
Elenco di controllo delle prestazioni front-end 2021 (PDF, pagine Apple, MS Word)
Pubblicato: 2022-03-10Questa guida è stata gentilmente supportata dai nostri amici di LogRocket, un servizio che combina il monitoraggio delle prestazioni del frontend , la riproduzione delle sessioni e l'analisi dei prodotti per aiutarti a creare esperienze migliori per i clienti. LogRocket tiene traccia delle metriche chiave, incl. DOM completo, tempo al primo byte, primo ritardo di input, CPU client e utilizzo della memoria. Ottieni una prova gratuita di LogRocket oggi.

Le prestazioni sul Web sono una bestia ingannevole, vero? Come facciamo a sapere effettivamente a che punto siamo in termini di prestazioni e quali sono esattamente i nostri colli di bottiglia in termini di prestazioni? JavaScript è costoso, consegna dei caratteri web lenta, immagini pesanti o rendering lento? Abbiamo ottimizzato abbastanza con tree-shaking, scope hoisting, code-splitting e tutti i modelli di caricamento fantasiosi con osservatore di intersezioni, idratazione progressiva, suggerimenti per i clienti, HTTP/3, addetti ai servizi e - oh mio - lavoratori edge? E, soprattutto, da dove iniziamo a migliorare le prestazioni e come stabiliamo una cultura delle prestazioni a lungo termine?
In passato, le prestazioni erano spesso un semplice ripensamento . Spesso rinviato fino alla fine del progetto, si riduce a minimizzazione, concatenazione, ottimizzazione delle risorse e potenzialmente alcune regolazioni fini sul file di config del server. Guardando indietro ora, le cose sembrano essere cambiate in modo abbastanza significativo.
Le prestazioni non sono solo una questione tecnica: influiscono su tutto, dall'accessibilità all'usabilità, all'ottimizzazione dei motori di ricerca e, quando le integrano nel flusso di lavoro, le decisioni di progettazione devono essere informate dalle loro implicazioni sulle prestazioni. Le prestazioni devono essere misurate, monitorate e perfezionate continuamente e la crescente complessità del Web pone nuove sfide che rendono difficile tenere traccia delle metriche, poiché i dati variano in modo significativo a seconda del dispositivo, del browser, del protocollo, del tipo di rete e della latenza ( CDN, ISP, cache, proxy, firewall, bilanciatori di carico e server svolgono tutti un ruolo nelle prestazioni).
Quindi, se creassimo una panoramica di tutte le cose che dobbiamo tenere a mente quando si migliorano le prestazioni, dall'inizio del progetto fino al rilascio finale del sito Web, come sarebbe? Di seguito troverai un elenco di controllo delle prestazioni front-end (si spera imparziale e obiettivo) per il 2021 : una panoramica aggiornata dei problemi che potresti dover considerare per assicurarti che i tuoi tempi di risposta siano rapidi, l'interazione dell'utente sia fluida e i tuoi siti no drenare la larghezza di banda dell'utente.
Sommario
- Tutto su pagine separate
- Prepararsi: pianificazione e metriche
Cultura delle prestazioni, Core Web Vitals, profili delle prestazioni, CrUX, Lighthouse, FID, TTI, CLS, dispositivi. - Stabilire obiettivi realistici
Budget prestazionali, obiettivi prestazionali, framework RAIL, budget 170KB/30KB. - Definire l'ambiente
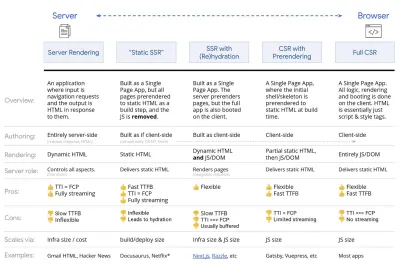
Scelta di un framework, costo delle prestazioni di base, Webpack, dipendenze, CDN, architettura front-end, CSR, SSR, CSR + SSR, rendering statico, prerendering, pattern PRPL. - Ottimizzazioni degli asset
Brotli, AVIF, WebP, immagini reattive, AV1, caricamento multimediale adattivo, compressione video, font web, font Google. - Costruisci ottimizzazioni
Moduli JavaScript, pattern modulo/nomodulo, tree-shaking, code-splitting, scope-hoisting, Webpack, pubblicazione differenziale, web worker, WebAssembly, bundle JavaScript, React, SPA, idratazione parziale, importazione su interazione, terze parti, cache. - Ottimizzazioni di consegna
Caricamento lento, osservatore di intersezione, differire il rendering e la decodifica, CSS critico, streaming, suggerimenti sulle risorse, turni di layout, addetto ai servizi. - Rete, HTTP/2, HTTP/3
Pinzatura OCSP, certificati EV/DV, packaging, IPv6, QUIC, HTTP/3. - Test e monitoraggio
Flusso di lavoro di controllo, browser proxy, pagina 404, richieste di consenso ai cookie GDPR, CSS di diagnostica delle prestazioni, accessibilità. - Vittorie veloci
- Scarica la lista di controllo (PDF, Apple Pages, MS Word)
- Si parte!
(Puoi anche scaricare il PDF della checklist (166 KB) o scaricare il file modificabile di Apple Pages (275 KB) o il file .docx (151 KB). Buona ottimizzazione, a tutti!)
Prepararsi: pianificazione e metriche
Le micro-ottimizzazioni sono ottime per mantenere le prestazioni in carreggiata, ma è fondamentale avere in mente obiettivi chiaramente definiti, obiettivi misurabili che influenzerebbero qualsiasi decisione presa durante il processo. Esistono un paio di modelli diversi e quelli discussi di seguito sono piuttosto supponenti: assicurati solo di stabilire le tue priorità all'inizio.
- Stabilire una cultura della performance.
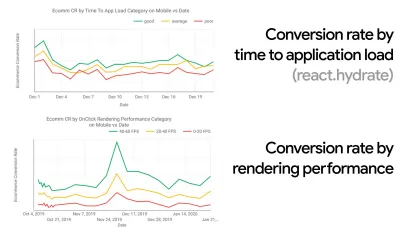
In molte organizzazioni, gli sviluppatori front-end sanno esattamente quali sono i problemi sottostanti comuni e quali strategie dovrebbero essere utilizzate per risolverli. Tuttavia, fintanto che non esiste un'approvazione consolidata della cultura della performance, ogni decisione si trasformerà in un campo di battaglia di dipartimenti, suddividendo l'organizzazione in silos. Hai bisogno di un coinvolgimento degli stakeholder aziendali e, per ottenerlo, devi stabilire un case study o un proof of concept su come la velocità, in particolare i Core Web Vitals di cui parleremo in dettaglio più avanti, avvantaggia le metriche e gli indicatori chiave di prestazione ( KPI ) a cui tengono.Ad esempio, per rendere le prestazioni più tangibili, è possibile esporre l'impatto sulle prestazioni dei ricavi mostrando la correlazione tra il tasso di conversione e il tempo di caricamento dell'applicazione, nonché le prestazioni di rendering. Oppure la velocità di scansione del bot di ricerca (PDF, pagine 27–50).
Senza un forte allineamento tra i team di sviluppo/design e business/marketing, le prestazioni non saranno sostenute a lungo termine. Studia i reclami comuni che arrivano al servizio clienti e al team di vendita, studia l'analisi per frequenze di rimbalzo elevate e cali di conversione. Scopri come migliorare le prestazioni può aiutare ad alleviare alcuni di questi problemi comuni. Modifica l'argomento in base al gruppo di stakeholder con cui stai parlando.
Esegui esperimenti sulle prestazioni e misura i risultati, sia su dispositivi mobili che desktop (ad esempio con Google Analytics). Ti aiuterà a creare un case study personalizzato con dati reali. Inoltre, l'utilizzo dei dati di casi di studio ed esperimenti pubblicati su WPO Stats aiuterà ad aumentare la sensibilità per le aziende sul motivo per cui le prestazioni sono importanti e quale impatto ha sull'esperienza utente e sulle metriche aziendali. Tuttavia, affermare che le prestazioni contano da sole non è sufficiente: devi anche stabilire alcuni obiettivi misurabili e tracciabili e osservarli nel tempo.
Come arrivare là? Nel suo discorso su Building Performance for the Long Term, Allison McKnight condivide un caso di studio completo su come ha contribuito a stabilire una cultura della performance su Etsy (diapositive). Più recentemente, Tammy Everts ha parlato delle abitudini dei team di prestazioni altamente efficaci nelle organizzazioni di piccole e grandi dimensioni.
Durante queste conversazioni nelle organizzazioni, è importante tenere a mente che, proprio come l'UX è uno spettro di esperienze, le prestazioni web sono una distribuzione. Come ha osservato Karolina Szczur, "aspettarsi che un singolo numero sia in grado di fornire una valutazione a cui aspirare è un'ipotesi errata". Quindi gli obiettivi di prestazione devono essere dettagliati, tracciabili e tangibili.
- Obiettivo: essere almeno il 20% più veloce del tuo concorrente più veloce.
Secondo la ricerca psicologica, se vuoi che gli utenti sentano che il tuo sito web è più veloce del sito web della concorrenza, devi essere almeno il 20% più veloce. Studia i tuoi principali concorrenti, raccogli metriche su come si comportano su dispositivi mobili e desktop e imposta soglie che ti aiuterebbero a superarli. Tuttavia, per ottenere risultati e obiettivi accurati, assicurati di avere prima un quadro completo dell'esperienza dei tuoi utenti studiando le tue analisi. È quindi possibile imitare l'esperienza del 90° percentile per i test.Per avere una buona prima impressione delle prestazioni dei tuoi concorrenti, puoi utilizzare Chrome UX Report ( CrUX , un set di dati RUM già pronto, video introduttivo di Ilya Grigorik e guida dettagliata di Rick Viscomi) o Treo, uno strumento di monitoraggio RUM che è alimentato da Chrome UX Report. I dati vengono raccolti dagli utenti del browser Chrome, quindi i rapporti saranno specifici di Chrome, ma ti forniranno una distribuzione abbastanza completa delle prestazioni, soprattutto i punteggi di Core Web Vitals, su un'ampia gamma di visitatori. Si noti che i nuovi dataset CrUX vengono rilasciati il secondo martedì di ogni mese .
In alternativa puoi anche utilizzare:
- Strumento di confronto dei rapporti sull'esperienza utente di Chrome di Addy Osmani,
- Speed Scorecard (fornisce anche uno strumento per la stima dell'impatto sulle entrate),
- Confronto del test dell'esperienza utente reale o
- SiteSpeed CI (basato su test sintetici).
Nota : se utilizzi Page Speed Insights o l'API Page Speed Insights (no, non è deprecato!), puoi ottenere i dati sulle prestazioni di CrUX per pagine specifiche anziché solo per gli aggregati. Questi dati possono essere molto più utili per impostare obiettivi di rendimento per risorse come "pagina di destinazione" o "scheda di prodotto". E se stai usando CI per testare i budget, devi assicurarti che il tuo ambiente testato corrisponda a CrUX se hai usato CrUX per impostare l'obiettivo ( grazie Patrick Meenan! ).
Se hai bisogno di aiuto per mostrare il ragionamento alla base della definizione delle priorità della velocità, o se desideri visualizzare il decadimento del tasso di conversione o l'aumento della frequenza di rimbalzo con prestazioni più lente, o forse avresti bisogno di sostenere una soluzione RUM nella tua organizzazione, Sergey Chernyshev ha creato un UX Speed Calculator, uno strumento open source che ti aiuta a simulare i dati e visualizzarli per guidare il tuo punto.
CrUX genera una panoramica delle distribuzioni delle prestazioni nel tempo, con il traffico raccolto dagli utenti di Google Chrome. Puoi crearne uno personalizzato su Chrome UX Dashboard. (Grande anteprima) 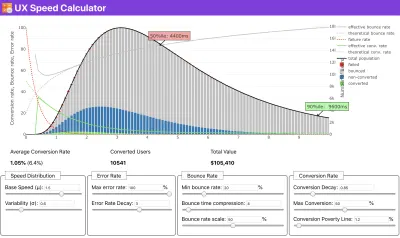
Proprio quando hai bisogno di dimostrare che le prestazioni guidino il tuo punto di vista: UX Speed Calculator visualizza l'impatto delle prestazioni su frequenze di rimbalzo, conversione e entrate totali, in base a dati reali. (Grande anteprima) A volte potresti voler andare un po' più a fondo, combinando i dati provenienti da CrUX con qualsiasi altro dato che hai già per capire rapidamente dove si trovano i rallentamenti, i punti ciechi e le inefficienze, per i tuoi concorrenti o per il tuo progetto. Nel suo lavoro, Harry Roberts ha utilizzato un foglio di calcolo della topografia della velocità del sito che utilizza per suddividere le prestazioni in base ai tipi di pagina chiave e tenere traccia delle diverse metriche chiave su di esse. Puoi scaricare il foglio di lavoro come Fogli Google, Excel, documento OpenOffice o CSV.
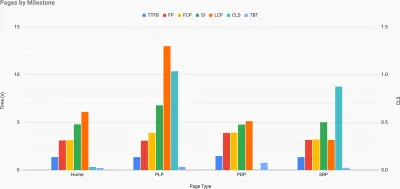
Topografia della velocità del sito, con metriche chiave rappresentate per le pagine chiave del sito. (Grande anteprima) E se vuoi andare fino in fondo , puoi eseguire un audit delle prestazioni di Lighthouse su ogni pagina di un sito (tramite Lightouse Parade), con un output salvato come CSV. Ciò ti aiuterà a identificare quali pagine (o tipi di pagine) specifici dei tuoi concorrenti hanno prestazioni peggiori o migliori e su cosa potresti voler concentrare i tuoi sforzi. (Per il tuo sito, probabilmente è meglio inviare dati a un endpoint di analisi!).

Con Lighthouse Parade, puoi eseguire un controllo delle prestazioni di Lighthouse su ogni pagina di un sito, con un output salvato come CSV. (Grande anteprima) Raccogli dati, imposta un foglio di lavoro, riduci il 20% e imposta i tuoi obiettivi ( budget di rendimento ) in questo modo. Ora hai qualcosa di misurabile con cui testare. Se stai tenendo a mente il budget e stai cercando di spedire solo il carico utile minimo per ottenere un rapido time-to-interactive, allora sei su una strada ragionevole.
Hai bisogno di risorse per iniziare?
- Addy Osmani ha scritto un articolo molto dettagliato su come avviare il budgeting delle prestazioni, come quantificare l'impatto delle nuove funzionalità e da dove iniziare quando si supera il budget.
- La guida di Lara Hogan su come affrontare i progetti con un budget di prestazioni può fornire utili suggerimenti ai designer.
- Harry Roberts ha pubblicato una guida sull'impostazione di un foglio Google per visualizzare l'impatto degli script di terze parti sulle prestazioni, utilizzando Request Map,
- Il calcolatore del budget delle prestazioni di Jonathan Fielding, il calcolatore del budget perf di Katie Hempenius e le calorie del browser possono aiutare nella creazione di budget (grazie a Karolina Szczur per l'avviso).
- In molte aziende, i budget delle prestazioni non dovrebbero essere ambiziosi, ma piuttosto pragmatici, fungendo da segno di attesa per evitare di scivolare oltre un certo punto. In tal caso, potresti scegliere come soglia il tuo peggior punto dati nelle ultime due settimane e prenderlo da lì. Budget delle prestazioni, ti mostra pragmaticamente una strategia per raggiungerlo.
- Inoltre, rendi visibili sia il budget delle prestazioni che le prestazioni attuali impostando dashboard con grafici che riportano le dimensioni delle build. Esistono molti strumenti che ti consentono di raggiungere questo obiettivo: dashboard SiteSpeed.io (open source), SpeedCurve e Calibre sono solo alcuni di questi e puoi trovare più strumenti su perf.rocks.

Browser Calories ti aiuta a impostare un budget di rendimento e misurare se una pagina supera questi numeri o meno. (Grande anteprima) Una volta stabilito un budget, incorporalo nel processo di creazione con Webpack Performance Hints e Bundlesize, Lighthouse CI, PWMetrics o Sitespeed CI per applicare i budget alle richieste pull e fornire una cronologia dei punteggi nei commenti PR.
Per esporre i budget delle prestazioni all'intero team, integra i budget delle prestazioni in Lighthouse tramite Lightwallet o usa LHCI Action per una rapida integrazione di Github Actions. E se hai bisogno di qualcosa di personalizzato, puoi utilizzare webpagetest-charts-api, un'API di endpoint per creare grafici dai risultati di WebPagetest.
Tuttavia, la consapevolezza delle prestazioni non dovrebbe venire solo dai budget delle prestazioni. Proprio come Pinterest, potresti creare una regola eslint personalizzata che non consenta l'importazione da file e directory noti per essere molto dipendenti e gonfiare il pacchetto. Imposta un elenco di pacchetti "sicuri" che possono essere condivisi con l'intero team.
Inoltre, pensa alle attività critiche dei clienti che sono più vantaggiose per la tua attività. Studiare, discutere e definire soglie di tempo accettabili per le azioni critiche e stabilire tempi utente "UX ready" approvati dall'intera organizzazione. In molti casi, i percorsi degli utenti toccheranno il lavoro di molti reparti diversi, quindi l'allineamento in termini di tempi accettabili aiuterà a supportare o prevenire le discussioni sulle prestazioni lungo la strada. Assicurati che i costi aggiuntivi delle risorse e delle funzionalità aggiunte siano visibili e compresi.
Allinea gli sforzi in termini di prestazioni con altre iniziative tecnologiche, che vanno dalle nuove funzionalità del prodotto in fase di creazione al refactoring fino al raggiungimento di un nuovo pubblico globale. Quindi, ogni volta che si verifica una conversazione su un ulteriore sviluppo, anche le prestazioni fanno parte di quella conversazione. È molto più facile raggiungere gli obiettivi di prestazioni quando la base di codice è nuova o è solo in fase di refactoring.
Inoltre, come suggerito da Patrick Meenan, vale la pena pianificare una sequenza di caricamento e dei compromessi durante il processo di progettazione. Se dai la priorità in anticipo a quali parti sono più critiche e definisci l'ordine in cui dovrebbero apparire, saprai anche cosa può essere ritardato. Idealmente, quell'ordine rifletterà anche la sequenza delle tue importazioni CSS e JavaScript, quindi gestirle durante il processo di compilazione sarà più semplice. Inoltre, considera quale dovrebbe essere l'esperienza visiva negli stati "intermedi", mentre la pagina viene caricata (ad esempio quando i caratteri web non sono ancora stati caricati).
Una volta che hai stabilito una forte cultura delle prestazioni nella tua organizzazione, punta a essere il 20% più veloce di te stesso per mantenere intatte le priorità con il passare del tempo ( grazie, Guy Podjarny! ). Ma tieni conto dei diversi tipi e comportamenti di utilizzo dei tuoi clienti (che Tobias Baldauf ha chiamato cadenza e coorti), insieme al traffico dei bot e agli effetti della stagionalità.
Pianificazione, pianificazione, pianificazione. Potrebbe essere allettante entrare presto in alcune rapide ottimizzazioni dei "frutti bassi" - e potrebbe essere una buona strategia per vittorie rapide - ma sarà molto difficile mantenere le prestazioni una priorità senza pianificare e impostare una compagnia realistica - obiettivi di performance su misura.
- Scegli le metriche giuste.
Non tutte le metriche sono ugualmente importanti. Studia quali metriche contano di più per la tua applicazione: di solito, sarà definita dalla velocità con cui puoi iniziare a eseguire il rendering dei pixel più importanti della tua interfaccia e dalla velocità con cui puoi fornire la reattività all'input per questi pixel renderizzati. Questa conoscenza ti darà il miglior obiettivo di ottimizzazione per gli sforzi in corso. Alla fine, non sono gli eventi di caricamento o i tempi di risposta del server a definire l'esperienza, ma la percezione di quanto sia scattante l'interfaccia.Cosa significa? Piuttosto che concentrarti sul tempo di caricamento della pagina intera (tramite i tempi onLoad e DOMContentLoaded , ad esempio), dai la priorità al caricamento della pagina come percepito dai tuoi clienti. Ciò significa concentrarsi su un insieme leggermente diverso di metriche. In effetti, scegliere la metrica giusta è un processo senza vincitori evidenti.
Sulla base della ricerca di Tim Kadlec e delle note di Marcos Iglesias nel suo intervento, le metriche tradizionali potrebbero essere raggruppate in pochi set. Di solito, avremo bisogno di tutti loro per avere un quadro completo delle prestazioni e nel tuo caso particolare alcuni di essi saranno più importanti di altri.
- Le metriche basate sulla quantità misurano il numero di richieste, il peso e un punteggio di prestazione. Buono per generare allarmi e monitorare i cambiamenti nel tempo, non così buono per comprendere l'esperienza dell'utente.
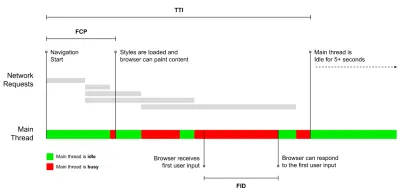
- Le metriche di traguardo utilizzano gli stati durante la durata del processo di caricamento, ad esempio Time To First Byte e Time To Interactive . Buono per descrivere l'esperienza dell'utente e il monitoraggio, non così buono per sapere cosa succede tra le pietre miliari.
- Le metriche di rendering forniscono una stima della velocità di rendering del contenuto (ad es. Tempo di avvio del rendering , Indice di velocità ). Buono per misurare e modificare le prestazioni di rendering, ma non così buono per misurare quando vengono visualizzati contenuti importanti e con cui è possibile interagire.
- Le metriche personalizzate misurano un particolare evento personalizzato per l'utente, ad esempio Time To First Tweet di Twitter e PinnerWaitTime di Pinterest. Buono per descrivere con precisione l'esperienza dell'utente, non così buono per ridimensionare le metriche e confrontarlo con i concorrenti.
Per completare il quadro, di solito cerchiamo metriche utili tra tutti questi gruppi. Di solito, quelli più specifici e rilevanti sono:
- Time to Interactive (TTI)
Il punto in cui il layout si è stabilizzato , i webfont chiave sono visibili e il thread principale è abbastanza disponibile per gestire l'input dell'utente, in pratica il contrassegno temporale in cui un utente può interagire con l'interfaccia utente. Le metriche chiave per capire quanta attesa deve subire un utente per utilizzare il sito senza ritardi. Boris Schapira ha scritto un post dettagliato su come misurare il TTI in modo affidabile. - First Input Delay (FID) o Reattività di input
Il momento in cui un utente interagisce per la prima volta con il tuo sito al momento in cui il browser è effettivamente in grado di rispondere a tale interazione. Completa molto bene TTI in quanto descrive la parte mancante dell'immagine: cosa succede quando un utente interagisce effettivamente con il sito. Inteso solo come metrica RUM. C'è una libreria JavaScript per misurare il FID nel browser. - La più grande vernice contenta (LCP)
Contrassegna il punto nella sequenza temporale di caricamento della pagina in cui è probabile che il contenuto importante della pagina sia stato caricato. Il presupposto è che l'elemento più importante della pagina sia quello più grande visibile nel viewport dell'utente. Se gli elementi sono renderizzati sia above che below the fold, solo la parte visibile è considerata rilevante. - Tempo di blocco totale ( TBT )
Una metrica che aiuta a quantificare la gravità di quanto una pagina non sia interattiva prima che diventi interattiva in modo affidabile (ovvero, il thread principale è stato privo di attività che superano i 50 ms ( attività lunghe ) per almeno 5 secondi). La metrica misura la quantità di tempo totale tra il primo disegno e Time to Interactive (TTI) in cui il thread principale è stato bloccato per un tempo sufficientemente lungo da impedire la reattività dell'input. Non c'è da stupirsi, quindi, che un TBT basso sia un buon indicatore di buone prestazioni. (grazie, Artem, Phil) - Spostamento cumulativo del layout ( CLS )
La metrica evidenzia la frequenza con cui gli utenti subiscono cambiamenti di layout imprevisti ( ridistribuzioni ) quando accedono al sito. Esamina gli elementi instabili e il loro impatto sull'esperienza complessiva. Più basso è il punteggio, meglio è. - Indice di velocità
Misura la velocità con cui i contenuti della pagina vengono popolati visivamente; più basso è il punteggio, meglio è. Il punteggio dell'indice di velocità viene calcolato in base alla velocità di avanzamento visivo , ma è semplicemente un valore calcolato. È anche sensibile alle dimensioni del viewport, quindi è necessario definire una gamma di configurazioni di test che corrispondano al pubblico di destinazione. Nota che sta diventando meno importante con LCP che sta diventando una metrica più rilevante ( grazie, Boris, Artem! ). - Tempo CPU speso
Una metrica che mostra la frequenza e la durata del blocco del thread principale, lavorando su pittura, rendering, scripting e caricamento. Il tempo di CPU elevato è un chiaro indicatore di un'esperienza janky , ovvero quando l'utente sperimenta un notevole ritardo tra la propria azione e una risposta. Con WebPageTest, puoi selezionare "Capture Dev Tools Timeline" nella scheda "Chrome" per esporre l'interruzione del thread principale mentre viene eseguito su qualsiasi dispositivo utilizzando WebPageTest. - Costi della CPU a livello di componente
Proprio come per il tempo impiegato dalla CPU , questa metrica, proposta da Stoyan Stefanov, esplora l' impatto di JavaScript sulla CPU . L'idea è di utilizzare il conteggio delle istruzioni della CPU per componente per comprenderne l'impatto sull'esperienza complessiva, in isolamento. Potrebbe essere implementato utilizzando Burattinaio e Chrome. - Indice di frustrazione
Mentre molti parametri descritti sopra spiegano quando si verifica un evento particolare, FrustrationIndex di Tim Vereecke esamina i divari tra i parametri invece di esaminarli individualmente. Esamina le pietre miliari chiave percepite dall'utente finale, come il titolo è visibile, il primo contenuto è visibile, visivamente pronto e la pagina sembra pronta e calcola un punteggio che indica il livello di frustrazione durante il caricamento di una pagina. Maggiore è il divario, maggiore è la possibilità che un utente venga frustrato. Potenzialmente un buon KPI per l'esperienza dell'utente. Tim ha pubblicato un post dettagliato su FrustrationIndex e su come funziona. - Impatto sul peso dell'annuncio
Se il tuo sito dipende dalle entrate generate dalla pubblicità, è utile monitorare il peso del codice relativo agli annunci. Lo script di Paddy Ganti costruisce due URL (uno normale e uno che blocca gli annunci), richiede la generazione di un confronto video tramite WebPageTest e segnala un delta. - Metriche di deviazione
Come notato dagli ingegneri di Wikipedia, i dati su quanta varianza esiste nei tuoi risultati potrebbero informarti sull'affidabilità dei tuoi strumenti e quanta attenzione dovresti prestare a deviazioni e outler. Una grande varianza è un indicatore delle regolazioni necessarie nell'impostazione. Aiuta anche a capire se alcune pagine sono più difficili da misurare in modo affidabile, ad esempio a causa di script di terze parti che causano variazioni significative. Potrebbe anche essere una buona idea tenere traccia della versione del browser per comprendere i picchi di prestazioni quando viene lanciata una nuova versione del browser. - Metriche personalizzate
Le metriche personalizzate sono definite dalle esigenze aziendali e dall'esperienza del cliente. Richiede di identificare pixel importanti , script critici , CSS necessari e risorse pertinenti e misurare la velocità con cui vengono consegnati all'utente. Per quello, puoi monitorare i tempi di rendering dell'eroe o utilizzare l'API delle prestazioni, contrassegnando timestamp particolari per eventi importanti per la tua attività. Inoltre, puoi raccogliere metriche personalizzate con WebPagetest eseguendo JavaScript arbitrario alla fine di un test.
Nota che il First Significato Paint (FMP) non appare nella panoramica sopra. Un tempo forniva un'idea della velocità con cui il server emette i dati. L'FMP lungo di solito indicava che JavaScript bloccava il thread principale, ma potrebbe essere correlato anche a problemi di back-end/server. Tuttavia, la metrica è stata deprecata di recente in quanto non sembra essere accurata in circa il 20% dei casi. È stato effettivamente sostituito con LCP che è sia più affidabile che più facile da ragionare. Non è più supportato in Lighthouse. Ricontrolla le ultime metriche e consigli sulle prestazioni incentrati sull'utente solo per assicurarti di essere sulla pagina sicura ( grazie, Patrick Meenan ).
Steve Souders ha una spiegazione dettagliata di molti di questi parametri. È importante notare che mentre il Time-To-Interactive viene misurato eseguendo controlli automatizzati nel cosiddetto ambiente di laboratorio , First Input Delay rappresenta l'esperienza utente effettiva , con gli utenti effettivi che subiscono un notevole ritardo. In generale, è probabilmente una buona idea misurare e monitorare sempre entrambi.
A seconda del contesto dell'applicazione, le metriche preferite potrebbero differire: ad es. per l'interfaccia utente di Netflix TV, la reattività dell'input chiave, l'utilizzo della memoria e il TTI sono più importanti e per Wikipedia, le prime/ultime modifiche visive e le metriche del tempo impiegato dalla CPU sono più importanti.
Nota : sia FID che TTI non tengono conto del comportamento di scorrimento; lo scorrimento può avvenire in modo indipendente poiché è fuori dal thread principale, quindi per molti siti di consumo di contenuti queste metriche potrebbero essere molto meno importanti ( grazie, Patrick! ).
- Misurare e ottimizzare i Core Web Vitals .
Per molto tempo, le metriche delle prestazioni sono state piuttosto tecniche, incentrate sulla visione ingegneristica della velocità di risposta dei server e della velocità di caricamento dei browser. Le metriche sono cambiate nel corso degli anni, cercando di trovare un modo per catturare l'esperienza utente effettiva , piuttosto che i tempi del server. A maggio 2020, Google ha annunciato Core Web Vitals, una serie di nuove metriche delle prestazioni incentrate sull'utente, ciascuna delle quali rappresenta un aspetto distinto dell'esperienza dell'utente.Per ciascuno di essi, Google consiglia una serie di obiettivi di velocità accettabili. Almeno il 75% di tutte le visualizzazioni di pagina deve superare l' intervallo Buono per superare questa valutazione. Queste metriche hanno rapidamente guadagnato terreno e, con i Core Web Vitals che sono diventati indicatori di ranking per la Ricerca Google a maggio 2021 ( aggiornamento dell'algoritmo di ranking di Page Experience ), molte aziende hanno rivolto la loro attenzione ai punteggi delle prestazioni.
Analizziamo ciascuno dei Core Web Vitals, uno per uno, insieme a tecniche e strumenti utili per ottimizzare le tue esperienze tenendo conto di queste metriche. (Vale la pena notare che ti ritroverai con punteggi migliori di Core Web Vitals seguendo un consiglio generale in questo articolo.)
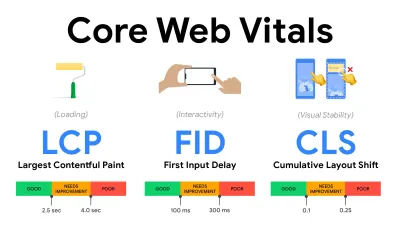
- Più grande Contentful Paint ( LCP ) < 2,5 sec.
Misura il caricamento di una pagina e segnala il tempo di rendering dell'immagine o del blocco di testo più grande visibile all'interno del viewport. Pertanto, LCP è influenzato da tutto ciò che sta rinviando il rendering di informazioni importanti, che si tratti di tempi di risposta del server lenti, blocco dei CSS, JavaScript in corso (di prima parte o di terze parti), caricamento di font Web, costose operazioni di rendering o pittura, pigrizia -immagini caricate, schermate dello scheletro o rendering lato client.
Per una buona esperienza, LCP dovrebbe verificarsi entro 2,5 secondi dal primo caricamento della pagina. Ciò significa che dobbiamo rendere la prima parte visibile della pagina il prima possibile. Ciò richiederà CSS critici personalizzati per ogni modello, orchestrando l'ordine di<head>e precaricando le risorse critiche (le tratteremo più avanti).Il motivo principale per un punteggio LCP basso sono solitamente le immagini. Fornire un LCP in meno di 2,5 secondi su Fast 3G — ospitato su un server ben ottimizzato, tutto statico senza rendering lato client e con un'immagine proveniente da un CDN di immagini dedicato — significa che la dimensione teorica massima dell'immagine è di soli 144 KB circa . Ecco perché le immagini reattive sono importanti, così come il precaricamento delle immagini critiche in anticipo (con
preload).Suggerimento rapido : per scoprire cosa è considerato LCP su una pagina, in DevTools puoi passare il mouse sopra il badge LCP sotto "Tempi" nel Performance Panel ( grazie, Tim Kadlec !).
- Ritardo primo ingresso ( FID ) < 100 ms.
Misura la reattività dell'interfaccia utente, ovvero per quanto tempo il browser è stato impegnato con altre attività prima che potesse reagire a un evento di input dell'utente discreto come un tocco o un clic. È progettato per catturare i ritardi risultanti dall'occupazione del thread principale, soprattutto durante il caricamento della pagina.
L'obiettivo è rimanere entro 50–100 ms per ogni interazione. Per arrivarci, dobbiamo identificare attività lunghe (blocca il thread principale per >50 ms) e suddividerle, suddividere il codice in più blocchi, ridurre il tempo di esecuzione di JavaScript, ottimizzare il recupero dei dati, rinviare l'esecuzione di script di terze parti , sposta JavaScript nel thread in background con i Web worker e utilizza l'idratazione progressiva per ridurre i costi di reidratazione nelle SPA.Suggerimento rapido : in generale, una strategia affidabile per ottenere un punteggio FID migliore consiste nel ridurre al minimo il lavoro sul thread principale suddividendo i pacchetti più grandi in pacchetti più piccoli e servendo ciò di cui l'utente ha bisogno quando ne ha bisogno, in modo che le interazioni dell'utente non vengano ritardate . Ne tratteremo di più in dettaglio di seguito.
- Spostamento cumulativo del layout ( CLS ) < 0,1.
Misura la stabilità visiva dell'interfaccia utente per garantire interazioni fluide e naturali, ovvero la somma totale di tutti i singoli punteggi di spostamento del layout per ogni spostamento imprevisto del layout che si verifica durante la vita della pagina. Un cambiamento di layout individuale si verifica ogni volta che un elemento già visibile cambia la sua posizione nella pagina. Viene valutato in base alle dimensioni del contenuto e alla distanza percorsa.
Quindi ogni volta che compare un cambiamento, ad esempio quando i font di fallback e i web font hanno metriche dei font differenti, o annunci, incorporamenti o iframe che arrivano in ritardo, o le dimensioni dell'immagine/video non sono riservate, o il CSS in ritardo impone ridisegni o le modifiche vengono iniettate da late JavaScript: ha un impatto sul punteggio CLS. Il valore consigliato per una buona esperienza è un CLS < 0,1.
Vale la pena notare che i Core Web Vitals dovrebbero evolversi nel tempo, con un ciclo annuale prevedibile . Per l'aggiornamento del primo anno, potremmo aspettarci che First Contentful Paint venga promosso a Core Web Vitals, una soglia FID ridotta e un migliore supporto per le applicazioni a pagina singola. We might also see the responding to user inputs after load gaining more weight, along with security, privacy and accessibility (!) considerations.
Related to Core Web Vitals, there are plenty of useful resources and articles that are worth looking into:
- Web Vitals Leaderboard allows you to compare your scores against competition on mobile, tablet, desktop, and on 3G and 4G.
- Core SERP Vitals, a Chrome extension that shows the Core Web Vitals from CrUX in the Google Search Results.
- Layout Shift GIF Generator that visualizes CLS with a simple GIF (also available from the command line).
- web-vitals library can collect and send Core Web Vitals to Google Analytics, Google Tag Manager or any other analytics endpoint.
- Analyzing Web Vitals with WebPageTest, in which Patrick Meenan explores how WebPageTest exposes data about Core Web Vitals.
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it's calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow ? Not quite. They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don't really measure the full lifecycle of a user's experience, plus it's difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- Più grande Contentful Paint ( LCP ) < 2,5 sec.
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn't provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old , costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that's a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. ( Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers! ).
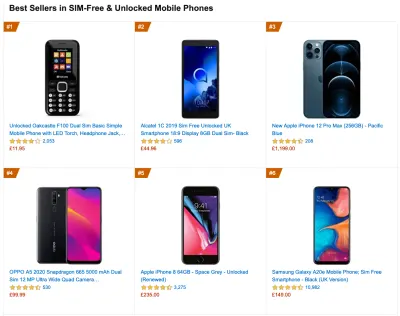
When building a new site or app, always check current Amazon Best Sellers for your target market first. (Grande anteprima) What test devices to choose then? The ones that fit well with the profile outlined above. It's a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset : a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!) .
If you don't have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (eg 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (eg 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That's why it's important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (eg Lighthouse , Calibre , WebPageTest ) and
- Real User Monitoring ( RUM ) tools evaluate user interactions continuously and collect field data (eg SpeedCurve , New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it's quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.

Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even monitor back-end and front-end performance all in one place.
Note : It's always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it's implemented ( thanks, Yoav, Patrick !). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it's likely that you'll be testing in Lighthouse, keep in mind that you can:
- Set up "clean" and "customer" profiles for testing.
While running tests in passive monitoring tools, it's a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).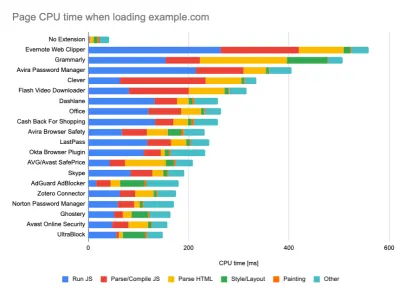
DebugBear's report highlights 20 slowest extensions, including password managers, ad-blockers and popular applications like Evernote and Grammarly. (Grande anteprima) However, it's also a good idea to study which browser extensions your customers use frequently, and test with dedicated "customer" profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence, "clean" profile results alone are overly optimistic and can be crushed in real-life scenarios.
- Condividi gli obiettivi di performance con i tuoi colleghi.
Assicurati che gli obiettivi di prestazione siano familiari a tutti i membri della tua squadra per evitare malintesi su tutta la linea. Ogni decisione, che si tratti di progettazione, marketing o qualsiasi altra via di mezzo, ha implicazioni sulle prestazioni e la distribuzione di responsabilità e proprietà nell'intero team semplificherebbe le decisioni incentrate sulle prestazioni in seguito. Mappa le decisioni di progettazione rispetto al budget delle prestazioni e alle priorità definite all'inizio.
Stabilire obiettivi realistici
- Tempo di risposta di 100 millisecondi, 60 fps.
Affinché un'interazione sia fluida, l'interfaccia ha 100 ms per rispondere all'input dell'utente. Non più a lungo e l'utente percepisce l'app come lenta. Il RAIL, un modello di prestazioni incentrato sull'utente, offre obiettivi sani : per consentire una risposta <100 millisecondi, la pagina deve restituire il controllo al thread principale al più tardi ogni <50 millisecondi. La latenza di input stimata ci dice se stiamo raggiungendo quella soglia e, idealmente, dovrebbe essere inferiore a 50 ms. Per i punti ad alta pressione come l'animazione, è meglio non fare nient'altro dove puoi e il minimo assoluto dove non puoi.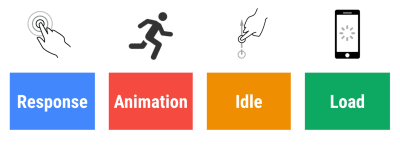
RAIL, un modello di prestazioni incentrato sull'utente. Inoltre, ogni fotogramma dell'animazione dovrebbe essere completato in meno di 16 millisecondi, ottenendo così 60 fotogrammi al secondo (1 secondo ÷ 60 = 16,6 millisecondi), preferibilmente sotto i 10 millisecondi. Poiché il browser ha bisogno di tempo per dipingere il nuovo frame sullo schermo, il codice dovrebbe terminare l'esecuzione prima di raggiungere il segno di 16,6 millisecondi. Stiamo iniziando a parlare di 120 fps (ad es. gli schermi di iPad Pro funzionano a 120 Hz) e Surma ha coperto alcune soluzioni di prestazioni di rendering per 120 fps, ma probabilmente non è un obiettivo che stiamo ancora guardando.
Sii pessimista nelle aspettative sulle prestazioni, ma sii ottimista nella progettazione dell'interfaccia e usa saggiamente il tempo di inattività (seleziona idle, idle-finché-urgente e reagisci-idle). Ovviamente, questi obiettivi si applicano alle prestazioni di runtime, piuttosto che alle prestazioni di caricamento.
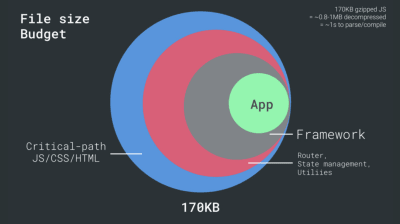
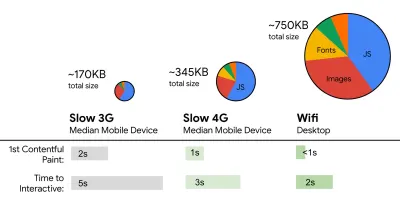
- FID < 100 ms, LCP < 2,5 s, TTI < 5 s su 3G, budget per dimensioni file critiche < 170 KB (gzippato).
Anche se potrebbe essere molto difficile da raggiungere, un buon obiettivo finale sarebbe Time to Interactive sotto i 5 anni e, per le visite ripetute, puntare ai minori di 2 anni (raggiungibile solo con un addetto al servizio). Puntare alla pittura di contenuto più grande di meno di 2,5 secondi e ridurre al minimo il tempo di blocco totale e lo spostamento cumulativo del layout . Un ritardo del primo ingresso accettabile è inferiore a 100 ms–70 ms. Come accennato in precedenza, stiamo considerando che la linea di base è un telefono Android da $ 200 (ad es. Moto G4) su una rete 3G lenta, emulato a 400 ms RTT e velocità di trasferimento di 400 kbps.Abbiamo due vincoli principali che modellano efficacemente un obiettivo ragionevole per la consegna rapida dei contenuti sul Web. Da un lato, abbiamo vincoli di recapito della rete dovuti a TCP Slow Start. I primi 14 KB dell'HTML - 10 pacchetti TCP, ciascuno da 1460 byte, per un totale di circa 14,25 KB, anche se da non prendere alla lettera - è il pezzo di carico utile più critico e l'unica parte del budget che può essere consegnata nel primo roundtrip ( che è tutto ciò che ottieni in 1 secondo a 400 ms RTT a causa degli orari di sveglia dei dispositivi mobili).

