
Che cos'è l'analisi dei dati esplorativi in Python? Impara da zero
Pubblicato: 2021-03-04L'analisi esplorativa dei dati o EDA, in breve, comprende quasi il 70% del progetto di scienza dei dati. L'EDA è il processo di esplorazione dei dati utilizzando vari strumenti di analisi per estrarre le statistiche inferenziali dai dati. Queste esplorazioni vengono eseguite visualizzando numeri semplici o tracciando grafici e diagrammi di diverso tipo.
Ogni grafico o grafico rappresenta una storia diversa e un'angolazione rispetto agli stessi dati. Per la maggior parte dell'analisi dei dati e della parte di pulizia, Pandas è lo strumento più utilizzato. Per le visualizzazioni e la stampa di grafici/grafici, vengono utilizzate librerie di stampa come Matplotlib, Seaborn e Plotly.
L'EDA è estremamente necessario per essere eseguito in quanto ti fa confessare i dati. Un Data Scientist che fa un ottimo EDA sa molto sui dati e quindi il modello che costruirà sarà automaticamente migliore del Data Scientist che non fa un buon EDA.
Alla fine di questo tutorial, saprai quanto segue:
- Controllo della panoramica di base dei dati
- Verifica delle statistiche descrittive dei dati
- Manipolazione di nomi di colonne e tipi di dati
- Gestione dei valori mancanti e delle righe duplicate
- Analisi bivariata
Sommario
Panoramica di base dei dati
Utilizzeremo il set di dati di Cars per questo tutorial che può essere scaricato da Kaggle. Il primo passaggio per quasi tutti i set di dati è importarlo e controllarne la panoramica di base: forma, colonne, tipi di colonna, prime 5 righe, ecc. Questo passaggio fornisce un rapido riepilogo dei dati con cui lavorerai. Vediamo come farlo in Python.
| # Importazione delle librerie richieste importa panda come pd importa numpy come np import seaborn come sns #visualisation importa matplotlib.pyplot come plt #visualisation %matplotlib in linea sns.set(color_codes= True ) |
Dati testa e coda
| data = pd.read_csv( “percorso/dataset.csv” ) # Controlla le prime 5 righe del dataframe data.head() |
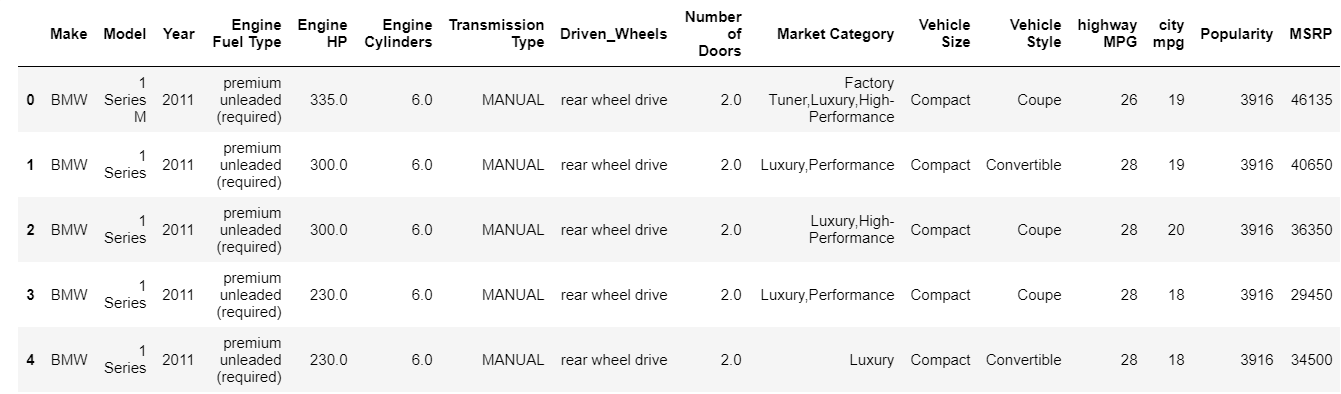
Per impostazione predefinita, la funzione head stampa i primi 5 indici del frame di dati. Puoi anche specificare quanti indici principali devi vedere bypassando quel valore in testa. La stampa della testina ci dà istantaneamente una rapida occhiata al tipo di dati che abbiamo, che tipo di funzionalità sono presenti e quali valori contengono. Ovviamente, questo non racconta l'intera storia dei dati, ma ti dà una rapida occhiata ai dati. Allo stesso modo puoi stampare la parte inferiore del frame di dati usando la funzione tail.
