
Aggiunta di funzionalità di suddivisione del codice a un sito Web WordPress tramite PoP
Pubblicato: 2022-03-10La velocità è tra le priorità principali per qualsiasi sito web al giorno d'oggi. Un modo per velocizzare il caricamento di un sito Web è la suddivisione del codice: suddividendo un'applicazione in blocchi che possono essere caricati su richiesta, caricando solo il JavaScript richiesto e nient'altro. I siti Web basati su framework JavaScript possono implementare immediatamente la divisione del codice tramite Webpack, il popolare bundler JavaScript. Per i siti Web WordPress, tuttavia, non è così facile. Innanzitutto, Webpack non è stato creato intenzionalmente per funzionare con WordPress, quindi la configurazione richiederà una soluzione alternativa; in secondo luogo, non sembrano essere disponibili strumenti che forniscano funzionalità native di caricamento delle risorse su richiesta per WordPress.
Data questa mancanza di una soluzione appropriata per WordPress, ho deciso di implementare la mia versione di code-splitting per PoP, un framework open source per la creazione di siti Web WordPress che ho creato. Un sito Web WordPress con PoP installato avrà funzionalità di suddivisione del codice in modo nativo, quindi non dovrà dipendere da Webpack o da qualsiasi altro bundler. In questo articolo, ti mostrerò come è fatto, spiegando quali decisioni sono state prese in base ad aspetti dell'architettura del framework. Alla fine, analizzerò le prestazioni di un sito Web con e senza la divisione del codice e i vantaggi e gli svantaggi dell'utilizzo di un'implementazione personalizzata su un bundler esterno. Spero che ti piaccia il viaggio!
Definire la strategia
La suddivisione del codice può essere sostanzialmente suddivisa in questi due passaggi:
- Calcolare quali asset devono essere caricati per ogni rotta,
- Caricamento dinamico di tali risorse su richiesta.
Per affrontare il primo passaggio, dovremo produrre una mappa delle dipendenze degli asset, che includa tutti gli asset nella nostra applicazione. Le risorse devono essere aggiunte in modo ricorsivo a questa mappa: è necessario aggiungere anche le dipendenze delle dipendenze, finché non sono necessarie altre risorse. Possiamo quindi calcolare tutte le dipendenze richieste per un percorso specifico attraversando la mappa delle dipendenze degli asset, a partire dal punto di ingresso del percorso (cioè il file o la parte di codice da cui inizia l'esecuzione) fino all'ultimo livello.
Per affrontare il secondo passaggio, potremmo calcolare quali risorse sono necessarie per l'URL richiesto sul lato server, quindi inviare l'elenco delle risorse necessarie nella risposta, su cui l'applicazione dovrebbe caricarle, o direttamente HTTP/ 2 spingere le risorse insieme alla risposta.
Queste soluzioni, tuttavia, non sono ottimali. Nel primo caso, l'applicazione deve richiedere tutte le risorse dopo che è stata restituita la risposta, quindi ci sarebbe un'ulteriore serie di richieste di andata e ritorno per recuperare le risorse e la visualizzazione non potrebbe essere generata prima che tutte siano state caricate, risultando in l'utente deve attendere (questo problema è facilitato dal fatto che tutte le risorse siano memorizzate nella cache tramite gli operatori di servizio, quindi i tempi di attesa sono ridotti, ma non possiamo evitare l'analisi delle risorse che avviene solo dopo che la risposta è tornata). Nel secondo caso, potremmo spingere ripetutamente gli stessi asset (a meno che non aggiungiamo qualche logica in più, ad esempio per indicare quali risorse abbiamo già caricato tramite i cookie, ma questo aggiunge effettivamente complessità indesiderata e blocca la risposta nella cache), e noi non può servire le risorse da una CDN.
Per questo motivo, ho deciso di gestire questa logica sul lato client. Un elenco delle risorse necessarie per ciascun percorso viene reso disponibile all'applicazione sul client, in modo che sappia già quali risorse sono necessarie per l'URL richiesto. Questo risolve i problemi sopra indicati:
- Le risorse possono essere caricate immediatamente, senza dover attendere la risposta del server. (Quando lo abbiniamo agli addetti ai servizi, possiamo essere abbastanza sicuri che, quando la risposta tornerà, tutte le risorse saranno state caricate e analizzate, quindi non ci saranno ulteriori tempi di attesa.)
