
Test traballanti: sbarazzarsi di un incubo vivente nei test
Pubblicato: 2022-03-10C'è una favola a cui penso molto in questi giorni. La favola mi è stata raccontata da bambino. Si chiama "Il ragazzo che gridò al lupo" di Esopo. Parla di un ragazzo che si prende cura delle pecore del suo villaggio. Si annoia e finge che un lupo stia attaccando il gregge, chiedendo aiuto agli abitanti del villaggio, solo per rendersi conto con delusione che si tratta di un falso allarme e lasciare il ragazzo in pace. Quindi, quando appare effettivamente un lupo e il ragazzo chiede aiuto, gli abitanti del villaggio credono che sia un altro falso allarme e non vengono in soccorso, e le pecore finiscono per essere mangiate dal lupo.
La morale della storia è meglio riassunta dall'autore stesso:
“Non si crederà a un bugiardo, anche quando dice la verità”.
Un lupo attacca la pecora e il ragazzo chiede aiuto, ma dopo numerose bugie nessuno gli crede più. Questa morale può essere applicata alla prova: la storia di Esopo è una bella allegoria per uno schema di corrispondenza in cui mi sono imbattuto: prove traballanti che non forniscono alcun valore.
Test front-end: perché anche preoccuparsi?
Trascorro la maggior parte delle mie giornate in test front-end. Quindi non dovrebbe sorprenderti che gli esempi di codice in questo articolo provengano principalmente dai test front-end che ho riscontrato nel mio lavoro. Tuttavia, nella maggior parte dei casi, possono essere facilmente tradotti in altre lingue e applicati ad altri framework. Quindi, spero che l'articolo ti sia utile, qualunque sia la tua esperienza.
Vale la pena ricordare cosa significa test front-end. Nella sua essenza, il test front-end è un insieme di pratiche per testare l'interfaccia utente di un'applicazione Web, inclusa la sua funzionalità.
Iniziando come ingegnere della garanzia della qualità, conosco il dolore degli infiniti test manuali da una lista di controllo subito prima di un rilascio. Quindi, oltre all'obiettivo di garantire che un'applicazione rimanga priva di errori durante gli aggiornamenti successivi, ho cercato di alleviare il carico di lavoro dei test causati da quelle attività di routine per le quali in realtà non è necessario un essere umano. Ora, come sviluppatore, trovo che l'argomento sia ancora rilevante, soprattutto perché cerco di aiutare direttamente utenti e colleghi allo stesso modo. E c'è un problema con i test in particolare che ci ha dato incubi.
La scienza dei test traballanti
Un test traballante è quello che non riesce a produrre lo stesso risultato ogni volta che viene eseguita la stessa analisi. La build fallirà solo occasionalmente: una volta passerà, un'altra fallirà, la prossima volta passerà di nuovo, senza che siano state apportate modifiche alla build.
Quando ricordo i miei incubi di test, mi viene in mente un caso in particolare. Era in un test dell'interfaccia utente. Abbiamo costruito una casella combinata personalizzata (cioè un elenco selezionabile con campo di input):
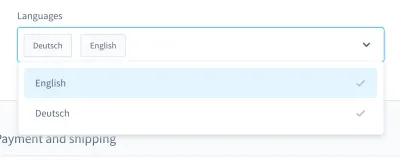
Con questa casella combinata, puoi cercare un prodotto e selezionare uno o più risultati. Per molti giorni questo test è andato bene, ma a un certo punto le cose sono cambiate. In una delle circa dieci build del nostro sistema di integrazione continua (CI), il test per la ricerca e la selezione di un prodotto in questa casella combinata non è riuscito.
Lo screenshot del fail mostra che l'elenco dei risultati non viene filtrato, nonostante la ricerca sia andata a buon fine:
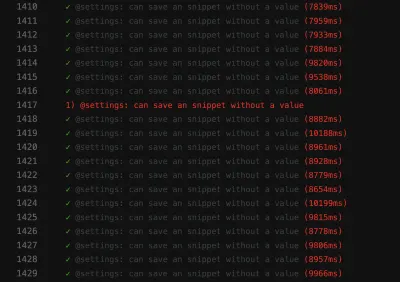
Un test instabile come questo può bloccare la pipeline di distribuzione continua , rendendo la distribuzione delle funzionalità più lenta del necessario. Inoltre, un test traballante è problematico perché non è più deterministico, il che lo rende inutile. Dopotutto, non ti fideresti di uno più di quanto ti fideresti di un bugiardo.
