
Performance front-end 2021: pianificazione e metriche
Pubblicato: 2022-03-10Questa guida è stata gentilmente supportata dai nostri amici di LogRocket, un servizio che combina il monitoraggio delle prestazioni del frontend , la riproduzione delle sessioni e l'analisi dei prodotti per aiutarti a creare esperienze migliori per i clienti. LogRocket tiene traccia delle metriche chiave, incl. DOM completo, tempo al primo byte, primo ritardo di input, CPU client e utilizzo della memoria. Ottieni una prova gratuita di LogRocket oggi.

Sommario
- Preparativi: pianificazione e metriche
Cultura delle prestazioni, Core Web Vitals, profili delle prestazioni, CrUX, Lighthouse, FID, TTI, CLS, dispositivi. - Stabilire obiettivi realistici
Budget prestazionali, obiettivi prestazionali, framework RAIL, budget 170KB/30KB. - Definire l'ambiente
Scelta di un framework, costo delle prestazioni di base, Webpack, dipendenze, CDN, architettura front-end, CSR, SSR, CSR + SSR, rendering statico, prerendering, pattern PRPL. - Ottimizzazioni degli asset
Brotli, AVIF, WebP, immagini reattive, AV1, caricamento multimediale adattivo, compressione video, font web, font Google. - Costruisci ottimizzazioni
Moduli JavaScript, pattern modulo/nomodulo, tree-shaking, code-splitting, scope-hoisting, Webpack, pubblicazione differenziale, web worker, WebAssembly, bundle JavaScript, React, SPA, idratazione parziale, importazione su interazione, terze parti, cache. - Ottimizzazioni di consegna
Caricamento lento, osservatore di intersezione, differire il rendering e la decodifica, CSS critico, streaming, suggerimenti sulle risorse, turni di layout, addetto ai servizi. - Rete, HTTP/2, HTTP/3
Pinzatura OCSP, certificati EV/DV, packaging, IPv6, QUIC, HTTP/3. - Test e monitoraggio
Flusso di lavoro di controllo, browser proxy, pagina 404, richieste di consenso ai cookie GDPR, CSS di diagnostica delle prestazioni, accessibilità. - Vittorie veloci
- Tutto in una pagina
- Scarica la lista di controllo (PDF, Apple Pages, MS Word)
- Iscriviti alla nostra newsletter via email per non perdere le prossime guide.
Prepararsi: pianificazione e metriche
Le micro-ottimizzazioni sono ottime per mantenere le prestazioni in carreggiata, ma è fondamentale avere in mente obiettivi chiaramente definiti, obiettivi misurabili che influenzerebbero qualsiasi decisione presa durante il processo. Esistono un paio di modelli diversi e quelli discussi di seguito sono piuttosto supponenti: assicurati solo di stabilire le tue priorità all'inizio.
- Stabilire una cultura della performance.
In molte organizzazioni, gli sviluppatori front-end sanno esattamente quali sono i problemi sottostanti comuni e quali strategie dovrebbero essere utilizzate per risolverli. Tuttavia, fintanto che non esiste un'approvazione consolidata della cultura della performance, ogni decisione si trasformerà in un campo di battaglia di dipartimenti, suddividendo l'organizzazione in silos. Hai bisogno di un coinvolgimento degli stakeholder aziendali e, per ottenerlo, devi stabilire un case study o un proof of concept su come la velocità, in particolare i Core Web Vitals di cui parleremo in dettaglio più avanti, avvantaggia le metriche e gli indicatori chiave di prestazione ( KPI ) a cui tengono.Ad esempio, per rendere le prestazioni più tangibili, è possibile esporre l'impatto sulle prestazioni dei ricavi mostrando la correlazione tra il tasso di conversione e il tempo di caricamento dell'applicazione, nonché le prestazioni di rendering. Oppure la velocità di scansione del bot di ricerca (PDF, pagine 27–50).
Senza un forte allineamento tra i team di sviluppo/design e business/marketing, le prestazioni non saranno sostenute a lungo termine. Studia i reclami comuni che arrivano al servizio clienti e al team di vendita, studia l'analisi per frequenze di rimbalzo elevate e cali di conversione. Scopri come migliorare le prestazioni può aiutare ad alleviare alcuni di questi problemi comuni. Modifica l'argomento in base al gruppo di stakeholder con cui stai parlando.
Esegui esperimenti sulle prestazioni e misura i risultati, sia su dispositivi mobili che desktop (ad esempio con Google Analytics). Ti aiuterà a creare un case study personalizzato con dati reali. Inoltre, l'utilizzo dei dati di casi di studio ed esperimenti pubblicati su WPO Stats aiuterà ad aumentare la sensibilità per le aziende sul motivo per cui le prestazioni sono importanti e quale impatto ha sull'esperienza utente e sulle metriche aziendali. Tuttavia, affermare che le prestazioni contano da sole non è sufficiente: devi anche stabilire alcuni obiettivi misurabili e tracciabili e osservarli nel tempo.
Come arrivare là? Nel suo discorso su Building Performance for the Long Term, Allison McKnight condivide un caso di studio completo su come ha contribuito a stabilire una cultura della performance su Etsy (diapositive). Più recentemente, Tammy Everts ha parlato delle abitudini dei team di prestazioni altamente efficaci nelle organizzazioni di piccole e grandi dimensioni.
Durante queste conversazioni nelle organizzazioni, è importante tenere a mente che, proprio come l'UX è uno spettro di esperienze, le prestazioni web sono una distribuzione. Come ha osservato Karolina Szczur, "aspettarsi che un singolo numero sia in grado di fornire una valutazione a cui aspirare è un'ipotesi errata". Quindi gli obiettivi di prestazione devono essere dettagliati, tracciabili e tangibili.
