
Costruire un rilevatore di ambienti per dispositivi IoT su Mac OS
Pubblicato: 2022-03-10Sapere in quale stanza ti trovi abilita varie applicazioni IoT, dall'accensione della luce al cambio dei canali TV. Quindi, come possiamo rilevare il momento in cui tu e il tuo telefono siete in cucina, in camera da letto o in soggiorno? Con l'hardware di base di oggi, ci sono una miriade di possibilità:
Una soluzione è dotare ogni stanza di un dispositivo bluetooth . Una volta che il tuo telefono è nel raggio di portata di un dispositivo Bluetooth, il tuo telefono saprà in quale stanza si trova, in base al dispositivo Bluetooth. Tuttavia, il mantenimento di una serie di dispositivi Bluetooth è un sovraccarico significativo, dalla sostituzione delle batterie alla sostituzione dei dispositivi disfunzionali. Inoltre, la vicinanza al dispositivo Bluetooth non è sempre la risposta: se sei in soggiorno, vicino al muro condiviso con la cucina, i tuoi elettrodomestici da cucina non dovrebbero iniziare a sfornare cibo.
Un'altra soluzione, anche se poco pratica, è quella di utilizzare il GPS . Tuttavia, tieni presente che il GPS funziona male all'interno in cui la moltitudine di muri, altri segnali e altri ostacoli devastano la precisione del GPS.
Il nostro approccio è invece quello di sfruttare tutte le reti Wi-Fi nel raggio d'azione, anche quelle a cui il tuo telefono non è connesso. Ecco come: considera la forza del WiFi A in cucina; diciamo che è 5. Poiché c'è un muro tra la cucina e la camera da letto, possiamo ragionevolmente aspettarci che la potenza del WiFi A nella camera da letto sia diversa; diciamo che è 2. Possiamo sfruttare questa differenza per prevedere in quale stanza ci troviamo. Inoltre: la rete WiFi B del nostro vicino può essere rilevata solo dal soggiorno ma è effettivamente invisibile dalla cucina. Ciò rende la previsione ancora più facile. In sintesi, l'elenco di tutti i WiFi nel raggio d'azione ci fornisce informazioni abbondanti.
Questo metodo ha i notevoli vantaggi di:
- non richiede più hardware;
- fare affidamento su segnali più stabili come il WiFi;
- funziona bene dove altre tecniche come il GPS sono deboli.
Più muri ci sono, meglio è, più disparati sono i punti di forza della rete WiFi, più facili saranno le stanze da classificare. Creerai una semplice app desktop che raccoglie dati, apprende dai dati e prevede in quale stanza ti trovi in un dato momento.
Ulteriori letture su SmashingMag:
- L'ascesa dell'interfaccia utente conversazionale intelligente
- Applicazioni dell'apprendimento automatico per i progettisti
- Come creare un prototipo di esperienze IoT: costruire l'hardware
- Progettare per l'Internet delle cose emotive
Prerequisiti
Per questo tutorial, avrai bisogno di un Mac OSX. Mentre il codice può essere applicato a qualsiasi piattaforma, forniremo solo istruzioni per l'installazione delle dipendenze per Mac.
- Mac OS X
- Homebrew, un gestore di pacchetti per Mac OSX. Per installare, copia e incolla il comando su brew.sh
- Installazione di NodeJS 10.8.0+ e npm
- Installazione di Python 3.6+ e pip. Vedi le prime 3 sezioni di "Come installare virtualenv, installare con pip e gestire i pacchetti"
Passaggio 0: impostare l'ambiente di lavoro
La tua app desktop verrà scritta in NodeJS. Tuttavia, per sfruttare librerie computazionali più efficienti come numpy , il codice di addestramento e previsione verrà scritto in Python. Per iniziare, configureremo i tuoi ambienti e installeremo le dipendenze. Crea una nuova directory per ospitare il tuo progetto.
mkdir ~/riotNaviga nella directory.
cd ~/riotUsa pip per installare il gestore dell'ambiente virtuale predefinito di Python.
sudo pip install virtualenv Crea un ambiente virtuale Python3.6 chiamato riot .