Inoltre, i test instabili sono costosi da riparare e spesso richiedono ore o addirittura giorni per il debug. Anche se i test end-to-end sono più inclini a essere traballanti, li ho sperimentati in tutti i tipi di test: test unitari, test funzionali, test end-to-end e tutto il resto.
Un altro problema significativo con i test traballanti è l'atteggiamento che instillano in noi sviluppatori. Quando ho iniziato a lavorare nell'automazione dei test, ho sentito spesso gli sviluppatori dire questo in risposta a un test fallito:
“Ah, quella build. Non importa, basta ricominciare. Alla fine passerà, da qualche parte".
Questa è un'enorme bandiera rossa per me . Mi mostra che l'errore nella build non verrà preso sul serio. Si presume che un test traballante non sia un vero bug, ma sia "solo" traballante, senza che sia necessario occuparsene o addirittura eseguirne il debug. Il test passerà comunque più tardi, giusto? No! Se un tale commit viene unito, nel peggiore dei casi avremo un nuovo test traballante nel prodotto.
Le cause
Quindi, i test traballanti sono problematici. Cosa dobbiamo fare per loro? Bene, se conosciamo il problema, possiamo progettare una contro-strategia.
Mi capita spesso di incontrare cause nella vita di tutti i giorni. Possono essere trovati all'interno dei test stessi . I test potrebbero essere scritti in modo non ottimale, contenere presupposti errati o contenere pratiche scorrette. Tuttavia, non solo. I test traballanti possono essere un'indicazione di qualcosa di molto peggio.
Nelle sezioni seguenti, esamineremo quelli più comuni che ho incontrato.
1. Cause lato test
In un mondo ideale, lo stato iniziale della tua applicazione dovrebbe essere immacolato e prevedibile al 100%. In realtà, non sai mai se l'ID che hai utilizzato nel test sarà sempre lo stesso.
Esaminiamo due esempi di un singolo errore da parte mia. L'errore numero uno è stato usare un ID nei miei dispositivi di prova:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }L'errore numero due è stato cercare un selettore univoco da utilizzare in un test dell'interfaccia utente e pensare: "Ok, questo ID sembra unico. Lo userò.”
<!-- This is a text field I took from a project I worked on --> <input type="text" />Tuttavia, se eseguissi il test su un'altra installazione o, in seguito, su più build in CI, tali test potrebbero non riuscire. La nostra applicazione genererebbe nuovamente gli ID, modificandoli tra le build. Quindi, la prima possibile causa è da ricercare negli ID hardcoded .
La seconda causa può derivare da dati demo generati casualmente (o in altro modo). Certo, potresti pensare che questo "difetto" sia giustificato - dopotutto, la generazione dei dati è casuale - ma pensa al debug di questi dati. Può essere molto difficile vedere se un bug è nei test stessi o nei dati demo.
Il prossimo è una causa lato test con cui ho lottato numerose volte: test con dipendenze incrociate . Alcuni test potrebbero non essere in grado di essere eseguiti in modo indipendente o in ordine casuale, il che è problematico. Inoltre, i test precedenti potrebbero interferire con quelli successivi. Questi scenari possono causare test traballanti introducendo effetti collaterali.
Tuttavia, non dimenticare che i test riguardano ipotesi sfidanti. Cosa succede se le tue ipotesi sono errate tanto per cominciare? L'ho sperimentato spesso, il mio preferito sono i presupposti errati sul tempo.
Un esempio è l'utilizzo di tempi di attesa imprecisi, in particolare nei test dell'interfaccia utente, ad esempio utilizzando tempi di attesa fissi . La riga seguente è tratta da un test di Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Un'altra ipotesi sbagliata riguarda il tempo stesso. Una volta ho scoperto che un test PHPUnit traballante stava fallendo solo nelle nostre build notturne. Dopo un po' di debug, ho scoperto che il colpevole era lo sfasamento temporale tra ieri e oggi. Un altro buon esempio sono i fallimenti dovuti ai fusi orari .