Con le connessioni TCP, iniziamo con una piccola finestra di congestione e la raddoppiamo per ogni andata e ritorno. Nel primo viaggio di andata e ritorno, possiamo contenere 14 KB. Da: Rete di browser ad alte prestazioni di Ilya Grigorik. (Grande anteprima) ( Nota : poiché TCP generalmente sottoutilizza la connessione di rete in misura significativa, Google ha sviluppato TCP Bottleneck Bandwidth e RRT ( BBR ), un algoritmo di controllo del flusso TCP controllato dal ritardo TCP. Progettato per il Web moderno, risponde alla congestione effettiva, invece della perdita di pacchetti come fa TCP, è significativamente più veloce, con un throughput più elevato e una latenza inferiore e l'algoritmo funziona in modo diverso ( grazie, Victor, Barry! ).
D'altra parte, abbiamo vincoli hardware su memoria e CPU a causa dell'analisi di JavaScript e dei tempi di esecuzione (ne parleremo in dettaglio più avanti). Per raggiungere gli obiettivi indicati nel primo paragrafo, dobbiamo considerare il budget critico delle dimensioni dei file per JavaScript. Le opinioni variano su quale dovrebbe essere quel budget (e dipende fortemente dalla natura del tuo progetto), ma un budget di 170 KB JavaScript già compresso richiederebbe fino a 1 secondo per analizzare e compilare su un telefono di fascia media. Supponendo che 170 KB si espandano a 3 volte quella dimensione quando decompresso (0,7 MB), quella potrebbe già essere la campana a morto di un'esperienza utente "decente" su un Moto G4/G5 Plus.
Nel caso del sito Web di Wikipedia, nel 2020, a livello globale, l'esecuzione del codice è diventata più veloce del 19% per gli utenti di Wikipedia. Quindi, se le tue metriche sulle prestazioni web anno dopo anno rimangono stabili, di solito è un segnale di avvertimento poiché stai effettivamente regredendo mentre l'ambiente continua a migliorare (dettagli in un post sul blog di Gilles Dubuc).
Se vuoi rivolgerti a mercati in crescita come il Sud-est asiatico, l'Africa o l'India, dovrai considerare una serie di vincoli molto diversi. Addy Osmani copre i principali vincoli dei feature phone, come pochi dispositivi a basso costo e di alta qualità, l'indisponibilità di reti di alta qualità e dati mobili costosi, insieme al budget PRPL-30 e alle linee guida di sviluppo per questi ambienti.
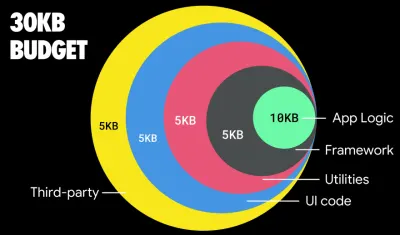
Secondo Addy Osmani, anche una dimensione consigliata per i percorsi con caricamento lento è inferiore a 35 KB. (Grande anteprima) 
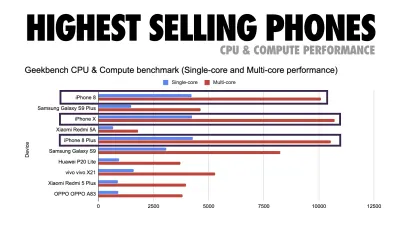
Addy Osmani suggerisce un budget per le prestazioni PRPL-30 (30 KB compresso con gzip + bundle iniziale ridotto al minimo) se si rivolge a un feature phone. (Grande anteprima) In effetti, Alex Russell di Google consiglia di puntare a 130–170 KB compressi con gzip come limite superiore ragionevole. Negli scenari del mondo reale, la maggior parte dei prodotti non è nemmeno vicina: una dimensione media del pacchetto oggi è di circa 452 KB, con un aumento del 53,6% rispetto all'inizio del 2015. Su un dispositivo mobile di classe media, ciò rappresenta 12-20 secondi per Time -To-Interattivo .
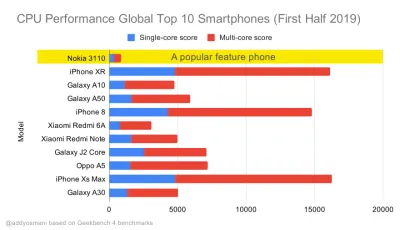
Geekbench benchmark delle prestazioni della CPU per gli smartphone più venduti a livello globale nel 2019. JavaScript sottolinea le prestazioni single-core (ricorda, è intrinsecamente più single-thread rispetto al resto della piattaforma Web) ed è vincolato alla CPU. Dall'articolo di Addy "Caricamento veloce di pagine Web su un telefono con funzionalità da $ 20". (Grande anteprima) Potremmo anche andare oltre il budget per le dimensioni del pacchetto. Ad esempio, potremmo impostare i budget delle prestazioni in base alle attività del thread principale del browser, ad esempio il tempo di disegno prima dell'inizio del rendering, o rintracciare i problemi di CPU front-end. Strumenti come Calibre, SpeedCurve e Bundlesize possono aiutarti a tenere sotto controllo i tuoi budget e possono essere integrati nel tuo processo di creazione.
Infine, un budget di rendimento probabilmente non dovrebbe essere un valore fisso . A seconda della connessione di rete, i budget delle prestazioni dovrebbero adattarsi, ma il carico utile su una connessione più lenta è molto più "costoso", indipendentemente da come vengono utilizzati.
Nota : potrebbe sembrare strano impostare budget così rigidi in tempi di HTTP/2 diffuso, imminenti 5G e HTTP/3, telefoni cellulari in rapida evoluzione e fiorenti SPA. Tuttavia, sembrano ragionevoli quando affrontiamo la natura imprevedibile della rete e dell'hardware, compreso qualsiasi cosa, dalle reti congestionate all'infrastruttura in lento sviluppo, ai limiti di dati, ai browser proxy, alla modalità di salvataggio dei dati e alle tariffe di roaming subdole.
Definire l'ambiente
- Scegli e configura i tuoi strumenti di costruzione.
Non prestare troppa attenzione a ciò che è apparentemente cool in questi giorni. Attenersi al proprio ambiente per la costruzione, che si tratti di Grunt, Gulp, Webpack, Parcel o una combinazione di strumenti. Finché ottieni i risultati di cui hai bisogno e non hai problemi a mantenere il tuo processo di creazione, stai andando bene.Tra gli strumenti di build, Rollup continua a guadagnare terreno, così come Snowpack, ma Webpack sembra essere il più consolidato, con letteralmente centinaia di plugin disponibili per ottimizzare le dimensioni delle tue build. Fai attenzione alla Roadmap Webpack 2021.
Una delle strategie più importanti apparse di recente è il blocco granulare con Webpack in Next.js e Gatsby per ridurre al minimo il codice duplicato. Per impostazione predefinita, i moduli che non sono condivisi in ogni punto di ingresso possono essere richiesti per i percorsi che non lo utilizzano. Questo finisce per diventare un sovraccarico poiché viene scaricato più codice del necessario. Con il chunking granulare in Next.js, possiamo utilizzare un file manifest di build lato server per determinare quali blocchi emessi vengono utilizzati da diversi punti di ingresso.
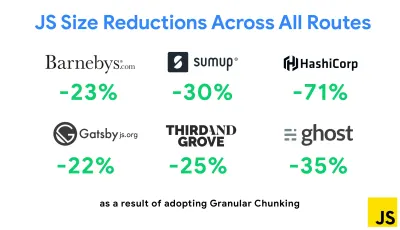
Per ridurre il codice duplicato nei progetti Webpack, possiamo utilizzare il chunking granulare, abilitato in Next.js e Gatsby per impostazione predefinita. Credito immagine: Addy Osmani. (Grande anteprima) Con SplitChunksPlugin, vengono creati più blocchi divisi in base a una serie di condizioni per impedire il recupero di codice duplicato su più percorsi. Ciò migliora il tempo di caricamento della pagina e la memorizzazione nella cache durante le navigazioni. Spedito in Next.js 9.2 e in Gatsby v2.20.7.
Tuttavia, iniziare con Webpack può essere difficile. Quindi, se vuoi tuffarti in Webpack, ci sono alcune ottime risorse là fuori:
- La documentazione di Webpack, ovviamente, è un buon punto di partenza, così come Webpack — The Confusing Bits di Raja Rao e An Annotated Webpack Config di Andrew Welch.
- Sean Larkin ha un corso gratuito su Webpack: The Core Concepts e Jeffrey Way ha rilasciato un fantastico corso gratuito su Webpack per tutti. Entrambi sono ottime introduzioni per immergersi in Webpack.
- Webpack Fundamentals è un corso molto completo di 4 ore con Sean Larkin, pubblicato da FrontendMasters.
- Gli esempi di Webpack hanno centinaia di configurazioni Webpack pronte per l'uso, suddivise per argomento e scopo. Bonus: esiste anche un configuratore di configurazione Webpack che genera un file di configurazione di base.
- awesome-webpack è un elenco curato di utili risorse Webpack, librerie e strumenti, inclusi articoli, video, corsi, libri ed esempi per progetti Angular, React e indipendenti dal framework.
- Il viaggio verso la creazione rapida di risorse di produzione con Webpack è il case study di Etsy su come il team è passato dall'utilizzo di un sistema di compilazione JavaScript basato su RequireJS all'utilizzo di Webpack e su come ha ottimizzato le proprie build, gestendo in media oltre 13.200 risorse in 4 minuti .
- I suggerimenti per le prestazioni di Webpack sono una miniera d'oro di Ivan Akulov, con molti suggerimenti incentrati sulle prestazioni, inclusi quelli incentrati specificamente su Webpack.
- awesome-webpack-perf è un repository GitHub miniera d'oro con utili strumenti Webpack e plug-in per le prestazioni. Mantenuto anche da Ivan Akulov.
- Usa il miglioramento progressivo come impostazione predefinita.
Tuttavia, dopo tutti questi anni, mantenere il miglioramento progressivo come principio guida dell'architettura e della distribuzione front-end è una scommessa sicura. Progetta e costruisci prima l'esperienza di base, quindi migliora l'esperienza con funzionalità avanzate per browser capaci, creando esperienze resilienti. Se il tuo sito Web funziona velocemente su una macchina lenta con uno schermo scadente in un browser scadente su una rete non ottimale, funzionerà più velocemente solo su una macchina veloce con un buon browser su una rete decente.In effetti, con il servizio di moduli adattivi, sembra che stiamo portando il miglioramento progressivo a un altro livello, offrendo esperienze di base "lite" ai dispositivi di fascia bassa e migliorando con funzionalità più sofisticate per i dispositivi di fascia alta. È improbabile che il miglioramento progressivo svanisca presto.
- Scegli una linea di base di prestazioni forti.
Con così tante incognite che incidono sul caricamento: rete, limitazione termica, rimozione della cache, script di terze parti, modelli di blocco del parser, I/O del disco, latenza IPC, estensioni installate, software antivirus e firewall, attività CPU in background, vincoli hardware e di memoria, differenze nella memorizzazione nella cache L2/L3, RTTS: JavaScript ha il costo più pesante dell'esperienza, accanto ai caratteri Web che bloccano il rendering per impostazione predefinita e alle immagini che spesso consumano troppa memoria. Con i colli di bottiglia delle prestazioni che si spostano dal server al client, come sviluppatori dobbiamo considerare tutte queste incognite in modo molto più dettagliato.Con un budget di 170 KB che contiene già il percorso critico HTML/CSS/JavaScript, router, gestione dello stato, utilità, framework e logica dell'applicazione, dobbiamo esaminare a fondo il costo di trasferimento di rete, il tempo di analisi/compilazione e il costo di runtime del quadro di nostra scelta. Fortunatamente, negli ultimi anni abbiamo assistito a un enorme miglioramento nella velocità con cui i browser possono analizzare e compilare gli script. Tuttavia, l'esecuzione di JavaScript è ancora il collo di bottiglia principale, quindi prestare molta attenzione al tempo di esecuzione degli script e alla rete può avere un impatto.
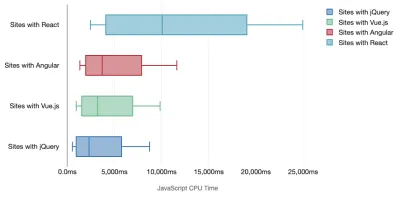
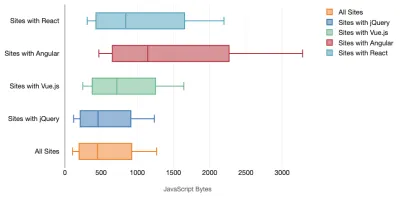
Tim Kadlec ha condotto una fantastica ricerca sulle prestazioni dei framework moderni e le ha riassunte nell'articolo "I framework JavaScript hanno un costo". Parliamo spesso dell'impatto dei framework standalone, ma come osserva Tim, in pratica non è raro avere più framework in uso . Forse una versione precedente di jQuery che viene lentamente migrata a un framework moderno, insieme ad alcune applicazioni legacy che utilizzano una versione precedente di Angular. Quindi è più ragionevole esplorare il costo cumulativo dei byte JavaScript e del tempo di esecuzione della CPU che può facilmente rendere le esperienze utente a malapena utilizzabili, anche su dispositivi di fascia alta.
In generale, i framework moderni non danno la priorità ai dispositivi meno potenti , quindi le esperienze su un telefono e su desktop saranno spesso notevolmente diverse in termini di prestazioni. Secondo la ricerca, i siti con React o Angular trascorrono più tempo sulla CPU rispetto ad altri (il che ovviamente non significa necessariamente che React sia più costoso sulla CPU di Vue.js).
Secondo Tim, una cosa è ovvia: "se stai utilizzando un framework per costruire il tuo sito, stai facendo un compromesso in termini di prestazioni iniziali , anche nel migliore degli scenari".
- Valuta framework e dipendenze.
Ora, non tutti i progetti necessitano di un framework e non tutte le pagine di un'applicazione a pagina singola devono caricare un framework. Nel caso di Netflix, "la rimozione di React, diverse librerie e il codice dell'app corrispondente dal lato client ha ridotto la quantità totale di JavaScript di oltre 200 KB, causando una riduzione di oltre il 50% del tempo di interattività di Netflix per la home page disconnessa ." Il team ha quindi utilizzato il tempo trascorso dagli utenti sulla pagina di destinazione per precaricare React per le pagine successive su cui è probabile che gli utenti atterrano (continua a leggere per i dettagli).E se rimuovessi del tutto un framework esistente su pagine critiche? Con Gatsby, puoi controllare gatsby-plugin-no-javascript che rimuove tutti i file JavaScript creati da Gatsby dai file HTML statici. Su Vercel, puoi anche consentire la disabilitazione di JavaScript runtime in produzione per determinate pagine (sperimentale).
Una volta scelto un framework, lo utilizzeremo per almeno alcuni anni, quindi se dobbiamo utilizzarne uno, dobbiamo assicurarci che la nostra scelta sia informata e ben ponderata, e questo vale soprattutto per le metriche chiave delle prestazioni che cura.
I dati mostrano che, per impostazione predefinita, i framework sono piuttosto costosi: il 58,6% delle pagine React spedisce oltre 1 MB di JavaScript e il 36% dei caricamenti di pagine Vue.js ha un First Contentful Paint di <1,5s. Secondo uno studio di Ankur Sethi, "la tua applicazione React non si caricherà mai più velocemente di circa 1,1 secondi su un telefono medio in India, non importa quanto la ottimizzi. La tua app Angular impiegherà sempre almeno 2,7 secondi per avviarsi. Il gli utenti della tua app Vue dovranno attendere almeno 1 secondo prima di poter iniziare a utilizzarla." Potresti comunque non rivolgerti all'India come mercato principale, ma gli utenti che accedono al tuo sito con condizioni di rete non ottimali avranno un'esperienza simile.
Ovviamente è possibile realizzare SPA veloci, ma non sono veloci, quindi dobbiamo tenere conto del tempo e degli sforzi necessari per realizzarle e mantenerle veloci. Probabilmente sarà più facile scegliendo all'inizio un costo di base delle prestazioni leggero.
Allora come scegliamo un framework ? È buona norma considerare almeno il costo totale sulla dimensione + i tempi di esecuzione iniziali prima di scegliere un'opzione; opzioni leggere come Preact, Inferno, Vue, Svelte, Alpine o Polymer possono portare a termine il lavoro perfettamente. La dimensione della tua linea di base definirà i vincoli per il codice della tua applicazione.
Come notato da Seb Markbage, un buon modo per misurare i costi di avvio per i framework è prima eseguire il rendering di una vista, quindi eliminarla e quindi renderizzare di nuovo in quanto può dirti come scala il framework. Il primo rendering tende a riscaldare un mucchio di codice compilato in modo pigro, di cui un albero più grande può trarre vantaggio quando viene ridimensionato. Il secondo rendering è fondamentalmente un'emulazione di come il riutilizzo del codice in una pagina influisce sulle caratteristiche delle prestazioni man mano che la pagina cresce in complessità.
Potresti arrivare fino a valutare i tuoi candidati (o qualsiasi libreria JavaScript in generale) sul sistema di punteggio in scala a 12 punti di Sacha Greif esplorando funzionalità, accessibilità, stabilità, prestazioni, ecosistema di pacchetti , comunità, curva di apprendimento, documentazione, strumenti, track record , team, compatibilità, sicurezza per esempio.
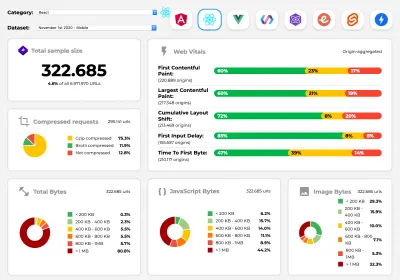
Perf Track tiene traccia delle prestazioni del framework su larga scala. (Grande anteprima) Puoi anche fare affidamento sui dati raccolti sul Web per un periodo di tempo più lungo. Ad esempio, Perf Track tiene traccia delle prestazioni del framework su larga scala, mostrando i punteggi dei Core Web Vitals aggregati all'origine per i siti Web creati in Angular, React, Vue, Polymer, Preact, Ember, Svelte e AMP. Puoi anche specificare e confrontare i siti Web creati con Gatsby, Next.js o Create React App, nonché i siti Web creati con Nuxt.js (Vue) o Sapper (Svelte).
Un buon punto di partenza è scegliere un buon stack predefinito per la tua applicazione. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI e PWA Starter Kit forniscono impostazioni predefinite ragionevoli per un rapido caricamento immediato sull'hardware mobile medio. Inoltre, dai un'occhiata alla guida alle prestazioni specifiche del framework web.dev per React e Angular ( grazie, Phillip! ).
E forse potresti adottare un approccio leggermente più rinfrescante alla creazione di applicazioni a pagina singola: Turbolinks, una libreria JavaScript da 15 KB che utilizza HTML anziché JSON per il rendering delle visualizzazioni. Quindi, quando segui un link, Turbolinks recupera automaticamente la pagina, scambia il suo
<body>e unisce il suo<head>, il tutto senza incorrere nel costo di un caricamento completo della pagina. Puoi controllare i dettagli rapidi e la documentazione completa sullo stack (Hotwire).
- Rendering lato client o rendering lato server? Tutti e due!
È una conversazione piuttosto accesa da avere. L'approccio finale sarebbe quello di impostare una sorta di avvio progressivo: utilizzare il rendering lato server per ottenere un rapido First Contentful Paint, ma includere anche alcuni JavaScript necessari minimi per mantenere il tempo di interazione vicino al First Contentful Paint. Se JavaScript arriva troppo tardi dopo l'FCP, il browser bloccherà il thread principale durante l'analisi, la compilazione e l'esecuzione di JavaScript scoperto in ritardo, limitando così l'interattività del sito o dell'applicazione.Per evitarlo, suddividi sempre l'esecuzione delle funzioni in attività asincrone separate e, ove possibile, usa
requestIdleCallback. Prendi in considerazione il caricamento lento di parti dell'interfaccia utente utilizzando il supporto dinamicoimport()di WebPack, evitando il costo di caricamento, analisi e compilazione fino a quando gli utenti non ne hanno davvero bisogno ( grazie Addy! ).Come accennato in precedenza, Time to Interactive (TTI) ci dice il tempo che intercorre tra la navigazione e l'interattività. In dettaglio, la metrica viene definita osservando la prima finestra di cinque secondi dopo il rendering del contenuto iniziale, in cui nessuna attività JavaScript richiede più di 50 ms ( Attività lunghe ). Se si verifica un'attività superiore a 50 ms, la ricerca di una finestra di cinque secondi ricomincia. Di conseguenza, il browser presumerà prima di tutto di aver raggiunto Interactive , solo per passare a Frozen , solo per tornare eventualmente a Interactive .
Una volta raggiunto Interactive , possiamo quindi, su richiesta o quando il tempo lo consente, avviare parti non essenziali dell'app. Sfortunatamente, come ha notato Paul Lewis, i framework in genere non hanno un semplice concetto di priorità che può essere mostrato agli sviluppatori, e quindi l'avvio progressivo non è facile da implementare con la maggior parte delle librerie e dei framework.
Comunque ci stiamo arrivando. In questi giorni ci sono un paio di scelte che possiamo esplorare, e Houssein Djirdeh e Jason Miller forniscono un'eccellente panoramica di queste opzioni nel loro discorso sul Rendering sul Web e nel commento di Jason e Addy sulle moderne architetture front-end. La panoramica di seguito si basa sul loro lavoro stellare.
- Rendering completo lato server (SSR)
Nell'SSR classico, come WordPress, tutte le richieste vengono gestite interamente sul server. Il contenuto richiesto viene restituito come pagina HTML finita e i browser possono visualizzarlo immediatamente. Pertanto, le app SSR non possono davvero utilizzare le API DOM, ad esempio. Il divario tra First Contentful Paint e Time to Interactive è generalmente piccolo e la pagina può essere visualizzata immediatamente mentre l'HTML viene trasmesso in streaming al browser.Ciò evita ulteriori round trip per il recupero dei dati e la creazione di modelli sul client, poiché viene gestito prima che il browser riceva una risposta. Tuttavia, ci ritroviamo con un tempo di riflessione del server più lungo e di conseguenza Time To First Byte e non utilizziamo le funzionalità reattive e ricche delle applicazioni moderne.
- Rendering statico
Sviluppiamo il prodotto come un'applicazione a pagina singola, ma tutte le pagine vengono prerenderizzate in HTML statico con JavaScript minimo come fase di compilazione. Ciò significa che con il rendering statico produciamo in anticipo singoli file HTML per ogni possibile URL , cosa che non molte applicazioni possono permettersi. Ma poiché l'HTML di una pagina non deve essere generato al volo, possiamo ottenere un Time To First Byte costantemente veloce. Pertanto, possiamo visualizzare rapidamente una pagina di destinazione e quindi precaricare un framework SPA per le pagine successive. Netflix ha adottato questo approccio diminuendo il caricamento e il Time-to-Interactive del 50%. - Rendering lato server con (ri)idratazione (rendering universale, SSR + CSR)
Possiamo provare a usare il meglio di entrambi i mondi: gli approcci SSR e CSR. Con l'idratazione nel mix, la pagina HTML restituita dal server contiene anche uno script che carica un'applicazione lato client completa. Idealmente, ciò ottenga un rapido First Contentful Paint (come SSR) e quindi continui il rendering con la (ri)idratazione. Sfortunatamente, questo è raramente il caso. Più spesso, la pagina sembra pronta ma non può rispondere all'input dell'utente, producendo clic di rabbia e abbandoni.Con React, possiamo utilizzare il modulo
ReactDOMServersu un server Node come Express, quindi chiamare il metodorenderToStringper eseguire il rendering dei componenti di livello superiore come una stringa HTML statica.Con Vue.js, possiamo utilizzare vue-server-renderer per eseguire il rendering di un'istanza Vue in HTML utilizzando
renderToString. In Angular, possiamo usare@nguniversalper trasformare le richieste dei client in pagine HTML completamente visualizzate dal server. È anche possibile ottenere immediatamente un'esperienza di rendering completamente server con Next.js (React) o Nuxt.js (Vue).L'approccio ha i suoi lati negativi. Di conseguenza, otteniamo la piena flessibilità delle app lato client fornendo al contempo un rendering lato server più veloce, ma finiamo anche con un divario più lungo tra First Contentful Paint e Time To Interactive e un aumento del First Input Delay. La reidratazione è molto costosa e di solito questa strategia da sola non sarà abbastanza buona poiché ritarda pesantemente Time To Interactive.
- Rendering in streaming lato server con idratazione progressiva (SSR + CSR)
Per ridurre al minimo il divario tra Time To Interactive e First Contentful Paint, eseguiamo il rendering di più richieste contemporaneamente e inviamo il contenuto in blocchi man mano che vengono generati. Quindi non dobbiamo aspettare l'intera stringa di HTML prima di inviare contenuto al browser e quindi migliorare Time To First Byte.In React, invece di
renderToString(), possiamo usare renderToNodeStream() per reindirizzare la risposta e inviare l'HTML in blocchi. In Vue, possiamo usare renderToStream() che può essere inviato in pipe e trasmesso in streaming. Con React Suspense, potremmo usare il rendering asincrono anche per questo scopo.Sul lato client, invece di avviare l'intera applicazione in una volta, avviamo i componenti progressivamente . Le sezioni delle applicazioni vengono prima suddivise in script standalone con suddivisione del codice e quindi idratate gradualmente (in base alle nostre priorità). In effetti, possiamo idratare prima i componenti critici, mentre il resto potrebbe essere idratato in seguito. Il ruolo del rendering lato client e lato server può quindi essere definito in modo diverso per componente. Possiamo quindi anche posticipare l'idratazione di alcuni componenti fino a quando non vengono visualizzati, o sono necessari per l'interazione dell'utente, o quando il browser è inattivo.
Per Vue, Markus Oberlehner ha pubblicato una guida sulla riduzione del Time To Interactive delle app SSR utilizzando l'idratazione sull'interazione dell'utente e vue-lazy-hydration, un plug-in in fase iniziale che consente l'idratazione dei componenti sulla visibilità o sull'interazione specifica dell'utente. Il team Angular lavora sull'idratazione progressiva con Ivy Universal. Puoi implementare l'idratazione parziale anche con Preact e Next.js.
- Rendering trisomorfo
Con i service worker attivi, possiamo utilizzare il rendering del server di streaming per le navigazioni iniziali/non JS e quindi fare in modo che il service worker esegua il rendering di HTML per le navigazioni dopo che è stato installato. In tal caso, l'operatore del servizio esegue il prerendering del contenuto e abilita le esplorazioni in stile SPA per il rendering di nuove viste nella stessa sessione. Funziona bene quando puoi condividere lo stesso modello e codice di routing tra il server, la pagina del client e l'operatore del servizio.
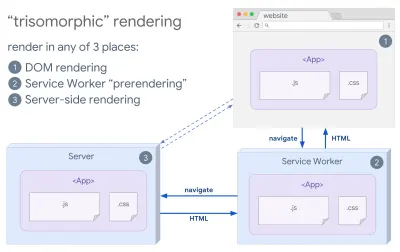
Rendering trisomorfo, con lo stesso rendering del codice in 3 posizioni qualsiasi: sul server, nel DOM o in un service worker. (Fonte immagine: Google Developers) (Anteprima grande) - CSR con prerendering
Il prerendering è simile al rendering lato server, ma anziché eseguire il rendering dinamico delle pagine sul server, eseguiamo il rendering dell'applicazione in HTML statico in fase di compilazione. Sebbene le pagine statiche siano completamente interattive senza molto JavaScript lato client, il prerendering funziona in modo diverso . Fondamentalmente acquisisce lo stato iniziale di un'applicazione lato client come HTML statico in fase di compilazione, mentre con il prerendering l'applicazione deve essere avviata sul client affinché le pagine siano interattive.Con Next.js, possiamo utilizzare l'esportazione HTML statico eseguendo il prerendering di un'app in HTML statico. In Gatsby, un generatore di siti statici open source che utilizza React, utilizza il metodo
renderToStaticMarkupinvece del metodorenderToStringdurante le build, con il blocco JS principale precaricato e le route future vengono precaricate, senza attributi DOM che non sono necessari per semplici pagine statiche.Per Vue, possiamo usare Vuepress per raggiungere lo stesso obiettivo. Puoi anche usare il prerender-loader con Webpack. Navi fornisce anche il rendering statico.
Il risultato è Time To First Byte e First Contentful Paint migliori e riduciamo il divario tra Time To Interactive e First Contentful Paint. Non possiamo usare l'approccio se ci si aspetta che il contenuto cambi molto. Inoltre, tutti gli URL devono essere conosciuti in anticipo per generare tutte le pagine. Quindi alcuni componenti potrebbero essere renderizzati usando il prerendering, ma se abbiamo bisogno di qualcosa di dinamico, dobbiamo fare affidamento sull'app per recuperare il contenuto.
- Rendering completo lato client (CSR)
Tutta la logica, il rendering e l'avvio vengono eseguiti sul client. Il risultato è solitamente un enorme divario tra Time To Interactive e First Contentful Paint. Di conseguenza, le applicazioni spesso sembrano lente poiché l'intera app deve essere avviata sul client per eseguire il rendering di qualsiasi cosa.Poiché JavaScript ha un costo in termini di prestazioni, poiché la quantità di JavaScript cresce con un'applicazione, la suddivisione del codice aggressiva e il rinvio di JavaScript saranno assolutamente necessari per domare l'impatto di JavaScript. In questi casi, un rendering lato server sarà solitamente un approccio migliore nel caso in cui non sia richiesta molta interattività. Se non è un'opzione, prendi in considerazione l'utilizzo di The App Shell Model.
In generale, la SSR è più veloce della CSR. Tuttavia, è un'implementazione abbastanza frequente per molte app là fuori.
Quindi, lato client o lato server? In generale, è una buona idea limitare l'uso di framework completamente lato client alle pagine che li richiedono assolutamente. Per le applicazioni avanzate, non è nemmeno una buona idea affidarsi al solo rendering lato server. Sia il rendering del server che il rendering del client sono un disastro se eseguiti male.
Sia che tu stia propendo per CSR o SSR, assicurati di eseguire il rendering di pixel importanti il prima possibile e di ridurre al minimo il divario tra quel rendering e Time To Interactive. Prendi in considerazione il prerendering se le tue pagine non cambiano molto e rimanda l'avvio dei framework se puoi. Trasmetti in streaming l'HTML in blocchi con il rendering lato server e implementa l'idratazione progressiva per il rendering lato client e idrata la visibilità, l'interazione o durante i tempi di inattività per ottenere il meglio da entrambi i mondi.
- Rendering completo lato server (SSR)

- Quanto possiamo servire staticamente?
Che tu stia lavorando su una grande applicazione o su un piccolo sito, vale la pena considerare quale contenuto potrebbe essere servito staticamente da una CDN (ad esempio JAM Stack), piuttosto che essere generato dinamicamente al volo. Anche se disponi di migliaia di prodotti e centinaia di filtri con numerose opzioni di personalizzazione, potresti comunque voler pubblicare le tue pagine di destinazione critiche in modo statico e separare queste pagine dal framework di tua scelta.Ci sono molti generatori di siti statici e le pagine che generano sono spesso molto veloci. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time . In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times , with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
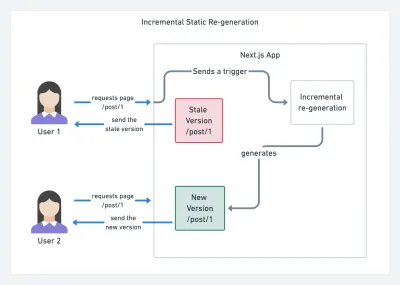
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
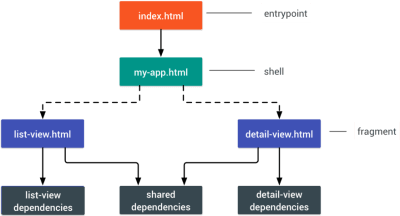
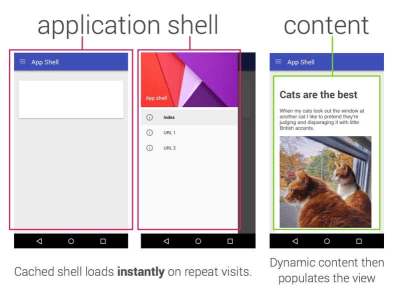
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you'll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints . When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services .As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering . When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request , and the response will be exactly what is required, without over or under -fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google's AMP or Facebook's Instant Articles or Apple's Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance , so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don't necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories , publishers might be moving away from AMP to a traditional stack instead ( thanks, Barry! ).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!) .
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (eg image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN's edge (ie the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN , how to finetune it and all the little things to keep in mind when evaluating one. In general, it's a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note : based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization ( thanks, Barry! ).
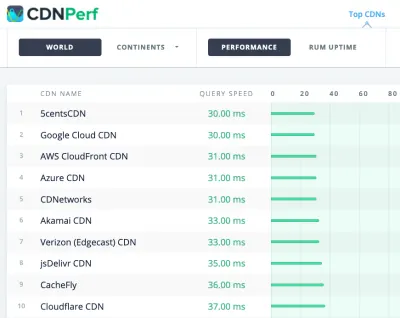
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. (Grande anteprima) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- Confronto CDN, una matrice di confronto CDN per Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai e molti altri.
- CDN Perf misura la velocità delle query per le CDN raccogliendo e analizzando 300 milioni di test ogni giorno, con tutti i risultati basati sui dati RUM di utenti di tutto il mondo. Controlla anche il confronto delle prestazioni DNS e il confronto delle prestazioni del cloud.
- CDN Planet Guides fornisce una panoramica delle CDN per argomenti specifici, come Serve Stale, Purge, Origin Shield, Prefetch e Compression.
- Web Almanac: CDN Adoption and Usage fornisce informazioni dettagliate sui principali provider CDN, sulla loro gestione RTT e TLS, sui tempi di negoziazione TLS, sull'adozione di HTTP/2 e altro. (Purtroppo i dati sono solo del 2019).
Ottimizzazioni degli asset
- Usa Brotli per la compressione del testo normale.
Nel 2015, Google ha introdotto Brotli, un nuovo formato di dati senza perdita di dati open source, che ora è supportato in tutti i browser moderni. La libreria Brotli open source, che implementa un codificatore e un decoder per Brotli, ha 11 livelli di qualità predefiniti per l'encoder, con un livello di qualità superiore che richiede più CPU in cambio di un migliore rapporto di compressione. Una compressione più lenta alla fine porterà a tassi di compressione più elevati, tuttavia Brotli si decomprime rapidamente. Vale la pena notare però che Brotli con il livello di compressione 4 è più piccolo e si comprime più velocemente di Gzip.In pratica, Brotli sembra essere molto più efficace di Gzip. Le opinioni e le esperienze differiscono, ma se il tuo sito è già ottimizzato con Gzip, potresti aspettarti miglioramenti almeno a una cifra e nella migliore delle ipotesi miglioramenti a due cifre nella riduzione delle dimensioni e nei tempi FCP. Puoi anche stimare i risparmi di compressione Brotli per il tuo sito.
I browser accetteranno Brotli solo se l'utente sta visitando un sito Web tramite HTTPS. Brotli è ampiamente supportato e molti CDN lo supportano (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (attualmente solo come pass-through), Cloudflare, CDN77) e puoi abilitare Brotli anche su CDN che non lo supportano ancora (con un addetto ai servizi).
Il problema è che, poiché la compressione di tutte le risorse con Brotli a un livello di compressione elevato è costosa, molti provider di hosting non possono utilizzarlo su vasta scala solo a causa dell'enorme sovraccarico di costi che produce. Infatti, al più alto livello di compressione, Brotli è così lento che qualsiasi potenziale aumento delle dimensioni del file potrebbe essere annullato dal tempo impiegato dal server per iniziare a inviare la risposta mentre attende di comprimere dinamicamente l'asset. (Ma se hai tempo durante il tempo di costruzione con la compressione statica, ovviamente, sono preferibili impostazioni di compressione più elevate.)
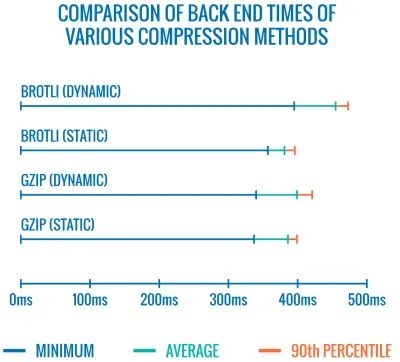
Confronto dei tempi di back-end di vari metodi di compressione. Non sorprende che Brotli sia più lento di gzip (per ora). (Grande anteprima) Questo potrebbe cambiare però. Il formato di file Brotli include un dizionario statico integrato e, oltre a contenere varie stringhe in più lingue, supporta anche l'opzione di applicare più trasformazioni a quelle parole, aumentandone la versatilità. Nella sua ricerca, Felix Hanau ha scoperto un modo per migliorare la compressione ai livelli da 5 a 9 utilizzando "un sottoinsieme del dizionario più specializzato rispetto a quello predefinito" e basandosi sull'intestazione
Content-Typeper dire al compressore se deve utilizzare un dizionario per HTML, JavaScript o CSS. Il risultato è stato un "impatto trascurabile sulle prestazioni (dall'1% al 3% in più di CPU rispetto al 12% normalmente) durante la compressione di contenuti Web a livelli di compressione elevati, utilizzando un approccio di utilizzo limitato del dizionario".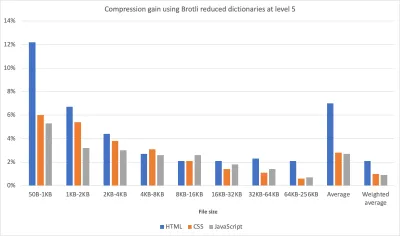
Con l'approccio del dizionario migliorato, possiamo comprimere le risorse più velocemente a livelli di compressione più elevati, il tutto utilizzando solo dall'1% al 3% in più di CPU. Normalmente, il livello di compressione 6 su 5 aumenterebbe l'utilizzo della CPU fino al 12%. (Grande anteprima) Inoltre, con la ricerca di Elena Kirilenko, possiamo ottenere una ricompressione Brotli rapida ed efficiente utilizzando precedenti artefatti di compressione. Secondo Elena, "una volta che abbiamo una risorsa compressa tramite Brotli, e stiamo cercando di comprimere il contenuto dinamico al volo, in cui il contenuto assomiglia a quello a nostra disposizione in anticipo, possiamo ottenere miglioramenti significativi nei tempi di compressione. "
Quante volte è il caso? Ad esempio con la consegna di sottoinsiemi di bundle JavaScript (ad esempio quando parti del codice sono già memorizzate nella cache del client o con bundle dinamici che servono con WebBundles). Oppure con HTML dinamico basato su modelli noti in anticipo o caratteri WOFF2 con sottoinsiemi dinamici . Secondo Elena, possiamo ottenere un miglioramento del 5,3% sulla compressione e del 39% sulla velocità di compressione rimuovendo il 10% del contenuto e tassi di compressione migliori del 3,2% e una compressione più veloce del 26% rimuovendo il 50% del contenuto.
La compressione Brotli sta migliorando, quindi se riesci a bypassare il costo della compressione dinamica delle risorse statiche, ne vale sicuramente la pena. Inutile dire che Brotli può essere utilizzato per qualsiasi payload in testo normale: HTML, CSS, SVG, JavaScript, JSON e così via.
Nota : all'inizio del 2021, circa il 60% delle risposte HTTP viene fornito senza compressione basata su testo, con il 30,82% di compressione con Gzip e il 9,1% di compressione con Brotli (sia su dispositivi mobili che desktop). Ad esempio, il 23,4% delle pagine Angular non viene compresso (tramite gzip o Brotli). Tuttavia, spesso attivare la compressione è una delle vittorie più facili per migliorare le prestazioni con un semplice tocco di un interruttore.
La strategia? Precomprime le risorse statiche con Brotli+Gzip al livello più alto e comprimi l'HTML (dinamico) al volo con Brotli al livello 4–6. Assicurati che il server gestisca correttamente la negoziazione dei contenuti per Brotli o Gzip.
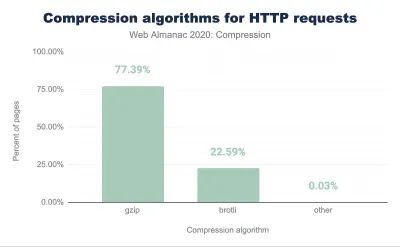
- Utilizziamo il caricamento adattivo dei media e i suggerimenti dei client?
Proviene dalla terra delle vecchie notizie, ma è sempre un buon promemoria per utilizzare immagini reattive consrcset,sizese l'elemento<picture>. Soprattutto per i siti con un elevato ingombro multimediale, possiamo fare un ulteriore passo avanti con il caricamento adattivo dei media (in questo esempio React + Next.js), offrendo un'esperienza leggera a reti lente e dispositivi con memoria insufficiente e un'esperienza completa su reti veloci e -dispositivi di memoria. Nel contesto di React, possiamo ottenerlo con suggerimenti client sul server e hook adattivi di reazione sul client.Il futuro delle immagini reattive potrebbe cambiare radicalmente con l'adozione più ampia dei suggerimenti dei clienti. I suggerimenti del client sono campi di intestazione della richiesta HTTP, ad esempio
DPR,Viewport-Width,Width,Save-Data,Accept(per specificare le preferenze del formato immagine) e altri. Dovrebbero informare il server sulle specifiche del browser, dello schermo, della connessione dell'utente, ecc.Di conseguenza, il server può decidere come riempire il layout con immagini di dimensioni adeguate e servire solo queste immagini nei formati desiderati. Con i suggerimenti per il client, spostiamo la selezione delle risorse dal markup HTML e nella negoziazione richiesta-risposta tra il client e il server.
Servizi multimediali adattivi in uso. Inviamo un segnaposto con testo agli utenti offline, un'immagine a bassa risoluzione agli utenti 2G, un'immagine ad alta risoluzione agli utenti 3G e un video HD agli utenti 4G. Tramite il caricamento rapido di pagine Web su un feature phone da $ 20. (Grande anteprima) Come Ilya Grigorik ha notato tempo fa, i suggerimenti dei clienti completano il quadro: non sono un'alternativa alle immagini reattive. "L'elemento
<picture>fornisce il necessario controllo della direzione artistica nel markup HTML. I suggerimenti del client forniscono annotazioni sulle richieste di immagini risultanti che consentono l'automazione della selezione delle risorse. Service Worker fornisce funzionalità complete di gestione delle richieste e delle risposte sul client".Un addetto al servizio potrebbe, ad esempio, aggiungere nuovi valori di intestazione dei suggerimenti client alla richiesta, riscrivere l'URL e indirizzare la richiesta di immagine a una CDN, adattare la risposta in base alla connettività e alle preferenze dell'utente, ecc. Vale non solo per le risorse immagine, ma praticamente anche per tutte le altre richieste.
Per i client che supportano i suggerimenti client, è possibile misurare un risparmio del 42% di byte sulle immagini e oltre 1 MB di byte in meno per il 70° percentile. Su Smashing Magazine, potremmo anche misurare un miglioramento del 19-32%. I suggerimenti per i client sono supportati nei browser basati su Chromium, ma sono ancora presi in considerazione in Firefox.
Tuttavia, se fornisci sia il normale markup delle immagini reattive che il tag
<meta>per i suggerimenti client, un browser di supporto valuterà il markup delle immagini reattive e richiederà l'origine dell'immagine appropriata utilizzando le intestazioni HTTP dei suggerimenti client. - Usiamo immagini reattive per le immagini di sfondo?
Dovremmo sicuramente! Conimage-set, ora supportato in Safari 14 e nella maggior parte dei browser moderni ad eccezione di Firefox, possiamo offrire anche immagini di sfondo reattive:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);Fondamentalmente possiamo servire in modo condizionale immagini di sfondo a bassa risoluzione con un descrittore
1xe immagini ad alta risoluzione con descrittore2xe persino un'immagine di qualità di stampa con descrittore600dpi. Attenzione però: i browser non forniscono alcuna informazione speciale sulle immagini di sfondo alla tecnologia assistiva, quindi idealmente queste foto sarebbero solo decorazioni. - Usiamo WebP?
La compressione delle immagini è spesso considerata una rapida vittoria, ma nella pratica è ancora fortemente sottoutilizzata. Ovviamente le immagini non bloccano il rendering, ma contribuiscono pesantemente a scarsi punteggi LCP e molto spesso sono semplicemente troppo pesanti e troppo grandi per il dispositivo su cui vengono consumate.Quindi, come minimo, potremmo esplorare utilizzando il formato WebP per le nostre immagini. In effetti, la saga di WebP si è avvicinata alla fine lo scorso anno con Apple che ha aggiunto il supporto per WebP in Safari 14. Quindi, dopo molti anni di discussioni e dibattiti, ad oggi WebP è supportato in tutti i browser moderni. Quindi possiamo fornire immagini WebP con l'elemento
<picture>e un fallback JPEG se necessario (vedi snippet di codice di Andreas Bovens) o utilizzando la negoziazione del contenuto (usando le intestazioniAccept).Tuttavia, WebP non è privo di svantaggi . Sebbene le dimensioni dei file di immagine WebP siano confrontate con gli equivalenti Guetzli e Zopfli, il formato non supporta il rendering progressivo come JPEG, motivo per cui gli utenti potrebbero vedere l'immagine finita più velocemente con un buon vecchio JPEG anche se le immagini WebP potrebbero diventare più veloci attraverso la rete. Con JPEG, possiamo offrire un'esperienza utente "decente" con la metà o addirittura un quarto dei dati e caricare il resto in un secondo momento, piuttosto che avere un'immagine semivuota come nel caso di WebP.
La tua decisione dipenderà da cosa cerchi: con WebP ridurrai il carico utile e con JPEG migliorerai le prestazioni percepite. Puoi saperne di più su WebP in WebP Rewind talk di Pascal Massimino di Google.
Per la conversione in WebP, puoi utilizzare WebP Converter, cwebp o libwebp. Anche Ire Aderinokun ha un tutorial molto dettagliato sulla conversione delle immagini in WebP, così come Josh Comeau nel suo pezzo sull'adozione dei moderni formati di immagine.

