
Creazione di un flusso di lavoro di test di integrazione continua utilizzando le azioni di GitHub
Pubblicato: 2022-03-10Quando si contribuisce a progetti su piattaforme di controllo della versione come GitHub e Bitbucket, la convenzione è che esiste il ramo principale contenente la base di codice funzionale. Poi, ci sono altri rami in cui diversi sviluppatori possono lavorare su copie del main per aggiungere una nuova funzionalità, correggere un bug e così via. Ha molto senso perché diventa più facile monitorare il tipo di effetto che le modifiche in arrivo avranno sul codice esistente. Se c'è qualche errore, può essere facilmente rintracciato e corretto prima di integrare le modifiche nel ramo principale. Può essere dispendioso in termini di tempo esaminare manualmente ogni singola riga di codice alla ricerca di errori o bug, anche per un piccolo progetto. È qui che entra in gioco l'integrazione continua.
Che cos'è l'integrazione continua (CI)?
"L'integrazione continua (CI) è la pratica di automatizzare l'integrazione delle modifiche al codice da più contributori in un unico progetto software."
— Atlassian.com
L'idea generale alla base dell'integrazione continua (CI) è garantire che le modifiche apportate al progetto non "interrompano la build", ovvero rovinino la base di codice esistente. L'implementazione dell'integrazione continua nel tuo progetto, a seconda di come imposti il flusso di lavoro, creerebbe una build ogni volta che qualcuno apporta modifiche al repository.
Allora, cos'è una build?
Una build, in questo contesto, è la compilazione del codice sorgente in un formato eseguibile. Se ha esito positivo, significa che le modifiche in arrivo non avranno un impatto negativo sulla base di codice e sono a posto. Tuttavia, se la compilazione non riesce, le modifiche dovranno essere rivalutate. Ecco perché è consigliabile apportare modifiche a un progetto lavorando su una copia del progetto su un ramo diverso prima di incorporarlo nella base di codice principale. In questo modo, se la build si interrompe, sarebbe più facile capire da dove proviene l'errore e inoltre non influisce sul codice sorgente principale.
"Prima si rilevano i difetti, meno costa risolverli."
— David Farley, Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation
Sono disponibili diversi strumenti per aiutare a creare un'integrazione continua per il tuo progetto. Questi includono Jenkins, TravisCI, CircleCI, GitLab CI, GitHub Actions, ecc. Per questo tutorial, utilizzerò GitHub Actions.
Azioni GitHub per l'integrazione continua
CI Actions è una funzionalità abbastanza nuova su GitHub e consente la creazione di flussi di lavoro che eseguono automaticamente la build e i test del progetto. Un flusso di lavoro contiene uno o più lavori che possono essere attivati quando si verifica un evento. Questo evento potrebbe essere un push a qualsiasi ramo del repository o la creazione di una richiesta pull. Spiegherò questi termini in dettaglio mentre procediamo.
Iniziamo!
Prerequisiti
Questo è un tutorial per principianti, quindi parlerò principalmente di GitHub Actions CI a livello di superficie. I lettori dovrebbero già avere familiarità con la creazione di un'API REST JS Node utilizzando il database PostgreSQL, Sequelize ORM e la scrittura di test con Mocha e Chai.
Dovresti anche avere installato quanto segue sulla tua macchina:
- NodeJS,
- PostgreSQL,
- NPM,
- VSCode (o qualsiasi editor e terminale di tua scelta).
Userò un'API REST che ho già creato chiamata countries-info-api . È una semplice API senza autorizzazioni basate sui ruoli (come al momento della stesura di questo tutorial). Ciò significa che chiunque può aggiungere, eliminare e/o aggiornare i dettagli di un Paese. Ogni paese avrà un ID (UUID generato automaticamente), nome, capitale e popolazione. Per raggiungere questo obiettivo, ho utilizzato Node js, express js framework e Postgresql per il database.
Spiegherò brevemente come ho impostato il server, il database prima di iniziare a scrivere i test per la copertura dei test e il file del flusso di lavoro per l'integrazione continua.
Puoi clonare il repository countries-info-api per seguire o creare la tua API.
Tecnologia utilizzata : Node Js, NPM (un gestore di pacchetti per Javascript), database Postgresql, sequelize ORM, Babel.
