
Costruire internamente un servizio di registrazione centralizzato
Pubblicato: 2022-03-10Sappiamo tutti quanto sia importante il debug per migliorare le prestazioni e le funzionalità delle applicazioni. BrowserStack esegue un milione di sessioni al giorno su uno stack di applicazioni altamente distribuito! Ciascuno coinvolge diverse parti mobili, poiché la singola sessione di un cliente può estendersi su più componenti in diverse aree geografiche.
Senza il framework e gli strumenti giusti, il processo di debug può essere un incubo. Nel nostro caso, avevamo bisogno di un modo per raccogliere gli eventi che accadono durante le diverse fasi di ogni processo al fine di ottenere una comprensione approfondita di tutto ciò che accade durante una sessione. Con la nostra infrastruttura, la risoluzione di questo problema è diventata complicata poiché ogni componente potrebbe avere più eventi dal ciclo di vita dell'elaborazione di una richiesta.
Ecco perché abbiamo sviluppato il nostro strumento di servizio di registrazione centrale (CLS) interno per registrare tutti gli eventi importanti registrati durante una sessione. Questi eventi aiutano i nostri sviluppatori a identificare le condizioni in cui qualcosa va storto in una sessione e aiutano a tenere traccia di alcune metriche chiave del prodotto.
I dati di debug vanno da cose semplici come la latenza della risposta API al monitoraggio dello stato di salute della rete di un utente. In questo articolo, condividiamo la nostra storia di creazione del nostro strumento CLS che raccoglie 70G di dati cronologici rilevanti al giorno da oltre 100 componenti in modo affidabile, su larga scala e con due istanze M3.large EC2.
La decisione di costruire internamente
Innanzitutto, consideriamo il motivo per cui abbiamo creato internamente il nostro strumento CLS anziché utilizzare una soluzione esistente. Ciascuna delle nostre sessioni invia in media 15 eventi, da più componenti al servizio, traducendosi in circa 15 milioni di eventi totali al giorno.
Il nostro servizio richiedeva la capacità di archiviare tutti questi dati. Abbiamo cercato una soluzione completa per supportare l'archiviazione, l'invio e l'interrogazione degli eventi tra gli eventi. Poiché abbiamo considerato soluzioni di terze parti come Amplitude e Keen, le nostre metriche di valutazione includevano costi, prestazioni nella gestione di richieste parallele elevate e facilità di adozione. Sfortunatamente, non siamo riusciti a trovare una soluzione che soddisfacesse tutti i nostri requisiti entro il budget, anche se i vantaggi avrebbero incluso il risparmio di tempo e la riduzione al minimo degli avvisi. Anche se ci sarebbe voluto uno sforzo aggiuntivo, abbiamo deciso di sviluppare noi stessi una soluzione interna.

Dettagli tecnici
In termini di architettura per il nostro componente, abbiamo delineato i seguenti requisiti di base:
- Prestazioni del cliente
Non influisce sulle prestazioni del client/componente che invia gli eventi. - Scala
In grado di gestire un numero elevato di richieste in parallelo. - Prestazioni di servizio
Veloce per elaborare tutti gli eventi inviati ad esso. - Approfondimento sui dati
Ogni evento registrato deve avere alcune metainformazioni per poter identificare in modo univoco il componente o l'utente, l'account o il messaggio e fornire più informazioni per aiutare lo sviluppatore a eseguire il debug più velocemente. - Interfaccia interrogabile
Gli sviluppatori possono eseguire query su tutti gli eventi per una sessione particolare, aiutando a eseguire il debug di una sessione particolare, creare report sull'integrità dei componenti o generare statistiche significative sulle prestazioni dei nostri sistemi. - Adozione più rapida e semplice
Facile integrazione con un componente esistente o nuovo senza appesantire i team e occupare le loro risorse. - Bassa manutenzione
Siamo un piccolo team di ingegneri, quindi abbiamo cercato una soluzione per ridurre al minimo gli avvisi!
