
La guida allo scraping etico di siti Web dinamici con Node.js e Puppeteer
Pubblicato: 2022-03-10Iniziamo con una piccola sezione su cosa significa effettivamente web scraping. Tutti noi utilizziamo il web scraping nella nostra vita di tutti i giorni. Descrive semplicemente il processo di estrazione delle informazioni da un sito web. Quindi, se copi e incolli una ricetta del tuo piatto di noodle preferito da Internet sul tuo taccuino personale, stai eseguendo il web scraping .
Quando si utilizza questo termine nell'industria del software, di solito ci si riferisce all'automazione di questa attività manuale utilizzando un pezzo di software. Attenendosi al nostro precedente esempio di "piatto di noodle", questo processo di solito prevede due passaggi:
- Recupero della pagina
Per prima cosa dobbiamo scaricare la pagina nel suo insieme. Questo passaggio è come aprire la pagina nel browser Web durante lo scraping manuale. - Analisi dei dati
Ora dobbiamo estrarre la ricetta nell'HTML del sito Web e convertirla in un formato leggibile dalla macchina come JSON o XML.
In passato ho lavorato per molte aziende come consulente dati. Sono rimasto sbalordito nel vedere quante attività di estrazione, aggregazione e arricchimento dei dati vengono ancora eseguite manualmente, sebbene possano essere facilmente automatizzate con poche righe di codice. Questo è esattamente ciò che il web scraping è per me: estrarre e normalizzare preziose informazioni da un sito Web per alimentare un altro processo aziendale che genera valore.
Durante questo periodo, ho visto le aziende utilizzare il web scraping per tutti i tipi di casi d'uso. Le società di investimento si sono concentrate principalmente sulla raccolta di dati alternativi, come recensioni di prodotti , informazioni sui prezzi o post sui social media per sostenere i loro investimenti finanziari.
Ecco un esempio. Un cliente mi ha contattato per raccogliere i dati delle recensioni dei prodotti per un elenco completo di prodotti da diversi siti Web di e-commerce, tra cui la valutazione, la posizione del revisore e il testo della recensione per ciascuna recensione inviata. I dati sui risultati hanno consentito al cliente di identificare le tendenze relative alla popolarità del prodotto in diversi mercati. Questo è un ottimo esempio di come una singola informazione apparentemente “inutile” possa diventare preziosa se confrontata con una quantità maggiore.
Altre aziende accelerano il loro processo di vendita utilizzando il web scraping per la generazione di lead . Questo processo di solito comporta l'estrazione di informazioni di contatto come il numero di telefono, l'indirizzo e-mail e il nome del contatto per un determinato elenco di siti Web. L'automazione di questa attività offre ai team di vendita più tempo per avvicinarsi ai potenziali clienti. Di conseguenza, l'efficienza del processo di vendita aumenta.
Attenersi alle regole
In generale, il web scraping dei dati pubblicamente disponibili è legale, come confermato dalla giurisdizione del caso Linkedin vs. HiQ. Tuttavia, mi sono prefissato un insieme etico di regole a cui mi piace attenermi quando inizio un nuovo progetto di web scraping. Ciò comprende:
- Controllo del file robots.txt.
Di solito contiene informazioni chiare su quali parti del sito il proprietario della pagina può accedere a robot e scraper ed evidenzia le sezioni a cui non dovrebbe essere consentito l'accesso. - Leggere i termini e le condizioni.
Rispetto al robots.txt, questa informazione non è disponibile meno spesso, ma di solito indica come trattano i data scraper. - Raschiare a velocità moderata.
Lo scraping crea un carico del server sull'infrastruttura del sito di destinazione. A seconda di ciò che si esegue lo scraping e del livello di simultaneità in cui opera lo scraper, il traffico può causare problemi all'infrastruttura del server del sito di destinazione. Naturalmente, la capacità del server gioca un ruolo importante in questa equazione. Quindi, la velocità del mio raschietto è sempre un equilibrio tra la quantità di dati che miro a raschiare e la popolarità del sito di destinazione. È possibile trovare questo equilibrio rispondendo a una singola domanda: "La velocità pianificata cambierà in modo significativo il traffico organico del sito?". Nei casi in cui non sono sicuro della quantità di traffico naturale di un sito, utilizzo strumenti come ahrefs per farmi un'idea approssimativa.