Configurazione del server
Prima di configurare il server, ho installato alcune dipendenze da npm.
npm install express dotenv cors npm install --save-dev @babel/core @babel/cli @babel/preset-env nodemonSto usando il framework express e scrivo nel formato ES6, quindi avrò bisogno di Babeljs per compilare il mio codice. Puoi leggere la documentazione ufficiale per saperne di più su come funziona e come configurarlo per il tuo progetto. Nodemon rileverà tutte le modifiche apportate al codice e riavvierà automaticamente il server.
Nota : i pacchetti Npm installati utilizzando il --save-dev sono necessari solo durante le fasi di sviluppo e sono visualizzati in devDependencies nel file package.json .
Ho aggiunto quanto segue al mio file index.js :
import express from "express"; import bodyParser from "body-parser"; import cors from "cors"; import "dotenv/config"; const app = express(); const port = process.env.PORT; app.use(bodyParser.json()); app.use(bodyParser.urlencoded({ extended: true })); app.use(cors()); app.get("/", (req, res) => { res.send({message: "Welcome to the homepage!"}) }) app.listen(port, () => { console.log(`Server is running on ${port}...`) }) Questo imposta la nostra API per l'esecuzione su tutto ciò che è assegnato alla variabile PORT nel file .env . Questo è anche il punto in cui dichiareremo variabili a cui non vogliamo che altri abbiano accesso facilmente. Il pacchetto dotenv npm carica le nostre variabili di ambiente da .env .
Ora quando npm run start nel mio terminale, ottengo questo:
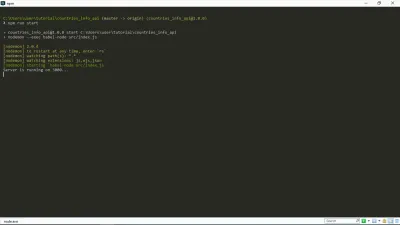
Come puoi vedere, il nostro server è attivo e funzionante. Sìì!
Questo link https://127.0.0.1:your_port_number/ nel tuo browser web dovrebbe restituire il messaggio di benvenuto. Cioè, finché il server è in esecuzione.
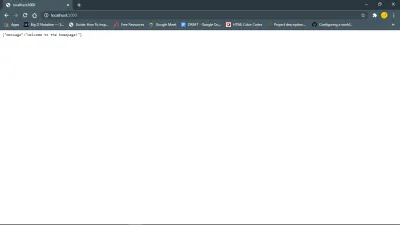
Avanti, database e modelli.
Ho creato il modello paese utilizzando Sequelize e mi sono connesso al mio database Postgres. Sequelize è un ORM per Nodejs. Uno dei principali vantaggi è che ci fa risparmiare tempo per scrivere query SQL grezze.
Poiché stiamo usando Postgresql, il database può essere creato tramite la riga di comando psql usando il comando CREATE DATABASE database_name . Questo può essere fatto anche sul tuo terminale, ma preferisco PSQL Shell.
Nel file env, imposteremo la stringa di connessione del nostro database, seguendo questo formato di seguito.
TEST_DATABASE_URL = postgres://<db_username>:<db_password>@127.0.0.1:5432/<database_name>Per il mio modello, ho seguito questo tutorial di sequela. È facile da seguire e spiega tutto sulla configurazione di Sequelize.
Successivamente, scriverò dei test per il modello che ho appena creato e imposterò la copertura su Coverall.
Scrittura di test e copertura dei rapporti
Perché scrivere dei test? Personalmente, credo che scrivere test ti aiuti come sviluppatore a capire meglio come ci si aspetta che il tuo software funzioni nelle mani del tuo utente perché è un processo di brainstorming. Ti aiuta anche a scoprire i bug in tempo.
Prove:
Esistono diversi metodi di test del software, tuttavia, per questo tutorial, ho utilizzato test unitari e end-to-end.
Ho scritto i miei test utilizzando il framework di test Mocha e la libreria di asserzioni Chai. Ho anche installato sequelize-test-helpers per testare il modello che ho creato usando sequelize.define .
Copertura del test:
È consigliabile controllare la copertura del test perché il risultato mostra se i nostri test case stanno effettivamente coprendo il codice e anche quanto codice viene utilizzato quando eseguiamo i nostri test case.