Un approfondito talk su WebP: WebP Rewind di Pascal Massimino. (Grande anteprima) Sketch supporta nativamente WebP e le immagini WebP possono essere esportate da Photoshop utilizzando un plug-in WebP per Photoshop. Ma sono disponibili anche altre opzioni.
Se stai utilizzando WordPress o Joomla, ci sono estensioni per aiutarti a implementare facilmente il supporto per WebP, come Optimus e Cache Enabler per WordPress e l'estensione supportata da Joomla (tramite Cody Arsenault). Puoi anche astrarre l'elemento
<picture>con React, componenti in stile o gatsby-image.Ah - spina spudorata! — Jeremy Wagner ha persino pubblicato un libro Smashing su WebP che potresti voler controllare se sei interessato a tutto ciò che riguarda WebP.
- Usiamo AVIF?
Potresti aver sentito la grande novità: l'AVIF è atterrato. È un nuovo formato immagine derivato dai fotogrammi chiave del video AV1. È un formato aperto e privo di royalty che supporta compressione, animazione, canale alfa con perdita e può gestire linee nitide e colori solidi (che era un problema con JPEG), fornendo risultati migliori in entrambi.Infatti, rispetto a WebP e JPEG, AVIF ha prestazioni significativamente migliori , producendo risparmi sulla dimensione media del file fino al 50% con la stessa ((dis)somiglianza DSSIM tra due o più immagini utilizzando un algoritmo che si avvicina alla visione umana). In effetti, nel suo post approfondito sull'ottimizzazione del caricamento delle immagini, Malte Ubl osserva che AVIF "supera costantemente JPEG in modo molto significativo. Questo è diverso da WebP che non produce sempre immagini più piccole di JPEG e potrebbe effettivamente essere un net- perdita per mancanza di supporto per il caricamento progressivo."

Possiamo utilizzare AVIF come miglioramento progressivo, fornendo WebP o JPEG o PNG a browser meno recenti. (Grande anteprima). Vedere la visualizzazione del testo normale di seguito. Ironia della sorte, AVIF può funzionare anche meglio dei grandi SVG, anche se ovviamente non dovrebbe essere visto come un sostituto degli SVG. È anche uno dei primi formati di immagine a supportare il supporto del colore HDR; offrendo maggiore luminosità, profondità di bit di colore e gamme di colori. L'unico aspetto negativo è che attualmente AVIF non supporta la decodifica progressiva delle immagini (ancora?) e, analogamente a Brotli, una codifica ad alto tasso di compressione è attualmente piuttosto lenta, sebbene la decodifica sia veloce.
AVIF è attualmente supportato in Chrome, Firefox e Opera e il supporto in Safari dovrebbe arrivare presto (poiché Apple è un membro del gruppo che ha creato AV1).
Qual è il modo migliore per offrire immagini in questi giorni , allora? Per illustrazioni e immagini vettoriali, SVG (compresso) è senza dubbio la scelta migliore. Per le foto, utilizziamo metodi di negoziazione dei contenuti con l'elemento
picture. Se l'AVIF è supportato, inviamo un'immagine AVIF; in caso contrario, torniamo prima a WebP e, se anche WebP non è supportato, passiamo a JPEG o PNG come fallback (applicando le condizioni@mediase necessario):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Francamente, è più probabile che utilizzeremo alcune condizioni all'interno dell'elemento
picture:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Puoi andare ancora oltre scambiando immagini animate con immagini statiche per i clienti che optano per meno movimento con
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>Nel corso dei due mesi, AVIF ha guadagnato terreno:
- Possiamo testare i fallback WebP/AVIF nel pannello Rendering in DevTools.
- Possiamo usare Squoosh, AVIF.io e libavif per codificare, decodificare, comprimere e convertire file AVIF.
- Possiamo usare il componente AVIF Preact di Jake Archibald che decodifica un file AVIF in un lavoratore e visualizza il risultato su una tela,
- Per fornire AVIF solo ai browser di supporto, possiamo utilizzare un plug-in PostCSS insieme a uno script 315B per utilizzare AVIF nelle dichiarazioni CSS.
- Siamo in grado di fornire progressivamente nuovi formati di immagine con CSS e Cloudlare Workers per alterare dinamicamente il documento HTML restituito, deducendo le informazioni dall'intestazione di
accepte quindi aggiungere lewebp/avifecc. a seconda dei casi. - AVIF è già disponibile in Cloudinary (con limiti di utilizzo), Cloudflare supporta AVIF in Image Resizing e puoi abilitare AVIF con intestazioni AVIF personalizzate in Netlify.
- Quando si tratta di animazione, AVIF si comporta così come
<img src=mp4>di Safari, superando GIF e WebP in generale, ma MP4 ha comunque prestazioni migliori. - In generale, per le animazioni, AVC1 (h264) > HVC1 > WebP > AVIF > GIF, supponendo che i browser basati su Chromium supportino sempre
<img src=mp4>. - Puoi trovare maggiori dettagli su AVIF in AVIF per il discorso sulla codifica delle immagini di nuova generazione di Aditya Mavlankar da Netflix e nel discorso sul formato immagine AVIF di Kornel Lesinski di Cloudflare.
- Un ottimo riferimento per tutto AVIF: il post completo di Jake Archibald su AVIF è arrivato.
Quindi il futuro AVIF è allora ? Jon Sneyers non è d'accordo: AVIF ha prestazioni peggiori del 60% rispetto a JPEG XL, un altro formato gratuito e aperto sviluppato da Google e Cloudinary. In effetti, JPEG XL sembra funzionare molto meglio su tutta la linea. Tuttavia, JPEG XL è ancora solo nelle fasi finali della standardizzazione e non funziona ancora in nessun browser. (Da non confondere con il JPEG-XR di Microsoft proveniente dal buon vecchio Internet Explorer 9 volte).
- I file JPEG/PNG/SVG sono ottimizzati correttamente?
Quando lavori su una pagina di destinazione in cui è fondamentale che l'immagine di un eroe si carichi in modo incredibilmente veloce, assicurati che i JPEG siano progressivi e compressi con mozJPEG (che migliora il tempo di rendering iniziale manipolando i livelli di scansione) o Guetzli, l'open source di Google codificatore incentrato sulle prestazioni percettive e sull'utilizzo degli apprendimenti di Zopfli e WebP. L'unico aspetto negativo: tempi di elaborazione lenti (un minuto di CPU per megapixel).Per PNG possiamo usare Pingo e per SVG possiamo usare SVGO o SVGOMG. E se hai bisogno di visualizzare in anteprima e copiare o scaricare rapidamente tutte le risorse SVG da un sito Web, svg-grabber può farlo anche per te.
Ogni singolo articolo sull'ottimizzazione delle immagini lo direbbe, ma vale sempre la pena ricordare di mantenere le risorse vettoriali pulite e compatte. Assicurati di ripulire le risorse inutilizzate, rimuovere i metadati non necessari e ridurre il numero di punti di percorso nella grafica (e quindi il codice SVG). ( Grazie, Jeremy! )
Ci sono anche utili strumenti online disponibili però:
- Usa Squoosh per comprimere, ridimensionare e manipolare le immagini ai livelli di compressione ottimali (lossy o lossless),
- Usa Guetzli.it per comprimere e ottimizzare le immagini JPEG con Guetzli, che funziona bene per immagini con bordi netti e colori solidi (ma potrebbe essere un po' più lento)).
- Utilizza Responsive Image Breakpoints Generator o un servizio come Cloudinary o Imgix per automatizzare l'ottimizzazione delle immagini. Inoltre, in molti casi, l'utilizzo
srcsetesizesda solo raccoglierà vantaggi significativi. - Per verificare l'efficienza del tuo markup reattivo, puoi utilizzare imaging-heap, uno strumento a riga di comando che misura l'efficienza tra le dimensioni del viewport e i rapporti pixel del dispositivo.
- Puoi aggiungere la compressione automatica delle immagini ai tuoi flussi di lavoro GitHub, in modo che nessuna immagine possa raggiungere la produzione non compressa. L'azione utilizza mozjpeg e libvips che funzionano con PNG e JPG.
- Per ottimizzare l'archiviazione internamente, puoi utilizzare il nuovo formato Lepton di Dropbox per comprimere i file JPEG senza perdite di una media del 22%.
- Usa BlurHash se desideri mostrare un'immagine segnaposto in anticipo. BlurHash prende un'immagine e ti dà una breve stringa (solo 20-30 caratteri!) che rappresenta il segnaposto per questa immagine. La stringa è abbastanza corta da poter essere facilmente aggiunta come campo in un oggetto JSON.
BlurHash è una rappresentazione minuscola e compatta di un segnaposto per un'immagine. (Grande anteprima) A volte l'ottimizzazione delle immagini da sola non basta. Per migliorare il tempo necessario per avviare il rendering di un'immagine critica, carica in modo lazy le immagini meno importanti e rinvia gli script da caricare dopo che le immagini critiche sono già state renderizzate. Il modo più a prova di proiettile è il lazy-loading ibrido, quando utilizziamo il lazy-loading e lazyload nativi, una libreria che rileva eventuali modifiche alla visibilità attivate dall'interazione dell'utente (con IntersectionObserver che esploreremo in seguito). Inoltre:
- Prendi in considerazione il precaricamento delle immagini critiche, in modo che un browser non le scopra troppo tardi. Per le immagini di sfondo, se vuoi essere ancora più aggressivo, puoi aggiungere l'immagine come un'immagine normale con
<img src>, quindi nasconderla dallo schermo. - Considerare lo scambio di immagini con l'attributo Dimensioni specificando diverse dimensioni di visualizzazione dell'immagine a seconda delle query multimediali, ad esempio per manipolare le
sizesper scambiare le sorgenti in un componente lente di ingrandimento. - Esamina le incoerenze di download delle immagini per evitare download imprevisti per le immagini in primo piano e di sfondo. Fai attenzione alle immagini che vengono caricate per impostazione predefinita, ma potrebbero non essere mai visualizzate, ad esempio nei caroselli, nelle fisarmoniche e nelle gallerie di immagini.
- Assicurati di impostare sempre
widtheheightsulle immagini. Fai attenzione alla proprietàaspect-ratioin CSS e all'attributointrinsicsizeche ci consentirà di impostare proporzioni e dimensioni per le immagini, in modo che il browser possa riservare uno slot di layout predefinito in anticipo per evitare salti di layout durante il caricamento della pagina.
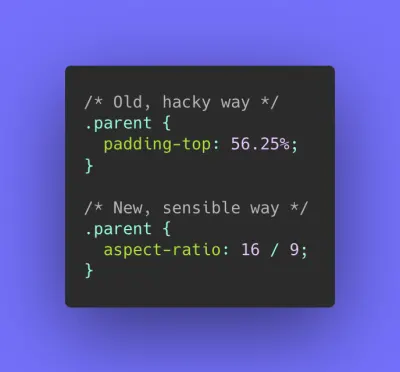
Dovrebbe essere solo questione di settimane o mesi ora, con le proporzioni che atterrano nei browser. Già in Safari Technical Preview 118. Attualmente dietro la bandiera in Firefox e Chrome. (Grande anteprima) Se ti senti avventuroso, puoi tagliare e riorganizzare i flussi HTTP/2 utilizzando Edge worker, fondamentalmente un filtro in tempo reale che vive sulla CDN, per inviare immagini più velocemente attraverso la rete. I lavoratori perimetrali utilizzano flussi JavaScript che utilizzano blocchi che puoi controllare (in pratica sono JavaScript che vengono eseguiti sul bordo CDN che possono modificare le risposte di streaming), in modo da poter controllare la consegna delle immagini.
Con un addetto ai servizi, è troppo tardi perché non puoi controllare cosa c'è sul cavo, ma funziona con i lavoratori Edge. Quindi puoi usarli sopra i JPEG statici salvati progressivamente per una particolare pagina di destinazione.
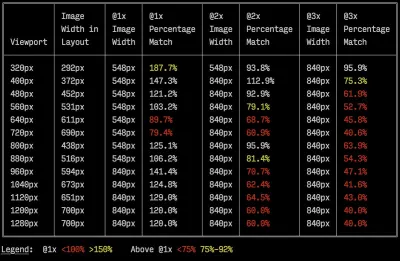
Un output di esempio di imaging-heap, uno strumento a riga di comando che misura l'efficienza tra le dimensioni del viewport e i rapporti pixel del dispositivo. (Fonte immagine) (Anteprima grande) Non buono abbastanza? Bene, puoi anche migliorare le prestazioni percepite per le immagini con la tecnica delle immagini di sfondo multiple. Tieni presente che giocare con il contrasto e sfocare i dettagli non necessari (o rimuovere i colori) può anche ridurre le dimensioni del file. Ah, devi ingrandire una piccola foto senza perdere in qualità? Prendi in considerazione l'utilizzo di Letsenhance.io.
Queste ottimizzazioni finora coprono solo le basi. Addy Osmani ha pubblicato una guida molto dettagliata sull'ottimizzazione dell'immagine essenziale che approfondisce i dettagli della compressione dell'immagine e della gestione del colore. Ad esempio, potresti sfocare parti non necessarie dell'immagine (applicando loro un filtro sfocatura gaussiana) per ridurre le dimensioni del file e alla fine potresti persino iniziare a rimuovere i colori o trasformare l'immagine in bianco e nero per ridurre ulteriormente le dimensioni . Per le immagini di sfondo, anche l'esportazione di foto da Photoshop con una qualità dallo 0 al 10% può essere assolutamente accettabile.
Su Smashing Magazine, utilizziamo il suffisso
-optper i nomi delle immagini, ad esempiobrotli-compression-opt.png; ogni volta che un'immagine contiene quel suffisso, tutti nel team sanno che l'immagine è già stata ottimizzata.Ah, e non utilizzare JPEG-XR sul Web: "l'elaborazione della decodifica di JPEG-XR lato software sulla CPU annulla e addirittura supera l'impatto potenzialmente positivo del risparmio di dimensioni dei byte, specialmente nel contesto delle SPA" (non da confondere con Cloudinary/JPEG XL di Google però).

- I video sono ottimizzati correttamente?
Finora abbiamo trattato le immagini, ma abbiamo evitato una conversazione sulle buone vecchie GIF. Nonostante il nostro amore per le GIF, è davvero il momento di abbandonarle per sempre (almeno nei nostri siti Web e app). Invece di caricare GIF animate pesanti che influiscono sia sulle prestazioni di rendering che sulla larghezza di banda, è una buona idea passare a WebP animato (con GIF come fallback) o sostituirle con video HTML5 in loop del tutto.A differenza delle immagini, i browser non precaricano il contenuto
<video>, ma i video HTML5 tendono ad essere molto più leggeri e più piccoli delle GIF. Non è un'opzione? Bene, almeno possiamo aggiungere una compressione con perdita di dati alle GIF con Lossy GIF, gifsicle o giflossy.I test di Colin Bendell mostrano che i video inline all'interno dei tag
imgin Safari Technology Preview vengono visualizzati almeno 20 volte più velocemente e decodificano 7 volte più velocemente dell'equivalente GIF, oltre ad essere una frazione delle dimensioni del file. Tuttavia, non è supportato in altri browser.Nella terra delle buone notizie, i formati video sono progrediti enormemente nel corso degli anni. Per molto tempo abbiamo sperato che WebM diventasse il formato per dominarli tutti e WebP (che è fondamentalmente un'immagine fissa all'interno del contenitore video WebM) diventasse un sostituto per formati di immagine datati. In effetti, Safari ora supporta WebP, ma nonostante WebP e WebM abbiano ottenuto supporto in questi giorni, la svolta in realtà non è avvenuta.
Tuttavia, potremmo utilizzare WebM per la maggior parte dei browser moderni disponibili:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Ma forse potremmo rivisitarlo del tutto. Nel 2018, l'Alliance of Open Media ha rilasciato un nuovo promettente formato video chiamato AV1 . AV1 ha una compressione simile al codec H.265 (l'evoluzione di H.264) ma a differenza di quest'ultimo, AV1 è gratuito. Il prezzo della licenza H.265 ha spinto i fornitori di browser ad adottare invece un AV1 con prestazioni comparabili: AV1 (proprio come H.265) si comprime due volte meglio di WebM .

AV1 ha buone possibilità di diventare lo standard definitivo per i video sul web. (Credito immagine: Wikimedia.org) (Anteprima grande) In effetti, Apple attualmente utilizza il formato HEIF e HEVC (H.265) e tutte le foto e i video sull'ultimo iOS vengono salvati in questi formati, non JPEG. Sebbene HEIF e HEVC (H.265) non siano adeguatamente esposti al Web (ancora?), AV1 lo è e sta ottenendo il supporto del browser. Quindi aggiungere la sorgente
AV1nel tag<video>è ragionevole, poiché tutti i fornitori di browser sembrano essere d'accordo.Per ora, la codifica più utilizzata e supportata è H.264, servita da file MP4, quindi prima di servire il file, assicurati che i tuoi MP4 siano elaborati con una codifica multipass, sfocata con l'effetto frei0r iirblur (se applicabile) e I metadati di moov atom vengono spostati nella parte iniziale del file, mentre il tuo server accetta la pubblicazione di byte. Boris Schapira fornisce istruzioni esatte per FFmpeg per ottimizzare i video al massimo. Naturalmente, anche fornire il formato WebM in alternativa aiuterebbe.
Devi iniziare a eseguire il rendering dei video più velocemente ma i file video sono ancora troppo grandi ? Ad esempio, ogni volta che hai un video di sfondo di grandi dimensioni su una pagina di destinazione? Una tecnica comune da utilizzare consiste nel mostrare prima il primo fotogramma come immagine fissa, oppure visualizzare un breve segmento di loop fortemente ottimizzato che potrebbe essere interpretato come parte del video, quindi, ogni volta che il video è sufficientemente bufferizzato, avviare la riproduzione il video vero e proprio. Doug Sillars ha scritto una guida dettagliata alle prestazioni dei video in background che potrebbe essere utile in questo caso. ( Grazie, Guy Podjarny! ).
Per lo scenario precedente, potresti voler fornire immagini poster reattive . Per impostazione predefinita, gli elementi
videoconsentono solo un'immagine come poster, il che non è necessariamente ottimale. Possiamo utilizzare Responsive Video Poster, una libreria JavaScript che ti consente di utilizzare immagini poster diverse per schermi diversi, aggiungendo anche una sovrapposizione di transizione e un controllo completo dello stile dei segnaposto video.La ricerca mostra che la qualità del flusso video influisce sul comportamento degli spettatori. Infatti, gli spettatori iniziano ad abbandonare il video se il ritardo di avvio supera i 2 secondi circa. Oltre tale punto, un aumento di 1 secondo del ritardo si traduce in un aumento di circa il 5,8% del tasso di abbandono. Quindi non sorprende che l'ora mediana di inizio del video sia 12,8 secondi, con il 40% dei video con almeno 1 stallo e il 20% almeno 2 secondi di riproduzione video bloccata. In effetti, gli stalli video sono inevitabili su 3G poiché i video vengono riprodotti più velocemente di quanto la rete possa fornire contenuti.
Allora, qual è la soluzione? Di solito i dispositivi con schermo piccolo non sono in grado di gestire i 720p e i 1080p che stiamo servendo sul desktop. Secondo Doug Sillars, possiamo creare versioni più piccole dei nostri video e utilizzare Javascript per rilevare la fonte per schermi più piccoli per garantire una riproduzione veloce e fluida su questi dispositivi. In alternativa, possiamo utilizzare lo streaming video. I flussi video HLS forniranno un video di dimensioni adeguate al dispositivo, eliminando la necessità di creare video diversi per schermi diversi. Negozierà anche la velocità della rete e adatterà il bitrate video alla velocità della rete che stai utilizzando.
Per evitare lo spreco di larghezza di banda, potremmo aggiungere la sorgente video solo per i dispositivi che effettivamente possono riprodurre bene il video. In alternativa, possiamo rimuovere del tutto l'attributo di riproduzione
autoplaydal tagvideoe utilizzare JavaScript per inserire laautoplayper schermi più grandi. Inoltre, dobbiamo aggiungerepreload="none"sulvideoper dire al browser di non scaricare nessuno dei file video fino a quando non ha effettivamente bisogno del file:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Quindi possiamo indirizzare specificamente i browser che supportano effettivamente AV1:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Potremmo quindi aggiungere nuovamente l'
autoplayoltre una certa soglia (es. 1000px):/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>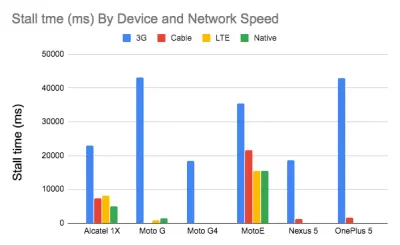
Numero di stalli per dispositivo e velocità di rete. I dispositivi più veloci su reti più veloci non hanno praticamente stalli. Secondo la ricerca di Doug Sillars. (Grande anteprima) Le prestazioni di riproduzione video sono una storia a sé stante e, se desideri approfondire i dettagli, dai un'occhiata a un'altra serie di Doug Sillars su The Current State of Video and Video Delivery Best Practices che include dettagli sulle metriche di consegna video , precaricamento, compressione e streaming video. Infine, puoi verificare quanto sarà lento o veloce il tuo streaming video con Stream or Not.
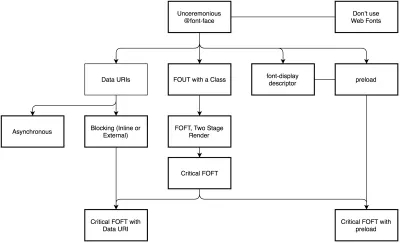
- La consegna dei caratteri web è ottimizzata?
The first question that's worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it's not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren't being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Muller's subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don't support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman's "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don't need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies, "resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint." Otherwise, font loading will cost you in the first render time.
When everything is critical, nothing is critical. preload only one or a maximum of two fonts of each family. (Image credit: Zach Leatherman – slide 93) (Large preview) It's a good idea to be selective and choose files that matter most, eg the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn't need to download the web font and can display the local font immediately. As Bram Stein noted, "though a local font matches the name of a web font, it most likely isn't the same font . Many web fonts differ from their "desktop" version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different."
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it's better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it's a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we'd creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach's explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.
Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it's always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it's not possible, you can perhaps proxy the Google Font files through the page origin.

It's worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays ( thanks, Barry! )
This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can't be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.
But if it's not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts' snippet:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harry's strategy is to pre-emptively warm up the fonts' origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it's arrived (with a print stylesheet trick). Finally, if JavaScript isn't supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.Una breve parola di cautela però. Se utilizzi
font-display: optional, potrebbe non essere ottimale utilizzare anche ilpreloadin quanto attiverà in anticipo la richiesta di font Web (causando una congestione della rete se hai altre risorse di percorso critiche che devono essere recuperate). Usapreconnectper richieste di font tra origini più veloci, ma fai attenzione con ilpreloadpoiché il precaricamento dei font da un'origine diversa comporterà conflitti di rete. Tutte queste tecniche sono trattate nelle ricette di caricamento dei caratteri Web di Zach.D'altra parte, potrebbe essere una buona idea disattivare i caratteri Web (o almeno il rendering della seconda fase) se l'utente ha abilitato Riduci movimento nelle preferenze di accessibilità o ha optato per la modalità Risparmio dati (vedi intestazione
Save-Data) o quando l'utente ha una connettività lenta (tramite Network Information API).Possiamo anche utilizzare la query multimediale CSS
prefers-reduced-dataper non definire le dichiarazioni dei caratteri se l'utente ha attivato la modalità di salvataggio dei dati (ci sono anche altri casi d'uso). La query multimediale mostrerebbe sostanzialmente se l'intestazione della richiestaSave-Datadall'estensione HTTP Hint client è attivata/disattivata per consentire l'utilizzo con CSS. Attualmente supportato solo in Chrome e Edge dietro una bandiera.Metrica? Per misurare le prestazioni di caricamento dei caratteri Web, considera la metrica Tutto il testo visibile (il momento in cui tutti i caratteri sono stati caricati e tutto il contenuto viene visualizzato nei caratteri Web), Tempo per il corsivo reale e Conteggio riflusso dei caratteri Web dopo il primo rendering. Ovviamente, più basse sono entrambe le metriche, migliori saranno le prestazioni.
Che dire dei caratteri variabili , potresti chiedere? È importante notare che i caratteri variabili potrebbero richiedere una considerazione significativa delle prestazioni. Ci danno uno spazio di progettazione molto più ampio per le scelte tipografiche, ma viene al costo di una singola richiesta seriale rispetto a un numero di richieste di file individuali.
Sebbene i caratteri variabili riducano drasticamente le dimensioni complessive dei file di caratteri combinati, quella singola richiesta potrebbe essere lenta, bloccando il rendering di tutto il contenuto di una pagina. Quindi il sottoinsieme e la divisione del carattere in set di caratteri sono ancora importanti. Tra i lati positivi, tuttavia, con un carattere variabile in atto, otterremo esattamente un reflow per impostazione predefinita, quindi non sarà richiesto JavaScript per raggruppare i ridisegni.
Ora, cosa renderebbe allora una strategia di caricamento dei font web a prova di proiettile ? Sottoimposta i caratteri e preparali per il rendering in 2 fasi, dichiarali con un descrittore
font-display, utilizza l'API di caricamento dei caratteri per raggruppare i ridisegni e archiviare i caratteri nella cache di un lavoratore del servizio permanente. Alla prima visita, iniettare il precaricamento degli script appena prima degli script esterni di blocco. Se necessario, potresti ricorrere a Font Face Observer di Bram Stein. E se sei interessato a misurare le prestazioni del caricamento dei caratteri, Andreas Marschke esplora il monitoraggio delle prestazioni con l'API dei caratteri e l'API UserTiming.Infine, non dimenticare di includere
unicode-rangeper scomporre un carattere grande in caratteri più piccoli specifici della lingua e utilizzare il corrispettivo dello stile dei caratteri di Monica Dinculescu per ridurre al minimo uno spostamento stridente nel layout, a causa delle discrepanze di dimensioni tra il fallback e il caratteri web.In alternativa, per emulare un font web per un font di fallback, possiamo usare i descrittori @font-face per sovrascrivere le metriche dei font (demo, abilitato in Chrome 87). (Si noti che le regolazioni sono complicate con pile di caratteri complicate.)
Il futuro sembra luminoso? Con l'arricchimento progressivo dei caratteri, alla fine potremmo essere in grado di "scaricare solo la parte richiesta del carattere su una determinata pagina e, per le successive richieste di quel carattere, "rattoppare" dinamicamente il download originale con set aggiuntivi di glifi come richiesto nella pagina successiva visualizzazioni", come spiega Jason Pamental. La demo di trasferimento incrementale è già disponibile ed è in lavorazione.
Costruisci ottimizzazioni
- Abbiamo definito le nostre priorità?
È una buona idea sapere prima con cosa hai a che fare. Esegui un inventario di tutte le tue risorse (JavaScript, immagini, caratteri, script di terze parti e moduli "costosi" sulla pagina, come caroselli, infografiche complesse e contenuti multimediali) e suddividili in gruppi.Imposta un foglio di calcolo . Definisci l'esperienza di base di base per i browser legacy (ovvero il contenuto di base completamente accessibile), l'esperienza avanzata per i browser abilitati (ovvero un'esperienza completa e arricchita) e gli extra (risorse che non sono assolutamente necessarie e possono essere caricate in modo pigro, come font web, stili non necessari, script di carosello, lettori video, widget di social media, immagini di grandi dimensioni). Anni fa, abbiamo pubblicato un articolo su "Improving Smashing Magazine's Performance", che descrive questo approccio in dettaglio.
Quando ottimizziamo le prestazioni, dobbiamo riflettere le nostre priorità. Carica immediatamente l' esperienza principale , poi i miglioramenti e poi gli extra .
- Utilizzi moduli JavaScript nativi in produzione?
Ricordi la buona vecchia tecnica del taglio della senape per inviare l'esperienza di base ai browser legacy e un'esperienza migliorata ai browser moderni? Una variante aggiornata della tecnica potrebbe utilizzare ES2017+<script type="module">, noto anche come pattern module/nomodule (introdotto anche da Jeremy Wagner come servizio differenziale ).L'idea è di compilare e servire due bundle JavaScript separati : la build "normale", quella con Babel-transforms e polyfill e servirli solo ai browser legacy che ne hanno effettivamente bisogno, e un altro bundle (stessa funzionalità) che non ha trasformazioni o poliriempimenti.
Di conseguenza, aiutiamo a ridurre il blocco del thread principale riducendo la quantità di script che il browser deve elaborare. Jeremy Wagner ha pubblicato un articolo completo sul servizio differenziale e su come configurarlo nella pipeline di compilazione, dall'impostazione di Babel, alle modifiche che dovrai apportare in Webpack, nonché ai vantaggi di fare tutto questo lavoro.
Gli script dei moduli JavaScript nativi sono posticipati per impostazione predefinita, quindi mentre è in corso l'analisi HTML, il browser scaricherà il modulo principale.

