
Preelaborazione dei dati in Machine Learning: 7 semplici passaggi da seguire
Pubblicato: 2021-07-15La preelaborazione dei dati in Machine Learning è un passaggio cruciale che aiuta a migliorare la qualità dei dati per promuovere l'estrazione di informazioni significative dai dati. La preelaborazione dei dati in Machine Learning si riferisce alla tecnica di preparazione (pulizia e organizzazione) dei dati grezzi per renderli adatti alla creazione e all'addestramento di modelli di Machine Learning. In parole semplici, la preelaborazione dei dati in Machine Learning è una tecnica di data mining che trasforma i dati grezzi in un formato comprensibile e leggibile.
Sommario
Perché la preelaborazione dei dati nell'apprendimento automatico?
Quando si tratta di creare un modello di Machine Learning, la preelaborazione dei dati è il primo passaggio che segna l'inizio del processo. In genere, i dati del mondo reale sono incompleti, incoerenti, imprecisi (contengono errori o valori anomali) e spesso mancano di valori/trend specifici degli attributi. È qui che entra in gioco la preelaborazione dei dati: aiuta a pulire, formattare e organizzare i dati grezzi, rendendoli così pronti per l'uso per i modelli di Machine Learning. Esaminiamo i vari passaggi della preelaborazione dei dati nell'apprendimento automatico.
Partecipa al corso di intelligenza artificiale online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
Passaggi nella preelaborazione dei dati in Machine Learning
Ci sono sette passaggi significativi nella preelaborazione dei dati in Machine Learning:
1. Acquisire il set di dati
L'acquisizione del set di dati è il primo passaggio nella preelaborazione dei dati nell'apprendimento automatico. Per costruire e sviluppare modelli di Machine Learning, devi prima acquisire il set di dati pertinente. Questo set di dati sarà composto da dati raccolti da fonti multiple e disparate che vengono quindi combinati in un formato appropriato per formare un set di dati. I formati dei set di dati differiscono in base ai casi d'uso. Ad esempio, un set di dati aziendali sarà completamente diverso da un set di dati medici. Mentre un set di dati aziendali conterrà dati rilevanti del settore e aziendali, un set di dati medici includerà dati relativi all'assistenza sanitaria.
Esistono diverse fonti online da cui è possibile scaricare set di dati come https://www.kaggle.com/uciml/datasets e https://archive.ics.uci.edu/ml/index.php . Puoi anche creare un set di dati raccogliendo dati tramite diverse API Python. Una volta che il set di dati è pronto, è necessario inserirlo nei formati di file CSV, HTML o XLSX.

2. Importa tutte le librerie cruciali
Poiché Python è la libreria più utilizzata e anche la più preferita dai data scientist di tutto il mondo, ti mostreremo come importare librerie Python per la preelaborazione dei dati in Machine Learning. Leggi di più sulle librerie Python per Data Science qui. Le librerie Python predefinite possono eseguire specifici lavori di preelaborazione dei dati. L'importazione di tutte le librerie cruciali è il secondo passaggio nella preelaborazione dei dati nell'apprendimento automatico. Le tre librerie Python principali utilizzate per questa preelaborazione dei dati in Machine Learning sono:
- NumPy – NumPy è il pacchetto fondamentale per il calcolo scientifico in Python. Quindi, viene utilizzato per inserire qualsiasi tipo di operazione matematica nel codice. Usando NumPy, puoi anche aggiungere grandi matrici e matrici multidimensionali nel tuo codice.
- Pandas – Pandas è un'eccellente libreria Python open source per la manipolazione e l'analisi dei dati. È ampiamente utilizzato per l'importazione e la gestione dei set di dati. Comprende strutture dati ad alte prestazioni e facili da usare e strumenti di analisi dei dati per Python.
- Matplotlib – Matplotlib è una libreria di plottaggio 2D Python che viene utilizzata per tracciare qualsiasi tipo di grafico in Python. Può fornire dati di qualità di pubblicazione in numerosi formati cartacei e ambienti interattivi su tutte le piattaforme (shell IPython, notebook Jupyter, server di applicazioni Web, ecc.).