- L'applicazione sa quali asset sono già stati caricati; quindi, non richiederà tutte le risorse necessarie per quel percorso, ma solo quelle che non sono state ancora caricate.
L'aspetto negativo della consegna di questo elenco al front-end è che potrebbe diventare pesante, a seconda delle dimensioni del sito Web (come il numero di percorsi disponibili). Dobbiamo trovare un modo per caricarlo senza aumentare il tempo di caricamento percepito dell'applicazione. Ne parleremo più avanti.
Dopo aver preso queste decisioni, possiamo procedere alla progettazione e quindi implementare la divisione del codice nell'applicazione. Per facilitare la comprensione, il processo è stato suddiviso nei seguenti passaggi:
- Comprendere l'architettura dell'applicazione,
- Mappatura delle dipendenze delle risorse,
- Elenco di tutti i percorsi di applicazione,
- Generando un elenco che definisce quali asset sono richiesti per ogni percorso,
- Caricamento dinamico delle risorse,
- Applicazione di ottimizzazioni.
Entriamo subito!
0. Comprendere l'architettura dell'applicazione
Avremo bisogno di mappare la relazione di tutte le risorse tra loro. Esaminiamo le particolarità dell'architettura di PoP al fine di progettare la soluzione più adatta per raggiungere questo obiettivo.
PoP è un livello che avvolge WordPress, consentendoci di utilizzare WordPress come CMS che alimenta l'applicazione, fornendo tuttavia un framework JavaScript personalizzato per eseguire il rendering dei contenuti sul lato client per creare siti Web dinamici. Ridefinisce le componenti di costruzione della pagina web: mentre WordPress è attualmente basato sul concetto di modelli gerarchici che producono HTML (come single.php , home.php e archive.php ), PoP si basa sul concetto di "moduli, ” che sono una funzionalità atomica o una composizione di altri moduli. Costruire un'applicazione PoP è come giocare con i LEGO : impilare i moduli uno sopra l'altro o avvolgersi l'un l'altro, creando in definitiva una struttura più complessa. Potrebbe anche essere pensato come un'implementazione del progetto atomico di Brad Frost, e si presenta così:
I moduli possono essere raggruppati in entità di ordine superiore, ovvero: blocchi, blockGroups, pageSections e topLevels. Anche queste entità sono moduli, solo con proprietà e responsabilità aggiuntive, e si contengono a vicenda seguendo un'architettura rigorosamente top-down in cui ogni modulo può vedere e modificare le proprietà di tutti i suoi moduli interni. La relazione tra i moduli è questa:
- 1 topLevel contiene N pagineSezioni,
- 1 pageSection contiene N blocchi o blockGroups,
- 1 blockGroup contiene N blocchi o blockGroup,
- 1 blocco contiene N moduli,
- 1 modulo contiene N moduli, all'infinito.
Esecuzione del codice JavaScript in PoP
PoP crea HTML dinamicamente, partendo dal livello di pageSection, scorrendo tutti i moduli lungo la linea, rendendo ciascuno di essi tramite il modello Handlebars predefinito del modulo e, infine, aggiungendo gli elementi appena creati corrispondenti del modulo nel DOM. Fatto ciò, esegue su di essi funzioni JavaScript, che sono predefinite modulo per modulo.
PoP differisce dai framework JavaScript (come React e AngularJS) in quanto il flusso dell'applicazione non ha origine sul client, ma è comunque configurato nel back-end, all'interno della configurazione del modulo (che è codificato in un oggetto PHP). Influenzato dagli action hook di WordPress, PoP implementa un modello di pubblicazione-iscrizione:
- Ogni modulo definisce quali funzioni JavaScript devono essere eseguite sui relativi elementi DOM appena creati, non necessariamente sapendo in anticipo cosa eseguirà questo codice o da dove verrà.
- Gli oggetti JavaScript devono registrare quali funzioni JavaScript implementano.
- Infine, in fase di esecuzione, PoP calcola quali oggetti JavaScript devono eseguire quali funzioni JavaScript e li invoca in modo appropriato.