virtualenv riot --python=python3.6Attiva l'ambiente virtuale.
source riot/bin/activate La tua richiesta è ora preceduta da (riot) . Ciò indica che siamo entrati con successo nell'ambiente virtuale. Installa i seguenti pacchetti usando pip :
-
numpy: una libreria di algebra lineare efficiente -
scipy: una libreria di calcolo scientifico che implementa modelli di apprendimento automatico popolari
pip install numpy==1.14.3 scipy ==1.1.0Con l'impostazione della directory di lavoro, inizieremo con un'app desktop che registra tutte le reti WiFi nel raggio d'azione. Queste registrazioni costituiranno dati di addestramento per il tuo modello di machine learning. Una volta che avremo i dati a portata di mano, scriverai un classificatore dei minimi quadrati, addestrato sui segnali WiFi raccolti in precedenza. Infine, utilizzeremo il modello dei minimi quadrati per prevedere la stanza in cui ti trovi, in base alle reti WiFi nel raggio d'azione.
Passaggio 1: applicazione desktop iniziale
In questo passaggio creeremo una nuova applicazione desktop utilizzando Electron JS. Per iniziare, avremo invece il gestore di pacchetti Node npm e un'utilità di download wget .
brew install npm wgetPer iniziare, creeremo un nuovo progetto Node.
npm init Viene richiesto il nome del pacchetto e quindi il numero di versione. Premi ENTER per accettare il nome predefinito di riot e la versione predefinita di 1.0.0 .
package name: (riot) version: (1.0.0) Viene richiesta una descrizione del progetto. Aggiungi qualsiasi descrizione non vuota che desideri. Di seguito, la descrizione è room detector
description: room detector Viene richiesto il punto di ingresso o il file principale da cui eseguire il progetto. Inserisci app.js .
entry point: (index.js) app.js Questo richiede il test command e il git repository . Premi ENTER per saltare questi campi per ora.
test command: git repository: Questo richiede keywords e author . Inserisci tutti i valori che desideri. Di seguito, utilizziamo iot , wifi per le parole chiave e usiamo John Doe per l'autore.
keywords: iot,wifi author: John Doe Viene richiesta la licenza. Premi ENTER per accettare il valore predefinito di ISC .
license: (ISC) A questo punto, npm ti chiederà un riepilogo delle informazioni fino ad ora. L'output dovrebbe essere simile al seguente.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Premi ENTER per accettare. npm quindi produce un package.json . Elenca tutti i file da ricontrollare.
lsQuesto produrrà l'unico file in questa directory, insieme alla cartella dell'ambiente virtuale.
package.json riotInstalla le dipendenze di NodeJS per il nostro progetto.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Inizia con main.js da Electron Quick Start, scaricando il file, usando il seguente. Il seguente argomento -O rinomina main.js in app.js .
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Apri app.js in nano o nel tuo editor di testo preferito.
nano app.js Alla riga 12, cambia index.html in static/index.html , poiché creeremo una directory static per contenere tutti i modelli HTML.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Salva le modifiche ed esci dall'editor. Il tuo file dovrebbe corrispondere al codice sorgente del file app.js Ora crea una nuova directory per ospitare i nostri modelli HTML.
mkdir staticScarica un foglio di stile creato per questo progetto.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Apri static/index.html in nano o nel tuo editor di testo preferito. Inizia con la struttura HTML standard.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Subito dopo il titolo, collega il font Montserrat collegato da Google Fonts e foglio di stile.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Tra i tag main , aggiungi uno slot per il nome della stanza previsto.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Il tuo script ora dovrebbe corrispondere esattamente a quanto segue. Esci dall'editor.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Ora, modifica il file del pacchetto in modo che contenga un comando di avvio.
nano package.json Subito dopo la riga 7, aggiungi un comando di start con alias a electron . . Assicurati di aggiungere una virgola alla fine della riga precedente.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Salva ed esci. Ora sei pronto per avviare la tua app desktop in Electron JS. Usa npm per avviare la tua applicazione.
npm startLa tua applicazione desktop dovrebbe corrispondere a quanto segue.

