
Analisi esplorativa dei dati in Python: cosa devi sapere?
Pubblicato: 2021-03-12L'analisi esplorativa dei dati (EDA) è una pratica molto comune e importante seguita da tutti i data scientist. È il processo di guardare tabelle e tabelle di dati da diverse angolazioni per comprenderlo completamente. Ottenere una buona comprensione dei dati ci aiuta a ripulirli e riassumerli, il che poi fa emergere le intuizioni e le tendenze che altrimenti non sarebbero chiare.
L'EDA non ha una serie di regole fondamentali da seguire come nell'"analisi dei dati", ad esempio. Le persone che sono nuove nel campo tendono sempre a confondere tra i due termini, che sono per lo più simili ma diversi nel loro scopo. A differenza dell'EDA, l'analisi dei dati è più incline all'implementazione di probabilità e metodi statistici per rivelare fatti e relazioni tra diverse varianti.
Tornando, non esiste un modo giusto o sbagliato di eseguire l'EDA. Varia da persona a persona, tuttavia, ci sono alcune linee guida importanti comunemente seguite che sono elencate di seguito.
- Gestione dei valori mancanti: i valori nulli possono essere visualizzati quando tutti i dati potrebbero non essere stati disponibili o registrati durante la raccolta.
- Rimozione dei dati duplicati: è importante prevenire qualsiasi overfitting o bias creato durante l'addestramento dell'algoritmo di apprendimento automatico utilizzando record di dati ripetuti
- Gestione dei valori anomali: i valori anomali sono record che differiscono drasticamente dal resto dei dati e non seguono la tendenza. Può verificarsi a causa di alcune eccezioni o imprecisioni durante la raccolta dei dati
- Ridimensionamento e normalizzazione: questa operazione viene eseguita solo per le variabili di dati numerici. Il più delle volte le variabili differiscono notevolmente nella loro gamma e scala, il che rende difficile confrontarle e trovare correlazioni.
- Analisi univariata e bivariata: l'analisi univariata viene solitamente eseguita osservando come una variabile sta influenzando la variabile target. L'analisi bivariata viene eseguita tra 2 variabili qualsiasi, può essere numerica o categoriale o entrambe.
Vedremo come alcuni di questi vengono implementati utilizzando un set di dati molto famoso "Rischio di insolvenza del credito domestico" disponibile su Kaggle qui . I dati contengono informazioni sul richiedente il prestito al momento della richiesta del prestito. Contiene due tipi di scenari:
- Il cliente con difficoltà di pagamento : ha avuto un ritardo nel pagamento superiore a X giorni
su almeno una delle prime rate Y del prestito del nostro campione,
- Tutti gli altri casi : Tutti gli altri casi in cui il pagamento viene pagato in tempo.
Lavoreremo solo sui file di dati dell'applicazione per il bene di questo articolo.
Correlati: Idee e argomenti del progetto Python per principianti
Sommario
Guardando i dati
app_data = pd.read_csv( 'application_data.csv' )
app_data.info()
Dopo aver letto i dati dell'applicazione, utilizziamo la funzione info() per ottenere una breve panoramica dei dati di cui ci occuperemo. L'output seguente ci informa che abbiamo circa 300000 record di prestito con 122 variabili. Di queste, ci sono 16 variabili categoriali e le restanti numeriche.
<classe 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 voci, da 0 a 307510
Colonne: 122 voci, da SK_ID_CURR a AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), oggetto(16)
utilizzo della memoria: 286,2+ MB
È sempre buona norma gestire e analizzare separatamente i dati numerici e categoriali.
categoriale = dati_app.select_dtypes(include = oggetto).colonne
app_data[categorical].apply(pd.Series.nunique, asse = 0)
Osservando solo le caratteristiche categoriali di seguito, vediamo che la maggior parte di esse ha solo alcune categorie che le rendono più facili da analizzare utilizzando semplici grafici.
