
Strutture dati in Python – Guida completa
Pubblicato: 2021-06-14Sommario
Che cos'è la struttura dei dati?
La struttura dei dati si riferisce alla memorizzazione computazionale dei dati per un uso efficiente. Memorizza i dati in un modo che può essere facilmente modificato e accessibile. Si riferisce collettivamente ai valori dei dati, alla relazione tra loro e alle operazioni che possono essere eseguite sui dati. L'importanza della struttura dei dati risiede nella sua applicazione per lo sviluppo di programmi per computer. Poiché i programmi per computer fanno molto affidamento sui dati, la corretta disposizione dei dati per un facile accesso è di primaria importanza per qualsiasi programma o software.
Le quattro funzioni principali di una struttura dati sono
- Per inserire informazioni
- Per elaborare le informazioni
- Per mantenere le informazioni
- Per recuperare le informazioni
Tipi di strutture dati in Python
Diverse strutture di dati sono supportate da Python per un facile accesso e archiviazione dei dati. I tipi di strutture dati Python possono essere classificati come tipi di dati primitivi e non primitivi. I primi tipi di dati includono Integers, Float, Strings e Boolean, mentre il secondo è l'array, l'elenco, le tuple, i dizionari, gli insiemi e i file. Pertanto, le strutture dati in Python sono sia strutture dati integrate che strutture dati definite dall'utente. La struttura dati incorporata viene definita struttura dati non primitiva.
Strutture dati integrate
Python ha diverse strutture di dati che fungono da contenitori per l'archiviazione di altri dati. Queste strutture di dati Python sono List, Dictionaries, Tuple e Sets.
Strutture dati definite dall'utente
Queste strutture dati possono essere programmate con la stessa funzione di quella delle strutture dati integrate in python . Le strutture dati definite dall'utente sono: Elenco collegato, Stack, Coda, Albero, Grafico e Hashmap.
Elenco delle strutture dati integrate e spiegazione
1. Elenco
I dati memorizzati in un elenco sono disposti in sequenza e di diversi tipi di dati. Ad ogni dato viene assegnato un indirizzo, noto come indice. Il valore dell'indice inizia con uno 0 e prosegue fino all'ultimo elemento. Questo è chiamato indice positivo. Un indice negativo esiste anche se si accede agli elementi in modo inverso. Questo è chiamato indicizzazione negativa.
Creazione lista
L'elenco viene creato tra parentesi quadre. Gli elementi possono quindi essere aggiunti di conseguenza. Può essere aggiunto tra parentesi quadre per creare un elenco. Se non vengono aggiunti elementi, verrà creata una lista vuota. Altrimenti verranno creati gli elementi all'interno dell'elenco.
| Ingresso mia_lista = [] #crea una lista vuota stampa(la mia_lista) mia_lista = [1, 2, 3, 'esempio', 3.132] #creazione lista con dati stampa(la mia_lista) | Produzione [] [1, 2, 3, 'esempio', 3.132] |
Aggiunta di elementi all'interno di un elenco
Tre funzioni vengono utilizzate per l'aggiunta di elementi all'interno di un elenco. Queste funzioni sono append(), extend() e insert().
- Tutti gli elementi vengono aggiunti come un singolo elemento utilizzando la funzione append().
- Per aggiungere gli elementi uno per uno nell'elenco, viene utilizzata la funzione extend().
- Per aggiungere elementi in base al loro valore di indice, viene utilizzata la funzione insert().
| Ingresso mia_lista = [1, 2, 3] stampa(la mia_lista) my_list.append([555, 12]) #aggiungi come singolo elemento stampa(la mia_lista) my_list.extend([234, 'more_example']) #aggiungi come elementi diversi stampa(la mia_lista) my_list.insert(1, 'insert_example') #aggiungi elemento i stampa(la mia_lista) | Produzione: [1, 2, 3] [1, 2, 3, [555, 12]] [1, 2, 3, [555, 12], 234, 'altro_esempio'] [1, 'inserire_esempio', 2, 3, [555, 12], 234, 'altro_esempio'] |
Eliminazione di elementi all'interno di un elenco
Una parola chiave incorporata "del" in python viene utilizzata per eliminare un elemento dall'elenco. Tuttavia, questa funzione non restituisce l'elemento eliminato.
- Per restituire un elemento eliminato viene utilizzata la funzione pop(). Utilizza il valore di indice dell'elemento da eliminare.