Questo completa l'app desktop iniziale. Per uscire, torna al tuo terminale e CTRL+C. Nel passaggio successivo, registreremo le reti Wi-Fi e renderemo accessibile l'utilità di registrazione tramite l'interfaccia utente dell'applicazione desktop.
Passaggio 2: registra le reti Wi-Fi
In questo passaggio, scriverai uno script NodeJS che registra la potenza e la frequenza di tutte le reti wifi nel raggio d'azione. Crea una directory per i tuoi script.
mkdir scripts Apri scripts/observe.js in nano o nel tuo editor di testo preferito.
nano scripts/observe.jsImporta un'utilità wifi NodeJS e l'oggetto filesystem.
var wifi = require('node-wifi'); var fs = require('fs'); Definire una funzione record che accetta un gestore di completamento.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } All'interno della nuova funzione, inizializza l'utilità wifi. Impostare iface su null per inizializzare su un'interfaccia wifi casuale, poiché questo valore è attualmente irrilevante.
function record(n, completion, hook) { wifi.init({ iface : null }); }Definisci un array per contenere i tuoi campioni. I campioni sono dati di addestramento che utilizzeremo per il nostro modello. Gli esempi in questo particolare tutorial sono elenchi di reti Wi-Fi nel raggio d'azione e i loro punti di forza, frequenze, nomi, ecc.
function record(n, completion, hook) { ... samples = [] } Definisci una funzione ricorsiva startScan , che avvierà le scansioni Wi-Fi in modo asincrono. Al termine, la scansione Wi-Fi asincrona invocherà in modo ricorsivo startScan .
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } Nella richiamata wifi.scan , verifica la presenza di errori o elenchi di reti vuoti e, in tal caso, riavvia la scansione.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Aggiungi il caso base della funzione ricorsiva, che richiama il gestore di completamento.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Emetti un aggiornamento sullo stato di avanzamento, aggiungi all'elenco di campioni ed effettua la chiamata ricorsiva.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); Alla fine del tuo file, richiama la funzione di record con un callback che salva i campioni su un file su disco.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Verifica che il tuo file corrisponda a quanto segue:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Salva ed esci. Esegui lo script.
node scripts/observe.jsIl tuo output corrisponderà a quanto segue, con un numero variabile di reti.
* [INFO] Collected sample 1 with 39 networks Esaminare i campioni che sono stati appena raccolti. Pipe a json_pp per stampare abbastanza il JSON e pipe per andare a visualizzare le prime 16 righe.
cat samples.json | json_pp | head -16Di seguito è riportato un esempio di output per una rete a 2,4 GHz.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },Questo conclude lo script di scansione Wi-Fi NodeJS. Questo ci consente di visualizzare tutte le reti WiFi nel raggio d'azione. Nel passaggio successivo, renderai questo script accessibile dall'app desktop.
Passaggio 3: collega lo script di scansione all'app desktop
In questo passaggio, prima aggiungerai un pulsante all'app desktop con cui attivare lo script. Quindi, aggiornerai l'interfaccia utente dell'app desktop con l'avanzamento dello script.
Apri static/index.html .
nano static/index.htmlInserisci il pulsante "Aggiungi", come mostrato di seguito.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Salva ed esci. Apri static/add.html .
nano static/add.htmlIncolla il seguente contenuto.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Salva ed esci. Riapri scripts/observe.js .
nano scripts/observe.js Sotto la funzione cli , definisci una nuova funzione ui .
function cli() { ... } // start new code function ui() { } // end new code cli();Aggiorna lo stato dell'app desktop per indicare che la funzione è stata avviata.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Suddividere i dati in set di dati di addestramento e convalida.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Sempre all'interno del callback di completion , scrivi entrambi i set di dati su disco.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Richiamare record con i callback appropriati per registrare 20 campioni e salvarli su disco.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } Infine, richiama le funzioni cli e ui dove appropriato. Inizia eliminando cli(); chiamare in fondo al file.
function ui() { ... } cli(); // remove me Verifica se l'oggetto documento è accessibile a livello globale. In caso contrario, lo script viene eseguito dalla riga di comando. In questo caso, invoca la funzione cli . In tal caso, lo script viene caricato dall'app desktop. In questo caso, associa il listener di clic alla funzione ui .
