
Rilevamento di notizie false nell'apprendimento automatico [spiegato con un esempio di codifica]
Pubblicato: 2021-02-08Le fake news sono uno dei maggiori problemi nell'era attuale di Internet e dei social media. Sebbene sia una benedizione che le notizie scorrano da un angolo all'altro del mondo nel giro di poche ore, è anche doloroso vedere molte persone e gruppi che diffondono notizie false.
Le tecniche di apprendimento automatico che utilizzano l'elaborazione del linguaggio naturale e l'apprendimento profondo possono essere utilizzate per affrontare questo problema in una certa misura. In questo tutorial creeremo un modello di rilevamento di notizie false utilizzando Machine Learning.
Entro la fine di questo articolo, saprai quanto segue:
- Gestione dei dati di testo
- Tecniche di elaborazione della PNL
- Conta vettorizzazione e TF-IDF
- Fare previsioni e classificare il testo delle notizie
Partecipa al corso di IA e ML online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzato in ML e IA per accelerare la tua carriera.
Sommario
Dati e problemi
Utilizzeremo i dati della sfida di Kaggle Fake News per creare un classificatore. Il set di dati è composto da 4 funzionalità e 1 target binario. Le 4 caratteristiche sono le seguenti:
- id : ID univoco per un articolo di notizie
- title : il titolo di un articolo di notizie
- autore : autore dell'articolo di notizie
- testo : il testo dell'articolo; potrebbe essere incompleto
E l'obiettivo è "etichetta" che contiene valori binari 0 e 1. Dove 0 significa che è una fonte affidabile di notizie, o in altre parole, non falso. 1 significa che si tratta di una notizia potenzialmente falsa e non affidabile. Il set di dati che abbiamo consisteva di 20800 istanze. Entriamo subito.

Pre-elaborazione e pulizia dei dati
| importa panda come pd df=pd.read_csv( 'fake-news/train.csv' ) df.head() |
| X=df.drop( 'label' ,axis= 1 ) # Caratteristiche y=df[ 'etichetta' ] # Destinazione |
Ora dobbiamo eliminare le istanze con dati mancanti.
| df=df.dropna() |
![]()
Come possiamo vedere, ha eliminato tutte le istanze con dati mancanti.
| messaggi=df.copy() messaggi.reset_index(inplace= True ) messaggi.head( 10 ) |
Diamo un'occhiata ai dati una volta.
| messaggi['testo'][6] |

Come possiamo vedere, è necessario eseguire i seguenti passaggi:
- Rimuovere le stopword: ci sono molte parole che non aggiungono valore a nessun testo, indipendentemente dai dati. Ad esempio, "I", "a", "am", ecc. Queste parole non hanno valore informativo e quindi possono essere rimosse per ridurre le dimensioni del nostro corpus in modo che possiamo concentrarci solo su parole/token che hanno un valore effettivo .
- Stemming delle parole: Stemming e Lemmatization sono le tecniche per ridurre le parole alle loro radici o radici. Il vantaggio principale di questo passaggio è ridurre le dimensioni del vocabolario. Ad esempio, parole come Riproduci, Riproduci, Riproduci verranno ridotte a "Riproduci". Stemming semplicemente tronca le parole alla parola più breve e non prende in considerazione l'aspetto grammaticale del testo. La lemmatizzazione, d'altra parte, prende anche in considerazione la grammatica e quindi produce risultati molto migliori. Tuttavia, la lemmatizzazione è solitamente più lenta della stemming in quanto deve fare riferimento al dizionario e prendere in considerazione l'aspetto grammaticale.
- Rimuovere tutto tranne i valori alfabetici: i valori non alfabetici non sono molto utili qui, quindi possono essere rimossi. Tuttavia, puoi esplorare ulteriormente per vedere se la presenza di dati numerici o di altro tipo ha un impatto sul target.
- Minuscole le parole: minuscole le parole per ridurre il vocabolario.
- Tokenize le frasi: Generazione di token dalle frasi.
| da sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer da nltk.corpus import stopwords da nltk.stem.porter import PorterStemmer importare ri ps = Porter Stemmer() corpus = [] for i in range(0, len(messages)): recensione = re.sub('[^a-zA-Z]', ' ', messaggi['testo'][i]) recensione = recensione.inferiore() recensione = recensione.split() review = [ps.stem(word) for word in review if not word in stopwords.words('english')] review = ' '.join(review) corpus.append(recensione) |
Diamo un'occhiata al nostro corpus ora.
| corpus[ 3 ] |
![]()
Come possiamo vedere, le parole ora sono derivate da parole radice.
