
Devi leggere 24 domande e risposte sull'intervista di Datastage [Guida definitiva 2022]
Pubblicato: 2021-01-08Datastage è uno strumento ETL, ovvero estrazione, trasformazione e caricamento fornito da IBM nella sua suite InfoSphere e nella suite Information Solutions Platforms. È uno strumento ETL popolare e viene utilizzato per lavorare con set di dati e warehouse di grandi dimensioni per creare e gestire i repository di dati. In questo articolo, esamineremo le domande più frequenti dell'intervista a DataStage e forniremo anche le risposte a queste domande. Se sei un principiante e sei interessato a saperne di più sulla scienza dei dati, dai un'occhiata alla nostra formazione sulla scienza dei dati dalle migliori università.
Le domande e le risposte più comuni per le interviste di DataStage sono le seguenti:
Sommario
Domande e risposte sull'intervista a DataStage
1. Che cos'è IBM DataStage e perché viene utilizzato?
DataStage è uno strumento fornito da IBM e utilizzato per progettare, sviluppare ed eseguire le applicazioni per inserire i dati nei data warehouse estraendo i dati dai database dai server Windows. Contiene la funzionalità di visualizzazioni grafiche per l'integrazione dei dati e può anche estrarre dati da più fonti. È quindi considerato uno degli strumenti ETL più potenti. DataStage dispone di varie versioni che le aziende possono utilizzare in base alle proprie esigenze. Le versioni sono Server Edition, MVS Edition ed Enterprise Edition.
2. Quali sono le caratteristiche di DataStage?
Le caratteristiche di IBM DataStage sono le seguenti:
- Può essere distribuito su server locali e sul cloud in base alle necessità e ai requisiti.
- È facile da usare e può aumentare la velocità e la flessibilità dell'integrazione dei dati in modo efficiente.
- Supporta i big data e può accedere ai big data in molti modi, come l'integratore JDBC, il supporto JSON e i file system distribuiti.
3. Descrivere brevemente l'architettura DataStage.
IBM DataStage segue un modello client-server come architettura e dispone di diversi tipi di architettura per le sue varie versioni. I componenti dell'architettura client-server sono:
- Componenti del cliente
- Server
- Fasi
- Definizioni di tabelle
- Contenitori
- Progetti
- Lavori
4. Come possiamo eseguire un lavoro utilizzando la riga di comando in DataStage?
Il comando è: dsjob -run -jobstatus <nome progetto> <nome lavoro>
5. Elenca alcune funzioni che possiamo eseguire usando il comando 'dsjob'.
Le diverse funzioni che possiamo eseguire usando il comando $dsjob sono:
- $dsjob -run: viene utilizzato per eseguire il lavoro DataStage
- $dsjob -stop: viene utilizzato per interrompere il lavoro attualmente presente nel processo
- $dsjob -jobid: viene utilizzato per fornire le informazioni sul lavoro
- $dsjob -report: viene utilizzato per visualizzare il rapporto di lavoro completo
- $dsjob -lprojects: serve per elencare tutti i progetti presenti
- $dsjob -ljobs: serve per elencare tutti i lavori presenti nel progetto
- $dsjob -lstages: viene utilizzato per elencare tutte le fasi del lavoro corrente
- $dsjob -llinks: viene utilizzato per elencare tutti i collegamenti
- $dsjobs -lparams: serve per elencare tutti i parametri del lavoro
- $dsjob -projectinfo: viene utilizzato per recuperare le informazioni sul progetto
- $dsjob -jobinfo: viene utilizzato per il recupero delle informazioni del lavoro
- $dsjob -stageinfo: viene utilizzato per il recupero delle informazioni di quella fase di quel lavoro
- $dsjob -linkinfo: viene utilizzato per ottenere le informazioni di quel collegamento
- $dsjob -paraminfo: Fornisce le informazioni di tutti i parametri
- $dsjob -loginfo: viene utilizzato per ottenere le informazioni sul registro
- $dsjob -log: viene utilizzato per aggiungere un messaggio di testo nel registro
- $dsjob -logsum: viene utilizzato per visualizzare i dati di registro
- $dsjob -logdetail: viene utilizzato per visualizzare tutti i dettagli del log
- $dsjob -lognewest: viene utilizzato per recuperare l'id del registro più recente
6. Che cos'è un designer di flusso in IBM DataStage?
Flow Designer è l'interfaccia utente basata sul Web di DataStage e viene utilizzata per creare, modificare, caricare ed eseguire i lavori in DataStage.