Ho usato Istanbul (uno strumento di copertura del test), nyc (client CLI di Instabul) e Coveralls.
Secondo i documenti, Istanbul strumenta il tuo codice JavaScript ES5 ed ES2015+ con contatori di riga, in modo da poter monitorare quanto bene i tuoi unit test esercitano la tua base di codice.
Nel mio file package.json , lo script di test esegue i test e genera un report.
{ "scripts": { "test": "nyc --reporter=lcov --reporter=text mocha -r @babel/register ./src/test/index.js" } } Nel processo, creerà una cartella .nyc_output contenente le informazioni grezze sulla copertura e una cartella di coverage contenente i file del rapporto di copertura. Entrambi i file non sono necessari nel mio repository, quindi li ho inseriti nel file .gitignore .
Ora che abbiamo generato un rapporto, dobbiamo inviarlo a Coveralls. Una cosa interessante di Coveralls (e di altri strumenti di copertura, presumo) è il modo in cui riporta la copertura del test. La copertura è suddivisa file per file e puoi vedere la copertura pertinente, le righe coperte e mancate e cosa è cambiato nella copertura della build.
Per iniziare, installa il pacchetto coveralls npm. Devi anche accedere alle tute e aggiungere il repository.
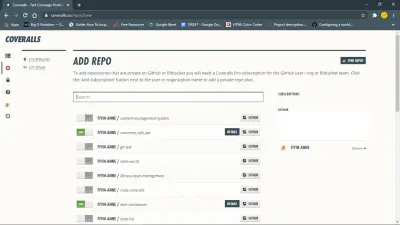
Quindi imposta le tute per il tuo progetto javascript creando un file coveralls.yml nella tua directory principale. Questo file conterrà il tuo repo-token ottenuto dalla sezione delle impostazioni per il tuo repository sulle tute.
Un altro script necessario nel file package.json sono gli script di copertura. Questo script tornerà utile quando creiamo una build tramite Actions.
{ "scripts": { "coverage": "nyc npm run test && nyc report --reporter=text-lcov --reporter=lcov | node ./node_modules/coveralls/bin/coveralls.js --verbose" } }Fondamentalmente, eseguirà i test, riceverà il rapporto e lo invierà alle tute per l'analisi.
Ora al punto principale di questo tutorial.
Crea il file del flusso di lavoro JS del nodo
A questo punto, abbiamo impostato i lavori necessari che eseguiremo nella nostra azione GitHub. (Ti chiedi cosa significano "lavori"? Continua a leggere.)
GitHub ha semplificato la creazione del file del flusso di lavoro fornendo un modello iniziale. Come si vede nella pagina Azioni, sono disponibili diversi modelli di flusso di lavoro con scopi diversi. Per questo tutorial, utilizzeremo il flusso di lavoro Node.js (che GitHub ha già gentilmente suggerito).
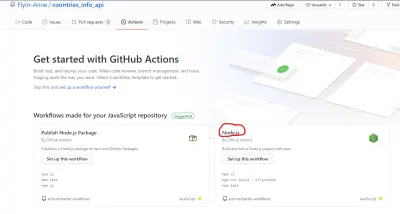
Puoi modificare il file direttamente su GitHub ma creerò manualmente il file sul mio repository locale. La cartella .github/workflows contenente il file node.js.yml sarà nella directory principale.
Questo file contiene già alcuni comandi di base e il primo commento spiega cosa fanno.
# This workflow will do a clean install of node dependencies, build the source code and run tests across different versions of nodeApporterò alcune modifiche in modo che oltre al commento sopra, esegua anche la copertura.
Il mio file .node.js.yml :
name: NodeJS CI on: ["push"] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run coverage - name: Coveralls uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} COVERALLS_GIT_BRANCH: ${{ github.ref }} with: github-token: ${{ secrets.GITHUB_TOKEN }}Cosa significa questo?
Analizziamolo.