| # Stampa le ultime 10 righe del dataframe data.tail( 10 ) |
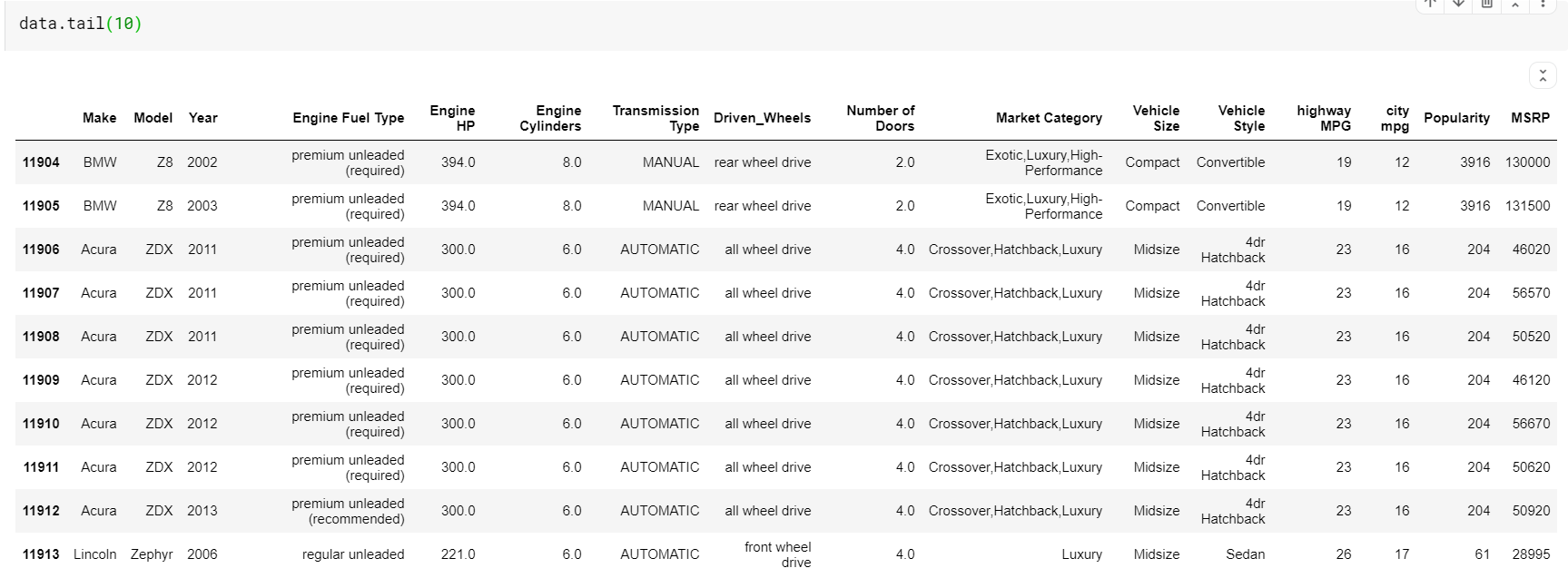
Una cosa da notare qui è che entrambe le funzioni-head e tail ci danno l'indice superiore o inferiore. Ma le righe superiore o inferiore non sono sempre una buona anteprima dei dati. Quindi puoi anche stampare un numero qualsiasi di righe campionate casualmente dal set di dati usando la funzione sample().