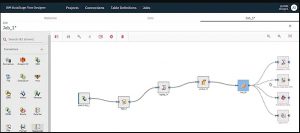
Fonte
7. Quali sono le caratteristiche principali del flow designer?
Le caratteristiche principali del flow designer sono:
- È molto utile per eseguire lavori con un numero elevato di fasi.
- Non è necessario migrare i lavori per utilizzare il designer del flusso.
- È possibile utilizzare la tavolozza fornita per aggiungere e rimuovere connettori e operatori nell'area di progettazione utilizzando la funzione di trascinamento della selezione.
Ulteriori informazioni su: Data Science Vs Data Mining: differenza tra Data Science e Data Mining
8. Come convertire un lavoro del server in un lavoro parallelo in DataStage?
Un lavoro del server può essere convertito in un lavoro parallelo utilizzando un raccoglitore Link e un raccoglitore IPC.
9 . Che cos'è un connettore HBase?
Un connettore HBase in DataStage è uno strumento utilizzato per connettere database e tabelle presenti nel database HBase. Viene utilizzato principalmente per eseguire le seguenti attività:
- Leggere e scrivere dati da e verso il database HBase.
- Lettura dei dati in modalità parallela.
- Utilizzo di HBase come tabella di visualizzazione
10. Che cos'è un connettore Hive?
Hive Connector è uno strumento utilizzato per supportare le modalità di partizione durante la lettura dei dati. Si può fare in due modi:
- modalità di partizione del modulo
- modalità di partizione minimo-massimo
11. Che cos'è Infosphere in DataStage?
Il server delle informazioni dell'infosfera è in grado di gestire i requisiti di volume elevati delle aziende e fornisce risultati di alta qualità e più rapidi. Fornisce alle aziende un'unica piattaforma per la gestione dei dati in cui possono comprendere, pulire, trasformare e fornire enormi quantità di informazioni.


Fonte
12. Elencare tutti i diversi livelli di InfoSphere Information Server?
I diversi livelli di InfoSphere Information Server sono:
- Livello cliente
- Livello servizi
- Livello motore
- Livello del repository di metadati
13. Descrivere brevemente il livello Client di Infosphere Information Server.
Il livello client di Infosphere Information Server viene utilizzato per lo sviluppo e l'amministrazione completa dei computer utilizzando i programmi client e le console.
14. Descrivere brevemente il livello Servizi di Infosphere Information Server.
Il livello dei servizi di Infosphere Information Server viene utilizzato per fornire servizi standard come metadati e registrazione e alcuni altri servizi specifici del modulo. Contiene un server delle applicazioni, vari moduli del prodotto e altri servizi del prodotto.
15. Descrivere brevemente il livello Motore di Infosphere Information Server.
Il livello motore di Infosphere Information Server è un insieme di componenti logici utilizzati per eseguire i lavori e altre attività per i moduli del prodotto.
16. Descrivere brevemente il livello Metadata Repository di Infosphere Information Server.
Il livello del repository di metadati di Infosphere Information Server include il repository di metadati, il database di analisi e il computer. Viene utilizzato per condividere i metadati, i dati condivisi e le informazioni di configurazione.
17. Quali sono i tipi di elaborazione parallela in DataStage?
Esistono due diversi tipi di elaborazione parallela, che sono:
- Partizionamento dei dati
- Pipeline di dati
18 . Che cos'è la partizione dei dati?
Il partizionamento dei dati è un tipo di approccio parallelo per l'elaborazione dei dati. Implica il processo di scomposizione dei record in partizioni per l'elaborazione. Aumenta l'efficienza dell'elaborazione in un modello lineare.
Ulteriori informazioni: Preelaborazione dei dati in Machine Learning: 7 semplici passaggi da seguire
19. Che cos'è la pipeline di dati?
Il Data Pipelining è un tipo di approccio parallelo per l'elaborazione dei dati in cui eseguiamo l'estrazione dei dati dalla fonte e quindi li facciamo passare attraverso una sequenza di funzioni di elaborazione per ottenere l'output richiesto.
20. Che cos'è la SSL in DataStage?
OSH è l'abbreviazione di Orchestrate Shell ed è un linguaggio di scripting utilizzato internamente in DataStage dal motore parallelo.