Scegliere la tecnologia giusta
In effetti, lo scraping con un browser headless è una delle tecnologie meno performanti che puoi utilizzare, poiché ha un forte impatto sulla tua infrastruttura. Un core del processore della tua macchina può gestire approssimativamente un'istanza di Chrome.
Facciamo un rapido calcolo di esempio per vedere cosa significa per un progetto di scraping web nel mondo reale.
Scenario
- Vuoi raschiare 20.000 URL.
- Il tempo medio di risposta dal sito di destinazione è di 6 secondi.
- Il tuo server ha 2 core di CPU.
Il completamento del progetto richiederà 16 ore .
Pertanto, cerco sempre di evitare di utilizzare un browser quando conduco un test di fattibilità di scraping per un sito Web dinamico.
Ecco una piccola lista di controllo che sfoglio sempre:
- Posso forzare lo stato della pagina richiesto tramite i parametri GET nell'URL? Se sì, possiamo semplicemente eseguire una richiesta HTTP con i parametri aggiunti.
- Le informazioni dinamiche fanno parte dell'origine della pagina e sono disponibili tramite un oggetto JavaScript da qualche parte nel DOM? In caso affermativo, possiamo nuovamente utilizzare una normale richiesta HTTP e analizzare i dati dall'oggetto stringato.
- I dati vengono recuperati tramite una richiesta XHR? In tal caso, posso accedere direttamente all'endpoint con un client HTTP? Se sì, possiamo inviare una richiesta HTTP direttamente all'endpoint. Molte volte, la risposta è persino formattata in JSON, il che rende la nostra vita molto più semplice.
Se a tutte le domande viene risposto con un preciso "No", abbiamo ufficialmente esaurito le opzioni fattibili per l'utilizzo di un client HTTP. Naturalmente, potrebbero esserci più modifiche specifiche del sito che potremmo provare, ma di solito il tempo necessario per capirle è troppo alto, rispetto alle prestazioni più lente di un browser senza testa. Il bello dello scraping con un browser è che puoi raschiare tutto ciò che è soggetto alla seguente regola di base:
Se puoi accedervi con un browser, puoi raschiare.
Prendiamo il seguente sito come esempio per il nostro scraper: https://quotes.toscrape.com/search.aspx. Presenta citazioni da un elenco di determinati autori per un elenco di argomenti. Tutti i dati vengono recuperati tramite XHR.
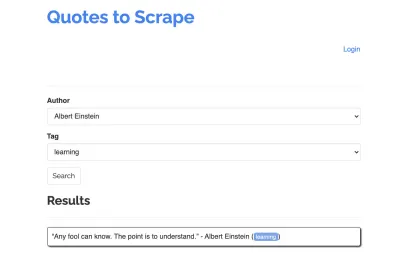
Chiunque abbia esaminato da vicino il funzionamento del sito e abbia esaminato la lista di controllo sopra, probabilmente si è reso conto che le citazioni potevano effettivamente essere eliminate utilizzando un client HTTP, poiché possono essere recuperate effettuando una richiesta POST direttamente sull'endpoint delle citazioni. Ma dal momento che questo tutorial dovrebbe coprire come raschiare un sito Web usando Puppeteer, faremo finta che fosse impossibile.
Installazione dei prerequisiti
Dato che creeremo tutto usando Node.js, creiamo e apriamo prima una nuova cartella e creiamo un nuovo progetto Node all'interno, eseguendo il seguente comando:
mkdir js-webscraper cd js-webscraper npm initAssicurati di aver già installato npm. Il programma di installazione ci farà alcune domande sulle meta-informazioni su questo progetto, che tutti possiamo saltare, premendo Invio .
Installazione Burattinaio
Abbiamo già parlato di scraping con un browser. Puppeteer è un'API Node.js che ci consente di parlare a un'istanza di Chrome senza testa in modo programmatico.
