
Come creare un raschietto per prodotti Amazon con Node.js
Pubblicato: 2022-03-10Sei mai stato in una posizione in cui hai bisogno di conoscere intimamente il mercato per un particolare prodotto? Forse stai lanciando del software e hai bisogno di sapere come valutarlo. O forse hai già il tuo prodotto sul mercato e vuoi vedere quali funzionalità aggiungere per un vantaggio competitivo. O forse vuoi semplicemente comprare qualcosa per te stesso e vuoi assicurarti di ottenere il miglior rapporto qualità-prezzo.
Tutte queste situazioni hanno una cosa in comune: sono necessari dati accurati per prendere la decisione corretta . In realtà, c'è un'altra cosa che condividono. Tutti gli scenari possono trarre vantaggio dall'uso di un web scraper.
Il web scraping è la pratica di estrarre grandi quantità di dati web attraverso l'uso di software. Quindi, in sostanza, è un modo per automatizzare il noioso processo di premere "copia" e quindi "incolla" 200 volte. Naturalmente, un bot può farlo nel tempo impiegato per leggere questa frase, quindi non è solo meno noioso ma anche molto più veloce.
Ma la domanda scottante è: perché qualcuno dovrebbe voler raschiare le pagine di Amazon?
Stai per scoprirlo! Ma prima di tutto, vorrei chiarire subito una cosa: mentre l'atto di raschiare i dati pubblicamente disponibili è legale, Amazon ha alcune misure per prevenirlo sulle loro pagine. Pertanto, ti esorto a essere sempre consapevole del sito Web durante lo scraping, fare attenzione a non danneggiarlo e seguire le linee guida etiche.
Letture consigliate : "La guida allo scraping etico di siti Web dinamici con Node.js e Burattinaio" di Andreas Altheimer
Perché dovresti estrarre i dati dei prodotti Amazon
Essendo il più grande rivenditore online del pianeta, è sicuro dire che se vuoi acquistare qualcosa, probabilmente puoi ottenerlo su Amazon. Quindi, è ovvio quanto sia grande il tesoro di dati del sito web.
Quando si esegue lo scraping del Web, la domanda principale dovrebbe essere cosa fare con tutti quei dati. Sebbene ci siano molte ragioni individuali, si riduce a due casi d'uso importanti: l'ottimizzazione dei prodotti e la ricerca delle migliori offerte.
“
Partiamo dal primo scenario. A meno che tu non abbia progettato un nuovo prodotto davvero innovativo, è probabile che tu possa già trovare qualcosa di almeno simile su Amazon. La raschiatura di quelle pagine di prodotto può farti guadagnare dati inestimabili come:
- La strategia di prezzo dei concorrenti
In modo che tu possa regolare i tuoi prezzi per essere competitivo e capire come gli altri gestiscono le offerte promozionali; - Opinioni dei clienti
Per vedere a cosa interessa di più la tua futura base di clienti e come migliorare la loro esperienza; - Caratteristiche più comuni
Per vedere cosa offre la tua concorrenza per sapere quali funzionalità sono cruciali e quali possono essere lasciate per dopo.
In sostanza, Amazon ha tutto ciò di cui hai bisogno per un'analisi approfondita del mercato e del prodotto. Sarai più preparato a progettare, lanciare ed espandere la tua gamma di prodotti con quei dati.
Il secondo scenario può applicarsi sia alle imprese che alle persone normali. L'idea è abbastanza simile a quella che ho menzionato prima. Puoi raschiare i prezzi, le caratteristiche e le recensioni di tutti i prodotti che potresti scegliere e così potrai scegliere quello che offre i maggiori vantaggi al prezzo più basso. Dopotutto, a chi non piace un buon affare?
Non tutti i prodotti meritano questo livello di attenzione ai dettagli, ma può fare un'enorme differenza con acquisti costosi. Sfortunatamente, mentre i vantaggi sono chiari, molte difficoltà vanno di pari passo con lo scraping di Amazon.
Le sfide di raschiare i dati dei prodotti Amazon
Non tutti i siti web sono uguali. Come regola generale, più un sito web è complesso e diffuso, più difficile sarà estrarlo. Ricordi quando ho detto che Amazon era il sito di e-commerce più importante? Bene, questo lo rende estremamente popolare e ragionevolmente complesso.