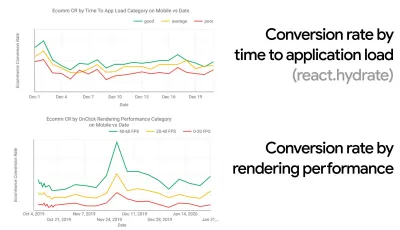
- Obiettivo: essere almeno il 20% più veloce del tuo concorrente più veloce.
Secondo la ricerca psicologica, se vuoi che gli utenti sentano che il tuo sito web è più veloce del sito web della concorrenza, devi essere almeno il 20% più veloce. Studia i tuoi principali concorrenti, raccogli metriche su come si comportano su dispositivi mobili e desktop e imposta soglie che ti aiuterebbero a superarli. Tuttavia, per ottenere risultati e obiettivi accurati, assicurati di avere prima un quadro completo dell'esperienza dei tuoi utenti studiando le tue analisi. È quindi possibile imitare l'esperienza del 90° percentile per i test.Per avere una buona prima impressione delle prestazioni dei tuoi concorrenti, puoi utilizzare Chrome UX Report ( CrUX , un set di dati RUM già pronto, video introduttivo di Ilya Grigorik e guida dettagliata di Rick Viscomi) o Treo, uno strumento di monitoraggio RUM che è alimentato da Chrome UX Report. I dati vengono raccolti dagli utenti del browser Chrome, quindi i rapporti saranno specifici di Chrome, ma ti forniranno una distribuzione abbastanza completa delle prestazioni, soprattutto i punteggi di Core Web Vitals, su un'ampia gamma di visitatori. Si noti che i nuovi dataset CrUX vengono rilasciati il secondo martedì di ogni mese .
In alternativa puoi anche utilizzare:
- Strumento di confronto dei rapporti sull'esperienza utente di Chrome di Addy Osmani,
- Speed Scorecard (fornisce anche uno strumento per la stima dell'impatto sulle entrate),
- Confronto del test dell'esperienza utente reale o
- SiteSpeed CI (basato su test sintetici).
Nota : se utilizzi Page Speed Insights o l'API Page Speed Insights (no, non è deprecato!), puoi ottenere i dati sulle prestazioni di CrUX per pagine specifiche anziché solo per gli aggregati. Questi dati possono essere molto più utili per impostare obiettivi di rendimento per risorse come "pagina di destinazione" o "scheda di prodotto". E se stai usando CI per testare i budget, devi assicurarti che il tuo ambiente testato corrisponda a CrUX se hai usato CrUX per impostare l'obiettivo ( grazie Patrick Meenan! ).
Se hai bisogno di aiuto per mostrare il ragionamento alla base della definizione delle priorità della velocità, o se desideri visualizzare il decadimento del tasso di conversione o l'aumento della frequenza di rimbalzo con prestazioni più lente, o forse avresti bisogno di sostenere una soluzione RUM nella tua organizzazione, Sergey Chernyshev ha creato un UX Speed Calculator, uno strumento open source che ti aiuta a simulare i dati e visualizzarli per guidare il tuo punto.
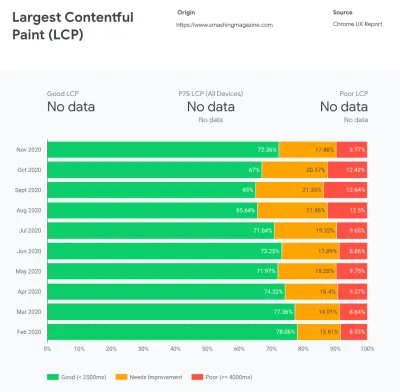
CrUX genera una panoramica delle distribuzioni delle prestazioni nel tempo, con il traffico raccolto dagli utenti di Google Chrome. Puoi crearne uno personalizzato su Chrome UX Dashboard. (Grande anteprima) 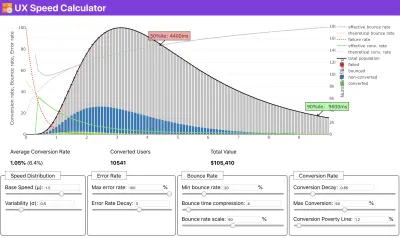
Proprio quando hai bisogno di dimostrare che le prestazioni guidino il tuo punto di vista: UX Speed Calculator visualizza l'impatto delle prestazioni su frequenze di rimbalzo, conversione e entrate totali, in base a dati reali. (Grande anteprima) A volte potresti voler andare un po' più a fondo, combinando i dati provenienti da CrUX con qualsiasi altro dato che hai già per capire rapidamente dove si trovano i rallentamenti, i punti ciechi e le inefficienze, per i tuoi concorrenti o per il tuo progetto. Nel suo lavoro, Harry Roberts ha utilizzato un foglio di calcolo della topografia della velocità del sito che utilizza per suddividere le prestazioni in base ai tipi di pagina chiave e tenere traccia delle diverse metriche chiave su di esse. Puoi scaricare il foglio di lavoro come Fogli Google, Excel, documento OpenOffice o CSV.
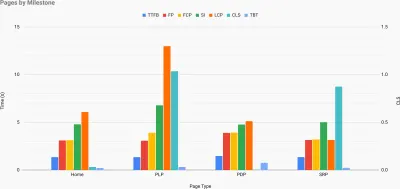
Topografia della velocità del sito, con metriche chiave rappresentate per le pagine chiave del sito. (Grande anteprima) E se vuoi andare fino in fondo , puoi eseguire un audit delle prestazioni di Lighthouse su ogni pagina di un sito (tramite Lightouse Parade), con un output salvato come CSV. Ciò ti aiuterà a identificare quali pagine (o tipi di pagine) specifici dei tuoi concorrenti hanno prestazioni peggiori o migliori e su cosa potresti voler concentrare i tuoi sforzi. (Per il tuo sito, probabilmente è meglio inviare dati a un endpoint di analisi!).

