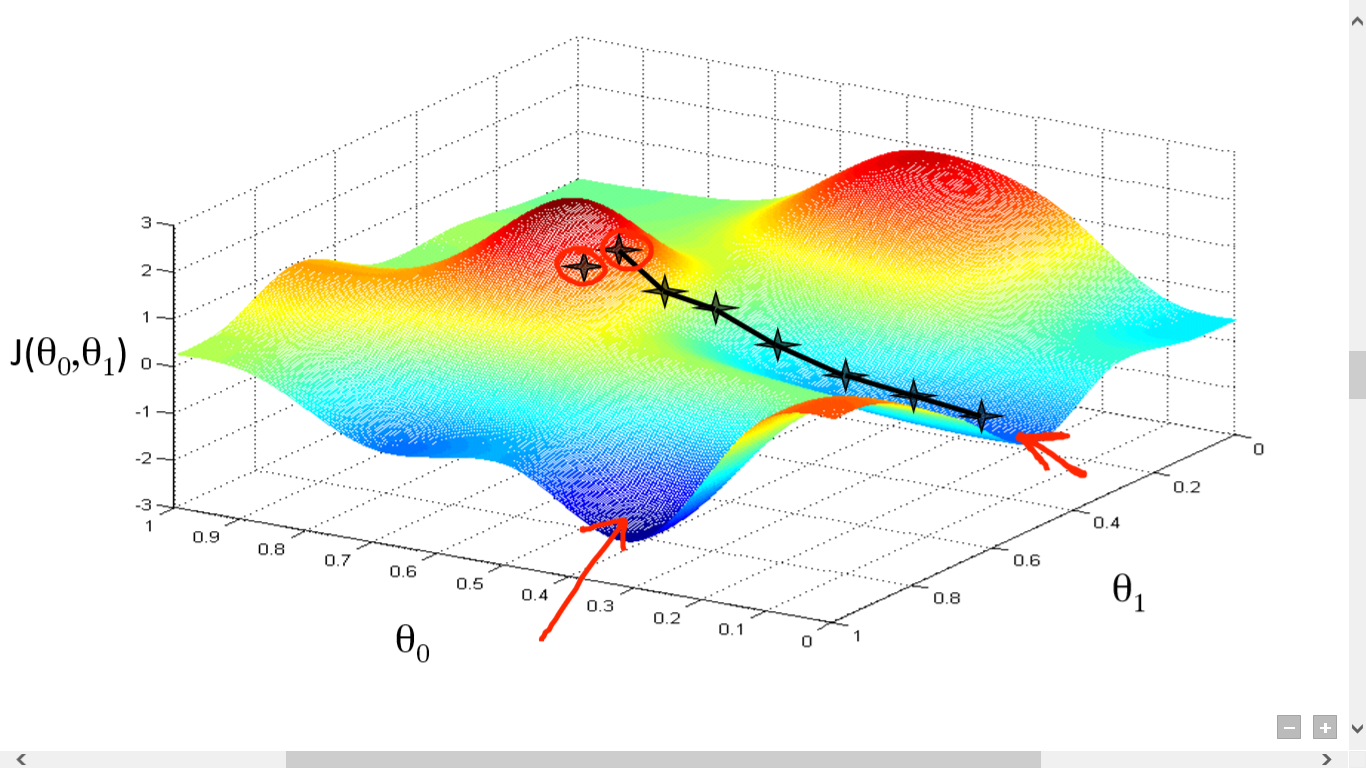 fonte
fonte
Qui abbiamo tracciato un grafico tra J() e . Il nostro obiettivo è trovare il punto più profondo (minimo globale) di questa funzione. Ora il punto più profondo è dove J() è minimo.
Per trovare il punto più profondo sono necessarie due cose:
- Derivato – per trovare la direzione del passaggio successivo.
- (Tasso di apprendimento) – entità del passaggio successivo
L'idea è di selezionare prima un punto casuale dalla funzione. Quindi devi calcolare la derivata di J()wrt . Questo indicherà la direzione del minimo locale. Ora moltiplica il gradiente risultante per il tasso di apprendimento. Il Learning Rate non ha un valore fisso e va deciso in base ai problemi.
Ora, devi sottrarre il risultato da per ottenere il nuovo .
Questo aggiornamento di dovrebbe essere eseguito simultaneamente per ogni (i) .
Esegui questi passaggi ripetutamente fino a raggiungere il minimo locale o globale. Raggiungendo il minimo globale, hai ottenuto la perdita più bassa possibile nella tua previsione.
Prendere derivati è semplice. È sufficiente solo il calcolo di base che devi aver fatto al liceo. Il problema principale riguarda il tasso di apprendimento(). Prendere un buon tasso di apprendimento è importante e spesso difficile.
Se prendi un tasso di apprendimento molto basso, ogni passaggio sarà troppo piccolo e quindi impiegherai molto tempo per raggiungere il minimo locale.

Ora, se tendi a prendere un valore enorme del tasso di apprendimento, supererai il minimo e non convergerai mai più. Non esiste una regola specifica per il tasso di apprendimento perfetto.
Devi modificarlo per preparare il modello migliore.
