
La scheda tecnica definitiva per la scienza dei dati che ogni data scientist dovrebbe avere
Pubblicato: 2021-01-29Per tutti quei professionisti in erba e principianti che stanno pensando di fare un tuffo nel mondo in forte espansione della scienza dei dati, abbiamo compilato un rapido cheat sheet per farti rispolverare le basi e le metodologie che sottolineano questo campo.
Sommario
Data Science-Le basi
I dati che vengono generati nel nostro mondo sono in una forma grezza, cioè numeri, codici, parole, frasi, ecc. La scienza dei dati prende questi dati molto grezzi per elaborarli utilizzando metodi scientifici per trasformarli in forme significative per acquisire conoscenze e intuizioni .
Dati
Prima di approfondire i principi della scienza dei dati, parliamo un po' dei dati, dei loro tipi e dell'elaborazione dei dati.
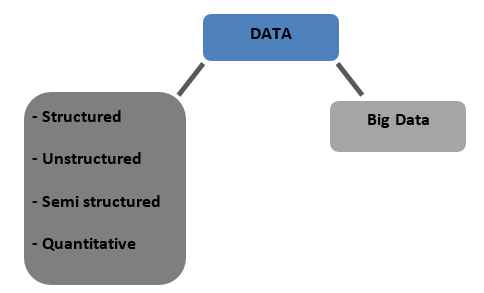
Tipi di dati
Strutturato : dati archiviati in un formato tabulato nei database. Può essere numerico o testuale
Non strutturati : i dati che non possono essere tabulati con alcuna struttura definitiva di cui parlare sono chiamati dati non strutturati
Semistrutturato : dati misti con caratteristiche di dati strutturati e non strutturati
Quantitativo : dati con valori numerici definiti che possono essere quantificati
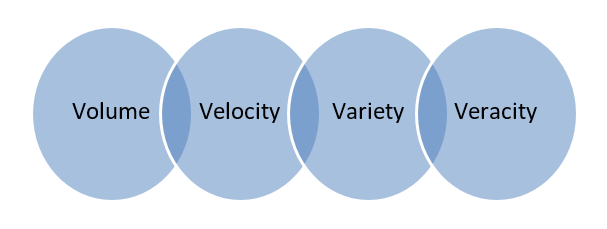
Big Data : i dati archiviati in enormi database che si estendono su più computer o server farm sono chiamati Big Data. I dati biometrici, i dati dei social media, ecc. sono considerati Big Data. I big data sono caratterizzati da 4 V
Preelaborazione dei dati
Classificazione dei dati : è il processo di categorizzazione o etichettatura dei dati in classi come numeriche, testuali o di immagini, testo, video, ecc.
Pulizia dei dati : consiste nell'eliminare i dati mancanti/incoerenti/incompatibili o nella sostituzione dei dati utilizzando uno dei seguenti metodi.
- Interpolazione
- Euristico
- Assegnazione casuale
- Vicino più vicino
Data Masking – Nascondere o mascherare i dati riservati per mantenere la privacy delle informazioni sensibili pur essendo in grado di elaborarle.
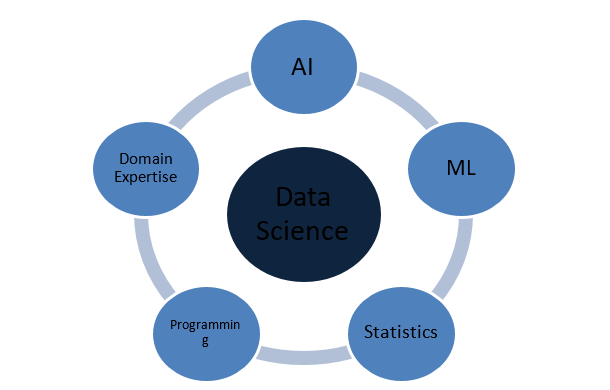
Di cosa è fatta la scienza dei dati?