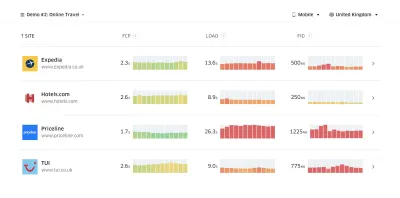
Con Lighthouse Parade, puoi eseguire un controllo delle prestazioni di Lighthouse su ogni pagina di un sito, con un output salvato come CSV. (Grande anteprima) Raccogli dati, imposta un foglio di lavoro, riduci il 20% e imposta i tuoi obiettivi ( budget di rendimento ) in questo modo. Ora hai qualcosa di misurabile con cui testare. Se stai tenendo a mente il budget e stai cercando di spedire solo il carico utile minimo per ottenere un rapido time-to-interactive, allora sei su una strada ragionevole.
Hai bisogno di risorse per iniziare?
- Addy Osmani ha scritto un articolo molto dettagliato su come avviare il budgeting delle prestazioni, come quantificare l'impatto delle nuove funzionalità e da dove iniziare quando si supera il budget.
- La guida di Lara Hogan su come affrontare i progetti con un budget di prestazioni può fornire utili suggerimenti ai designer.
- Harry Roberts ha pubblicato una guida sull'impostazione di un foglio Google per visualizzare l'impatto degli script di terze parti sulle prestazioni, utilizzando Request Map,
- Il calcolatore del budget delle prestazioni di Jonathan Fielding, il calcolatore del budget perf di Katie Hempenius e le calorie del browser possono aiutare nella creazione di budget (grazie a Karolina Szczur per l'avviso).
- In molte aziende, i budget delle prestazioni non dovrebbero essere ambiziosi, ma piuttosto pragmatici, fungendo da segno di attesa per evitare di scivolare oltre un certo punto. In tal caso, potresti scegliere come soglia il tuo peggior punto dati nelle ultime due settimane e prenderlo da lì. Budget delle prestazioni, ti mostra pragmaticamente una strategia per raggiungerlo.
- Inoltre, rendi visibili sia il budget delle prestazioni che le prestazioni attuali impostando dashboard con grafici che riportano le dimensioni delle build. Esistono molti strumenti che ti consentono di raggiungere questo obiettivo: dashboard SiteSpeed.io (open source), SpeedCurve e Calibre sono solo alcuni di questi e puoi trovare più strumenti su perf.rocks.

Browser Calories ti aiuta a impostare un budget di rendimento e misurare se una pagina supera questi numeri o meno. (Grande anteprima) Una volta stabilito un budget, incorporalo nel processo di creazione con Webpack Performance Hints e Bundlesize, Lighthouse CI, PWMetrics o Sitespeed CI per applicare i budget alle richieste pull e fornire una cronologia dei punteggi nei commenti PR.
Per esporre i budget delle prestazioni all'intero team, integra i budget delle prestazioni in Lighthouse tramite Lightwallet o usa LHCI Action per una rapida integrazione di Github Actions. E se hai bisogno di qualcosa di personalizzato, puoi utilizzare webpagetest-charts-api, un'API di endpoint per creare grafici dai risultati di WebPagetest.
Tuttavia, la consapevolezza delle prestazioni non dovrebbe venire solo dai budget delle prestazioni. Proprio come Pinterest, potresti creare una regola eslint personalizzata che non consenta l'importazione da file e directory noti per essere molto dipendenti e gonfiare il pacchetto. Imposta un elenco di pacchetti "sicuri" che possono essere condivisi con l'intero team.
Inoltre, pensa alle attività critiche dei clienti che sono più vantaggiose per la tua attività. Studiare, discutere e definire soglie di tempo accettabili per le azioni critiche e stabilire tempi utente "UX ready" approvati dall'intera organizzazione. In molti casi, i percorsi degli utenti toccheranno il lavoro di molti reparti diversi, quindi l'allineamento in termini di tempi accettabili aiuterà a supportare o prevenire le discussioni sulle prestazioni lungo la strada. Assicurati che i costi aggiuntivi delle risorse e delle funzionalità aggiunte siano visibili e compresi.
Allinea gli sforzi in termini di prestazioni con altre iniziative tecnologiche, che vanno dalle nuove funzionalità del prodotto in fase di creazione al refactoring fino al raggiungimento di un nuovo pubblico globale. Quindi, ogni volta che si verifica una conversazione su un ulteriore sviluppo, anche le prestazioni fanno parte di quella conversazione. È molto più facile raggiungere gli obiettivi di prestazioni quando la base di codice è nuova o è solo in fase di refactoring.
Inoltre, come suggerito da Patrick Meenan, vale la pena pianificare una sequenza di caricamento e dei compromessi durante il processo di progettazione. Se dai la priorità in anticipo a quali parti sono più critiche e definisci l'ordine in cui dovrebbero apparire, saprai anche cosa può essere ritardato. Idealmente, quell'ordine rifletterà anche la sequenza delle tue importazioni CSS e JavaScript, quindi gestirle durante il processo di compilazione sarà più semplice. Inoltre, considera quale dovrebbe essere l'esperienza visiva negli stati "intermedi", mentre la pagina viene caricata (ad esempio quando i caratteri web non sono ancora stati caricati).
Una volta che hai stabilito una forte cultura delle prestazioni nella tua organizzazione, punta a essere il 20% più veloce di te stesso per mantenere intatte le priorità con il passare del tempo ( grazie, Guy Podjarny! ). Ma tieni conto dei diversi tipi e comportamenti di utilizzo dei tuoi clienti (che Tobias Baldauf ha chiamato cadenza e coorti), insieme al traffico dei bot e agli effetti della stagionalità.
Pianificazione, pianificazione, pianificazione. Potrebbe essere allettante entrare presto in alcune rapide ottimizzazioni dei "frutti bassi" - e potrebbe essere una buona strategia per vittorie rapide - ma sarà molto difficile mantenere le prestazioni una priorità senza pianificare e impostare una compagnia realistica - obiettivi di performance su misura.
