
Sviluppare per il web semantico
Pubblicato: 2022-03-10A luglio la Wikimedia Foundation ha annunciato Abstract Wikipedia, un tentativo di marcare la conoscenza che è indipendente dal linguaggio. Per molti aspetti, questo è il culmine di decenni di costruzione, durante i quali il sogno di un Web semantico non è mai decollato del tutto, ma nemmeno del tutto scomparso.
In effetti, il Web semantico sta crescendo e, rinnovando la sua missione, tutti noi possiamo guadagnare dall'incorporare il markup semantico nei nostri siti Web, siano essi blog personali o giganti dei social media. Che ti interessino le esperienze web sofisticate, la SEO o la difesa dalla tirannia dei monopoli web, il Web semantico merita la nostra attenzione.
I vantaggi dello sviluppo per il Web semantico non sono sempre immediati o visibili, ma ogni sito che lo fa rafforza le basi di un Internet aperto, trasparente e decentralizzato.
Il web semantico
Che cos'è esattamente il Web semantico? È un Web leggibile dalla macchina, che fornisce attraverso i metadati "un framework comune che consente ai dati di essere condivisi e riutilizzati oltre i confini di applicazioni, aziende e comunità".
L'idea è vecchia quanto il World Wide Web stesso. Più vecchio, infatti. Era un punto focale della proposta di Tim Berners-Lee del 1989. Come ha sottolineato, non solo i documenti dovrebbero formare reti, ma anche i dati al loro interno dovrebbero:
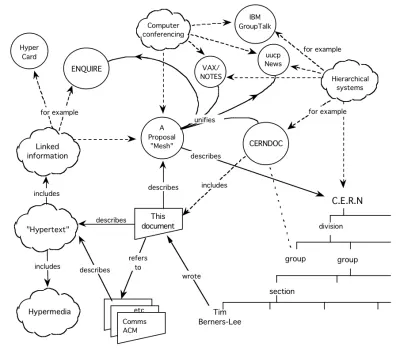
Il Web semantico ha percorso una strada rocciosa nei decenni successivi. Dall'inizio del millennio, si è trasformato in più concetti - dati aperti, grafici della conoscenza - tutti in effetti significano tutti la stessa cosa: reti di dati.
Come riassume il W3C, è "un'estensione dell'attuale web in cui alle informazioni viene dato un significato ben definito, consentendo ai computer e alle persone di lavorare in modo migliore in cooperazione".

L'idea ha avuto la sua giusta quota di sostenitori. L'hacker di Internet Aaron Swartz ha scritto un libro manoscritto sul Web semantico intitolato A Programmable Web . In esso ha scritto:
“I documenti non possono essere realmente uniti, integrati e interrogati; servono principalmente come istanze isolate da visualizzare e rivedere. Ma i dati sono proteiformi, in grado di assumere la forma che meglio si adatta alle tue esigenze".
Per una serie di ragioni, il Web semantico non è decollato allo stesso modo del Web, sebbene stia recuperando terreno. Diversi markup hanno cercato di prendere il sopravvento nel corso degli anni - RDFa, OWL e Schema per citarne alcuni - sebbene nessuno sia diventato standard nel modo, ad esempio, di HTML o CSS. La barriera all'ingresso era troppo alta.
Tuttavia, il sogno del Web semantico è durato, e man mano che sempre più siti lo incorporano nei loro progetti, c'è sempre più motivo per unirsi alla festa. Più siti salgono a bordo, più forte diventa il Web semantico.
Ulteriori letture
- Intelligenza dati
- The Semantic Web , un articolo del 2001 di Tim Berners-Lee, James Hensley e Ora Lassila
- Gruppo di comunità Web credibile al W3C
Conoscenza senza frontiere
Prima di entrare nel merito di come progettare per il Web semantico, vale la pena approfondire un po' il perché . Che importa se i dati sono collegati? I documenti collegati non sono sufficienti?
Ci sono diversi motivi per cui il Web semantico continua a essere spinto da coloro che hanno a cuore un Internet libero e aperto. La comprensione di tali ragioni è essenziale per il processo di attuazione. Non dovrebbe essere un caso di "mangia le tue verdure, usa il markup semantico". Il Web semantico è qualcosa in cui credere e di cui far parte.
