
Guida introduttiva a uno stack JavaScript Express ed ES6+
Pubblicato: 2022-03-10Questo articolo è la seconda parte di una serie, con la prima parte che si trova qui, che ha fornito informazioni di base e (si spera) intuitive su Node.js, JavaScript ES6+, funzioni di callback, funzioni freccia, API, protocollo HTTP, JSON, MongoDB e Di Più.
In questo articolo, svilupperemo le competenze acquisite nel precedente, imparando come implementare e distribuire un database MongoDB per archiviare le informazioni sugli elenchi degli utenti, creare un'API con Node.js e il framework dell'applicazione Web Express per esporre quel database ed eseguire operazioni CRUD su di esso e altro ancora. Lungo il percorso, discuteremo di ES6 Object Destructuring, ES6 Object Shorthand, la sintassi Async/Await, Spread Operator e daremo una breve occhiata a CORS, la stessa politica di origine e altro ancora.
In un articolo successivo, eseguiremo il refactoring della nostra base di codice in modo da separare i problemi utilizzando l'architettura a tre livelli e ottenendo l'inversione del controllo tramite l'inserimento delle dipendenze, eseguiremo la sicurezza e il controllo degli accessi basati su token Web JSON e autenticazione Firebase, impareremo come eseguire in modo sicuro archivia le password e utilizza AWS Simple Storage Service per archiviare gli avatar degli utenti con Node.js Buffer e Streams, utilizzando al contempo PostgreSQL per la persistenza dei dati. Lungo la strada, riscriveremo la nostra base di codice da zero in TypeScript per esaminare i concetti di OOP classici (come polimorfismo, ereditarietà, composizione e così via) e persino modelli di progettazione come fabbriche e adattatori.
Una parola di avvertimento
C'è un problema con la maggior parte degli articoli che parlano di Node.js oggi. La maggior parte di essi, non tutti, si limita a illustrare come configurare Express Routing, integrare Mongoose e forse utilizzare l'autenticazione token Web JSON. Il problema è che non parlano di architettura, o best practices di sicurezza, o di principi di clean coding, o ACID Compliance, Relational Database, Fifth Normal Form, CAP Theorem o Transactions. Si presume che tu sappia tutto ciò che sta arrivando, o che non costruirai progetti abbastanza grandi o popolari da garantire quella conoscenza di cui sopra.
Sembrano esserci alcuni tipi diversi di sviluppatori Node, tra gli altri, alcuni sono nuovi alla programmazione in generale e altri provengono da una lunga storia di sviluppo aziendale con C# e .NET Framework o Java Spring Framework. La maggior parte degli articoli si rivolge al primo gruppo.
In questo articolo, farò esattamente quello che ho appena affermato che stanno facendo troppi articoli, ma in un articolo successivo, rifattorizzeremo completamente la nostra base di codice, permettendomi di spiegare principi come Iniezione di dipendenza, Tre- Architettura dei livelli (controller/servizio/repository), mappatura dei dati e record attivo, modelli di progettazione, test di unità, integrazione e mutazione, principi SOLID, unità di lavoro, codifica rispetto alle interfacce, best practice di sicurezza come HSTS, CSRF, NoSQL e SQL Injection Prevenzione, e così via. Migreremo anche da MongoDB a PostgreSQL, utilizzando il semplice generatore di query Knex invece di un ORM, consentendoci di costruire la nostra infrastruttura di accesso ai dati e di entrare in contatto con il linguaggio di query strutturato, i diversi tipi di relazioni (One- to-One, Many-to-Many, ecc.) e altro ancora. Questo articolo, quindi, dovrebbe interessare i principianti, ma i prossimi dovrebbero soddisfare gli sviluppatori più intermedi che cercano di migliorare la propria architettura.
In questo, ci preoccuperemo solo della persistenza dei dati del libro. Non gestiamo l'autenticazione degli utenti, l'hashing delle password, l'architettura o qualcosa di complesso del genere. Tutto ciò arriverà nei prossimi e futuri articoli. Per ora, e in pratica, creeremo solo un metodo con cui consentire a un client di comunicare con il nostro server Web tramite il protocollo HTTP in modo da salvare le informazioni sui libri in un database.
Nota : l'ho mantenuto intenzionalmente estremamente semplice e forse non del tutto pratico qui perché questo articolo, in sé e per sé, è estremamente lungo, poiché mi sono preso la libertà di deviare per discutere argomenti supplementari. Pertanto, miglioreremo progressivamente la qualità e la complessità dell'API in questa serie, ma ancora una volta, poiché la considero una delle prime introduzioni a Express, sto intenzionalmente mantenendo le cose estremamente semplici.
- ES6 Destrutturazione di oggetti
- ES6 abbreviazione di oggetti
- Operatore di diffusione ES6 (...)
- In arrivo...
ES6 Destrutturazione di oggetti
ES6 Object Destructuring, o Destructuring Assignment Syntax, è un metodo con cui estrarre o decomprimere valori da array o oggetti nelle proprie variabili. Inizieremo con le proprietà degli oggetti e poi discuteremo gli elementi dell'array.
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // Log properties: console.log('Name:', person.name); console.log('Occupation:', person.occupation); Un'operazione del genere è piuttosto primitiva, ma può essere un po' una seccatura considerando che dobbiamo continuare a fare riferimento a person.something ovunque. Supponiamo che ci fossero altri 10 punti nel nostro codice in cui dovevamo farlo: sarebbe diventato piuttosto arduo abbastanza velocemente. Un metodo di brevità sarebbe assegnare questi valori alle proprie variabili.
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; const personName = person.name; const personOccupation = person.occupation; // Log properties: console.log('Name:', personName); console.log('Occupation:', personOccupation); Forse questo sembra ragionevole, ma se avessimo altre 10 proprietà nidificate anche sull'oggetto person ? Sarebbero molte righe inutili solo per assegnare valori alle variabili - a quel punto siamo in pericolo perché se le proprietà dell'oggetto sono mutate, le nostre variabili non rifletteranno quel cambiamento (ricorda, solo i riferimenti all'oggetto sono immutabili con l'assegnazione const , non le proprietà dell'oggetto), quindi in pratica non possiamo più mantenere sincronizzato lo "stato" (e sto usando quella parola in modo approssimativo). Passa per riferimento e passa per valore potrebbe entrare in gioco qui, ma non voglio allontanarmi troppo dall'ambito di questa sezione.
ES6 Object Destructing fondamentalmente ci consente di fare questo:
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // This is new. It's called Object Destructuring. const { name, occupation } = person; // Log properties: console.log('Name:', name); console.log('Occupation:', occupation); Non stiamo creando un nuovo oggetto/oggetto letterale, stiamo decomprimendo il name e le proprietà occupation dall'oggetto originale e inserendoli nelle proprie variabili con lo stesso nome. I nomi che utilizziamo devono corrispondere ai nomi delle proprietà che desideriamo estrarre.
Di nuovo, la sintassi const { a, b } = someObject; sta specificatamente dicendo che ci aspettiamo che alcune proprietà a e alcune proprietà b esistano all'interno di someObject (ad esempio, someObject potrebbe essere { a: 'dataA', b: 'dataB' } , per esempio) e che vogliamo posizionare qualunque siano i valori di quelle chiavi/proprietà all'interno delle variabili const con lo stesso nome. Ecco perché la sintassi sopra ci fornirebbe due variabili const a = someObject.a e const b = someObject.b .
Ciò significa che ci sono due lati nella distruzione degli oggetti. Il lato "Modello" e il lato "Sorgente", dove il lato const { a, b } (il lato sinistro) è il modello e il lato someObject (il lato destro) è il lato sorgente , il che ha senso — stiamo definendo una struttura o “modello” a sinistra che rispecchia i dati sul lato “sorgente”.
Ancora una volta, solo per chiarire, ecco alcuni esempi:
// ----- Destructure from Object Variable with const ----- // const objOne = { a: 'dataA', b: 'dataB' }; // Destructure const { a, b } = objOne; console.log(a); // dataA console.log(b); // dataB // ----- Destructure from Object Variable with let ----- // let objTwo = { c: 'dataC', d: 'dataD' }; // Destructure let { c, d } = objTwo; console.log(c); // dataC console.log(d); // dataD // Destructure from Object Literal with const ----- // const { e, f } = { e: 'dataE', f: 'dataF' }; // <-- Destructure console.log(e); // dataE console.log(f); // dataF // Destructure from Object Literal with let ----- // let { g, h } = { g: 'dataG', h: 'dataH' }; // <-- Destructure console.log(g); // dataG console.log(h); // dataHNel caso di proprietà nidificate, rispecchia la stessa struttura nell'assegnazione di distruzione:
const person = { name: 'Richard P. Feynman', occupation: { type: 'Theoretical Physicist', location: { lat: 1, lng: 2 } } }; // Attempt one: const { name, occupation } = person; console.log(name); // Richard P. Feynman console.log(occupation); // The entire `occupation` object. // Attempt two: const { occupation: { type, location } } = person; console.log(type); // Theoretical Physicist console.log(location) // The entire `location` object. // Attempt three: const { occupation: { location: { lat, lng } } } = person; console.log(lat); // 1 console.log(lng); // 2Come puoi vedere, le proprietà che decidi di ottenere sono facoltative e per decomprimere le proprietà nidificate, rispecchia semplicemente la struttura dell'oggetto originale (l'origine) nel lato modello della tua sintassi di destrutturazione. Se tenti di destrutturare una proprietà che non esiste nell'oggetto originale, quel valore non sarà definito.
Possiamo inoltre destrutturare una variabile senza prima dichiararla - assegnazione senza dichiarazione - utilizzando la seguente sintassi:
let name, occupation; const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; ;({ name, occupation } = person); console.log(name); // Richard P. Feynman console.log(occupation); // Theoretical PhysicistPrecediamo l'espressione con un punto e virgola per assicurarci di non creare accidentalmente un IIFE (Immediately Invoked Function Expression) con una funzione su una riga precedente (se esiste una di queste funzioni) e le parentesi attorno all'istruzione di assegnazione sono necessarie per impedisci a JavaScript di trattare il tuo lato sinistro (modello) come un blocco.
Un caso d'uso molto comune di destrutturazione esiste all'interno degli argomenti di funzione:
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; // Destructures `baseUrl` and `awsBucket` off `config`. const performOperation = ({ baseUrl, awsBucket }) => { fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);Come puoi vedere, avremmo potuto semplicemente usare la normale sintassi di destrutturazione a cui siamo abituati ora all'interno della funzione, in questo modo:
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; const performOperation = someConfig => { const { baseUrl, awsBucket } = someConfig; fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);Ma l'inserimento di detta sintassi all'interno della firma della funzione esegue automaticamente la destrutturazione e ci salva una riga.
Un caso d'uso nel mondo reale di questo è in React Functional Components per props di scena:
import React from 'react'; // Destructure `titleText` and `secondaryText` from `props`. export default ({ titleText, secondaryText }) => ( <div> <h1>{titleText}</h1> <h3>{secondaryText}</h3> </div> );Al contrario di:
import React from 'react'; export default props => ( <div> <h1>{props.titleText}</h1> <h3>{props.secondaryText}</h3> </div> );In entrambi i casi, possiamo anche impostare valori di default sulle proprietà:
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(name); console.log(password); return { id: Math.random().toString(36) // <--- Should follow RFC 4122 Spec in real app. .substring(2, 15) + Math.random() .toString(36).substring(2, 15), name: name, // <-- We'll discuss this next. password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt Hash Come puoi vedere, nel caso in cui quel name non sia presente quando destrutturato, gli forniamo un valore predefinito. Possiamo farlo anche con la sintassi precedente:
const { a, b, c = 'Default' } = { a: 'dataA', b: 'dataB' }; console.log(a); // dataA console.log(b); // dataB console.log(c); // DefaultAnche gli array possono essere destrutturati:
const myArr = [4, 3]; // Destructuring happens here. const [valOne, valTwo] = myArr; console.log(valOne); // 4 console.log(valTwo); // 3 // ----- Destructuring without assignment: ----- // let a, b; // Destructuring happens here. ;([a, b] = [10, 2]); console.log(a + b); // 12Un motivo pratico per la destrutturazione dell'array si verifica con React Hooks. (E ci sono molti altri motivi, sto solo usando React come esempio).
import React, { useState } from "react"; export default () => { const [buttonText, setButtonText] = useState("Default"); return ( <button onClick={() => setButtonText("Toggled")}> {buttonText} </button> ); } Si noti che useState viene destrutturato dall'esportazione e le funzioni/valori dell'array vengono destrutturati useState . Ancora una volta, non preoccuparti se quanto sopra non ha senso - dovresti capire React - e lo sto semplicemente usando come esempio.