I falsi presupposti non si fermano qui. Possiamo anche avere ipotesi sbagliate sull'ordine dei dati . Immagina una griglia o un elenco contenente più voci con informazioni, come un elenco di valute:
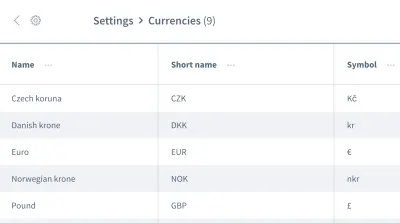
Vogliamo lavorare con le informazioni della prima voce, la valuta "Corona ceca". Puoi essere sicuro che la tua applicazione collocherà sempre questo dato come prima voce ogni volta che viene eseguito il test? Potrebbe essere che l'"Euro" o un'altra valuta sarà la prima voce in alcune occasioni?
Non dare per scontato che i tuoi dati arriveranno nell'ordine in cui ne hai bisogno. Simile agli ID hardcoded, un ordine può cambiare tra build, a seconda del design dell'applicazione.
2. Cause lato ambiente
La prossima categoria di cause riguarda tutto ciò che è al di fuori dei tuoi test. In particolare, stiamo parlando dell'ambiente in cui vengono eseguiti i test, delle dipendenze relative a CI e docker al di fuori dei test, tutte cose che puoi a malapena influenzare, almeno nel tuo ruolo di tester.
Una causa comune lato ambiente sono le perdite di risorse : spesso si tratta di un'applicazione sotto carico, che causa tempi di caricamento variabili o comportamenti imprevisti. Test di grandi dimensioni possono facilmente causare perdite, consumando molta memoria. Un altro problema comune è la mancanza di pulizia .
L'incompatibilità tra le dipendenze mi dà gli incubi in particolare. Si è verificato un incubo quando stavo lavorando con Nightwatch.js per i test dell'interfaccia utente. Nightwatch.js utilizza WebDriver, che ovviamente dipende da Chrome. Quando Chrome è andato avanti con un aggiornamento, si è verificato un problema con la compatibilità: Chrome, WebDriver e Nightwatch.js stesso non funzionavano più insieme, il che causava il fallimento delle nostre build di tanto in tanto.
A proposito di dipendenze : una menzione d'onore va a qualsiasi problema di npm, come autorizzazioni mancanti o npm inattivo. Ho sperimentato tutto questo osservando CI.
Quando si tratta di errori nei test dell'interfaccia utente dovuti a problemi ambientali, tenere presente che è necessario l'intero stack dell'applicazione per poter essere eseguiti. Più cose sono coinvolte, maggiore è il potenziale di errore . I test JavaScript sono, quindi, i test più difficili da stabilizzare nello sviluppo web, perché coprono una grande quantità di codice.
3. Cause lato prodotto
Ultimo ma non meno importante, dobbiamo davvero stare attenti a questa terza area, un'area con veri bug. Sto parlando di cause di sfaldamento lato prodotto. Uno degli esempi più noti sono le condizioni di gara in un'applicazione. Quando ciò accade, il bug deve essere corretto nel prodotto, non nel test! Cercare di correggere il test o l'ambiente non avrà alcuna utilità in questo caso.
Modi per combattere la fragilità
Abbiamo identificato tre cause di desquamazione. Possiamo costruire la nostra controstrategia su questo! Ovviamente, avrai già guadagnato molto tenendo a mente le tre cause quando incontrerai test traballanti. Saprai già cosa cercare e come migliorare i test. Tuttavia, oltre a questo, ci sono alcune strategie che ci aiuteranno a progettare, scrivere ed eseguire il debug dei test e le esamineremo insieme nelle sezioni seguenti.
Concentrati sulla tua squadra
La tua squadra è probabilmente il fattore più importante . Come primo passo, ammetti di avere un problema con i test traballanti. Ottenere l'impegno di tutta la squadra è fondamentale! Quindi, come squadra, devi decidere come affrontare i test traballanti.