- La funzione remove() viene utilizzata per eliminare un elemento in base al suo valore.
Produzione:
[1, 2, 3, 'esempio', 3.132, 30]
[1, 2, 3, 3.132, 30]
Elemento saltato: 2 Elenco rimanente: [1, 3, 3.132, 30]
[]
Valutazione di elementi in una lista
- Valutare l'elemento in un elenco è semplice. La stampa dell'elenco visualizzerà direttamente gli elementi.
- Elementi specifici possono essere valutati passando il valore dell'indice.
Produzione:
1
2
3
esempio
3.132
10
30
[1, 2, 3, 'esempio', 3.132, 10, 30]
Esempio
[1, 2]
[30, 10, 3.132, 'esempio', 3, 2, 1]
Oltre alle operazioni sopra menzionate, in Python sono disponibili molte altre funzioni integrate per lavorare con le liste.
- len(): la funzione viene utilizzata per restituire la lunghezza della lista.
- index(): questa funzione permette all'utente di conoscere il valore di indice di un valore passato.
- La funzione count() viene utilizzata per trovare il conteggio del valore passato.
- sort() ordina il valore in un elenco e modifica l'elenco.
- sorted() ordina il valore in un elenco e restituisce l'elenco.
Produzione
6
3
2
[1, 2, 3, 10, 10, 30]
[30, 10, 10, 3, 2, 1]
2. Dizionario
Il dizionario è un tipo di struttura dati in cui vengono archiviate coppie chiave-valore anziché singoli elementi. Può essere spiegato con l'esempio di un elenco telefonico che contiene tutti i numeri delle persone insieme ai loro numeri di telefono. Il nome e il numero di telefono qui definiscono i valori costanti che sono la "chiave" e i numeri e i nomi di tutte le persone come valori di quella chiave. La valutazione di una chiave darà accesso a tutti i valori memorizzati all'interno di quella chiave. Questa struttura chiave-valore definita su Python è nota come dizionario.
Creazione di un dizionario
- Le parentesi graffe inattive la funzione dict() può essere utilizzata per creare un dizionario.
- Le coppie chiave-valore devono essere aggiunte durante la creazione di un dizionario.
Modifica in coppie chiave-valore
Eventuali modifiche al dizionario possono essere effettuate solo tramite la chiave. Pertanto, è necessario prima accedere alle chiavi e poi eseguire le modifiche.
| Ingresso my_dict = {'First': 'Python', 'Second': 'Java'} print(my_dict) my_dict['Second'] = 'C++' #change element print(my_dict) my_dict['Terzo'] = 'Ruby' #aggiunta coppia chiave-valore print(my_dict) | Produzione: {'Primo': 'Python', 'Secondo': 'Java'} {'Primo': 'Pitone', 'Secondo': 'C++'} {'Primo': 'Pitone', 'Secondo': 'C++', 'Terzo': 'Rubino'} |
Cancellazione di un dizionario
Una funzione clear() viene utilizzata per eliminare l'intero dizionario. Il dizionario può essere valutato attraverso le chiavi usando la funzione get() o passando i valori delle chiavi.
| Ingresso dict = {'Mese': 'Gennaio', 'Stagione': 'inverno'} print(dict['Primo']) print(dict.get('Secondo') | Produzione gennaio Inverno |
Altre funzioni associate a un dizionario sono keys(), values() e items().
3. Tupla
Simile all'elenco, le tuple sono elenchi di archiviazione dati, ma l'unica differenza è che i dati archiviati in una tupla non possono essere modificati. Se i dati all'interno di una tupla sono mutabili, solo allora è possibile modificare i dati.
- Le tuple possono essere create tramite la funzione tuple().
Ingresso
nuova_tupla = (10, 20, 30, 40)
stampa(nuova_tupla)
Produzione
(10, 20, 30, 40)
- Gli elementi in una tupla possono essere valutati allo stesso modo della valutazione degli elementi in un elenco.
Ingresso
new_tuple2 = (10, 20, 30, 'età')
per x in new_tuple2:
stampa(x)
stampa(nuova_tupla2)
print(new_tuple2[0])
Produzione
10
20
30
Età
(10, 20, 30, 'età')
10
- L'operatore '+' viene utilizzato per aggiungere un'altra tupla
Ingresso
tupla = (1, 2, 3)
tupla = tupla + (4, 5, 6
stampa (tupla)
Produzione
(1, 2, 3, 4, 5, 6)
4. Impostare
La struttura dei dati degli insiemi è simile agli insiemi aritmetici. È fondamentalmente la raccolta di elementi unici. Se i dati continuano a ripetersi, gli insiemi considerano l'aggiunta di quell'elemento solo una volta.