Leggi : Idee per progetti di apprendimento automatico per principianti
3. Importare il set di dati
In questo passaggio, devi importare il/i set di dati che hai raccolto per il progetto ML in questione. L'importazione del set di dati è uno dei passaggi importanti nella preelaborazione dei dati nell'apprendimento automatico. Tuttavia, prima di poter importare il/i set di dati, è necessario impostare la directory corrente come directory di lavoro. Puoi impostare la directory di lavoro in Spyder IDE in tre semplici passaggi:
- Salva il tuo file Python nella directory contenente il set di dati.
- Vai all'opzione Esplora file in Spyder IDE e scegli la directory richiesta.
- Ora, fai clic sul pulsante F5 o sull'opzione Esegui per eseguire il file.
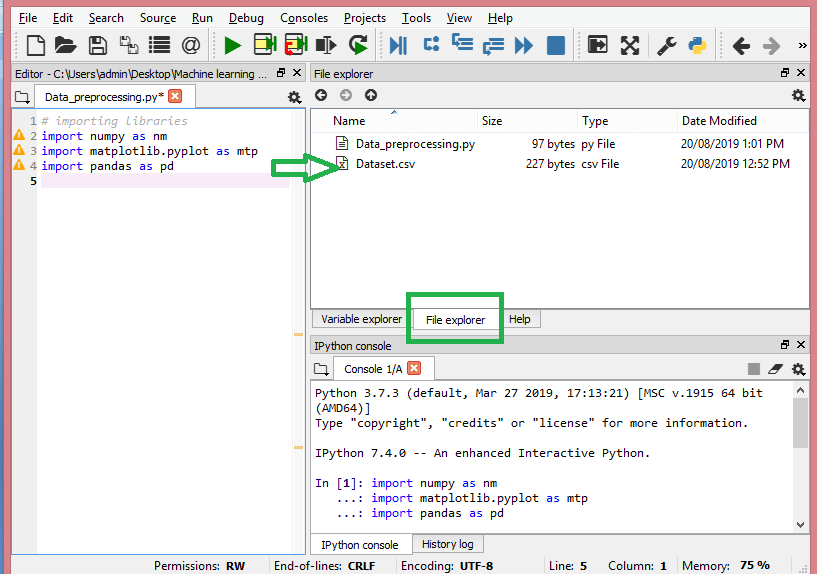
Fonte
Ecco come dovrebbe apparire la directory di lavoro.
Dopo aver impostato la directory di lavoro contenente il set di dati pertinente, puoi importare il set di dati utilizzando la funzione "read_csv()" della libreria Pandas. Questa funzione può leggere un file CSV (in locale o tramite un URL) ed eseguire anche varie operazioni su di esso. read_csv() è scritto come:
data_set= pd.read_csv('Dataset.csv')
In questa riga di codice, "data_set" indica il nome della variabile in cui è stato archiviato il set di dati. La funzione contiene anche il nome del set di dati. Una volta eseguito questo codice, il set di dati verrà importato correttamente.
Durante il processo di importazione del set di dati, c'è un'altra cosa essenziale che devi fare: estrarre le variabili dipendenti e indipendenti. Per ogni modello di Machine Learning, è necessario separare le variabili indipendenti (matrice di funzionalità) e le variabili dipendenti in un set di dati.
Considera questo set di dati:
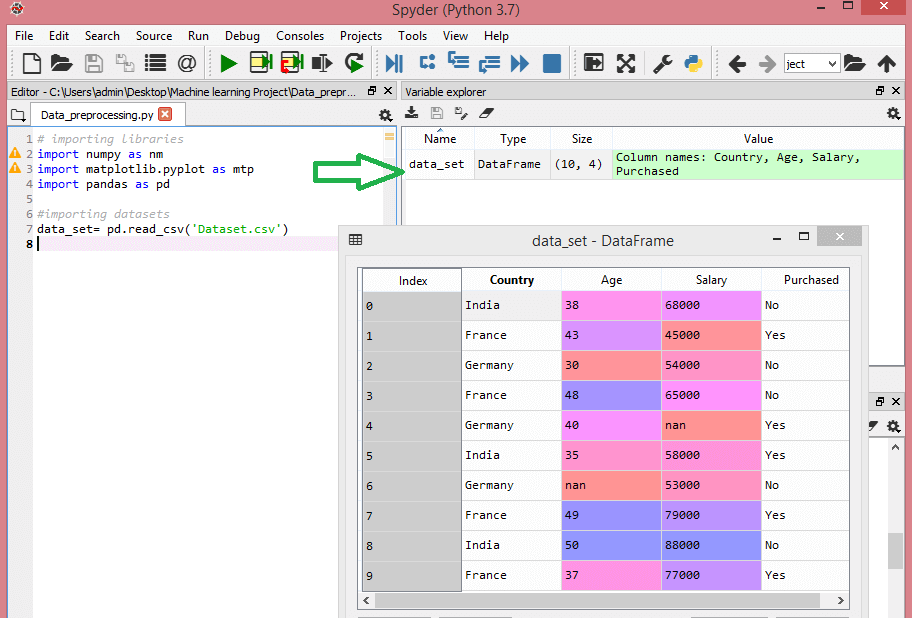
Fonte
Questo set di dati contiene tre variabili indipendenti – paese, età e stipendio e una variabile dipendente – acquistata.
