
Frame di dati in Python: tutorial approfondito su Python 2022
Pubblicato: 2021-01-09Se sei uno sviluppatore o un programmatore che lavora nel linguaggio di programmazione Python, devi avere familiarità con una delle più straordinarie librerie di gestione dei dati in circolazione: Pandas, una delle migliori librerie Python in circolazione. Nel corso degli anni, Pandas è diventato uno strumento standard per l'analisi e la gestione dei dati tramite Python. Leggi altri importanti strumenti Python.
Pandas è senza dubbio il pacchetto Python più versatile per la scienza dei dati e giustamente. Fornisce strutture dati potenti, espressive e flessibili per una facile manipolazione e analisi dei dati e Data Frames in Python è una di queste strutture.
Questo è esattamente il nostro argomento di discussione in questo post: ti presenteremo il formato dei dati di base per Pandas, ovvero il Pandas Data Frame.
Sommario
Che cos'è un frame di dati?
Secondo la documentazione della libreria Pandas , un Data Frame è una "struttura di dati tabulari bidimensionali, di dimensioni variabili e potenzialmente eterogenea con assi etichettati (righe e colonne)". In parole semplici, un Data Frame è una struttura di dati in cui i dati sono allineati in modo tabulare, cioè in righe e colonne.
Un Data Frame ha solitamente le seguenti caratteristiche:
- Può avere più righe e colonne.
- Mentre ogni riga rappresenta un campione di dati, ogni colonna comprende una variabile diversa che descrive i campioni (righe).
- I dati in ogni colonna sono generalmente dello stesso tipo di dati (ad esempio numeri, stringhe, date, ecc.).
- A differenza dei set di dati di Excel, evita di avere valori mancanti, quindi non ci sono spazi vuoti o valori vuoti tra righe o colonne.
In un Data Frame Pandas, puoi anche specificare l'indice e i nomi delle colonne per il tuo Data Frame. Mentre l'indice indica la differenza nelle righe, i nomi delle colonne mostrano la differenza nelle colonne.
Come creare un frame di dati in Python (usando Pandas)
La creazione di un frame di dati è il primo passo per il data munging in Python. Puoi creare un Data Frame Pandas utilizzando input come:
- dict
- Elenchi
- Serie
- Numpy "ndarray"
- Un altro frame di dati
- File esterni come CS
- Creazione di un frame di dati vuoto
È abbastanza facile creare un frame di dati di base, alias un frame di dati vuoto. Ecco un esempio:
Ingresso –

Produzione -

- Creazione di un frame di dati da elenchi
È possibile creare un Data Frame utilizzando un singolo elenco o più elenchi.
Ingresso –

Produzione -

- Creazione di un frame di dati da Dict di "ndaray" o elenchi
Per creare un Data Frame da un dict di ndarray, tutti i ndarray devono essere della stessa lunghezza. Inoltre, se è indicizzato, la lunghezza dell'indice dovrebbe essere uguale alla lunghezza delle matrici. Tuttavia, se non è indicizzato, l'indice sarà range(n) per impostazione predefinita, dove 'n' indica la lunghezza dell'array.
Ingresso –

Produzione -

Qui i valori 0,1,2,3 sono l'indice predefinito assegnato a ciascuna riga utilizzando la funzione range(n).
Quali sono le operazioni fondamentali sui frame di dati?
Ora che abbiamo visto tre modi per creare frame di dati in Python, è tempo di conoscere le diverse operazioni all'interno di un frame di dati.
- Selezione di un indice o di una colonna da un Pandas Data Frame
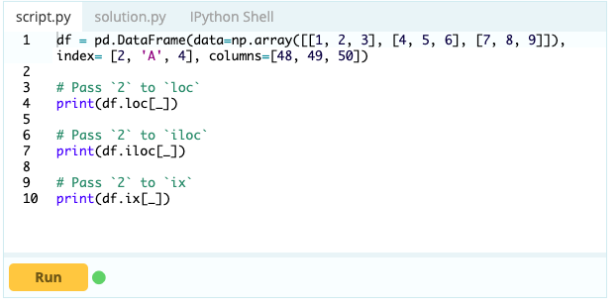
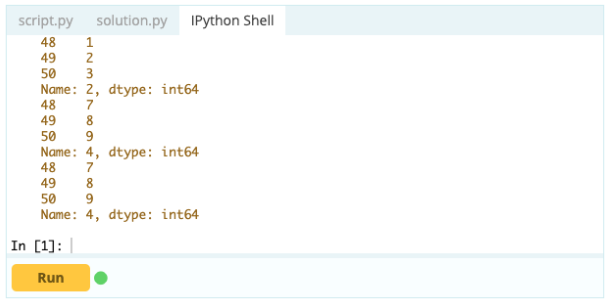
È importante sapere come selezionare un indice o una colonna prima di poter iniziare ad aggiungere, eliminare e rinominare i componenti all'interno di un DataFrame. Supponiamo che questo sia il tuo frame di dati:

Si desidera accedere al valore sotto l'indice 0 nella colonna 'A' – il valore è 1. Esistono molti modi per accedere a questo valore, ma due dei più importanti sono – .loc[] e .iloc[].
Ingresso –
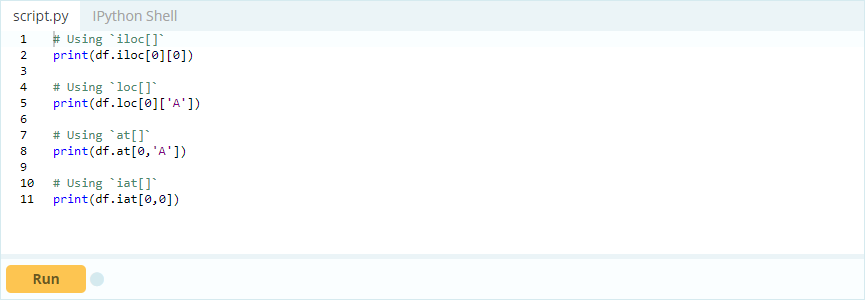
Produzione -
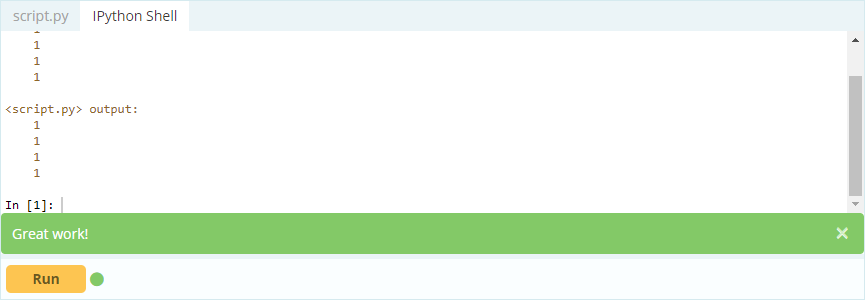
Quindi, come puoi vedere, puoi accedere ai valori chiamandoli tramite la loro etichetta o dichiarando la loro posizione nell'indice o nella colonna. Mentre questo stava selezionando un valore da un frame di dati, come puoi selezionare righe e colonne dallo stesso?
Questo è come:
Ingresso –
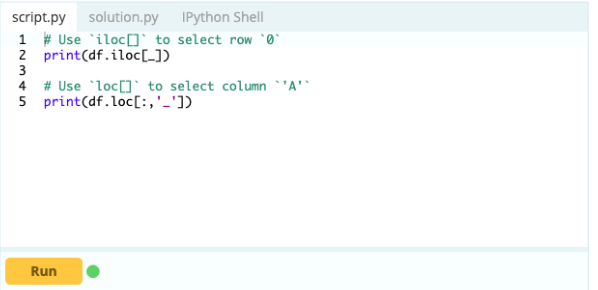
Produzione-
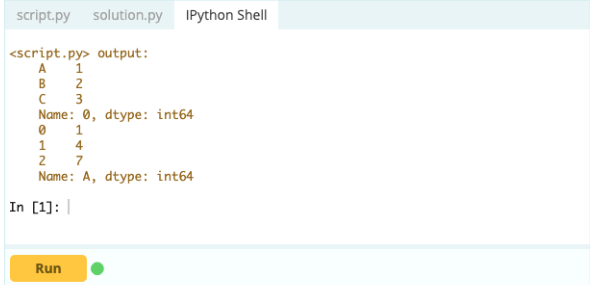
- Come aggiungere un indice, una riga o una colonna a un DataFrame Pandas
Dopo aver appreso come accedere ai valori e selezionare le colonne da un frame di dati, puoi imparare ad aggiungere un indice, una riga o una colonna in un frame di dati Pandas.
Aggiunta di un indice:
Durante la creazione di un frame di dati, puoi scegliere di aggiungere un input all'argomento "indice". Ciò garantisce che tu possa accedere facilmente all'indice che desideri. Se non si specifica l'indice, per impostazione predefinita, verrà aggiunto un indice con valori numerici che inizia con 0 e continua fino all'ultima riga del DataFrame. Sebbene, anche dopo che l'indice è stato specificato per impostazione predefinita, è possibile utilizzare una colonna e convertirla in un indice chiamando la funzione set_index() nel frame di dati.