I vantaggi del Web semantico includono:
- Esperienze web più ricche e sofisticate
- Bypassare i silos di contenuti e i monopoli di Internet
- Migliore leggibilità e posizionamento sui motori di ricerca
- Democratizzazione dell'informazione
La maggior parte di questi può essere ricondotta a un principio fondamentale del Web semantico: un linguaggio universale per i dati. Sebbene Internet abbia già fatto miracoli per la comunicazione internazionale, non si può sfuggire al fatto che alcuni paesi lo hanno molto meglio di altri. Prendi, ad esempio, le lingue utilizzate sul Web rispetto alle lingue utilizzate nel mondo reale. Gli occhi d'aquila tra voi potrebbero essere in grado di individuare un leggero squilibrio nei dati sottostanti...
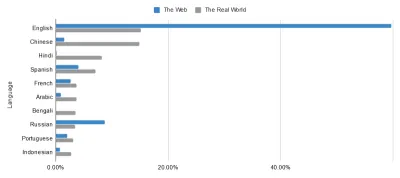
L'utopia senza confini del web non è così vicina come potrebbe sembrare a quelli di noi all'interno della bolla anglofona. È qualcosa per cui punire qualcuno? Non necessariamente, ma è qualcosa da affrontare. In questo modo si evidenzia l'importanza del markup che colma queste lacune. Arricchindo i dati del web, togliamo il peso dei suoi linguaggi.
Questo è il punto cruciale della Wikipedia astratta recentemente annunciata, che tenterà di separare gli articoli dalla lingua in cui sono scritti. Il direttore esecutivo di Wikimedia Katherine Maher scrive: “Usando il codice, i volontari saranno in grado di tradurre questi 'articoli' astratti in le proprie lingue. In caso di successo, ciò potrebbe consentire a tutti di leggere qualsiasi argomento in Wikidata nella propria lingua".
Abstract Il creatore di Wikipedia Denny Vrandecic è stato un sostenitore del Web semantico per anni, riconoscendo il suo potenziale per sbloccare il potenziale non sfruttato online. Abbattere le barriere nazionali è essenziale per questo processo.
"Non importa in quale lingua pubblichi i tuoi contenuti, ti perderai l'inclusione della stragrande maggioranza delle persone nel mondo. Il Web ci ha offerto questa meravigliosa opportunità di avere una portata globale, ma affidandoci a una singola lingua, oa un piccolo insieme di lingue, stiamo sprecando questa opportunità. Sebbene l'obiettivo più importante sia in primo luogo creare buoni contenuti, inviti più persone a partecipare allo sviluppo di contenuti migliori essendo indipendente dalla lingua. Ti aiuta ad abbassare le barriere al contributo e al consumo e consente a molte più persone di beneficiare di tale sforzo".
— Denny Vrandecic, creatore di Wikipedia astratta
Un esempio tempestivo di ciò è stata la visualizzazione dei dati durante la pandemia di COVID-19. Il virus ha provocato un caos indicibile in tutto il mondo, ma è stato anche un momento brillante per le reti di dati aperti, consentendo alle superbe app Web, reportistica e altro ancora di essere comuni in tutto il Web.
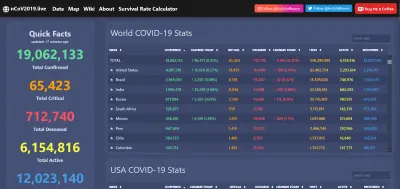
E, naturalmente, quando i dati sono trasparenti e facilmente accessibili, è più facile identificare le anomalie... o l'inganno. Un accesso pubblico diffuso al tipo di informazioni di cui sopra sarebbe impensabile anche 20 anni fa. Ora ce lo aspettiamo, e annusiamo un topo quando ce lo nega. I dati sono potenti e, se vogliamo, possono essere utilizzati per sempre.
Allo stesso modo, controllare noi stessi fuori dai silos di contenuti - un segno distintivo della moderna esperienza web - toglie potere ai monopoli web come Google, Facebook e Twitter. Siamo così abituati a piattaforme di terze parti che decifrano e presentano informazioni che dimentichiamo che non sono strettamente necessarie.
"Se avessimo formati condivisi, protocolli condivisi, potremmo comunque ritrovarci con alcuni provider a svolgere un ruolo importante in determinati mercati - pensa a Gmail per la posta elettronica - ma tutti sono liberi di passare a un altro provider e il mercato rimane competitivo".
— Denny Vrandecic, creatore di Wikipedia astratta
Il Web semantico è senza silo; è libero, aperto e astratto, consentendo la comunicazione tra linguaggi e piattaforme diverse che altrimenti sarebbe molto più difficile.