Ad esempio, tramite il suo oggetto PHP corrispondente, un modulo calendario indica che ha bisogno della funzione calendar per essere eseguita sui suoi elementi DOM in questo modo:
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Quindi, un oggetto JavaScript, in questo caso popFullCalendar , annuncia di aver implementato la funzione calendar . Questo viene fatto chiamando popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); Infine, popJSLibraryManager esegue la corrispondenza su ciò che esegue quale codice. Consente agli oggetti JavaScript di registrare quali funzioni implementano e fornisce un metodo per eseguire una particolare funzione da tutti gli oggetti JavaScript sottoscritti:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } Dopo che un nuovo elemento di calendario è stato aggiunto al DOM, che ha un ID di calendar-293 , PoP eseguirà semplicemente la seguente funzione:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Punto d'entrata
Per PoP, il punto di ingresso per l'esecuzione del codice JavaScript è questa riga alla fine dell'output HTML:
<script type="text/javascript">popManager.init();</script> popManager.init() prima inizializza il framework front-end, quindi esegue le funzioni JavaScript definite da tutti i moduli renderizzati, come spiegato sopra. Di seguito è riportata una forma molto semplice di questa funzione (il codice originale è su GitHub). Richiamando popJSLibraryManager.execute('pageSectionInitialized', pageSection) e popJSLibraryManager.execute('documentInitialized') , tutti gli oggetti JavaScript che implementano tali funzioni ( pageSectionInitialized e documentInitialized ) le eseguiranno.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); La funzione runJSMethods esegue i metodi JavaScript definiti per ogni singolo modulo, a partire da pageSection, che è il modulo più in alto, e poi in basso per tutti i suoi blocchi interni e i loro moduli interni:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);In sintesi, l'esecuzione di JavaScript in PoP è vagamente accoppiata: invece di avere dipendenze fisse, eseguiamo funzioni JavaScript tramite hook a cui qualsiasi oggetto JavaScript può iscriversi.
Pagine Web e API
Un sito Web PoP è un'API autoconsumata. In PoP, non c'è distinzione tra una pagina Web e un'API: ogni URL restituisce la pagina Web per impostazione predefinita e, semplicemente aggiungendo il parametro output=json , restituisce invece la sua API (ad esempio, getpop.org/en/ è un pagina web e getpop.org/en/?output=json è la sua API). L'API viene utilizzata per il rendering dinamico dei contenuti in PoP; quindi, quando si fa clic su un collegamento a un'altra pagina, l'API è ciò che viene richiesto, perché a quel punto verrà caricato il frame del sito Web (come la navigazione superiore e laterale), quindi l'insieme di risorse necessarie per la modalità API sarà essere un sottoinsieme di quello dalla pagina web. Dovremo tenerne conto quando calcoliamo le dipendenze per un percorso: il caricamento del percorso al primo caricamento del sito Web o il caricamento dinamico facendo clic su un collegamento produrrà diversi set di risorse richieste.
Questi sono gli aspetti più importanti del PoP che definiranno la progettazione e l'implementazione del code-splitting. Procediamo con il passaggio successivo.
1. Mappatura delle dipendenze dalle risorse
Potremmo aggiungere un file di configurazione per ogni file JavaScript, specificando le loro dipendenze esplicite. Tuttavia, ciò duplierebbe il codice e sarebbe difficile mantenerlo coerente. Una soluzione più pulita sarebbe quella di mantenere i file JavaScript come unica fonte di verità, estraendo il codice al loro interno e quindi analizzando questo codice per ricreare le dipendenze.
I metadati che stiamo cercando nei file sorgente JavaScript, per poter ricreare la mappatura, sono i seguenti:
- chiamate a metodi interni, come
this.runJSMethods(...); - chiamate a metodi esterni, come
popJSRuntimeManager.getDOMElements(...); - tutte le occorrenze di
popJSLibraryManager.execute(...), che esegue una funzione JavaScript in tutti quegli oggetti che la implementano; - tutte le occorrenze di
popJSLibraryManager.register(...), per ottenere quali oggetti JavaScript implementano quali metodi JavaScript.
Useremo jParser e jTokenizer per tokenizzare i nostri file sorgente JavaScript in PHP ed estrarre i metadati, come segue:
- Le chiamate interne al metodo (come
this.runJSMethods) vengono dedotte quando si trova la sequenza seguente: tokenthisothat+.+ qualche altro token, che è il nome del metodo interno (runJSMethods). - Le chiamate a metodi esterni (come
popJSRuntimeManager.getDOMElements) vengono dedotte quando si trova la seguente sequenza: un token incluso nell'elenco di tutti gli oggetti JavaScript nella nostra applicazione (avremo bisogno di questo elenco in anticipo; in questo caso, conterrà l'oggettopopJSRuntimeManager) +.+ qualche altro token, che è il nome del metodo esterno (getDOMElements). - Ogni volta che troviamo
popJSLibraryManager.execute("someFunctionName")deduciamo il metodo Javascript comesomeFunctionName. - Ogni volta che troviamo
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])deduciamo l'oggetto JavascriptsomeJSObjectper implementare i metodisomeFunctionName1,someFunctionName2.