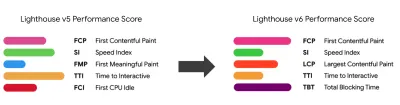
- Scegli le metriche giuste.
Non tutte le metriche sono ugualmente importanti. Studia quali metriche contano di più per la tua applicazione: di solito, sarà definita dalla velocità con cui puoi iniziare a eseguire il rendering dei pixel più importanti della tua interfaccia e dalla velocità con cui puoi fornire la reattività all'input per questi pixel renderizzati. Questa conoscenza ti darà il miglior obiettivo di ottimizzazione per gli sforzi in corso. Alla fine, non sono gli eventi di caricamento o i tempi di risposta del server a definire l'esperienza, ma la percezione di quanto sia scattante l'interfaccia.Cosa significa? Piuttosto che concentrarti sul tempo di caricamento della pagina intera (tramite i tempi onLoad e DOMContentLoaded , ad esempio), dai la priorità al caricamento della pagina come percepito dai tuoi clienti. Ciò significa concentrarsi su un insieme leggermente diverso di metriche. In effetti, scegliere la metrica giusta è un processo senza vincitori evidenti.
Sulla base della ricerca di Tim Kadlec e delle note di Marcos Iglesias nel suo intervento, le metriche tradizionali potrebbero essere raggruppate in pochi set. Di solito, avremo bisogno di tutti loro per avere un quadro completo delle prestazioni e nel tuo caso particolare alcuni di essi saranno più importanti di altri.
- Le metriche basate sulla quantità misurano il numero di richieste, il peso e un punteggio di prestazione. Buono per generare allarmi e monitorare i cambiamenti nel tempo, non così buono per comprendere l'esperienza dell'utente.
- Le metriche di traguardo utilizzano gli stati durante la durata del processo di caricamento, ad esempio Time To First Byte e Time To Interactive . Buono per descrivere l'esperienza dell'utente e il monitoraggio, non così buono per sapere cosa succede tra le pietre miliari.
- Le metriche di rendering forniscono una stima della velocità di rendering del contenuto (ad es. Tempo di avvio del rendering , Indice di velocità ). Buono per misurare e modificare le prestazioni di rendering, ma non così buono per misurare quando vengono visualizzati contenuti importanti e con cui è possibile interagire.
- Le metriche personalizzate misurano un particolare evento personalizzato per l'utente, ad esempio Time To First Tweet di Twitter e PinnerWaitTime di Pinterest. Buono per descrivere con precisione l'esperienza dell'utente, non così buono per ridimensionare le metriche e confrontarlo con i concorrenti.
Per completare il quadro, di solito cerchiamo metriche utili tra tutti questi gruppi. Di solito, quelli più specifici e rilevanti sono:
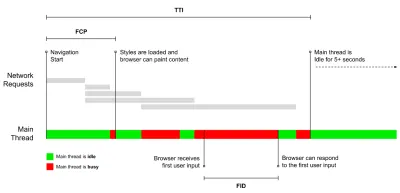
- Time to Interactive (TTI)
Il punto in cui il layout si è stabilizzato , i webfont chiave sono visibili e il thread principale è abbastanza disponibile per gestire l'input dell'utente, in pratica il contrassegno temporale in cui un utente può interagire con l'interfaccia utente. Le metriche chiave per capire quanta attesa deve subire un utente per utilizzare il sito senza ritardi. Boris Schapira ha scritto un post dettagliato su come misurare il TTI in modo affidabile. - First Input Delay (FID) o Reattività di input
Il momento in cui un utente interagisce per la prima volta con il tuo sito al momento in cui il browser è effettivamente in grado di rispondere a tale interazione. Completa molto bene TTI in quanto descrive la parte mancante dell'immagine: cosa succede quando un utente interagisce effettivamente con il sito. Inteso solo come metrica RUM. C'è una libreria JavaScript per misurare il FID nel browser. - La più grande vernice contenta (LCP)
Contrassegna il punto nella sequenza temporale di caricamento della pagina in cui è probabile che il contenuto importante della pagina sia stato caricato. Il presupposto è che l'elemento più importante della pagina sia quello più grande visibile nel viewport dell'utente. Se gli elementi sono renderizzati sia above che below the fold, solo la parte visibile è considerata rilevante. - Tempo di blocco totale ( TBT )
Una metrica che aiuta a quantificare la gravità di quanto una pagina non sia interattiva prima che diventi interattiva in modo affidabile (ovvero, il thread principale è stato privo di attività che superano i 50 ms ( attività lunghe ) per almeno 5 secondi). La metrica misura la quantità di tempo totale tra il primo disegno e Time to Interactive (TTI) in cui il thread principale è stato bloccato per un tempo sufficientemente lungo da impedire la reattività dell'input. Non c'è da stupirsi, quindi, che un TBT basso sia un buon indicatore di buone prestazioni. (grazie, Artem, Phil) - Spostamento cumulativo del layout ( CLS )
La metrica evidenzia la frequenza con cui gli utenti subiscono cambiamenti di layout imprevisti ( ridistribuzioni ) quando accedono al sito. Esamina gli elementi instabili e il loro impatto sull'esperienza complessiva. Più basso è il punteggio, meglio è. - Indice di velocità
Misura la velocità con cui i contenuti della pagina vengono popolati visivamente; più basso è il punteggio, meglio è. Il punteggio dell'indice di velocità viene calcolato in base alla velocità di avanzamento visivo , ma è semplicemente un valore calcolato. È anche sensibile alle dimensioni del viewport, quindi è necessario definire una gamma di configurazioni di test che corrispondano al pubblico di destinazione. Nota che sta diventando meno importante con LCP che sta diventando una metrica più rilevante ( grazie, Boris, Artem! ). - Tempo CPU speso
Una metrica che mostra la frequenza e la durata del blocco del thread principale, lavorando su pittura, rendering, scripting e caricamento. Il tempo di CPU elevato è un chiaro indicatore di un'esperienza janky , ovvero quando l'utente sperimenta un notevole ritardo tra la propria azione e una risposta. Con WebPageTest, puoi selezionare "Capture Dev Tools Timeline" nella scheda "Chrome" per esporre l'interruzione del thread principale mentre viene eseguito su qualsiasi dispositivo utilizzando WebPageTest. - Costi della CPU a livello di componente