- Un set può essere creato semplicemente passando i valori all'interno di parentesi floreali.
Ingresso

set = {10, 20, 30, 40, 40, 40}
stampa (imposta)
Produzione
{10, 20, 30, 40}
- La funzione add() può essere utilizzata per aggiungere elementi a un set.
- Per combinare i dati di due insiemi, è possibile utilizzare la funzione union().
- Per identificare i dati presenti in entrambi gli insiemi, viene utilizzata la funzione di intersezione().
- La funzione Difference() restituisce solo i dati univoci per l'insieme, rimuovendo i dati comuni.
- La funzione symmetric_difference() restituisce i dati univoci per entrambi gli insiemi.
Elenco delle strutture dati definite dall'utente e spiegazione
1. Pile
Uno stack è una struttura lineare che è una struttura Last in First out (LIFO) o First in Last Out (FIFO). Esistono due operazioni principali nello stack, ovvero push e pop. Push significa aggiungere un elemento in cima all'elenco mentre pop significa rimuovere un elemento dal fondo dello stack. Il processo è ben descritto nella Figura 1.
Utilità della pila
- Gli elementi precedenti possono essere valutati attraverso il tracciamento a ritroso.
- Abbinamento di elementi ricorsivi.
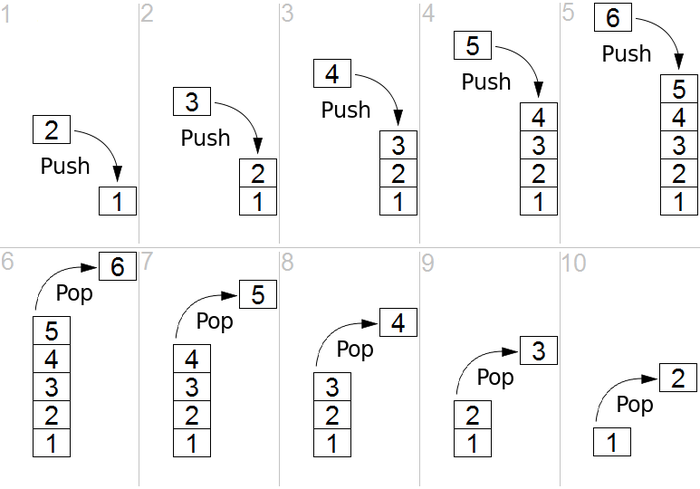
Fonte
Figura 1: Rappresentazione grafica di Stack
Esempio

Produzione
['primo secondo terzo']
['primo secondo terzo quarto quinto']
quinto
['primo secondo terzo quarto']
2. Coda
Simile alle pile, una coda è una struttura lineare che consente l'inserimento di un elemento a un'estremità e la cancellazione dall'altra estremità. Le due operazioni sono note come accodamento e rimozione dalla coda. L'elemento aggiunto di recente viene rimosso per primo come le pile. Una rappresentazione grafica della coda è mostrata in Figura 2. Uno degli usi principali di una coda è per l'elaborazione delle cose non appena entrano.
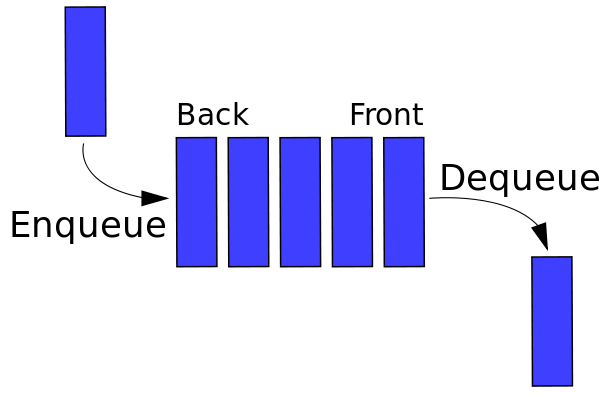
Fonte
Figura 2 : Rappresentazione grafica delle code
Esempio

Produzione
['primo secondo terzo']
['primo secondo terzo quarto quinto']
primo
quinto
['secondo', 'terzo', 'quarto', 'quinto']
3. Albero
Gli alberi sono strutture di dati non lineari e gerarchiche costituite da nodi collegati tramite archi. La struttura dei dati dell'albero di Python ha un nodo radice, un nodo padre e un nodo figlio. La radice è l'elemento più in alto di una struttura dati. Un albero binario è una struttura in cui gli elementi non hanno più di due nodi figlio.