Concetti di statistica
Regressione
Regressione lineare
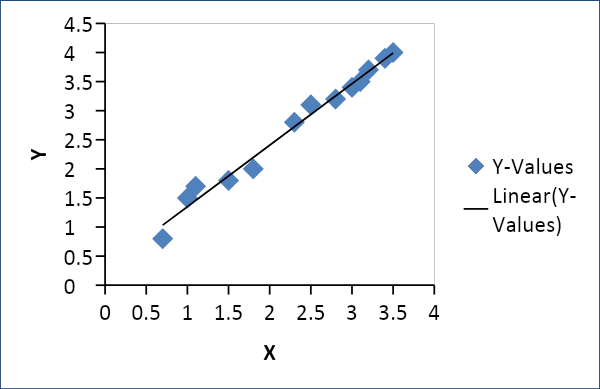
La regressione lineare viene utilizzata per stabilire una relazione tra due variabili come domanda e offerta, prezzo e consumo, ecc. Collega una variabile x come una funzione lineare di un'altra variabile y come segue
Y = f(x) o Y =mx + c, dove m = coefficiente
Regressione logistica
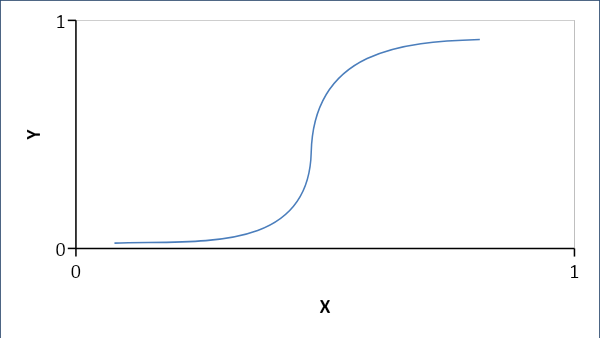
La regressione logistica stabilisce una relazione probabilistica piuttosto che lineare tra le variabili. La risposta risultante è 0 o 1 e cerchiamo le probabilità e la curva è a forma di S.
Se p < 0,5, allora è 0 altrimenti 1
Formula:
Y = e^ (b0 + b1x) / (1 + e^ (b0 + b1x))
dove b0 = bias e b1 = coefficiente
Probabilità
La probabilità aiuta a prevedere la probabilità che si verifichi un evento. Alcune terminologie:
Campione: l'insieme dei risultati probabili
Evento: è un sottoinsieme dello spazio campionario
Variabile casuale: le variabili casuali aiutano a mappare o quantificare i risultati probabili su numeri o linee in uno spazio campionario
Distribuzioni di probabilità
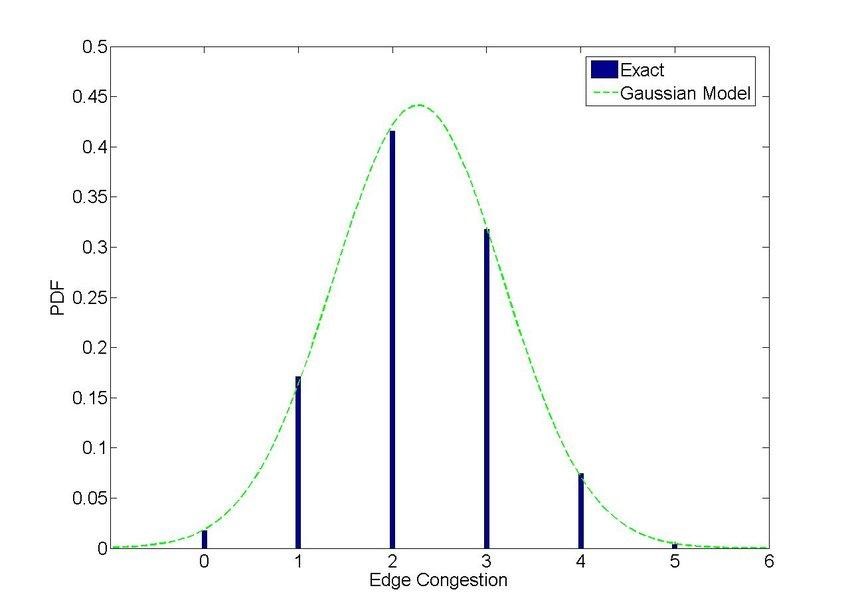
Distribuzioni discrete: fornisce la probabilità come un insieme di valori discreti (intero)
P[X=x] = p(x)
 Fonte immagine
Fonte immagine
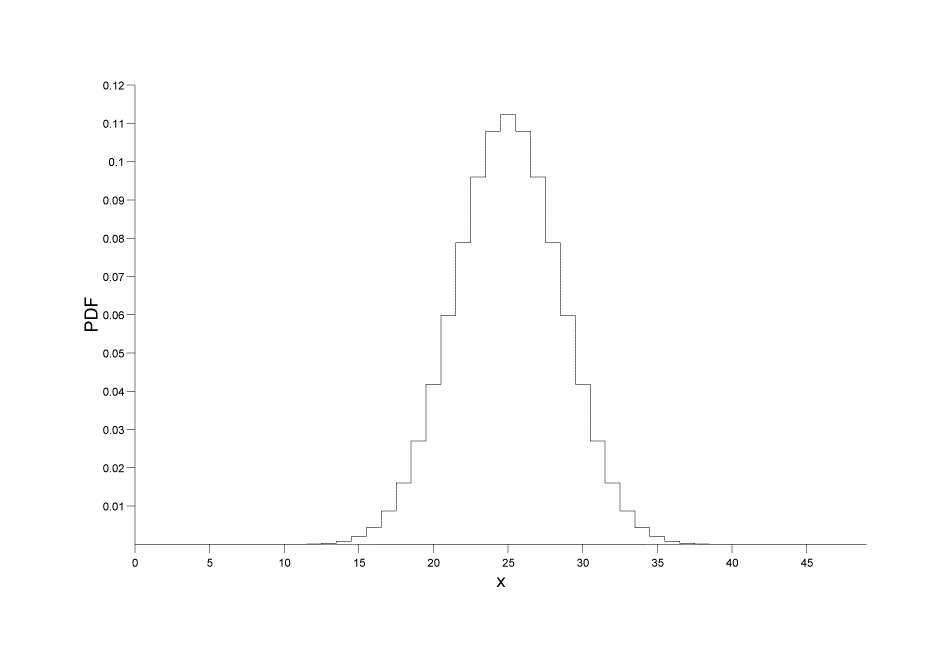