Anche se c'è di più in ES6 Object Destructuring, tratterò un altro argomento qui: Destructuring Renaming, che è utile per prevenire collisioni di scope o ombre variabili, ecc. Supponiamo di voler destrutturare una proprietà chiamata name da un oggetto chiamato person , ma c'è già una variabile con il nome di name nell'ambito. Possiamo rinominare al volo con i due punti:
// JS Destructuring Naming Collision Example: const name = 'Jamie Corkhill'; const person = { name: 'Alan Turing' }; // Rename `name` from `person` to `personName` after destructuring. const { name: personName } = person; console.log(name); // Jamie Corkhill <-- As expected. console.log(personName); // Alan Turing <-- Variable was renamed.Infine, possiamo anche impostare i valori predefiniti con la ridenominazione:
const name = 'Jamie Corkhill'; const person = { location: 'New York City, United States' }; const { name: personName = 'Anonymous', location } = person; console.log(name); // Jamie Corkhill console.log(personName); // Anonymous console.log(location); // New York City, United States Come puoi vedere, in questo caso, name from person ( person.name ) verrà rinominato personName e impostato sul valore predefinito di Anonymous se non esistente.
E, naturalmente, lo stesso può essere eseguito nelle firme di funzione:
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name: personName = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(personName); console.log(password); return { id: Math.random().toString(36).substring(2, 15) + Math.random().toString(36).substring(2, 15), name: personName, password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt HashES6 abbreviazione di oggetti
Supponiamo che tu abbia la seguente fabbrica: (ci occuperemo delle fabbriche in seguito)
const createPersonFactory = (name, location, position) => ({ name: name, location: location, position: position }); Si potrebbe usare questa fabbrica per creare un oggetto person , come segue. Inoltre, si noti che la fabbrica restituisce implicitamente un oggetto, evidente dalle parentesi attorno alle parentesi della Funzione Freccia.
const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person); // { ... } Questo è ciò che sappiamo già dalla sintassi letterale degli oggetti ES5. Si noti, tuttavia, nella funzione factory, che il valore di ciascuna proprietà è lo stesso nome dell'identificatore di proprietà (chiave) stesso. Cioè — location: location o name: name . Si è scoperto che era un evento abbastanza comune con gli sviluppatori JS.
Con la sintassi abbreviata di ES6, possiamo ottenere lo stesso risultato riscrivendo la fabbrica come segue:
const createPersonFactory = (name, location, position) => ({ name, location, position }); const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person);Produzione dell'output:
{ name: 'Jamie', location: 'Texas', position: 'Developer' }È importante rendersi conto che possiamo usare questa scorciatoia solo quando l'oggetto che desideriamo creare viene creato dinamicamente in base a variabili, dove i nomi delle variabili sono gli stessi dei nomi delle proprietà a cui vogliamo assegnare le variabili.
Questa stessa sintassi funziona con i valori degli oggetti:
const createPersonFactory = (name, location, position, extra) => ({ name, location, position, extra // <- right here. }); const extra = { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] }; const person = createPersonFactory('Jamie', 'Texas', 'Developer', extra); console.log(person);Produzione dell'output:
{ name: 'Jamie', location: 'Texas', position: 'Developer', extra: { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] } }Come ultimo esempio, funziona anche con i valori letterali degli oggetti:
const id = '314159265358979'; const name = 'Archimedes of Syracuse'; const location = 'Syracuse'; const greatMathematician = { id, name, location };Operatore di diffusione ES6 (…)
Lo Spread Operator ci permette di fare una varietà di cose, alcune delle quali discuteremo qui.
In primo luogo, possiamo distribuire le proprietà da un oggetto a un altro oggetto:
const myObjOne = { a: 'a', b: 'b' }; const myObjTwo = { ...myObjOne }: Questo ha l'effetto di posizionare tutte le proprietà su myObjOne su myObjTwo , in modo tale che myObjTwo sia ora { a: 'a', b: 'b' } . Possiamo usare questo metodo per sovrascrivere le proprietà precedenti. Supponiamo che un utente desideri aggiornare il proprio account:
const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */
Lo stesso può essere eseguito con gli array:
const apollo13Astronauts = ['Jim', 'Jack', 'Fred']; const apollo11Astronauts = ['Neil', 'Buz', 'Michael']; const unionOfAstronauts = [...apollo13Astronauts, ...apollo11Astronauts]; console.log(unionOfAstronauts); // ['Jim', 'Jack', 'Fred', 'Neil', 'Buz, 'Michael'];Si noti qui che abbiamo creato un'unione di entrambi gli insiemi (array) distribuendo gli array in un nuovo array.
C'è molto di più nell'operatore Rest/Spread, ma non rientra nell'ambito di questo articolo. Può essere utilizzato per ottenere più argomenti per una funzione, ad esempio. Se vuoi saperne di più, consulta la documentazione MDN qui.
ES6 Asincrono/In attesa
Async/Await è una sintassi per alleviare il dolore del concatenamento delle promesse.
La parola chiave await riservato consente di “attendere” il regolamento di una promessa, ma può essere utilizzata solo nelle funzioni contrassegnate con la parola chiave async . Supponiamo di avere una funzione che restituisce una promessa. In una nuova funzione async , posso await il risultato di quella promessa invece di usare .then e .catch .
// Returns a promise. const myFunctionThatReturnsAPromise = () => { return new Promise((resolve, reject) => { setTimeout(() => resolve('Hello'), 3000); }); } const myAsyncFunction = async () => { const promiseResolutionResult = await myFunctionThatReturnsAPromise(); console.log(promiseResolutionResult); }; // Writes the log statement after three seconds. myAsyncFunction(); Ci sono alcune cose da notare qui. Quando usiamo await in una funzione async , solo il valore risolto va nella variabile sul lato sinistro. Se la funzione rifiuta, è un errore che dobbiamo rilevare, come vedremo tra poco. Inoltre, qualsiasi funzione contrassegnata come async restituirà, per impostazione predefinita, una promessa.
Supponiamo di dover effettuare due chiamate API, una con la risposta della prima. Usando le promesse e il concatenamento delle promesse, potresti farlo in questo modo:
const makeAPICall = route => new Promise((resolve, reject) => { console.log(route) resolve(route); }); const main = () => { makeAPICall('/whatever') .then(response => makeAPICall(response + ' second call')) .then(response => console.log(response + ' logged')) .catch(err => console.error(err)) }; main(); // Result: /* /whatever /whatever second call /whatever second call logged */ Quello che sta succedendo qui è che prima chiamiamo makeAPICall passando ad esso /whatever , che viene registrato la prima volta. La promessa si risolve con quel valore. Quindi chiamiamo di nuovo makeAPICall , passando ad esso /whatever second call , che viene registrato e, di nuovo, la promessa si risolve con quel nuovo valore. Infine, prendiamo quel nuovo valore /whatever second call con cui la promessa si è appena risolta e lo registriamo noi stessi nel registro finale, aggiungendo alla fine logged . Se questo non ha senso, dovresti esaminare il concatenamento delle promesse.
Usando async / await , possiamo eseguire il refactoring in base a quanto segue:
const main = async () => { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); }; Ecco cosa accadrà. L'intera funzione smetterà di essere eseguita alla prima istruzione await fino a quando la promessa della prima chiamata a makeAPICall si risolve, dopo la risoluzione, il valore risolto verrà inserito in resultOne . Quando ciò accade, la funzione si sposterà alla seconda istruzione await , fermandosi di nuovo proprio lì per la durata del regolamento della promessa. Quando la promessa si risolve, il risultato della risoluzione verrà inserito in resultTwo . Se l'idea sull'esecuzione della funzione sembra bloccante, non temere, è ancora asincrona e discuterò il perché tra un minuto.
Questo descrive solo il percorso "felice". Nel caso in cui una delle promesse venga rifiutata, possiamo prenderlo con try/catch, perché se la promessa viene rifiutata, verrà generato un errore, che sarà l'errore con cui la promessa è stata rifiutata.
const main = async () => { try { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); } catch (e) { console.log(e) } }; Come ho detto prima, qualsiasi funzione dichiarata async restituirà una promessa. Quindi, se vuoi chiamare una funzione asincrona da un'altra funzione, puoi usare le normali promesse o await se dichiari la funzione chiamante async . Tuttavia, se vuoi chiamare una funzione async dal codice di primo livello e attendere il suo risultato, dovresti usare .then e .catch .
Per esempio:
const returnNumberOne = async () => 1; returnNumberOne().then(value => console.log(value)); // 1In alternativa, puoi utilizzare un'espressione di funzione richiamata immediatamente (IIFE):
(async () => { const value = await returnNumberOne(); console.log(value); // 1 })(); Quando si utilizza await in una funzione async , l'esecuzione della funzione si interromperà in corrispondenza dell'istruzione await fino a quando la promessa non sarà soddisfatta. Tuttavia, tutte le altre funzioni sono libere di procedere con l'esecuzione, quindi non vengono allocate risorse CPU aggiuntive né il thread viene mai bloccato. Lo dirò di nuovo: le operazioni in quella specifica funzione in quel momento specifico si interromperanno fino a quando la promessa non si sarà stabilizzata, ma tutte le altre funzioni sono libere di attivarsi. Considera un server Web HTTP: in base alla richiesta, tutte le funzioni possono essere attivate per tutti gli utenti contemporaneamente quando vengono effettuate le richieste, è solo che la sintassi asincrona/attesa fornirà l' illusione che un'operazione sia sincrona e bloccante da fare promette più facile lavorare con, ma ancora una volta, tutto rimarrà bello e asincrono.
Questo non è tutto quello che c'è da async / await , ma dovrebbe aiutarti a cogliere i principi di base.
Fabbriche OOP classiche
Ora lasceremo il mondo JavaScript ed entreremo nel mondo Java . Può arrivare un momento in cui il processo di creazione di un oggetto (in questo caso, un'istanza di una classe, ancora una volta Java) è abbastanza complesso o quando vogliamo che oggetti diversi vengano prodotti in base a una serie di parametri. Un esempio potrebbe essere una funzione che crea diversi oggetti di errore. Una fabbrica è un modello di progettazione comune nella programmazione orientata agli oggetti ed è fondamentalmente una funzione che crea oggetti. Per esplorare questo, spostiamoci da JavaScript nel mondo di Java. Questo avrà senso per gli sviluppatori che provengono da un background linguistico OOP classico (cioè non prototipo), tipizzato staticamente. Se non sei uno di questi sviluppatori, sentiti libero di saltare questa sezione. Questa è una piccola deviazione, quindi se seguire qui si interrompe il flusso di JavaScript, di nuovo, salta questa sezione.
Un modello di creazione comune, il modello di fabbrica ci consente di creare oggetti senza esporre la logica di business richiesta per eseguire tale creazione.
Supponiamo di scrivere un programma che ci permetta di visualizzare forme primitive in n-dimensioni. Se forniamo un cubo, ad esempio, vedremmo un cubo 2D (un quadrato), un cubo 3D (un cubo) e un cubo 4D (un Tesseract o Hypercube). Ecco come questo potrebbe essere fatto, banalmente, e escludendo la parte di disegno vera e propria, in Java.
// Main.java // Defining an interface for the shape (can be used as a base type) interface IShape { void draw(); } // Implementing the interface for 2-dimensions: class TwoDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 2D."); } } // Implementing the interface for 3-dimensions: class ThreeDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 3D."); } } // Implementing the interface for 4-dimensions: class FourDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 4D."); } } // Handles object creation class ShapeFactory { // Factory method (notice return type is the base interface) public IShape createShape(int dimensions) { switch(dimensions) { case 2: return new TwoDimensions(); case 3: return new ThreeDimensions(); case 4: return new FourDimensions(); default: throw new IllegalArgumentException("Invalid dimension."); } } } // Main class and entry point. public class Main { public static void main(String[] args) throws Exception { ShapeFactory shapeFactory = new ShapeFactory(); IShape fourDimensions = shapeFactory.createShape(4); fourDimensions.draw(); // Drawing a shape in 4D. } } Come puoi vedere, definiamo un'interfaccia che specifica un metodo per disegnare una forma. Facendo in modo che le diverse classi implementino l'interfaccia, possiamo garantire che tutte le forme possano essere disegnate (perché tutte devono avere un metodo di draw sovrascrivibile secondo la definizione dell'interfaccia). Considerando che questa forma è disegnata in modo diverso a seconda delle dimensioni entro cui viene visualizzata, definiamo classi helper che implementano l'interfaccia in modo da eseguire il lavoro intensivo della GPU di simulazione del rendering n-dimensionale. ShapeFactory fa il lavoro di istanziare la classe corretta: il metodo createShape è una fabbrica e, come la definizione sopra, è un metodo che restituisce un oggetto di una classe. Il tipo restituito di createShape è l'interfaccia IShape perché l'interfaccia IShape è il tipo base di tutte le forme (perché hanno un metodo di draw ).
Questo esempio Java è abbastanza banale, ma puoi facilmente vedere quanto diventa utile in applicazioni più grandi in cui l'impostazione per creare un oggetto potrebbe non essere così semplice. Un esempio di questo potrebbe essere un videogioco. Supponiamo che l'utente debba sopravvivere a diversi nemici. Classi e interfacce astratte potrebbero essere utilizzate per definire le funzioni principali disponibili per tutti i nemici (e i metodi che possono essere ignorati), magari utilizzando il modello di delega (preferire la composizione rispetto all'ereditarietà come suggerito dalla Banda dei Quattro in modo da non rimanere bloccati nell'estensione di un un'unica classe base e per semplificare il testing/beffe/DI). Per gli oggetti nemici istanziati in modi diversi, l'interfaccia consentirebbe la creazione di oggetti di fabbrica basandosi sul tipo di interfaccia generico. Questo sarebbe molto rilevante se il nemico fosse creato dinamicamente.