Ho implementato lo script ma non lo descriverò qui. (È troppo lungo non aggiunge molto valore, ma può essere trovato nel repository di PoP). Lo script, che viene eseguito su richiesta di una pagina interna sul server di sviluppo del sito web (metodologia di cui ho parlato in un precedente articolo sui service worker), genererà il file di mappatura e lo memorizzerà sul server. Ho preparato un esempio del file di mappatura generato. È un semplice file JSON, contenente i seguenti attributi:
-
internalMethodCalls
Per ogni oggetto JavaScript, elenca tra loro le dipendenze dalle funzioni interne. -
externalMethodCalls
Per ogni oggetto JavaScript, elenca le dipendenze dalle funzioni interne alle funzioni di altri oggetti JavaScript. -
publicMethods
Elenca tutti i metodi registrati e, per ciascun metodo, quali oggetti JavaScript lo implementano. -
methodExecutions
Per ogni oggetto JavaScript e ogni funzione interna, elenca tutti i metodi eseguiti tramitepopJSLibraryManager.execute('someMethodName').
Tieni presente che il risultato non è ancora una mappa di dipendenza dalle risorse, ma piuttosto una mappa di dipendenza da oggetti JavaScript. Da questa mappa possiamo stabilire, ogni volta che viene eseguita una funzione da un oggetto, quali altri oggetti saranno richiesti. Dobbiamo ancora configurare quali oggetti JavaScript sono contenuti in ogni asset, per tutti gli asset (nello script jTokenizer, gli oggetti JavaScript sono i token che stiamo cercando per identificare le chiamate esterne al metodo, quindi queste informazioni sono un input per lo script e possono 'non essere ottenuto dai file di origine stessi). Questo viene fatto tramite oggetti PHP ResourceLoaderProcessor , come ResourceLoaderProcessor.php.
Infine, combinando la mappa e la configurazione, saremo in grado di calcolare tutti gli asset necessari per ogni percorso nell'applicazione.
2. Elenco di tutti i percorsi di applicazione
Dobbiamo identificare tutti i percorsi disponibili nella nostra applicazione. Per un sito Web WordPress, questo elenco inizierà con l'URL di ciascuna delle gerarchie di modelli. Quelli implementati per PoP sono questi:
- home page: https://getpop.org/en/
- autore: https://getpop.org/en/u/leo/
- singolo: https://getpop.org/en/blog/new-feature-code-splitting/
- tag: https://getpop.org/en/tags/internet/
- pagina: https://getpop.org/en/filosofia/
- categoria: https://getpop.org/en/blog/ (la categoria è effettivamente implementata come pagina, per rimuovere
category/dal percorso URL) - 404: https://getpop.org/en/questa-pagina-non-esiste/
Per ciascuna di queste gerarchie, dobbiamo ottenere tutti i percorsi che producono una configurazione univoca (cioè che richiederà un insieme univoco di risorse). Nel caso di PoP, abbiamo quanto segue:
- home page e 404 sono unici.
- Le pagine dei tag hanno sempre la stessa configurazione per qualsiasi tag. Pertanto, sarà sufficiente un singolo URL per qualsiasi tag.
- Il singolo post dipende dalla combinazione del tipo di post (come "evento" o "post") e dalla categoria principale del post (come "blog" o "articolo"). Quindi, abbiamo bisogno di un URL per ciascuna di queste combinazioni.
- La configurazione di una pagina di categoria dipende dalla categoria. Quindi, avremo bisogno dell'URL di ogni categoria di post.
- Una pagina dell'autore dipende dal ruolo dell'autore ("individuo", "organizzazione" o "comunità"). Quindi, avremo bisogno di URL per tre autori, ognuno con uno di questi ruoli.
- Ogni pagina può avere una propria configurazione ("accedi", "contattaci", "la nostra missione", ecc.). Pertanto, tutti gli URL delle pagine devono essere aggiunti all'elenco.
