
Crea un'applicazione di bookmarking con FaunaDB, Netlify e 11ty
Pubblicato: 2022-03-10La rivoluzione di JAMstack (JavaScript, API e Markup) è in pieno svolgimento. I siti statici sono sicuri, veloci, affidabili e divertenti su cui lavorare. Al centro di JAMstack ci sono i generatori di siti statici (SSG) che archiviano i tuoi dati come file flat: Markdown, YAML, JSON, HTML e così via. A volte, gestire i dati in questo modo può essere eccessivamente complicato. A volte, abbiamo ancora bisogno di un database.
Con questo in mente, Netlify, un host del sito statico e FaunaDB, un database cloud serverless, hanno collaborato per rendere più semplice la combinazione di entrambi i sistemi.
Perché un sito di bookmarking?
Il JAMstack è ottimo per molti usi professionali, ma uno dei miei aspetti preferiti di questo set di tecnologie è la sua bassa barriera all'ingresso di strumenti e progetti personali.
Ci sono molti buoni prodotti sul mercato per la maggior parte delle applicazioni che potrei inventare, ma nessuno sarebbe esattamente impostato per me. Nessuno mi darebbe il pieno controllo sui miei contenuti. Nessuno verrebbe senza un costo (monetario o informativo).
Con questo in mente, possiamo creare i nostri mini-servizi utilizzando i metodi JAMstack. In questo caso, creeremo un sito per archiviare e pubblicare tutti gli articoli interessanti che mi imbatterò nella mia lettura quotidiana di tecnologia.
Passo molto tempo a leggere articoli che sono stati condivisi su Twitter. Quando mi piace uno, premo l'icona del "cuore". Quindi, nel giro di pochi giorni, è quasi impossibile trovare con l'afflusso di nuovi preferiti. Voglio costruire qualcosa che sia il più vicino alla facilità del "cuore", ma che possiedo e controllo.
Come lo faremo? Sono felice che tu l'abbia chiesto.
Interessato a ricevere il codice? Puoi prenderlo su Github o semplicemente distribuirlo direttamente su Netlify da quel repository! Dai un'occhiata al prodotto finito qui.
Le nostre tecnologie
Hosting e funzioni serverless: Netlify
Per le funzioni di hosting e serverless, utilizzeremo Netlify. Come bonus aggiuntivo, con la nuova collaborazione sopra menzionata, la CLI di Netlify - "Netlify Dev" - si collegherà automaticamente a FaunaDB e memorizzerà le nostre chiavi API come variabili di ambiente.
Database: FaunaDB
FaunaDB è un database NoSQL "serverless". Lo useremo per memorizzare i dati dei nostri segnalibri.
Generatore di siti statici: 11ty
Sono un grande sostenitore dell'HTML. Per questo motivo, il tutorial non utilizzerà JavaScript front-end per eseguire il rendering dei nostri segnalibri. Invece, utilizzeremo 11ty come generatore di siti statici. 11ty ha funzionalità di dati integrate che rendono il recupero dei dati da un'API facile come scrivere un paio di brevi funzioni JavaScript.
Scorciatoie iOS
Avremo bisogno di un modo semplice per inviare i dati al nostro database. In questo caso, utilizzeremo l'app Scorciatoie di iOS. Questo potrebbe anche essere convertito in un bookmarklet JavaScript per Android o desktop.
Configurazione di FaunaDB tramite Netlify Dev
Se ti sei già registrato a FaunaDB o devi creare un nuovo account, il modo più semplice per impostare un collegamento tra FaunaDB e Netlify è tramite la CLI di Netlify: Netlify Dev. Puoi trovare le istruzioni complete da FaunaDB qui o seguire di seguito.
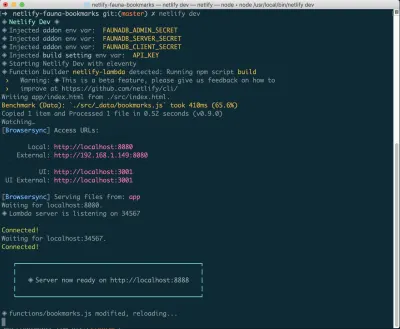
Se non lo hai già installato, puoi eseguire il seguente comando in Terminale:
npm install netlify-cli -gDall'interno della directory del tuo progetto, esegui i seguenti comandi:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Una volta che tutto è connesso, puoi eseguire netlify dev nel tuo progetto. Questo eseguirà tutti gli script di build che abbiamo impostato, ma si collegherà anche ai servizi Netlify e FaunaDB e acquisirà tutte le variabili di ambiente necessarie. Maneggevole!