Installiamolo usando npm:
npm install puppeteerCostruire il nostro raschietto
Ora, iniziamo a costruire il nostro scraper creando un nuovo file, chiamato scraper.js .
Innanzitutto, importiamo la libreria precedentemente installata, Puppeteer:
const puppeteer = require('puppeteer');Come passaggio successivo, diciamo a Puppeteer di aprire una nuova istanza del browser all'interno di una funzione asincrona e auto-eseguibile:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Nota : per impostazione predefinita, la modalità senza testa è disattivata, poiché aumenta le prestazioni. Tuttavia, quando costruisco un nuovo raschietto, mi piace disattivare la modalità senza testa. Questo ci permette di seguire il processo che sta attraversando il browser e vedere tutti i contenuti renderizzati. Questo ci aiuterà a eseguire il debug del nostro script in seguito.
All'interno della nostra istanza del browser aperta, ora apriamo una nuova pagina e ci dirigiamo verso il nostro URL di destinazione:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Come parte della funzione asincrona, utilizzeremo l'istruzione await per attendere l'esecuzione del comando seguente prima di procedere con la riga di codice successiva.
Ora che abbiamo aperto con successo una finestra del browser e navigato alla pagina, dobbiamo creare lo stato del sito Web , in modo che le informazioni desiderate diventino visibili per lo scraping.
Gli argomenti disponibili vengono generati dinamicamente per un autore selezionato. Quindi, selezioneremo prima "Albert Einstein" e aspetteremo l'elenco di argomenti generato. Una volta che l'elenco è stato completamente generato, selezioniamo 'apprendimento' come argomento e lo selezioniamo come secondo parametro del modulo. Quindi facciamo clic su invia ed estraiamo le virgolette recuperate dal contenitore che contiene i risultati.

Poiché ora lo convertiremo in logica JavaScript, facciamo prima un elenco di tutti i selettori di elementi di cui abbiamo parlato nel paragrafo precedente:
| Campo di selezione dell'autore | #author |
| Campo di selezione tag | #tag |
| Pulsante Invia | input[type="submit"] |
| Contenitore preventivo | .quote |
Prima di iniziare a interagire con la pagina, ci assicureremo che tutti gli elementi a cui accederemo siano visibili, aggiungendo le seguenti righe al nostro script:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Successivamente, selezioneremo i valori per i nostri due campi di selezione:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Ora siamo pronti per condurre la nostra ricerca premendo il pulsante "Cerca" sulla pagina e attendere che appaiano le virgolette:
await page.click('.btn'); await page.waitForSelector('.quote'); Poiché ora accederemo alla struttura DOM HTML della pagina, chiamiamo la funzione page.evaluate() fornita, selezionando il contenitore che contiene le virgolette (in questo caso è solo uno). Quindi costruiamo un oggetto e definiamo null come valore di fallback per ogni parametro object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Possiamo rendere visibili tutti i risultati nella nostra console registrandoli:
console.log(quotes);Infine, chiudiamo il nostro browser e aggiungiamo una dichiarazione catch:
await browser.close();Il raschietto completo è simile al seguente:
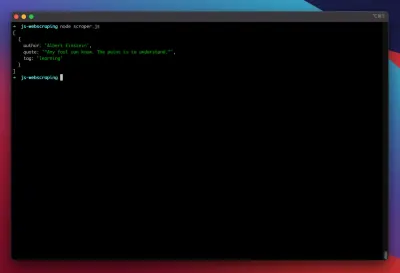
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Proviamo ad eseguire il nostro scraper con:
node scraper.jsE ci siamo! Il raschietto restituisce il nostro oggetto preventivo proprio come previsto:
Ottimizzazioni avanzate
Il nostro raschietto di base ora funziona. Aggiungiamo alcuni miglioramenti per prepararlo ad alcune attività di scraping più serie.