| # Stampa 5 righe casuali campione.dati( 5 ) |
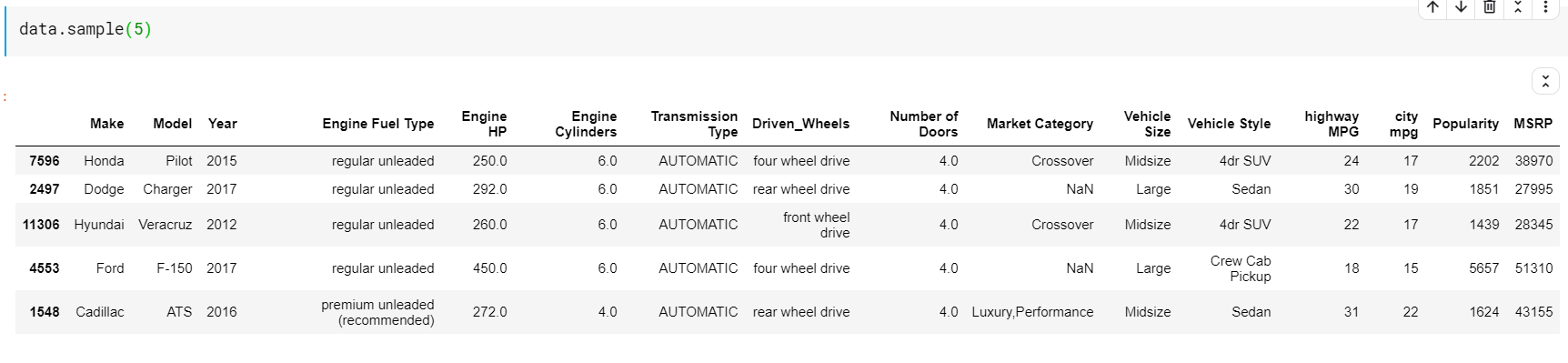
Statistiche descrittive
Successivamente, esaminiamo le statistiche descrittive del set di dati. Le statistiche descrittive consistono in tutto ciò che "descrive" il set di dati. Controlliamo la forma del frame di dati, quali sono tutte le colonne, quali sono tutte le caratteristiche numeriche e categoriali. Vedremo anche come fare tutto questo in funzioni semplici.
Forma
| # Verifica della forma del dataframe (mxn) # m=numero di righe # n=numero di colonne data.shape |

Come vediamo, questo frame di dati contiene 11914 righe e 16 colonne.
Colonne
| # Stampa i nomi delle colonne colonne.dati |
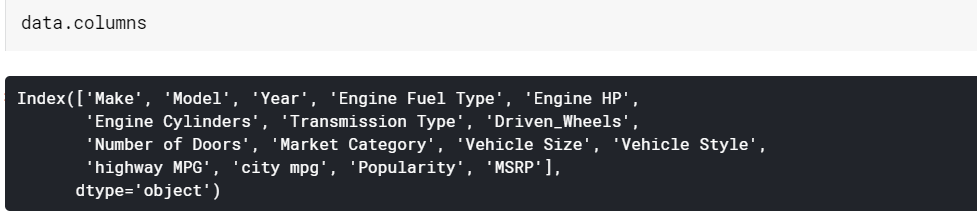
Informazioni sul frame di dati
| # Stampa i tipi di dati della colonna e il numero di valori non mancanti dati.info() |
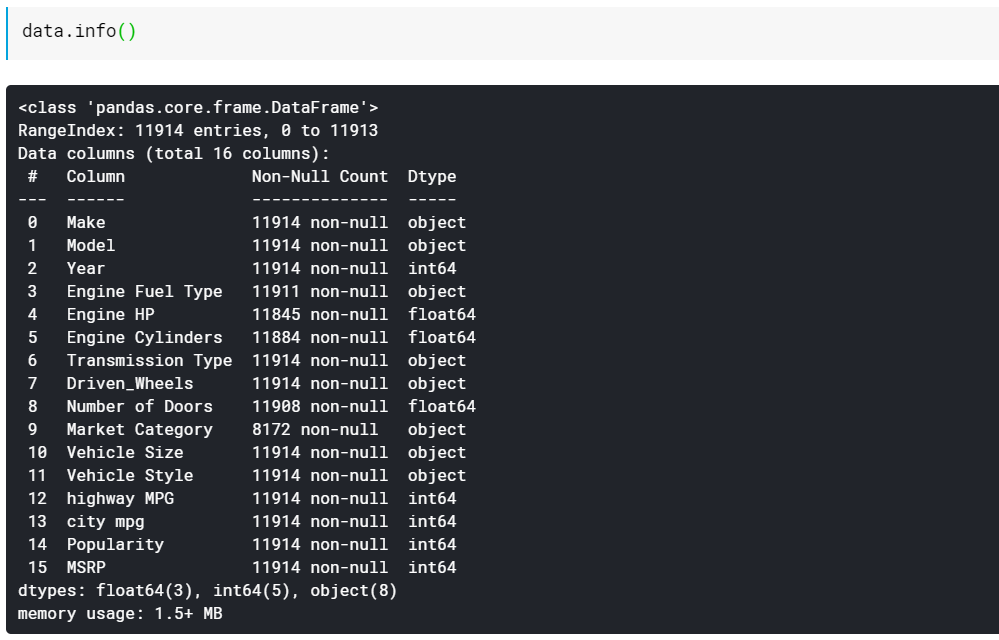
Come vedi, la funzione info() ci fornisce tutte le colonne, quanti valori non nulli o non mancanti ci sono in quelle colonne e infine il tipo di dati di quelle colonne. Questo è un modo rapido per vedere quali sono tutte le funzionalità numeriche e quali sono tutte categoriali/basate su testo. Inoltre, ora abbiamo informazioni sui valori mancanti di tutte le colonne. Vedremo come lavorare con i valori mancanti in seguito.