Aggiunta di una riga:
Puoi aggiungere righe a un DataFrame usando la funzione append.
Ingresso –

Produzione -

Puoi anche usare .loc per inserire righe nel tuo DataFrame in questo modo:
Ingresso –
Produzione -
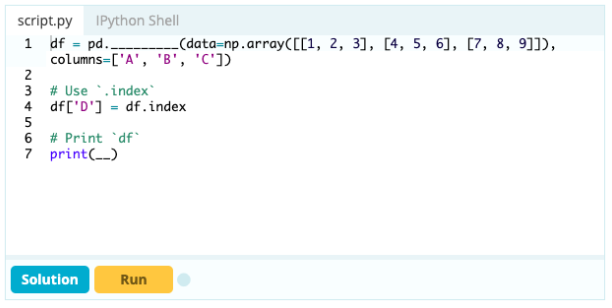
Aggiunta di una colonna
Se vuoi fare di un indice la parte di un Data Frame, puoi prendere una colonna dal Data Frame o fare riferimento a una colonna che non è stata ancora creata e assegnarla alla proprietà .index in questo modo:
Ingresso –
Produzione -
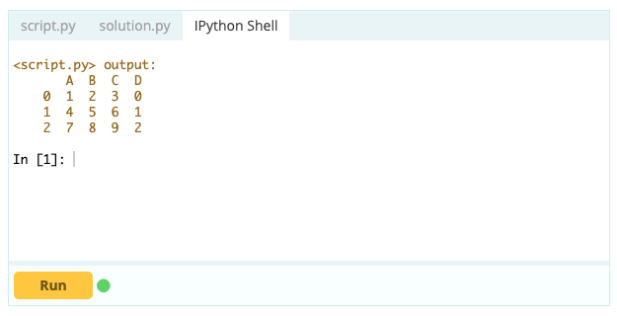
Per aggiungere colonne a un frame di dati, puoi anche utilizzare lo stesso approccio che utilizzeresti per aggiungere un indice al frame di dati, ovvero puoi utilizzare la funzione .loc[ ] o .iloc[ ]. Per esempio:
Ingresso –
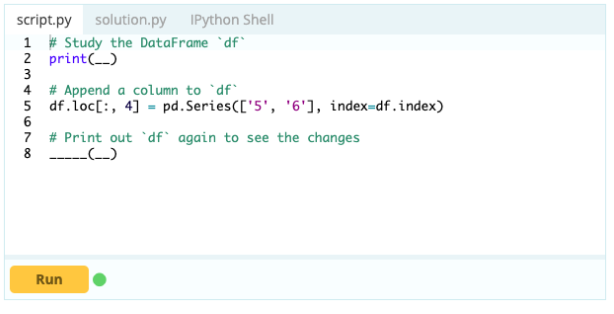
Produzione
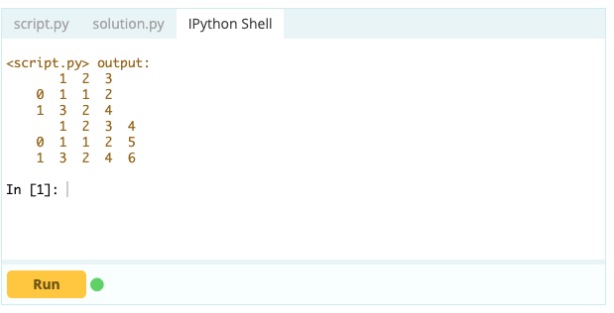
Con .loc[ ], puoi aggiungere una serie a un DataFrame esistente. Poiché un oggetto Series è abbastanza simile a una colonna di un frame di dati, è molto facile aggiungere una serie a un frame di dati esistente.
- Come reimpostare l'indice di un frame di dati?
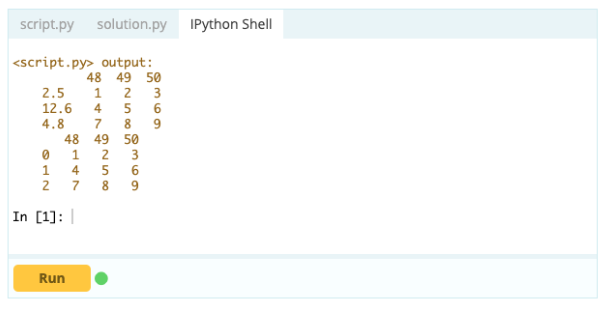
Puoi reimpostare l'indice di un frame di dati se non ha la forma che desideri. È possibile utilizzare la funzione .reset_index() per farlo.
Ingresso –
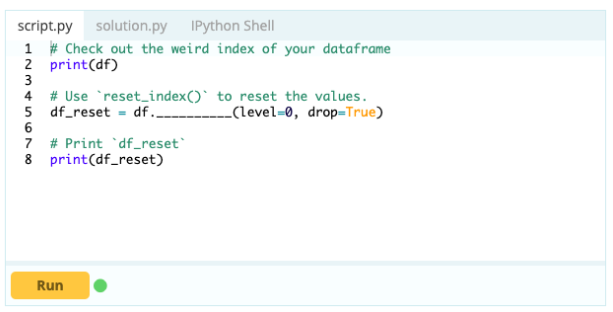
Produzione -
- Come eliminare un indice, una riga o una colonna in un DataFrame Pandas
Eliminazione di un indice
- Ripristino dell'indice del Data Frame.
- Rimuovere il nome dell'indice (se presente) utilizzando la funzione del df.index.name.
- Rimuovere un indice insieme a una riga.