Come estrarre le variabili indipendenti?
Per estrarre le variabili indipendenti, puoi usare la funzione “iloc[ ]” della libreria Pandas. Questa funzione può estrarre righe e colonne selezionate dal set di dati.
x= set_dati.iloc[:,:-1].valori
Nella riga di codice sopra, il primo due punti(:) considera tutte le righe e il secondo due punti(:) considera tutte le colonne. Il codice contiene ":-1" poiché devi omettere l'ultima colonna contenente la variabile dipendente. Eseguendo questo codice, otterrai la matrice delle funzionalità, come questa –
[['India' 38.0 68000.0]
['Francia' 43.0 45000.0]
['Germania' 30.0 54000.0]
['Francia' 48.0 65000.0]
['Germania' 40.0 nan]
['India' 35.0 58000.0]
['Germania' nan 53000.0]
['Francia' 49.0 79000.0]
['India' 50.0 88000.0]
['Francia' 37.0 77000.0]]
Come estrarre la variabile dipendente?
È possibile utilizzare la funzione "iloc[ ]" per estrarre anche la variabile dipendente. Ecco come lo scrivi:
y= data_set.iloc[:,3].valori
Questa riga di codice considera solo tutte le righe con l'ultima colonna. Eseguendo il codice sopra, otterrai l'array di variabili dipendenti, in questo modo:
array(['No', 'Sì', 'No', 'No', 'Sì', 'Sì', 'No', 'Sì', 'No', 'Sì'],
dtipo=oggetto)
4. Identificazione e gestione dei valori mancanti
Nella preelaborazione dei dati, è fondamentale identificare e gestire correttamente i valori mancanti, in caso contrario si potrebbero trarre conclusioni e inferenze imprecise e errate dai dati. Inutile dire che questo ostacolerà il tuo progetto ML.
Fondamentalmente, ci sono due modi per gestire i dati mancanti:
- Eliminazione di una riga particolare : in questo metodo si rimuove una riga specifica che ha un valore Null per una funzionalità o una colonna particolare in cui manca più del 75% dei valori. Tuttavia, questo metodo non è efficiente al 100% e si consiglia di utilizzarlo solo quando il set di dati dispone di campioni adeguati. È necessario assicurarsi che dopo aver eliminato i dati non rimangano aggiunte distorsioni.
- Calcolo della media : questo metodo è utile per le funzioni che hanno dati numerici come età, stipendio, anno, ecc. Qui puoi calcolare la media, la mediana o la modalità di una particolare funzione o colonna o riga che contiene un valore mancante e sostituire il risultato per il valore mancante. Questo metodo può aggiungere varianza al set di dati e qualsiasi perdita di dati può essere annullata in modo efficiente. Quindi, fornisce risultati migliori rispetto al primo metodo (omissione di righe/colonne). Un altro modo di approssimazione è attraverso la deviazione dei valori vicini. Tuttavia, questo funziona meglio per i dati lineari.
Leggi: Applicazioni delle applicazioni di machine learning utilizzando il cloud
5. Codificare i dati categoriali
I dati categoriali si riferiscono alle informazioni che hanno categorie specifiche all'interno del set di dati. Nel set di dati sopra citato, ci sono due variabili categoriali: paese e acquisto.
I modelli di Machine Learning si basano principalmente su equazioni matematiche. Pertanto, puoi capire intuitivamente che mantenere i dati categoriali nell'equazione causerà determinati problemi poiché avresti bisogno solo di numeri nelle equazioni.
Come codificare la variabile paese?