I moduli JavaScript nativi sono posticipati per impostazione predefinita. Praticamente tutto sui moduli JavaScript nativi. (Grande anteprima) Una nota di avvertimento però: il pattern module/nomodule può ritorcersi contro alcuni client, quindi potresti prendere in considerazione una soluzione alternativa: il pattern di servizio differenziale meno rischioso di Jeremy che, tuttavia, elude lo scanner di precaricamento, che potrebbe influire sulle prestazioni in modi che non si potrebbero anticipare. ( grazie, Jeremy! )
In effetti, Rollup supporta i moduli come formato di output, quindi possiamo sia raggruppare il codice che distribuire i moduli in produzione. Parcel ha il supporto del modulo in Parcel 2. Per Webpack, module-nomodule-plugin automatizza la generazione di script module/nomodule.
Nota : vale la pena affermare che il rilevamento delle funzionalità da solo non è sufficiente per prendere una decisione informata sul carico utile da spedire a quel browser. Di per sé, non possiamo dedurre la capacità del dispositivo dalla versione del browser. Ad esempio, i telefoni Android economici nei paesi in via di sviluppo eseguono principalmente Chrome e ridurranno la senape nonostante la memoria limitata e le capacità della CPU.
Alla fine, utilizzando l'intestazione dei suggerimenti del client di memoria del dispositivo, saremo in grado di indirizzare i dispositivi di fascia bassa in modo più affidabile. Al momento della scrittura, l'intestazione è supportata solo in Blink (vale per i suggerimenti del cliente in generale). Poiché Device Memory ha anche un'API JavaScript disponibile in Chrome, un'opzione potrebbe essere quella di rilevare funzionalità in base all'API e tornare al pattern module/nomodule se non è supportato ( grazie, Yoav! ).
- Stai usando lo scuotimento degli alberi, il sollevamento del cannocchiale e la suddivisione del codice?
Il tree-shaking è un modo per ripulire il processo di compilazione includendo solo il codice effettivamente utilizzato nella produzione ed eliminando le importazioni inutilizzate in Webpack. Con Webpack e Rollup, abbiamo anche il sollevamento dell'ambito che consente a entrambi gli strumenti di rilevare dove il concatenamento diimportpuò essere appiattito e convertito in una funzione inline senza compromettere il codice. Con Webpack, possiamo anche utilizzare JSON Tree Shaking.La suddivisione del codice è un'altra funzionalità di Webpack che suddivide la base di codice in "blocchi" caricati su richiesta. Non tutto JavaScript deve essere scaricato, analizzato e compilato subito. Una volta definiti i punti di divisione nel codice, Webpack può occuparsi delle dipendenze e dei file prodotti. Ti consente di mantenere piccolo il download iniziale e di richiedere il codice su richiesta quando richiesto dall'applicazione. Alexander Kondrov ha una fantastica introduzione alla divisione del codice con Webpack e React.
Prendi in considerazione l'utilizzo di preload-webpack-plugin che prende le rotte suddivise in codice e quindi richiede al browser di precaricarle utilizzando
<link rel="preload">o<link rel="prefetch">. Le direttive inline di Webpack danno anche un certo controllo supreload/prefetch. (Fai attenzione ai problemi di priorità.)Dove definire i punti di divisione? Tracciando quali blocchi di CSS/JavaScript vengono utilizzati e quali non vengono utilizzati. Umar Hansa spiega come utilizzare la copertura del codice di Devtools per ottenerlo.
Quando si tratta di applicazioni a pagina singola, è necessario del tempo per inizializzare l'app prima di poter eseguire il rendering della pagina. La tua impostazione richiederà la tua soluzione personalizzata, ma potresti fare attenzione a moduli e tecniche per accelerare il tempo di rendering iniziale. Ad esempio, ecco come eseguire il debug delle prestazioni di React ed eliminare i problemi comuni di prestazioni di React, ed ecco come migliorare le prestazioni in Angular. In generale, la maggior parte dei problemi di prestazioni deriva dall'avvio iniziale dell'app.
Quindi, qual è il modo migliore per dividere il codice in modo aggressivo, ma non troppo aggressivo? Secondo Phil Walton, "oltre alla suddivisione del codice tramite importazioni dinamiche, [potremmo] anche utilizzare la suddivisione del codice a livello di pacchetto , in cui ogni modulo del nodo importato viene inserito in un blocco in base al nome del pacchetto". Phil fornisce anche un tutorial su come costruirlo.
- Possiamo migliorare l'output di Webpack?
Poiché Webpack è spesso considerato misterioso, ci sono molti plug-in Webpack che possono tornare utili per ridurre ulteriormente l'output di Webpack. Di seguito sono riportati alcuni di quelli più oscuri che potrebbero richiedere un po' più di attenzione.Uno di quelli interessanti viene dal thread di Ivan Akulov. Immagina di avere una funzione che chiami una volta, memorizzi il suo risultato in una variabile e quindi non usi quella variabile. Lo scuotimento dell'albero rimuoverà la variabile, ma non la funzione, perché potrebbe essere utilizzata diversamente. Tuttavia, se la funzione non viene utilizzata da nessuna parte, potresti volerla rimuovere. Per fare ciò, anteponi la chiamata alla funzione con
/*#__PURE__*/che è supportata da Uglify e Terser — fatto!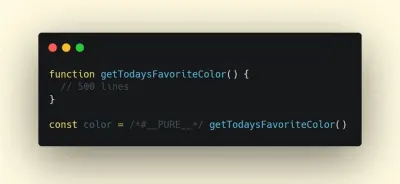
Per rimuovere una tale funzione quando il suo risultato non viene utilizzato, anteporre la chiamata alla funzione con /*#__PURE__*/. Via Ivan Akulov.(Grande anteprima)Ecco alcuni degli altri strumenti che Ivan consiglia:
- purgecss-webpack-plugin rimuove le classi non utilizzate, specialmente quando si utilizza Bootstrap o Tailwind.
- Abilita
optimization.splitChunks: 'all'con split-chunks-plugin. Ciò renderebbe webpack automaticamente diviso in codice i tuoi bundle di voci per una migliore memorizzazione nella cache. - Imposta
optimization.runtimeChunk: true. Ciò sposterebbe il runtime del webpack in un blocco separato e migliorerebbe anche la memorizzazione nella cache. - google-fonts-webpack-plugin scarica i file dei caratteri, così puoi servirli dal tuo server.
- workbox-webpack-plugin ti consente di generare un service worker con una configurazione di precaching per tutte le tue risorse webpack. Inoltre, controlla i pacchetti Service Worker, una guida completa di moduli che potrebbero essere applicati immediatamente. Oppure usa preload-webpack-plugin per generare
preload/prefetchper tutti i blocchi JavaScript. - speed-measure-webpack-plugin misura la velocità di compilazione del tuo webpack, fornendo informazioni dettagliate su quali fasi del processo di compilazione richiedono più tempo.
- duplicate-package-checker-webpack-plugin avverte quando il pacchetto contiene più versioni dello stesso pacchetto.
- Usa l'isolamento dell'ambito e abbrevia i nomi delle classi CSS in modo dinamico al momento della compilazione.
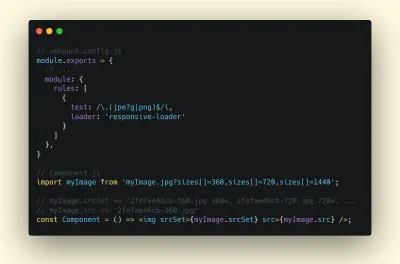
- Puoi scaricare JavaScript in un Web Worker?
Per ridurre l'impatto negativo su Time-to-Interactive, potrebbe essere una buona idea esaminare l'offload di JavaScript pesante in un Web Worker.Man mano che la base di codice continua a crescere, i colli di bottiglia delle prestazioni dell'interfaccia utente verranno visualizzati, rallentando l'esperienza dell'utente. Questo perché le operazioni DOM vengono eseguite insieme al tuo JavaScript sul thread principale. Con i web worker, possiamo spostare queste costose operazioni in un processo in background in esecuzione su un thread diverso. I casi d'uso tipici per i lavoratori Web sono il precaricamento dei dati e le app Web progressive per caricare e archiviare alcuni dati in anticipo in modo da poterli utilizzare in seguito quando necessario. E potresti usare Comlink per semplificare la comunicazione tra la pagina principale e il lavoratore. Ancora un po' di lavoro da fare, ma ci stiamo arrivando.
Ci sono alcuni casi di studio interessanti sui web worker che mostrano diversi approcci per spostare la logica del framework e delle app ai web worker. La conclusione: in generale, ci sono ancora alcune sfide, ma ci sono già dei buoni casi d'uso ( grazie, Ivan Akulov! ).
A partire da Chrome 80, è stata lanciata una nuova modalità per i web worker con i vantaggi in termini di prestazioni dei moduli JavaScript, denominata module worker. Possiamo modificare il caricamento e l'esecuzione degli script in modo che corrispondano allo
script type="module", inoltre possiamo anche utilizzare le importazioni dinamiche per il caricamento lento del codice senza bloccare l'esecuzione del lavoratore.Come iniziare? Ecco alcune risorse che vale la pena esaminare:
- Surma ha pubblicato un'eccellente guida su come eseguire JavaScript dal thread principale del browser e anche Quando dovresti usare i Web Workers?
- Inoltre, controlla i discorsi di Surma sull'architettura del thread principale.
- A Quest to Guarantee Responsiveness di Shubhie Panicker e Jason Miller forniscono informazioni dettagliate su come utilizzare i web worker e quando evitarli.
- Uscire dagli utenti: meno lavoro con i lavoratori Web mette in evidenza modelli utili per lavorare con i lavoratori Web, modi efficaci per comunicare tra lavoratori, gestire l'elaborazione di dati complessi fuori dal thread principale, testarli ed eseguirne il debug.
- Workerize consente di spostare un modulo in un Web Worker, riflettendo automaticamente le funzioni esportate come proxy asincroni.
- Se stai usando Webpack, puoi usare workerize-loader. In alternativa, puoi usare anche worker-plugin.

Usa i web worker quando il codice si blocca per molto tempo, ma evitali quando ti affidi al DOM, gestisci la risposta all'input e hai bisogno di un ritardo minimo. (via Addy Osmani) (Anteprima grande) Nota che i Web Worker non hanno accesso al DOM perché il DOM non è "thread-safe" e il codice che eseguono deve essere contenuto in un file separato.
- Puoi scaricare "percorsi caldi" su WebAssembly?
Potremmo scaricare compiti computazionalmente pesanti su WebAssembly ( WASM ), un formato di istruzione binaria, progettato come destinazione portatile per la compilazione di linguaggi di alto livello come C/C++/Rust. Il supporto del browser è notevole e di recente è diventato praticabile poiché le chiamate di funzione tra JavaScript e WASM stanno diventando più veloci. Inoltre, è persino supportato sull'edge cloud di Fastly.Naturalmente, WebAssembly non dovrebbe sostituire JavaScript, ma può integrarlo nei casi in cui si notano problemi di CPU. Per la maggior parte delle app Web, JavaScript è più adatto e WebAssembly è utilizzato al meglio per app Web ad alta intensità di calcolo , come i giochi.
Se desideri saperne di più su WebAssembly:
- Lin Clark ha scritto una serie completa per WebAssembly e Milica Mihajlija fornisce una panoramica generale su come eseguire codice nativo nel browser, perché potresti volerlo fare e cosa significa tutto questo per JavaScript e il futuro dello sviluppo web.
- Come abbiamo utilizzato WebAssembly per velocizzare la nostra app Web di 20 volte (Case Study) evidenzia un caso di studio su come i calcoli JavaScript lenti sono stati sostituiti con WebAssembly compilati e hanno apportato miglioramenti significativi alle prestazioni.
- Patrick Hamann ha parlato del ruolo crescente di WebAssembly e sta sfatando alcuni miti sul WebAssembly, ne esplora le sfide e oggi possiamo usarlo praticamente nelle applicazioni.
- Google Codelabs fornisce un'introduzione a WebAssembly, un corso di 60 minuti in cui imparerai come prendere il codice nativo in C e compilarlo in WebAssembly, quindi chiamarlo direttamente da JavaScript.
- Alex Danilo ha spiegato WebAssembly e come funziona durante il suo colloquio di Google I/O. Inoltre, Benedek Gagyi ha condiviso un caso di studio pratico su WebAssembly, in particolare su come il team lo utilizza come formato di output per la base di codice C++ su iOS, Android e il sito Web.
Non sei ancora sicuro di quando utilizzare Web Worker, Web Assembly, stream o forse l'API JavaScript WebGL per accedere alla GPU? Accelerare JavaScript è una guida breve ma utile che spiega quando usare cosa e perché, anche con un diagramma di flusso pratico e molte risorse utili.
- Serviamo codice legacy solo per browser legacy?
Poiché ES2017 è notevolmente ben supportato nei browser moderni, possiamo utilizzarebabelEsmPluginper trasferire solo le funzionalità ES2017+ non supportate dai browser moderni a cui ti rivolgi.Houssein Djirdeh e Jason Miller hanno recentemente pubblicato una guida completa su come trasporre e servire JavaScript moderno e legacy, entrando nei dettagli per farlo funzionare con Webpack e Rollup e gli strumenti necessari. Puoi anche stimare la quantità di JavaScript che puoi eliminare dal tuo sito o dagli app bundle.
I moduli JavaScript sono supportati in tutti i principali browser, quindi usa
script type="module"per consentire ai browser con supporto del modulo ES di caricare il file, mentre i browser meno recenti potrebbero caricare build legacy conscript nomodule.In questi giorni possiamo scrivere JavaScript basato su moduli che viene eseguito in modo nativo nel browser, senza transpiler o bundler. L'intestazione
<link rel="modulepreload">fornisce un modo per avviare il caricamento anticipato (e ad alta priorità) degli script dei moduli. Fondamentalmente, è un modo ingegnoso per aiutare a massimizzare l'utilizzo della larghezza di banda, dicendo al browser cosa deve recuperare in modo che non sia bloccato con nulla da fare durante quei lunghi viaggi di andata e ritorno. Inoltre, Jake Archibald ha pubblicato un articolo dettagliato con trucchi e cose da tenere a mente con i moduli ES che vale la pena leggere.
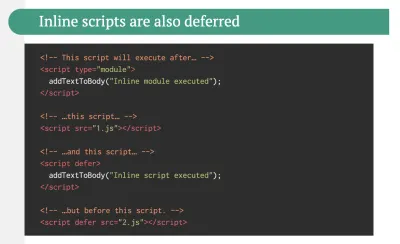
- Identifica e riscrivi il codice legacy con il disaccoppiamento incrementale .
I progetti di lunga durata hanno la tendenza a raccogliere polvere e codice datato. Rivedi le tue dipendenze e valuta quanto tempo sarebbe necessario per refactoring o riscrivere il codice legacy che ha causato problemi ultimamente. Naturalmente, è sempre una grande impresa, ma una volta che conosci l'impatto del codice legacy, potresti iniziare con il disaccoppiamento incrementale.Innanzitutto, imposta le metriche che tengono traccia se il rapporto delle chiamate di codice legacy rimane costante o diminuisce, non aumenta. Scoraggia pubblicamente il team dall'usare la libreria e assicurati che l'elemento della configurazione avvisi gli sviluppatori se viene utilizzata nelle richieste pull. polyfills potrebbe aiutare la transizione dal codice legacy alla base di codice riscritta che utilizza le funzionalità standard del browser.
- Identifica e rimuovi CSS/JS inutilizzati .
La copertura del codice CSS e JavaScript in Chrome ti consente di sapere quale codice è stato eseguito/applicato e quale no. Puoi iniziare a registrare la copertura, eseguire azioni su una pagina e quindi esplorare i risultati della copertura del codice. Dopo aver rilevato il codice inutilizzato, trova quei moduli e carica lazy conimport()(vedi l'intero thread). Quindi ripeti il profilo di copertura e verifica che ora stia inviando meno codice al caricamento iniziale.Puoi utilizzare Puppeteer per raccogliere a livello di codice la copertura. Chrome ti consente anche di esportare i risultati della copertura del codice. Come ha notato Andy Davies, potresti voler raccogliere la copertura del codice sia per i browser moderni che per quelli legacy.
Ci sono molti altri casi d'uso e strumenti per Puppetter che potrebbero richiedere un po' più di esposizione:
- Casi d'uso per Burattinaio, come, ad esempio, la differenziazione visiva automatica o il monitoraggio di CSS inutilizzati con ogni build,
- Ricette per performance web con Burattinaio,
- Strumenti utili per la registrazione e la generazione di script Pupeeteer e Playwright,
- Inoltre, puoi persino registrare i test direttamente in DevTools,
- Panoramica completa di Puppeteer di Nitay Neeman, con esempi e casi d'uso.
Possiamo utilizzare Puppeteer Recorder e Puppeteer Sandbox per registrare l'interazione del browser e generare script Puppeteer e Playwright. (Grande anteprima) Inoltre, purgecss, UnCSS ed Helium possono aiutarti a rimuovere gli stili inutilizzati dai CSS. E se non sei sicuro che un pezzo di codice sospetto sia usato da qualche parte, puoi seguire il consiglio di Harry Roberts: crea una GIF trasparente 1×1px per una classe particolare e rilasciala in una directory
dead/, ad esempio/assets/img/dead/comments.gif.Dopodiché, imposti quell'immagine specifica come sfondo sul selettore corrispondente nel tuo CSS, siediti e attendi qualche mese se il file apparirà nei tuoi registri. Se non ci sono voci, nessuno ha avuto quel componente legacy visualizzato sul proprio schermo: probabilmente puoi andare avanti ed eliminarlo tutto.
Per il dipartimento I-feel-adventurous , potresti persino automatizzare la raccolta di CSS inutilizzati attraverso un insieme di pagine monitorando DevTools usando DevTools.
- Taglia le dimensioni dei tuoi bundle JavaScript.
Come ha notato Addy Osmani, c'è un'alta probabilità che tu stia inviando librerie JavaScript complete quando ti serve solo una frazione, insieme a polyfill datati per i browser che non ne hanno bisogno o semplicemente duplicano il codice. Per evitare il sovraccarico, prendi in considerazione l'utilizzo di webpack-libs-optimizations che rimuove i metodi e i polyfill inutilizzati durante il processo di compilazione.Controlla e rivedi i polyfill che stai inviando ai browser legacy e ai browser moderni e sii più strategico al riguardo. Dai un'occhiata a polyfill.io che è un servizio che accetta una richiesta per un insieme di funzionalità del browser e restituisce solo i polyfill necessari al browser richiedente.
Aggiungi anche il controllo dei pacchetti al tuo normale flusso di lavoro. Potrebbero esserci alcune alternative leggere alle librerie pesanti che hai aggiunto anni fa, ad esempio Moment.js (ora fuori produzione) potrebbe essere sostituito con:
- API di internazionalizzazione nativa,
- Day.js con un'API e modelli Moment.js familiari,
- date-fns o
- Luxon.
- Puoi anche utilizzare Skypack Discover che combina i consigli sui pacchetti sottoposti a revisione umana con una ricerca incentrata sulla qualità.
La ricerca di Benedikt Rotsch ha mostrato che un passaggio da Moment.js a date-fns potrebbe ridurre di circa 300 ms per la prima vernice su 3G e un telefono cellulare di fascia bassa.
Per il controllo del pacchetto, Bundlephobia potrebbe aiutare a trovare il costo dell'aggiunta di un pacchetto npm al tuo pacchetto. size-limit estende il controllo delle dimensioni del pacchetto di base con dettagli sul tempo di esecuzione di JavaScript. Puoi anche integrare questi costi con un audit personalizzato del faro. Questo vale anche per i framework. Rimuovendo o tagliando l'adattatore Vue MDC (Component Components for Vue), gli stili scendono da 194 KB a 10 KB.
Esistono molti altri strumenti per aiutarti a prendere una decisione informata sull'impatto delle tue dipendenze e alternative praticabili:
- webpack-bundle-analyzer
- Esplora mappa di origine
- Fagotto amico
- Fobia del fascio
- L'analisi di Webpack mostra perché un modulo specifico è incluso nel pacchetto.
- bundle-wizard crea anche una mappa delle dipendenze per l'intera pagina.
- Plugin dimensione Webpack
- Costo di importazione per codice visivo
In alternativa alla spedizione dell'intero framework, puoi ritagliare il tuo framework e compilarlo in un bundle JavaScript grezzo che non richiede codice aggiuntivo. Svelte lo fa, così come il plug-in Rawact Babel che trasferisce i componenti React.js alle operazioni DOM native in fase di compilazione. Come mai? Bene, come spiegano i manutentori, "react-dom include codice per ogni possibile componente/HTMLElement di cui è possibile eseguire il rendering, incluso il codice per il rendering incrementale, la pianificazione, la gestione degli eventi, ecc. Ma ci sono applicazioni che non necessitano di tutte queste funzionalità (inizialmente caricamento della pagina). Per tali applicazioni, potrebbe avere senso utilizzare operazioni DOM native per creare l'interfaccia utente interattiva."
- Usiamo l'idratazione parziale?
Con la quantità di JavaScript utilizzata nelle applicazioni, dobbiamo trovare il modo di inviare il meno possibile al client. Un modo per farlo - e l'abbiamo già brevemente trattato - è con l'idratazione parziale. L'idea è abbastanza semplice: invece di eseguire SSR e quindi inviare l'intera app al client, solo piccoli frammenti del JavaScript dell'app verrebbero inviati al client e quindi idratati. Possiamo pensarlo come più piccole app React con più radici di rendering su un sito Web altrimenti statico.Nell'articolo "Il caso dell'idratazione parziale (con Next e Preact)", Lukas Bombach spiega come il team dietro Welt.de, una delle testate giornalistiche in Germania, abbia ottenuto prestazioni migliori con l'idratazione parziale. Puoi anche controllare il repository GitHub successivo con prestazioni eccellenti con spiegazioni e frammenti di codice.
Potresti anche considerare opzioni alternative:
- idratazione parziale con Preact ed Eleventy,
- idratazione progressiva nel repository React GitHub,
- lazy-idratazione in Vue.js (repo GitHub),
- Importa su modello di interazione per caricare in modo lento le risorse non critiche (ad es. componenti, incorporamenti) quando un utente interagisce con l'interfaccia utente che ne ha bisogno.
Jason Miller ha pubblicato demo di lavoro su come implementare l'idratazione progressiva con React, quindi puoi usarle subito: demo 1, demo 2, demo 3 (disponibile anche su GitHub). Inoltre, puoi esaminare la libreria dei componenti di react-prerendering.
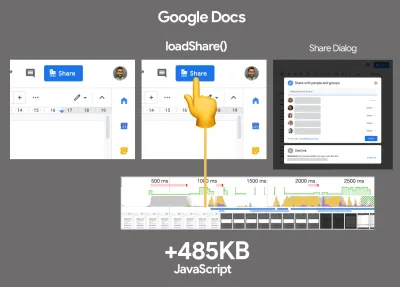
L'importazione all'interazione per il codice proprietario deve essere eseguita solo se non sei in grado di precaricare le risorse prima dell'interazione. (Grande anteprima) - Abbiamo ottimizzato la strategia per React/SPA?
Stai lottando con le prestazioni della tua applicazione a pagina singola? Jeremy Wagner ha esplorato l'impatto delle prestazioni del framework lato client su una varietà di dispositivi, evidenziando alcune delle implicazioni e delle linee guida di cui potremmo voler essere consapevoli quando ne utilizziamo uno.Di conseguenza, ecco una strategia SPA che Jeremy suggerisce di utilizzare per il framework React (ma non dovrebbe cambiare in modo significativo per altri framework):
- Quando possibile, rifattorizzare i componenti con stato come componenti senza stato .
- Quando possibile, eseguire il prerendering dei componenti stateless per ridurre al minimo i tempi di risposta del server. Rendering solo sul server.
- Per i componenti con stato con interattività semplice, prendi in considerazione il prerendering o il rendering del server di quel componente e sostituisci la sua interattività con listener di eventi indipendenti dal framework .
- Se devi idratare i componenti con stato sul client, usa l'idratazione pigra sulla visibilità o sull'interazione.
- Per i componenti pigramente idratati, pianifica la loro idratazione durante il tempo di inattività del thread principale con
requestIdleCallback.
Ci sono alcune altre strategie che potresti voler perseguire o rivedere:
- Considerazioni sulle prestazioni per CSS-in-JS nelle app React
- Riduci le dimensioni del pacchetto Next.js caricando i polyfill solo quando necessario, utilizzando le importazioni dinamiche e l'idratazione pigra.
- Segreti di JavaScript: una storia di React, ottimizzazione delle prestazioni e multi-threading, una lunga serie in 7 parti sul miglioramento delle sfide dell'interfaccia utente con React,
- Come misurare le prestazioni di React e come profilare le applicazioni React.
- Costruire animazioni Web mobile-first in React, un fantastico discorso di Alex Holachek, insieme a diapositive e repository GitHub ( grazie per il suggerimento, Addy! ).
- webpack-libs-optimizations è un fantastico repository GitHub con molte utili ottimizzazioni relative alle prestazioni specifiche di Webpack. Gestito da Ivan Akulov.
- Miglioramenti delle prestazioni di React in Notion, una guida di Ivan Akulov su come migliorare le prestazioni in React, con molti suggerimenti utili per rendere l'app più veloce di circa il 30%.
- React Refresh Webpack Plugin (sperimentale) consente il ricaricamento a caldo che preserva lo stato dei componenti e supporta hook e componenti di funzioni.
- Fai attenzione ai componenti del server React a dimensione zero, un nuovo tipo di componenti proposto che non avrà alcun impatto sulle dimensioni del pacchetto. Il progetto è attualmente in fase di sviluppo, ma qualsiasi feedback da parte della community è molto apprezzato (ottimo spiegatore di Sophie Alpert).
- Stai usando il prelettura predittiva per i blocchi JavaScript?
Potremmo usare l'euristica per decidere quando precaricare i blocchi JavaScript. Guess.js è un insieme di strumenti e librerie che utilizzano i dati di Google Analytics per determinare quale pagina è più probabile che un utente visiterà successivamente da una determinata pagina. Sulla base dei modelli di navigazione dell'utente raccolti da Google Analytics o da altre fonti, Guess.js crea un modello di apprendimento automatico per prevedere e precaricare JavaScript che sarà richiesto in ogni pagina successiva.Quindi, ogni elemento interattivo riceve un punteggio di probabilità per il coinvolgimento e, sulla base di tale punteggio, uno script lato client decide di precaricare una risorsa in anticipo. Puoi integrare la tecnica nella tua applicazione Next.js, Angular e React, e c'è un plug-in Webpack che automatizza anche il processo di installazione.
Ovviamente, potresti chiedere al browser di consumare dati non necessari e precaricare le pagine indesiderate, quindi è una buona idea essere piuttosto prudenti nel numero di richieste precaricate. Un buon caso d'uso potrebbe essere il precaricamento degli script di convalida richiesti durante il checkout o il precaricamento speculativo quando un invito all'azione critico entra nel viewport.
Hai bisogno di qualcosa di meno sofisticato? DNStradamus esegue il precaricamento DNS per i collegamenti in uscita così come appaiono nel viewport. Quicklink, InstantClick e Instant.page sono piccole librerie che precaricano automaticamente i collegamenti nel viewport durante il tempo di inattività nel tentativo di caricare più velocemente le navigazioni della pagina successiva. Quicklink permette di precaricare i percorsi di React Router e Javascript; inoltre è attento ai dati, quindi non esegue il precaricamento su 2G o se
Data-Saverè attivo. Lo stesso vale per Instant.page se la modalità è impostata per utilizzare il prelettura del viewport (che è un'impostazione predefinita).Se vuoi approfondire la scienza del prefetch predittivo in dettaglio, Divya Tagtachian ha un ottimo discorso su The Art of Predictive Prefetch, coprendo tutte le opzioni dall'inizio alla fine.
- Approfitta delle ottimizzazioni per il tuo motore JavaScript di destinazione.
Studia quali motori JavaScript dominano nella tua base di utenti, quindi esplora i modi per ottimizzarli. Ad esempio, durante l'ottimizzazione per V8 che viene utilizzato in Blink-browser, runtime Node.js ed Electron, utilizzare lo streaming di script per gli script monolitici.Lo streaming di script consente l'analisi degli script
asyncodefer scriptssu un thread in background separato una volta avviato il download, migliorando così in alcuni casi i tempi di caricamento della pagina fino al 10%. Practically, use<script defer>in the<head>, so that the browsers can discover the resource early and then parse it on the background thread.Caveat : Opera Mini doesn't support script deferment, so if you are developing for India or Africa,
deferwill be ignored, resulting in blocking rendering until the script has been evaluated (thanks Jeremy!) .You could also hook into V8's code caching as well, by splitting out libraries from code using them, or the other way around, merge libraries and their uses into a single script, group small files together and avoid inline scripts. Or perhaps even use v8-compile-cache.
When it comes to JavaScript in general, there are also some practices that are worth keeping in mind:
- Clean Code concepts for JavaScript, a large collection of patterns for writing readable, reusable, and refactorable code.
- You can Compress data from JavaScript with the CompressionStream API, eg to gzip before uploading data (Chrome 80+).
- Detached window memory leaks and Fixing memory leaks in web apps are detailed guides on how to find and fix tricky JavaScript memory leaks. Plus, you can use queryObjects(SomeConstructor) from the DevTools Console ( thanks, Mathias! ).
- Reexports are bad for loading and runtime performance, and avoiding them can help reduce the bundle size significantly.
- We can improve scroll performance with passive event listeners by setting a flag in the
optionsparameter. So browsers can scroll the page immediately, rather than after the listener has finished. (via Kayce Basques). - If you have any
scrollortouch*listeners, passpassive: trueto addEventListener. This tells the browser you're not planning to callevent.preventDefault()inside, so it can optimize the way it handles these events. (via Ivan Akulov) - We can achieve better JavaScript scheduling with isInputPending(), a new API that attempts to bridge the gap between loading and responsiveness with the concepts of interrupts for user inputs on the web, and allows for JavaScript to be able to check for input without yielding to the browser.
- You can also automatically remove an event listener after it has executed.
- Firefox's recently released Warp, a significant update to SpiderMonkey (shipped in Firefox 83), Baseline Interpreter and there are a few JIT Optimization Strategies available as well.
- Always prefer to self-host third-party assets.
Yet again, self-host your static assets by default. It's common to assume that if many sites use the same public CDN and the same version of a JavaScript library or a web font, then the visitors would land on our site with the scripts and fonts already cached in their browser, speeding up their experience considerably. However, it's very unlikely to happen.For security reasons, to avoid fingerprinting, browsers have been implementing partitioned caching that was introduced in Safari back in 2013, and in Chrome last year. So if two sites point to the exact same third-party resource URL, the code is downloaded once per domain , and the cache is "sandboxed" to that domain due to privacy implications ( thanks, David Calhoun! ). Hence, using a public CDN will not automatically lead to better performance.
Furthermore, it's worth noting that resources don't live in the browser's cache as long as we might expect, and first-party assets are more likely to stay in the cache than third-party assets. Therefore, self-hosting is usually more reliable and secure, and better for performance, too.
- Constrain the impact of third-party scripts.
With all performance optimizations in place, often we can't control third-party scripts coming from business requirements. Third-party-scripts metrics aren't influenced by end-user experience, so too often one single script ends up calling a long tail of obnoxious third-party scripts, hence ruining a dedicated performance effort. To contain and mitigate performance penalties that these scripts bring along, it's not enough to just defer their loading and execution and warm up connections via resource hints, iedns-prefetchorpreconnect.Currently 57% of all JavaScript code excution time is spent on third-party code. The median mobile site accesses 12 third-party domains , with a median of 37 different requests (or about 3 requests made to each third party).
Furthermore, these third-parties often invite fourth-party scripts to join in, ending up with a huge performance bottleneck, sometimes going as far as to the eigth-party scripts on a page. So regularly auditing your dependencies and tag managers can bring along costly surprises.
Another problem, as Yoav Weiss explained in his talk on third-party scripts, is that in many cases these scripts download resources that are dynamic. The resources change between page loads, so we don't necessarily know which hosts the resources will be downloaded from and what resources they would be.
Deferring, as shown above, might be just a start though as third-party scripts also steal bandwidth and CPU time from your app. We could be a bit more aggressive and load them only when our app has initialized.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors' devices, and depending on how they're implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne's Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts' approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.