Impostazione di un agente utente
Per impostazione predefinita, Puppeteer utilizza uno user-agent che contiene la stringa HeadlessChrome . Molti siti Web cercano questo tipo di firma e bloccano le richieste in arrivo con una firma come quella. Per evitare che questo sia un potenziale motivo per il fallimento dello scraper, ho sempre impostato uno user-agent personalizzato aggiungendo la seguente riga al nostro codice:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Questo potrebbe essere ulteriormente migliorato scegliendo uno user-agent casuale con ogni richiesta da un array dei primi 5 user-agent più comuni. Un elenco degli agenti utente più comuni può essere trovato in un pezzo sugli agenti utente più comuni.
Implementazione di un proxy
Burattinaio rende molto semplice la connessione a un proxy, poiché l'indirizzo proxy può essere passato a Burattinaio all'avvio, in questo modo:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies fornisce un ampio elenco di proxy gratuiti che puoi utilizzare. In alternativa, è possibile utilizzare i servizi proxy a rotazione. Poiché i proxy sono generalmente condivisi tra molti clienti (o utenti gratuiti in questo caso), la connessione diventa molto più inaffidabile di quanto non lo sia già in circostanze normali. Questo è il momento perfetto per parlare di gestione degli errori e di gestione dei tentativi.
Gestione errori e tentativi
Molti fattori possono causare il guasto del tuo raschietto. Pertanto, è importante gestire gli errori e decidere cosa dovrebbe accadere in caso di errore. Poiché abbiamo collegato il nostro scraper a un proxy e ci aspettiamo che la connessione sia instabile (soprattutto perché stiamo usando proxy gratuiti), vogliamo riprovare quattro volte prima di rinunciare.
Inoltre, non ha senso riprovare una richiesta con lo stesso indirizzo IP se in precedenza non è riuscita. Quindi, costruiremo un piccolo sistema di rotazione proxy .
Innanzitutto creiamo due nuove variabili:
let retry = 0; let maxRetries = 5; Ogni volta che eseguiamo la nostra funzione scrape() , aumenteremo la nostra variabile retry di 1. Quindi avvolgiamo la nostra logica di scraping completa con un'istruzione try and catch in modo da poter gestire gli errori. La gestione dei tentativi avviene all'interno della nostra funzione catch :
L'istanza del browser precedente verrà chiusa e se la nostra variabile retry è più piccola della nostra variabile maxRetries , la funzione scrape viene chiamata ricorsivamente.
Il nostro raschietto ora apparirà così:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Ora aggiungiamo il rotatore proxy menzionato in precedenza.
Per prima cosa creiamo un array contenente un elenco di proxy:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Ora, scegli un valore casuale dall'array:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Ora possiamo eseguire il proxy generato dinamicamente insieme alla nostra istanza Burattinaio:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Ovviamente, questo rotatore proxy potrebbe essere ulteriormente ottimizzato per contrassegnare i proxy morti e così via, ma questo andrebbe sicuramente oltre lo scopo di questo tutorial.
Questo è il codice del nostro scraper (compresi tutti i miglioramenti):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Ecco! L'esecuzione del nostro raschietto all'interno del nostro terminale restituirà le virgolette.
Drammaturgo come alternativa al burattinaio
Burattinaio è stato sviluppato da Google. All'inizio del 2020, Microsoft ha rilasciato un'alternativa chiamata Playwright. Microsoft ha dato la caccia a molti ingegneri del Puppeteer-Team. Quindi, Playwright è stato sviluppato da molti ingegneri che hanno già messo le mani su Puppeteer. Oltre ad essere il nuovo arrivato del blog, il più grande punto di differenziazione di Playwright è il supporto cross-browser, poiché supporta Chromium, Firefox e WebKit (Safari).
I test sulle prestazioni (come questo condotto da Checkly) mostrano che Puppeteer generalmente offre prestazioni migliori di circa il 30% rispetto a Playwright, che corrisponde alla mia esperienza, almeno al momento della scrittura.
Altre differenze, come il fatto che puoi eseguire più dispositivi con un'istanza del browser, non sono molto utili per il contesto dello scraping web.
Risorse e collegamenti aggiuntivi
- Documentazione sui burattinai
- Imparare burattinaio e drammaturgo
- Web scraping con Javascript di Zenscrape
- User-Agent più comuni
- Burattinaio contro drammaturgo