L'equazione per la discesa del gradiente è:
Ripetere fino alla convergenza:
Quindi possiamo riassumere l'algoritmo di discesa del gradiente come:
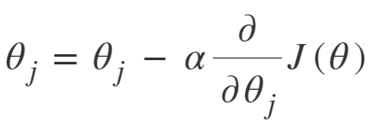
- Inizia con casuale
- Ciclo fino alla convergenza:
- Calcola gradiente
- Aggiornare
- Ritorno
Algoritmo di discesa del gradiente stocastico
Ora, Gradient Descent Algorithm è un ottimo algoritmo per ridurre al minimo la funzione di costo, in particolare per dati di piccole e medie dimensioni. Ma quando abbiamo bisogno di gestire set di dati più grandi, l'algoritmo di discesa del gradiente risulta essere lento nel calcolo. Il motivo è semplice: deve calcolare il gradiente e aggiornare i valori contemporaneamente per ogni parametro e anche per ogni esempio di allenamento.
Quindi pensa a tutti quei calcoli! È enorme, e quindi c'era bisogno di un algoritmo di discesa del gradiente leggermente modificato, vale a dire - Algoritmo di discesa del gradiente stocastico (SGD).
L'unica differenza che SGD ha con Normal Gradient Descent è che, in SGD, non trattiamo l'intera istanza di addestramento in una sola volta. In SGD, calcoliamo il gradiente della funzione di costo per un solo esempio casuale ad ogni iterazione.
Ora, così facendo si riduce il tempo impiegato per i calcoli di un enorme margine, specialmente per set di dati di grandi dimensioni. Il percorso intrapreso da SGD è molto casuale e rumoroso (sebbene un percorso rumoroso possa darci la possibilità di raggiungere i minimi globali).
Ma va bene così, dal momento che non dobbiamo preoccuparci del percorso intrapreso.
Abbiamo solo bisogno di raggiungere una perdita minima in un tempo più veloce.
Quindi possiamo riassumere l'algoritmo di discesa del gradiente come:
- Ciclo fino alla convergenza:
- Scegli un singolo punto dati ' i'
- Calcola gradiente su quel singolo punto
- Aggiornare
- Ritorno
Algoritmo di discesa gradiente mini-batch
Mini-Batch Gradient Descent è un'altra leggera modifica dell'algoritmo Gradient Descent. È in qualche modo a metà strada tra la Discesa Gradiente Normale e la Discesa Gradiente Stocastica.
Mini-Batch Gradient Descent sta solo prendendo un batch più piccolo dell'intero set di dati e quindi riducendo al minimo la perdita su di esso.
Questo processo è più efficiente di entrambi i precedenti due algoritmi di discesa del gradiente. Ora la dimensione del batch può essere ovviamente qualsiasi cosa tu voglia.
Ma i ricercatori hanno dimostrato che è meglio tenerlo entro 1-100, con 32 che è la dimensione del lotto migliore.
Quindi la dimensione del batch = 32 viene mantenuta predefinita nella maggior parte dei framework.
- Ciclo fino alla convergenza:
- Scegli un lotto di punti dati ' b '
- Calcola gradiente su quel batch
- Aggiornare
- Ritorno
Conclusione
Ora hai la comprensione teorica della regressione logistica. Hai imparato a rappresentare matematicamente la funzione logistica. Sai come misurare l'errore previsto usando la funzione di costo.
Sai anche come ridurre al minimo questa perdita usando l'algoritmo di discesa del gradiente.
Infine, sai quale variazione dell'algoritmo di discesa del gradiente dovresti scegliere per il tuo problema. upGrad fornisce un diploma PG in Machine Learning e AI e un Master of Science in Machine Learning e AI che potrebbero guidarti verso la costruzione di una carriera. Questi corsi spiegheranno la necessità dell'apprendimento automatico e ulteriori passaggi per raccogliere conoscenze in questo dominio che coprono vari concetti che vanno dagli algoritmi di discesa del gradiente alle reti neurali.
Che cos'è un algoritmo di discesa del gradiente?
La discesa del gradiente è un algoritmo di ottimizzazione per trovare il minimo di una funzione. Supponiamo di voler trovare il minimo di una funzione f(x) tra due punti (a, b) e (c, d) sul grafico di y = f(x). Quindi la discesa del gradiente prevede tre passaggi: (1) scegliere un punto nel mezzo tra due estremi, (2) calcolare il gradiente ∇f(x) (3) spostarsi nella direzione opposta al gradiente, ovvero da (c, d) a (a, b). Il modo per pensare a questo è che l'algoritmo scopre la pendenza della funzione in un punto e quindi si sposta nella direzione opposta alla pendenza.
Cos'è la funzione sigmoidea?
La funzione sigmoidea, o curva sigmoidea, è un tipo di funzione matematica non lineare e di forma molto simile alla lettera S (da cui il nome). Viene utilizzato nella ricerca operativa, nella statistica e in altre discipline per modellare determinate forme di crescita a valore reale. Viene anche utilizzato in un'ampia gamma di applicazioni nell'informatica e nell'ingegneria, in particolare nelle aree relative alle reti neurali e all'intelligenza artificiale. Le funzioni sigmoidali sono utilizzate come parte degli input per gli algoritmi di apprendimento per rinforzo, che si basano su reti neurali artificiali.
Che cos'è l'algoritmo di discesa del gradiente stocastico?
Stochastic Gradient Descent è una delle varianti popolari del classico algoritmo Gradient Descent per trovare i minimi locali della funzione. L'algoritmo seleziona casualmente la direzione in cui andrà la funzione per ridurre al minimo il valore e la direzione viene ripetuta fino al raggiungimento di un minimo locale. L'obiettivo è che ripetendo continuamente questo processo, l'algoritmo convergerà al minimo globale o locale della funzione.