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Salva ed esci. Crea una directory per contenere i nostri dati.
mkdir dataAvvia l'app desktop.
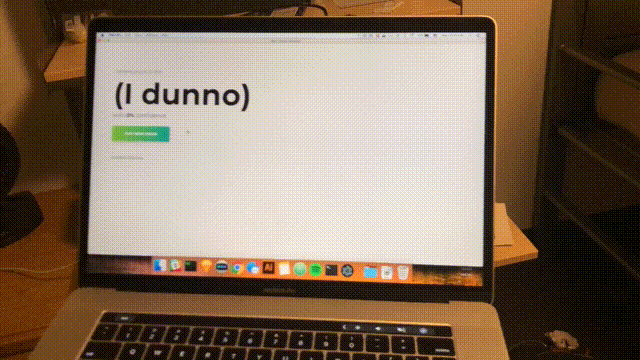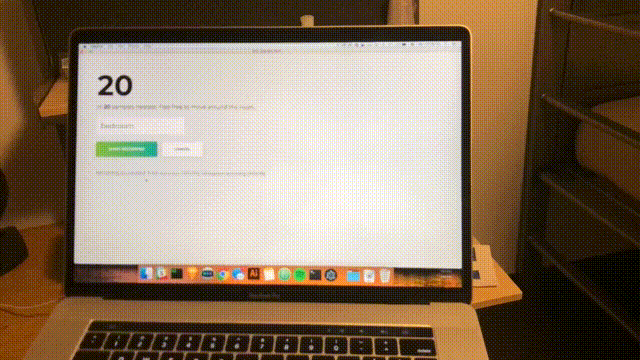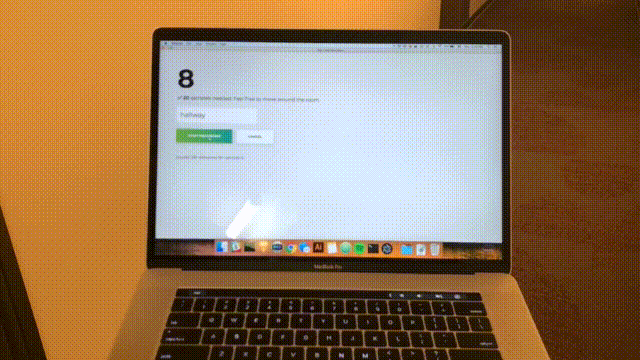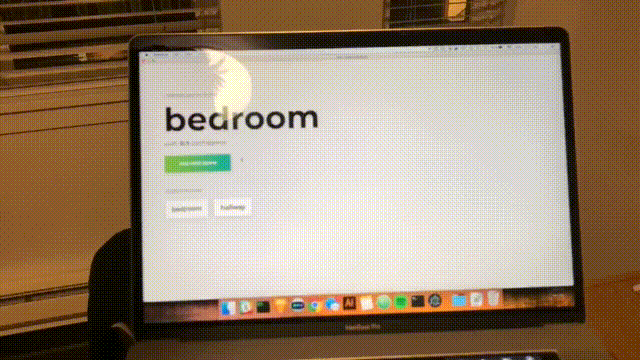
npm startVedrai la seguente home page. Clicca su "Aggiungi stanza".
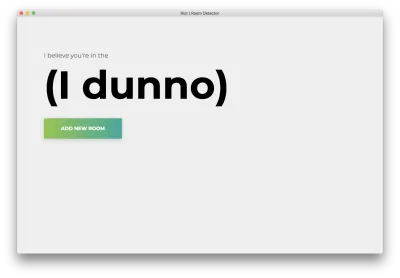
Vedrai il seguente modulo. Digita un nome per la stanza. Ricorda questo nome, poiché lo useremo in seguito. Il nostro esempio sarà la camera da bedroom .