Come possiamo vedere, l'elenco è già piuttosto lungo. Inoltre, la nostra applicazione può aggiungere parametri all'URL che modificano la configurazione, modificando potenzialmente anche le risorse necessarie. PoP, ad esempio, offre di aggiungere i seguenti parametri URL:
- tab (
?tab=…), per mostrare un'informazione correlata: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - format (
?format=…), per modificare la modalità di visualizzazione dei dati: https://getpop.org/en/blog/?format=list; - target (
?target=…), per aprire la pagina in una pagina diversaSezione: https://getpop.org/en/add-post/?target=addons.
Alcuni dei percorsi iniziali possono avere uno, due o anche tre dei parametri sopra, creando una vasta gamma di combinazioni:
- singolo post: https://getpop.org/en/blog/new-feature-code-splitting/
- autori del singolo post: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- autori di un singolo post come elenco: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- autori di un singolo post come elenco in una finestra modale: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
In sintesi, per PoP, tutti i percorsi possibili sono una combinazione dei seguenti elementi:
- tutti i percorsi della gerarchia dei modelli iniziali;
- tutti i diversi valori per i quali la gerarchia produrrà una diversa configurazione;
- tutte le schede possibili per ciascuna gerarchia (gerarchie diverse possono avere valori di scheda diversi: un singolo post può avere le schede "autori" e "risposte", mentre un autore può avere le schede "post" e "follower");
- tutti i formati possibili per ciascuna scheda (schede diverse possono essere applicate in formati diversi: la scheda "autori" può avere il formato "mappa", ma la scheda "risposte" potrebbe no);
- tutti i possibili target che indicano la paginaSezioni in cui ogni percorso può essere visualizzato (mentre è possibile creare un post nella sezione principale o in una finestra mobile, la pagina “Condividi con i tuoi amici” può essere impostata per aprirsi in una finestra modale).
Quindi, per un'applicazione leggermente complessa, la produzione dell'elenco con tutti i percorsi non può essere eseguita manualmente. Dobbiamo, quindi, creare uno script per estrarre queste informazioni dal database, manipolarle e, infine, emetterle nel formato necessario. Questo script otterrà tutte le categorie di post, da cui possiamo produrre l'elenco di tutti i diversi URL delle pagine di categoria e quindi, per ciascuna categoria, interrogare il database per qualsiasi post sotto la stessa, che produrrà l'URL per un singolo posta in ogni categoria e così via. Lo script completo è disponibile, a partire dalla function get_resources() , che espone gli hook che devono essere implementati da ciascuno dei casi della gerarchia.
3. Generazione dell'elenco che definisce quali risorse sono necessarie per ciascuna rotta
A questo punto, abbiamo la mappa delle dipendenze degli asset e l'elenco di tutti i percorsi nell'applicazione. È ora il momento di combinare questi due e produrre un elenco che indichi, per ogni rotta, quali asset sono necessari.
Per creare questo elenco, applichiamo la seguente procedura:
- Produci un elenco contenente tutti i metodi JavaScript da eseguire per ogni route:
Calcola i moduli del percorso, quindi ottieni la configurazione per ciascun modulo, quindi estrai dalla configurazione le funzioni JavaScript che il modulo deve eseguire e aggiungile tutte insieme. - Quindi, attraversa la mappa delle dipendenze delle risorse per ciascuna funzione JavaScript, raccogli l'elenco di tutte le sue dipendenze richieste e aggiungile tutte insieme.
- Infine, aggiungi i modelli Handlebars necessari per eseguire il rendering di ogni modulo all'interno di quel percorso.
Inoltre, come affermato in precedenza, ogni URL ha modalità pagina Web e API, quindi è necessario eseguire la procedura sopra due volte, una per ciascuna modalità (ad esempio una volta aggiungendo il parametro output=json all'URL, che rappresenta il percorso per la modalità API, e una volta mantenendo l'URL invariato per la modalità pagina web). Produrremo quindi due liste, che avranno usi diversi:

- L'elenco delle modalità della pagina Web verrà utilizzato durante il caricamento iniziale del sito Web, in modo che gli script corrispondenti per quel percorso siano inclusi nella risposta HTML iniziale. Questo elenco verrà archiviato sul server.
- L'elenco delle modalità API verrà utilizzato durante il caricamento dinamico di una pagina sul sito Web. Questo elenco verrà caricato sul client, per consentire all'applicazione di calcolare quali risorse extra devono essere caricate, su richiesta, quando si fa clic su un collegamento.