Manipolazione di nomi di colonne e tipi di dati
Controllare e manipolare accuratamente ogni colonna è estremamente cruciale in EDA. Abbiamo bisogno di vedere cosa contiene tutti i tipi di contenuto in una colonna/caratteristica e quali panda hanno letto il suo tipo di dati. I tipi di dati numerici sono principalmente int64 o float64. Alle funzioni basate su testo o categoriali viene assegnato il tipo di dati "oggetto".
Le funzionalità basate sulla data e l'ora vengono assegnate Ci sono momenti in cui Pandas non comprende il tipo di dati di una funzionalità. In questi casi, gli assegna pigramente il tipo di dati "oggetto". Possiamo specificare i tipi di dati della colonna in modo esplicito durante la lettura dei dati con read_csv.
Selezione di colonne categoriali e numeriche
| # Aggiungi tutte le colonne categoriali e numeriche a elenchi separati categorical = data.select_dtypes( 'object' ).columns numerico = data.select_dtypes( 'number' ).columns |

Qui il tipo che abbiamo passato come "numero" seleziona tutte le colonne con tipi di dati che hanno qualsiasi tipo di numero, sia esso int64 o float64.

Rinominare le colonne
| # Rinominare i nomi delle colonne data = data.rename(columns={ “Motore HP” : “HP” , “Cilindri motore” : “Cilindri” , “Tipo di trasmissione” : “Trasmissione” , “Ruote_guidate” : “Modalità di guida” , “autostrada MPG” : “MPG-H” , “Prezzo consigliato” : “Prezzo” }) data.head( 5 ) |

La funzione di ridenominazione accetta solo un dizionario con i nomi delle colonne da rinominare e i loro nuovi nomi.
Gestione dei valori mancanti e delle righe duplicate
I valori mancanti sono uno dei problemi/discrepanze più comuni in qualsiasi set di dati della vita reale. La gestione dei valori mancanti è di per sé un argomento vasto poiché esistono diversi modi per farlo. Alcuni modi sono metodi più generici e altri sono più specifici per il set di dati con cui si potrebbe avere a che fare.
Controllo dei valori mancanti
| # Verifica dei valori mancanti data.isnull().sum() |
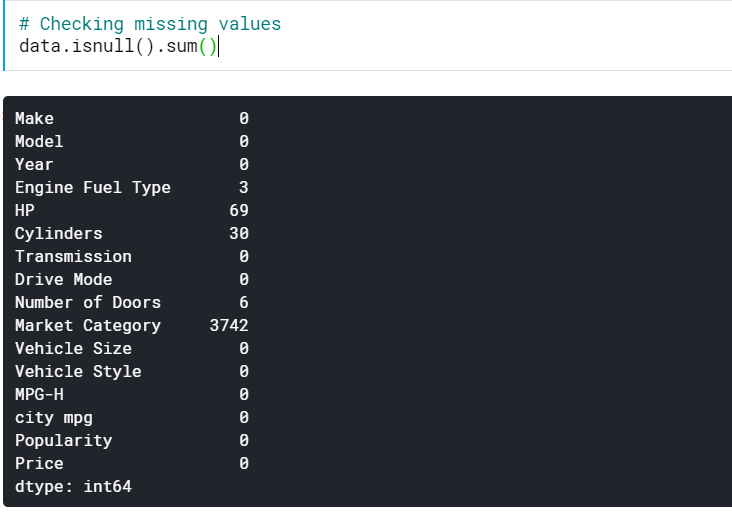
Questo ci dà il numero dei valori mancanti in tutte le colonne. Possiamo anche vedere la percentuale di valori mancanti.