-
name
Questo sarebbe il nome del tuo flusso di lavoro (NodeJS CI) o del lavoro (build) e GitHub lo visualizzerà nella pagina delle azioni del tuo repository. -
on
Questo è l'evento che attiva il flusso di lavoro. Quella riga nel mio file sta praticamente dicendo a GitHub di attivare il flusso di lavoro ogni volta che viene effettuato un push al mio repository. -
jobs
Un flusso di lavoro può contenere almeno uno o più lavori e ogni lavoro viene eseguito in un ambiente specificato daruns-on. Nell'esempio di file sopra, c'è solo un lavoro che esegue la build ed esegue anche la copertura, e viene eseguito in un ambiente Windows. Posso anche separarlo in due diversi lavori come questo:
File Node.yml aggiornato
name: NodeJS CI on: [push] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run test coverage: name: Coveralls runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} with: github-token: ${{ secrets.GITHUB_TOKEN }}-
env
Contiene le variabili di ambiente disponibili per tutti o per lavori e passaggi specifici nel flusso di lavoro. Nel lavoro di copertura, puoi vedere che le variabili di ambiente sono state "nascoste". Possono essere trovati nella pagina dei segreti del tuo repository nelle impostazioni. -
steps
Questo è fondamentalmente un elenco dei passaggi da eseguire durante l'esecuzione di quel lavoro. - Il lavoro di
buildfa una serie di cose:- Utilizza un'azione di checkout (v2 indica la versione) che esegue letteralmente il check-out del tuo repository in modo che sia accessibile dal tuo flusso di lavoro;
- Utilizza un'azione del nodo di installazione che configura l'ambiente del nodo da utilizzare;
- Esegue gli script di installazione, compilazione e test che si trovano nel nostro file package.json.
-
coverage
Questo utilizza un'azione coverallsapp che pubblica i dati di copertura LCOV della tua suite di test su coveralls.io per l'analisi.
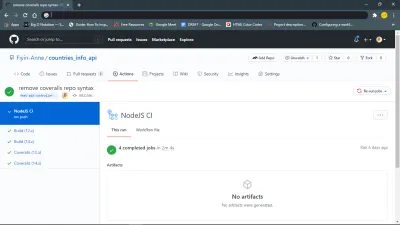
Inizialmente ho fatto un push al mio ramo feat-add-controllers-and-route e ho dimenticato di aggiungere il repo_token da Coveralls al mio file .coveralls.yml , quindi ho ricevuto l'errore che puoi vedere alla riga 132.
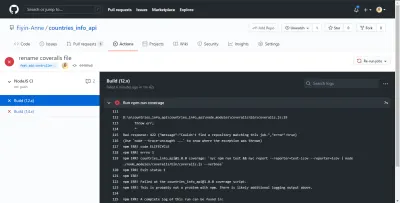
Bad response: 422 {"message":"Couldn't find a repository matching this job.","error":true} Dopo aver aggiunto il repo_token , la mia build è stata in grado di funzionare correttamente. Senza questo token, le tute non sarebbero in grado di riportare correttamente la mia analisi della copertura del test. Meno male che il nostro CI GitHub Actions ha evidenziato l'errore prima che venisse inviato al ramo principale.
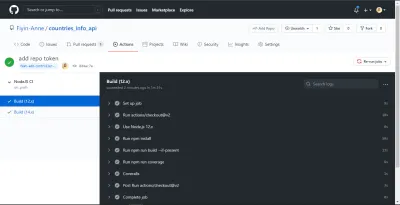
NB: Questi sono stati presi prima che separassi il lavoro in due lavori. Inoltre, sono stato in grado di vedere il riepilogo della copertura e il messaggio di errore sul mio terminale perché ho aggiunto il flag --verbose alla fine del mio script di copertura
Conclusione
Possiamo vedere come impostare l'integrazione continua per i nostri progetti e anche integrare la copertura dei test utilizzando le azioni messe a disposizione da GitHub. Ci sono tanti altri modi in cui questo può essere regolato per adattarsi alle esigenze del tuo progetto. Sebbene il repository di esempio utilizzato in questo tutorial sia un progetto davvero secondario, puoi vedere quanto sia essenziale l'integrazione continua anche in un progetto più grande. Ora che i miei lavori sono stati eseguiti correttamente, sono sicuro di unire il ramo con il mio ramo principale. Ti consiglierei comunque di leggere anche i risultati dei passaggi dopo ogni corsa per vedere che ha completamente successo.