
Visualizzazione dei dati in Python: Spiegazione dei grafici fondamentali [con illustrazione grafica]
Pubblicato: 2021-02-08Sommario
Principi di progettazione di base
Per qualsiasi aspirante data scientist di successo, essere in grado di spiegare le proprie ricerche e analisi è un'abilità molto importante e utile da possedere. È qui che entra in gioco la visualizzazione dei dati. È fondamentale utilizzare questo strumento in modo onesto poiché il pubblico può essere facilmente disinformato o ingannato da scelte di progettazione sbagliate.
Come data scientist, tutti noi abbiamo determinati obblighi in materia di preservare ciò che è vero.
Il primo è che dovremmo essere completamente onesti con noi stessi mentre puliamo e riepiloghiamo i dati. La pre-elaborazione dei dati è un passaggio molto cruciale per il funzionamento di qualsiasi algoritmo di apprendimento automatico e quindi qualsiasi disonestà nei dati porterà a risultati drasticamente diversi.
Un altro obbligo è nei confronti del nostro pubblico di destinazione. Esistono varie tecniche nella visualizzazione dei dati che vengono utilizzate per evidenziare sezioni specifiche di dati e rendere meno importanti alcuni altri dati. Quindi, se non stiamo abbastanza attenti, il lettore non sarà in grado di esplorare e giudicare correttamente l'analisi che può portare a dubbi e mancanza di fiducia.
Mettere sempre in discussione se stessi è una buona caratteristica per i data scientist. E dovremmo sempre pensare a come mostrare ciò che conta veramente in un modo comprensibile oltre che esteticamente gradevole, ricordando anche che il contesto è importante.
Questo è esattamente ciò che Alberto Cairo cerca di ritrarre nei suoi insegnamenti. Menziona le Cinque Qualità delle Grandi Visualizzazioni: belle, illuminanti, funzionali, perspicaci e veritiere che vale la pena tenere a mente.
Alcune trame fondamentali
Ora che abbiamo una conoscenza di base dei principi di progettazione, immergiamoci in alcune tecniche di visualizzazione fondamentali utilizzando la libreria matplotlib in Python.
Tutto il codice seguente può essere eseguito in un notebook Jupyter.
%taccuino matplotlib
# questo fornisce un ambiente interattivo e imposta il back-end. ( È possibile utilizzare anche %matplotlib inline ma non è interattivo. Ciò significa che qualsiasi ulteriore chiamata alle funzioni di stampa non aggiornerà automaticamente la nostra visualizzazione originale.)
import matplotlib.pyplot come plt # importazione del modulo libreria richiesto
Grafici a punti
La funzione matplotlib più semplice per tracciare un punto è plot() . Gli argomenti rappresentano le coordinate X e Y, quindi un valore stringa che descrive come visualizzare l'output dei dati.
plt.figura()
plt.plot( 5, 6, '+' ) # il segno + funge da marcatore
Grafici a dispersione
Un grafico a dispersione è un grafico bidimensionale. La funzione scatter() prende anche il valore X come primo argomento e il valore Y come secondo. Il grafico sottostante è una linea diagonale e matplotlib regola automaticamente le dimensioni di entrambi gli assi. Qui, il grafico a dispersione non tratta gli elementi come una serie. Quindi, possiamo anche fornire un elenco di colori desiderati corrispondenti a ciascuno dei punti.
importa numpy come np
x = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
y = x
plt.figura()
plt.scatter( x, y )
Grafici a linee
Un grafico lineare viene creato con la funzione plot() e traccia un numero di diverse serie di punti dati come un grafico a dispersione, ma collega ciascuna serie di punti con una linea.
importa numpy come np
dati_lineari = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
dati_quadrati = dati_lineari**2
plt.figura()
plt.plot( dati_lineari, '-o', dati_quadrati, '-o')
Per rendere il grafico più leggibile, possiamo anche aggiungere una legenda che ci dirà cosa rappresenta ogni linea. È importante un titolo adatto per il grafico e per entrambi gli assi. Inoltre, qualsiasi sezione del grafico può essere ombreggiata utilizzando la funzione fill_between() per evidenziare le regioni rilevanti.
plt.xlabel('valori X')
plt.ylabel('Valori Y')
plt.title('Trame lineari')

plt.legend( ['lineare', 'quadrato'] )
plt.gca().fill_between( range ( len ( linear_data ) ), linear_data, squared_data, facecolor = 'blue', alpha = 0.25)
Ecco come appare il grafico modificato-
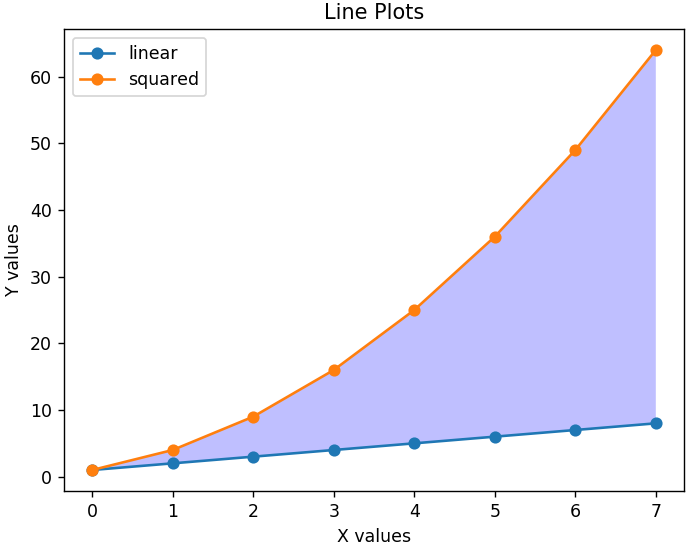
Grafici a barre
Possiamo tracciare un grafico a barre inviando argomenti per i valori X e l'altezza di ciascuna barra alla funzione bar() . Di seguito è riportato un grafico a barre dello stesso array di dati lineari che abbiamo usato sopra.