Contenuti online di data-fying
La progettazione per il Web semantico si riduce al data-fying di contenuti online: guardare i tuoi contenuti e vedere cosa può (e dovrebbe) essere astratto. Cosa significa questo in termini pratici, al di là del vago accordo che vale la pena fare? Dipende:
- Se inizi un progetto da zero, incorpora le considerazioni sul Web semantico in quello che fai. Quando un sito web prende forma, intreccia il markup semantico nel suo DNA.
- Se si aggiorna o si ricostruisce un progetto, valutare cosa potrebbe essere intessuto nel Web semantico che attualmente non lo è, quindi implementare.
Entrambi i casi equivalgono sostanzialmente a contenuti di data-fying. In questa sezione, esamineremo alcuni esempi di astrazione dei dati e come può rendere i contenuti migliori, più intelligenti e più ampiamente disponibili.
Astrazione delle informazioni
Progettare e sviluppare per il Semantic Web significa guardare i contenuti online con il cappello dei dati. La maggior parte di noi vive il Web come una serie di documenti o pagine di collegamento; quello che vuoi fare con il Web semantico è collegare le informazioni. Ciò significa valutare i tuoi contenuti per i punti dati, quindi adattare il design in base a ciò che trovi.
James Hendler, sostenitore del Web semantico, delinea questo processo particolarmente bene con la sua filosofia DIVE. ( Immergiti nei dati, eh? Eh?). Si articola come segue:
- Scoprire
Trova set di dati e/o contenuti (anche al di fuori della tua organizzazione). - Integrare
Collega le relazioni usando etichette significative. - Convalidare
Fornire input ai sistemi di modellazione e simulazione. - Esplorare
Sviluppare approcci per trasformare i dati in conoscenza fruibile.
Sviluppare per il Web semantico è in gran parte avere quella visione a volo d'uccello delle cose che fai e come alimenta potenzialmente esperienze web infinitamente più ricche. Come dice Hendler, l'obiettivo è la conoscenza praticabile.
Questo può davvero essere applicato a quasi tutti i tipi di contenuti web, ma iniziamo con un esempio comune: le ricette . Diciamo che gestisci un blog di cucina, con nuove ricette ogni giovedì. Se sei francese e pubblichi una fantastica ricetta di soufflé sul tuo blog personale in chiaro, è utile solo a coloro che sanno leggere il francese.
Tuttavia, implementando il markup semantico, il blog può essere trasformato in un set di dati di ricette leggibile dalla macchina. La sintassi esiste per astrarre i termini di cucina. Schema, ad esempio, che può funzionare insieme a Microdata, RDFa o JSON-LD, ha un markup che include:
- tempo di preparazione
- tempo di cucinare
- ricettaResa
- ricettaIngrediente
- costo stimato
- nutrizione, scomponendo in calorie e grassi
- adatto per la dieta.
potrei andare avanti. L'intera gamma di opzioni, con esempi, può essere letta su Schema.org. Aggiungendoli al formato del post, il formato della ricetta non deve cambiare affatto: stai semplicemente inserendo le informazioni in termini comprensibili dai computer.

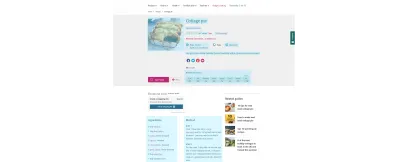
Ad esempio, a tutto ciò che è evidenziato in blu nella ricetta della BBC sopra è stato assegnato un markup semantico, dal tempo di cottura al contenuto nutrizionale. Puoi vedere cosa sta succedendo sotto il cofano inserendo l'URL della ricetta nel test dei risultati ricchi di Google. Nota la funzionalità "Aggiungi alla lista della spesa", un esempio di connessione resa possibile dall'implementazione del Web semantico. Un buon contenuto diventa dati utilizzabili.
La maggior parte di noi ha incrociato questo tipo di sofisticatezza tramite i risultati di ricerca, ma le applicazioni sono molto più ampie. Il markup semantico delle ricette semplifica la ricerca e l'utilizzo dei siti Web da parte degli assistenti domestici. Gli ingredienti elencati possono essere ordinati al supermercato locale. Le ricette possono essere filtrate in tutti i modi: per diete, allergie, religione, costi, e così via. Oppure supponiamo che tu abbia un numero limitato di ingredienti in casa. Con un database puoi inserire quegli ingredienti e vedere quali ricette si adattano al conto.
La gamma di possibilità rasenta davvero il limite. Come ha detto Swartz, i dati sono proteiformi. Una volta che lo hai, puoi usarlo in tutti i modi strani e meravigliosi. Questo pezzo non parla di quei modi strani e meravigliosi quanto di renderli possibili. La progettazione per il Web semantico rende la progettazione successiva infinitamente più ricca.