NAME_CONTRACT_TYPE 2
CODICE_GENERE 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPAZIONE_TIPO 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZZAZIONE_TIPO 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtipo: int64
Ora per le caratteristiche numeriche, il metodo describe() ci fornisce le statistiche dei nostri dati:
numer= dati_app.descrivi()
numerico= numero.colonne
numero
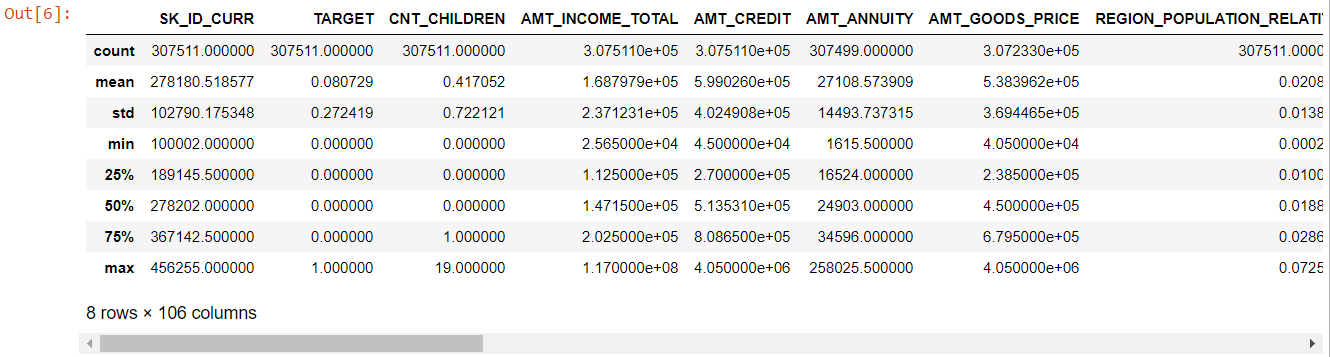
Guardando l'intera tabella è evidente che:
- days_birth è negativo: età del richiedente (in giorni) relativa al giorno della domanda
- giorni_impiegati ha valori anomali (il valore massimo è di circa 100 anni) (635243)
- amt_annuity- significa molto più piccolo del valore massimo
Quindi ora sappiamo quali caratteristiche dovranno essere ulteriormente analizzate.
Dati mancanti
Possiamo creare un grafico puntuale di tutte le caratteristiche che hanno valori mancanti tracciando la % di dati mancanti lungo l'asse Y.
missing = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
ax = sns.pointplot('index', 0, data = mancante)

plt.xticks(rotazione = 90, dimensione carattere = 7)
plt.title ("Percentuale di valori mancanti")
plt.ylabel("PERCENTUALE")
plt.show()
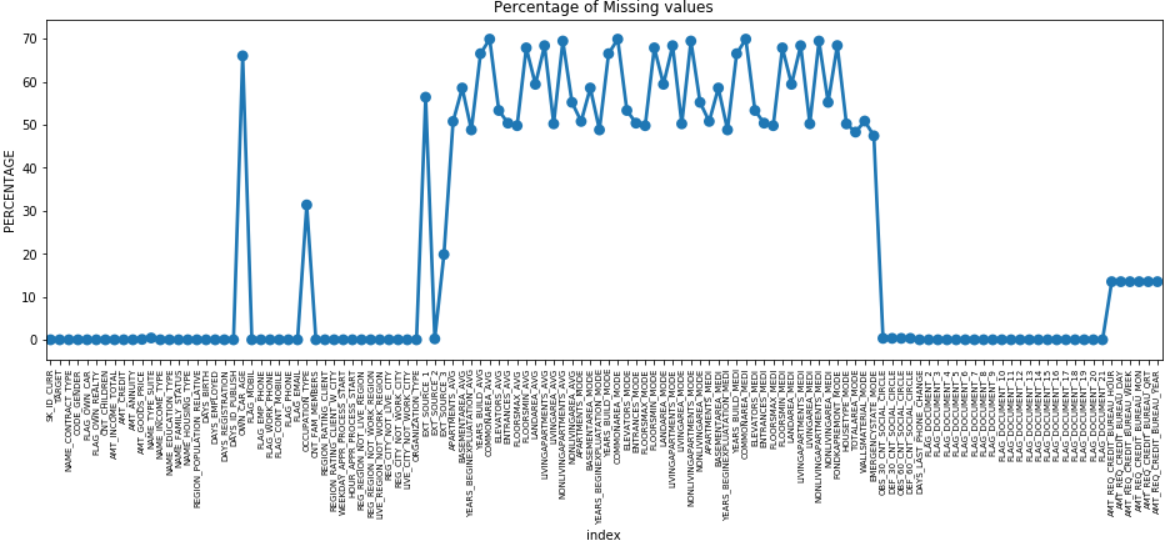
Molte colonne hanno molti dati mancanti (30-70%), alcune hanno pochi dati mancanti (13-19%) e molte colonne non hanno affatto dati mancanti. Non è davvero necessario modificare il set di dati quando devi solo eseguire l'EDA. Tuttavia, andando avanti con la pre-elaborazione dei dati, dovremmo sapere come gestire i valori mancanti.