- Rimuovere tutti i valori di indice duplicati reimpostando l'indice, eliminando i duplicati della colonna dell'indice che è stata aggiunta al frame di dati e ripristinando nuovamente la nuova colonna (priva di un indice duplicato) come indice.
Eliminazione di una colonna
Per rimuovere colonne da un frame di dati, puoi utilizzare la funzione drop().
Ingresso –
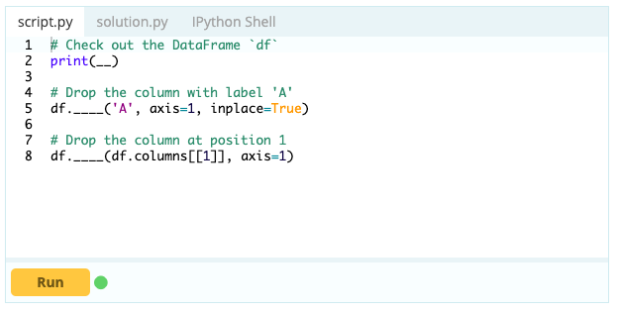
Produzione -
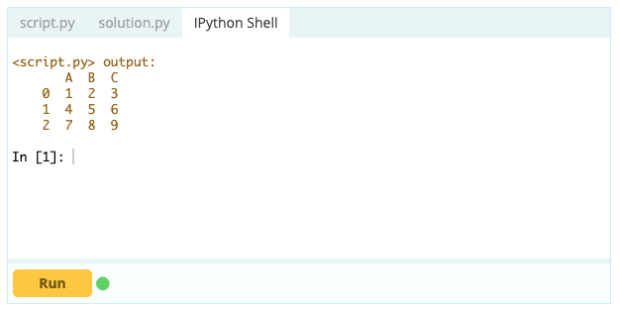
Eliminazione di una riga
Per eliminare una riga da un Data Frame, è possibile utilizzare la funzione drop() utilizzando la proprietà index per specificare l'indice delle righe che si desidera eliminare da DataFrame.
Ingresso –
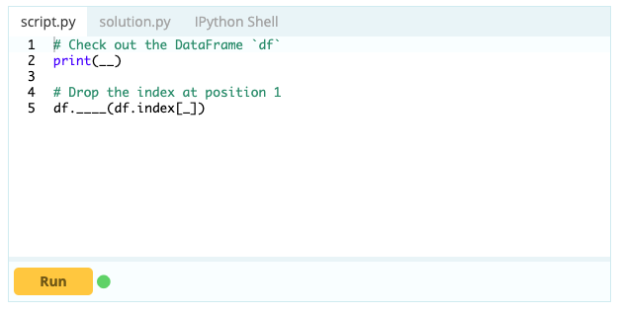
Produzione -
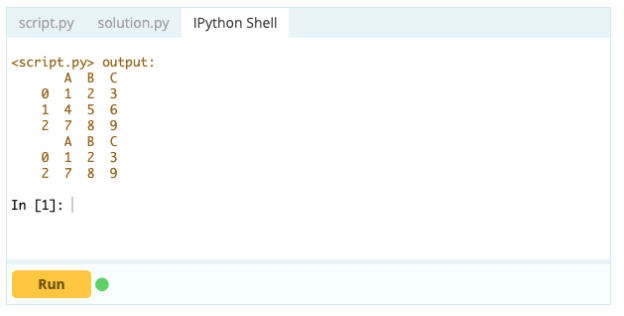
Tuttavia, per eliminare le righe duplicate, puoi utilizzare la funzione df.drop_duplicates().
Ingresso –
Produzione -
Fonti: Tutorialspoint Datacamp
Conclusione
Quindi, c'è il tuo tutorial di base per Data Frame in Python usando Pandas.
Se sei interessato a imparare Python, la scienza dei dati, dai un'occhiata al Diploma PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1 contro 1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Perché Pandas è una delle librerie preferite per creare frame di dati in Python?
La libreria Pandas è considerata la più adatta per la creazione di frame di dati poiché fornisce varie funzionalità che rendono efficiente la creazione di un frame di dati. Alcune di queste funzionalità sono le seguenti: I panda ci forniscono vari frame di dati che non solo consentono una rappresentazione efficiente dei dati, ma ci consentono anche di manipolarli. Fornisce funzionalità di allineamento e