plt.figura()
x = range( len ( dati_lineari ))
plt.bar( x, dati_lineari )
# per tracciare i dati al quadrato come un altro insieme di barre sullo stesso grafico, dobbiamo regolare i nuovi valori x per compensare il primo insieme di barre
nuovo_x = []
per i dati in x:
new_x.append(data+0.3)
plt.bar(new_x, dati_quadrati, larghezza = 0,3, colore = 'verde')
# Per i grafici con orientamento orizzontale utilizziamo la funzione barh()
plt.figura()
x = range( len( linear_data ))
plt.barh( x, dati_lineari, altezza = 0,3, colore = 'b')
plt.barh( x, dati_quadrati, altezza = 0,3, sinistra = dati_lineari, colore = 'g')
#qui è un esempio di impilamento dei grafici a barre verticalmente
plt.figura()
x = range( len( linear_data ))
plt.bar( x, dati_lineari, larghezza = 0,3, colore = 'b')
plt.bar( x, dati_quadrati, larghezza = 0,3, fondo = dati_lineari, colore = 'g')
Impara i corsi di scienza dei dati dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
Conclusione
I tipi di visualizzazione non finiscono qui. Python ha anche una grande libreria chiamata seaborn che vale sicuramente la pena esplorare. Una corretta visualizzazione delle informazioni aiuta notevolmente ad aumentare il valore dei nostri dati. La visualizzazione dei dati sarà sempre l'opzione migliore per ottenere informazioni dettagliate e identificare varie tendenze e modelli piuttosto che guardare attraverso noiose tabelle con milioni di record.
Se sei curioso di conoscere la scienza dei dati, dai un'occhiata al Diploma PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1- on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Quali sono alcuni pacchetti Python utili per la visualizzazione dei dati?
Python ha alcuni pacchetti utili e sorprendenti per la visualizzazione dei dati. Alcuni di questi pacchetti sono menzionati di seguito:
1. Matplotlib - Matplotlib è una popolare libreria Python utilizzata per la visualizzazione dei dati in varie forme come grafici a dispersione, grafici a barre, grafici a torta e grafici a linee. Usa Numpy per le sue operazioni matematiche.
2. Seaborn - La libreria Seaborn viene utilizzata per le rappresentazioni statistiche in Python. È sviluppato sulla parte superiore di Matplotlib ed è integrato con le strutture dati di Pandas.
3. Altair - Altair è un'altra popolare libreria Python per la visualizzazione dei dati. È una libreria statistica dichiarativa che consente di creare elementi visivi con il minimo codice possibile.
4. Plotly - Plotly è una libreria di visualizzazione dati interattiva e open source di Python. Gli elementi visivi creati da questa libreria basata su browser sono supportati da molte piattaforme come Jupyter Notebook e file HTML autonomi.
Cosa sai sui grafici a punti e sui grafici a dispersione?
I grafici a punti sono i grafici più semplici e basilari per la visualizzazione dei dati. Un grafico a punti visualizza i dati sotto forma di punti su un piano cartesiano. Il “+” indica l'aumento del valore mentre “-” indica la diminuzione del valore nel tempo.
Un grafico a dispersione d'altra parte è un grafico ottimizzato in cui i dati vengono visualizzati su un piano 2-D. Viene definito utilizzando la funzione scatter() che prende il valore dell'asse x come primo parametro e il valore dell'asse y come secondo parametro.
Quali sono i vantaggi della visualizzazione dei dati?
I seguenti vantaggi mostrano come le visualizzazioni dei dati possono diventare il vero eroe per la crescita di un'organizzazione:
1. La visualizzazione dei dati semplifica l'interpretazione dei dati grezzi e la loro comprensione per ulteriori analisi.
2. Dopo aver ricercato e analizzato i dati, i risultati possono essere visualizzati utilizzando visualizzazioni significative. Questo rende più facile entrare in contatto con il pubblico e spiegare i risultati.
3. Una delle applicazioni più essenziali di questa tecnica è l'analisi di modelli e tendenze per dedurre previsioni e potenziali aree di crescita.
4. Consente inoltre di separare i dati in base alle preferenze del cliente. Puoi anche identificare le aree che richiedono maggiore attenzione.