Durante gli anni in cui ho lavorato nella tecnologia, mi sono imbattuto in quattro strategie utilizzate dai team per contrastare la fragilità:

- Non fare nulla e accettare il risultato traballante del test.
Naturalmente, questa strategia non è affatto una soluzione. Il test non darà alcun valore perché non puoi più fidarti di esso, anche se accetti la debolezza. Quindi possiamo saltare questo abbastanza rapidamente. - Riprova il test finché non passa.
Questa strategia era comune all'inizio della mia carriera, risultando nella risposta che ho menzionato prima. C'è stata una certa accettazione con la ripetizione dei test fino al superamento. Questa strategia non richiede il debug, ma è pigra. Oltre a nascondere i sintomi del problema, rallenterà ulteriormente la tua suite di test, il che rende la soluzione non praticabile. Tuttavia, potrebbero esserci delle eccezioni a questa regola, che spiegherò più avanti. - Elimina e dimentica il test.
Questo è autoesplicativo: elimina semplicemente il test traballante, in modo che non disturbi più la tua suite di test. Certo, ti farà risparmiare denaro perché non avrai più bisogno di eseguire il debug e correggere il test. Ma va a scapito della perdita di un po' di copertura dei test e della perdita di potenziali correzioni di bug. Il test esiste per un motivo! Non sparare al messenger cancellando il test. - Metti in quarantena e ripara.
Ho avuto più successo con questa strategia. In questo caso, salteremo temporaneamente il test e faremo in modo che la suite di test ci ricordi costantemente che un test è stato saltato. Per assicurarci che la correzione non venga trascurata, pianificheremo un biglietto per il prossimo sprint. Anche i promemoria dei bot funzionano bene. Una volta risolto il problema che causava la flakiness, integreremo (cioè annulleremo) il test di nuovo. Sfortunatamente, perderemo temporaneamente la copertura, ma tornerà con una correzione, quindi non ci vorrà molto.
Queste strategie ci aiutano ad affrontare i problemi di test a livello di flusso di lavoro e non sono l'unico ad averli incontrati. Nel suo articolo, Sam Saffron giunge alla conclusione simile. Ma nel nostro lavoro quotidiano, ci aiutano in misura limitata. Quindi, come procediamo quando un tale compito ci viene incontro?
Mantieni i test isolati
Quando pianifichi i test case e la struttura, mantieni sempre i test isolati dagli altri test, in modo che possano essere eseguiti in un ordine indipendente o casuale. Il passaggio più importante è ripristinare un'installazione pulita tra i test . Inoltre, verifica solo il flusso di lavoro che desideri testare e crea dati fittizi solo per il test stesso. Un altro vantaggio di questa scorciatoia è che migliorerà le prestazioni del test . Se segui questi punti, nessun effetto collaterale di altri test o dati rimanenti si intrometterà.
L'esempio seguente è tratto dai test dell'interfaccia utente di una piattaforma di e-commerce e si occupa del login del cliente nella vetrina del negozio. (Il test è scritto in JavaScript, utilizzando il framework Cypress.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): Il primo passaggio consiste nel ripristinare l'applicazione su un'installazione pulita. Viene eseguito come primo passaggio nell'hook del ciclo di vita beforeEach per assicurarsi che il ripristino venga eseguito in ogni occasione. Successivamente, i dati del test vengono creati appositamente per il test: per questo test case, verrebbe creato un cliente tramite un comando personalizzato. Successivamente, possiamo iniziare con l'unico flusso di lavoro che vogliamo testare: il login del cliente.
Ottimizza ulteriormente la struttura del test
Possiamo apportare altre piccole modifiche per rendere più stabile la nostra struttura di test. Il primo è abbastanza semplice: inizia con test più piccoli. Come detto prima, più fai in un test, più può andare storto. Mantieni i test il più semplici possibile ed evita molta logica in ciascuno di essi.