Prima di tutto, Amazon sa come agiscono i robot scraping, quindi il sito Web ha messo in atto contromisure. Vale a dire, se lo scraper segue uno schema prevedibile, inviando richieste a intervalli fissi, più velocemente di quanto potrebbe fare un essere umano o con parametri quasi identici, Amazon noterà e bloccherà l'IP. I proxy possono risolvere questo problema, ma non ne avevo bisogno poiché non raschieremo troppe pagine nell'esempio.
Successivamente, Amazon utilizza deliberatamente strutture di pagina variabili per i propri prodotti. Vale a dire che se esamini le pagine per prodotti diversi, ci sono buone probabilità che troverai differenze significative nella loro struttura e attributi. Il motivo alla base di questo è abbastanza semplice. Devi adattare il codice del tuo scraper per un sistema specifico e, se usi lo stesso script su un nuovo tipo di pagina, dovresti riscriverne parti. Quindi, essenzialmente ti stanno facendo lavorare di più per i dati.
Infine, Amazon è un vasto sito web. Se desideri raccogliere grandi quantità di dati, l'esecuzione del software di scraping sul tuo computer potrebbe richiedere troppo tempo per le tue esigenze. Questo problema è ulteriormente consolidato dal fatto che andare troppo veloce bloccherà il tuo raschietto. Quindi, se vuoi un sacco di dati velocemente, avrai bisogno di uno scraper davvero potente.
Bene, basta parlare di problemi, concentriamoci sulle soluzioni!
Come costruire un web scraper per Amazon
Per semplificare le cose, adotteremo un approccio graduale alla scrittura del codice. Sentiti libero di lavorare in parallelo con la guida.
Cerca i dati di cui abbiamo bisogno
Quindi, ecco uno scenario: tra qualche mese mi trasferirò in un nuovo posto e avrò bisogno di un paio di nuovi scaffali per contenere libri e riviste. Voglio conoscere tutte le mie opzioni e ottenere il miglior affare possibile. Quindi, andiamo al mercato di Amazon, cerchiamo "scaffali" e vediamo cosa otteniamo.
L'URL per questa ricerca e la pagina che andremo a raschiare sono qui.
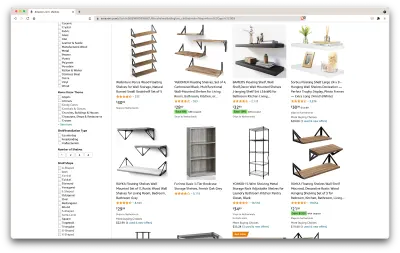
Ok, facciamo il punto su quello che abbiamo qui. Solo dando un'occhiata alla pagina, possiamo avere una buona immagine di:
- come appaiono gli scaffali;
- cosa include il pacchetto;
- come li valutano i clienti;
- il loro prezzo;
- il link al prodotto;
- un suggerimento per un'alternativa più economica per alcuni degli articoli.
È più di quanto potremmo chiedere!
Ottieni gli strumenti necessari
Assicuriamoci di avere tutti i seguenti strumenti installati e configurati prima di continuare con il passaggio successivo.
- Cromo
Possiamo scaricarlo da qui. - Codice VSC
Segui le istruzioni in questa pagina per installarlo sul tuo dispositivo specifico. - Node.js
Prima di iniziare a utilizzare Axios o Cheerio, è necessario installare Node.js e Node Package Manager. Il modo più semplice per installare Node.js e NPM è ottenere uno dei programmi di installazione dalla fonte ufficiale di Node.Js ed eseguirlo.
Ora creiamo un nuovo progetto NPM. Crea una nuova cartella per il progetto ed esegui il comando seguente:
npm init -yPer creare il web scraper, dobbiamo installare un paio di dipendenze nel nostro progetto:
- Cheerio
Una libreria open source che ci aiuta a estrarre informazioni utili analizzando il markup e fornendo un'API per manipolare i dati risultanti. Cheerio ci consente di selezionare i tag di un documento HTML utilizzando i selettori:$("div"). Questo selettore specifico ci aiuta a selezionare tutti gli elementi<div>su una pagina. Per installare Cheerio, esegui il seguente comando nella cartella dei progetti:
npm install cheerio- Asso
Una libreria JavaScript utilizzata per effettuare richieste HTTP da Node.js.
npm install axiosIspeziona l'origine della pagina
Nei passaggi seguenti, impareremo di più su come sono organizzate le informazioni nella pagina. L'idea è di ottenere una migliore comprensione di ciò che possiamo raschiare dalla nostra fonte.