Un altro esempio è una funzione builder. Supponiamo di utilizzare il modello di delega per fare in modo che un delegato di classe lavori ad altre classi che rispettano un'interfaccia. Potremmo posizionare un metodo di build statico sulla classe per far sì che costruisca la propria istanza (supponendo che tu non stia utilizzando un contenitore/framework di iniezione di dipendenze). Invece di dover chiamare ogni setter, puoi farlo:
public class User { private IMessagingService msgService; private String name; private int age; public User(String name, int age, IMessagingService msgService) { this.name = name; this.age = age; this.msgService = msgService; } public static User build(String name, int age) { return new User(name, age, new SomeMessageService()); } } Spiegherò il modello di delega in un articolo successivo se non lo conosci: in pratica, attraverso la composizione e in termini di modellazione a oggetti, crea una relazione "ha-a" invece di un "è-a" rapporto come si otterrebbe con l'eredità. Se hai una classe Mammal e una classe Dog e Dog estende Mammal , allora un Dog is-a Mammal . Considerando che, se avevi una classe Bark e hai appena passato istanze di Bark nel costruttore di Dog , allora Dog has-a Bark . Come puoi immaginare, questo rende particolarmente più semplice il test unitario, poiché puoi iniettare mock e affermare fatti sul mock fintanto che mock onora il contratto di interfaccia nell'ambiente di test.
Il metodo di fabbrica static "build" di cui sopra crea semplicemente un nuovo oggetto di User e passa un MessageService concreto. Nota come questo segue dalla definizione di cui sopra: non esporre la logica aziendale per creare un oggetto di una classe, o, in questo caso, non esporre la creazione del servizio di messaggistica al chiamante della fabbrica.
Ancora una volta, questo non è necessariamente il modo in cui faresti le cose nel mondo reale, ma presenta abbastanza bene l'idea di una funzione/metodo di fabbrica. Ad esempio, potremmo utilizzare un contenitore Dependency Injection. Ora torniamo a JavaScript.
A partire da Express
Express è un Web Application Framework per Node (disponibile tramite un modulo NPM) che consente di creare un server Web HTTP. È importante notare che Express non è l'unico framework a farlo (esiste Koa, Fastify, ecc.) e che, come visto nell'articolo precedente, Node può funzionare senza Express come entità autonoma. (Express è semplicemente un modulo progettato per Node — Node può fare molte cose senza di esso, sebbene Express sia popolare per i server Web).
Ancora una volta, permettetemi di fare una distinzione molto importante. È presente una dicotomia tra Node/JavaScript ed Express. Node, il runtime/l'ambiente all'interno del quale esegui JavaScript, può fare molte cose, come permetterti di creare app React Native, app desktop, strumenti da riga di comando, ecc. — Express non è altro che un framework leggero che ti consente di utilizzare Node/JS per creare server Web invece di gestire la rete di basso livello di Node e le API HTTP. Non è necessario Express per creare un server web.
Prima di iniziare questa sezione, se non hai familiarità con HTTP e Richieste HTTP (GET, POST, ecc.), Ti incoraggio a leggere la sezione corrispondente del mio precedente articolo, che è collegato sopra.
Utilizzando Express, imposteremo diversi percorsi a cui possono essere inviate richieste HTTP, nonché i relativi endpoint (che sono funzioni di callback) che verranno attivati quando viene effettuata una richiesta a tale percorso. Non preoccuparti se i percorsi e gli endpoint sono attualmente privi di senso: li spiegherò più avanti.
A differenza di altri articoli, adotterò l'approccio di scrivere il codice sorgente mentre procediamo, riga per riga, piuttosto che scaricare l'intera base di codice in uno snippet e poi spiegare in seguito. Iniziamo aprendo un terminale (sto usando Terminus su Git Bash su Windows, che è una buona opzione per gli utenti Windows che desiderano una shell Bash senza configurare il sottosistema Linux), impostando il boilerplate del nostro progetto e aprendolo nel codice di Visual Studio.
mkdir server && cd server touch server.js npm init -y npm install express code . All'interno del file server.js , inizierò richiedendo express utilizzando la funzione require() .
const express = require('express'); require('express') dice a Node di uscire e prendere il modulo Express che abbiamo installato in precedenza, che è attualmente all'interno della cartella node_modules (poiché è ciò che fa npm install : crea una cartella node_modules e inserisce i moduli e le loro dipendenze). Per convenzione, e quando si ha a che fare con Express, chiamiamo la variabile che contiene il risultato restituito da require('express') express , sebbene possa essere chiamata qualsiasi cosa.
This returned result, which we have called express , is actually a function — a function we'll have to invoke to create our Express app and set up our routes. Again, by convention, we call this app — app being the return result of express() — that is, the return result of calling the function that has the name express as express() .
const express = require('express'); const app = express(); // Note that the above variable names are the convention, but not required. // An example such as that below could also be used. const foo = require('express'); const bar = foo(); // Note also that the node module we installed is called express. The line const app = express(); simply puts a new Express Application inside of the app variable. It calls a function named express (the return result of require('express') ) and stores its return result in a constant named app . If you come from an object-oriented programming background, consider this equivalent to instantiating a new object of a class, where app would be the object and where express() would call the constructor function of the express class. Remember, JavaScript allows us to store functions in variables — functions are first-class citizens. The express variable, then, is nothing more than a mere function. It's provided to us by the developers of Express.
I apologize in advance if I'm taking a very long time to discuss what is actually very basic, but the above, although primitive, confused me quite a lot when I was first learning back-end development with Node.
Inside the Express source code, which is open-source on GitHub, the variable we called express is a function entitled createApplication , which, when invoked, performs the work necessary to create an Express Application:
A snippet of Express source code:
exports = module.exports = createApplication; /* * Create an express application */ // This is the function we are storing in the express variable. (- Jamie) function createApplication() { // This is what I mean by "Express App" (- Jamie) var app = function(req, res, next) { app.handle(req, res, next); }; mixin(app, EventEmitter.prototype, false); mixin(app, proto, false); // expose the prototype that will get set on requests app.request = Object.create(req, { app: { configurable: true, enumerable: true, writable: true, value: app } }) // expose the prototype that will get set on responses app.response = Object.create(res, { app: { configurable: true, enumerable: true, writable: true, value: app } }) app.init(); // See - `app` gets returned. (- Jamie) return app; }GitHub: https://github.com/expressjs/express/blob/master/lib/express.js
With that short deviation complete, let's continue setting up Express. Thus far, we have required the module and set up our app variable.
const express = require('express'); const app = express(); From here, we have to tell Express to listen on a port. Any HTTP Requests made to the URL and Port upon which our application is listening will be handled by Express. We do that by calling app.listen(...) , passing to it the port and a callback function which gets called when the server starts running:
const PORT = 3000; app.listen(PORT, () => console.log(`Server is up on port {PORT}.`)); We notate the PORT variable in capital by convention, for it is a constant variable that will never change. You could do that with all variables that you declare const , but that would look messy. It's up to the developer or development team to decide on notation, so we'll use the above sparsely. I use const everywhere as a method of “defensive coding” — that is, if I know that a variable is never going to change then I might as well just declare it const . Since I define everything const , I make the distinction between what variables should remain the same on a per-request basis and what variables are true actual global constants.
Here is what we have thus far:
const express = require('express'); const app = express(); const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`); });Let's test this to see if the server starts running on port 3000.
I'll open a terminal and navigate to our project's root directory. I'll then run node server/server.js . Note that this assumes you have Node already installed on your system (You can check with node -v ).
If everything works, you should see the following in the terminal:
Server is up on port 3000.
Go ahead and hit Ctrl + C to bring the server back down.
If this doesn't work for you, or if you see an error such as EADDRINUSE , then it means you may have a service already running on port 3000. Pick another port number, like 3001, 3002, 5000, 8000, etc. Be aware, lower number ports are reserved and there is an upper bound of 65535.
At this point, it's worth taking another small deviation as to understand servers and ports in the context of computer networking. We'll return to Express in a moment. I take this approach, rather than introducing servers and ports first, for the purpose of relevance. That is, it is difficult to learn a concept if you fail to see its applicability. In this way, you are already aware of the use case for ports and servers with Express, so the learning experience will be more pleasurable.
A Brief Look At Servers And Ports
A server is simply a computer or computer program that provides some sort of “functionality” to the clients that talk to it. More generally, it's a device, usually connected to the Internet, that handles connections in a pre-defined manner. In our case, that “pre-defined manner” will be HTTP or the HyperText Transfer Protocol. Servers that use the HTTP Protocol are called Web Servers.
When building an application, the server is a critical component of the “client-server model”, for it permits the sharing and syncing of data (generally via databases or file systems) across devices. It's a cross-platform approach, in a way, for the SDKs of platforms against which you may want to code — be they web, mobile, or desktop — all provide methods (APIs) to interact with a server over HTTP or TCP/UDP Sockets. It's important to make a distinction here — by APIs, I mean programming language constructs to talk to a server, like XMLHttpRequest or the Fetch API in JavaScript, or HttpUrlConnection in Java, or even HttpClient in C#/.NET. This is different from the kind of REST API we'll be building in this article to perform CRUD Operations on a database.
To talk about ports, it's important to understand how clients connect to a server. A client requires the IP Address of the server and the Port Number of our specific service on that server. An IP Address, or Internet Protocol Address, is just an address that uniquely identifies a device on a network. Public and private IPs exist, with private addresses commonly used behind a router or Network Address Translator on a local network. You might see private IP Addresses of the form 192.168.XXX.XXX or 10.0.XXX.XXX . When articulating an IP Address, decimals are called “dots”. So 192.168.0.1 (a common router IP Addr.) might be pronounced, “one nine two dot one six eight dot zero dot one”. (By the way, if you're ever in a hotel and your phone/laptop won't direct you to the AP captive portal, try typing 192.168.0.1 or 192.168.1.1 or similar directly into Chrome).
For simplicity, and since this is not an article about the complexities of computer networking, assume that an IP Address is equivalent to a house address, allowing you to uniquely identify a house (where a house is analogous to a server, client, or network device) in a neighborhood. One neighborhood is one network. Put together all of the neighborhoods in the United States, and you have the public Internet. (This is a basic view, and there are many more complexities — firewalls, NATs, ISP Tiers (Tier One, Tier Two, and Tier Three), fiber optics and fiber optic backbones, packet switches, hops, hubs, etc., subnet masks, etc., to name just a few — in the real networking world.) The traceroute Unix command can provide more insight into the above, displaying the path (and associated latency) that packets take through a network as a series of “hops”.
Un numero di porta identifica un servizio specifico in esecuzione su un server. SSH, o Secure Shell, che consente l'accesso remoto della shell a un dispositivo, viene comunemente eseguito sulla porta 22. FTP o File Transfer Protocol (che potrebbe, ad esempio, essere utilizzato con un client FTP per trasferire risorse statiche a un server) viene comunemente eseguito su Porta 21. Potremmo dire, quindi, che le porte sono stanze specifiche all'interno di ogni casa nella nostra analogia sopra, perché le stanze nelle case sono fatte per cose diverse: una camera da letto per dormire, una cucina per preparare il cibo, una sala da pranzo per il consumo di detto cibo, ecc., proprio come i porti corrispondono a programmi che svolgono servizi specifici. Per noi, i server Web funzionano comunemente sulla porta 80, anche se sei libero di specificare il numero di porta che desideri purché non siano utilizzati da qualche altro servizio (non possono entrare in collisione).
Per accedere a un sito web è necessario l'indirizzo IP del sito. Nonostante ciò, normalmente accediamo ai siti Web tramite un URL. Dietro le quinte, un DNS o Domain Name Server converte quell'URL in un indirizzo IP, consentendo al browser di effettuare una richiesta GET al server, ottenere l'HTML e visualizzarlo sullo schermo. 8.8.8.8 è l'indirizzo di uno dei server DNS pubblici di Google. Potresti immaginare che richiedere la risoluzione di un nome host in un indirizzo IP tramite un server DNS remoto richiederà tempo e avresti ragione. Per ridurre la latenza, i sistemi operativi dispongono di una cache DNS, un database temporaneo che memorizza le informazioni di ricerca DNS, riducendo così la frequenza di tali ricerche. La cache del resolver DNS può essere visualizzata su Windows con il ipconfig /displaydns CMD ed eliminata tramite il comando ipconfig /flushdns .
Su un server Unix, le porte con numero inferiore più comuni, come 80, richiedono privilegi di livello root ( escalation se si proviene da uno sfondo Windows). Per questo motivo, utilizzeremo la porta 3000 per il nostro lavoro di sviluppo, ma consentiremo al server di scegliere il numero di porta (qualunque sia disponibile) quando verrà distribuito nel nostro ambiente di produzione.