La maggior parte della logica è stata implementata a partire dalla function add_resources_from_settingsprocessors($fetching_json, ...) , (la puoi trovare nel repository). Il parametro $fetching_json distingue tra le modalità pagina web ( false ) e API ( true ).
Quando viene eseguito lo script per la modalità pagina Web, verrà generato l'output di resourceloader-bundle-mapping.json, che è un oggetto JSON con le seguenti proprietà:
-
bundle-ids
Questa è una raccolta di un massimo di quattro risorse (i loro nomi sono stati alterati per l'ambiente di produzione:eq=>handlebars,er=>handlebars-helpers, ecc.), raggruppate sotto un ID bundle. -
bundlegroup-ids
Questa è una raccolta dibundle-ids. Ogni bundleGroup rappresenta un insieme unico di risorse. -
key-ids
Questa è la mappatura tra le rotte (rappresentate dal loro hash, che identifica l'insieme di tutti gli attributi che rendono unica una rotta) e il corrispondente bundleGroup.
Come si può osservare, la mappatura tra un percorso e le sue risorse non è lineare. Invece di mappare key-ids a un elenco di risorse, li mappa a un bundleGroup univoco, che è esso stesso un elenco di bundles e solo ogni bundle è un elenco di resources (fino a quattro elementi per bundle). Perché è stato fatto così? Questo serve a due scopi:
- Ci consente di identificare tutte le risorse in un bundleGroup univoco. Pertanto, invece di includere tutte le risorse nella risposta HTML, siamo in grado di includere un asset JavaScript univoco, che è invece il file bundleGroup corrispondente, che raggruppa tutte le risorse corrispondenti. Questo è utile quando servono dispositivi che ancora non supportano HTTP/2 e aumenterà anche il tempo di caricamento, perché Gzip'ing un singolo file in bundle è più efficace che comprimere i suoi file costitutivi da soli e poi sommarli insieme. In alternativa, potremmo anche caricare una serie di bundle invece di un bundleGroup univoco, che è un compromesso tra risorse e bundleGroup (il caricamento dei bundle è più lento di bundleGroups a causa di Gzip'ing, ma è più performante se l'invalidazione si verifica spesso, in modo da scaricherebbe solo il bundle aggiornato e non l'intero bundleGroup). Gli script per raggruppare tutte le risorse in bundle e bundleGroup si trovano in filegenerator-bundles.php e filegenerator-bundlegroups.php.
- La divisione degli insiemi di risorse in bundle ci consente di identificare schemi comuni (ad esempio, identificare insiemi di quattro risorse condivise tra molti percorsi), consentendo di conseguenza che percorsi diversi si colleghino allo stesso bundle. Di conseguenza, l'elenco generato avrà una dimensione inferiore. Questo potrebbe non essere di grande utilità per l'elenco delle pagine Web, che risiede sul server, ma è ottimo per l'elenco delle API, che verrà caricato sul client, come vedremo in seguito.
Quando viene eseguito lo script per la modalità API, verrà generato il file resources.js, con le seguenti proprietà:
-
bundlesebundle-groupslo stesso scopo indicato per la modalità pagina web - le
keyshanno anche lo stesso scopokey-idsper la modalità pagina web. Tuttavia, invece di avere un hash come chiave per rappresentare la rotta, è una concatenazione di tutti quegli attributi che rendono unica una rotta: nel nostro caso, format (f), tab (t) e target (r). -
sourcesè il file di origine per ciascuna risorsa. -
typesè il CSS o JavaScript per ciascuna risorsa (anche se, per semplicità, non abbiamo trattato in questo articolo che le risorse JavaScript possono anche impostare risorse CSS come dipendenze e che i moduli possono caricare le proprie risorse CSS, implementando la strategia di caricamento CSS progressivo ). -
resourcesacquisisce quali bundleGroup devono essere caricati per ciascuna gerarchia. -
ordered-load-resourcescontiene quali risorse devono essere caricate in ordine, per evitare che gli script vengano caricati prima dei loro script dipendenti (per impostazione predefinita, sono asincroni).
Esploreremo come utilizzare questo file nella prossima sezione.
4. Caricamento dinamico degli asset
Come affermato, l'elenco delle API verrà caricato sul client, in modo che possiamo iniziare a caricare le risorse richieste per un percorso immediatamente dopo che l'utente ha fatto clic su un collegamento.