Per le caratteristiche con meno valori mancanti, possiamo usare la regressione per prevedere i valori mancanti o riempire con la media dei valori presenti, a seconda della caratteristica. E per le funzionalità con un numero molto elevato di valori mancanti, è meglio eliminare quelle colonne poiché forniscono informazioni molto meno dettagliate sull'analisi.
Squilibrio dei dati
In questo set di dati, gli inadempienti sui prestiti vengono identificati utilizzando la variabile binaria 'TARGET'.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
Nome: TARGET, dtype: float64
Vediamo che i dati sono molto sbilanciati con un rapporto di 92:8. La maggior parte dei prestiti è stata rimborsata in tempo (obiettivo = 0). Quindi, ogni volta che c'è uno squilibrio così grande, è meglio prendere le caratteristiche e confrontarle con la variabile target (analisi mirata) per determinare quali categorie in quelle caratteristiche tendono a insolvere sui prestiti più di altre.
Di seguito sono riportati solo alcuni esempi di grafici che possono essere realizzati utilizzando la libreria Seaborn di Python e semplici funzioni definite dall'utente.
Genere
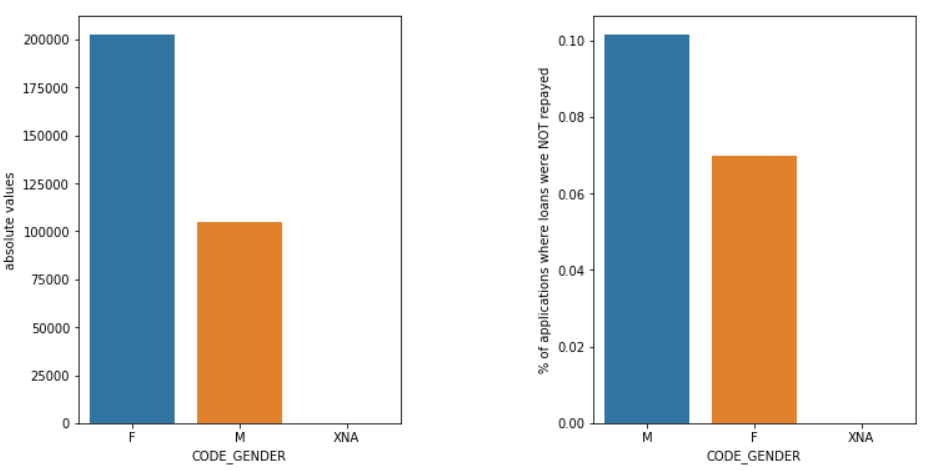
I maschi (M) hanno una probabilità maggiore di inadempienza rispetto alle femmine (F), anche se il numero di richiedenti femmine è quasi il doppio. Quindi le donne sono più affidabili degli uomini per il rimborso dei loro prestiti.