Infine, tieni presente che possiamo digitare gli indirizzi IP direttamente nella barra di ricerca di Google Chrome, aggirando così il meccanismo di risoluzione DNS. Digitando 216.58.194.36 , ad esempio, verrai indirizzato a Google.com. Nel nostro ambiente di sviluppo, quando utilizziamo il nostro computer come server di sviluppo, utilizzeremo localhost e port 3000. Un indirizzo è formattato come hostname:port , quindi il nostro server sarà su localhost:3000 . Localhost, o 127.0.0.1 , è l'indirizzo di loopback e indica l'indirizzo di "questo computer". È un nome host e il suo indirizzo IPv4 si risolve in 127.0.0.1 . Prova subito a eseguire il ping di localhost sul tuo computer. Potresti ottenere ::1 back — che è l'indirizzo di loopback IPv6, o 127.0.0.1 back — che è l'indirizzo di loopback IPv4. IPv4 e IPv6 sono due formati di indirizzi IP diversi associati a standard diversi: alcuni indirizzi IPv6 possono essere convertiti in IPv4 ma non tutti.
Tornando a Express
Ho menzionato richieste HTTP, verbi e codici di stato nel mio precedente articolo, Guida introduttiva a Node: un'introduzione alle API, HTTP e JavaScript ES6+. Se non hai una conoscenza generale del protocollo, sentiti libero di passare alla sezione "Richieste HTTP e HTTP" di quel pezzo.
Per avere un'idea di Express, configureremo semplicemente i nostri endpoint per le quattro operazioni fondamentali che eseguiremo sul database: creazione, lettura, aggiornamento ed eliminazione, note collettivamente come CRUD.
Ricorda, accediamo agli endpoint tramite percorsi nell'URL. Cioè, sebbene le parole "route" ed "endpoint" siano comunemente usate in modo intercambiabile, un endpoint è tecnicamente una funzione del linguaggio di programmazione (come ES6 Arrow Functions) che esegue alcune operazioni lato server, mentre una route è ciò che l'endpoint si trova dietro di . Specifichiamo questi endpoint come funzioni di callback, che Express attiverà quando viene effettuata la richiesta appropriata dal client al percorso dietro il quale risiede l'endpoint. Puoi ricordare quanto sopra rendendoti conto che sono gli endpoint che svolgono una funzione e la route è il nome utilizzato per accedere agli endpoint. Come vedremo, la stessa route può essere associata a più endpoint utilizzando verbi HTTP diversi (simile all'overloading del metodo se si proviene da uno sfondo OOP classico con polimorfismo).
Tieni presente che stiamo seguendo l'architettura REST (REpresentational State Transfer) consentendo ai clienti di effettuare richieste al nostro server. Dopotutto, si tratta di un'API REST o RESTful. Richieste specifiche fatte a percorsi specifici attiveranno endpoint specifici che faranno cose specifiche. Un esempio di tale "cosa" che un endpoint potrebbe fare è aggiungere nuovi dati a un database, rimuovere dati, aggiornare dati, ecc.
Express sa quale endpoint attivare perché gli diciamo, in modo esplicito, il metodo di richiesta (GET, POST, ecc.) e il percorso: definiamo quali funzioni attivare per combinazioni specifiche di quanto sopra e il client effettua la richiesta, specificando un percorso e metodo. Per dirla in modo più semplice, con Node diremo a Express: "Ehi, se qualcuno fa una richiesta GET per questa route, vai avanti e attiva questa funzione (usa questo endpoint)". Le cose possono diventare più complicate: "Express, se qualcuno invia una richiesta GET a questa route, ma non invia un token di autorizzazione valido nell'intestazione della richiesta, rispondi con un HTTP 401 Unauthorized . Se possiedono un token al portatore valido, inviare qualsiasi risorsa protetta che stavano cercando attivando l'endpoint. Grazie mille e buona giornata.” In effetti, sarebbe bello se i linguaggi di programmazione potessero essere di quel livello senza perdere ambiguità, ma dimostra comunque i concetti di base.
Ricorda, l'endpoint, in un certo senso, vive dietro la rotta. Quindi è fondamentale che il client fornisca, nell'intestazione della richiesta, quale metodo desidera utilizzare in modo che Express possa capire cosa fare. La richiesta verrà inoltrata a un percorso specifico, che il client specificherà (insieme al tipo di richiesta) quando contatta il server, consentendo a Express di fare ciò che deve fare e noi di fare ciò che dobbiamo fare quando Express attiva i nostri callback . Ecco a cosa si riduce tutto.
Negli esempi di codice precedenti, abbiamo chiamato la funzione listen che era disponibile su app , passandole una porta e una callback. app stessa, se ricordi, è il risultato di ritorno dalla chiamata della variabile express come una funzione (ovvero, express() ), e la variabile express è ciò che abbiamo chiamato il risultato di ritorno dalla richiesta di 'express' dalla nostra cartella node_modules . Proprio come l' listen viene chiamato app , specifichiamo gli endpoint delle richieste HTTP chiamandoli app . Diamo un'occhiata a GET:
app.get('/my-test-route', () => { // ... }); Il primo parametro è una string ed è il percorso dietro il quale vivrà l'endpoint. La funzione di callback è l'endpoint. Lo dirò di nuovo: la funzione di callback, il secondo parametro, è l'endpoint che si attiverà quando viene effettuata una richiesta HTTP GET a qualsiasi percorso specifichiamo come primo argomento ( /my-test-route in questo caso).
Ora, prima di continuare a lavorare con Express, dobbiamo sapere come funzionano i percorsi. Il percorso che specifichiamo come stringa verrà chiamato facendo la richiesta a www.domain.com/the-route-we-chose-earlier-as-a-string . Nel nostro caso, il dominio è localhost:3000 , il che significa che, per attivare la funzione di callback sopra, dobbiamo fare una richiesta GET a localhost:3000/my-test-route . Se usiamo una stringa diversa come primo argomento sopra, l'URL dovrebbe essere diverso per corrispondere a quello che abbiamo specificato in JavaScript.
Quando parli di queste cose, probabilmente sentirai parlare di modelli glob. Potremmo dire che tutte le rotte della nostra API si trovano in localhost:3000/** Glob Pattern, dove ** è un carattere jolly che indica qualsiasi directory o sottodirectory (nota che le rotte non sono directory) a cui root è un genitore — cioè tutto.
Andiamo avanti e aggiungiamo un'istruzione log in quella funzione di callback in modo che complessivamente abbiamo:
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); Metteremo in funzione il nostro server eseguendo node server/server.js (con Node installato sul nostro sistema e accessibile a livello globale dalle variabili di ambiente di sistema) nella directory principale del progetto. Come prima, dovresti vedere il messaggio che il server è attivo nella console. Ora che il server è in esecuzione, apri un browser e visita localhost:3000 nella barra degli URL.
Dovresti essere accolto con un messaggio di errore che indica Cannot GET / . Premi Ctrl + Maiusc + I su Windows in Chrome per visualizzare la console per sviluppatori. Lì, dovresti vedere che abbiamo un 404 (risorsa non trovata). Questo ha senso: abbiamo solo detto al server cosa fare quando qualcuno visita localhost:3000/my-test-route . Il browser non ha nulla da visualizzare in localhost:3000 (che equivale a localhost:3000/ con una barra).
Se guardi la finestra del terminale in cui è in esecuzione il server, non dovrebbero esserci nuovi dati. Ora visita localhost:3000/my-test-route nella barra degli URL del tuo browser. Potresti visualizzare lo stesso errore nella console di Chrome (perché il browser sta memorizzando nella cache il contenuto e non ha ancora HTML da visualizzare), ma se visualizzi il tuo terminale in cui è in esecuzione il processo del server, vedrai che la funzione di callback si è effettivamente attivata e il messaggio di registro è stato effettivamente registrato.
Spegni il server con Ctrl + C.
Ora, diamo al browser qualcosa da visualizzare quando viene inviata una richiesta GET a quella route in modo da poter perdere il messaggio Cannot GET / . Prenderò il nostro app.get() di prima e nella funzione di callback aggiungerò due argomenti. Ricorda, la funzione di callback che stiamo passando viene chiamata da Express dietro le quinte ed Express può aggiungere qualsiasi argomento desideri. In realtà ne aggiunge due (beh, tecnicamente tre, ma lo vedremo più avanti), e sebbene siano entrambi estremamente importanti, per ora non ci interessa il primo. Il secondo argomento si chiama res , abbreviazione di response , e vi accederò impostando undefined come primo parametro:
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); }); Di nuovo, possiamo chiamare l'argomento res come vogliamo, ma res è una convenzione quando si ha a che fare con Express. res è in realtà un oggetto e su di esso esistono diversi metodi per inviare i dati al client. In questo caso, accederò alla funzione send(...) disponibile su res per restituire l'HTML che il browser visualizzerà. Non ci limitiamo a restituire HTML, tuttavia, e possiamo scegliere di restituire testo, un oggetto JavaScript, uno stream (gli stream sono particolarmente belli) o qualsiasi altra cosa.
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); res.send('<h1>Hello, World!</h1>'); }); Se spegni il server e lo riattivi, quindi aggiorni il browser nel /my-test-route , vedrai l'HTML essere visualizzato.
La scheda Rete degli strumenti per sviluppatori di Chrome ti consentirà di visualizzare questa richiesta GET con maggiori dettagli in quanto riguarda le intestazioni.
A questo punto, ci sarà utile iniziare a conoscere Express Middleware, funzioni che possono essere attivate a livello globale dopo che un client ha effettuato una richiesta.
Middleware espresso
Express fornisce metodi per definire il middleware personalizzato per l'applicazione. In effetti, il significato di Express Middleware è meglio definito in Express Docs, qui)
Le funzioni middleware sono funzioni che hanno accesso all'oggetto richiesta (
req), all'oggetto risposta (res) e alla successiva funzione middleware nel ciclo richiesta-risposta dell'applicazione. La funzione middleware successiva è comunemente indicata da una variabile denominatanext.
Le funzioni middleware possono eseguire le seguenti attività:
- Esegui qualsiasi codice.
- Apporta modifiche alla richiesta e agli oggetti di risposta.
- Termina il ciclo richiesta-risposta.
- Chiama la prossima funzione middleware nello stack.
In altre parole, una funzione middleware è una funzione personalizzata che noi (lo sviluppatore) possiamo definire e che fungerà da intermediario tra quando Express riceve la richiesta e quando viene attivata la nostra funzione di callback appropriata. Potremmo creare una funzione di log , ad esempio, che registrerà ogni volta che viene effettuata una richiesta. Nota che possiamo anche scegliere di attivare queste funzioni middleware dopo che il nostro endpoint è stato attivato, a seconda di dove lo posizioni nello stack, cosa che vedremo più avanti.
Per specificare il middleware personalizzato, dobbiamo definirlo come una funzione e passarlo in app.use(...) .
const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } app.use(myMiddleware); // This is the app variable returned from express().Tutti insieme, ora abbiamo:
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Our middleware function. const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } // Tell Express to use the middleware. app.use(myMiddleware); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); Se effettui nuovamente le richieste tramite il browser, ora dovresti vedere che la tua funzione middleware si attiva e registra i timestamp. Per favorire la sperimentazione, prova a rimuovere la chiamata alla funzione next e guarda cosa succede.
La funzione di callback del middleware viene chiamata con tre argomenti, req , res e next . req è il parametro che abbiamo saltato durante la creazione del gestore GET in precedenza ed è un oggetto contenente informazioni relative alla richiesta, come intestazioni, intestazioni personalizzate, parametri e qualsiasi corpo che potrebbe essere stato inviato dal client (come fai con una richiesta POST). So che stiamo parlando di middleware qui, ma sia gli endpoint che la funzione middleware vengono chiamati con req e res . req e res saranno gli stessi (a meno che l'uno o l'altro non lo muti) sia nel middleware che nell'endpoint nell'ambito di una singola richiesta dal client. Ciò significa, ad esempio, è possibile utilizzare una funzione middleware per disinfettare i dati eliminando tutti i caratteri che potrebbero essere finalizzati all'esecuzione di iniezioni SQL o NoSQL e quindi consegnando la richiesta di sicurezza req .
res , come visto in precedenza, consente di inviare i dati al client in una manciata di modi diversi.
next è una funzione di callback che devi eseguire quando il middleware ha terminato il suo lavoro per chiamare la prossima funzione del middleware nello stack o nell'endpoint. Assicurati di prendere nota che dovrai chiamarlo nel blocco then di qualsiasi funzione asincrona che attivi nel middleware. A seconda dell'operazione asincrona, potresti volerla chiamare o meno nel blocco catch . Ovvero, la funzione myMiddleware si attiva dopo che la richiesta è stata effettuata dal client ma prima che la funzione endpoint della richiesta venga attivata. Quando eseguiamo questo codice e facciamo una richiesta, dovresti vedere il messaggio Middleware has fired... prima che A GET Request was made to... nella console. Se non chiami next() , l'ultima parte non verrà mai eseguita: la funzione dell'endpoint per la richiesta non verrà attivata.