Proprio come per il tempo impiegato dalla CPU , questa metrica, proposta da Stoyan Stefanov, esplora l' impatto di JavaScript sulla CPU . L'idea è di utilizzare il conteggio delle istruzioni della CPU per componente per comprenderne l'impatto sull'esperienza complessiva, in isolamento. Potrebbe essere implementato utilizzando Burattinaio e Chrome. - Indice di frustrazione
Mentre molti parametri descritti sopra spiegano quando si verifica un evento particolare, FrustrationIndex di Tim Vereecke esamina i divari tra i parametri invece di esaminarli individualmente. Esamina le pietre miliari chiave percepite dall'utente finale, come il titolo è visibile, il primo contenuto è visibile, visivamente pronto e la pagina sembra pronta e calcola un punteggio che indica il livello di frustrazione durante il caricamento di una pagina. Maggiore è il divario, maggiore è la possibilità che un utente venga frustrato. Potenzialmente un buon KPI per l'esperienza dell'utente. Tim ha pubblicato un post dettagliato su FrustrationIndex e su come funziona. - Impatto sul peso dell'annuncio
Se il tuo sito dipende dalle entrate generate dalla pubblicità, è utile monitorare il peso del codice relativo agli annunci. Lo script di Paddy Ganti costruisce due URL (uno normale e uno che blocca gli annunci), richiede la generazione di un confronto video tramite WebPageTest e segnala un delta. - Metriche di deviazione
Come notato dagli ingegneri di Wikipedia, i dati su quanta varianza esiste nei tuoi risultati potrebbero informarti sull'affidabilità dei tuoi strumenti e quanta attenzione dovresti prestare a deviazioni e outler. Una grande varianza è un indicatore delle regolazioni necessarie nell'impostazione. Aiuta anche a capire se alcune pagine sono più difficili da misurare in modo affidabile, ad esempio a causa di script di terze parti che causano variazioni significative. Potrebbe anche essere una buona idea tenere traccia della versione del browser per comprendere i picchi di prestazioni quando viene lanciata una nuova versione del browser. - Metriche personalizzate
Le metriche personalizzate sono definite dalle esigenze aziendali e dall'esperienza del cliente. Richiede di identificare pixel importanti , script critici , CSS necessari e risorse pertinenti e misurare la velocità con cui vengono consegnati all'utente. Per quello, puoi monitorare i tempi di rendering dell'eroe o utilizzare l'API delle prestazioni, contrassegnando timestamp particolari per eventi importanti per la tua attività. Inoltre, puoi raccogliere metriche personalizzate con WebPagetest eseguendo JavaScript arbitrario alla fine di un test.
Nota che il First Significato Paint (FMP) non appare nella panoramica sopra. Un tempo forniva un'idea della velocità con cui il server emette i dati. L'FMP lungo di solito indicava che JavaScript bloccava il thread principale, ma potrebbe essere correlato anche a problemi di back-end/server. Tuttavia, la metrica è stata deprecata di recente in quanto non sembra essere accurata in circa il 20% dei casi. È stato effettivamente sostituito con LCP che è sia più affidabile che più facile da ragionare. Non è più supportato in Lighthouse. Ricontrolla le ultime metriche e consigli sulle prestazioni incentrati sull'utente solo per assicurarti di essere sulla pagina sicura ( grazie, Patrick Meenan ).

Steve Souders ha una spiegazione dettagliata di molti di questi parametri. È importante notare che mentre il Time-To-Interactive viene misurato eseguendo controlli automatizzati nel cosiddetto ambiente di laboratorio , First Input Delay rappresenta l'esperienza utente effettiva , con gli utenti effettivi che subiscono un notevole ritardo. In generale, è probabilmente una buona idea misurare e monitorare sempre entrambi.
A seconda del contesto dell'applicazione, le metriche preferite potrebbero differire: ad es. per l'interfaccia utente di Netflix TV, la reattività dell'input chiave, l'utilizzo della memoria e il TTI sono più importanti e per Wikipedia, le prime/ultime modifiche visive e le metriche del tempo impiegato dalla CPU sono più importanti.
Nota : sia FID che TTI non tengono conto del comportamento di scorrimento; lo scorrimento può avvenire in modo indipendente poiché è fuori dal thread principale, quindi per molti siti di consumo di contenuti queste metriche potrebbero essere molto meno importanti ( grazie, Patrick! ).
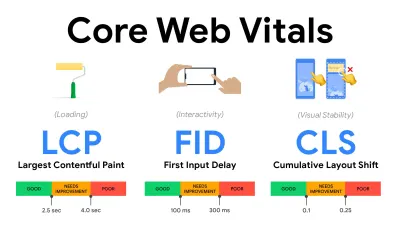
- Misurare e ottimizzare i Core Web Vitals .
Per molto tempo, le metriche delle prestazioni sono state piuttosto tecniche, incentrate sulla visione ingegneristica della velocità di risposta dei server e della velocità di caricamento dei browser. Le metriche sono cambiate nel corso degli anni, cercando di trovare un modo per catturare l'esperienza utente effettiva , piuttosto che i tempi del server. A maggio 2020, Google ha annunciato Core Web Vitals, una serie di nuove metriche delle prestazioni incentrate sull'utente, ciascuna delle quali rappresenta un aspetto distinto dell'esperienza dell'utente.Per ciascuno di essi, Google consiglia una serie di obiettivi di velocità accettabili. Almeno il 75% di tutte le visualizzazioni di pagina deve superare l' intervallo Buono per superare questa valutazione. Queste metriche hanno rapidamente guadagnato terreno e, con i Core Web Vitals che sono diventati indicatori di ranking per la Ricerca Google a maggio 2021 ( aggiornamento dell'algoritmo di ranking di Page Experience ), molte aziende hanno rivolto la loro attenzione ai punteggi delle prestazioni.