Quando si tratta di non assumere un ordine di dati (ad esempio, quando si ha a che fare con l' ordine delle voci in un elenco nei test dell'interfaccia utente), possiamo progettare un test per funzionare indipendentemente da qualsiasi ordine. Per riportare l'esempio della griglia con le informazioni al suo interno, non useremmo pseudo-selettori o altri CSS che hanno una forte dipendenza dall'ordine. Invece del selettore nth-child(3) , potremmo usare testo o altre cose per le quali l'ordine non ha importanza. Ad esempio, potremmo usare un'asserzione come "Trovami l'elemento con questa stringa di testo in questa tabella".
Attesa! I tentativi di test a volte vanno bene?
Ritentare i test è un argomento controverso, e giustamente. Lo considero ancora un anti-modello se il test viene ripetuto alla cieca fino a quando non ha successo. Tuttavia, esiste un'importante eccezione: quando non è possibile controllare gli errori, riprovare può essere l'ultima risorsa (ad esempio, per escludere errori dalle dipendenze esterne). In questo caso, non possiamo influenzare la fonte dell'errore. Tuttavia, fai molta attenzione quando esegui questa operazione: non diventare cieco di fronte alla sfarfallio quando ripeti un test e usa le notifiche per ricordarti quando un test viene saltato.
L'esempio seguente è quello che ho usato nel nostro CI con GitLab. Altri ambienti potrebbero avere una sintassi diversa per ottenere nuovi tentativi, ma questo dovrebbe darti un assaggio:
test: script: rspec retry: max: 2 when: runner_system_failureIn questo esempio, stiamo configurando il numero di tentativi da eseguire se il lavoro non riesce. Ciò che è interessante è la possibilità di riprovare se si verifica un errore nel sistema del corridore (ad esempio, l'impostazione del lavoro non è riuscita). Scegliamo di riprovare il nostro lavoro solo se qualcosa nella configurazione della finestra mobile non riesce.
Si noti che questo ritenterà l'intero lavoro quando attivato. Se desideri riprovare solo il test difettoso, dovrai cercare una funzionalità nel tuo framework di test per supportarlo. Di seguito è riportato un esempio di Cypress, che ha supportato la ripetizione di un singolo test dalla versione 5:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Puoi attivare i tentativi di prova nel file di configurazione di Cypress, cypress.json . Lì puoi definire i tentativi di ripetizione nel test runner e in modalità headless.
Utilizzo di tempi di attesa dinamici
Questo punto è importante per tutti i tipi di test, ma soprattutto per i test dell'interfaccia utente. Non posso sottolinearlo abbastanza: non usare mai tempi di attesa fissi , almeno non senza una buona ragione. Se lo fai, considera i possibili risultati. Nel migliore dei casi, sceglierai tempi di attesa troppo lunghi, rendendo la suite di test più lenta del necessario. Nel peggiore dei casi, non aspetterai abbastanza a lungo, quindi il test non procederà perché l'applicazione non è ancora pronta, causando il fallimento del test in modo traballante. Nella mia esperienza, questa è la causa più comune di test traballanti.
Utilizzare invece tempi di attesa dinamici. Ci sono molti modi per farlo, ma Cypress li gestisce particolarmente bene.
Tutti i comandi Cypress possiedono un metodo di attesa implicito: controllano già se l'elemento a cui viene applicato il comando esiste nel DOM per il tempo specificato, indicando la capacità di riprovare di Cypress. Tuttavia, controlla solo l'esistenza e niente di più. Quindi ti consiglio di fare un ulteriore passo avanti, aspettando eventuali modifiche nell'interfaccia utente del tuo sito Web o dell'applicazione che vedrebbero anche un utente reale, come le modifiche nell'interfaccia utente stessa o nell'animazione.
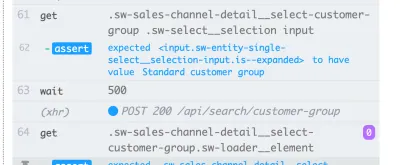
Questo esempio utilizza un tempo di attesa esplicito sull'elemento con il selettore .offcanvas . Il test procederà solo se l'elemento è visibile fino al timeout specificato, che puoi configurare:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Un'altra ottima possibilità in Cypress per l'attesa dinamica sono le sue funzionalità di rete. Sì, possiamo attendere l'arrivo delle richieste e l'esito delle loro risposte. Uso questo tipo di attesa particolarmente spesso. Nell'esempio seguente, definiamo la richiesta da attendere, utilizziamo un comando wait per attendere la risposta e affermiamo il suo codice di stato:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);In questo modo, siamo in grado di aspettare esattamente il tempo necessario alla nostra applicazione, rendendo i test più stabili e meno soggetti a sfaldamenti dovuti a perdite di risorse o altri problemi ambientali.