Distribuzioni continue: fornisce la probabilità su un numero di punti o intervalli continui anziché su valori discreti. Formula:
P[a ≤ x ≤ b] = a∫bf(x) dx, dove a, b sono i punti
Fonte immagine
Correlazione e covarianza
Deviazione standard: la variazione o deviazione di un dato set di dati dal suo valore medio
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
Covarianza
Definisce l'entità della deviazione delle variabili casuali X e Y con la media del set di dati.
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
Correlazione
La correlazione definisce l'estensione di una relazione lineare tra le variabili insieme alla loro direzione, +ve o -ve
ρXY= σ2XY/ σX * *σY
Intelligenza artificiale
La capacità delle macchine di acquisire conoscenze e prendere decisioni basate su input è chiamata Intelligenza Artificiale o semplicemente AI.
Tipi
- Macchine reattive: l'IA delle macchine reattive funziona imparando a reagire a scenari predefiniti restringendosi alle opzioni più veloci e migliori. Non hanno memoria e sono ideali per attività con un insieme definito di parametri. Altamente affidabile e coerente.
- Memoria limitata: questa IA ha alcuni dati osservativi e legacy del mondo reale alimentati. Può apprendere e prendere decisioni in base ai dati forniti ma non può acquisire nuove esperienze.
- Teoria della mente: è un'IA interattiva che può prendere decisioni in base al comportamento delle entità circostanti.