Gli strumenti per sviluppatori ci aiutano a esplorare in modo interattivo il Document Object Model (DOM) del sito web. Utilizzeremo gli strumenti per sviluppatori in Chrome, ma puoi utilizzare qualsiasi browser web con cui ti senti a tuo agio.
Apriamolo facendo clic con il pulsante destro del mouse in un punto qualsiasi della pagina e selezionando l'opzione "Ispeziona":
Si aprirà una nuova finestra contenente il codice sorgente della pagina. Come abbiamo detto prima, stiamo cercando di raschiare le informazioni di ogni scaffale.
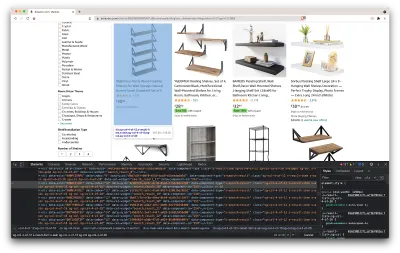
Come possiamo vedere dallo screenshot sopra, i contenitori che contengono tutti i dati hanno le seguenti classi:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20Nel passaggio successivo, utilizzeremo Cheerio per selezionare tutti gli elementi contenenti i dati di cui abbiamo bisogno.

Recupera i dati
Dopo aver installato tutte le dipendenze presentate sopra, creiamo un nuovo file index.js e digitiamo le seguenti righe di codice:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Come possiamo vedere, importiamo le dipendenze di cui abbiamo bisogno nelle prime due righe, quindi creiamo una funzione fetchShelves() che, utilizzando Cheerio, estrae dalla pagina tutti gli elementi contenenti le informazioni sui nostri prodotti.
Itera su ciascuno di essi e lo inserisce in un array vuoto per ottenere un risultato formattato meglio.
La funzione fetchShelves() restituirà solo il titolo del prodotto al momento, quindi prendiamo il resto delle informazioni di cui abbiamo bisogno. Aggiungi le seguenti righe di codice dopo la riga in cui abbiamo definito la variabile title .
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } E sostituisci shelves.push(title) con shelves.push(element) .
Ora selezioniamo tutte le informazioni di cui abbiamo bisogno e le aggiungiamo a un nuovo oggetto chiamato element . Ogni elemento viene quindi inviato all'array degli shelves per ottenere un elenco di oggetti contenente solo i dati che stiamo cercando.
Ecco come dovrebbe apparire un oggetto shelf prima di essere aggiunto al nostro elenco:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Formatta i dati
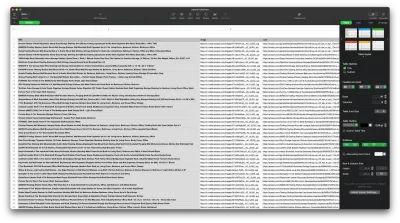
Ora che siamo riusciti a recuperare i dati di cui abbiamo bisogno, è una buona idea salvarli come file .CSV per migliorare la leggibilità. Dopo aver ottenuto tutti i dati, utilizzeremo il modulo fs fornito da Node.js e salveremo un nuovo file chiamato saved-shelves.csv nella cartella del progetto. Importa il modulo fs nella parte superiore del file e copia o scrivi lungo le seguenti righe di codice:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Come possiamo vedere, sulle prime tre righe, formattiamo i dati che abbiamo raccolto in precedenza unendo tutti i valori di un oggetto shelve usando una virgola. Quindi, utilizzando il modulo fs , creiamo un file chiamato saved-shelves.csv , aggiungiamo una nuova riga che contiene le intestazioni di colonna, aggiungiamo i dati che abbiamo appena formattato e creiamo una funzione di callback che gestisce gli errori.
Il risultato dovrebbe assomigliare a questo:
Suggerimenti bonus!
Raschiare le applicazioni a pagina singola
Il contenuto dinamico sta diventando lo standard al giorno d'oggi, poiché i siti Web sono più complessi che mai. Per fornire la migliore esperienza utente possibile, gli sviluppatori devono adottare diversi meccanismi di caricamento per i contenuti dinamici , rendendo il nostro lavoro un po' più complicato. Se non sai cosa significa, immagina un browser privo di un'interfaccia utente grafica. Fortunatamente, c'è Puppeteer, la magica libreria Node che fornisce un'API di alto livello per controllare un'istanza di Chrome tramite il protocollo DevTools. Tuttavia, offre le stesse funzionalità di un browser, ma deve essere controllato a livello di codice digitando un paio di righe di codice. Vediamo come funziona.