| # Percentuale di valori mancanti data.isnull().mean()* 100 |
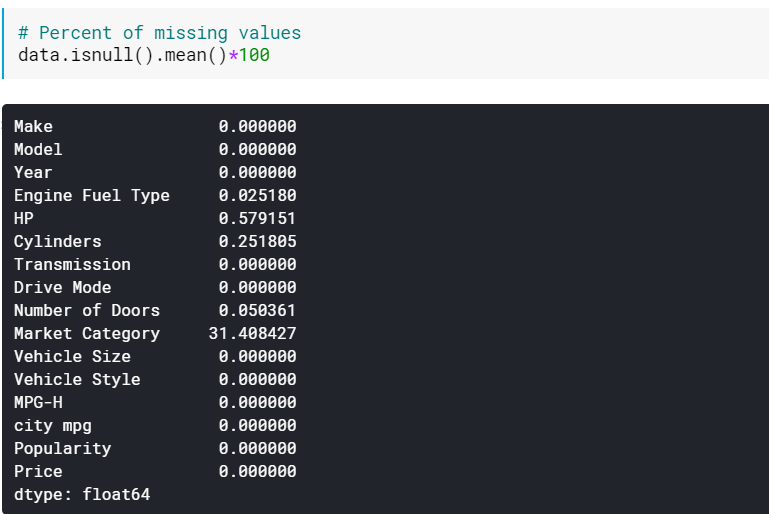
Il controllo delle percentuali potrebbe essere utile quando sono presenti molte colonne con valori mancanti. In questi casi, le colonne con molti valori mancanti (ad esempio, >60% mancante) possono essere semplicemente eliminate.
Immissione di valori mancanti
| #Imputazione dei valori mancanti delle colonne numeriche per mezzo data[numerica] = data[numerica].fillna(data[numerica].mean().iloc[ 0 ]) #Imputazione dei valori mancanti delle colonne categoriali per modalità data[categorial] = data[categorical].fillna(data[categorical].mode().iloc[ 0 ]) |
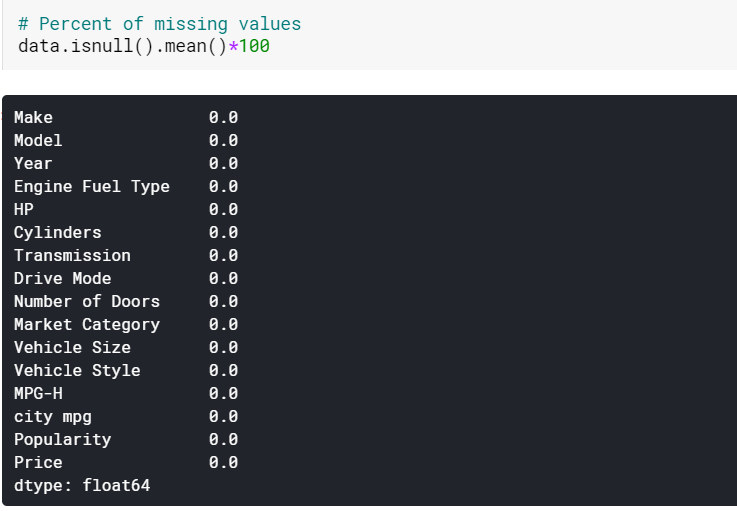
Qui attribuiamo semplicemente i valori mancanti nelle colonne numeriche con i rispettivi mezzi e quelli nelle colonne categoriali con le loro modalità. E come possiamo vedere, ora non ci sono valori mancanti.
Si noti che questo è il modo più primitivo di imputare i valori e non funziona nei casi della vita reale in cui vengono sviluppati modi più sofisticati, ad esempio interpolazione, KNN, ecc.
Gestione delle righe duplicate
| # Elimina le righe duplicate data.drop_duplicates(inplace= True ) |
Questo elimina solo le righe duplicate.
Checkout: idee e argomenti del progetto Python
Analisi bivariata
Ora vediamo come ottenere più approfondimenti eseguendo l'analisi bivariata. Bivariato significa un'analisi che consiste di 2 variabili o caratteristiche. Sono disponibili diversi tipi di grafici per diversi tipi di funzionalità.