21. Cosa sono i giocatori?
I giocatori in DataStage sono i processi cavallo di battaglia. Ci aiutano a eseguire l'elaborazione parallela e sono assegnati agli operatori su ciascun nodo.
22. Che cos'è una libreria di raccolta in DataStage?
Le librerie di raccolta sono l'insieme degli operatori e vengono utilizzate per raccogliere i dati partizionati.
23. Quali sono i tipi di raccoglitori disponibili nella libreria di raccolta di DataStage?
Le tipologie di collezionisti disponibili nella biblioteca della collezione sono:
- Raccoglitore di smistamento
- Collettore tondo
- Collezionista ordinato
24. Come viene popolato il file di origine in DataStage?
Il file di origine può essere popolato utilizzando query SQL e anche utilizzando lo strumento di estrazione del generatore di righe.
Linea di fondo
Ci auguriamo che il nostro articolo contenente tutte le domande e le risposte sull'intervista a DataStage ti abbia aiutato a prepararti per l'intervista a DataStage. Puoi dare un'occhiata a questi corsi offerti da upGrad per aumentare le tue conoscenze su questi argomenti:
- Diploma PG in Software Development Specializzazione in Big Data : questo corso è creato da upGrad in associazione con IIIT-B per fornire alle persone le conoscenze necessarie per lo sviluppo del software e coprire le conoscenze sulla gestione dei Big Data.
- PGC in Full Stack Development : questo corso sullo sviluppo full-stack è creato da upGrad e dai professionisti del settore di Tech Mahindra per rendere le persone in grado di risolvere le sfide a livello di settore e acquisire tutte le competenze necessarie per entrare e lavorare nei settori.
Noi di upGrad siamo sempre lì per aiutarti con la tua preparazione. Puoi anche guardare i nostri corsi che possono aiutarti ad apprendere tutte le competenze e le tecniche richieste dal settore per prepararti bene ai colloqui e alle future ambizioni lavorative, come diciamo sempre "Raho Ambizioso". Questi corsi sono stati realizzati da esperti del settore e accademici esperti per renderti capace di diventare esperto in qualsiasi tecnologia e abilità tu voglia imparare.
Se sei interessato a imparare Python e vuoi sporcarti le mani su vari strumenti e librerie, dai un'occhiata al programma Executive PG in Data Science.
Quali sono le quattro fasi principali di Datastage?
IBM Datastage è un potente strumento per la progettazione, lo sviluppo e l'esecuzione delle applicazioni per inserire i dati nei data warehouse estraendo i dati dai database. Di seguito sono elencate le quattro fasi principali di Datastage. L'amministratore viene utilizzato per attività di amministrazione che includono la configurazione degli utenti DataStage e l'eliminazione dei criteri, la mobilitazione e la smobilitazione di progetti, ecc. Il designer o l'interfaccia di progettazione sviluppa le applicazioni Datastage O i lavori che sono regolati dal direttore ed eseguiti dal server. Come suggerisce il nome, manager mantiene e gestisce i repository e consente agli utenti di modificare i dati archiviati attraverso di essi. Il direttore svolge varie funzioni, tra cui la convalida dei lavori, la pianificazione e l'esecuzione, oltre al monitoraggio dei lavori paralleli.
Per quali scopi viene utilizzato il comando "dsjob"?
Il comando dsjob viene utilizzato per varie funzioni, incluso il recupero e la visualizzazione dei dati su progetti o lavori. Ecco alcune delle funzioni che possono essere eseguite usando il comando dsjob. $dsjob -run utilizzato per eseguire il lavoro DataStage, $dsjob -stop utilizzato per interrompere il lavoro attualmente presente nel processo, $dsjob -jobid utilizzato per fornire le informazioni sul lavoro, $dsjob -report utilizzato per visualizzare il rapporto completo del lavoro , eccetera.
Quali sono le caratteristiche di DataStage?
Datastage è un potente strumento di architettura dei dati e presenta diverse caratteristiche. Alcune delle caratteristiche di Datastage sono le seguenti: Datastage può essere distribuito sui server locali e sui server cloud a seconda delle esigenze dell'utente. La velocità e la flessibilità dell'integrazione dei dati possono essere aumentate in qualsiasi momento e possono essere utilizzate in modo efficiente. Supporta i big data e può accedere ai big data in molti modi, come l'integratore JDBC, il supporto JSON e i file system distribuiti.