Analizziamo ciascuno dei Core Web Vitals, uno per uno, insieme a tecniche e strumenti utili per ottimizzare le tue esperienze tenendo conto di queste metriche. (Vale la pena notare che ti ritroverai con punteggi migliori di Core Web Vitals seguendo un consiglio generale in questo articolo.)
- Più grande Contentful Paint ( LCP ) < 2,5 sec.
Misura il caricamento di una pagina e segnala il tempo di rendering dell'immagine o del blocco di testo più grande visibile all'interno del viewport. Pertanto, LCP è influenzato da tutto ciò che sta rinviando il rendering di informazioni importanti, che si tratti di tempi di risposta del server lenti, blocco dei CSS, JavaScript in corso (di prima parte o di terze parti), caricamento di font Web, costose operazioni di rendering o pittura, pigrizia -immagini caricate, schermate dello scheletro o rendering lato client.
Per una buona esperienza, LCP dovrebbe verificarsi entro 2,5 secondi dal primo caricamento della pagina. Ciò significa che dobbiamo rendere la prima parte visibile della pagina il prima possibile. Ciò richiederà CSS critici personalizzati per ogni modello, orchestrando l'ordine di<head>e precaricando le risorse critiche (le tratteremo più avanti).Il motivo principale per un punteggio LCP basso sono solitamente le immagini. Fornire un LCP in meno di 2,5 secondi su Fast 3G — ospitato su un server ben ottimizzato, tutto statico senza rendering lato client e con un'immagine proveniente da un CDN di immagini dedicato — significa che la dimensione teorica massima dell'immagine è di soli 144 KB circa . Ecco perché le immagini reattive sono importanti, così come il precaricamento delle immagini critiche in anticipo (con
preload).Suggerimento rapido : per scoprire cosa è considerato LCP su una pagina, in DevTools puoi passare il mouse sopra il badge LCP sotto "Tempi" nel Performance Panel ( grazie, Tim Kadlec !).
- Ritardo primo ingresso ( FID ) < 100 ms.
Misura la reattività dell'interfaccia utente, ovvero per quanto tempo il browser è stato impegnato con altre attività prima che potesse reagire a un evento di input dell'utente discreto come un tocco o un clic. È progettato per catturare i ritardi risultanti dall'occupazione del thread principale, soprattutto durante il caricamento della pagina.
L'obiettivo è rimanere entro 50–100 ms per ogni interazione. Per arrivarci, dobbiamo identificare attività lunghe (blocca il thread principale per >50 ms) e suddividerle, suddividere il codice in più blocchi, ridurre il tempo di esecuzione di JavaScript, ottimizzare il recupero dei dati, rinviare l'esecuzione di script di terze parti , sposta JavaScript nel thread in background con i Web worker e utilizza l'idratazione progressiva per ridurre i costi di reidratazione nelle SPA.Suggerimento rapido : in generale, una strategia affidabile per ottenere un punteggio FID migliore consiste nel ridurre al minimo il lavoro sul thread principale suddividendo i pacchetti più grandi in pacchetti più piccoli e servendo ciò di cui l'utente ha bisogno quando ne ha bisogno, in modo che le interazioni dell'utente non vengano ritardate . Ne tratteremo di più in dettaglio di seguito.
- Spostamento cumulativo del layout ( CLS ) < 0,1.
Misura la stabilità visiva dell'interfaccia utente per garantire interazioni fluide e naturali, ovvero la somma totale di tutti i singoli punteggi di spostamento del layout per ogni spostamento imprevisto del layout che si verifica durante la vita della pagina. Un cambiamento di layout individuale si verifica ogni volta che un elemento già visibile cambia la sua posizione nella pagina. Viene valutato in base alle dimensioni del contenuto e alla distanza percorsa.
Quindi ogni volta che compare un cambiamento, ad esempio quando i font di fallback e i web font hanno metriche dei font differenti, o annunci, incorporamenti o iframe che arrivano in ritardo, o le dimensioni dell'immagine/video non sono riservate, o il CSS in ritardo impone ridisegni o le modifiche vengono iniettate da late JavaScript: ha un impatto sul punteggio CLS. Il valore consigliato per una buona esperienza è un CLS < 0,1.
Vale la pena notare che i Core Web Vitals dovrebbero evolversi nel tempo, con un ciclo annuale prevedibile . Per l'aggiornamento del primo anno, potremmo aspettarci che First Contentful Paint venga promosso a Core Web Vitals, una soglia FID ridotta e un migliore supporto per le applicazioni a pagina singola. Potremmo anche vedere la risposta agli input degli utenti dopo il carico aumentare di peso, insieme a considerazioni di sicurezza, privacy e accessibilità (!).
In relazione a Core Web Vitals, ci sono molte risorse utili e articoli che vale la pena esaminare:
- Web Vitals Leaderboard ti consente di confrontare i tuoi punteggi con la concorrenza su dispositivi mobili, tablet, desktop e su 3G e 4G.
- Core SERP Vitals, un'estensione di Chrome che mostra i Core Web Vitals di CrUX nei risultati di ricerca di Google.
- Layout Shift GIF Generator che visualizza CLS con una semplice GIF (disponibile anche da riga di comando).
- la libreria web-vitals può raccogliere e inviare Core Web Vitals a Google Analytics, Google Tag Manager o qualsiasi altro endpoint di analisi.
- Analisi di Web Vitals con WebPageTest, in cui Patrick Meenan esplora come WebPageTest espone i dati sui Core Web Vitals.
- Ottimizzazione con Core Web Vitals, un video di 50 minuti con Addy Osmani, in cui evidenzia come migliorare Core Web Vitals in un caso di studio di eCommerce.