Loading YouTube with facades, eg lite-youtube-embed that's significantly smaller than an actual YouTube player. (Fonte immagine) (Anteprima grande) If it's not viable, we can at least lazy load third-party resources with facades, ie a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction .
For example, we can use:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests : to avoid flickering between the different test scenarios, they hide the
bodyof the document withopacity: 0, then adds a function that gets called after a few seconds to bring theopacityback. This often results in massive delays in rendering due to massive client-side execution costs.
With A/B testing in use, customers would often see flickering like this one. Anti-Flicker snippets prevent that, but they also cost in performance. Via Andy Davies. (Grande anteprima) Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec, "Friends don't let friends do client side A/B testing". Server-side A/B testing on CDNs (eg Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager , Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
Attenzione: alcuni widget di terze parti si nascondono dagli strumenti di controllo, quindi potrebbero essere più difficili da individuare e misurare. Per sottoporre a stress test di terze parti, esamina i riepiloghi bottom-up nella pagina del profilo delle prestazioni in DevTools, verifica cosa succede se una richiesta è bloccata o è scaduta: per quest'ultimo, puoi utilizzare il server Blackhole di WebPageTest
blackhole.webpagetest.orgche hai può puntare a domini specifici nel filehosts.Quali opzioni abbiamo allora? Prendi in considerazione l'utilizzo di service worker eseguendo il download della risorsa con un timeout e se la risorsa non ha risposto entro un determinato timeout, restituisci una risposta vuota per indicare al browser di continuare con l'analisi della pagina. Puoi anche registrare o bloccare le richieste di terze parti che non vanno a buon fine o che non soddisfano determinati criteri. Se puoi, carica lo script di terze parti dal tuo server anziché dal server del fornitore e caricalo in modo lento.
Un'altra opzione è stabilire una politica di sicurezza dei contenuti (CSP) per limitare l'impatto di script di terze parti, ad esempio vietando il download di audio o video. L'opzione migliore è incorporare gli script tramite
<iframe>in modo che gli script siano in esecuzione nel contesto dell'iframe e quindi non abbiano accesso al DOM della pagina e non possano eseguire codice arbitrario sul tuo dominio. Gli iframe possono essere ulteriormente vincolati utilizzando l'attributosandbox, quindi puoi disabilitare qualsiasi funzionalità che iframe potrebbe fare, ad esempio impedire l'esecuzione di script, impedire avvisi, invio di moduli, plug-in, accesso alla navigazione in alto e così via.Potresti anche tenere sotto controllo le terze parti tramite l'intasamento delle prestazioni nel browser con le politiche delle funzionalità, una funzionalità relativamente nuova che ti consente
attivare o disattivare alcune funzionalità del browser sul tuo sito. (Come nota a margine, potrebbe anche essere utilizzato per evitare immagini sovradimensionate e non ottimizzate, supporti non dimensionati, script di sincronizzazione e altro). Attualmente supportato nei browser basati su Blink. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Poiché molti script di terze parti sono in esecuzione negli iframe, probabilmente è necessario essere scrupolosi nel limitare le loro autorizzazioni. Gli iframe in modalità sandbox sono sempre una buona idea e ciascuna delle limitazioni può essere revocata tramite una serie di valori di
allownell'attributosandbox. Il sandboxing è supportato quasi ovunque, quindi limita gli script di terze parti al minimo indispensabile di ciò che dovrebbero essere autorizzati a fare.
ThirdPartyWeb.Today raggruppa tutti gli script di terze parti per categoria (analytics, social, advertising, hosting, tag manager ecc.) e visualizza quanto tempo impiegano gli script dell'entità per essere eseguiti (in media). (Grande anteprima) Prendi in considerazione l'utilizzo di un osservatore di intersezione; ciò consentirebbe agli annunci di essere iframe mentre si inviano ancora eventi o si ottengono le informazioni di cui hanno bisogno dal DOM (ad es. visibilità dell'annuncio). Fai attenzione alle nuove politiche come la politica delle funzionalità, i limiti delle dimensioni delle risorse e la priorità CPU/larghezza di banda per limitare le funzionalità Web dannose e gli script che rallenteranno il browser, ad esempio script sincroni, richieste XHR sincrone, document.write e implementazioni obsolete.
Infine, quando scegli un servizio di terze parti, valuta la possibilità di controllare ThirdPartyWeb.Today di Patrick Hulce, un servizio che raggruppa tutti gli script di terze parti per categoria (analisi, social, pubblicità, hosting, tag manager ecc.) e visualizza per quanto tempo gli script dell'entità prendere per eseguire (in media). Ovviamente, le entità più grandi hanno il peggior impatto sulle prestazioni delle pagine in cui si trovano. Semplicemente scorrendo la pagina, avrai un'idea dell'impronta delle prestazioni che dovresti aspettarti.
Ah, e non dimentichiamoci dei soliti sospetti: al posto dei widget di terze parti per la condivisione, possiamo utilizzare pulsanti di condivisione social statici (tipo SSBG) e link statici a mappe interattive al posto delle mappe interattive.
- Imposta correttamente le intestazioni della cache HTTP.
La memorizzazione nella cache sembra essere una cosa così ovvia da fare, ma potrebbe essere piuttosto difficile da correggere. È necessario ricontrollare che le intestazioni diexpires,max-age,cache-controle altre cache HTTP siano state impostate correttamente. Senza le intestazioni della cache HTTP corrette, i browser le imposteranno automaticamente al 10% del tempo trascorsolast-modified, finendo con una potenziale cache insufficiente e eccessiva.In generale, le risorse dovrebbero essere memorizzabili nella cache per un tempo molto breve (se è probabile che cambino) o indefinitamente (se sono statiche): puoi semplicemente modificare la loro versione nell'URL quando necessario. Puoi chiamarla strategia Cache-Forever, in cui potremmo inoltrare le intestazioni
Cache-ControleExpiresal browser per consentire alle risorse di scadere solo in un anno. Quindi, il browser non farebbe nemmeno una richiesta per l'asset se lo ha nella cache.L'eccezione sono le risposte API (ad es
/api/user). Per impedire la memorizzazione nella cache, possiamo utilizzareprivate, no storee nonmax-age=0, no-store:Cache-Control: private, no-storeUsa
Cache-control: immutableper evitare la riconvalida di lunghe durate della cache esplicita quando gli utenti premono il pulsante di ricarica. Per il caso di ricarica,immutablesalva le richieste HTTP e migliora il tempo di caricamento dell'HTML dinamico poiché non competono più con la moltitudine di 304 risposte.Un tipico esempio in cui vogliamo usare
immutablesono le risorse CSS/JavaScript con un hash nel loro nome. Per loro, probabilmente vogliamo memorizzare nella cache il più a lungo possibile e assicurarci che non vengano mai riconvalidati:Cache-Control: max-age: 31556952, immutableSecondo la ricerca di Colin Bendell,
immutableriduce 304 reindirizzamenti di circa il 50% poiché anche conmax-agein uso, i client continuano a riconvalidare e bloccare al momento dell'aggiornamento. È supportato in Firefox, Edge e Safari e Chrome sta ancora discutendo il problema.Secondo Web Almanac, "il suo utilizzo è cresciuto fino al 3,5% ed è ampiamente utilizzato nelle risposte di terze parti di Facebook e Google".

Cache-Control: Immutable riduce i 304 secondi di circa il 50%, secondo la ricerca di Colin Bendell su Cloudinary. (Grande anteprima) Ricordi il buon vecchio stantio-mentre-riconvalidato? Quando specifichiamo il tempo di memorizzazione nella cache con l'intestazione della risposta
Cache-Control(ad es.Cache-Control: max-age=604800), dopo la scadenzamax-age, il browser recupererà il contenuto richiesto, rallentando il caricamento della pagina. Questo rallentamento può essere evitato constale-while-revalidate; fondamentalmente definisce una finestra di tempo aggiuntiva durante la quale una cache può utilizzare una risorsa non aggiornata purché la riconvalidi in modo asincrono in background. Pertanto, "nasconde" la latenza (sia nella rete che sul server) dai client.Nel giugno-luglio 2019, Chrome e Firefox hanno lanciato il supporto di
stale-while-revalidatenell'intestazione HTTP Cache-Control, quindi, di conseguenza, dovrebbe migliorare le successive latenze di caricamento della pagina poiché le risorse obsolete non si trovano più nel percorso critico. Risultato: zero RTT per le visualizzazioni ripetute.Fai attenzione all'intestazione vary, specialmente in relazione alle CDN, e fai attenzione alle varianti di rappresentazione HTTP che aiutano a evitare un round trip aggiuntivo per la convalida ogni volta che una nuova richiesta differisce leggermente (ma non in modo significativo) dalle richieste precedenti ( grazie, Guy e Mark ! ).
Inoltre, ricontrolla di non inviare intestazioni non necessarie (ad es.
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectione altri) e di includere utili intestazioni di sicurezza e prestazioni (come comeContent-Security-Policy,X-Content-Type-Optionse altri). Infine, tieni presente il costo delle prestazioni delle richieste CORS nelle applicazioni a pagina singola.Nota : spesso si presume che le risorse memorizzate nella cache vengano recuperate istantaneamente, ma la ricerca mostra che il recupero di un oggetto dalla cache può richiedere centinaia di millisecondi. In effetti, secondo Simon Hearne, "a volte la rete potrebbe essere più veloce della cache e il recupero delle risorse dalla cache può essere costoso con un gran numero di risorse memorizzate nella cache (non la dimensione del file) e i dispositivi dell'utente. Ad esempio: recupero della cache media di Chrome OS raddoppia da ~50ms con 5 risorse nella cache fino a ~100ms con 25 risorse".
Inoltre, spesso assumiamo che la dimensione del pacchetto non sia un grosso problema e gli utenti lo scaricheranno una volta e quindi utilizzeranno la versione memorizzata nella cache. Allo stesso tempo, con CI/CD inseriamo il codice in produzione più volte al giorno, la cache viene invalidata ogni volta, quindi essere strategici riguardo alla memorizzazione nella cache è importante.
Quando si tratta di memorizzazione nella cache, ci sono molte risorse che vale la pena leggere:
- Cache-Control for Civilians, un tuffo nella cache con Harry Roberts.
- Il manuale di Heroku sulle intestazioni di memorizzazione nella cache HTTP,
- Best practice per la memorizzazione nella cache di Jake Archibald,
- Primer per la memorizzazione nella cache HTTP di Ilya Grigorik,
- Mantenere le cose fresche con stantio-mentre-revalidate di Jeff Posnick.
- CS Visualized: CORS di Lydia Hallie è un ottimo esplicativo su CORS, su come funziona e su come dargli un senso.
- Parlando di CORS, ecco un piccolo aggiornamento sulla politica della stessa origine di Eric Portis.
Ottimizzazioni di consegna
- Usiamo il
deferper caricare JavaScript critico in modo asincrono?
Quando l'utente richiede una pagina, il browser recupera l'HTML e costruisce il DOM, quindi recupera il CSS e costruisce il CSSOM, quindi genera un albero di rendering abbinando il DOM e il CSSOM. Se è necessario risolvere qualsiasi JavaScript, il browser non avvierà il rendering della pagina fino a quando non verrà risolto, ritardando così il rendering. Come sviluppatori, dobbiamo dire esplicitamente al browser di non aspettare e di iniziare a eseguire il rendering della pagina. Il modo per farlo per gli script è con gli attributidefereasyncin HTML.In pratica, risulta che è meglio usare
deferinvece diasync. Ah, qual è la differenza di nuovo? Secondo Steve Souders, una volta che gli scriptasyncarrivano, vengono eseguiti immediatamente, non appena lo script è pronto. Se ciò accade molto velocemente, ad esempio quando lo script è già nella cache, può effettivamente bloccare il parser HTML. Condefer, il browser non esegue gli script finché l'HTML non viene analizzato. Quindi, a meno che tu non abbia bisogno di JavaScript da eseguire prima di avviare il rendering, è meglio usaredefer. Inoltre, più file asincroni verranno eseguiti in un ordine non deterministico.Vale la pena notare che ci sono alcune idee sbagliate su
asyncedefer. Ancora più importante,asyncnon significa che il codice verrà eseguito ogni volta che lo script è pronto; significa che verrà eseguito ogni volta che gli script sono pronti e tutto il lavoro di sincronizzazione precedente è terminato. Nelle parole di Harry Roberts, "Se inserisci uno scriptasyncdopo gli script di sincronizzazione, il tuo scriptasyncè veloce quanto lo script di sincronizzazione più lento".Inoltre, non è consigliabile utilizzare sia
asyncchedefer. I browser moderni supportano entrambi, ma ogni volta che vengono utilizzati entrambi gli attributi, l'asyncvincerà sempre.Se desideri approfondire i dettagli, Milica Mihajlija ha scritto una guida molto dettagliata su Costruire il DOM più velocemente, entrando nei dettagli dell'analisi speculativa, dell'asincrono e del differimento.
- Carica pigramente componenti costosi con IntersectionObserver e suggerimenti per la priorità.
In generale, si consiglia di caricare in modo pigro tutti i componenti costosi, come JavaScript pesante, video, iframe, widget e potenzialmente immagini. Il caricamento lento nativo è già disponibile per immagini e iframe con l'attributo diloading(solo Chromium). Sotto il cofano, questo attributo rinvia il caricamento della risorsa fino a quando non raggiunge una distanza calcolata dal viewport.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Tale soglia dipende da alcune cose, dal tipo di risorsa immagine che viene recuperata al tipo di connessione efficace. Ma gli esperimenti condotti utilizzando Chrome su Android suggeriscono che su 4G, il 97,5% delle immagini under-the-fold caricate in modo pigro sono state completamente caricate entro 10 ms da quando sono diventate visibili, quindi dovrebbe essere sicuro.
Possiamo anche utilizzare l'attributo di
importance(higholow) su un elemento<script>,<img>o<link>(solo Blink). In effetti, è un ottimo modo per ridurre la priorità alle immagini nei caroselli, nonché per ridefinire la priorità degli script. Tuttavia, a volte potremmo aver bisogno di un controllo un po' più granulare.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />Il modo più efficace per eseguire un caricamento lento leggermente più sofisticato consiste nell'usare l'API Intersection Observer che fornisce un modo per osservare in modo asincrono le modifiche nell'intersezione di un elemento di destinazione con un elemento predecessore o con il viewport di un documento di primo livello. Fondamentalmente, devi creare un nuovo oggetto
IntersectionObserver, che riceve una funzione di callback e un insieme di opzioni. Quindi aggiungiamo un obiettivo da osservare.La funzione di callback viene eseguita quando il target diventa visibile o invisibile, quindi quando intercetta il viewport, puoi iniziare a intraprendere alcune azioni prima che l'elemento diventi visibile. In effetti, abbiamo un controllo granulare su quando deve essere invocata la richiamata dell'osservatore, con
rootMargin(margine attorno alla radice) ethreshold(un singolo numero o una matrice di numeri che indicano a quale percentuale della visibilità del bersaglio stiamo puntando).Alejandro Garcia Anglada ha pubblicato un pratico tutorial su come implementarlo effettivamente, Rahul Nanwani ha scritto un post dettagliato sul caricamento lento delle immagini in primo piano e di sfondo e Google Fundamentals fornisce anche un tutorial dettagliato sul caricamento lento di immagini e video con Intersection Observer.
Ricordi lunghe letture di narrazione artistica con oggetti in movimento e appiccicosi? Puoi anche implementare lo scrollytelling performante con Intersection Observer.
Controlla di nuovo cos'altro potresti caricare pigro. Anche le stringhe di traduzione e le emoji a caricamento lento potrebbero aiutare. In questo modo, Mobile Twitter è riuscito a ottenere un'esecuzione JavaScript più veloce dell'80% dalla nuova pipeline di internazionalizzazione.
Una breve parola di cautela però: vale la pena notare che il caricamento lento dovrebbe essere un'eccezione piuttosto che la regola. Probabilmente non è ragionevole caricare in modo pigro tutto ciò che si desidera che le persone vedano rapidamente, ad esempio immagini della pagina del prodotto, immagini dell'eroe o uno script necessario affinché la navigazione principale diventi interattiva.

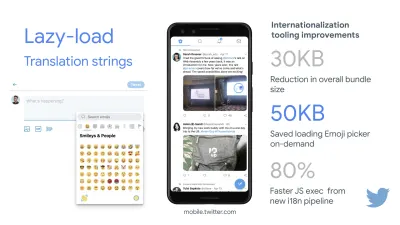
- Carica le immagini progressivamente.
Potresti persino portare il caricamento lento al livello successivo aggiungendo il caricamento progressivo delle immagini alle tue pagine. Analogamente a Facebook, Pinterest, Medium e Wolt, è possibile caricare prima immagini di bassa qualità o addirittura sfocate, quindi, mentre la pagina continua a caricarsi, sostituirle con le versioni di qualità completa utilizzando la tecnica BlurHash o LQIP (Low Quality Image Placeholders) tecnica.Le opinioni divergono se queste tecniche migliorano o meno l'esperienza dell'utente, ma migliorano decisamente il tempo di First Contentful Paint. Possiamo persino automatizzarlo utilizzando SQIP che crea una versione di bassa qualità di un'immagine come segnaposto SVG o segnaposto immagine sfumata con gradienti lineari CSS.
Questi segnaposto potrebbero essere incorporati all'interno di HTML poiché si comprimono naturalmente bene con i metodi di compressione del testo. Nel suo articolo, Dean Hume ha descritto come questa tecnica può essere implementata utilizzando Intersection Observer.
Ricaderci? Se il browser non supporta l'osservatore di intersezione, possiamo comunque caricare in modo lento un polyfill o caricare immediatamente le immagini. E c'è anche una libreria per questo.
Vuoi diventare più elegante? È possibile tracciare le immagini e utilizzare forme e bordi primitivi per creare un segnaposto SVG leggero, caricarlo prima e quindi passare dall'immagine vettoriale segnaposto all'immagine bitmap (caricata).
- Rimandi il rendering con
content-visibility?
Per layout complessi con molti blocchi di contenuto, immagini e video, la decodifica dei dati e il rendering dei pixel potrebbero essere un'operazione piuttosto costosa, specialmente su dispositivi di fascia bassa. Concontent-visibility: auto, possiamo richiedere al browser di saltare il layout dei bambini mentre il contenitore è al di fuori del viewport.Ad esempio, potresti saltare il rendering del piè di pagina e delle sezioni finali sul caricamento iniziale:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Si noti che la visibilità del contenuto: auto; si comporta come overflow: nascosto; , ma puoi risolverlo applicando
padding-leftepadding-rightinvece delmargin-left: auto;,margin-right: auto;e una larghezza dichiarata. Il riempimento sostanzialmente consente agli elementi di traboccare nella casella del contenuto ed entrare nella casella di riempimento senza lasciare il modello della scatola nel suo insieme e essere tagliato.Inoltre, tieni presente che potresti introdurre alcuni CLS quando alla fine viene eseguito il rendering di nuovi contenuti, quindi è una buona idea usare
contain-intrinsic-sizecon un segnaposto di dimensioni adeguate ( grazie, Una! ).Thijs Terluin ha molti più dettagli su entrambe le proprietà e su come viene calcolata la
contain-intrinsic-sizedal browser, Malte Ubl mostra come calcolarla e un breve video esplicativo di Jake e Surma spiega come funziona.E se hai bisogno di diventare un po' più granulare, con CSS Containment, puoi saltare manualmente il layout, lo stile e il lavoro di disegno per i discendenti di un nodo DOM se hai bisogno solo di dimensioni, allineamento o stili calcolati su altri elementi — o l'elemento è attualmente fuori tela.