Caricamento dello script di mappatura
Il file JavaScript generato con l'elenco delle risorse per tutti i percorsi nell'applicazione non è leggero: in questo caso è arrivato a 85 KB (che è esso stesso ottimizzato, avendo alterato i nomi delle risorse e prodotto bundle per identificare schemi comuni tra i percorsi) . Il tempo di analisi non dovrebbe essere un grosso collo di bottiglia, perché l'analisi di JSON è 10 volte più veloce dell'analisi di JavaScript per gli stessi dati. Tuttavia, la dimensione è un problema dovuto al trasferimento di rete, quindi dobbiamo caricare questo script in un modo che non influisca sul tempo di caricamento percepito dell'applicazione o faccia aspettare l'utente.
La soluzione che ho implementato è di precachere questo file utilizzando i service worker, caricarlo usando il defer in modo che non blocchi il thread principale durante l'esecuzione dei metodi JavaScript critici e quindi mostrare un messaggio di notifica di fallback se l'utente fa clic su un collegamento prima che lo script sia stato caricato: "Il sito Web è ancora in fase di caricamento, attendere qualche istante per fare clic sui collegamenti". Ciò si ottiene aggiungendo un div fisso con una classe di loadingscreen posizionato sopra tutto mentre gli script vengono caricati, quindi aggiungendo il messaggio di notifica, con una classe di notificationmsg , all'interno del div, e queste poche righe di CSS:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }Un'altra soluzione è dividere questo file in più file e caricarli progressivamente secondo necessità (una strategia che ho già codificato). Inoltre, il file da 85 KB include tutti i percorsi possibili nell'applicazione, inclusi percorsi come "gli annunci dell'autore, mostrati in miniature, visualizzati nella finestra modale", a cui è possibile accedere una volta in una luna blu, se non del tutto. I percorsi a cui si accede per la maggior parte sono a malapena pochi (home page, singolo, autore, tag e tutte le pagine, tutte senza attributi extra), che dovrebbero produrre un file molto più piccolo, nell'intorno di 30 KB.
Ottenere il percorso dall'URL richiesto
Dobbiamo essere in grado di identificare il percorso dall'URL richiesto. Per esempio:
-
https://getpop.org/en/u/leo/mappe del percorso “autore”, -
https://getpop.org/en/u/leo/?tab=followersmappe del percorso “seguaci dell'autore”, -
https://getpop.org/en/tags/internet/mappe del percorso “tag”, -
https://getpop.org/en/tags/mappe del percorso “pagina/tags/”, - e così via.
Per fare ciò, dovremo valutare l'URL e dedurne gli elementi che rendono unico un percorso: la gerarchia e tutti gli attributi (formato, scheda e destinazione). Identificare gli attributi non è un problema, perché quelli sono parametri nell'URL. L'unica sfida è dedurre la gerarchia (home, autore, singolo, pagina o tag) dall'URL, facendo corrispondere l'URL a diversi modelli. Per esempio,
- Tutto ciò che inizia con
https://getpop.org/en/u/è un autore. - Tutto ciò che inizia con ma non è esattamente
https://getpop.org/en/tags/è un tag. Se è esattamentehttps://getpop.org/en/tags/, allora è una pagina. - E così via.
La funzione seguente, implementata a partire dalla riga 321 di Resourceloader.js, deve essere alimentata con una configurazione con i pattern per tutte queste gerarchie. Per prima cosa controlla se non è presente alcun sottopercorso nell'URL, nel qual caso è "home". Quindi, controlla uno per uno per far corrispondere le gerarchie per "autore", "tag" e "singolo". Se non riesce con nessuno di questi, allora è il caso predefinito, che è "pagina":
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Poiché tutti i dati richiesti sono già nel database (tutte le categorie, tutti gli slug di pagina, ecc.), eseguiremo uno script per creare automaticamente questo file di configurazione in un ambiente di sviluppo o staging. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
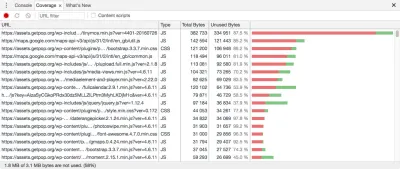
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
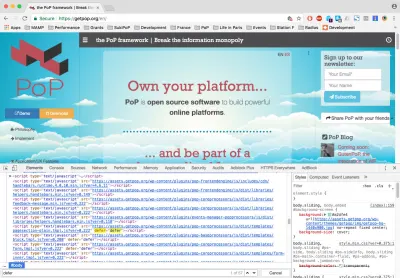
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
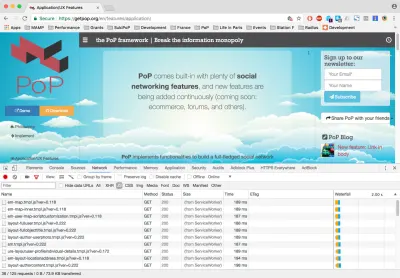
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Svantaggi
- Dobbiamo mantenerlo.
