
CNN vs RNN: differenza tra CNN e RNN
Pubblicato: 2021-02-25Sommario
introduzione
Nel campo dell'intelligenza artificiale, le reti neurali ispirate al cervello umano sono ampiamente utilizzate per estrarre ed elaborare informazioni complesse da vari dati e l'uso sia delle reti neurali convoluzionali (CNN) che delle reti neurali ricorrenti (RNN) in tali applicazioni si stanno rivelando utili.
In questo articolo, comprenderemo i concetti alla base delle reti neurali convoluzionali e delle reti neurali ricorrenti, vedremo le loro applicazioni e distingueremo le differenze tra i due tipi popolari di reti neurali.
Impara la formazione sull'apprendimento automatico dalle migliori università del mondo. Guadagna master, Executive PGP o programmi di certificazione avanzati per accelerare la tua carriera.
Reti neurali e deep learning
Prima di entrare nei concetti di Reti Neurali Convoluzionali e Reti Neurali Ricorrenti, cerchiamo di capire i concetti alla base delle Reti Neurali e come è collegato al Deep Learning.
Negli ultimi tempi, il Deep Learning è un concetto ampiamente utilizzato in molti campi e quindi è un argomento caldo in questi giorni. Ma qual è il motivo per cui se ne parla così tanto? Per rispondere a questa domanda, impareremo a conoscere il concetto di Reti Neurali.
In breve, le reti neurali sono la spina dorsale del Deep Learning. Sono un determinato numero di strati costituiti da elementi altamente interconnessi noti come neuroni che eseguono una serie di trasformazioni sui dati che generano la propria comprensione di quei dati a cui ci riferiamo con il termine di caratteristiche.

Cosa sono le reti neurali?
Il primo concetto che dobbiamo affrontare è quello delle Reti Neurali. Sappiamo che il Cervello Umano è una delle strutture complesse che sia mai stata studiata. A causa della sua complessità, c'è stata un'enorme difficoltà nello svelare i suoi meccanismi interni, ma al momento sono in corso diversi tipi di ricerca per svelarne i segreti. Questo cervello umano funge da ispirazione dietro i modelli di rete neurale.
Per definizione, le reti neurali sono le unità funzionali del Deep Learning che utilizza queste reti neurali per imitare l'attività cerebrale e risolvere problemi complessi. Quando i dati di input vengono inviati alla rete neurale, vengono elaborati attraverso gli strati del perceptron e infine fornisce l'output.
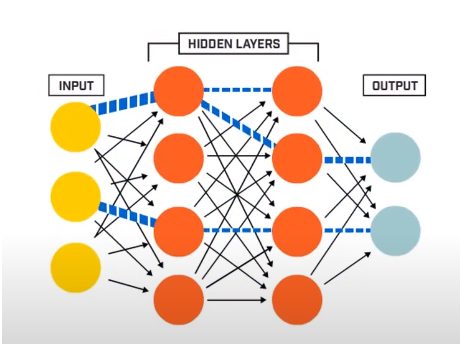
Una rete neurale consiste fondamentalmente di 3 strati:
- Livello di input
- Strati nascosti
- Livello di uscita
Lo strato di input legge i dati di input che vengono immessi nel sistema della rete neurale per un'ulteriore pre-elaborazione da parte degli strati successivi di neuroni artificiali. Tutti i livelli che esistono tra il livello di input e il livello di output sono definiti livelli nascosti.
È in questi strati nascosti che i neuroni presenti in essi fanno uso di input e bias ponderati e producono un output utilizzando le funzioni di attivazione. Il livello di output è l'ultimo livello di neuroni che ci fornisce l'output per il programma specificato.
Fonte
Come funzionano le reti neurali?
Ora che abbiamo un'idea della struttura di base delle Reti Neurali, andremo avanti e capiremo come funzionano. Per comprenderne il funzionamento, dobbiamo prima conoscere una delle strutture di base delle Reti Neurali, nota come Perceptron.