Ecco un esempio più personale per mostrare cosa intendo. Io e un paio di amici gestiamo una piccola webzine musicale per hobby. Sebbene pubblichiamo l'articolo o l'intervista dispari, l'"evento principale" sono le recensioni settimanali degli album, in cui ognuno di noi tre assegna un punteggio, sceglie i brani preferiti e scrivi i riepiloghi. Abbiamo lavorato per più di cinque anni, il che significa che abbiamo quasi 250 recensioni, il che significa un'enorme quantità di dati potenziali. Non ci siamo resi conto di quanto fino a quando non abbiamo iniziato a riprogettare il sito.
Ne ho parlato in un pezzo sulla cottura di dati strutturati nel processo di progettazione. Analizzando le nostre recensioni ci siamo resi conto che erano piene zeppe di informazioni a cui poteva essere assegnato un markup semantico. Artisti, nomi degli album, artwork, data di uscita, punteggi individuali, punteggi complessivi, tipo di pubblicazione e altro ancora. Inoltre, ed è qui che diventa davvero eccitante, ci siamo resi conto che potevamo connetterci a un database esistente: MusicBrainz.
Questo approccio bidirezionale è il punto cruciale del Web semantico. Quando il nostro sito Web di musica verrà rilanciato, sarà una propria fonte di dati aperta con migliaia di punti dati unici. La connessione a un database musicale esistente darà ai nostri dati più contesto e potenziale. Migliaia di punti dati diventano decine di migliaia di punti dati, forse di più.
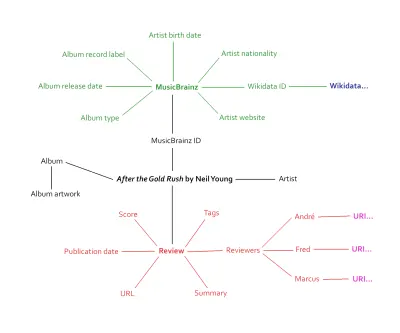
Il grafico sopra graffia solo la superficie di quante informazioni saranno collegate alle pagine delle recensioni. Il contenuto è lo stesso di prima, solo che ora è collegato a un ecosistema di metadati: il Giant Global Graph, come lo chiamava una volta Berners-Lee.
Sviluppare per il Web semantico significa identificare i propri dati, annotarli, quindi scoprire come si connettono ad altri dati. Perché lo fa. Lo fa sempre. E quel processo è come questo...
… col tempo diventa questo…
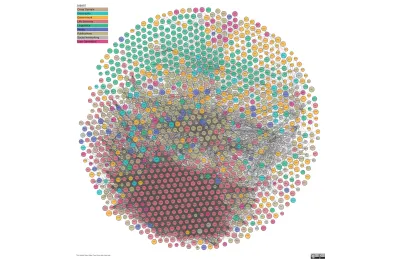
La seconda immagine è The Linked Open Data Cloud, una visualizzazione in continuo aggiornamento dei dati connessi del web. Quel rosso alveare di connessioni è la scienza; il resto ha molta strada da fare. È qui che entriamo in gioco.
Utili risorse del Web semantico
- RDF su w3schools.com
- Validatore RDF del W3C
- "Il Web semantico reso facile" di W3C
- "Che fine ha fatto il Web semantico?" da Storia a due bit
- Generatore JSON-LD
- Assistente per il markup dei dati strutturati di Google
Collegamento
L'ideale del Web semantico è la connessione. Crea dati, condividi dati, richiedi dati. Entra a far parte di un ecosistema informativo. Quando crei dati originali, fantastico. Condividilo. Quando i dati esistono già e desideri utilizzarli, inseriscili.
Ecco solo alcune delle risorse di dati disponibili:
- DPpedia
- Musica Brainz
- WorldCat
- ISBNdb
In effetti, dove esistono database come questi, direi che la cosa giusta da fare sarebbe aggiornarli dove mancano informazioni. Perché tenerlo per te? Diventa un collaboratore, un sostenitore del Web semantico.
Implementazione
Per quanto riguarda la creazione di Semantic Webness nei tuoi siti, non sto certamente sostenendo il markup manuale, doc-by-doc. Chi ha tempo per quello? Il più delle volte la soluzione è standardizzare un formato e creare modelli per esso.