- Spostamento cumulativo del layout nella pratica e Spostamento cumulativo del layout nel mondo reale sono articoli completi di Nic Jansma, che coprono praticamente tutto su CLS e come si correla con metriche chiave come frequenza di rimbalzo, tempo di sessione o clic di rabbia.
- Cosa forza il riflusso, con una panoramica delle proprietà o dei metodi, quando richiesto/chiamato in JavaScript, che attiverà il browser per calcolare in modo sincrono lo stile e il layout.
- Trigger CSS mostra quali proprietà CSS attivano Layout, Paint e Composite.
- La correzione dell'instabilità del layout è una procedura dettagliata dell'utilizzo di WebPageTest per identificare e correggere i problemi di instabilità del layout.
- Cumulative Layout Shift, The Layout Instability Metric, un'altra guida molto dettagliata di Boris Schapira su CLS, come viene calcolato, come misurare e come ottimizzarlo.
- How To Improvement Core Web Vitals, una guida dettagliata di Simon Hearne su ciascuna delle metriche (inclusi altri Web Vital, come FCP, TTI, TBT), quando si verificano e come vengono misurate.
Quindi, Core Web Vitals è la metrica definitiva da seguire ? Non proprio. Sono infatti già esposti nella maggior parte delle soluzioni e piattaforme RUM, tra cui Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (già nella vista filmstrip), Newrelic, Shopify, Next.js, tutti gli strumenti di Google (PageSpeed Insights, Lighthouse + CI, Search Console ecc.) e molti altri.
Tuttavia, come spiega Katie Sylor-Miller, alcuni dei problemi principali con Core Web Vitals sono la mancanza di supporto cross-browser, non misuriamo realmente l'intero ciclo di vita dell'esperienza di un utente, inoltre è difficile correlare i cambiamenti in FID e CLS con risultati di business.
Poiché dovremmo aspettarci un'evoluzione di Core Web Vitals, sembra ragionevole combinare sempre Web Vitals con le tue metriche personalizzate per ottenere una migliore comprensione della tua posizione in termini di prestazioni.
- Più grande Contentful Paint ( LCP ) < 2,5 sec.
- Raccogli dati su un dispositivo rappresentativo del tuo pubblico.
Per raccogliere dati accurati, dobbiamo scegliere accuratamente i dispositivi su cui testare. Nella maggior parte delle aziende, ciò significa esaminare le analisi e creare profili utente basati sui tipi di dispositivi più comuni. Tuttavia, spesso, l'analisi da sola non fornisce un quadro completo. Una parte significativa del pubblico di destinazione potrebbe abbandonare il sito (e non tornare indietro) solo perché la loro esperienza è troppo lenta ed è improbabile che i loro dispositivi vengano visualizzati come i dispositivi più popolari nell'analisi per questo motivo. Quindi, condurre ulteriori ricerche su dispositivi comuni nel tuo gruppo target potrebbe essere una buona idea.A livello globale nel 2020, secondo l'IDC, l'84,8% di tutti i telefoni cellulari spediti sono dispositivi Android. Un consumatore medio aggiorna il proprio telefono ogni 2 anni e negli Stati Uniti il ciclo di sostituzione del telefono è di 33 mesi. I telefoni più venduti in media in tutto il mondo costeranno meno di $ 200.
Un dispositivo rappresentativo, quindi, è un dispositivo Android che ha almeno 24 mesi , costa $ 200 o meno, funziona su 3G lento, 400 ms RTT e 400 kbps di trasferimento, solo per essere leggermente più pessimisti. Questo potrebbe essere molto diverso per la tua azienda, ovviamente, ma questa è un'approssimazione abbastanza vicina alla maggior parte dei clienti là fuori. In effetti, potrebbe essere una buona idea esaminare gli attuali Best Seller di Amazon per il tuo mercato di riferimento. ( Grazie a Tim Kadlec, Henri Helvetica e Alex Russell per le indicazioni! ).
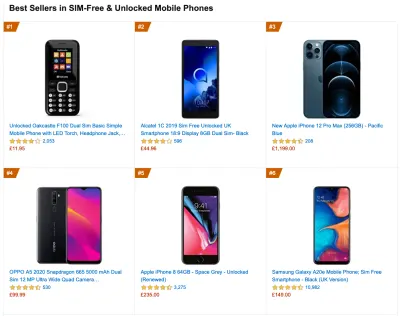
Quando crei un nuovo sito o un'app, controlla sempre prima gli attuali Best Seller di Amazon per il tuo mercato di riferimento. (Grande anteprima) Quali dispositivi di test scegliere allora? Quelli che si adattano bene al profilo sopra delineato. È una buona opzione scegliere un Moto G4/G5 Plus leggermente più vecchio, un dispositivo Samsung di fascia media (Galaxy A50, S8), un buon dispositivo di fascia media come un Nexus 5X, Xiaomi Mi A3 o Xiaomi Redmi Note 7 e un dispositivo lento come Alcatel 1X o Cubot X19, magari in un laboratorio di dispositivi aperti. Per i test su dispositivi con accelerazione termica più lenti, potresti anche ottenere un Nexus 4, che costa solo circa $ 100.
Inoltre, controlla i chipset utilizzati in ogni dispositivo e non sovrarappresentare un chipset : alcune generazioni di Snapdragon e Apple oltre a Rockchip di fascia bassa, Mediatek sarebbero sufficienti (grazie, Patrick!) .
Se non hai un dispositivo a portata di mano, emula l'esperienza mobile sul desktop testando su una rete 3G ridotta (ad es. 300 ms RTT, 1,6 Mbps giù, 0,8 Mbps su) con una CPU ridotta (5 volte il rallentamento). Alla fine passa al normale 3G, al 4G lento (ad es. 170 ms RTT, 9 Mbps in basso, 9 Mbps in alto) e Wi-Fi. Per rendere più visibile l'impatto sulle prestazioni, potresti persino introdurre i martedì 2G o configurare una rete 3G/4G ridotta nel tuo ufficio per test più rapidi.