L'utilità di un albero
- Visualizza le relazioni strutturali degli elementi di dati.
- Attraversa ogni nodo in modo efficiente
- Gli utenti possono inserire, cercare, recuperare ed eliminare i dati.
- Strutture dati flessibili
Figura 3: Rappresentazione grafica di un albero
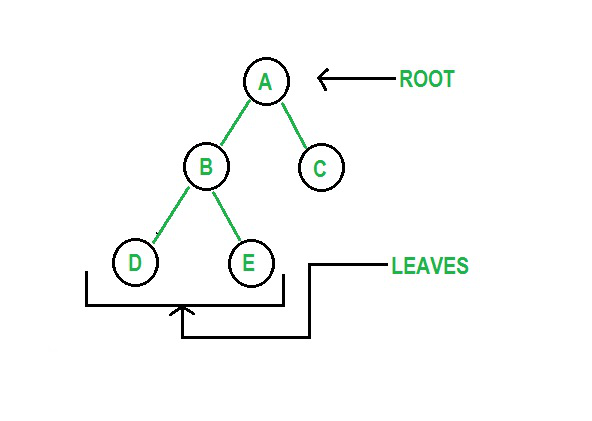
Fonte
Esempio:

Produzione
Primo
Secondo
Terzo
4. Grafico
Un'altra struttura di dati non lineare in Python è il grafico che consiste di nodi e bordi. Graficamente mostra un insieme di oggetti, con alcuni oggetti collegati tramite link. I vertici sono oggetti interconnessi mentre i collegamenti sono definiti bordi. La rappresentazione di un grafico può essere eseguita tramite la struttura dati del dizionario di python, dove la chiave rappresenta i vertici ei valori rappresentano i bordi.
Operazioni di base eseguibili sui grafici
- Visualizza i vertici e gli spigoli del grafico.
- Aggiunta di un vertice.
- Aggiunta di un bordo.
- Creazione di un grafico
L'utilità di un grafico
- La rappresentazione di un grafico è facile da capire e da seguire.
- È un'ottima struttura per rappresentare le relazioni collegate, ad esempio gli amici di Facebook.
Figura 4: Rappresentazione grafica di un grafico
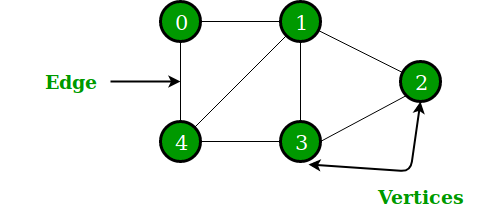
Fonte
Esempio

g = grafico(4)
g.edge(0, 2)
g.edge(1, 3)
g.edge(3, 2)
g.edge(0, 3)
g.__repr__()
Produzione
Elenco di adiacenza del vertice 0
testa -> 3 -> 2
Elenco di adiacenza del vertice 1
testa -> 3
Lista di adiacenza del vertice 2
testa -> 3 -> 0
Lista di adiacenza del vertice 3
testa -> 0 -> 2 -> 1
5. Hashmap
Le hashmap sono strutture dati python indicizzate utili per l'archiviazione di coppie chiave-valore. I dati memorizzati nelle hashmap vengono recuperati tramite le chiavi che vengono calcolate tramite l'aiuto di una funzione hash. Questi tipi di strutture dati sono utili per la memorizzazione dei dati degli studenti, dei dettagli dei clienti, ecc. I dizionari in Python sono un esempio di hashmap.
Esempio

Produzione
0 -> primo
1 -> secondo
2 -> terzo
0 -> primo
1 -> secondo
2 -> terzo
3 -> quarto
0 -> primo
1 -> secondo
2 -> terzo
Utilità
- È il metodo più flessibile e affidabile per recuperare informazioni rispetto ad altre strutture di dati.
6. Elenco collegato
È un tipo di struttura dati lineare. Fondamentalmente, è una serie di elementi di dati uniti tra loro tramite collegamenti in Python. Gli elementi in un elenco collegato sono collegati tramite puntatori. Il primo nodo di questa struttura dati è indicato come intestazione e l'ultimo nodo è indicato come coda. Pertanto, un elenco collegato è costituito da nodi con valori e ogni nodo è costituito da un puntatore collegato a un altro nodo.