La creazione di modelli è la grande opportunità qui. Quante persone hanno davvero il tempo di contrassegnare manualmente tutte queste informazioni? Tuttavia, se hai input personalizzati, ottieni il meglio da entrambi i mondi. Il contenuto può essere riempito con informazioni a misura di persona e le informazioni esistono come dati pronti a servire a qualsiasi scopo venga in mente.
Prendi, ad esempio, un generatore di siti statici come Eleventy, che ultimamente si sta godendo un po' di amore da parte della comunità di sviluppatori. Scrivi un post, lo esegui attraverso un modello e sei d'oro. Allora perché non incorporare il markup semantico nel modello stesso?
Come Eleventy, la nuova versione del nostro sito webzine musicale utilizza Markdown per i suoi post. Anche se abbiamo gli stessi vecchi post di testo che abbiamo sempre fatto, ogni recensione ora include anche i seguenti input di metadati, che vengono poi inseriti nel modello:
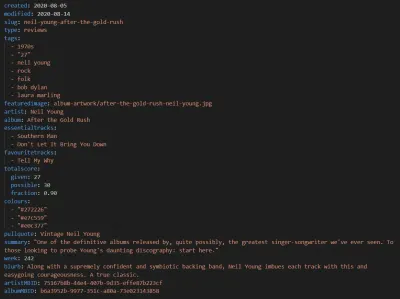
Insieme ai dettagli dell'autore nel corpo del post e ad alcune informazioni generiche sul sito Web, questo si traduce nel seguente markup semantico:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>Laddove prima c'era solo testo, su ogni singola pagina di recensione ora ci saranno anche versioni leggibili dalla macchina di ciò che i lettori vedono quando visitano il sito. Le parole sono ancora lì, il contenuto è appena cambiato: è stato appena modificato con i dati. Dai risultati di ricerca avanzati alle pagine interattive delle statistiche delle recensioni, questo aumenta enormemente ciò che è possibile. La strada da percorrere è ampia e aperta. Ci dà anche una partecipazione nel futuro di MusicBrainz. Collegando i loro dati ai nostri dati, a nostra volta vogliamo che funzionino bene e faremo la nostra parte per assicurarci che lo facciano.
Il markup semantico appropriato dipende dalla natura di un sito Web, ma è probabile che esista. Inizia con gli input ovvi (data, autore, tipo di contenuto, ecc.) e fatti strada tra le erbacce del contenuto. Il primo passo potrebbe essere semplice come una hCard (una specie di carta d'identità digitale) per il tuo sito web personale. Stampa schermate di pagine e inizia ad annotare. Rimarrai stupito dalla quantità di contenuti che può essere data-fyed.
Oltre l'immaginazione
La progettazione e lo sviluppo per il Web semantico è una pratica che risale agli ideali fondanti di Internet. Sia che tu apprezzi la visualizzazione dei dati bella e informativa, desideri risultati di ricerca più sofisticati, desideri rimuovere il potere dai monopoli del Web o semplicemente credere in informazioni libere e aperte, il Web semantico è il tuo alleato.
Aaron Swartz ha chiuso il suo manoscritto con un appello alla speranza:
"Il Web semantico si basa sulla scommessa, una scommessa che fornire al mondo strumenti per collaborare e comunicare facilmente porterà a possibilità così meravigliose che possiamo a malapena immaginarle in questo momento".
Abstract Wikipedia Denny Vrandecic fa eco a questi sentimenti oggi, dicendo:
"C'è bisogno di un'infrastruttura web che faciliti l'interoperabilità tra i servizi, che richiede un insieme comune di standard per rappresentare i dati e protocolli comuni tra i provider".
Il Web semantico è zoppicato abbastanza a lungo da essere chiaro che è improbabile che appaia un linguaggio proiettile d'argento, ma ora ce ne sono abbastanza che coesistono pacificamente perché il sogno fondatore di Berners-Lee diventi realtà per la maggior parte del web. Ognuno di noi può essere difensore nei propri quartieri.
Sii migliore, chiedi di meglio
Come ha affermato Tim Berners-Lee, il Web semantico è una cultura tanto quanto un ostacolo tecnico. In un TED Talk del 2009 lo ha riassunto bene: creare dati collegati, richiedere dati collegati . Questo è più vero ora che mai. Il World Wide Web è aperto, connesso e buono solo come lo costringiamo ad essere. Ogni volta che fai qualcosa online chiediti: "Come può questo collegarsi al Web semantico?" Le risposte aggiungeranno nuove dimensioni alle cose che creiamo e creeranno nuove possibilità inimmaginabilmente meravigliose per gli anni a venire.