- Consapevolezza di sé: questa IA è consapevole della sua esistenza e del suo funzionamento indipendentemente dall'ambiente circostante. Può sviluppare capacità cognitive e comprendere e valutare gli impatti delle proprie azioni sull'ambiente circostante.
Termini dell'IA
Reti neurali
Le reti neurali sono un insieme o una rete di nodi interconnessi che trasmettono dati e informazioni in un sistema. Gli NN sono modellati per imitare i neuroni nel nostro cervello e possono prendere decisioni imparando e prevedendo.
Euristico
L'euristica è la capacità di prevedere rapidamente sulla base di approssimazioni e stime utilizzando l'esperienza precedente in situazioni in cui le informazioni disponibili sono irregolari. È veloce ma non preciso o preciso.
Ragionamento per casi
La capacità di imparare dai precedenti casi di problem solving e applicarli nelle situazioni attuali per arrivare a una soluzione accettabile
Elaborazione del linguaggio naturale
È semplicemente la capacità di una macchina di comprendere e interagire direttamente nel parlato o nel testo umano. Ad esempio, i comandi vocali in un'auto
Apprendimento automatico
L'apprendimento automatico è semplicemente un'applicazione dell'IA che utilizza vari modelli e algoritmi per prevedere e risolvere problemi.

Tipi
Supervisionato
Questo metodo si basa sui dati di input associati ai dati di output. La macchina è dotata di un set di variabili target Y e deve arrivare alla variabile target attraverso un set di variabili di input X sotto la supervisione di un algoritmo di ottimizzazione. Esempi di apprendimento supervisionato sono le reti neurali, la foresta casuale, l'apprendimento profondo, le macchine vettoriali di supporto, ecc.
Senza supervisione
In questo metodo, le variabili di input non hanno etichettatura o associazione e gli algoritmi lavorano per trovare modelli e cluster che danno origine a nuove conoscenze e approfondimenti.
Rinforzati
L'apprendimento rinforzato si concentra sulle tecniche di improvvisazione per affinare o perfezionare il comportamento di apprendimento. È un metodo basato sulla ricompensa in cui la macchina migliora gradualmente le sue tecniche per ottenere una ricompensa target.
Metodi di modellazione
Regressione
I modelli di regressione forniscono sempre numeri come output tramite l'interpolazione o l'estrapolazione di dati continui.
Classificazione
I modelli di classificazione producono risultati come una classe o un'etichetta e sono più bravi a prevedere risultati discreti come "che tipo"
Sia la regressione che la classificazione sono modelli supervisionati.
Raggruppamento
Il clustering è un modello non supervisionato che identifica i cluster in base a tratti, attributi, caratteristiche, ecc.
Algoritmi ML
Alberi decisionali
Gli alberi decisionali utilizzano un approccio binario per arrivare a una soluzione basata su domande successive in ogni fase in modo tale che il risultato sia uno dei due possibili come "Sì" o "No". Gli alberi decisionali sono semplici da implementare e interpretare.
Foresta casuale o insacco
Random Forest è un algoritmo avanzato di alberi decisionali. Utilizza un gran numero di alberi decisionali che rendono la struttura densa e complessa come una foresta. Genera più risultati e quindi porta a risultati e prestazioni più accurati.
K- Vicino più vicino (KNN)
kNN utilizza la vicinanza dei punti dati più vicini su un grafico rispetto a un nuovo punto dati per prevedere in quale categoria rientra. Il nuovo punto dati viene assegnato alla categoria con un numero maggiore di vicini.
k = numero di vicini più vicini
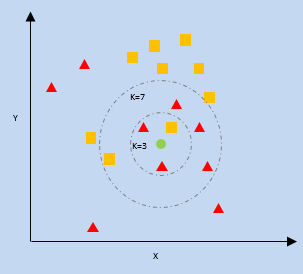
Ingenuo Bayes
Naive Bayes lavora su due pilastri, primo che ogni caratteristica dei punti dati è indipendente, non correlato tra loro, cioè unico, e secondo sul teorema di Bayes che predice i risultati sulla base di una condizione o ipotesi.