Costruire la nostra soluzione CLS
Decisione 1: scegliere un'interfaccia da esporre
Nello sviluppo di CLS, ovviamente non volevamo perdere nessuno dei nostri dati, ma non volevamo nemmeno che le prestazioni dei componenti subissero un colpo. Per non parlare del fattore aggiuntivo di impedire che i componenti esistenti diventino più complicati, poiché ritarderebbe l'adozione e il rilascio complessivi. Nel determinare la nostra interfaccia, abbiamo considerato le seguenti scelte:
- Memorizzazione di eventi in Redis locali in ogni componente, poiché un processore in background lo invia a CLS. Tuttavia, ciò richiede una modifica in tutti i componenti, insieme all'introduzione di Redis per i componenti che non lo contenevano già.
- Un modello Publisher - Abbonato, in cui Redis è più vicino al CLS. Poiché tutti pubblicano eventi, di nuovo abbiamo il fattore dei componenti in esecuzione in tutto il mondo. Durante il periodo di traffico intenso, ciò ritarderebbe i componenti. Inoltre, questa scrittura potrebbe saltare a intermittenza fino a cinque secondi (a causa del solo Internet).
- Invio di eventi tramite UDP, che offre un impatto minore sulle prestazioni dell'applicazione. In questo caso i dati verrebbero inviati e dimenticati, tuttavia, lo svantaggio qui sarebbe la perdita di dati.
È interessante notare che la nostra perdita di dati su UDP è stata inferiore allo 0,1%, un importo accettabile per noi da considerare la creazione di un servizio di questo tipo. Siamo stati in grado di convincere tutti i team che questa quantità di perdita valeva la prestazione e siamo andati avanti per sfruttare un'interfaccia UDP che ascoltava tutti gli eventi inviati.
Sebbene un risultato fosse un impatto minore sulle prestazioni di un'applicazione, abbiamo riscontrato un problema poiché il traffico UDP non era consentito da tutte le reti, principalmente dai nostri utenti, causando in alcuni casi la mancata ricezione di dati. Come soluzione alternativa, abbiamo supportato la registrazione di eventi utilizzando le richieste HTTP. Tutti gli eventi provenienti dal lato utente verrebbero inviati tramite HTTP, mentre tutti gli eventi registrati dai nostri componenti sarebbero tramite UDP.
Decisione 2: stack tecnologico (lingua, struttura e archiviazione)
Siamo un negozio Ruby. Tuttavia, eravamo incerti se Ruby sarebbe stata una scelta migliore per il nostro particolare problema. Il nostro servizio dovrebbe gestire molte richieste in arrivo, oltre a elaborare molte scritture. Con il blocco dell'interprete globale, raggiungere il multithreading o la concorrenza sarebbe difficile in Ruby (per favore non offenderti: adoriamo Ruby!). Quindi avevamo bisogno di una soluzione che ci aiutasse a raggiungere questo tipo di concorrenza.
Volevamo anche valutare un nuovo linguaggio nel nostro stack tecnologico e questo progetto sembrava perfetto per sperimentare cose nuove. È stato allora che abbiamo deciso di provare Golang poiché offriva supporto integrato per la concorrenza e thread leggeri e go-routine. Ogni punto dati registrato assomiglia a una coppia chiave-valore in cui "chiave" è l'evento e "valore" funge da valore associato.
Ma avere una chiave e un valore semplici non è sufficiente per recuperare i dati relativi alla sessione: sono presenti più metadati. Per risolvere questo problema, abbiamo deciso che qualsiasi evento che deve essere registrato avrebbe un ID sessione insieme alla sua chiave e al suo valore. Abbiamo anche aggiunto campi extra come timestamp, ID utente e il componente che registra i dati, in modo che sia diventato più facile recuperare e analizzare i dati.

Ora che abbiamo deciso la nostra struttura del carico utile, abbiamo dovuto scegliere il nostro datastore. Abbiamo preso in considerazione Elastic Search, ma volevamo anche supportare le richieste di aggiornamento per le chiavi. Ciò attiverebbe la reindicizzazione dell'intero documento, il che potrebbe influire sulle prestazioni delle nostre scritture. MongoDB aveva più senso come archivio dati poiché sarebbe stato più semplice eseguire query su tutti gli eventi in base a uno qualsiasi dei campi di dati che sarebbero stati aggiunti. Questo è stato facile!
Decisione 3: la dimensione del DB è enorme e le query e l'archiviazione fanno schifo!