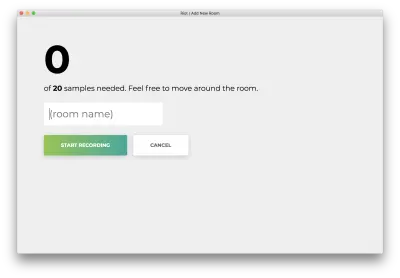
Fai clic su "Avvia registrazione" e vedrai il seguente stato "Ascolto Wi-Fi in corso...".
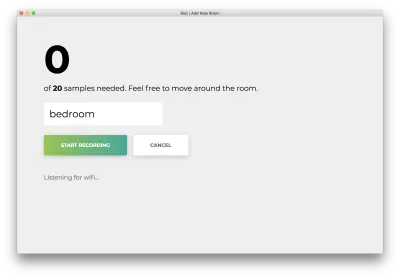
Una volta registrati tutti i 20 campioni, la tua app corrisponderà a quanto segue. Lo stato leggerà "Fatto".

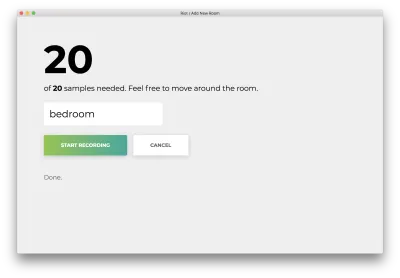
Fare clic sul nome errato "Annulla" per tornare alla home page, che corrisponde a quanto segue.
Ora possiamo scansionare le reti wifi dall'interfaccia utente desktop, che salverà tutti i campioni registrati su file su disco. Successivamente, addestreremo un algoritmo di apprendimento automatico pronto all'uso, i minimi quadrati sui dati che hai raccolto.
Passaggio 4: scrivi lo script di addestramento Python
In questo passaggio, scriveremo uno script di addestramento in Python. Crea una directory per le tue utilità di formazione.
mkdir model Apri model/train.py
nano model/train.py Nella parte superiore del file, importa la libreria computazionale numpy e scipy per il suo modello dei minimi quadrati.
import numpy as np from scipy.linalg import lstsq import json import sysLe tre utilità successive gestiranno il caricamento e l'impostazione dei dati dai file su disco. Inizia aggiungendo una funzione di utilità che appiattisce gli elenchi nidificati. Lo userai per appiattire un elenco di elenchi di campioni.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Aggiungi una seconda utilità che carica campioni dai file specificati. Questo metodo astrae il fatto che i campioni sono distribuiti su più file, restituendo un solo generatore per tutti i campioni. Per ciascuno dei campioni, l'etichetta è l'indice del file. ad esempio, se chiami get_all_samples('a.json', 'b.json') , tutti i campioni in a.json avranno l'etichetta 0 e tutti i campioni in b.json avranno l'etichetta 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelSuccessivamente, aggiungi un'utilità che codifichi i campioni utilizzando un modello bag-of-words-esque. Ecco un esempio: supponiamo di raccogliere due campioni.
- rete wifi A a potenza 10 e rete wifi B a potenza 15
- rete wifi B a potenza 20 e rete wifi C a potenza 25.