Debug di test instabili
Ora sappiamo come prevenire i test traballanti in base alla progettazione. Ma cosa succede se hai già a che fare con un test traballante? Come puoi liberartene?
Durante il debug, mettere in loop il test difettoso mi ha aiutato molto a scoprire la fragilità. Ad esempio, se esegui un test 50 volte e passa ogni volta, puoi essere più certo che il test sia stabile, forse la tua correzione ha funzionato. In caso contrario, puoi almeno ottenere maggiori informazioni sul test traballante.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Ottenere maggiori informazioni su questo test traballante è particolarmente difficile in CI. Per ottenere assistenza, verifica se il tuo framework di test è in grado di ottenere ulteriori informazioni sulla tua build. Quando si tratta di test front-end, di solito puoi utilizzare un console.log nei tuoi test:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Questo esempio è tratto da uno unit test di Jest in cui utilizzo un console.log per ottenere l'output dell'HTML del componente da testare. Se utilizzi questa possibilità di registrazione nel test runner di Cypress, puoi persino ispezionare l'output nei tuoi strumenti di sviluppo preferiti. Inoltre, quando si tratta di Cypress in CI, puoi controllare questo output nel registro del tuo CI utilizzando un plug-in.
Guarda sempre le funzionalità del tuo framework di test per ottenere supporto con la registrazione. Nei test dell'interfaccia utente, la maggior parte dei framework fornisce funzionalità di screenshot : almeno in caso di errore, verrà eseguito automaticamente uno screenshot. Alcuni framework forniscono anche la registrazione video , che può essere di grande aiuto per ottenere informazioni dettagliate su ciò che sta accadendo nel test.
Combatti gli incubi di Flakiness!
È importante cercare continuamente test instabili, sia prevenendoli in primo luogo sia eseguendo il debug e risolvendoli non appena si verificano. Dobbiamo prenderli sul serio, perché possono suggerire problemi nella tua applicazione.
Individuazione delle bandiere rosse
Prevenire i test traballanti in primo luogo è la cosa migliore, ovviamente. Per ricapitolare velocemente, ecco alcune bandiere rosse:
- Il test è ampio e contiene molta logica.
- Il test copre molto codice (ad esempio, nei test dell'interfaccia utente).
- Il test si avvale di tempi di attesa fissi.
- Il test dipende dai test precedenti.
- Il test afferma dati che non sono prevedibili al 100%, come l'uso di ID, orari o dati demo, in particolare quelli generati casualmente.
Se tieni a mente i suggerimenti e le strategie di questo articolo, puoi prevenire i test traballanti prima che si verifichino. E se arrivano, saprai come eseguire il debug e risolverli.
Questi passaggi mi hanno davvero aiutato a riguadagnare fiducia nella nostra suite di test. La nostra suite di test sembra essere stabile al momento. Potrebbero esserci problemi in futuro: niente è perfetto al 100%. Questa conoscenza e queste strategie mi aiuteranno ad affrontarle. Così, acquisterò fiducia nella mia capacità di combattere quegli incubi di prova traballanti .
Spero di essere stato in grado di alleviare almeno un po' del tuo dolore e delle tue preoccupazioni sulla sfaldatura!
Ulteriori letture
Se vuoi saperne di più su questo argomento, ecco alcune risorse e articoli utili, che mi hanno aiutato molto:
- Articoli su "fiocco", Cypress.io
- "Ritentare i test è in realtà una buona cosa (se il tuo approccio è giusto)", Filip Hric, Cypress.io
- "Test Flakiness: metodi per identificare e gestire i test instabili", Jason Palmer, Spotify R&D Engineering
- "Test instabili su Google e come li mitighiamo", John Micco, blog sui test di Google