Per ridurre la manutenzione, il nostro servizio dovrebbe gestire il maggior numero possibile di eventi. Data la velocità con cui BrowserStack rilascia funzionalità e prodotti, eravamo certi che il numero dei nostri eventi sarebbe aumentato a tassi più elevati nel tempo, il che significa che il nostro servizio avrebbe dovuto continuare a funzionare bene. Con l'aumento dello spazio, le letture e le scritture richiedono più tempo, il che potrebbe avere un enorme impatto sulle prestazioni del servizio.
La prima soluzione che abbiamo esplorato è stata spostare i log di un certo periodo lontano dal database (nel nostro caso, abbiamo deciso per 15 giorni). Per fare ciò, abbiamo creato un database diverso per ogni giorno, consentendoci di trovare registri più vecchi di un determinato periodo senza dover scansionare tutti i documenti scritti. Ora rimuoviamo continuamente i database più vecchi di 15 giorni da Mongo, mantenendo ovviamente i backup per ogni evenienza.
L'unico pezzo rimasto era un'interfaccia per sviluppatori per interrogare i dati relativi alla sessione. Onestamente, questo era il problema più semplice da risolvere. Forniamo un'interfaccia HTTP, in cui le persone possono interrogare gli eventi relativi alla sessione nel database corrispondente nel MongoDB, per qualsiasi dato che ha un particolare ID di sessione.
Architettura
Parliamo delle componenti interne del servizio, considerando i seguenti punti:
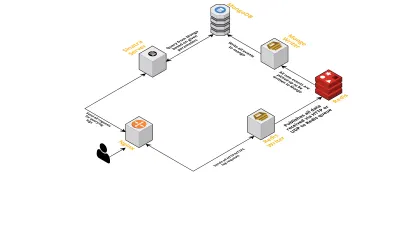
- Come discusso in precedenza, avevamo bisogno di due interfacce: una in ascolto su UDP e un'altra in ascolto su HTTP. Quindi abbiamo costruito due server, sempre uno per ogni interfaccia, per ascoltare gli eventi. Non appena arriva un evento, lo analizziamo per verificare se ha i campi richiesti: ID sessione, chiave e valore. In caso contrario, i dati vengono eliminati. In caso contrario, i dati vengono passati su un canale Go a un'altra goroutine, la cui unica responsabilità è scrivere nel MongoDB.
- Una possibile preoccupazione qui è scrivere a MongoDB. Se le scritture su MongoDB sono più lente della velocità di ricezione dei dati, si crea un collo di bottiglia. Questo, a sua volta, fa morire di fame altri eventi in arrivo e significa che i dati vengono eliminati. Il server, quindi, dovrebbe essere veloce nell'elaborazione dei log in entrata ed essere pronto per elaborare quelli in arrivo. Per risolvere il problema, abbiamo diviso il server in due parti: la prima riceve tutti gli eventi e li mette in coda per la seconda, che li elabora e li scrive nel MongoDB.
- Per la coda abbiamo scelto Redis. Dividendo l'intero componente in questi due pezzi abbiamo ridotto il carico di lavoro del server, dandogli spazio per gestire più log.
- Abbiamo scritto un piccolo servizio utilizzando il server Sinatra per gestire tutto il lavoro di interrogazione di MongoDB con determinati parametri. Restituisce una risposta HTML/JSON agli sviluppatori quando necessitano di informazioni su una particolare sessione.
Tutti questi processi vengono eseguiti felicemente su una singola istanza m3.large .
Richieste di funzionalità
Poiché il nostro strumento CLS è stato utilizzato di più nel tempo, necessitava di più funzionalità. Di seguito, discutiamo di questi e di come sono stati aggiunti.
Metadati mancanti
Man mano che il numero di componenti in BrowserStack aumenta, abbiamo richiesto di più da CLS. Ad esempio, avevamo bisogno della possibilità di registrare eventi da componenti privi di un ID sessione. In caso contrario, ottenerne uno appesantirebbe la nostra infrastruttura, influenzando le prestazioni delle applicazioni e aumentando il traffico sui nostri server principali.