Come visto nel nostro esempio di set di dati, la colonna del paese causerà problemi, quindi devi convertirla in valori numerici. Per fare ciò, puoi usare la classe LabelEncoder() dalla libreria di apprendimento sci-kit. Il codice sarà il seguente:
#Dati categorici
#per la variabile Paese
da sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
E l'output sarà -
Fuori[15]:
matrice([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.1111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=oggetto)
Qui possiamo vedere che la classe LabelEncoder ha codificato con successo le variabili in cifre. Tuttavia, ci sono variabili paese che sono codificate come 0, 1 e 2 nell'output mostrato sopra. Quindi, il modello ML può presumere che ci sia una qualche correlazione tra le tre variabili, producendo così un output errato. Per eliminare questo problema, useremo ora la codifica fittizia.
Le variabili fittizie sono quelle che assumono i valori 0 o 1 per indicare l'assenza o la presenza di uno specifico effetto categoriale che può modificare il risultato. In questo caso il valore 1 indica la presenza di quella variabile in una determinata colonna mentre le altre variabili diventano di valore 0. Nella codifica fittizia, il numero di colonne è uguale al numero di categorie.
Poiché il nostro set di dati ha tre categorie, produrrà tre colonne con i valori 0 e 1. Per la codifica fittizia, utilizzeremo la classe OneHotEncoder della libreria scikit-learn. Il codice di input sarà il seguente –
#per la variabile Paese
da sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])

#Codifica per variabili fittizie
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
All'esecuzione di questo codice, otterrai il seguente output:
matrice([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
Nell'output mostrato sopra, tutte le variabili sono divise in tre colonne e codificate nei valori 0 e 1.
Come codificare la variabile acquistata?
Per la seconda variabile categoriale, ovvero acquistata, è possibile utilizzare l'oggetto “labelencoder” della classe LableEncoder. Non stiamo usando la classe OneHotEncoder poiché la variabile acquistata ha solo due categorie sì o no, entrambe codificate in 0 e 1.
Il codice di input per questa variabile sarà –
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
L'uscita sarà -
Out[17]: array([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Suddivisione del set di dati
La suddivisione del set di dati è il passaggio successivo nella preelaborazione dei dati nell'apprendimento automatico. Ogni set di dati per il modello di Machine Learning deve essere suddiviso in due set separati: set di addestramento e set di test.
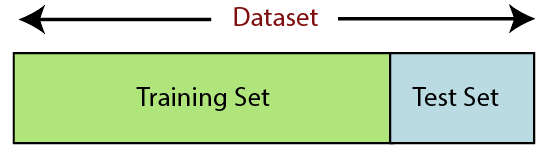
Fonte
Il set di training indica il sottoinsieme di un set di dati utilizzato per il training del modello di machine learning. Qui, sei già a conoscenza dell'output. Un set di test, d'altra parte, è il sottoinsieme del set di dati utilizzato per testare il modello di apprendimento automatico. Il modello ML utilizza il set di test per prevedere i risultati.
Di solito, il set di dati è suddiviso in rapporto 70:30 o rapporto 80:20. Ciò significa che prendi il 70% o l'80% dei dati per il training del modello, tralasciando il resto del 30% o del 20%. Il processo di suddivisione varia in base alla forma e alle dimensioni del set di dati in questione.
Per dividere il set di dati, devi scrivere la seguente riga di codice:
da sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Qui, la prima riga divide gli array del set di dati in treno casuale e sottoinsiemi di test. La seconda riga di codice include quattro variabili:
- x_train – funzionalità per i dati di allenamento
- x_test – funzionalità per i dati di test
- y_train – variabili dipendenti per i dati di addestramento
- y_test – variabile indipendente per testare i dati
Pertanto, la funzione train_test_split() include quattro parametri, i primi due dei quali sono per gli array di dati. La funzione test_size specifica la dimensione del set di test. Il test_size può essere .5, .3 o .2: specifica il rapporto di divisione tra i set di training e di test. L'ultimo parametro, "random_state", imposta il seme per un generatore casuale in modo che l'output sia sempre lo stesso.
7. Ridimensionamento delle funzioni
Il ridimensionamento delle funzionalità segna la fine della preelaborazione dei dati in Machine Learning. È un metodo per standardizzare le variabili indipendenti di un set di dati all'interno di un intervallo specifico. In altre parole, il ridimensionamento delle funzionalità limita l'intervallo di variabili in modo da poterle confrontare su basi comuni.