Tipo di istruzione
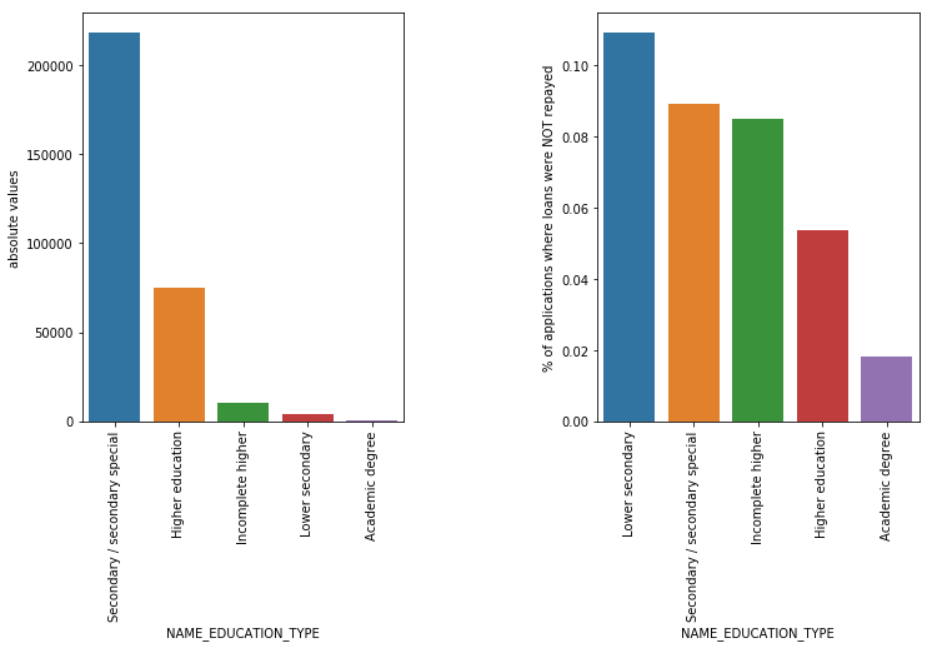
Anche se la maggior parte dei prestiti agli studenti sono destinati all'istruzione secondaria o superiore, sono i prestiti all'istruzione secondaria inferiore a essere più rischiosi per l'azienda, seguiti dalla scuola secondaria.
Leggi anche: Carriera nella scienza dei dati
Conclusione
Tale tipo di analisi vista sopra viene ampiamente eseguita nell'analisi del rischio nei servizi bancari e finanziari. In questo modo gli archivi di dati possono essere utilizzati per ridurre al minimo il rischio di perdere denaro durante i prestiti ai clienti. L'ambito dell'EDA in tutti gli altri settori è infinito e dovrebbe essere ampiamente utilizzato.
Se sei curioso di conoscere la scienza dei dati, dai un'occhiata all'Executive PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1- on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
L'analisi esplorativa dei dati è considerata il livello iniziale quando inizi a modellare i tuoi dati. Questa è una tecnica piuttosto perspicace per analizzare le migliori pratiche per la modellazione dei dati. Sarai in grado di estrarre grafici, grafici e report visivi dai dati per ottenerne una comprensione completa. I valori anomali sono riferiti ad anomalie o leggere variazioni nei tuoi dati. Può succedere durante la raccolta dei dati. Esistono 4 modi in cui possiamo rilevare un valore anomalo nel set di dati. Questi metodi sono i seguenti: A differenza dell'analisi dei dati, non ci sono regole e regolamenti rigidi da seguire per l'EDA. Non si può dire che questo sia il metodo giusto o quello sbagliato per eseguire l'EDA. I principianti sono spesso fraintesi e si confondono tra EDA e analisi dei dati.Perché è necessaria l'analisi dei dati esplorativi (EDA)?
L'EDA prevede alcuni passaggi per analizzare completamente i dati, tra cui la derivazione dei risultati statistici, la ricerca di valori di dati mancanti, la gestione delle voci di dati errate e infine la deduzione di vari grafici e grafici.
L'obiettivo principale di questa analisi è garantire che il set di dati in uso sia adatto per iniziare ad applicare algoritmi di modellazione. Questo è il motivo per cui questo è il primo passaggio da eseguire sui dati prima di passare alla fase di modellazione. Cosa sono i valori anomali e come gestirli?
1. Boxplot - Boxplot è un metodo per rilevare un valore anomalo in cui segreghiamo i dati attraverso i loro quartili.
2. Grafico a dispersione - Un grafico a dispersione mostra i dati di 2 variabili sotto forma di una raccolta di punti segnati sul piano cartesiano. Il valore di una variabile rappresenta l'asse orizzontale (x-ais) e il valore dell'altra variabile rappresenta l'asse verticale (asse y).
3. Punteggio Z - Durante il calcolo del punteggio Z, cerchiamo i punti che sono lontani dal centro e li consideriamo come valori anomali.
4. InterQuartile Range (IQR) - L'InterQuartile Range o IQR è la differenza tra i quartili superiore e inferiore o il 75° e il 25° quartile, spesso indicato come dispersione statistica. Quali sono le linee guida per eseguire l'EDA?
Tuttavia, ci sono alcune linee guida comunemente praticate:
1. Gestione dei valori mancanti
2. Rimozione dei dati duplicati
3. Gestione dei valori anomali
4. Ridimensionamento e normalizzazione
5. Analisi univariata e bivariata