Teorema di Bayes:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Dove P(X|Y) = Probabilità condizionata di X data l'occorrenza di Y
P(Y|X) = Probabilità condizionata di Y data l'occorrenza di X
P(X), P(Y) = Probabilità di X e Y singolarmente
Supporta le macchine vettoriali
Questo algoritmo tenta di segregare i dati nello spazio in base a confini che possono essere una linea o un piano. Questo confine è chiamato "iperpiano" ed è definito dai punti dati più vicini di ciascuna classe che a loro volta sono chiamati "vettori di supporto". La distanza massima tra i vettori di supporto di entrambi i lati è chiamata margine.
Reti neurali
Perceptron
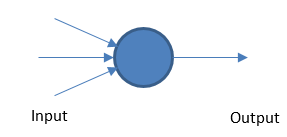
La rete neurale fondamentale funziona prendendo input e output ponderati in base a un valore di soglia.
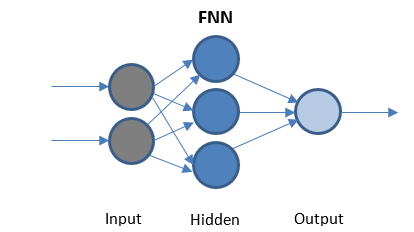
Feed Forward Rete neurale
FFN è la rete più semplice che trasmette dati in una sola direzione. Può avere o meno livelli nascosti.
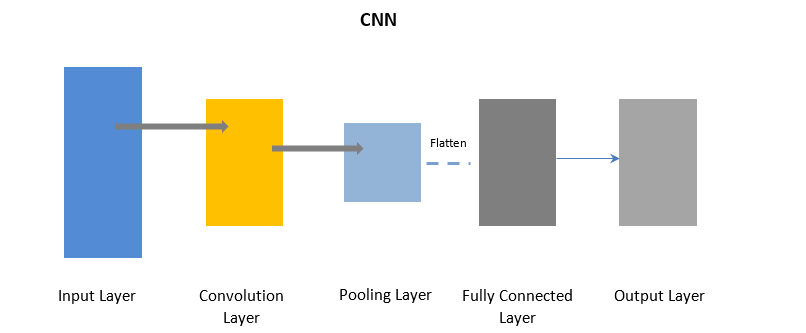
Reti neurali convoluzionali
La CNN utilizza un livello di convoluzione per elaborare alcune parti dei dati di input in batch seguiti da un livello di pooling per completare l'output.
Reti neurali ricorrenti
RNN è costituito da alcuni livelli ricorrenti tra livelli di I/O che possono memorizzare dati "storici". Il flusso di dati è bidirezionale e viene inviato ai livelli ricorrenti per migliorare le previsioni.
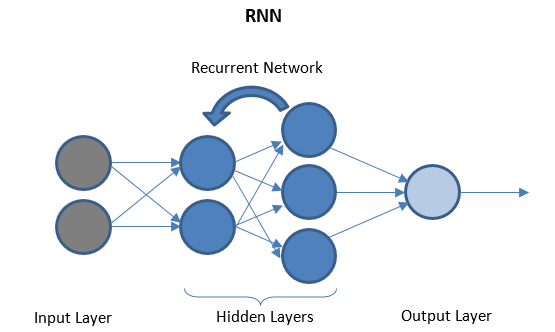
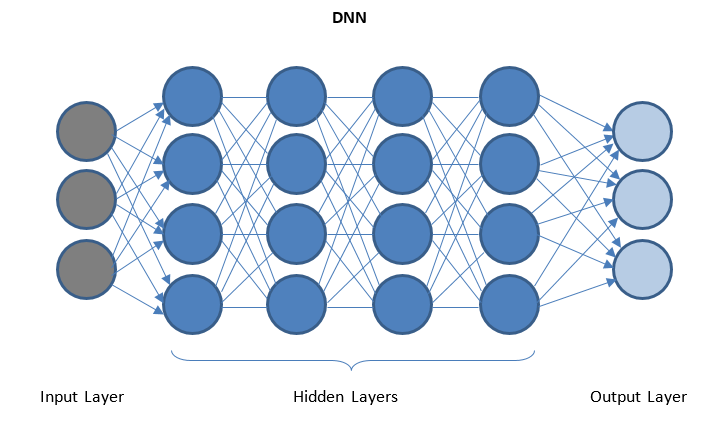
Reti neurali profonde e apprendimento profondo
DNN è una rete con più livelli nascosti tra livelli di I/O. I livelli nascosti applicano trasformazioni successive ai dati prima di inviarli al livello di output.