Vettorizzatore TF-IDF
Ora dobbiamo vettorizzare le parole in dati numerici che sono anche chiamati vettorizzazione. Il modo più semplice per vettorializzare è utilizzare il Bag of Words. Ma Bag of Words crea una matrice sparsa e quindi è necessaria molta memoria di elaborazione. Inoltre, BoW non prende in considerazione la frequenza delle parole che lo rende un cattivo algoritmo.
TF-IDF (Term Frequency – Inverse Document Frequency) è un altro modo per vettorizzare le parole che prende in considerazione le frequenze delle parole. Ad esempio, parole comuni come "noi", "nostro", "il" sono presenti in ogni documento/istanza, quindi il valore BoW sarà troppo alto e quindi fuorviante. Questo porterà a un cattivo modello. TF-IDF è la moltiplicazione di Term Frequency e Inverse Document Frequency.
Term Frequency tiene conto della frequenza delle parole in un documento e Inverse Document Frequency tiene conto delle parole presenti nell'intero corpus. Le parole presenti nell'intero corpus hanno un'importanza ridotta poiché il valore dell'IDF è molto più basso. Le parole che sono presenti specificamente in un documento hanno un valore IDF alto che rende alto il valore TF-IDF totale.
| ## Vettorizzatore TFi df da sklearn.feature_extraction.text import TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messaggi[ 'etichetta' ] |
Nel codice sopra, importiamo il vettorizzatore TF-IDF dal modulo di estrazione delle funzionalità di Sklearn. Realizziamo il suo oggetto passando max_features come 5000 e ngram_range come (1,3). Il parametro max_features definisce il numero massimo di vettori di funzionalità che vogliamo creare e il parametro ngram_range definisce le combinazioni di ngram che vogliamo includere. Nel nostro caso, otterremo 3 combinazioni di 1 parola, 2 parole e 3 parole. Diamo un'occhiata ad alcune delle funzionalità create.

| tfidf_v.get_feature_names()[: 20 ] |

Come possiamo vedere, ci sono più tipi di combinazioni formate. Ci sono nomi di funzioni con 1 gettone, 2 gettoni e anche con 3 gettoni.
Realizzazione di un dataframe
| ## Dividi il set di dati in Train and Test da sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, columns=tfidf_v.get_feature_names()) count_df.head() |
Dividiamo il set di dati in treno e test in modo da poter testare le prestazioni del modello su dati invisibili. Quindi creiamo un nuovo Dataframe che contiene i nuovi vettori di funzionalità al suo interno.
Modellazione e messa a punto
Algoritmo multinomiale NB
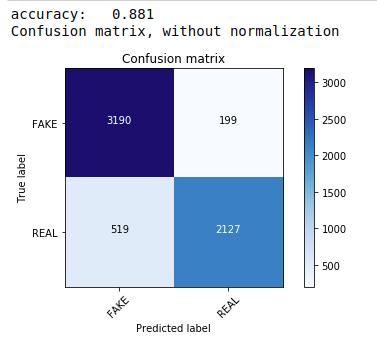
In primo luogo, utilizziamo il teorema multinomiale di Bayes, che è l'algoritmo più comune e più semplice preferito per la classificazione dei dati di testo. Ci adattiamo ai dati di allenamento e prevediamo sui dati del test. Successivamente calcoliamo e tracciamo la matrice di confusione e otteniamo una precisione dell'88,1%.
| da sklearn.naive_bayes import MultinomialNB dalle metriche di importazione di sklearn importa numpy come np importare itertools da sklearn.metrics import plot_confusion_matrix classificatore=MultinomialeNB() classificatore.fit(X_treno, y_treno) pred = classificatore.predict(X_test) punteggio = metrics.accuracy_score(y_test, pred) print( "precisione: %0.3f" % punteggio) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, classi=[ 'FALSO' , 'REALE' ]) |
Classificatore multinomiale con ottimizzazione iperparametrica
MultinomialNB ha un parametro alfa che può essere ulteriormente ottimizzato. Quindi eseguiamo un ciclo per provare più classificatori MultinomialNB con diversi valori alfa e verificarne i punteggi di accuratezza. E controlliamo se il punteggio attuale è maggiore del punteggio precedente. Se lo è, impostiamo il classificatore come quello corrente.
| punteggio_precedente= 0 per alfa in np.arange( 0 , 1 , 0.1 ): sub_classifier=MultinomialeNB(alfa=alfa) sub_classifier.fit(X_treno, y_treno) y_pred=sub_classifier.predict(X_test) punteggio = metrics.accuracy_score(y_test, y_pred) se punteggio>punteggio_precedente: classificatore=sotto_classificatore print( “Alfa: {}, Punteggio: {}” .format(alfa, punteggio)) |
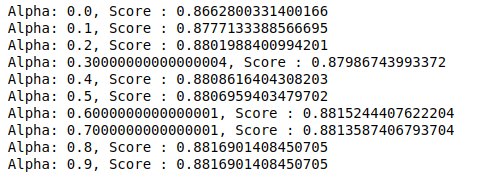
Quindi possiamo vedere che un valore alfa di 0,9 o 0,8 ha dato il punteggio di accuratezza più alto.