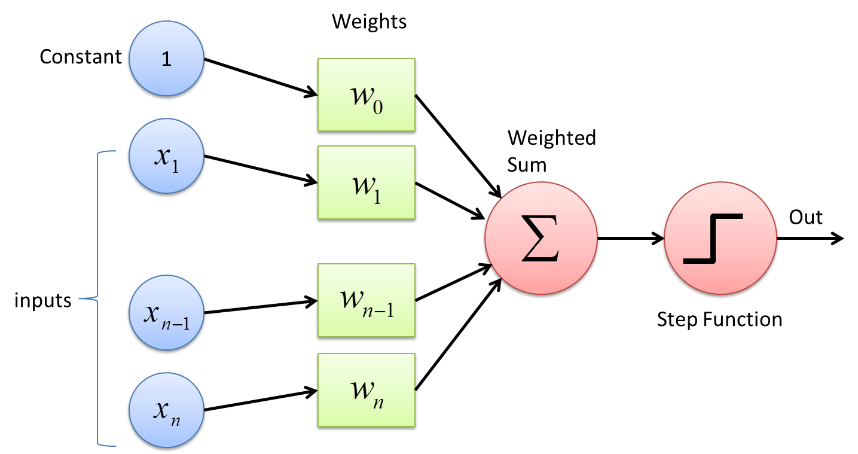
Perceptron è un tipo di rete neurale che ha la forma più elementare. È una semplice rete neurale artificiale feed-forward con un solo livello nascosto. Nella rete Perceptron, ogni neurone è connesso a ogni altro neurone nella direzione in avanti.
Le connessioni tra questi neuroni sono ponderate per cui l'informazione che viene trasferita tra i due neuroni viene rafforzata o attenuata da questi pesi. Nel processo di addestramento delle reti neurali, sono questi pesi che vengono regolati per ottenere il valore corretto.
Il Perceptron utilizza una funzione di classificazione binaria in cui mappa un vettore di variabili di natura binaria su un singolo output binario. Questo può essere utilizzato anche nell'apprendimento supervisionato. I passaggi dell'algoritmo di apprendimento Perceptron sono:
- Moltiplica tutti gli input con i loro pesi w, dove w sono numeri reali che possono essere inizialmente fissi o randomizzati.
- Sommare il prodotto per ottenere la somma pesata, ∑ wj xj
- Una volta ottenuta la somma ponderata degli input, viene applicata la Funzione di Attivazione per determinare se la somma pesata è maggiore di un determinato valore di soglia o meno a seconda della funzione di attivazione applicata. L'uscita viene assegnata come 1 o 0 a seconda della condizione di soglia. Qui il valore “-soglia” si riferisce anche al termine bias, b.
In questo modo, l'algoritmo Perceptron Learning può essere utilizzato per attivare (valore =1) i neuroni presenti nelle Reti Neurali che oggi vengono progettate e sviluppate. Un'altra rappresentazione dell'algoritmo di apprendimento Perceptron è:
f(x) = 1, se ∑ wj xj + b ≥ 0
0, se ∑ wj xj + b < 0
Sebbene i Perceptron non siano ampiamente utilizzati al giorno d'oggi, rimane ancora uno dei concetti chiave nelle reti neurali. In ulteriori ricerche, si è capito che piccoli cambiamenti nei pesi o nella distorsione anche in un percettrone potevano cambiare notevolmente l'output da 1 a 0 o viceversa. Questo era uno dei principali svantaggi del Perceptron. Quindi, sono state sviluppate funzioni di attivazione più complesse come la ReLU, le funzioni Sigmoid che introducono solo cambiamenti moderati nei pesi e nella distorsione dei neuroni artificiali.
Fonte
Reti neurali convoluzionali
Una rete neurale convoluzionale è un algoritmo di apprendimento profondo che prende un'immagine come input, assegna vari pesi e pregiudizi a varie parti dell'immagine in modo che siano differenziabili l'una dall'altra. Una volta che sono diventati differenziabili, utilizzando varie funzioni di attivazione, il modello di rete neurale convoluzionale può eseguire diverse attività nel dominio dell'elaborazione delle immagini tra cui il riconoscimento delle immagini, la classificazione delle immagini, il rilevamento di oggetti e volti, ecc.
Il fondamentale di un modello di rete neurale convoluzionale è che riceve un'immagine di input. L'immagine di input può essere etichettata (come gatto, cane, leone, ecc.) o senza etichetta. A seconda di ciò, gli algoritmi di Deep Learning sono classificati in due tipi: gli algoritmi supervisionati in cui le immagini sono etichettate e gli algoritmi non supervisionati in cui alle immagini non viene assegnata alcuna etichetta particolare.