Creare i nostri primi dati
Da qui, accederemo a FaunaDB e creeremo il nostro primo set di dati. Inizieremo creando un nuovo database chiamato "segnalibri". All'interno di un Database, abbiamo Collezioni, Documenti e Indici.
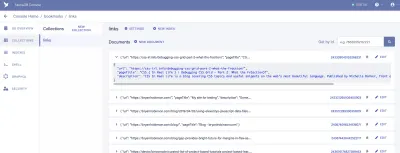
Una raccolta è un gruppo di dati classificato. Ogni dato assume la forma di un Documento. Un documento è un "record singolo e modificabile all'interno di un database FaunaDB", secondo la documentazione di Fauna. Puoi pensare alle raccolte come a una tabella di database tradizionale e a un documento come a una riga.
Per la nostra applicazione, abbiamo bisogno di una raccolta, che chiameremo "collegamenti". Ogni documento all'interno della raccolta "links" sarà un semplice oggetto JSON con tre proprietà. Per iniziare, aggiungeremo un nuovo documento che utilizzeremo per creare il nostro primo recupero di dati.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Questo crea la base per le informazioni che dovremo estrarre dai nostri segnalibri e ci fornisce il nostro primo set di dati da inserire nel nostro modello.
Se sei come me, vuoi vedere subito i frutti del tuo lavoro. Mettiamo qualcosa sulla pagina!
Installazione di 11ty e estrazione dei dati in un modello
Dal momento che vogliamo che i segnalibri vengano visualizzati in HTML e non vengano recuperati dal browser, avremo bisogno di qualcosa per eseguire il rendering. Ci sono molti ottimi modi per farlo, ma per facilità e potenza, adoro usare il generatore di siti statici 11ty.
Poiché 11ty è un generatore di siti statici JavaScript, possiamo installarlo tramite NPM.
npm install --save @11ty/eleventy Da quell'installazione, possiamo eseguirne undici o eleventy --serve eleventy nostro progetto per essere operativi.
Netlify Dev rileverà spesso 11ty come requisito ed eseguirà il comando per noi. Per fare in modo che funzioni, e assicurarci di essere pronti per la distribuzione, possiamo anche creare comandi "serve" e "build" nel nostro package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }File di dati di 11ty
La maggior parte dei generatori di siti statici ha un'idea di un "file di dati" integrato. Di solito, questi file saranno file JSON o YAML che ti consentono di aggiungere informazioni extra al tuo sito.
In 11ty, puoi utilizzare file di dati JSON o file di dati JavaScript. Utilizzando un file JavaScript, possiamo effettivamente effettuare le nostre chiamate API e restituire i dati direttamente in un modello.
Per impostazione predefinita, 11ty desidera che i file di dati siano archiviati in una directory _data . È quindi possibile accedere ai dati utilizzando il nome del file come variabile nei modelli. Nel nostro caso, creeremo un file in _data/bookmarks.js e vi accederemo tramite il nome della variabile {{ bookmarks }} .
Se vuoi approfondire la configurazione dei file di dati, puoi leggere gli esempi nella documentazione di 11ty o dare un'occhiata a questo tutorial sull'utilizzo dei file di dati 11ty con l'API Meetup.
Il file sarà un modulo JavaScript. Quindi, per far funzionare qualcosa, dobbiamo esportare i nostri dati o una funzione. Nel nostro caso, esporteremo una funzione.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Analizziamolo. Abbiamo due funzioni che svolgono il nostro lavoro principale qui: mapBookmarks() e getBookmarks() .
La funzione getBookmarks() andrà a prendere i nostri dati dal nostro database FaunaDB e mapBookmarks() prenderà un array di segnalibri e lo ristrutturerà per funzionare meglio per il nostro modello.