Abbiamo risolto questo problema abilitando la registrazione degli eventi utilizzando altre chiavi, come il terminale e gli ID utente. Ora, ogni volta che viene creata o aggiornata una sessione, CLS viene informato con l'ID della sessione, nonché i rispettivi ID utente e terminale. Memorizza una mappa che può essere recuperata dal processo di scrittura su MongoDB. Ogni volta che viene recuperato un evento che contiene l'ID utente o terminale, viene aggiunto l'ID sessione.
Gestire lo spamming (problemi di codice in altri componenti)
CLS ha anche affrontato le solite difficoltà nella gestione degli eventi di spam. Abbiamo spesso riscontrato distribuzioni in componenti che hanno generato un volume enorme di richieste inviate a CLS. Altri registri avrebbero risentito del processo, poiché il server diventava troppo occupato per elaborarli e i registri importanti venivano eliminati.
Per la maggior parte, la maggior parte dei dati registrati avveniva tramite richieste HTTP. Per controllarli abilitiamo la limitazione della velocità su nginx (usando il modulo limit_req_zone), che blocca le richieste da qualsiasi IP che abbiamo riscontrato che ha raggiunto richieste più di un certo numero in un breve lasso di tempo. Naturalmente, sfruttiamo i rapporti sanitari su tutti gli IP bloccati e informiamo i team responsabili.
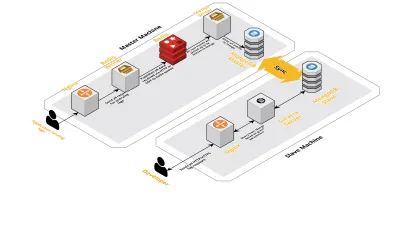
Scala v2
Con l'aumento delle nostre sessioni giornaliere, aumentavano anche i dati registrati su CLS. Ciò ha influito sulle query che i nostri sviluppatori eseguivano quotidianamente e presto il collo di bottiglia che abbiamo avuto è stato con la macchina stessa. La nostra configurazione consisteva in due macchine principali che eseguivano tutti i componenti di cui sopra, insieme a una serie di script per interrogare Mongo e tenere traccia delle metriche chiave per ciascun prodotto. Nel tempo, i dati sulla macchina sono aumentati notevolmente e gli script hanno iniziato a richiedere molto tempo alla CPU. Anche dopo aver cercato di ottimizzare le query Mongo, siamo sempre tornati sugli stessi problemi.
Per risolvere questo problema, abbiamo aggiunto un'altra macchina per l'esecuzione di script di report sull'integrità e l'interfaccia per interrogare queste sessioni. Il processo prevedeva l'avvio di una nuova macchina e la configurazione di uno slave del Mongo in esecuzione sulla macchina principale. Ciò ha contribuito a ridurre i picchi di CPU che vedevamo ogni giorno causati da questi script.
Conclusione
La creazione di un servizio per un'attività semplice come la registrazione dei dati può diventare complicata, poiché la quantità di dati aumenta. Questo articolo discute le soluzioni che abbiamo esplorato, insieme alle sfide affrontate durante la risoluzione di questo problema. Abbiamo sperimentato con Golang per vedere come si adattasse bene al nostro ecosistema e finora siamo rimasti soddisfatti. La nostra scelta di creare un servizio interno invece di pagarne uno esterno è stata straordinariamente efficiente in termini di costi. Inoltre, non abbiamo dovuto ridimensionare la nostra configurazione su un'altra macchina fino a molto tempo dopo, quando il volume delle nostre sessioni è aumentato. Naturalmente, le nostre scelte nello sviluppo di CLS erano completamente basate sui nostri requisiti e priorità.
Oggi CLS gestisce fino a 15 milioni di eventi ogni giorno, costituendo fino a 70 GB di dati. Questi dati vengono utilizzati per aiutarci a risolvere eventuali problemi che i nostri clienti devono affrontare durante qualsiasi sessione. Utilizziamo questi dati anche per altri scopi. Dati gli approfondimenti forniti dai dati di ciascuna sessione sui diversi prodotti e componenti interni, abbiamo iniziato a sfruttare questi dati per tenere traccia di ciascun prodotto. Ciò si ottiene estraendo le metriche chiave per tutti i componenti importanti.
Tutto sommato, abbiamo riscontrato un grande successo nella creazione del nostro strumento CLS. Se ha senso per te, ti consiglio di considerare di fare lo stesso!