Per la macchina del computer, l'immagine di input è vista come una matrice di pixel, più spesso sotto forma di matrice. Le immagini sono per lo più della forma hxwxd (dove h = altezza, w = larghezza, d = dimensione). Ad esempio, un'immagine di dimensioni 16 x 16 x 3 matrice matrice denota un'immagine RGB (3 sta per i valori RGB). D'altra parte, un'immagine di matrice 14 x 14 x 1 rappresenta un'immagine in scala di grigi.
Fonte
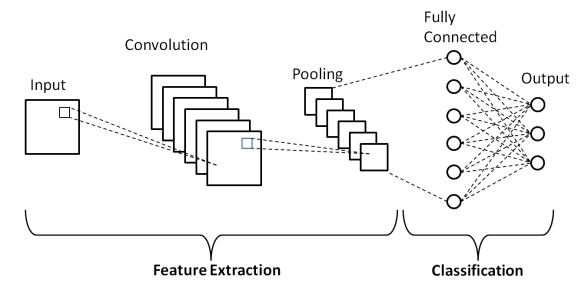
Strati di rete neurale convoluzionale
Come mostrato nell'Architettura di base di una rete neurale convoluzionale sopra, un modello CNN è costituito da diversi livelli attraverso i quali le immagini di input subiscono una pre-elaborazione per ottenere l'output. Fondamentalmente, questi strati sono differenziati in due parti:

- I primi tre livelli includono Input Layer, Convolution Layer e Pooling layer che funge da strumento di estrazione delle caratteristiche per derivare le caratteristiche del livello base dalle immagini inserite nel modello.
- Il livello completamente connesso finale e il livello di output utilizzano l'output dei livelli di estrazione delle funzionalità e prevedono una classe per l'immagine a seconda delle funzionalità estratte.
Il primo livello è lo strato di input in cui l'immagine viene inserita nel modello di rete neurale convoluzionale sotto forma di un array di matrici, ovvero 32 x 32 x 3, dove 3 indica che l'immagine è un'immagine RGB con altezza e larghezza uguali di 32 pixel. Quindi, queste immagini di input passano attraverso il Convolutional Layer dove viene eseguita l'operazione matematica di Convolution.
L'immagine di input è convogliata con un'altra matrice quadrata nota come kernel o filtro. Facendo scorrere il kernel uno per uno sui pixel dell'immagine di input, otteniamo l'immagine di output nota come mappa delle caratteristiche che fornisce informazioni sulle caratteristiche di livello base dell'immagine come bordi e linee.
Il livello convoluzionale è seguito dal livello di pooling il cui scopo è ridurre le dimensioni della mappa delle caratteristiche per ridurre i costi di calcolo. Questo viene fatto da diversi tipi di pooling come Max Pooling, Average Pooling e Sum Pooling.
Il livello completamente connesso (FC) è il penultimo livello del modello di rete neurale convoluzionale in cui i livelli vengono appiattiti e alimentati al livello FC. Qui, utilizzando funzioni di attivazione come le funzioni Sigmoid, ReLU e tanH, la previsione dell'etichetta ha luogo e viene distribuita nel livello di output finale .
Dove le CNN falliscono
Con così tante utili applicazioni della rete neurale convoluzionale nei dati di immagini visive, le CNN hanno un piccolo svantaggio in quanto non funzionano bene con una sequenza di immagini (video) e non riescono a interpretare le informazioni temporali e i blocchi di testo.
Per gestire dati temporali o sequenziali come le frasi, abbiamo bisogno di algoritmi che imparino dai dati passati e anche dai dati futuri nella sequenza. Fortunatamente, le reti neurali ricorrenti fanno proprio questo.