Considera ad esempio questo set di dati:
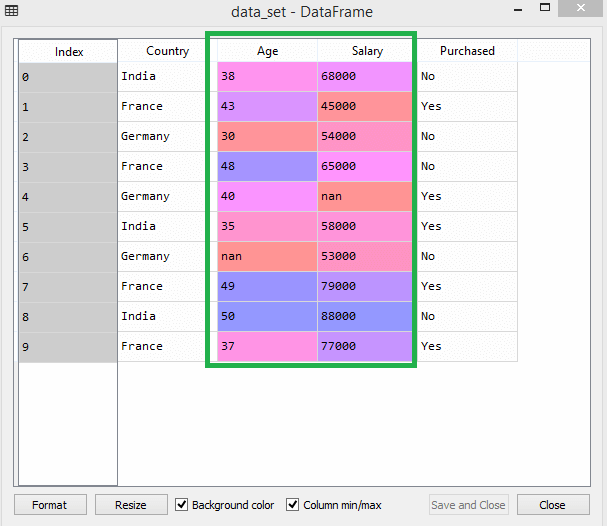
Fonte
Nel set di dati, puoi notare che le colonne età e stipendio non hanno la stessa scala. In uno scenario del genere, se si calcolano due valori qualsiasi dalle colonne età e stipendio, i valori salariali domineranno i valori dell'età e forniranno risultati errati. Pertanto, è necessario rimuovere questo problema eseguendo il ridimensionamento delle funzionalità per Machine Learning.
La maggior parte dei modelli ML si basa sulla distanza euclidea, che è rappresentata come:
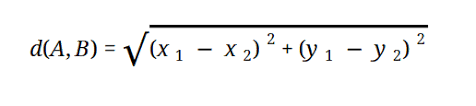
Fonte
Puoi eseguire il ridimensionamento delle funzionalità in Machine Learning in due modi:
Standardizzazione
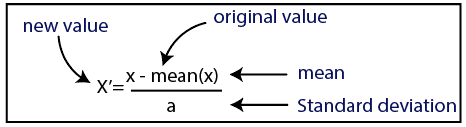
Fonte
Normalizzazione
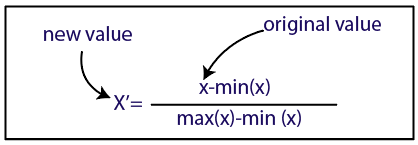
Fonte
Per il nostro set di dati, utilizzeremo il metodo di standardizzazione. Per fare ciò, importeremo la classe StandardScaler della libreria sci-kit-learn utilizzando la seguente riga di codice:
da sklearn.preprocessing import StandardScaler
Il prossimo passo sarà creare l'oggetto della classe StandardScaler per variabili indipendenti. Successivamente, puoi adattare e trasformare il set di dati di addestramento utilizzando il codice seguente:
st_x= StandardScaler()
x_treno= st_x.fit_transform(x_treno)
Per il set di dati di test, puoi applicare direttamente la funzione transform() (non è necessario utilizzare la funzione fit_transform() perché è già stata eseguita nel set di allenamento). Il codice sarà il seguente:
x_test= st_x.transform(x_test)
L'output per il set di dati di test mostrerà i valori in scala per x_train e x_test come:
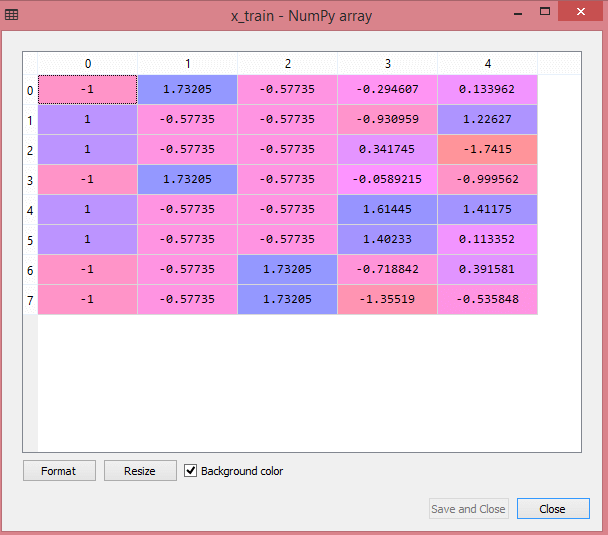
Fonte
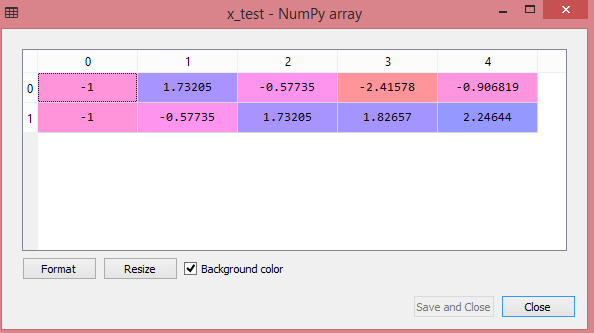
Fonte
Tutte le variabili nell'output vengono ridimensionate tra i valori -1 e 1.