Per Numerico – Numerico
- Trama a dispersione
- Trama lineare
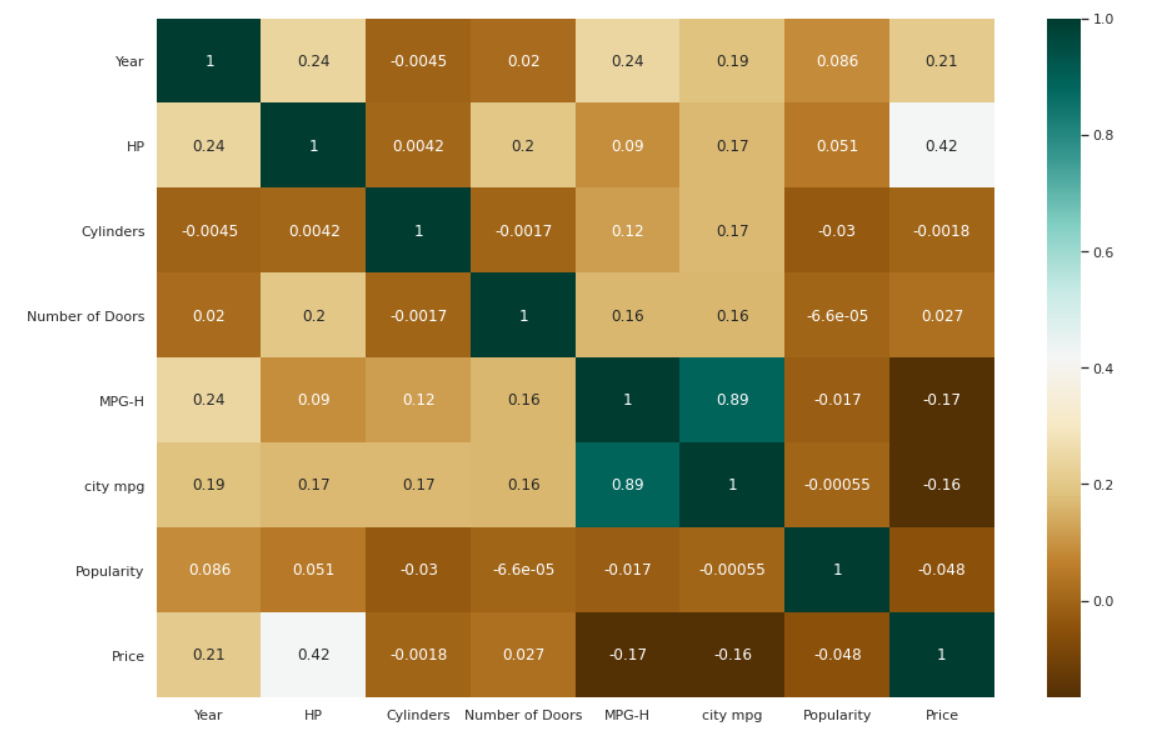
- Heatmap per le correlazioni
Per categoriale-numerico
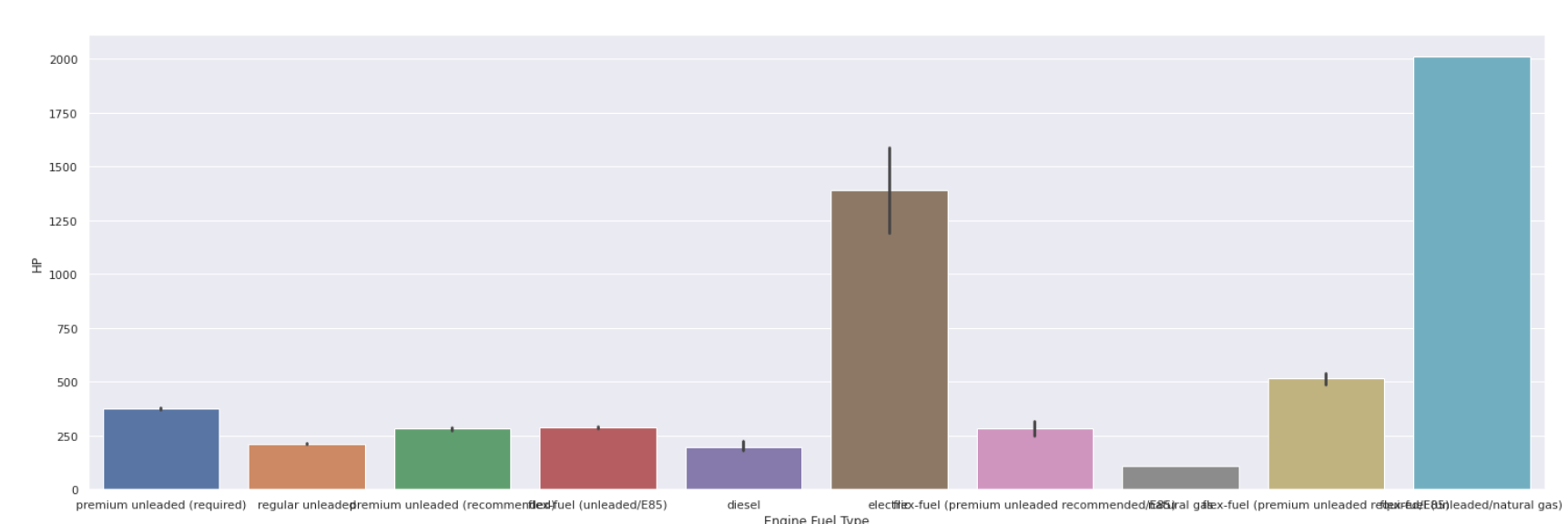
- Grafico a barre
- Trama di violino
- Trama dello sciame
Per Categorico-Categorico
- Grafico a barre
- Trama a punti
Heatmap per le correlazioni
| # Verifica delle correlazioni tra le variabili. plt.figure(figsize=( 15 , 10 )) c=dati.corr() sns.heatmap(c,cmap= “BrBG” ,annot= True ) |
Trama del bar
| sns.barplot(data[ 'Tipo carburante motore' ], data[ 'HP' ]) |
Ottieni la certificazione di data science dalle migliori università del mondo. Impara i programmi Executive PG, Advanced Certificate Program o Master per accelerare la tua carriera.
Conclusione
Come abbiamo visto, ci sono molti passaggi da coprire durante l'esplorazione di un set di dati. Abbiamo trattato solo una manciata di aspetti in questo tutorial, ma questo ti darà più della semplice conoscenza di base di un buon EDA.
Se sei curioso di conoscere Python, tutto ciò che riguarda la scienza dei dati, dai un'occhiata al Diploma PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con l'industria esperti, 1 contro 1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Quali sono le fasi dell'analisi esplorativa dei dati?
I passaggi principali che è necessario eseguire per eseguire l'analisi esplorativa dei dati sono:
È necessario identificare variabili e tipi di dati.
Analisi delle metriche fondamentali
Analisi non grafica univariata
Analisi grafica univariata
Analisi di dati bivariati
Trasformazioni variabili
Trattamento per il valore mancante
Trattamento dei valori anomali
Analisi di correlazione