content-visibility: auto alle aree di contenuto in blocchi offre un aumento delle prestazioni di rendering di 7 volte al carico iniziale. (Grande anteprima)- Rinvii la decodifica con
decoding="async"?
A volte il contenuto appare fuori schermo, ma vogliamo assicurarci che sia disponibile quando i clienti ne hanno bisogno, idealmente, non bloccando nulla nel percorso critico, ma decodificando e visualizzando in modo asincrono. Possiamo usaredecoding="async"per dare al browser il permesso di decodificare l'immagine fuori dal thread principale, evitando l'impatto dell'utente del tempo CPU utilizzato per decodificare l'immagine (tramite Malte Ubl):<img decoding="async" … />In alternativa, per le immagini fuori schermo, possiamo visualizzare prima un segnaposto e, quando l'immagine è all'interno del viewport, utilizzando IntersectionObserver, attivare una chiamata di rete per scaricare l'immagine in background. Inoltre, possiamo rinviare il rendering fino alla decodifica con img.decode() o scaricare l'immagine se l'API Image Decode non è disponibile.
Durante il rendering dell'immagine, ad esempio, possiamo utilizzare animazioni di dissolvenza in entrata. Katie Hempenius e Addy Osmani condividono ulteriori approfondimenti nel loro discorso Speed at Scale: Web Performance Tips and Tricks from the Trenches.
- Generate e servite CSS critici?
Per garantire che i browser inizino a visualizzare la tua pagina il più rapidamente possibile, è diventata una pratica comune raccogliere tutti i CSS necessari per iniziare a eseguire il rendering della prima parte visibile della pagina (nota come "CSS critico" o "CSS above-the-fold ") e includerlo in linea nel<head>della pagina, riducendo così i roundtrip. A causa delle dimensioni limitate dei pacchetti scambiati durante la fase di avvio lento, il tuo budget per CSS critici è di circa 14 KB.Se vai oltre, il browser avrà bisogno di ulteriori roundtrip per recuperare più stili. CriticalCSS e Critical ti consentono di generare CSS critici per ogni modello che stai utilizzando. Nella nostra esperienza, tuttavia, nessun sistema automatico è mai stato migliore della raccolta manuale di CSS critici per ogni modello, e in effetti questo è l'approccio a cui siamo tornati di recente.
È quindi possibile incorporare CSS critici e caricare in modo pigro il resto con il plug-in Critters Webpack. Se possibile, prendi in considerazione l'utilizzo dell'approccio inline condizionale utilizzato dal Filament Group o converti al volo il codice inline in risorse statiche.
Se attualmente carichi il tuo CSS completo in modo asincrono con librerie come loadCSS, non è davvero necessario. Con
media="print", puoi indurre il browser a recuperare il CSS in modo asincrono ma applicandolo all'ambiente dello schermo una volta caricato. ( grazie, Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Quando si raccolgono tutti i CSS critici per ogni modello, è comune esplorare solo l'area "above-the-fold". Tuttavia, per layout complessi, potrebbe essere una buona idea includere anche le basi del layout per evitare enormi costi di ricalcolo e ridisegno, danneggiando di conseguenza il punteggio di Core Web Vitals.
Cosa succede se un utente ottiene un URL che si collega direttamente al centro della pagina ma il CSS non è stato ancora scaricato? In tal caso, è diventato comune nascondere i contenuti non critici, ad esempio con l'
opacity: 0;in CSS integrato eopacity: 1nel file CSS completo e visualizzalo quando CSS è disponibile. Tuttavia, ha un grosso svantaggio , poiché gli utenti con connessioni lente potrebbero non essere mai in grado di leggere il contenuto della pagina. Ecco perché è meglio mantenere sempre visibile il contenuto, anche se potrebbe non avere uno stile adeguato.L'inserimento di CSS critici (e altre risorse importanti) in un file separato nel dominio principale presenta vantaggi, a volte anche più dell'inlining, a causa della memorizzazione nella cache. Chrome apre in modo speculativo una seconda connessione HTTP al dominio principale quando richiede la pagina, il che elimina la necessità di una connessione TCP per recuperare questo CSS. Ciò significa che puoi creare una serie di file CSS critici (ad esempio critical-homepage.css , critical-product-page.css ecc.) e servirli dalla tua radice, senza doverli incorporare. ( grazie, Filippo! )
Un avvertimento: con HTTP/2, i CSS critici potrebbero essere archiviati in un file CSS separato e inviati tramite un server push senza gonfiare l'HTML. Il problema è che il push del server è stato problematico con molti trucchi e condizioni di gara su tutti i browser. Non è mai stato supportato in modo coerente e ha avuto alcuni problemi di memorizzazione nella cache (vedi diapositiva 114 in poi della presentazione di Hooman Beheshti).
L'effetto potrebbe, infatti, essere negativo e gonfiare i buffer di rete, impedendo la consegna di frame autentici nel documento. Quindi non è stato molto sorprendente che per il momento Chrome stia pianificando di rimuovere il supporto per Server Push.
- Prova a raggruppare le tue regole CSS.
Ci siamo abituati ai CSS critici, ma ci sono alcune ottimizzazioni che potrebbero andare oltre. Harry Roberts ha condotto una ricerca notevole con risultati abbastanza sorprendenti. Ad esempio, potrebbe essere una buona idea dividere il file CSS principale nelle sue singole media query. In questo modo, il browser recupererà CSS critici con priorità alta e tutto il resto con priorità bassa, completamente fuori dal percorso critico.Inoltre, evita di posizionare
<link rel="stylesheet" />prima degli snippetasync. Se gli script non dipendono dai fogli di stile, considera di posizionare gli script di blocco sopra gli stili di blocco. Se lo fanno, dividi quel JavaScript in due e caricalo su entrambi i lati del tuo CSS.Scott Jehl ha risolto un altro problema interessante memorizzando nella cache un file CSS integrato con un addetto ai servizi, un problema comune che è familiare se si utilizzano CSS critici. Fondamentalmente, aggiungiamo un attributo ID all'elemento
stylein modo che sia facile trovarlo usando JavaScript, quindi un piccolo pezzo di JavaScript trova quel CSS e usa l'API Cache per memorizzarlo in una cache del browser locale (con un tipo di contenuto ditext/css) da utilizzare nelle pagine successive. Per evitare l'inlining nelle pagine successive e fare riferimento invece alle risorse memorizzate nella cache esternamente, impostiamo un cookie alla prima visita a un sito. Ecco!Vale la pena notare che anche lo stile dinamico può essere costoso, ma di solito solo nei casi in cui ti affidi a centinaia di componenti composti contemporaneamente renderizzati. Quindi, se stai usando CSS-in-JS, assicurati che la tua libreria CSS-in-JS ottimizzi l'esecuzione quando il tuo CSS non ha dipendenze da temi o oggetti di scena e non componi eccessivamente i componenti con stile . Aggelos Arvanitakis condivide ulteriori approfondimenti sui costi delle prestazioni di CSS-in-JS.
- Trasmetti in streaming le risposte?
Spesso dimenticati e trascurati, i flussi forniscono un'interfaccia per leggere o scrivere blocchi di dati asincroni, di cui solo un sottoinsieme potrebbe essere disponibile in memoria in un dato momento. Fondamentalmente, consentono alla pagina che ha effettuato la richiesta originale di iniziare a lavorare con la risposta non appena è disponibile il primo blocco di dati e utilizzano parser ottimizzati per lo streaming per visualizzare progressivamente il contenuto.Potremmo creare un flusso da più fonti. Ad esempio, invece di servire una shell dell'interfaccia utente vuota e lasciare che JavaScript la popola, puoi lasciare che l'operatore del servizio costruisca un flusso in cui la shell proviene da una cache, ma il corpo proviene dalla rete. Come ha notato Jeff Posnick, se la tua app Web è alimentata da un CMS che esegue il rendering del server HTML unendo insieme modelli parziali, quel modello si traduce direttamente nell'utilizzo di risposte in streaming, con la logica del modello replicata nel lavoratore del servizio anziché nel tuo server. L'articolo The Year of Web Streams di Jake Archibald evidenzia come esattamente potresti costruirlo. L'aumento delle prestazioni è abbastanza evidente.
Un importante vantaggio dello streaming dell'intera risposta HTML è che l'HTML visualizzato durante la richiesta di navigazione iniziale può sfruttare appieno il parser HTML in streaming del browser. I blocchi di HTML inseriti in un documento dopo il caricamento della pagina (come è comune con i contenuti popolati tramite JavaScript) non possono trarre vantaggio da questa ottimizzazione.
Supporto del browser? Ci si arriva ancora con il supporto parziale in Chrome, Firefox, Safari ed Edge che supportano l'API e Service Workers supportati in tutti i browser moderni. E se ti senti di nuovo avventuroso, puoi controllare un'implementazione sperimentale delle richieste di streaming, che ti consente di iniziare a inviare la richiesta mentre continua a generare il corpo. Disponibile in Chrome 85.
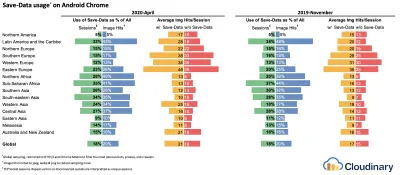
- Considera di rendere i tuoi componenti sensibili alla connessione.
I dati possono essere costosi e con il carico utile in aumento, dobbiamo rispettare gli utenti che scelgono di optare per il risparmio dei dati mentre accedono ai nostri siti o app. L'intestazione della richiesta di suggerimento client Save-Data ci consente di personalizzare l'applicazione e il carico utile per utenti con vincoli di costi e prestazioni.In effetti, è possibile riscrivere le richieste di immagini con DPI elevati in immagini DPI basse, rimuovere i caratteri Web, effetti di parallasse fantasiosi, visualizzare in anteprima le miniature e lo scorrimento infinito, disattivare la riproduzione automatica dei video, i push del server, ridurre il numero di elementi visualizzati e ridurre la qualità dell'immagine, oppure cambia anche il modo in cui fornisci il markup. Tim Vereecke ha pubblicato un articolo molto dettagliato sulle strategie di data-s(h)aver con molte opzioni per il salvataggio dei dati.
Chi sta usando
save-data, ti starai chiedendo? Il 18% degli utenti globali di Android Chrome ha la modalità Lite abilitata (con ilSave-Dataattivato) ed è probabile che il numero sia più alto. Secondo la ricerca di Simon Hearne, il tasso di adesione è più alto su dispositivi più economici, ma ci sono molti valori anomali. Ad esempio: gli utenti in Canada hanno un tasso di partecipazione di oltre il 34% (rispetto al 7% circa negli Stati Uniti) e gli utenti dell'ultima ammiraglia Samsung hanno un tasso di partecipazione di quasi il 18% a livello globale.Con la modalità
Save-Dataattiva, Chrome Mobile fornirà un'esperienza ottimizzata, ovvero un'esperienza Web proxy con script differiti ,font-display: swape caricamento lento forzato. È solo più sensato costruire l'esperienza da solo piuttosto che fare affidamento sul browser per effettuare queste ottimizzazioni.L'intestazione è attualmente supportata solo in Chromium, sulla versione Android di Chrome o tramite l'estensione Data Saver su un dispositivo desktop. Infine, puoi anche utilizzare l'API Network Information per fornire costosi moduli JavaScript, immagini e video ad alta risoluzione in base al tipo di rete. L'API Network Information e in particolare
navigator.connection.effectiveTypeutilizzano i valoriRTT,downlink,effectiveType(e pochi altri) per fornire una rappresentazione della connessione e dei dati che gli utenti possono gestire.In questo contesto, Max Bock parla di componenti sensibili alla connessione e Addy Osmani parla di servizio di moduli adattivi. Ad esempio, con React, potremmo scrivere un componente che esegue il rendering in modo diverso per diversi tipi di connessione. Come suggerito da Max, un componente
<Media />in un articolo di notizie potrebbe produrre:-
Offline: un segnaposto con testoalt, -
2G/ modalitàsave-data: un'immagine a bassa risoluzione, -
3Gsu schermo non retina: un'immagine a media risoluzione, -
3Gsu schermi Retina: immagine Retina ad alta risoluzione, -
4G: un video HD.
Dean Hume fornisce un'implementazione pratica di una logica simile utilizzando un operatore di servizio. Per un video, potremmo visualizzare un poster video per impostazione predefinita, quindi visualizzare l'icona "Riproduci" nonché la shell del lettore video, i metadati del video ecc. su connessioni migliori. Come ripiego per i browser non di supporto, potremmo ascoltare l'evento
canplaythroughe utilizzarePromise.race()per interrompere il caricamento del codice sorgente se l'eventocanplaythroughnon si attiva entro 2 secondi.Se vuoi approfondire un po', ecco un paio di risorse per iniziare:
- Addy Osmani mostra come implementare il servizio adattivo in React.
- React Adaptive Loading Hooks & Utilities fornisce frammenti di codice per React,
- Netanel Basel esplora i componenti Connection-Aware in Angular,
- Theodore Vorilas condivide il funzionamento del servizio di componenti adattivi utilizzando l'API di informazioni di rete in Vue.
- Umar Hansa mostra come scaricare/eseguire selettivamente JavaScript costoso.
-
- Prendi in considerazione l'idea di rendere i tuoi componenti sensibili alla memoria del dispositivo.
Tuttavia, la connessione di rete ci offre solo una prospettiva nel contesto dell'utente. Andando oltre, puoi anche regolare dinamicamente le risorse in base alla memoria del dispositivo disponibile, con l'API Device Memory.navigator.deviceMemoryreturns how much RAM the device has in gigabytes, rounded down to the nearest power of two. The API also features a Client Hints Header,Device-Memory, that reports the same value.Bonus : Umar Hansa shows how to defer expensive scripts with dynamic imports to change the experience based on device memory, network connectivity and hardware concurrency.
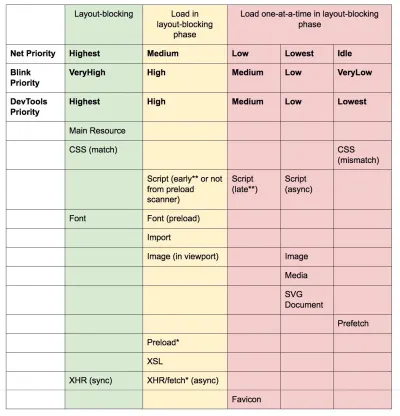
- Warm up the connection to speed up delivery.
Use resource hints to save time ondns-prefetch(which performs a DNS lookup in the background),preconnect(which asks the browser to start the connection handshake (DNS, TCP, TLS) in the background),prefetch(which asks the browser to request a resource) andpreload(which prefetches resources without executing them, among other things). Well supported in modern browsers, with support coming to Firefox soon.Remember
prerender? The resource hint used to prompt browser to build out the entire page in the background for next navigation. The implementations issues were quite problematic, ranging from a huge memory footprint and bandwidth usage to multiple registered analytics hits and ad impressions.Unsurprinsingly, it was deprecated, but the Chrome team has brought it back as NoState Prefetch mechanism. In fact, Chrome treats the
prerenderhint as a NoState Prefetch instead, so we can still use it today. As Katie Hempenius explains in that article, "like prerendering, NoState Prefetch fetches resources in advance ; but unlike prerendering, it does not execute JavaScript or render any part of the page in advance."NoState Prefetch only uses ~45MiB of memory and subresources that are fetched will be fetched with an
IDLENet Priority. Since Chrome 69, NoState Prefetch adds the header Purpose: Prefetch to all requests in order to make them distinguishable from normal browsing.Also, watch out for prerendering alternatives and portals, a new effort toward privacy-conscious prerendering, which will provide the inset
previewof the content for seamless navigations.Using resource hints is probably the easiest way to boost performance , and it works well indeed. When to use what? As Addy Osmani has explained, it's reasonable to preload resources that we know are very likely to be used on the current page and for future navigations across multiple navigation boundaries, eg Webpack bundles needed for pages the user hasn't visited yet.
Addy's article on "Loading Priorities in Chrome" shows how exactly Chrome interprets resource hints, so once you've decided which assets are critical for rendering, you can assign high priority to them. To see how your requests are prioritized, you can enable a "priority" column in the Chrome DevTools network request table (as well as Safari).
Most of the time these days, we'll be using at least
preconnectanddns-prefetch, and we'll be cautious with usingprefetch,preloadandprerender. Note that even withpreconnectanddns-prefetch, the browser has a limit on the number of hosts it will look up/connect to in parallel, so it's a safe bet to order them based on priority ( thanks Philip Tellis! ).Since fonts usually are important assets on a page, sometimes it's a good idea to request the browser to download critical fonts with
preload. However, double check if it actually helps performance as there is a puzzle of priorities when preloading fonts: aspreloadis seen as high importance, it can leapfrog even more critical resources like critical CSS. ( thanks, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Since
<link rel="preload">accepts amediaattribute, you could choose to selectively download resources based on@mediaquery rules, as shown above.Furthermore, we can use
imagesrcsetandimagesizesattributes to preload late-discovered hero images faster, or any images that are loaded via JavaScript, eg movie posters:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>We can also preload the JSON as fetch , so it's discovered before JavaScript gets to request it:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>We could also load JavaScript dynamically, effectively for lazy execution of the script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);A few gotchas to keep in mind:
preloadis good for moving the start download time of an asset closer to the initial request, but preloaded assets land in the memory cache which is tied to the page making the request.preloadplays well with the HTTP cache: a network request is never sent if the item is already there in the HTTP cache.Hence, it's useful for late-discovered resources, hero images loaded via
background-image, inlining critical CSS (or JavaScript) and pre-loading the rest of the CSS (or JavaScript).
Preload important images early; no need to wait on JavaScript to discover them. (Image credit: “Preload Late-Discovered Hero Images Faster” by Addy Osmani) (Large preview) A
preloadtag can initiate a preload only after the browser has received the HTML from the server and the lookahead parser has found thepreloadtag. Preloading via the HTTP header could be a bit faster since we don't to wait for the browser to parse the HTML to start the request (it's debated though).Early Hints will help even further, enabling preload to kick in even before the response headers for the HTML are sent (on the roadmap in Chromium, Firefox). Plus, Priority Hints will help us indicate loading priorities for scripts.
Beware : if you're using
preload,asmust be defined or nothing loads, plus preloaded fonts without thecrossoriginattribute will double fetch. If you're usingprefetch, beware of theAgeheader issues in Firefox.
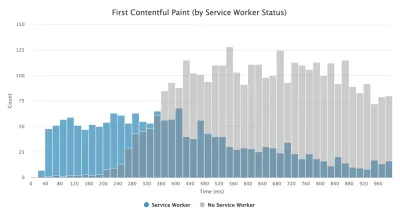
- Use service workers for caching and network fallbacks.
No performance optimization over a network can be faster than a locally stored cache on a user's machine (there are exceptions though). If your website is running over HTTPS, we can cache static assets in a service worker cache and store offline fallbacks (or even offline pages) and retrieve them from the user's machine, rather than going to the network.As suggested by Phil Walton, with service workers, we can send smaller HTML payloads by programmatically generating our responses. A service worker can request just the bare minimum of data it needs from the server (eg an HTML content partial, a Markdown file, JSON data, etc.), and then it can programmatically transform that data into a full HTML document. So once a user visits a site and the service worker is installed, the user will never request a full HTML page again. The performance impact can be quite impressive.
Browser support? Service workers are widely supported and the fallback is the network anyway. Does it help boost performance ? Oh yes, it does. And it's getting better, eg with Background Fetch allowing background uploads/downloads via a service worker as well.
There are a number of use cases for a service worker. For example, you could implement "Save for offline" feature, handle broken images, introduce messaging between tabs or provide different caching strategies based on request types. In general, a common reliable strategy is to store the app shell in the service worker's cache along with a few critical pages, such as offline page, frontpage and anything else that might be important in your case.
There are a few gotchas to keep in mind though. With a service worker in place, we need to beware range requests in Safari (if you are using Workbox for a service worker it has a range request module). If you ever stumbled upon
DOMException: Quota exceeded.error in the browser console, then look into Gerardo's article When 7KB equals 7MB.Come scrive Gerardo, "Se stai creando un'app Web progressiva e stai riscontrando un'archiviazione della cache gonfia quando il tuo addetto ai servizi memorizza nella cache le risorse statiche servite dalle CDN, assicurati che esista l'intestazione di risposta CORS corretta per le risorse multiorigine, non memorizzi nella cache le risposte opache con il tuo addetto ai servizi involontariamente, attivi le risorse immagine cross-origin in modalità CORS aggiungendo l'attributo
crossoriginal tag<img>".Ci sono molte ottime risorse per iniziare con gli addetti ai servizi:
- Service Worker Mindset, che ti aiuta a capire come lavorano gli operatori di servizio dietro le quinte e le cose da capire quando ne costruiscono uno.
- Chris Ferdinandi fornisce un'ampia serie di articoli sugli operatori del servizio, spiegando come creare applicazioni offline e coprendo una varietà di scenari, dal salvataggio offline delle pagine visualizzate di recente all'impostazione di una data di scadenza per gli elementi in una cache di un lavoratore del servizio.
- Insidie e best practice per gli operatori del servizio, con alcuni suggerimenti sull'ambito, il ritardo della registrazione di un lavoratore del servizio e la memorizzazione nella cache del lavoratore del servizio.
- Grande serie di Ire Aderinokun su "Offline First" con Service Worker, con una strategia sul precaching della shell dell'app.
- Service Worker: un'introduzione con suggerimenti pratici su come utilizzare Service Worker per esperienze offline avanzate, sincronizzazioni periodiche in background e notifiche push.
- Vale sempre la pena fare riferimento al buon vecchio libro di cucina offline di Jake Archibald con una serie di ricette su come cuocere il tuo personale di servizio.
- Workbox è un set di librerie di operatori di servizio create appositamente per la creazione di app Web progressive.
- Stai eseguendo server worker sulla CDN/Edge, ad esempio per test A/B?
A questo punto, siamo abbastanza abituati a eseguire i service worker sul client, ma con le CDN che li implementano sul server, potremmo usarli per modificare le prestazioni anche al limite.Ad esempio, nei test A/B, quando HTML deve variare il suo contenuto per utenti diversi, potremmo utilizzare Service Workers sui server CDN per gestire la logica. Potremmo anche eseguire lo streaming della riscrittura HTML per velocizzare i siti che utilizzano Google Fonts.
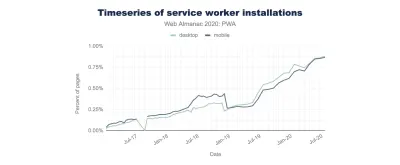
- Ottimizza le prestazioni di rendering.
Ogni volta che l'applicazione è lenta, si nota subito. Quindi dobbiamo assicurarci che non ci siano ritardi durante lo scorrimento della pagina o quando un elemento è animato e che stai raggiungendo costantemente 60 fotogrammi al secondo. Se ciò non è possibile, è preferibile almeno rendere coerenti i fotogrammi al secondo rispetto a un intervallo misto compreso tra 60 e 15. Usawill-changedei CSS per informare il browser di quali elementi e proprietà cambieranno.Ogni volta che si verificano, eseguire il debug di ridisegni non necessari in DevTools:
- Misura le prestazioni di rendering in runtime. Dai un'occhiata ad alcuni suggerimenti utili su come dargli un senso.
- Per iniziare, dai un'occhiata al corso gratuito Udacity di Paul Lewis sull'ottimizzazione del rendering del browser e all'articolo di Georgy Marchuk sulla pittura del browser e considerazioni per le prestazioni web.
- Abilita Paint Flashing in "Altri strumenti → Rendering → Paint Flashing" in Firefox DevTools.
- In React DevTools, seleziona "Evidenzia aggiornamenti" e abilita "Registra perché ogni componente è stato renderizzato",
- Puoi anche utilizzare Why Did You Render, quindi quando un componente viene rieseguito, un flash ti avviserà della modifica.
Stai usando un layout in muratura? Tieni presente che potrebbe essere in grado di costruire un layout in muratura con la sola griglia CSS, molto presto.
Se vuoi approfondire l'argomento, Nolan Lawson ha condiviso trucchi per misurare accuratamente le prestazioni del layout nel suo articolo e anche Jason Miller ha suggerito tecniche alternative. Abbiamo anche un piccolo articolo di Sergey Chikuyonok su come ottenere correttamente l'animazione della GPU.