Se utilizzassimo solo Webpack, potremmo fare affidamento sulla sua comunità per mantenere aggiornato il software e potremmo trarre vantaggio dal suo ecosistema di plugin. - Gli script richiedono tempo per essere eseguiti.
Il sito web PoP Agenda Urbana ha 304 percorsi diversi, dai quali produce 422 set di risorse uniche. Per questo sito Web, l'esecuzione dello script che genera la mappa di dipendenza delle risorse, utilizzando un MacBook Pro del 2012, richiede circa 8 minuti, mentre l'esecuzione dello script che genera gli elenchi con tutte le risorse e crea i file bundle e bundleGroup richiede 15 minuti . È più che sufficiente per andare a prendere un caffè! - Richiede un ambiente di allestimento.
Se dobbiamo attendere circa 25 minuti per eseguire gli script, non possiamo eseguirlo in produzione. Avremmo bisogno di un ambiente di staging con esattamente la stessa configurazione del sistema di produzione. - Viene aggiunto un codice extra al sito web, solo per la gestione.
Gli 85 KB di codice non sono funzionali di per sé, ma semplicemente codice per gestire altro codice. - Si aggiunge la complessità.
Ciò è inevitabile in ogni caso se vogliamo dividere i nostri beni in unità più piccole. Webpack aggiungerebbe anche complessità all'applicazione.
Vantaggi
- Funziona con WordPress.
Webpack non funziona con WordPress pronto all'uso e per farlo funzionare è necessaria una soluzione alternativa. Questa soluzione funziona immediatamente per WordPress (purché PoP sia installato). - È scalabile ed estensibile.
Le dimensioni e la complessità dell'applicazione possono crescere senza limiti, poiché i file JavaScript vengono caricati su richiesta. - Supporta Gutenberg (aka il WordPress di domani).
Poiché ci consente di caricare framework JavaScript su richiesta, supporterà i blocchi di Gutenberg (chiamati Gutenblocks), che dovrebbero essere codificati nel framework scelto dallo sviluppatore, con il potenziale risultato di diversi framework necessari per la stessa applicazione. - È conveniente.
Lo strumento di compilazione si occupa della generazione dei file di configurazione. A parte l'attesa, non è necessario alcuno sforzo extra da parte nostra. - Semplifica l'ottimizzazione.
Attualmente, se un plug-in di WordPress desidera caricare in modo selettivo risorse JavaScript, utilizzerà molti condizionali per verificare se l'ID pagina è quello giusto. Con questo strumento, non ce n'è bisogno; il processo è automatico. - L'applicazione verrà caricata più rapidamente.
Questo è stato l'intero motivo per cui abbiamo codificato questo strumento. - Richiede un ambiente di allestimento.
Un effetto collaterale positivo è una maggiore affidabilità: non eseguiremo gli script in produzione, quindi non romperemo nulla lì; il processo di distribuzione non fallirà a causa di comportamenti imprevisti; e lo sviluppatore sarà costretto a testare l'applicazione utilizzando la stessa configurazione della produzione. - È personalizzato per la nostra applicazione.
Non ci sono spese generali o soluzioni alternative. Quello che otteniamo è esattamente ciò di cui abbiamo bisogno, in base all'architettura con cui stiamo lavorando.
In conclusione: sì, ne vale la pena, perché ora siamo in grado di applicare le risorse di caricamento su richiesta sul nostro sito Web WordPress e farlo caricare più velocemente.
Ulteriori risorse
- Webpack, inclusa la guida ""Separazione del codice".
- "Migliori Webpack Builds" (video), K. Adam White
Integrazione di Webpack con WordPress - "Gutenberg e il WordPress di domani", Morten Rand-Hendriksen, WP Tavern
- "WordPress esplora un approccio indipendente dal framework JavaScript per costruire blocchi di Gutenberg", Sarah Gooding, WP Tavern