Reti neurali ricorrenti
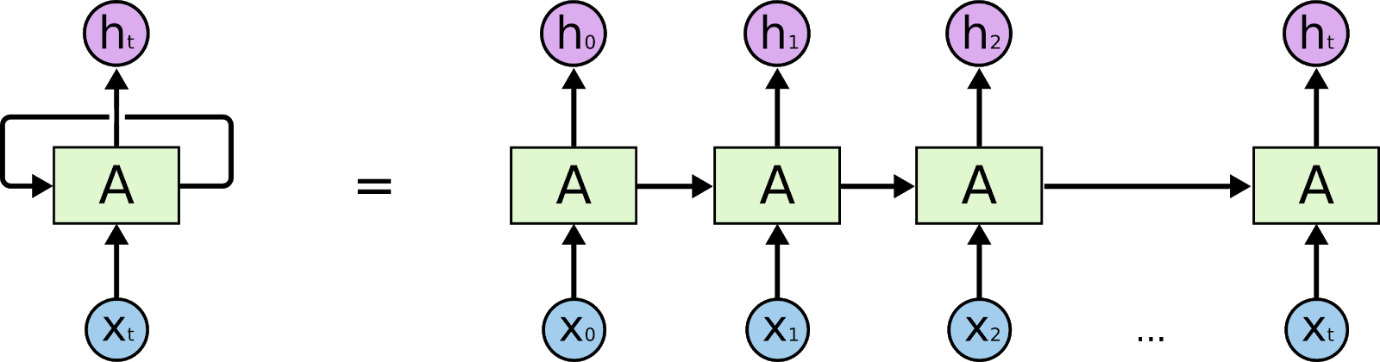
Le reti neurali ricorrenti sono reti progettate per interpretare informazioni temporali o sequenziali. Gli RNN utilizzano altri punti dati in una sequenza per fare previsioni migliori. Lo fanno prendendo l'input e riutilizzando le attivazioni dei nodi precedenti o successivi nella sequenza per influenzare l'output.
Fonte
Come risultato della loro memoria interna, le reti neurali ricorrenti possono ricordare dettagli vitali come l'input che hanno ricevuto, il che le rende molto precise nel prevedere ciò che verrà dopo. Pertanto, sono l'algoritmo preferito per dati sequenziali come serie temporali, voce, testo, audio, video e molti altri. Le reti neurali ricorrenti possono formare una comprensione molto più profonda di una sequenza e del suo contesto rispetto ad altri algoritmi.
Come funzionano le reti neurali ricorrenti?
Le basi per comprendere il lavoro sulle reti neurali ricorrenti sono le stesse delle reti neurali convoluzionali, le semplici reti neurali feed-forward, note anche come Perceptron. Inoltre, nelle reti neurali ricorrenti, l'output del passaggio precedente viene inviato come input al passaggio corrente. Nella maggior parte delle reti neurali, l'output è solitamente indipendente dagli input e viceversa, questa è la differenza fondamentale tra la RNN e le altre reti neurali.
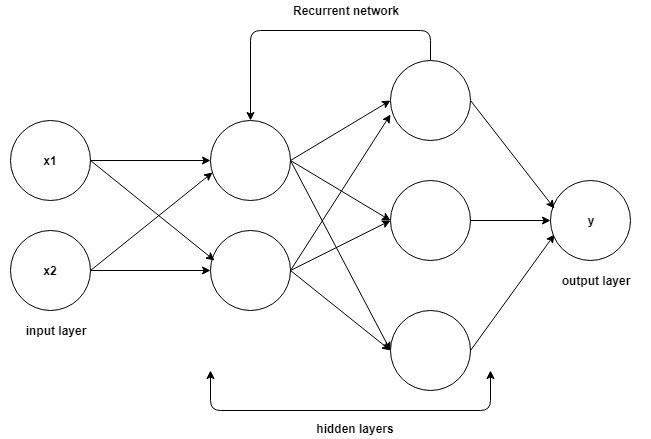
Fonte
Pertanto, un RNN ha due input: il presente e il passato recente. Questo è importante perché la sequenza di dati contiene informazioni cruciali su ciò che verrà dopo, motivo per cui un RNN può fare cose che altri algoritmi non possono fare. La caratteristica principale e più importante delle Reti Neurali Ricorrenti è lo stato Nascosto, che ricorda alcune informazioni su una sequenza.
Le Reti Neurali Ricorrenti hanno una memoria che immagazzina tutte le informazioni su quanto calcolato. Utilizzando gli stessi parametri per ogni input ed eseguendo la stessa attività su tutti gli input o livelli nascosti, la complessità dei parametri viene ridotta.