Il "Deep Learning" è facilitato tramite DNN e può gestire enormi quantità di dati complessi e ottenere un'elevata precisione grazie a più livelli nascosti
Ottieni la certificazione di data science dalle migliori università del mondo. Impara i programmi Executive PG, Advanced Certificate Program o Master per accelerare la tua carriera.
Conclusione
La scienza dei dati è un vasto campo che attraversa diversi flussi ma si presenta come una rivoluzione e una rivelazione per noi. La scienza dei dati è in piena espansione e cambierà il modo in cui i nostri sistemi funzionano e si sentono in futuro.
Se sei curioso di conoscere la scienza dei dati, dai un'occhiata al Diploma PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1- on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Quale linguaggio di programmazione è più adatto per Data Science e perché?
Esistono dozzine di linguaggi di programmazione per la scienza dei dati, ma la maggior parte della comunità della scienza dei dati crede che se vuoi eccellere nella scienza dei dati, Python è la scelta giusta con cui andare. Di seguito sono riportati alcuni dei motivi che supportano questa convinzione:
1. Python ha un'ampia gamma di moduli e librerie come TensorFlow e PyTorch che semplificano la gestione dei concetti di data science.
2. Una vasta comunità di sviluppatori Python aiuta costantemente i neofiti a passare alla fase successiva del loro viaggio nella scienza dei dati.
3. Questa lingua è di gran lunga una delle più comode e facili da scrivere con una sintassi pulita che ne migliora la leggibilità.
Quali sono i concetti che rendono completa la scienza dei dati?
La scienza dei dati è un vasto dominio che funge da ombrello per vari altri domini cruciali. I seguenti sono i concetti più importanti che costituiscono la scienza dei dati:
Statistiche
La statistica è un concetto importante in cui devi eccellere per andare avanti nella scienza dei dati. Ha inoltre alcuni sotto-argomenti:
1. Regressione lineare
2. Probabilità
3. Distribuzione di probabilità
Intelligenza artificiale
La scienza per fornire alle macchine un cervello e consentire loro di prendere le proprie decisioni in base agli input è nota come Intelligenza Artificiale. Macchine reattive, memoria limitata, teoria della mente e consapevolezza di sé sono alcuni dei tipi di intelligenza artificiale.
Apprendimento automatico
L'apprendimento automatico è un altro componente cruciale della scienza dei dati che si occupa delle macchine didattiche per prevedere i risultati futuri sulla base dei dati forniti. L'apprendimento automatico ha tre metodi di modellazione importanti: clustering, regressione e classificazione.
Descrivi i tipi di Machine Learning?
Machine Learning o Simple ML ha tre tipi principali in base ai loro metodi di lavoro. Questi tipi sono i seguenti:
1. Apprendimento supervisionato
Questo è il tipo più primitivo di ML in cui i dati di input sono etichettati. La macchina viene fornita con un set di dati più piccolo che fornisce alla macchina una visione del problema e viene addestrata su di esso.
2. Apprendimento senza supervisione
Il più grande vantaggio di questo tipo è che i dati non sono etichettati qui e il lavoro umano è quasi trascurabile. Ciò apre le porte a set di dati molto più grandi da introdurre nel modello.
3. Apprendimento rinforzato Questo è il tipo più avanzato di ML che si ispira alla vita degli esseri umani. Le uscite desiderate vengono rafforzate mentre le uscite inutili vengono scoraggiate.