Ora, per combinare tutti i passaggi che abbiamo eseguito finora, ottieni:
# importazione di librerie
importa numpy come nm
importa matplotlib.pyplot come mtp
importa panda come pd
#importazione di set di dati
data_set= pd.read_csv('Dataset.csv')
#Estrazione variabile indipendente
x= set_dati.iloc[:, :-1].valori
#Estrazione variabile dipendente
y= data_set.iloc[:, 3].valori
#handling dei dati mancanti(Sostituzione dei dati mancanti con il valore medio)
da sklearn.preprocessing import Imputer
imputer= Imputer(valori_mancanti ='NaN', strategia='media', asse = 0)
#Fitting oggetto imputatore alle variabili indipendenti x.
imputerimputer= imputer.fit(x[:, 1:3])
#Sostituzione dei dati mancanti con il valore medio calcolato
x[:, 1:3]= imputer.transform(x[:, 1:3])
#per la variabile Paese
da sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Codifica per variabili fittizie
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#codifica per la variabile acquistata
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Suddivisione del set di dati in training e test set.
da sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Feature Scaling dei set di dati
da sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_treno= st_x.fit_transform(x_treno)
x_test= st_x.transform(x_test)
Quindi, in poche parole, questa è l'elaborazione dei dati in Machine Learning!
Puoi controllare il programma Executive PG di IIT Delhi in Machine Learning e AI in associazione con upGrad . IIT Delhi è una delle istituzioni più prestigiose in India. Con più di oltre 500 docenti interni che sono i migliori nelle materie.
Qual è l'importanza della preelaborazione dei dati?
Poiché errori, ridondanze, valori mancanti e incoerenze mettono a rischio l'integrità del set di dati, è necessario risolverli tutti per ottenere un risultato più accurato. Supponi di utilizzare un set di dati difettoso per addestrare un sistema di Machine Learning per gestire gli acquisti dei tuoi clienti. È probabile che il sistema generi distorsioni e deviazioni, causando un'esperienza utente negativa. Di conseguenza, prima di utilizzare tali dati per lo scopo previsto, è necessario che siano organizzati e "puliti" il più possibile. A seconda del tipo di difficoltà che stai affrontando, ci sono numerose opzioni.
Che cos'è la pulizia dei dati?
Quasi sicuramente ci saranno dati mancanti e rumorosi nei tuoi set di dati. Poiché la procedura di raccolta dei dati non è l'ideale, avrai molte informazioni inutili e mancanti. La pulizia dei dati è il modo che dovresti impiegare per affrontare questo problema. Questo può essere diviso in due categorie. Il primo discute come gestire i dati mancanti. Puoi scegliere di ignorare i valori mancanti in questa sezione della raccolta dati (chiamata tupla). Il secondo metodo di pulizia dei dati è per i dati rumorosi. È fondamentale eliminare i dati inutili che non possono essere letti dai sistemi se si desidera che l'intero processo funzioni senza intoppi.
Cosa intendi per trasformazione e riduzione dei dati?
La preelaborazione dei dati passa alla fase di trasformazione dopo aver affrontato i problemi. Lo usi per convertire i dati in conformazioni rilevanti per l'analisi. Normalizzazione, selezione degli attributi, discretizzazione e generazione di gerarchie di concetti sono alcuni degli approcci che possono essere utilizzati per ottenere questo risultato. Anche per i metodi automatizzati, il setacciamento di set di dati di grandi dimensioni può richiedere molto tempo. Ecco perché la fase di riduzione dei dati è così cruciale: riduce le dimensioni dei set di dati limitandoli alle informazioni più importanti, aumentando l'efficienza di archiviazione e riducendo le spese finanziarie e di tempo per lavorare con essi.