Questa funzione produrrà un elenco di tre numeri per ciascuno dei campioni: il primo valore è la potenza della rete wifi A, il secondo per la rete B e il terzo per C. In effetti, il formato è [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] Usando tutte e tre le utilità sopra, sintetizziamo una raccolta di campioni e le loro etichette. Raccogli tutti i campioni e le etichette usando get_all_samples . Definire un formato coerente che ordering la codifica one-hot di tutti i campioni, quindi applica la codifica one_hot ai campioni. Infine, costruisci i dati ed etichetta le matrici rispettivamente X e Y
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingQueste funzioni completano la pipeline di dati. Successivamente, astraiamo la previsione e la valutazione del modello. Inizia definendo il metodo di previsione. La prima funzione normalizza gli output del nostro modello, in modo che la somma di tutti i valori sia pari a 1 e che tutti i valori non siano negativi; questo assicura che l'output sia una distribuzione di probabilità valida. Il secondo valuta il modello.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)Quindi, valutare l'accuratezza del modello. La prima riga esegue la previsione utilizzando il modello. Il secondo conta il numero di volte in cui i valori previsti e veri concordano, quindi normalizza in base al numero totale di campioni.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy Questo conclude le nostre utilità di previsione e valutazione. Dopo queste utilità, definisci una funzione main che raccoglierà il set di dati, addestrerà e valuterà. Inizia leggendo l'elenco degli argomenti dalla riga di comando sys.argv ; queste sono le stanze da inserire nella formazione. Quindi crea un set di dati di grandi dimensioni da tutte le stanze specificate.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Applicare la codifica one-hot alle etichette. Una codifica one-hot è simile al modello bag-of-words sopra; usiamo questa codifica per gestire le variabili categoriali. Supponiamo di avere 3 possibili etichette. Invece di etichettare 1, 2 o 3, etichettiamo i dati con [1, 0, 0], [0, 1, 0] o [0, 0, 1]. Per questo tutorial, risparmieremo la spiegazione del perché la codifica one-hot è importante. Addestra il modello e valuta sia il treno che i set di convalida.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Stampa entrambe le precisioni e salva il modello su disco.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() Alla fine del file, esegui la funzione main .
if __name__ == '__main__': main()Salva ed esci. Verifica che il tuo file corrisponda a quanto segue:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Salva ed esci. Richiamare il nome della stanza utilizzato sopra durante la registrazione dei 20 campioni. Usa quel nome invece della bedroom da letto qui sotto. Il nostro esempio è la bedroom . Usiamo -W ignore per ignorare gli avvisi da un bug LAPACK.
python -W ignore model/train.py bedroomPoiché abbiamo raccolto campioni di formazione solo per una stanza, dovresti vedere un'accuratezza di formazione e convalida del 100%.
Train accuracy (100.0%), Validation accuracy (100.0%)Successivamente, collegheremo questo script di formazione all'app desktop.
Passaggio 5: collega lo script del treno
In questo passaggio, riaddegneremo automaticamente il modello ogni volta che l'utente raccoglie un nuovo lotto di campioni. Apri scripts/observe.js .
nano scripts/observe.js Subito dopo l'importazione fs , importa lo spawner del processo figlio e le utilità.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); Nella funzione ui , aggiungi la seguente chiamata per retrain alla fine del gestore di completamento.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } Dopo la funzione ui , aggiungi la seguente funzione di retrain . Questo genera un processo figlio che eseguirà lo script python. Al termine, il processo chiama un gestore di completamento. In caso di errore, registrerà il messaggio di errore.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Salva ed esci. Apri scripts/utils.js .
nano scripts/utils.js Aggiungi la seguente utilità per recuperare tutti i set di dati in data/ .
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Salva ed esci. Per la conclusione di questo passaggio, spostati fisicamente in una nuova posizione. Idealmente dovrebbe esserci un muro tra la tua posizione originale e la tua nuova posizione. Più sono le barriere, meglio funzionerà la tua app desktop.
Ancora una volta, esegui la tua app desktop.
npm startProprio come prima, esegui lo script di formazione. Clicca su "Aggiungi stanza".
Digita il nome di una stanza diverso da quello della tua prima stanza. Useremo living room .
Fai clic su "Avvia registrazione" e vedrai il seguente stato "Ascolto Wi-Fi in corso...".
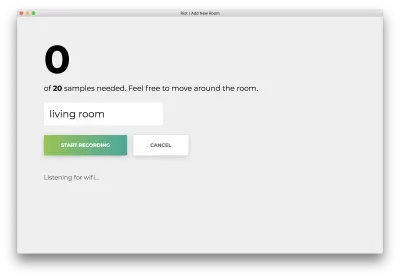
Una volta registrati tutti i 20 campioni, la tua app corrisponderà a quanto segue. Lo stato visualizzerà "Fatto. Modello di riqualificazione…”
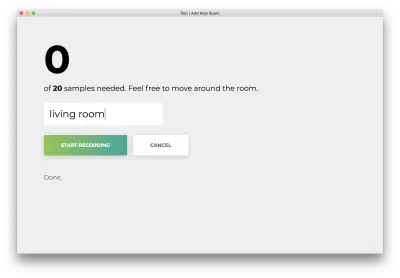
Nella fase successiva, utilizzeremo questo modello riqualificato per prevedere al volo la stanza in cui ti trovi.