Differenza tra CNN e RNN
| Reti neurali convoluzionali | Reti neurali ricorrenti |
| Nell'apprendimento profondo, una rete neurale convoluzionale (CNN o ConvNet) è una classe di reti neurali profonde, più comunemente applicata all'analisi delle immagini visive. | Una rete neurale ricorrente (RNN) è una classe di reti neurali artificiali in cui le connessioni tra i nodi formano un grafo diretto lungo una sequenza temporale. |
| È adatto per dati spaziali come le immagini. | RNN viene utilizzato per i dati temporali, detti anche dati sequenziali. |
| La CNN è un tipo di rete neurale artificiale feed-forward con variazioni di perceptron multistrato progettata per utilizzare quantità minime di preelaborazione. | RNN, a differenza delle reti neurali feed-forward, può utilizzare la propria memoria interna per elaborare sequenze arbitrarie di input. |
| La CNN è considerata più potente di RNN. | RNN include una minore compatibilità delle funzionalità rispetto alla CNN. |
| Questa CNN prende input di dimensioni fisse e genera output di dimensioni fisse. | RNN può gestire lunghezze di input/output arbitrarie. |
| Le CNN sono ideali per l'elaborazione di immagini e video. | Gli RNN sono ideali per l'analisi del testo e del parlato. |
| Le applicazioni includono il riconoscimento delle immagini, la classificazione delle immagini, l'analisi delle immagini mediche, il rilevamento dei volti e la visione artificiale. | Le applicazioni includono traduzione di testi, elaborazione del linguaggio naturale, traduzione linguistica, analisi del sentimento e analisi del parlato. |
Conclusione
Pertanto, in questo articolo sulle differenze tra i due tipi più popolari di reti neurali, le reti neurali convoluzionali e le reti neurali ricorrenti, abbiamo appreso la struttura di base di una rete neurale, insieme ai fondamenti di CNN e RNN e infine abbiamo riassunto un breve confronto tra i due con le loro applicazioni nel mondo reale.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI , progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT -B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Perché la CNN è più veloce di RNN?
Le CNN sono più veloci delle RNN perché sono progettate per gestire le immagini, mentre le RNN sono progettate per gestire il testo. Sebbene gli RNN possano essere addestrati per gestire le immagini, è comunque difficile per loro separare le caratteristiche contrastanti che sono più vicine tra loro. Ad esempio, se hai l'immagine di un viso con occhi, naso e bocca, gli RNN hanno difficoltà a capire quale caratteristica visualizzare per prima. Le CNN utilizzano una griglia di punti e, utilizzando un algoritmo, possono essere addestrate a riconoscere forme e schemi. Le CNN sono migliori delle RNN nell'ordinare le immagini; sono più veloci degli RNN perché sono semplici da calcolare e sono più bravi a ordinare le immagini.
A cosa serve RNN?
Le reti neurali ricorrenti (RNN) sono una classe di reti neurali artificiali in cui le connessioni tra le unità formano un ciclo diretto. L'output di un'unità diventa l'input di un'altra unità e così via, proprio come l'output di un neurone diventa l'input di un altro. Gli RNN sono stati utilizzati con successo per svolgere compiti complessi, come il riconoscimento vocale e la traduzione automatica, che sono difficili da eseguire con i metodi standard.
Che cos'è RNN e in che cosa differisce dalle reti neurali Feedforward?
Le reti neurali ricorrenti (RNN) sono una sorta di reti neurali utilizzate per l'elaborazione di dati sequenziali. Una rete neurale ricorrente è costituita da un livello di input, uno o più livelli nascosti e un livello di output. I livelli nascosti sono progettati per apprendere le rappresentazioni interne dei dati di input, che vengono quindi presentati al livello di output come una rappresentazione esterna. L'RNN è addestrato con l'aiuto della backpropagation. Le RNN vengono spesso confrontate con le reti neurali feedforward (FNN). Mentre sia gli RNN che gli FNN possono apprendere le rappresentazioni interne dei dati, gli RNN sono in grado di apprendere dipendenze a lungo termine, di cui gli FNN non sono in grado.