indicizzazione efficienti che forniscono metodi intelligenti per etichettare e organizzare i dati. Alcune funzionalità di Panda rendono il codice pulito e ne aumentano la leggibilità, rendendolo così più efficiente. Può anche leggere più formati di file. JSON, CSV, HDF5 ed Excel sono alcuni dei formati di file supportati da Pandas. La fusione di più set di dati è stata una vera sfida per molti programmatori. I panda superano anche questo e uniscono più set di dati in modo molto efficiente.
Quali sono le altre librerie e strumenti che completano la libreria Pandas?
Pandas non funziona solo come libreria centrale per la creazione di frame di dati, ma funziona anche con altre librerie e strumenti di Python per essere più efficiente. Pandas è basato sul pacchetto NumPy Python che indica che la maggior parte della struttura della libreria Pandas viene replicata dal pacchetto NumPy. L'analisi statistica sui dati nella libreria Pandas è gestita da SciPy, tracciando funzioni su Matplotlib e algoritmi di apprendimento automatico in Scikit-learn. Jupyter Notebook è un ambiente interattivo basato sul Web che funziona come IDE e offre un buon ambiente per Panda.
Quali sono le operazioni fondamentali sui frame di dati?
È importante selezionare un indice o una colonna prima di iniziare qualsiasi operazione come l'aggiunta o l'eliminazione. Dopo aver appreso come accedere ai valori e selezionare le colonne da un Data Frame, puoi imparare ad aggiungere un indice, una riga o una colonna in un Pandas Dataframe. Se l'indice nel frame di dati non risulta essere quello desiderato, è possibile reimpostarlo. Per ripristinare l'indice, puoi utilizzare la funzione "reset_index()".