Interpretare i risultati
Ora vediamo cosa significano questi valori del coefficiente di classificazione. Per prima cosa salveremo tutti i nomi delle funzioni in un'altra variabile.
| ## Ottieni nomi di funzioni feature_names = cv.get_feature_names() |
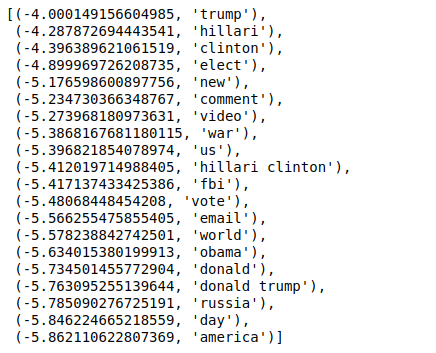
Ora, quando ordiniamo i valori in ordine inverso, otteniamo valori con un valore minimo di -4. Questi denotano le parole più reali o meno false.
| ### Più reale sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
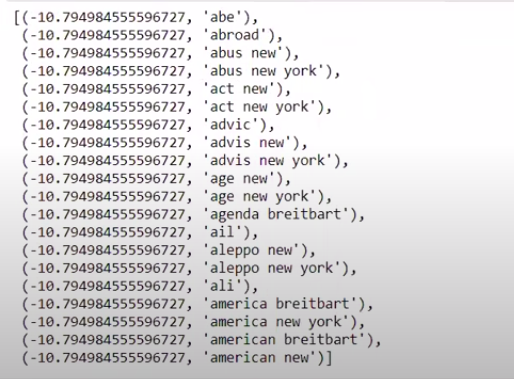
Quando ordiniamo i valori in ordine non inverso, otteniamo valori con un valore minimo di -10. Questi denotano le parole meno reali o più false.
| ### Più reale sorted(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Conclusione
In questo tutorial, abbiamo utilizzato solo algoritmi ML, ma utilizzi anche altri metodi di reti neurali. Inoltre, per vettorizzare i dati di testo, abbiamo utilizzato il vettorizzatore TF-IDF. Ci sono anche più vettorizzatori come Count Vectorizer, Hashing Vectorizer, ecc. che possono essere migliori nel fare il lavoro. Prova e sperimenta altri algoritmi e tecniche per vedere se riesci a produrre risultati migliori o meno.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI , progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT -B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Perché è necessario rilevare le fake news?
Nella loro condizione attuale, le piattaforme dei social media sono molto potenti e preziose poiché consentono agli utenti di discutere e scambiare idee, nonché di discutere argomenti come democrazia, istruzione e salute. Tuttavia, alcune entità utilizzano tali piattaforme male, per guadagno monetario in alcune circostanze e per produrre punti di vista prevenuti, alterare le mentalità e diffondere satira o ridicolo in altri. Fake news è il termine per questo fenomeno. La proliferazione di postare articoli online che non aderiscono alla realtà ha portato a una serie di problemi in politica, sport, salute, scienza e altri campi.
Quali aziende utilizzano principalmente il rilevamento di notizie false?
Il rilevamento di notizie false viene utilizzato su piattaforme come social media e siti Web di notizie. I colossi dei social media come Facebook, Instagram e Twitter sono vulnerabili alle notizie false poiché la maggior parte dei suoi utenti si affida a loro come fonti di notizie quotidiane per ottenere le informazioni più aggiornate. Le tecniche di rilevamento dei falsi vengono utilizzate anche dalle società di media per determinare l'autenticità delle informazioni in loro possesso. L'e-mail è un altro mezzo attraverso il quale le persone possono ricevere notizie, il che rende difficile identificare e verificare la loro veridicità. Hoax, spam e posta indesiderata sono noti per essere trasmessi tramite e-mail. Di conseguenza, la maggior parte delle piattaforme di posta elettronica utilizza il rilevamento di notizie false per identificare spam e posta indesiderata.