Nota anche che avrei potuto definire questa funzione in modo anonimo, in quanto tale (una convenzione a cui mi atterrò):
app.use((req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); }); Per chiunque sia nuovo a JavaScript ed ES6, se il modo in cui funziona quanto sopra non ha un senso immediato, l'esempio seguente dovrebbe aiutare. Stiamo semplicemente definendo una funzione di callback (la funzione anonima) che accetta un'altra funzione di callback ( next ) come argomento. Chiamiamo una funzione che accetta un argomento di funzione una funzione di ordine superiore. Guardalo nel modo seguente: descrive un esempio di base di come il codice sorgente espresso potrebbe funzionare dietro le quinte:
console.log('Suppose a request has just been made from the client.\n'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middleware. const next = () => console.log('Terminating Middleware!\n'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the "middleware" function that is passed into "use". // "next" is the above function that pretends to stop the middleware. callback(req, res, next); }; // This is analogous to the middleware function we defined earlier. // It gets passed in as "callback" in the "use" function above. const myMiddleware = (req, res, next) => { console.log('Inside the myMiddleware function!'); next(); } // Here, we are actually calling "use()" to see everything work. use(myMiddleware); console.log('Moving on to actually handle the HTTP Request or the next middleware function.'); Per prima cosa chiamiamo use che prende myMiddleware come argomento. myMiddleware , in sé e per sé, è una funzione che accetta tre argomenti: req , res e next . All'interno di use , viene chiamato myMiddlware e questi tre argomenti vengono passati. next è una funzione definita in use . myMiddleware è definito come callback nel metodo use . Se avessi posizionato use , in questo esempio, su un oggetto chiamato app , avremmo potuto imitare completamente la configurazione di Express, anche se senza socket o connettività di rete.

In questo caso, sia myMiddleware che callback sono funzioni di ordine superiore, poiché entrambe accettano funzioni come argomenti.
Se esegui questo codice, vedrai la seguente risposta:
Suppose a request has just been made from the client. Inside use() - the "use" function has been called. Inside the middleware function! Terminating Middleware! Moving on to actually handle the HTTP Request or the next middleware function.Nota che avrei anche potuto utilizzare funzioni anonime per ottenere lo stesso risultato:
console.log('Suppose a request has just been made from the client.'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middlewear. const next = () => console.log('Terminating Middlewear!'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the function which is passed into "use". // "next" is the above function that pretends to stop the middlewear. callback(req, res, () => { console.log('Terminating Middlewear!'); }); }; // Here, we are actually calling "use()" to see everything work. use((req, res, next) => { console.log('Inside the middlewear function!'); next(); }); console.log('Moving on to actually handle the HTTP Request.');Con questo, si spera, risolto, ora possiamo tornare al compito effettivo: configurare il nostro middleware.
Il fatto è che in genere dovrai inviare i dati tramite una richiesta HTTP. Hai alcune opzioni diverse per farlo: inviare parametri di query URL, inviare dati che saranno accessibili sull'oggetto req di cui abbiamo appreso in precedenza, ecc. Quell'oggetto non è disponibile solo nel callback per chiamare app.use() , ma anche a qualsiasi punto finale. Abbiamo usato undefined come riempitivo in precedenza in modo da poterci concentrare su res per inviare l'HTML al client, ma ora abbiamo bisogno di accedervi.
app.use('/my-test-route', (req, res) => { // The req object contains client-defined data that is sent up. // The res object allows the server to send data back down. });Le richieste HTTP POST potrebbero richiedere l'invio di un oggetto corpo al server. Se hai un modulo sul client e prendi il nome e l'e-mail dell'utente, probabilmente invierai quei dati al server nel corpo della richiesta.
Diamo un'occhiata a come potrebbe apparire sul lato client:
<!DOCTYPE html> <html> <body> <form action="https://localhost:3000/email-list" method="POST" > <input type="text" name="nameInput"> <input type="email" name="emailInput"> <input type="submit"> </form> </body> </html>Lato server:
app.post('/email-list', (req, res) => { // What do we now? // How do we access the values for the user's name and email? }); Per accedere al nome e all'e-mail dell'utente, dovremo utilizzare un particolare tipo di middleware. Questo metterà i dati su un oggetto chiamato body disponibile su req . Body Parser era un metodo popolare per farlo, disponibile dagli sviluppatori di Express come modulo NPM autonomo. Ora, Express viene fornito preconfezionato con il proprio middleware per farlo, e lo chiameremo così:
app.use(express.urlencoded({ extended: true }));Ora possiamo fare:
app.post('/email-list', (req, res) => { console.log('User Name: ', req.body.nameInput); console.log('User Email: ', req.body.emailInput); }); Tutto ciò fa è prendere qualsiasi input definito dall'utente che viene inviato dal client e renderlo disponibile sull'oggetto body di req . Nota che su req.body , ora abbiamo nameInput ed emailInput , che sono i nomi dei tag di input nell'HTML. Ora, questi dati definiti dal cliente dovrebbero essere considerati pericolosi (mai, mai fidarsi del cliente) e devono essere disinfettati, ma ne parleremo più avanti.
Un altro tipo di middleware fornito da express è express.json() . express.json viene utilizzato per impacchettare tutti i payload JSON inviati in una richiesta dal client su req.body , mentre express.urlencoded impacchetta tutte le richieste in arrivo con stringhe, array o altri dati con codifica URL su req.body . In breve, entrambi manipolano req.body , ma .json() è per JSON Payloads e .urlencoded() è, tra gli altri, parametri di query POST.
Un altro modo per dirlo è che le richieste in entrata con un'intestazione Content-Type: application/json (come la specifica di un corpo POST con l'API fetch ) saranno gestite da express.json() , mentre le richieste con header Content-Type: application/x-www-form-urlencoded (come i moduli HTML) verrà gestito con express.urlencoded() . Si spera che ora abbia un senso.
Inizio delle nostre rotte CRUD per MongoDB
Nota : durante l'esecuzione di richieste PATCH in questo articolo, non seguiremo le specifiche RFC JSONPatch, un problema che correggeremo nel prossimo articolo di questa serie.
Considerando che comprendiamo che specifichiamo ogni endpoint chiamando la relativa funzione su app , passandogli la route e una funzione di callback contenente gli oggetti di richiesta e risposta, possiamo iniziare a definire i nostri percorsi CRUD per l'API Bookshelf. In effetti, e considerando che questo è un articolo introduttivo, non mi prenderò cura di seguire completamente le specifiche HTTP e REST, né tenterò di utilizzare l'architettura più pulita possibile. Arriverà in un prossimo articolo.
Aprirò il file server.js che abbiamo utilizzato finora e svuoterò tutto per iniziare dalla lavagna pulita di seguito:
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true )); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Considera tutto il codice seguente per occupare la // ... parte del file sopra.
Per definire i nostri endpoint e poiché stiamo costruendo un'API REST, dovremmo discutere il modo corretto per denominare le rotte. Ancora una volta, dovresti dare un'occhiata alla sezione HTTP del mio precedente articolo per ulteriori informazioni. Abbiamo a che fare con libri, quindi tutti i percorsi saranno posizionati dietro /books (la convenzione di denominazione plurale è standard).
| Richiesta | Rotta |
|---|---|
| INVIARE | /books |
| OTTENERE | /books/id |
| TOPPA | /books/id |
| ELIMINARE | /books/id |
Come puoi vedere, non è necessario specificare un ID durante il POST di un libro perché lo genereremo (o meglio, MongoDB) per noi, automaticamente, lato server. I libri GETting, PATCHing ed DELETing richiederanno tutti di passare quell'ID al nostro endpoint, di cui parleremo in seguito. Per ora, creiamo semplicemente gli endpoint:
// HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); La sintassi :id dice a Express che id è un parametro dinamico che verrà passato nell'URL. Abbiamo accesso ad esso sull'oggetto params che è disponibile su req . So che "abbiamo accesso ad esso su req " suona come la magia e la magia (che non esiste) è pericolosa nella programmazione, ma devi ricordare che Express non è una scatola nera. È un progetto open source disponibile su GitHub con una licenza MIT. Puoi facilmente visualizzare il suo codice sorgente se vuoi vedere come i parametri di query dinamici vengono inseriti nell'oggetto req .
Tutti insieme, ora abbiamo quanto segue nel nostro file server.js :
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Vai avanti e avvia il server, eseguendo node server.js dal terminale o dalla riga di comando e visita il tuo browser. Apri la Console di sviluppo di Chrome e nella barra dell'URL (Uniform Resource Locator), visita localhost:3000/books . Dovresti già vedere l'indicatore nel terminale del tuo sistema operativo che il server è attivo così come l'istruzione di registro per GET.
Finora, abbiamo utilizzato un browser Web per eseguire le richieste GET. Questo è un bene per iniziare, ma scopriremo rapidamente che esistono strumenti migliori per testare i percorsi API. In effetti, potremmo incollare le chiamate di fetch direttamente nella console o utilizzare un servizio online. Nel nostro caso, e per risparmiare tempo, utilizzeremo cURL e Postman. Io uso entrambi in questo articolo (anche se potresti usare uno o l'altro) in modo da poterli presentare se non li hai usati. cURL è una libreria (una libreria molto, molto importante) e uno strumento da riga di comando progettato per trasferire dati utilizzando vari protocolli. Postman è uno strumento basato su GUI per testare le API. Dopo aver seguito le istruzioni di installazione pertinenti per entrambi gli strumenti sul tuo sistema operativo, assicurati che il tuo server sia ancora in esecuzione, quindi esegui i seguenti comandi (uno per uno) in un nuovo terminale. È importante digitarli ed eseguirli individualmente, quindi guardare il messaggio di registro nel terminale separato dal server. Si noti inoltre che il simbolo di commento del linguaggio di programmazione standard // non è un simbolo valido in Bash o MS-DOS. Dovrai omettere quelle righe e le uso qui solo per descrivere ogni blocco di comandi cURL .
// HTTP POST Request (Localhost, IPv4, IPv6) curl -X POST https://localhost:3000/books curl -X POST https://127.0.0.1:3000/books curl -X POST https://[::1]:3000/books // HTTP GET Request (Localhost, IPv4, IPv6) curl -X GET https://localhost:3000/books/123abc curl -X GET https://127.0.0.1:3000/books/book-id-123 curl -X GET https://[::1]:3000/books/book-abc123 // HTTP PATCH Request (Localhost, IPv4, IPv6) curl -X PATCH https://localhost:3000/books/456 curl -X PATCH https://127.0.0.1:3000/books/218 curl -X PATCH https://[::1]:3000/books/some-id // HTTP DELETE Request (Localhost, IPv4, IPv6) curl -X DELETE https://localhost:3000/books/abc curl -X DELETE https://127.0.0.1:3000/books/314 curl -X DELETE https://[::1]:3000/books/217 Come puoi vedere, l'ID passato come parametro URL può essere qualsiasi valore. Il flag -X specifica il tipo di richiesta HTTP (può essere omesso per GET) e forniamo l'URL a cui verrà inviata la richiesta in seguito. Ho duplicato ogni richiesta tre volte, consentendoti di vedere che tutto funziona ancora indipendentemente dal fatto che utilizzi il nome host localhost , l'indirizzo IPv4 ( 127.0.0.1 ) a cui si risolve localhost o l'indirizzo IPv6 ( ::1 ) a cui si risolve localhost . Tieni presente che cURL richiede il wrapping degli indirizzi IPv6 tra parentesi quadre.
Ora siamo in una posizione decente: abbiamo impostato la struttura semplice delle nostre rotte e degli endpoint. Il server funziona correttamente e accetta le richieste HTTP come previsto. Contrariamente a quanto ci si potrebbe aspettare, a questo punto non c'è molto da fare: dobbiamo solo configurare il nostro database, ospitarlo (usando un Database-as-a-Service - MongoDB Atlas) e persistere i dati su di esso (e eseguire la convalida e creare risposte di errore).
Configurazione di un database MongoDB di produzione
Per impostare un database di produzione, ci dirigeremo alla home page di MongoDB Atlas e ci iscriveremo per un account gratuito. Successivamente, crea un nuovo cluster. È possibile mantenere le impostazioni predefinite, selezionando una regione applicabile a un livello tariffario. Quindi premi il pulsante "Crea cluster". La creazione del cluster richiederà del tempo, quindi sarai in grado di ottenere l'URL e la password del database. Prendi nota di questi quando li vedi. Per ora li codificheremo e li memorizzeremo nelle variabili di ambiente in un secondo momento per motivi di sicurezza. Per assistenza nella creazione e connessione a un cluster, ti rimando alla documentazione MongoDB, in particolare questa pagina e questa pagina, oppure puoi lasciare un commento qui sotto e cercherò di aiutarti.
Creazione di un modello di mangusta
Si consiglia di comprendere i significati di Documenti e Raccolte nel contesto di NoSQL (non solo SQL — Structured Query Language). Per riferimento, potresti voler leggere sia la Guida rapida di Mongoose che la sezione MongoDB del mio precedente articolo.