Tieni presente che su un dispositivo mobile dovremmo aspettarci un rallentamento 4×–5× rispetto alle macchine desktop. I dispositivi mobili hanno diverse GPU, CPU, memoria e diverse caratteristiche della batteria. Ecco perché è importante avere un buon profilo di un dispositivo medio e testare sempre su un dispositivo del genere.
- Gli strumenti di test sintetici raccolgono i dati di laboratorio in un ambiente riproducibile con dispositivi e impostazioni di rete predefiniti (ad es. Lighthouse , Calibre , WebPageTest ) e
- Gli strumenti Real User Monitoring ( RUM ) valutano continuamente le interazioni degli utenti e raccolgono dati sul campo (ad es. SpeedCurve , New Relic : gli strumenti forniscono anche test sintetici).
- usa Lighthouse CI per tenere traccia dei punteggi di Lighthouse nel tempo (è piuttosto impressionante),
- esegui Lighthouse in GitHub Actions per ottenere un report Lighthouse insieme a ogni PR,
- eseguire un audit delle prestazioni di Lighthouse su ogni pagina di un sito (tramite Lightouse Parade), con un output salvato come CSV,
- usa il calcolatore dei punteggi del faro e i pesi metrici del faro se hai bisogno di approfondire i dettagli.
- Lighthouse è disponibile anche per Firefox, ma sotto il cofano utilizza l'API PageSpeed Insights e genera un rapporto basato su un Chrome 79 User-Agent senza testa.

Fortunatamente, ci sono molte ottime opzioni che ti aiutano ad automatizzare la raccolta di dati e a misurare le prestazioni del tuo sito web nel tempo in base a queste metriche. Tieni presente che un buon quadro delle prestazioni copre una serie di metriche delle prestazioni, dati di laboratorio e dati sul campo:
Il primo è particolarmente utile durante lo sviluppo in quanto ti aiuterà a identificare, isolare e risolvere i problemi di prestazioni mentre lavori sul prodotto. Quest'ultimo è utile per la manutenzione a lungo termine in quanto ti aiuterà a comprendere i colli di bottiglia delle prestazioni mentre si verificano dal vivo, quando gli utenti accedono effettivamente al sito.
Toccando le API RUM integrate come Navigation Timing, Resource Timing, Paint Timing, Long Tasks, ecc., gli strumenti di test sintetici e RUM insieme forniscono un quadro completo delle prestazioni della tua applicazione. Puoi usare Calibre, Treo, SpeedCurve, mPulse e Boomerang, Sitespeed.io, che sono tutte ottime opzioni per il monitoraggio delle prestazioni. Inoltre, con l'intestazione Server Timing, puoi persino monitorare le prestazioni di back-end e front-end in un unico posto.
Nota : è sempre una scommessa più sicura scegliere dei throttling a livello di rete, esterni al browser, poiché, ad esempio, DevTools ha problemi nell'interazione con HTTP/2 push, a causa del modo in cui è implementato ( grazie, Yoav, Patrick !). Per Mac OS, possiamo usare Network Link Conditioner, per Windows Windows Traffic Shaper, per Linux netem e per FreeBSD dummynet.
Poiché è probabile che eseguirai il test in Lighthouse, tieni presente che puoi:
- Impostare i profili "pulito" e "cliente" per il test.
Durante l'esecuzione di test negli strumenti di monitoraggio passivo, è una strategia comune disattivare le attività antivirus e in background della CPU, rimuovere i trasferimenti di larghezza di banda in background e testare con un profilo utente pulito senza estensioni del browser per evitare risultati distorti (in Firefox e in Chrome).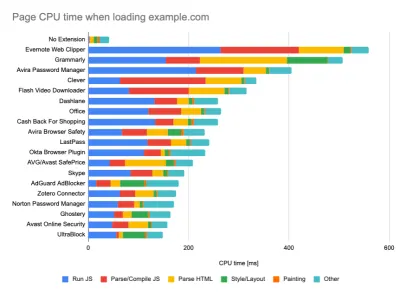
Il rapporto di DebugBear mette in evidenza le 20 estensioni più lente, inclusi gestori di password, ad-blocker e applicazioni popolari come Evernote e Grammarly. (Grande anteprima) Tuttavia, è anche una buona idea studiare quali estensioni del browser utilizzano frequentemente i tuoi clienti e testare anche con profili "clienti" dedicati. In effetti, alcune estensioni potrebbero avere un profondo impatto sulle prestazioni (rapporto sul rendimento delle estensioni di Chrome 2020) sulla tua applicazione e, se i tuoi utenti le utilizzano molto, potresti voler tenerne conto in anticipo. Pertanto, i risultati del profilo "pulito" da soli sono eccessivamente ottimistici e possono essere schiacciati in scenari di vita reale.
- Condividi gli obiettivi di performance con i tuoi colleghi.
Assicurati che gli obiettivi di prestazione siano familiari a tutti i membri della tua squadra per evitare malintesi su tutta la linea. Ogni decisione, che si tratti di progettazione, marketing o qualsiasi altra via di mezzo, ha implicazioni sulle prestazioni e la distribuzione di responsabilità e proprietà nell'intero team semplificherebbe le decisioni incentrate sulle prestazioni in seguito. Mappa le decisioni di progettazione rispetto al budget delle prestazioni e alle priorità definite all'inizio.
Sommario
- Preparativi: pianificazione e metriche
- Stabilire obiettivi realistici
- Definire l'ambiente
- Ottimizzazioni degli asset
- Costruisci ottimizzazioni
- Ottimizzazioni di consegna
- Rete, HTTP/2, HTTP/3
- Test e monitoraggio
- Vittorie veloci
- Tutto in una pagina
- Scarica la lista di controllo (PDF, Apple Pages, MS Word)
- Iscriviti alla nostra newsletter via email per non perdere le prossime guide.