Riduzione della dimensionalità
Qual è lo scopo dell'analisi esplorativa dei dati?
L'obiettivo principale dell'EDA è assistere nell'analisi dei dati prima di formulare ipotesi. Può aiutare a rilevare errori evidenti, nonché a una migliore comprensione dei modelli di dati, al rilevamento di valori anomali o eventi insoliti e alla scoperta di relazioni interessanti tra le variabili.
L'analisi esplorativa può essere utilizzata dai data scientist per garantire che i risultati che creano siano accurati e adeguati a qualsiasi risultato e obiettivo aziendale mirato. L'EDA assiste anche le parti interessate assicurando che rispondano alle domande appropriate. Deviazioni standard, dati categoriali e intervalli di confidenza possono essere risolti con EDA. Dopo il completamento di EDA e l'estrazione di informazioni dettagliate, le sue funzionalità possono essere applicate ad analisi o modelli di dati più avanzati, incluso il machine learning.
Quali sono i diversi tipi di analisi dei dati esplorativi?
Esistono due tipi di tecniche EDA: grafiche e quantitative (non grafiche). L'approccio quantitativo, invece, richiede la compilazione di statistiche riassuntive, mentre i metodi grafici prevedono la raccolta dei dati in maniera schematica o visiva. Gli approcci univariati e multivariati sono sottoinsiemi di questi due tipi di metodologie.
Per studiare le relazioni, gli approcci univariati esaminano una variabile (colonna dati) alla volta, mentre i metodi multivariati esaminano due o più variabili contemporaneamente. Grafica univariata e multivariata e non grafica sono le quattro forme di EDA. Le procedure quantitative sono più oggettive, mentre i metodi pittorici sono più soggettivi.