Ora abbiamo un database pronto per accettare le operazioni CRUD. Mongoose è un modulo Node (o ODM — Object Document Mapper) che ci consentirà di eseguire tali operazioni (astraendo alcune delle complessità) nonché di impostare lo schema, o la struttura, della raccolta di database.
Come importante disclaimer, ci sono molte controversie sugli ORM e su modelli come Active Record o Data Mapper. Alcuni sviluppatori giurano sugli ORM e altri giurano contro di loro (credendo che si mettano in mezzo). È anche importante notare che gli ORM astraggono molto come pool di connessioni, connessioni socket e gestione, ecc. Potresti facilmente usare il driver nativo MongoDB (un altro modulo NPM), ma parlerebbe molto più lavoro. Sebbene sia consigliabile giocare con il driver nativo prima di utilizzare gli ORM, ometto il driver nativo qui per brevità. Per operazioni SQL complesse su un database relazionale, non tutti gli ORM saranno ottimizzati per la velocità delle query e potresti finire per scrivere il tuo SQL grezzo. ORMs can come into play a lot with Domain-Driven Design and CQRS, among others. They are an established concept in the .NET world, and the Node.js community has not completely caught up yet — TypeORM is better, but it's not NHibernate or Entity Framework.
To create our Model, I'll create a new folder in the server directory entitled models , within which I'll create a single file with the name book.js . Thus far, our project's directory structure is as follows:
- server - node_modules - models - book.js - package.json - server.js Indeed, this directory structure is not required, but I use it here because it's simple. Allow me to note that this is not at all the kind of architecture you want to use for larger applications (and you might not even want to use JavaScript — TypeScript could be a better option), which I discuss in this article's closing. The next step will be to install mongoose , which is performed via, as you might expect, npm i mongoose .
The meaning of a Model is best ascertained from the Mongoose documentation:
Models are fancy constructors compiled from
Schemadefinitions. An instance of a model is called a document. Models are responsible for creating and reading documents from the underlying MongoDB database.
Before creating the Model, we'll define its Schema. A Schema will, among others, make certain expectations about the value of the properties provided. MongoDB is schemaless, and thus this functionality is provided by the Mongoose ODM. Let's start with a simple example. Suppose I want my database to store a user's name, email address, and password. Traditionally, as a plain old JavaScript Object (POJO), such a structure might look like this:
const userDocument = { name: 'Jamie Corkhill', email: '[email protected]', password: 'Bcrypt Hash' };If that above object was how we expected our user's object to look, then we would need to define a schema for it, like this:
const schema = { name: { type: String, trim: true, required: true }, email: { type: String, trim: true, required: true }, password: { type: String, required: true } }; Notice that when creating our schema, we define what properties will be available on each document in the collection as an object in the schema. In our case, that's name , email , and password . The fields type , trim , required tell Mongoose what data to expect. If we try to set the name field to a number, for example, or if we don't provide a field, Mongoose will throw an error (because we are expecting a type of String ), and we can send back a 400 Bad Request to the client. This might not make sense right now because we have defined an arbitrary schema object. However, the fields of type , trim , and required (among others) are special validators that Mongoose understands. trim , for example, will remove any whitespace from the beginning and end of the string. We'll pass the above schema to mongoose.Schema() in the future and that function will know what to do with the validators.
Understanding how Schemas work, we'll create the model for our Books Collection of the Bookshelf API. Let's define what data we require:
Titolo
ISBN Number
Autore
Nome di battesimo
Cognome
Publishing Date
Finished Reading (Boolean)
I'm going to create this in the book.js file we created earlier in /models . Like the example above, we'll be performing validation:
const mongoose = require('mongoose'); // Define the schema: const mySchema = { title: { type: String, required: true, trim: true, }, isbn: { type: String, required: true, trim: true, }, author: { firstName:{ type: String, required: true, trim: true }, lastName: { type: String, required: true, trim: true } }, publishingDate: { type: String }, finishedReading: { type: Boolean, required: true, default: false } } default will set a default value for the property if none is provided — finishedReading for example, although a required field, will be set automatically to false if the client does not send one up.
Mongoose also provides the ability to perform custom validation on our fields, which is done by supplying the validate() method, which attains the value that was attempted to be set as its one and only parameter. In this function, we can throw an error if the validation fails. Ecco un esempio:
// ... isbn: { type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } } // ... Now, if anyone supplies an invalid ISBN to our model, Mongoose will throw an error when trying to save that document to the collection. I've already installed the NPM module validator via npm i validator and required it. validator contains a bunch of helper functions for common validation requirements, and I use it here instead of RegEx because ISBNs can't be validated with RegEx alone due to a tailing checksum. Remember, users will be sending a JSON body to one of our POST routes. That endpoint will catch any errors (such as an invalid ISBN) when attempting to save, and if one is thrown, it'll return a blank response with an HTTP 400 Bad Request status — we haven't yet added that functionality.
Finally, we have to define our schema of earlier as the schema for our model, so I'll make a call to mongoose.Schema() passing in that schema:
const bookSchema = mongoose.Schema(mySchema); To make things more precise and clean, I'll replace the mySchema variable with the actual object all on one line:
const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } });Let's take a final moment to discuss this schema. We are saying that each of our documents will consist of a title, an ISBN, an author with a first and last name, a publishing date, and a finishedReading boolean.
-
titlewill be of typeString, it's a required field, and we'll trim any whitespace. -
isbnwill be of typeString, it's a required field, it must match the validator, and we'll trim any whitespace. -
authoris of typeobjectcontaining a required, trimmed,stringfirstName and a required, trimmed,stringlastName. -
publishingDateis of type String (although we could make it of typeDateorNumberfor a Unix timestamp. -
finishedReadingis a requiredbooleanthat will default tofalseif not provided.
With our bookSchema defined, Mongoose knows what data and what fields to expect within each document to the collection that stores books. However, how do we tell it what collection that specific schema defines? We could have hundreds of collections, so how do we correlate, or tie, bookSchema to the Book collection?
The answer, as seen earlier, is with the use of models. We'll use bookSchema to create a model, and that model will model the data to be stored in the Book collection, which will be created by Mongoose automatically.
Append the following lines to the end of the file:
const Book = mongoose.model('Book', bookSchema); module.exports = Book; As you can see, we have created a model, the name of which is Book (— the first parameter to mongoose.model() ), and also provided the ruleset, or schema, to which all data is saved in the Book collection will have to abide. We export this model as a default export, allowing us to require the file for our endpoints to access. Book is the object upon which we'll call all of the required functions to Create, Read, Update, and Delete data which are provided by Mongoose.
Altogether, our book.js file should look as follows:
const mongoose = require('mongoose'); const validator = require('validator'); // Define the schema. const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String, required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } }); // Create the "Book" model of name Book with schema bookSchema. const Book = mongoose.model('Book', bookSchema); // Provide the model as a default export. module.exports = Book;Connecting To MongoDB (Basics)
Don't worry about copying down this code. I'll provide a better version in the next section. To connect to our database, we'll have to provide the database URL and password. We'll call the connect method available on mongoose to do so, passing to it the required data. For now, we are going hardcode the URL and password — an extremely frowned upon technique for many reasons: namely the accidental committing of sensitive data to a public (or private made public) GitHub Repository. Realize also that commit history is saved, and that if you accidentally commit a piece of sensitive data, removing it in a future commit will not prevent people from seeing it (or bots from harvesting it), because it's still available in the commit history. CLI tools exist to mitigate this issue and remove history.
As stated, for now, we'll hard code the URL and password, and then save them to environment variables later. At this point, let's look at simply how to do this, and then I'll mention a way to optimize it.
const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false, useUnifiedTopology: true });Questo si collegherà al database. Forniamo l'URL che abbiamo ottenuto dal dashboard di MongoDB Atlas e l'oggetto passato come secondo parametro specifica le funzionalità da utilizzare per prevenire, tra l'altro, avvisi di deprecazione.
Mongoose, che utilizza il core MongoDB Native Driver dietro le quinte, deve tentare di tenere il passo con le modifiche sostanziali apportate al driver. In una nuova versione del driver, il meccanismo utilizzato per analizzare gli URL di connessione è stato modificato, quindi passiamo al flag useNewUrlParser: true per specificare che vogliamo utilizzare l'ultima versione disponibile dal driver ufficiale.
Per impostazione predefinita, se imposti gli indici (e sono chiamati "indici" non "indici") (che non tratteremo in questo articolo) sui dati nel tuo database, Mongoose utilizza la funzione ensureIndex() disponibile dal driver nativo. MongoDB ha deprecato quella funzione a favore di createIndex() , quindi impostando il flag useCreateIndex su true dirà a Mongoose di usare il metodo createIndex() dal driver, che è la funzione non deprecata.
La versione originale di Mongoose di findOneAndUpdate (che è un metodo per trovare un documento in un database e aggiornarlo) è precedente alla versione del driver nativo. Cioè, findOneAndUpdate() non era originariamente una funzione Native Driver ma piuttosto una fornita da Mongoose, quindi Mongoose ha dovuto usare findAndModify fornito dietro le quinte dal driver per creare la funzionalità findOneAndUpdate . Con il driver ora aggiornato, contiene la propria funzione di questo tipo, quindi non dobbiamo usare findAndModify . Questo potrebbe non avere senso, e va bene: non è un'informazione importante sulla scala delle cose.
Infine, MongoDB ha deprecato il suo vecchio sistema di monitoraggio del server e del motore. Usiamo il nuovo metodo con useUnifiedTopology: true .
Quello che abbiamo finora è un modo per connettersi al database. Ma ecco il punto: non è scalabile o efficiente. Quando scriviamo unit test per questa API, gli unit test utilizzeranno i propri dati di test (o fixture) sui propri database di test. Quindi, vogliamo un modo per essere in grado di creare connessioni per scopi diversi: alcuni per ambienti di test (che possiamo avviare e smontare a piacimento), altri per ambienti di sviluppo e altri per ambienti di produzione. Per farlo, costruiremo una fabbrica. (Ricordi quello di prima?)
Collegamento a Mongo — Realizzazione di un'implementazione di una fabbrica JS
In effetti, gli oggetti Java non sono affatto analoghi agli oggetti JavaScript e quindi, di conseguenza, ciò che sappiamo sopra dal Factory Design Pattern non si applicherà. L'ho semplicemente fornito come esempio per mostrare il modello tradizionale. Per ottenere un oggetto in Java, o C#, o C++, ecc., dobbiamo istanziare una classe. Questo viene fatto con la new parola chiave, che indica al compilatore di allocare memoria per l'oggetto nell'heap. In C++, questo ci fornisce un puntatore all'oggetto che dobbiamo ripulire noi stessi in modo da non avere puntatori sospesi o perdite di memoria (C++ non ha Garbage Collector, a differenza di Node/V8 che è basato su C++) In JavaScript, il non è necessario fare quanto sopra — non è necessario istanziare una classe per ottenere un oggetto — un oggetto è solo {} . Alcune persone diranno che tutto in JavaScript è un oggetto, anche se tecnicamente non è vero perché i tipi primitivi non sono oggetti.
Per i motivi di cui sopra, la nostra fabbrica JS sarà più semplice, attenendosi alla definizione vaga di una fabbrica che è una funzione che restituisce un oggetto (un oggetto JS). Poiché una funzione è un oggetto (perché la function eredita object tramite l'ereditarietà prototipica), il nostro esempio seguente soddisferà questo criterio. Per implementare la fabbrica, creerò una nuova cartella all'interno del server chiamata db . All'interno di db creerò un nuovo file chiamato mongoose.js . Questo file effettuerà connessioni al database. All'interno di mongoose.js , creerò una funzione chiamata connectionFactory e la esporterò per impostazione predefinita:
// Directory - server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; const connectionFactory = () => { return mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false }); }; module.exports = connectionFactory; Usando la scorciatoia fornita da ES6 per le funzioni freccia che restituiscono un'istruzione sulla stessa riga della firma del metodo, renderò questo file più semplice eliminando la definizione connectionFactory ed esportando semplicemente la fabbrica per impostazione predefinita:
// server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; module.exports = () => mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: true });Ora, tutto ciò che devi fare è richiedere il file e chiamare il metodo che viene esportato, in questo modo:
const connectionFactory = require('./db/mongoose'); connectionFactory(); // OR require('./db/mongoose')();Puoi invertire il controllo fornendo il tuo URL MongoDB come parametro per la funzione factory, ma cambieremo dinamicamente l'URL come variabile di ambiente basata sull'ambiente.
I vantaggi di creare la nostra connessione come funzione sono che possiamo chiamare quella funzione più avanti nel codice per connetterci al database da file destinati alla produzione e quelli finalizzati al test di integrazione locale e remoto sia sul dispositivo che con una pipeline CI/CD remota /crea server.
Costruire i nostri endpoint
Ora iniziamo ad aggiungere una logica correlata a CRUD molto semplice ai nostri endpoint. Come detto in precedenza, è d'obbligo un breve disclaimer. I metodi con cui implementiamo la nostra logica aziendale qui non sono quelli che dovresti rispecchiare per qualcosa di diverso dai semplici progetti. La connessione ai database e l'esecuzione della logica direttamente all'interno degli endpoint è (e dovrebbe essere) disapprovata, poiché si perde la capacità di sostituire servizi o DBMS senza dover eseguire un refactoring a livello di applicazione. Tuttavia, considerando che questo è un articolo per principianti, utilizzo queste cattive pratiche qui. Un futuro articolo di questa serie discuterà come possiamo aumentare sia la complessità che la qualità della nostra architettura.