I browser possono animare la trasformazione e l'opacità a buon mercato. Trigger CSS è utile per verificare se CSS attiva re-layout o reflow. (Credito immagine: Addy Osmani) (Anteprima grande) Nota : le modifiche ai livelli composti da GPU sono le meno costose, quindi se riesci a farla franca attivando solo la composizione tramite
opacityetransform, sarai sulla strada giusta. Anche Anna Migas ha fornito molti consigli pratici nel suo intervento sul debug delle prestazioni di rendering dell'interfaccia utente. E per capire come eseguire il debug delle prestazioni della vernice in DevTools, controlla il video di controllo delle prestazioni della vernice di Umar. - Hai ottimizzato per le prestazioni percepite?
Sebbene la sequenza di come i componenti appaiono sulla pagina e la strategia di come serviamo le risorse al browser sono importanti, non dovremmo sottovalutare anche il ruolo delle prestazioni percepite. Il concetto si occupa degli aspetti psicologici dell'attesa, fondamentalmente mantenendo i clienti occupati o coinvolti mentre sta accadendo qualcos'altro. È qui che entrano in gioco la gestione della percezione, l'avvio preventivo, il completamento anticipato e la gestione della tolleranza.Che cosa significa tutto questo? Durante il caricamento delle risorse, possiamo cercare di essere sempre un passo avanti rispetto al cliente, in modo che l'esperienza sia rapida mentre succedono molte cose in background. Per mantenere il cliente impegnato, possiamo testare schermate dello scheletro (demo di implementazione) invece di caricare indicatori, aggiungere transizioni/animazioni e sostanzialmente imbrogliare l'UX quando non c'è più niente da ottimizzare.
Nel loro caso di studio su The Art of UI Skeletons, Kumar McMillan condivide alcune idee e tecniche su come simulare elenchi dinamici, testo e schermo finale, oltre a come considerare il pensiero scheletrico con React.
Attenzione però: gli schermi dello scheletro devono essere testati prima dell'implementazione poiché alcuni test hanno dimostrato che gli schermi dello scheletro possono avere le prestazioni peggiori in base a tutte le metriche.
- Impedite spostamenti di layout e ridipinture?
Nel regno delle prestazioni percepite, probabilmente una delle esperienze più dirompenti è lo spostamento del layout , o reflow , causato da immagini e video ridimensionati, font Web, pubblicità iniettata o script scoperti in ritardo che popolano i componenti con contenuto reale. Di conseguenza, un cliente potrebbe iniziare a leggere un articolo solo per essere interrotto da un salto di layout sopra l'area di lettura. L'esperienza è spesso brusca e abbastanza disorientante: e questo è probabilmente un caso di priorità di caricamento che devono essere riconsiderate.La community ha sviluppato un paio di tecniche e soluzioni alternative per evitare reflow. In generale, è una buona idea evitare di inserire nuovi contenuti al di sopra dei contenuti esistenti , a meno che ciò non avvenga in risposta a un'interazione dell'utente. Imposta sempre gli attributi di larghezza e altezza sulle immagini, quindi i browser moderni assegnano la casella e riservano lo spazio per impostazione predefinita (Firefox, Chrome).
Sia per le immagini che per i video, possiamo utilizzare un segnaposto SVG per riservare la casella di visualizzazione in cui apparirà il file multimediale. Ciò significa che l'area verrà riservata correttamente quando è necessario mantenere anche le sue proporzioni. Possiamo anche utilizzare segnaposto o immagini di riserva per annunci e contenuti dinamici, nonché slot di layout preassegnati.
Invece di caricare lazy le immagini con script esterni, prendere in considerazione l'utilizzo del lazy-loading nativo o del lazy-loading ibrido quando carichiamo uno script esterno solo se il lazy-loading nativo non è supportato.
Come accennato in precedenza, raggruppa sempre i ridisegni dei caratteri Web e passa da tutti i caratteri di fallback a tutti i caratteri Web contemporaneamente: assicurati solo che il passaggio non sia troppo brusco, regolando l'altezza della linea e la spaziatura tra i caratteri con il font-style-matcher .
Per sovrascrivere le metriche dei caratteri per un carattere di riserva per emulare un carattere Web, possiamo utilizzare i descrittori @font-face per sovrascrivere le metriche dei caratteri (demo, abilitato in Chrome 87). (Si noti che le regolazioni sono complicate con pile di caratteri complicate.)
Per i CSS tardivi, possiamo garantire che i CSS critici per il layout siano integrati nell'intestazione di ciascun modello. Anche oltre: per le pagine lunghe, quando viene aggiunta la barra di scorrimento verticale, sposta il contenuto principale di 16px a sinistra. Per visualizzare una barra di scorrimento in anticipo, possiamo aggiungere
overflow-y: scrollsuhtmlper applicare una barra di scorrimento al primo disegno. Quest'ultimo aiuta perché le barre di scorrimento possono causare spostamenti di layout non banali a causa del riflusso del contenuto above the fold quando la larghezza cambia. Dovrebbe accadere principalmente su piattaforme con barre di scorrimento non sovrapposte come Windows. Ma: interrompe laposition: stickyperché quegli elementi non scorreranno mai fuori dal contenitore.Se hai a che fare con intestazioni che diventano fisse o posizionate appiccicose nella parte superiore della pagina durante lo scorrimento, riserva spazio per l'intestazione quando diventa sbiadita, ad esempio con un elemento segnaposto o un
margin-topsul contenuto. Un'eccezione dovrebbero essere i banner di consenso ai cookie che non dovrebbero avere impatto su CLS, ma a volte lo fanno: dipende dall'implementazione. Ci sono alcune strategie interessanti e takeaway in questo thread di Twitter.Per un componente di schede che potrebbe includere varie quantità di testo, puoi impedire i cambiamenti di layout con le pile di griglie CSS. Posizionando il contenuto di ciascuna scheda nella stessa area della griglia e nascondendone una alla volta, possiamo garantire che il contenitore occupi sempre l'altezza dell'elemento più grande, quindi non si verificheranno spostamenti di layout.
Ah, e, naturalmente, lo scorrimento infinito e "Carica altro" possono causare anche spostamenti di layout se c'è contenuto sotto l'elenco (es. piè di pagina). Per migliorare CLS, riserva spazio sufficiente per il contenuto che verrebbe caricato prima che l'utente scorri fino a quella parte della pagina, rimuovi il piè di pagina o qualsiasi elemento DOM nella parte inferiore della pagina che potrebbe essere spinto verso il basso dal caricamento del contenuto. Inoltre, precarica i dati e le immagini per i contenuti below-the-fold in modo che quando un utente scorre così lontano, è già lì. Puoi utilizzare le librerie di virtualizzazione degli elenchi come react-window per ottimizzare anche elenchi lunghi ( grazie, Addy Osmani! ).
Per garantire che l'impatto dei reflow sia contenuto, misurare la stabilità del layout con l'API Layout Instability. Con esso, puoi calcolare il punteggio Cumulative Layout Shift ( CLS ) e includerlo come requisito nei tuoi test, quindi ogni volta che viene visualizzata una regressione, puoi tracciarla e risolverla.
Per calcolare il punteggio di spostamento del layout, il browser esamina le dimensioni della finestra e il movimento degli elementi instabili nella finestra tra due fotogrammi renderizzati. Idealmente, il punteggio sarebbe vicino a
0. C'è un'ottima guida di Milica Mihajlija e Philip Walton su cos'è il CLS e come misurarlo. È un buon punto di partenza per misurare e mantenere le prestazioni percepite ed evitare interruzioni, soprattutto per le attività business-critical.Suggerimento rapido : per scoprire cosa ha causato un cambiamento di layout in DevTools, puoi esplorare i cambiamenti di layout in "Esperienza" nel pannello delle prestazioni.
Bonus : se vuoi ridurre i reflow e le ridipinture, controlla la guida di Charis Theodoulou per ridurre al minimo il DOM Reflow/Layout Thrashing e l'elenco di Paul Irish di What force layout / reflow così come CSSTriggers.com, una tabella di riferimento sulle proprietà CSS che attivano il layout, paint e compositing.
Reti e HTTP/2
- La pinzatura OCSP è abilitata?
Abilitando la pinzatura OCSP sul tuo server, puoi velocizzare i tuoi handshake TLS. L'Online Certificate Status Protocol (OCSP) è stato creato come alternativa al protocollo Certificate Revocation List (CRL). Entrambi i protocolli vengono utilizzati per verificare se un certificato SSL è stato revocato.Tuttavia, il protocollo OCSP non richiede al browser di dedicare tempo a scaricare e quindi cercare in un elenco le informazioni sui certificati, riducendo così il tempo necessario per un handshake.
- Hai ridotto l'impatto della revoca del certificato SSL?
Nel suo articolo su "The Performance Cost of EV Certificates", Simon Hearne fornisce un'ottima panoramica dei certificati comuni e dell'impatto che la scelta di un certificato può avere sulle prestazioni complessive.Come scrive Simon, nel mondo dell'HTTPS esistono alcuni tipi di livelli di convalida dei certificati utilizzati per proteggere il traffico:
- Domain Validation (DV) convalida che il richiedente del certificato possiede il dominio,
- La convalida dell'organizzazione (OV) convalida che un'organizzazione possiede il dominio,
- La convalida estesa (EV) convalida che un'organizzazione possiede il dominio, con una convalida rigorosa.
È importante notare che tutti questi certificati sono gli stessi in termini di tecnologia; differiscono solo per le informazioni e le proprietà fornite in tali certificati.
I certificati EV sono costosi e richiedono tempo in quanto richiedono a un essere umano di rivedere un certificato e garantirne la validità. I certificati DV, d'altra parte, sono spesso forniti gratuitamente, ad esempio da Let's Encrypt, un'autorità di certificazione aperta e automatizzata ben integrata in molti provider di hosting e CDN. In effetti, al momento in cui scriviamo, alimenta oltre 225 milioni di siti Web (PDF), sebbene rappresenti solo il 2,69% delle pagine (aperte in Firefox).
Allora qual è il problema? Il problema è che i certificati EV non supportano completamente la graffatura OCSP sopra menzionata. Mentre la pinzatura consente al server di verificare con l'Autorità di certificazione se il certificato è stato revocato e quindi aggiungere ("pinzatura") queste informazioni al certificato, senza pinzare il client deve fare tutto il lavoro, risultando in richieste non necessarie durante la negoziazione TLS . In caso di connessioni scadenti, ciò potrebbe comportare notevoli costi di prestazioni (oltre 1000 ms).
I certificati EV non sono un'ottima scelta per le prestazioni web e possono causare un impatto molto maggiore sulle prestazioni rispetto ai certificati DV. Per prestazioni Web ottimali, fornisci sempre un certificato DV pinzato OCSP. Sono anche molto più economici dei certificati EV e meno seccature da acquisire. Bene, almeno fino a quando CRLite non sarà disponibile.
La compressione è importante: il 40–43% delle catene di certificati non compresse è troppo grande per adattarsi a un singolo volo QUIC di 3 datagrammi UDP. (Credito immagine:) Velocemente) (Grande anteprima) Nota : con QUIC/HTTP/3 alle porte, vale la pena notare che la catena di certificati TLS è l'unico contenuto di dimensioni variabili che domina il conteggio dei byte nell'handshake QUIC. La dimensione varia tra poche centinaia di bye e oltre 10 KB.
Quindi mantenere i certificati TLS piccoli è molto importante su QUIC/HTTP/3, poiché i certificati di grandi dimensioni causeranno più handshake. Inoltre, dobbiamo assicurarci che i certificati siano compressi, altrimenti le catene di certificati sarebbero troppo grandi per adattarsi a un singolo volo QUIC.
Puoi trovare molti più dettagli e indicazioni al problema e alle soluzioni su:
- I certificati EV rendono il Web lento e inaffidabile di Aaron Peters,
- L'impatto della revoca del certificato SSL sulle prestazioni web da parte di Matt Hobbs,
- Il costo delle prestazioni dei certificati EV di Simon Hearne,
- L'handshake QUIC richiede una compressione veloce? di Patrick McManus.
- Hai già adottato IPv6?
Poiché lo spazio è esaurito con IPv4 e le principali reti mobili stanno adottando IPv6 rapidamente (gli Stati Uniti hanno quasi raggiunto una soglia di adozione di IPv6 del 50%), è una buona idea aggiornare il tuo DNS a IPv6 per rimanere a prova di proiettile per il futuro. Assicurati solo che il supporto dual-stack sia fornito attraverso la rete: consente a IPv6 e IPv4 di funzionare simultaneamente l'uno accanto all'altro. Dopotutto, IPv6 non è compatibile con le versioni precedenti. Inoltre, gli studi dimostrano che IPv6 ha reso questi siti Web dal 10 al 15% più veloci grazie alla scoperta dei vicini (NDP) e all'ottimizzazione del percorso. - Assicurati che tutte le risorse vengano eseguite su HTTP/2 (o HTTP/3).
Con Google che negli ultimi anni ha spinto verso un Web HTTPS più sicuro, il passaggio all'ambiente HTTP/2 è sicuramente un buon investimento. Infatti, secondo Web Almanac, il 64% di tutte le richieste viene già eseguito su HTTP/2.È importante capire che HTTP/2 non è perfetto e presenta problemi di priorità, ma è supportato molto bene; e, nella maggior parte dei casi, è meglio per te.
Un avvertimento: HTTP/2 Server Push è stato rimosso da Chrome, quindi se la tua implementazione si basa su Server Push, potrebbe essere necessario rivisitarlo. Invece, potremmo guardare gli Early Hints, che sono già integrati come esperimento in Fastly.
Se sei ancora in esecuzione su HTTP, l'attività più dispendiosa in termini di tempo sarà prima migrare a HTTPS, quindi regolare il processo di compilazione per soddisfare il multiplexing e la parallelizzazione HTTP/2. Portare HTTP/2 su Gov.uk è un fantastico case study su come fare proprio questo, trovare un modo attraverso CORS, SRI e WPT lungo il percorso. Per il resto di questo articolo, presupponiamo che tu stia passando o sia già passato a HTTP/2.
- Distribuire correttamente HTTP/2.
Anche in questo caso, servire le risorse su HTTP/2 può trarre vantaggio da una revisione parziale di come hai servito le risorse finora. Dovrai trovare un giusto equilibrio tra l'imballaggio dei moduli e il caricamento di molti piccoli moduli in parallelo. Alla fine della giornata, la migliore richiesta non è ancora la richiesta, tuttavia, l'obiettivo è trovare un buon equilibrio tra la prima rapida consegna degli asset e la memorizzazione nella cache.Da un lato, potresti voler evitare di concatenare del tutto le risorse, invece di scomporre l'intera interfaccia in tanti piccoli moduli, comprimerli come parte del processo di compilazione e caricarli in parallelo. Una modifica in un file non richiede il download dell'intero foglio di stile o JavaScript. Inoltre, riduce al minimo il tempo di analisi e mantiene bassi i payload delle singole pagine.
D'altra parte, l'imballaggio è ancora importante. Utilizzando molti piccoli script, la compressione complessiva ne risentirà e aumenterà il costo del recupero degli oggetti dalla cache. La compressione di un pacchetto di grandi dimensioni trarrà vantaggio dal riutilizzo del dizionario, mentre i pacchetti separati piccoli non lo faranno. C'è un lavoro standard per affrontarlo, ma per ora è lontano. In secondo luogo, i browser non sono ancora stati ottimizzati per tali flussi di lavoro. Ad esempio, Chrome attiverà le comunicazioni tra processi (IPC) lineari rispetto al numero di risorse, quindi includere centinaia di risorse avrà costi di runtime del browser.
Per ottenere i migliori risultati con HTTP/2, considera di caricare i CSS progressivamente, come suggerito da Jake Archibald di Chrome. Tuttavia, puoi provare a caricare i CSS progressivamente. In effetti, il CSS interno non blocca più il rendering per Chrome. Ma ci sono alcuni problemi di priorità, quindi non è così semplice, ma vale la pena sperimentare.
Potresti farla franca con la coalescenza della connessione HTTP/2, che ti consente di utilizzare il partizionamento orizzontale del dominio beneficiando di HTTP/2, ma raggiungerlo in pratica è difficile e, in generale, non è considerata una buona pratica. Inoltre, HTTP/2 e Integrità delle sottorisorse non vanno sempre d'accordo.
Cosa fare? Bene, se stai utilizzando HTTP/2, inviare circa 6-10 pacchetti sembra un compromesso decente (e non è male per i browser legacy). Sperimenta e misura per trovare il giusto equilibrio per il tuo sito web.
- Inviamo tutte le risorse su una singola connessione HTTP/2?
Uno dei principali vantaggi di HTTP/2 è che ci consente di inviare risorse via cavo su una singola connessione. Tuttavia, a volte potremmo aver fatto qualcosa di sbagliato, ad esempio avere un problema con CORS o configurato in modo errato l'attributocrossorigin, quindi il browser sarebbe costretto ad aprire una nuova connessione.Per verificare se tutte le richieste utilizzano una singola connessione HTTP/2 o qualcosa non è configurato correttamente, abilita la colonna "ID connessione" in DevTools → Rete. Ad esempio, qui tutte le richieste condividono la stessa connessione (286), tranne manifest.json, che ne apre una separata (451).
- I tuoi server e CDN supportano HTTP/2?
Server e CDN diversi (ancora) supportano HTTP/2 in modo diverso. Usa Confronto CDN per controllare le tue opzioni o cercare rapidamente le prestazioni dei tuoi server e le funzionalità che puoi aspettarti di essere supportate.Consulta l'incredibile ricerca di Pat Meenan sulle priorità HTTP/2 (video) e verifica il supporto del server per la definizione delle priorità HTTP/2. Secondo Pat, si consiglia di abilitare il controllo della congestione BBR e impostare
tcp_notsent_lowatsu 16 KB affinché la priorità HTTP/2 funzioni in modo affidabile su kernel Linux 4.9 e versioni successive ( grazie, Yoav! ). Andy Davies ha svolto una ricerca simile per la definizione delle priorità HTTP/2 su browser, CDN e servizi di hosting cloud.Mentre ci sei, ricontrolla se il tuo kernel supporta TCP BBR e abilitalo se possibile. Attualmente è utilizzato su Google Cloud Platform, Amazon Cloudfront, Linux (es. Ubuntu).
- È in uso la compressione HPACK?
Se stai utilizzando HTTP/2, verifica che i tuoi server implementino la compressione HPACK per le intestazioni di risposta HTTP per ridurre il sovraccarico non necessario. Alcuni server HTTP/2 potrebbero non supportare completamente la specifica, ad esempio HPACK. H2spec è un ottimo strumento (anche se molto tecnicamente dettagliato) per verificarlo. L'algoritmo di compressione di HPACK è piuttosto impressionante e funziona. - Assicurati che la sicurezza sul tuo server sia a prova di proiettile.
Tutte le implementazioni del browser di HTTP/2 vengono eseguite su TLS, quindi probabilmente vorrai evitare avvisi di sicurezza o alcuni elementi della tua pagina non funzionano. Ricontrolla che le tue intestazioni di sicurezza siano impostate correttamente, elimina le vulnerabilità note e controlla la tua configurazione HTTPS.Inoltre, assicurati che tutti i plug-in esterni e gli script di monitoraggio siano caricati tramite HTTPS, che non sia possibile eseguire script tra siti e che sia le intestazioni HTTP Strict Transport Security che le intestazioni dei criteri di sicurezza dei contenuti siano impostate correttamente.
- I tuoi server e CDN supportano HTTP/3?
Sebbene HTTP/2 abbia apportato una serie di significativi miglioramenti delle prestazioni al Web, ha anche lasciato una certa area di miglioramento, in particolare il blocco dell'intestazione in TCP, che era evidente su una rete lenta con una significativa perdita di pacchetti. HTTP/3 risolve definitivamente questi problemi (articolo).Per risolvere i problemi di HTTP/2, IETF, insieme a Google, Akamai e altri, ha lavorato su un nuovo protocollo che è stato recentemente standardizzato come HTTP/3.
Robin Marx ha spiegato molto bene HTTP/3 e la seguente spiegazione si basa sulla sua spiegazione. Nel suo nucleo, HTTP/3 è molto simile a HTTP/2 in termini di funzionalità, ma sotto il cofano funziona in modo molto diverso. HTTP/3 offre una serie di miglioramenti: handshake più veloci, migliore crittografia, flussi indipendenti più affidabili, migliore crittografia e controllo del flusso. Una differenza notevole è che HTTP/3 utilizza QUIC come livello di trasporto, con pacchetti QUIC incapsulati sopra i diagrammi UDP, anziché TCP.
QUIC integra completamente TLS 1.3 nel protocollo, mentre in TCP è sovrapposto. Nel tipico stack TCP, abbiamo alcuni tempi di andata e ritorno di sovraccarico perché TCP e TLS devono eseguire i propri handshake separati, ma con QUIC entrambi possono essere combinati e completati in un solo viaggio di andata e ritorno . Poiché TLS 1.3 ci consente di impostare chiavi di crittografia per una connessione successiva, dalla seconda connessione in poi, possiamo già inviare e ricevere dati a livello di applicazione nel primo round trip, che si chiama "0-RTT".
Inoltre, l'algoritmo di compressione dell'intestazione di HTTP/2 è stato interamente riscritto, insieme al suo sistema di definizione delle priorità. Inoltre, QUIC supporta la migrazione della connessione dal Wi-Fi alla rete cellulare tramite gli ID di connessione nell'intestazione di ciascun pacchetto QUIC. La maggior parte delle implementazioni viene eseguita nello spazio utente, non nello spazio del kernel (come avviene con TCP), quindi dovremmo aspettarci che il protocollo si evolva in futuro.
Tutto farebbe una grande differenza? Probabilmente sì, soprattutto influendo sui tempi di caricamento sui dispositivi mobili, ma anche sul modo in cui serviamo le risorse agli utenti finali. Mentre in HTTP/2, più richieste condividono una connessione, in HTTP/3 anche le richieste condividono una connessione ma trasmettono in modo indipendente, quindi un pacchetto eliminato non influisce più su tutte le richieste, ma solo su un flusso.
Ciò significa che mentre con un pacchetto JavaScript di grandi dimensioni l'elaborazione delle risorse verrà rallentata quando un flusso si interrompe, l'impatto sarà meno significativo quando più file vengono trasmessi in streaming in parallelo (HTTP/3). Quindi l'imballaggio è ancora importante .
HTTP/3 è ancora in lavorazione. Chrome, Firefox e Safari hanno già implementazioni. Alcuni CDN supportano già QUIC e HTTP/3. Alla fine del 2020, Chrome ha iniziato a distribuire HTTP/3 e IETF QUIC, e infatti tutti i servizi Google (Google Analytics, YouTube ecc.) sono già in esecuzione su HTTP/3. LiteSpeed Web Server supporta HTTP/3, ma né Apache, nginx o IIS lo supportano ancora, ma è probabile che cambi rapidamente nel 2021.
In conclusione : se hai un'opzione per utilizzare HTTP/3 sul server e sulla tua CDN, è probabilmente un'ottima idea farlo. Il vantaggio principale verrà dal recupero simultaneo di più oggetti, specialmente su connessioni ad alta latenza. Non lo sappiamo ancora con certezza poiché non ci sono molte ricerche fatte in quello spazio, ma i primi risultati sono molto promettenti.
Se vuoi approfondire le specifiche e i vantaggi del protocollo, ecco alcuni buoni punti di partenza da verificare:
- HTTP/3 Explained, uno sforzo collaborativo per documentare i protocolli HTTP/3 e QUIC. Disponibile in varie lingue, anche in PDF.
- Migliorare le prestazioni Web con HTTP/3 con Daniel Stenberg.
- Una guida accademica a QUIC con Robin Marx introduce i concetti di base dei protocolli QUIC e HTTP/3, spiega come HTTP/3 gestisce il blocco dell'intestazione e la migrazione delle connessioni e come HTTP/3 è progettato per essere sempreverde (grazie, Simon !).
- Puoi controllare se il tuo server è in esecuzione su HTTP/3 su HTTP3Check.net.
Test e monitoraggio
- Hai ottimizzato il flusso di lavoro di auditing?
Potrebbe non sembrare un grosso problema, ma avere le giuste impostazioni a portata di mano potrebbe farti risparmiare un bel po' di tempo nei test. Prendi in considerazione l'utilizzo di Alfred Workflow per WebPageTest di Tim Kadlec per inviare un test all'istanza pubblica di WebPageTest. In effetti, WebPageTest ha molte caratteristiche oscure, quindi prenditi il tempo necessario per imparare a leggere un grafico di visualizzazione a cascata di WebPageTest e come leggere un grafico di visualizzazione di connessione di WebPageTest per diagnosticare e risolvere più rapidamente i problemi di prestazioni.Puoi anche guidare WebPageTest da un foglio di calcolo di Google e incorporare accessibilità, prestazioni e punteggi SEO nella tua configurazione di Travis con Lighthouse CI o direttamente in Webpack.
Dai un'occhiata a AutoWebPerf recentemente rilasciato, uno strumento modulare che consente la raccolta automatica di dati sulle prestazioni da più origini. Ad esempio, potremmo impostare un test giornaliero sulle tue pagine critiche per acquisire i dati sul campo dall'API CrUX e i dati di laboratorio da un report Lighthouse di PageSpeed Insights.
E se hai bisogno di eseguire rapidamente il debug di qualcosa ma il tuo processo di compilazione sembra essere notevolmente lento, tieni presente che "la rimozione degli spazi bianchi e la manipolazione dei simboli rappresentano il 95% della riduzione delle dimensioni nel codice minimizzato per la maggior parte di JavaScript, non elaborare le trasformazioni del codice. Puoi disabilita semplicemente la compressione per velocizzare le build di Uglify da 3 a 4 volte."
- Hai testato in browser proxy e browser legacy?
I test su Chrome e Firefox non sono sufficienti. Guarda come funziona il tuo sito web nei browser proxy e nei browser legacy. UC Browser e Opera Mini, ad esempio, detengono una quota di mercato significativa in Asia (fino al 35% in Asia). Misura la velocità media di Internet nei tuoi paesi di interesse per evitare grandi sorprese lungo la strada. Testare con la limitazione della rete ed emulare un dispositivo con DPI elevati. BrowserStack è fantastico per i test su dispositivi reali remoti e integralo anche con almeno alcuni dispositivi reali nel tuo ufficio: ne vale la pena.
- Hai testato le prestazioni delle tue 404 pagine?
Normalmente non ci pensiamo due volte quando si tratta di 404 pagine. Dopotutto, quando un client richiede una pagina che non esiste sul server, il server risponderà con un codice di stato 404 e la pagina 404 associata. Non c'è molto da fare, vero?Un aspetto importante di 404 risposte è la dimensione effettiva del corpo della risposta che viene inviata al browser. Secondo la ricerca di 404 pagine di Matt Hobbs, la stragrande maggioranza delle 404 risposte proviene da favicon mancanti, richieste di caricamento di WordPress, richieste JavaScript non funzionanti, file manifest nonché file CSS e font. Ogni volta che un cliente richiede una risorsa che non esiste, riceverà una risposta 404 e spesso tale risposta è enorme.
Assicurati di esaminare e ottimizzare la strategia di memorizzazione nella cache per le tue 404 pagine. Il nostro obiettivo è fornire HTML al browser solo quando si aspetta una risposta HTML e restituire un piccolo errore di payload per tutte le altre risposte. Secondo Matt, "se mettiamo una CDN davanti alla nostra origine, abbiamo la possibilità di memorizzare nella cache la risposta della pagina 404 sulla CDN. Questo è utile perché senza di essa, colpire una pagina 404 potrebbe essere utilizzato come vettore di attacco DoS, da costringendo il server di origine a rispondere a ogni richiesta 404 anziché lasciare che la CDN risponda con una versione memorizzata nella cache."
Gli errori 404 non solo possono danneggiare le tue prestazioni, ma possono anche costare traffico, quindi è una buona idea includere una pagina di errore 404 nella suite di test di Lighthouse e tenerne traccia nel tempo.
- Hai testato le prestazioni delle tue richieste di consenso GDPR?
In tempi di GDPR e CCPA, è diventato comune affidarsi a terze parti per fornire opzioni ai clienti dell'UE per accettare o rifiutare il monitoraggio. Tuttavia, come con qualsiasi altro script di terze parti, le loro prestazioni possono avere un impatto piuttosto devastante sull'intero sforzo di prestazioni.Naturalmente, è probabile che il consenso effettivo cambi l'impatto degli script sulle prestazioni complessive, quindi, come ha notato Boris Schapira, potremmo voler studiare alcuni profili di prestazioni web diversi:
- Il consenso è stato completamente rifiutato,
- Il consenso è stato parzialmente rifiutato,
- Il consenso è stato interamente dato.
- L'utente non ha agito alla richiesta di consenso (o la richiesta è stata bloccata da un blocco dei contenuti),
Normalmente le richieste di consenso ai cookie non dovrebbero avere un impatto su CLS, ma a volte lo fanno, quindi prendi in considerazione l'utilizzo di opzioni gratuite e open source Osano o cookie-consent-box.
In generale, vale la pena esaminare le prestazioni del popup poiché sarà necessario determinare l'offset orizzontale o verticale dell'evento del mouse e posizionare correttamente il popup rispetto all'ancora. Noam Rosenthal condivide gli insegnamenti del team di Wikimedia nell'articolo Case study sulle prestazioni Web: anteprime della pagina di Wikipedia (disponibili anche come video e minuti).
- Mantieni un CSS di diagnostica delle prestazioni?
Sebbene possiamo includere tutti i tipi di controlli per garantire che il codice non performante venga distribuito, spesso è utile avere una rapida idea di alcuni dei frutti a basso impatto che potrebbero essere risolti facilmente. Per questo, potremmo usare il brillante Performance Diagnostics CSS di Tim Kadlec (ispirato allo snippet di Harry Roberts che mette in evidenza immagini caricate pigre, immagini non dimensionate, immagini in formato legacy e script sincroni.Ad esempio, potresti voler assicurarti che nessuna immagine above the fold venga caricata in modo pigro. È possibile personalizzare lo snippet in base alle proprie esigenze, ad esempio per evidenziare i caratteri Web non utilizzati o per rilevare i caratteri delle icone. Un piccolo grande strumento per garantire che gli errori siano visibili durante il debug o semplicemente per controllare il progetto corrente molto rapidamente.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Have you tested the impact on accessibility?
When the browser starts to load a page, it builds a DOM, and if there is an assistive technology like a screen reader running, it also creates an accessibility tree. The screen reader then has to query the accessibility tree to retrieve the information and make it available to the user — sometimes by default, and sometimes on demand. And sometimes it takes time.When talking about fast Time to Interactive, usually we mean an indicator of how soon a user can interact with the page by clicking or tapping on links and buttons. The context is slightly different with screen readers. In that case, fast Time to Interactive means how much time passes by until the screen reader can announce navigation on a given page and a screen reader user can actually hit keyboard to interact.
Leonie Watson has given an eye-opening talk on accessibility performance and specifically the impact slow loading has on screen reader announcement delays. Screen readers are used to fast-paced announcements and quick navigation, and therefore might potentially be even less patient than sighted users.
Large pages and DOM manipulations with JavaScript will cause delays in screen reader announcements. A rather unexplored area that could use some attention and testing as screen readers are available on literally every platform (Jaws, NVDA, Voiceover, Narrator, Orca).
- Is continuous monitoring set up?
Having a private instance of WebPagetest is always beneficial for quick and unlimited tests. However, a continuous monitoring tool — like Sitespeed, Calibre and SpeedCurve — with automatic alerts will give you a more detailed picture of your performance. Set your own user-timing marks to measure and monitor business-specific metrics. Also, consider adding automated performance regression alerts to monitor changes over time.Look into using RUM-solutions to monitor changes in performance over time. For automated unit-test-alike load testing tools, you can use k6 with its scripting API. Also, look into SpeedTracker, Lighthouse and Calibre.
Vittorie veloci
This list is quite comprehensive, and completing all of the optimizations might take quite a while. So, if you had just 1 hour to get significant improvements, what would you do? Let's boil it all down to 17 low-hanging fruits . Obviously, before you start and once you finish, measure results, including Largest Contentful Paint and Time To Interactive on a 3G and cable connection.
- Measure the real world experience and set appropriate goals. Aim to be at least 20% faster than your fastest competitor. Stay within Largest Contentful Paint < 2.5s, a First Input Delay < 100ms, Time to Interactive < 5s on slow 3G, for repeat visits, TTI < 2s. Optimize at least for First Contentful Paint and Time To Interactive.
- Optimize images with Squoosh, mozjpeg, guetzli, pingo and SVGOMG, and serve AVIF/WebP with an image CDN.
- Prepare critical CSS for your main templates, and inline them in the
<head>of each template. For CSS/JS, operate within a critical file size budget of max. 170KB gzipped (0.7MB decompressed). - Trim, optimize, defer and lazy-load scripts. Invest in the config of your bundler to remove redundancies and check lightweight alternatives.
- Always self-host your static assets and always prefer to self-host third-party assets. Limit the impact of third-party scripts. Use facades, load widgets on interaction and beware of anti-flicker snippets.
- Be selective when choosing a framework. For single-page-applications, identify critical pages and serve them statically, or at least prerender them, and use progressive hydration on component-level and import modules on interaction.
- Client-side rendering alone isn't a good choice for performance. Prerender if your pages don't change much, and defer the booting of frameworks if you can. If possible, use streaming server-side rendering.
- Serve legacy code only to legacy browsers with
<script type="module">and module/nomodule pattern. - Experiment with regrouping your CSS rules and test in-body CSS.
- Add resource hints to speed up delivery with faster
dns-lookup,preconnect,prefetch,preloadandprerender. - Subset web fonts and load them asynchronously, and utilize
font-displayin CSS for fast first rendering. - Check that HTTP cache headers and security headers are set properly.
- Enable Brotli compression on the server. (If that's not possible, at least make sure that Gzip compression is enabled.)
- Enable TCP BBR congestion as long as your server is running on the Linux kernel version 4.9+.
- Enable OCSP stapling and IPv6 if possible. Always serve an OCSP stapled DV certificate.
- Enable HPACK compression for HTTP/2 and move to HTTP/3 if it's available.
- Cache assets such as fonts, styles, JavaScript and images in a service worker cache.
Download The Checklist (PDF, Apple Pages)
With this checklist in mind, you should be prepared for any kind of front-end performance project. Feel free to download the print-ready PDF of the checklist as well as an editable Apple Pages document to customize the checklist for your needs:
- Download the checklist PDF (PDF, 166 KB)
- Download the checklist in Apple Pages (.pages, 275 KB)
- Download the checklist in MS Word (.docx, 151 KB)
If you need alternatives, you can also check the front-end checklist by Dan Rublic, the "Designer's Web Performance Checklist" by Jon Yablonski and the FrontendChecklist.
Si parte!
Some of the optimizations might be beyond the scope of your work or budget or might just be overkill given the legacy code you have to deal with. That's fine! Use this checklist as a general (and hopefully comprehensive) guide, and create your own list of issues that apply to your context. But most importantly, test and measure your own projects to identify issues before optimizing. Happy performance results in 2021, everyone!
A huge thanks to Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov and Rodney Rehm for reviewing this article, as well as our fantastic community which has shared techniques and lessons learned from its work in performance optimization for everybody to use. Sei davvero strepitoso!