L'utilità delle liste collegate
- Rispetto a un array fisso, un elenco collegato è una forma dinamica di immissione di dati. La memoria viene salvata in quanto alloca la memoria dei nodi. Mentre in un array, la dimensione deve essere predefinita, causando uno spreco di memoria.
- Un elenco collegato può essere archiviato in qualsiasi punto della memoria. Un nodo elenco collegato può essere aggiornato e spostato in una posizione diversa.
Figura 6: Rappresentazione grafica di un elenco collegato
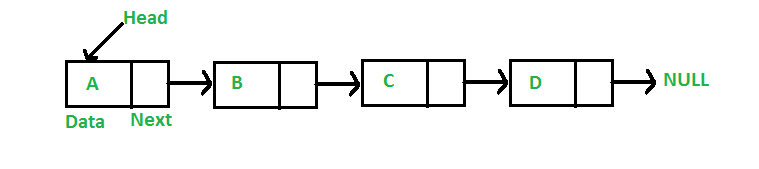
Fonte
Esempio

Produzione:
['primo secondo terzo']
['primo', 'secondo', 'terzo', 'sesto', 'quarto', 'quinto']
['primo', 'terzo', 'sesto', 'quarto', 'quinto']
Conclusione
Sono stati esplorati i vari tipi di strutture dati in Python . Che tu sia un principiante o un esperto le strutture dati e gli algoritmi non possono essere ignorati. Durante l'esecuzione di qualsiasi forma di operazione sui dati, i concetti di strutture dati svolgono un ruolo fondamentale. Le strutture dati aiutano a memorizzare le informazioni in modo organizzato, mentre gli algoritmi aiutano a guidare durante l'analisi dei dati. Pertanto, sia le strutture di dati python che gli algoritmi aiutano l'informatico o qualsiasi utente a elaborare i propri dati.
Se sei curioso di conoscere le strutture dei dati, dai un'occhiata all'Executive PG Program in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1 -on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Quale struttura dati è più veloce in Python?
Nei dizionari, le ricerche sono più veloci perché Python utilizza tabelle hash per implementarle. Se usiamo i concetti di Big O per illustrare la distinzione, i dizionari possiedono una complessità temporale costante, O(1), mentre le liste hanno una complessità temporale lineare, O(n).
In Python, i dizionari sono il modo più rapido per cercare frequentemente i dati con migliaia di voci. I dizionari sono altamente ottimizzati perché sono il tipo di mappatura integrato in Python. Nei dizionari e nelle liste, tuttavia, esiste un comune compromesso spazio-temporale. Indica che mentre possiamo ridurre il tempo richiesto per il nostro approccio, dovremo utilizzare più spazio di memoria.
Negli elenchi, per ottenere ciò che desideri, devi scorrere l'elenco completo. Un dizionario, d'altra parte, restituirà il valore che stai cercando senza guardare tutte le chiavi.
Qual è più veloce nell'elenco o nell'array Python?
In generale, gli elenchi Python sono incredibilmente flessibili e possono contenere dati casuali completamente eterogenei, oltre ad essere aggiunti rapidamente e in un tempo approssimativo costante. Sono la strada da percorrere se hai bisogno di ridimensionare ed estendere la tua lista in modo rapido e indolore. Tuttavia, occupano molto più spazio degli array, in parte perché ogni elemento nell'elenco richiede la creazione di un oggetto Python separato.
D'altra parte, il tipo array.array è essenzialmente un sottile wrapper attorno agli array C. Può trasportare solo dati omogenei (cioè dati dello stesso tipo), quindi la memoria è limitata a sizeof(un oggetto) * byte di lunghezza.
Qual è la differenza tra l'array NumPy e l'elenco?
Numpy è il pacchetto principale di calcolo scientifico di Python. Utilizza un grande oggetto array multidimensionale e utilità per manipolarli. Un array numpy è una griglia di valori di tipo identico indicizzati da una tupla di interi non negativi.
Gli elenchi sono stati inclusi nella libreria principale di Python. Un elenco è simile a un array in Python, ma può essere ridimensionato e contenere elementi di vario tipo. Qual è la vera differenza qui? Le prestazioni sono la risposta. Le strutture dati Numpy sono più efficienti in termini di dimensioni, prestazioni e funzionalità.