Per ora, torniamo al nostro file server.js e assicuriamoci di avere entrambi lo stesso punto di partenza. Avviso Ho aggiunto l'istruzione require per la nostra factory di connessione al database e ho importato il modello che abbiamo esportato da ./models/book.js .
const express = require('express'); // Database connection and model. require('./db/mongoose.js'); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Inizierò con app.post() . Abbiamo accesso al modello Book perché lo abbiamo esportato dal file all'interno del quale lo abbiamo creato. Come affermato nei documenti di Mongoose, il Book è costruibile. Per creare un nuovo libro, chiamiamo il costruttore e passiamo i dati del libro, come segue:
const book = new Book(bookData); Nel nostro caso avremo bookData come oggetto inviato nella richiesta, che sarà disponibile su req.body.book . Ricorda, il middleware express.json() inserirà tutti i dati JSON che inviamo su req.body . Dobbiamo inviare JSON nel seguente formato:
{ "book": { "title": "The Art of Computer Programming", "isbn": "ISBN-13: 978-0-201-89683-1", "author": { "firstName": "Donald", "lastName": "Knuth" }, "publishingDate": "July 17, 1997", "finishedReading": true } } Ciò significa, quindi, che il JSON che trasmettiamo verrà analizzato e l'intero oggetto JSON (il primo paio di parentesi graffe) verrà posizionato su req.body dal middleware express.json express.json() . L'unica proprietà del nostro oggetto JSON è book , quindi l'oggetto book sarà disponibile su req.body.book .
A questo punto, possiamo chiamare la funzione di costruzione del modello e passare i nostri dati:
app.post('/books', async (req, res) => { // <- Notice 'async' const book = new Book(req.body.book); await book.save(); // <- Notice 'await' }); Nota alcune cose qui. Chiamando il metodo save sull'istanza che torniamo dalla chiamata alla funzione di costruzione, l'oggetto req.body.book persisterà nel database se e solo se è conforme allo schema che abbiamo definito nel modello Mongoose. L'atto di salvare i dati in un database è un'operazione asincrona e questo metodo save() restituisce una promessa, la cui conclusione è molto attesa. Invece di concatenare una chiamata .then() , utilizzo la sintassi ES6 Async/Await, il che significa che devo eseguire la funzione di callback su app.post async .
book.save() rifiuterà con un ValidationError se l'oggetto inviato dal client non è conforme allo schema che abbiamo definito. La nostra configurazione attuale rende il codice molto traballante e scritto male, perché non vogliamo che la nostra applicazione si arresti in modo anomalo in caso di errore relativo alla convalida. Per risolvere il problema, circonderò l'operazione pericolosa in una clausola try/catch . In caso di errore, restituirò una richiesta non valida HTTP 400 o un'entità non elaborabile HTTP 422. C'è una certa quantità di dibattito su quale usare, quindi rimarrò con un 400 per questo articolo poiché è più generico.
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { return res.status(400).send({ error: 'ValidationError' }); } }); Si noti che utilizzo l'abbreviazione dell'oggetto ES6 per restituire l'oggetto book al client nel caso di successo con res.send({ book }) — sarebbe equivalente a res.send({ book: book }) . Restituisco anche l'espressione solo per assicurarmi che la mia funzione esca. Nel blocco catch , ho impostato lo stato su 400 in modo esplicito e ho restituito la stringa "ValidationError" sulla proprietà error dell'oggetto che viene restituito. A 201 è il codice di stato del percorso di successo che significa "CREATO".
In effetti, questa non è nemmeno la soluzione migliore perché non possiamo essere davvero sicuri che il motivo del fallimento sia una cattiva richiesta da parte del cliente. Forse abbiamo perso la connessione (supponendo una connessione socket interrotta, quindi un'eccezione transitoria) al database, nel qual caso dovremmo probabilmente restituire un errore interno del server 500. Un modo per verificarlo sarebbe leggere l'oggetto e error e restituire selettivamente una risposta. Facciamolo ora, ma come ho detto più volte, un articolo successivo discuterà l'architettura corretta in termini di router, controller, servizi, repository, classi di errore personalizzate, middleware di errore personalizzato, risposte di errore personalizzate, modello di database/dati di entità di dominio mappatura e separazione delle query dei comandi (CQS).
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'ValidationError' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); Vai avanti e apri Postman (supponendo che tu lo abbia, altrimenti scaricalo e installalo) e crea una nuova richiesta. Faremo una richiesta POST a localhost:3000/books . Nella scheda "Corpo" all'interno della sezione Richiesta postino, selezionerò il pulsante di opzione "grezzo" e selezionerò "JSON" nel pulsante a discesa all'estrema destra. Questo andrà avanti e aggiungerà automaticamente l'intestazione Content-Type: application/json alla richiesta. Quindi copierò e incollerò l'oggetto JSON del libro da prima nell'area di testo del corpo. Questo è quello che abbiamo:
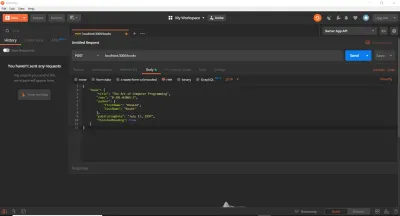
Successivamente, premerò il pulsante di invio e dovresti vedere una risposta 201 Created nella sezione "Risposta" di Postman (la riga in basso). Lo vediamo perché abbiamo chiesto espressamente a Express di rispondere con un 201 e l'oggetto Book: se avessimo appena fatto res.send() senza codice di stato, express avrebbe risposto automaticamente con un 200 OK. Come puoi vedere, l'oggetto Book è ora salvato nel database ed è stato restituito al client come risposta alla richiesta POST.
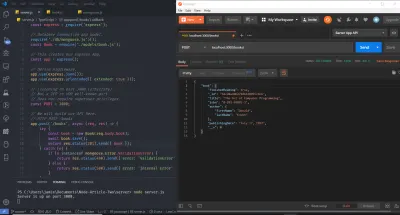
Se visualizzi la raccolta di libri del database tramite MongoDB Atlas, vedrai che il libro è stato effettivamente salvato.
Puoi anche dire che MongoDB ha inserito i campi __v e _id . Il primo rappresenta la versione del documento, in questo caso, 0, e il secondo è l'ObjectID del documento, che viene generato automaticamente da MongoDB e garantisce una bassa probabilità di collisione.
Un riassunto di ciò che abbiamo trattato finora
Abbiamo trattato molto finora nell'articolo. Facciamo una breve tregua esaminando un breve riepilogo prima di tornare a completare l'API Express.
Abbiamo appreso della ES6 Object Destructuring, della ES6 Object Shorthand Syntax e dell'operatore ES6 Rest/Spread. Tutti e tre ci permettono di fare quanto segue (e altro, come discusso sopra):
// Destructuring Object Properties: const { a: newNameA = 'Default', b } = { a: 'someData', b: 'info' }; console.log(`newNameA: ${newNameA}, b: ${b}`); // newNameA: someData, b: info // Destructuring Array Elements const [elemOne, elemTwo] = [() => console.log('hi'), 'data']; console.log(`elemOne(): ${elemOne()}, elemTwo: ${elemTwo}`); // elemOne(): hi, elemTwo: data // Object Shorthand const makeObj = (name) => ({ name }); console.log(`makeObj('Tim'): ${JSON.stringify(makeObj('Tim'))}`); // makeObj('Tim'): { "name": "Tim" } // Rest, Spread const [c, d, ...rest] = [0, 1, 2, 3, 4]; console.log(`c: ${c}, d: ${d}, rest: ${rest}`) // c: 0, d: 1, rest: 2, 3, 4 Abbiamo anche trattato Express, Expess Middleware, Server, Porte, Indirizzamento IP, ecc. Le cose sono diventate interessanti quando abbiamo appreso che esistono metodi disponibili sul risultato restituito da require('express')(); con i nomi dei verbi HTTP, come app.get e app.post .
Se quella parte require('express')() non aveva senso per te, questo era il punto che stavo facendo:
const express = require('express'); const app = express(); app.someHTTPVerbDovrebbe avere senso nello stesso modo in cui abbiamo licenziato la fabbrica di connessioni prima per Mongoose.
Ogni gestore di route, che è la funzione endpoint (o funzione di callback), viene passato in un oggetto req e un oggetto res da Express dietro le quinte. (Tecnicamente ottengono anche il next , come vedremo tra un minuto). req contiene i dati specifici della richiesta in arrivo dal client, come le intestazioni o qualsiasi JSON inviato. res è ciò che ci permette di restituire le risposte al cliente. Anche la funzione next viene passata ai gestori.
Con Mongoose, abbiamo visto come possiamo connetterci al database con due metodi: un modo primitivo e un modo più avanzato/pratico che prende in prestito dal Factory Pattern. Finiremo per usarlo quando discuteremo di Unit e Integration Testing con Jest (e test di mutazione) perché ci consentirà di creare un'istanza di test del DB popolata con dati seed rispetto alla quale possiamo eseguire asserzioni.
Successivamente, abbiamo creato un oggetto schema Mongoose e lo abbiamo utilizzato per creare un modello, quindi abbiamo imparato come chiamare il costruttore di quel modello per crearne una nuova istanza. Nell'istanza è disponibile un metodo di save (tra gli altri), che è di natura asincrona e che verificherà che la struttura dell'oggetto che abbiamo passato sia conforme allo schema, risolvendo la promessa se lo fa e rifiutando la promessa con un ValidationError se non è così. In caso di risoluzione, il nuovo documento viene salvato nel database e noi rispondiamo con un HTTP 200 OK/201 CREATED, altrimenti catturiamo l'errore generato nel nostro endpoint e restituiamo un HTTP 400 Bad Request al client.
Man mano che continuiamo a creare i nostri endpoint, imparerai di più su alcuni dei metodi disponibili sul modello e sull'istanza del modello.
Finire i nostri endpoint
Dopo aver completato il POST Endpoint, gestiamo GET. Come accennato in precedenza, la sintassi :id all'interno della route consente a Express di sapere che id è un parametro di route, accessibile da req.params . Hai già visto che quando abbini un ID per il parametro "carattere jolly" nel percorso, è stato stampato sullo schermo nei primi esempi. Ad esempio, se hai effettuato una richiesta GET a "/books/test-id-123", req.params.id sarebbe la stringa test-id-123 perché il nome del parametro era id avendo il percorso come HTTP GET /books/:id .
Quindi, tutto ciò che dobbiamo fare è recuperare quell'ID dall'oggetto req e controllare se qualche documento nel nostro database ha lo stesso ID, cosa resa molto semplice da Mongoose (e dal driver nativo).
app.get('/books/:id', async (req, res) => { const book = await Book.findById(req.params.id); console.log(book); res.send({ book }); }); Puoi vedere che accessibile sul nostro modello è una funzione che possiamo chiamare che troverà un documento in base al suo ID. Dietro le quinte, Mongoose lancerà qualsiasi ID che passiamo in findById al tipo del campo _id sul documento, o in questo caso, un ObjectId . Se viene trovato un ID corrispondente (e solo uno verrà mai trovato per ObjectId ha una probabilità di collisione estremamente bassa), quel documento verrà inserito nella nostra variabile costante del book . In caso contrario, il book sarà nullo, un fatto che utilizzeremo nel prossimo futuro.
Per ora, riavviamo il server (devi riavviare il server a meno che tu non stia usando nodemon ) e assicurati di avere ancora il documento di un libro di prima all'interno della Raccolta di Books . Vai avanti e copia l'ID di quel documento, la parte evidenziata dell'immagine qui sotto:

E usalo per fare una richiesta GET a /books/:id con Postman come segue (nota che i dati del corpo sono appena rimasti dalla mia precedente richiesta POST. In realtà non viene utilizzato nonostante sia raffigurato nell'immagine qui sotto) :
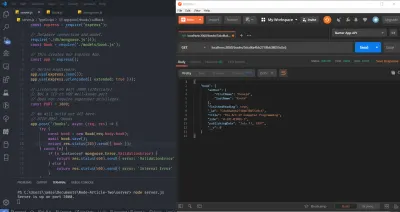
In tal caso, dovresti recuperare il documento del libro con l'ID specificato nella sezione di risposta del postino. Si noti che in precedenza, con la route POST, progettata per "POST" o "spingere" nuove risorse sul server, abbiamo risposto con un 201 Created, perché è stata creata una nuova risorsa (o documento). Nel caso di GET, non è stato creato nulla di nuovo: abbiamo solo richiesto una risorsa con un ID specifico, quindi un codice di stato 200 OK è quello che abbiamo ottenuto, invece di 201 Creato.