Nel progetto creato in precedenza, installa la libreria Puppeteer eseguendo npm install puppeteer , crea un nuovo file puppeteer.js e copia o scrivi lungo le seguenti righe di codice:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() Nell'esempio sopra, creiamo un'istanza di Chrome e apriamo una nuova pagina del browser necessaria per accedere a questo collegamento. Nella riga seguente, diciamo al browser headless di attendere fino a quando l'elemento con la classe rpBJOHq2PR60pnwJlUyP0 appare nella pagina. Abbiamo anche specificato per quanto tempo il browser deve attendere il caricamento della pagina (2000 millisecondi).
Usando il metodo di evaluate sulla variabile di page , abbiamo incaricato Puppeteer di eseguire i frammenti di Javascript all'interno del contesto della pagina subito dopo che l'elemento è stato finalmente caricato. Questo ci consentirà di accedere al contenuto HTML della pagina e restituire il corpo della pagina come output. Quindi chiudiamo l'istanza di Chrome chiamando il metodo close sulla variabile chrome . Il lavoro risultante dovrebbe consistere in tutto il codice HTML generato dinamicamente. Questo è il modo in cui Puppeteer può aiutarci a caricare contenuto HTML dinamico .
Se non ti senti a tuo agio con Puppeteer, tieni presente che ci sono un paio di alternative là fuori, come NightwatchJS, NightmareJS o CasperJS. Sono leggermente diversi, ma alla fine il processo è abbastanza simile.
Impostazione delle intestazioni user-agent
user-agent è un'intestazione di richiesta che informa su di te il sito Web che stai visitando, ovvero il browser e il sistema operativo. Viene utilizzato per ottimizzare il contenuto per la tua configurazione, ma i siti Web lo utilizzano anche per identificare i bot che inviano tonnellate di richieste, anche se cambia IPS.
Ecco come appare un'intestazione user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Nell'interesse di non essere rilevato e bloccato, dovresti cambiare regolarmente questa intestazione. Fai particolare attenzione a non inviare un'intestazione vuota o obsoleta poiché ciò non dovrebbe mai accadere per un utente run-fo-the-mill e ti distinguerai.
Limitazione della tariffa
I web scraper possono raccogliere contenuti in modo estremamente veloce, ma dovresti evitare di andare alla massima velocità. Ci sono due ragioni per questo:
- Troppe richieste in breve tempo possono rallentare il server del sito web o addirittura portarlo fuori, causando problemi al proprietario e agli altri visitatori. Può essenzialmente diventare un attacco DoS.
- Senza proxy rotanti, è come annunciare ad alta voce che stai usando un bot poiché nessun essere umano invierebbe centinaia o migliaia di richieste al secondo.
La soluzione è introdurre un ritardo tra le vostre richieste, una pratica chiamata “rate limiting”. ( È anche piuttosto semplice da implementare! )
Nell'esempio di Burattinaio fornito sopra, prima di creare la variabile body , possiamo utilizzare il metodo waitForTimeout fornito da Burattinaio per attendere un paio di secondi prima di effettuare un'altra richiesta:
await page.waitForTimeout(3000); Dove ms è il numero di secondi che vorresti aspettare.
Inoltre, se volessimo fare la stessa cosa per l'esempio di axios, possiamo creare una promessa che chiama il metodo setTimeout() , per aiutarci ad aspettare il numero di millisecondi desiderato:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))In questo modo, puoi evitare di esercitare troppa pressione sul server di destinazione e anche portare un approccio più umano allo scraping web.
Pensieri di chiusura
E il gioco è fatto, una guida passo passo per creare il tuo web scraper per i dati dei prodotti Amazon! Ma ricorda, questa era solo una situazione. Se desideri eseguire lo scraping di un sito Web diverso, dovrai apportare alcune modifiche per ottenere risultati significativi.
Lettura correlata
Se desideri ancora vedere più web scraping in azione, ecco del materiale di lettura utile per te:
- "La guida definitiva al web scraping con JavaScript e Node.Js", Robert Sfichi
- "Advanced Node.JS Web Scraping con Puppeteer", Gabriel Cioci
- "Python Web Scraping: la guida definitiva per costruire il tuo raschietto", Raluca Penciuc