Passaggio 6: scrivi lo script di valutazione Python
In questo passaggio, caricheremo i parametri del modello pre-addestrati, cercheremo reti Wi-Fi e prevediamo la stanza in base alla scansione.
Apri model/eval.py .
nano model/eval.pyImporta le librerie utilizzate e definite nel nostro ultimo script.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Definire un'utilità per estrarre i nomi di tutti i set di dati. Questa funzione presuppone che tutti i set di dati siano archiviati in data/ come <dataset>_train.json e <dataset>_test.json .
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Definire la funzione main e iniziare caricando i parametri salvati dallo script di addestramento.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Creare il set di dati e prevedere.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Calcola un punteggio di confidenza basato sulla differenza tra le prime due probabilità.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) Infine, estrai la categoria e stampa il risultato. Per concludere lo script, richiamare la funzione main .
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Salva ed esci. Verifica che il tuo codice corrisponda a quanto segue (codice sorgente):
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Successivamente, collegheremo questo script di valutazione all'app desktop. L'app desktop eseguirà continuamente scansioni Wi-Fi e aggiornerà l'interfaccia utente con la stanza prevista.
Passaggio 7: collega la valutazione all'app desktop
In questo passaggio, aggiorneremo l'interfaccia utente con una visualizzazione "confidenza". Quindi, lo script NodeJS associato eseguirà continuamente scansioni e previsioni, aggiornando di conseguenza l'interfaccia utente.
Apri static/index.html .
nano static/index.htmlAggiungi una linea di sicurezza subito dopo il titolo e prima dei pulsanti.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Subito dopo main ma prima della fine del body , aggiungi un nuovo script predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Salva ed esci. Apri scripts/predict.js .
nano scripts/predict.jsImporta le utilità NodeJS necessarie per il filesystem, le utilità e lo spawner del processo figlio.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Definisci una funzione di predict che invochi un processo di nodo separato per rilevare le reti Wi-Fi e un processo Python separato per prevedere la stanza.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }Dopo che entrambi i processi sono stati generati, aggiungi callback al processo Python sia per i successi che per gli errori. Il callback di successo registra le informazioni, richiama il callback di completamento e aggiorna l'interfaccia utente con la previsione e l'affidabilità. Il callback di errore registra l'errore.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Definire una funzione principale per invocare la funzione di predict in modo ricorsivo, per sempre.
function main() { f = function() { predict(f) } predict(f) } main();Un'ultima volta, apri l'app desktop per vedere la previsione in tempo reale.
npm startApprossimativamente ogni secondo, verrà completata una scansione e l'interfaccia verrà aggiornata con l'ultima affidabilità e la stanza prevista. Congratulazioni; hai completato un semplice rilevatore di ambienti basato su tutte le reti WiFi nel raggio d'azione.
Conclusione
In questo tutorial, abbiamo creato una soluzione utilizzando solo il desktop per rilevare la tua posizione all'interno di un edificio. Abbiamo creato una semplice app desktop utilizzando Electron JS e applicato un semplice metodo di apprendimento automatico su tutte le reti Wi-Fi nel raggio d'azione. Questo apre la strada alle applicazioni Internet delle cose senza la necessità di array di dispositivi costosi da mantenere (costo non in termini di denaro ma in termini di tempo e sviluppo).
Nota : puoi vedere il codice sorgente nella sua interezza su Github.
Con il tempo, potresti scoprire che questi minimi quadrati non si comportano in modo spettacolare. Prova a trovare due posizioni all'interno di una singola stanza o fermati sulle porte. I minimi quadrati saranno grandi incapaci di distinguere tra casi limite. Possiamo fare di meglio? Si scopre che possiamo, e nelle lezioni future, sfrutteremo altre tecniche e i fondamenti dell'apprendimento automatico per migliorare le prestazioni. Questo tutorial funge da banco di prova rapido per gli esperimenti a venire.