Come è comune nel campo dello sviluppo del software, i casi limite devono essere presi in considerazione: l'input dell'utente è intrinsecamente pericoloso ed errato, ed è nostro compito, come sviluppatori, essere flessibili ai tipi di input che possiamo ricevere e rispondere ad essi di conseguenza. Cosa facciamo se l'utente (o il chiamante API) ci passa un ID che non può essere trasmesso a un ObjectID MongoDB o un ID che può essere trasmesso ma che non esiste?
Nel primo caso, Mongoose lancerà un CastError , il che è comprensibile perché se forniamo un ID come math-is-fun , allora ovviamente non è qualcosa che può essere lanciato su un ObjectID e il casting su un ObjectID è specificamente ciò che La mangusta sta facendo sotto il cofano.
Per quest'ultimo caso, potremmo facilmente correggere il problema tramite un Null Check o una Guard Clause. In ogni caso, invierò indietro e HTTP 404 Not Found Response. Ti mostrerò alcuni modi in cui possiamo farlo, un modo cattivo e poi un modo migliore.
In primo luogo, potremmo fare quanto segue:
app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) throw new Error(); return res.send({ book }); } catch (e) { return res.status(404).send({ error: 'Not Found' }); } }); Funziona e possiamo usarlo bene. Mi aspetto che l'istruzione await Book.findById() genererà un Mongoose CastError se non è possibile eseguire il cast della stringa ID su un ObjectID, causando l'esecuzione del blocco catch . Se può essere eseguito il cast ma l'ObjectID corrispondente non esiste, book sarà null e il Null Check genererà un errore, attivando nuovamente il blocco catch . Dentro catch , restituiamo solo un 404. Ci sono due problemi qui. In primo luogo, anche se il libro viene trovato ma si verifica qualche altro errore sconosciuto, inviamo un 404 quando probabilmente dovremmo fornire al client un generico 500 catch-all. In secondo luogo, non stiamo davvero differenziando tra se l'ID inviato è valido ma inesistente o se si tratta solo di un ID errato.
Quindi, ecco un altro modo:
const mongoose = require('mongoose'); app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); La cosa bella di questo è che possiamo gestire tutti e tre i casi di un 400, un 404 e un 500 generico. Si noti che dopo il Null Check on book , utilizzo la parola chiave return nella mia risposta. Questo è molto importante perché vogliamo assicurarci di uscire dal gestore del percorso lì.
Alcune altre opzioni potrebbero essere utili per verificare se l' id su req.params può essere convertito in un ObjectID in modo esplicito invece di consentire a Mongoose di eseguire il cast implicito con mongoose.Types.ObjectId.isValid('id); , ma esiste un caso limite con stringhe di 12 byte che a volte fa funzionare in modo imprevisto.
Potremmo rendere tale ripetizione meno dolorosa con Boom , una libreria di risposta HTTP, ad esempio, oppure potremmo utilizzare il middleware di gestione degli errori. Potremmo anche trasformare Mongoose Errors in qualcosa di più leggibile con Mongoose Hooks/Middleware come descritto qui. Un'opzione aggiuntiva sarebbe quella di definire oggetti di errore personalizzati e utilizzare il middleware di gestione degli errori espresso globale, tuttavia, lo salverò per un prossimo articolo in cui discutiamo metodi architetturali migliori.
Nell'endpoint per PATCH /books/:id , ci si aspetta che venga passato un oggetto update contenente gli aggiornamenti per il libro in questione. Per questo articolo, consentiremo l'aggiornamento di tutti i campi, ma in futuro mostrerò come impedire l'aggiornamento di campi particolari. Inoltre, vedrai che la logica di gestione degli errori nel nostro PATCH Endpoint sarà la stessa del nostro GET Endpoint. Questa è un'indicazione che stiamo violando i principi DRY, ma ancora una volta, ne parleremo più avanti.
Mi aspetto che tutti gli aggiornamenti siano disponibili sull'oggetto updates di req.body (il che significa che il client invierà JSON contenente un oggetto updates ) e utilizzerà la funzione Book.findByAndUpdate con un flag speciale per eseguire l'aggiornamento.
app.patch('/books/:id', async (req, res) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); Nota alcune cose qui. Destrutturiamo prima l' id da req.params e updates da req.body .
Nel modello Book è disponibile una funzione denominata findByIdAndUpdate che prende l'ID del documento in questione, gli aggiornamenti da eseguire e un oggetto opzioni facoltativo. Normalmente, Mongoose non eseguirà nuovamente la convalida per le operazioni di aggiornamento, quindi il runValidators: true passiamo quando l'oggetto options lo costringe a farlo. Inoltre, a partire da Mongoose 4, Model.findByIdAndUpdate non restituisce più il documento modificato ma restituisce invece il documento originale. Il new: true flag (che è false per impostazione predefinita) sovrascrive quel comportamento.
Infine, possiamo costruire il nostro endpoint DELETE, che è abbastanza simile a tutti gli altri:
app.delete('/books/:id', async (req, res) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } });Con ciò, la nostra API primitiva è completa e puoi testarla effettuando richieste HTTP a tutti gli endpoint.
Una breve dichiarazione di non responsabilità sull'architettura e su come la correggeremo
Da un punto di vista architettonico, il codice che abbiamo qui è piuttosto scadente, è disordinato, non è DRY, non è SOLIDO, anzi, potresti anche chiamarlo ripugnante. Questi cosiddetti "Route Handler" stanno facendo molto di più della semplice "gestione di rotte": si interfacciano direttamente con il nostro database. Ciò significa che non c'è assolutamente alcuna astrazione.
Ammettiamolo, la maggior parte delle applicazioni non sarà mai così piccola o probabilmente potresti farla franca con le architetture serverless con il database Firebase. Forse, come vedremo più avanti, gli utenti vogliono la possibilità di caricare avatar, citazioni e frammenti dai loro libri, ecc. Forse vogliamo aggiungere una funzione di chat dal vivo tra utenti con WebSocket, e andiamo addirittura a dire che Apriremo la nostra applicazione per consentire agli utenti di prendere in prestito libri tra loro con un piccolo addebito, a quel punto dobbiamo considerare l'integrazione dei pagamenti con l'API Stripe e la logistica di spedizione con l'API Shippo.
Supponiamo di procedere con la nostra attuale architettura e di aggiungere tutte queste funzionalità. Questi gestori di percorso, noti anche come Controller Actions, finiranno per essere molto, molto grandi con un'elevata complessità ciclomatica . Un tale stile di codifica potrebbe andar bene per noi all'inizio, ma cosa succede se decidiamo che i nostri dati sono referenziali e quindi PostgreSQL è una scelta di database migliore di MongoDB? Ora dobbiamo eseguire il refactoring della nostra intera applicazione, eliminando Mongoose, alterando i nostri controller, ecc., Tutto questo potrebbe portare a potenziali bug nel resto della logica aziendale. Un altro esempio potrebbe essere quello di decidere che AWS S3 è troppo costoso e desideriamo migrare a GCP. Ancora una volta, ciò richiede un refactoring a livello di applicazione.
Sebbene ci siano molte opinioni sull'architettura, da Domain-Driven Design, Command Query Responsibility Segregation e Event Sourcing, a Test-Driven Development, SOILD, Layered Architecture, Onion Architecture e altro, ci concentreremo sull'implementazione di una semplice Layered Architecture in articoli futuri, costituiti da controller, servizi e repository e che utilizzano modelli di progettazione come composizione, adattatori/involucri e inversione del controllo tramite iniezione di dipendenza. Sebbene, in una certa misura, ciò possa essere in qualche modo eseguito con JavaScript, esamineremo anche le opzioni di TypeScript per ottenere questa architettura, consentendoci di utilizzare paradigmi di programmazione funzionale come Both Monads oltre a concetti OOP come Generics.
Per ora, ci sono due piccole modifiche che possiamo apportare. Poiché la nostra logica di gestione degli errori è abbastanza simile nel blocco catch di tutti gli endpoint, possiamo estrarla in una funzione personalizzata Express Error Handling Middleware all'estremità dello stack.
Ripulire la nostra architettura
Al momento, stiamo ripetendo una quantità molto grande di logica di gestione degli errori su tutti i nostri endpoint. Invece, possiamo creare una funzione Express Middleware per la gestione degli errori, che è una funzione Express Middleware che viene chiamata con un errore, gli oggetti req e res e la funzione successiva.
Per ora, costruiamo quella funzione middleware. Tutto quello che farò è ripetere la stessa logica di gestione degli errori a cui siamo abituati:
app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); Questo non sembra funzionare con Mongoose Errors, ma in generale, invece di usare if/else if/else per determinare le istanze di errore, puoi cambiare il costruttore dell'errore. Lascio quello che abbiamo, comunque.
In un gestore di endpoint/route sincrono , se si genera un errore, Express lo catturerà e lo elaborerà senza che sia necessario alcun lavoro aggiuntivo da parte tua. Purtroppo per noi non è così. Abbiamo a che fare con codice asincrono . Per delegare la gestione degli errori a Express con gestori di route asincroni, prendiamo l'errore noi stessi e lo passiamo a next() .
Quindi, permetterò che il next sia il terzo argomento nell'endpoint e rimuoverò la logica di gestione degli errori nei blocchi catch a favore del semplice passaggio dell'istanza di errore a next , in quanto tale:
app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { next(e) } });Se lo fai a tutti i gestori di percorso, dovresti ritrovarti con il seguente codice:
const express = require('express'); const mongoose = require('mongoose'); // Database connection and model. require('./db/mongoose.js')(); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { next(e) } }); // HTTP GET /books/:id app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { next(e); } }); // HTTP PATCH /books/:id app.patch('/books/:id', async (req, res, next) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { next(e); } }); // HTTP DELETE /books/:id app.delete('/books/:id', async (req, res, next) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { next(e); } }); // Notice - bottom of stack. app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Andando oltre, varrebbe la pena separare il nostro middleware di gestione degli errori in un altro file, ma è banale e lo vedremo nei futuri articoli di questa serie. Inoltre, potremmo usare un modulo NPM chiamato express-async-errors per permetterci di non dover chiamare il prossimo nel blocco catch, ma ancora una volta, sto cercando di mostrarti come vengono fatte ufficialmente le cose.
Una parola su CORS e la stessa politica di origine
Supponiamo che il tuo sito web sia servito dal dominio myWebsite.com ma il tuo server sia su myOtherDomain.com/api . CORS sta per Cross-Origin Resource Sharing ed è un meccanismo mediante il quale è possibile eseguire richieste tra domini. Nel caso precedente, poiché il server e il codice JS front-end si trovano in domini diversi, faresti una richiesta su due origini diverse, che è comunemente limitata dal browser per motivi di sicurezza e mitigata fornendo intestazioni HTTP specifiche.
La stessa politica di origine è ciò che esegue le suddette restrizioni: un browser Web consentirà solo che sia necessario effettuare la stessa origine.
Toccheremo CORS e SOP in seguito quando creeremo un front-end in bundle Webpack per la nostra API Book con React.
Conclusione e cosa c'è dopo
Abbiamo discusso molto in questo articolo. Forse non era del tutto pratico, ma si spera che ti abbia messo più a tuo agio nel lavorare con le funzionalità JavaScript Express ed ES6. Se sei nuovo alla programmazione e Node è il primo percorso che stai intraprendendo, si spera che i riferimenti a linguaggi di tipi statici come Java, C++ e C# abbiano aiutato a evidenziare alcune delle differenze tra JavaScript e le sue controparti statiche.
Next time, we'll finish building out our Book API by making some fixes to our current setup with regards to the Book Routes, as well as adding in User Authentication so that users can own books. We'll do all of this with a similar architecture to what I described here and with MongoDB for data persistence. Finally, we'll permit users to upload avatar images to AWS S3 via Buffers.
In the article thereafter, we'll be rebuilding our application from the ground up in TypeScript, still with Express. We'll also move to PostgreSQL with Knex instead of MongoDB with Mongoose as to depict better architectural practices. Finally, we'll update our avatar image uploading process to use Node Streams (we'll discuss Writable, Readable, Duplex, and Transform Streams). Along the way, we'll cover a great amount of design and architectural patterns and functional paradigms, including:
- Controllers/Controller Actions
- Servizi
- Repositories
- Data Mapping
- The Adapter Pattern
- The Factory Pattern
- The Delegation Pattern
- OOP Principles and Composition vs Inheritance
- Inversion of Control via Dependency Injection
- SOLID Principles
- Coding against interfaces
- Data Transfer Objects
- Domain Models and Domain Entities
- Either Monads
- Convalida
- Decorators
- Logging and Logging Levels
- Unit Tests, Integration Tests (E2E), and Mutation Tests
- The Structured Query Language
- Relations
- HTTP/Express Security Best Practices
- Node Best Practices
- OWASP Security Best Practices
- E altro ancora.
Using that new architecture, in the article after that, we'll write Unit, Integration, and Mutation tests, aiming for close to 100 percent testing coverage, and we'll finally discuss setting up a remote CI/CD pipeline with CircleCI, as well as Message Busses, Job/Task Scheduling, and load balancing/reverse proxying.
Hopefully, this article has been helpful, and if you have any queries or concerns, let me know in the comments below.