Analizziamo più a fondo getBookmarks() .
getBookmarks()
Innanzitutto, dovremo installare e inizializzare un'istanza del driver JavaScript FaunaDB.
npm install --save faunadbOra che l'abbiamo installato, aggiungiamolo all'inizio del nostro file di dati. Questo codice è direttamente dai documenti di Fauna.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); Successivamente, possiamo creare la nostra funzione. Inizieremo creando la nostra prima query utilizzando i metodi integrati nel driver. Questo primo bit di codice restituirà i riferimenti al database che possiamo utilizzare per ottenere i dati completi per tutti i nostri collegamenti con segnalibro. Usiamo il metodo Paginate , come aiuto per gestire lo stato del cursore se dovessimo decidere di impaginare i dati prima di consegnarli a 11ty. Nel nostro caso, restituiremo solo tutti i riferimenti.
In questo esempio, presumo che tu abbia installato e connesso FaunaDB tramite Netlify Dev CLI. Usando questo processo, ottieni le variabili di ambiente locali dei segreti di FaunaDB. Se non l'hai installato in questo modo o non stai eseguendo netlify dev nel tuo progetto, avrai bisogno di un pacchetto come dotenv per creare le variabili d'ambiente. Dovrai anche aggiungere le tue variabili di ambiente alla configurazione del tuo sito Netlify per far funzionare le distribuzioni in seguito.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Questo codice restituirà un array di tutti i nostri collegamenti in forma di riferimento. Ora possiamo creare un elenco di query da inviare al nostro database.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) Da qui, dobbiamo solo ripulire i dati restituiti. È qui che entra in mapBookmarks() !
mapBookmarks()
In questa funzione ci occupiamo di due aspetti dei dati.
Innanzitutto, otteniamo un dateTime gratuito in FaunaDB. Per tutti i dati creati, esiste una proprietà timestamp ( ts ). Non è formattato in un modo che renda felice il filtro della data predefinito di Liquid, quindi risolviamolo.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Detto questo, possiamo creare un nuovo oggetto per i nostri dati. In questo caso, avrà una proprietà time e utilizzeremo l'operatore Spread per destrutturare il nostro oggetto data per farli vivere tutti a un livello.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Ecco i nostri dati prima della nostra funzione:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Ecco i nostri dati dopo la nostra funzione:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Ora abbiamo dati ben formattati pronti per il nostro modello!
Scriviamo un modello semplice. Esamineremo i nostri segnalibri e convalideremo che ognuno ha un pageTitle di pagina e un url in modo da non sembrare sciocchi.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Ora stiamo importando e visualizzando i dati da FaunaDB. Prendiamoci un momento e pensiamo a quanto è bello che questo renda HTML puro e non sia necessario recuperare i dati sul lato client!
Ma questo non è davvero abbastanza per rendere questa app utile per noi. Scopriamo un modo migliore rispetto all'aggiunta di un segnalibro nella console di FaunaDB.
Entra in Netlify Functions
Il componente aggiuntivo Functions di Netlify è uno dei modi più semplici per distribuire le funzioni lambda di AWS. Poiché non c'è un passaggio di configurazione, è perfetto per i progetti fai-da-te in cui vuoi solo scrivere il codice.
Questa funzione vivrà su un URL nel tuo progetto che assomiglia a questo: https://myproject.com/.netlify/functions/bookmarks supponendo che il file che creiamo nella nostra cartella functions sia bookmarks.js .
Flusso di base
- Passa un URL come parametro di query all'URL della nostra funzione.
- Usa la funzione per caricare l'URL e raschiare il titolo e la descrizione della pagina, se disponibili.
- Formatta i dettagli per FaunaDB.
- Invia i dettagli alla nostra Collezione FaunaDB.
- Ricostruisci il sito.
Requisiti
Abbiamo alcuni pacchetti di cui avremo bisogno mentre lo costruiamo. Utilizzeremo la CLI netlify-lambda per creare le nostre funzioni in locale. request-promise è il pacchetto che useremo per fare le richieste. Cheerio.js è il pacchetto che useremo per raschiare elementi specifici dalla nostra pagina richiesta (pensa a jQuery per Node). E infine, avremo bisogno di FaunaDb (che dovrebbe essere già installato.
npm install --save netlify-lambda request-promise cheerioUna volta installato, configuriamo il nostro progetto per creare e servire le funzioni in locale.
Modificheremo i nostri script "build" e "serve" nel nostro package.json in modo che assomiglino a questo:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Avvertenza: si è verificato un errore con il driver NodeJS di Fauna durante la compilazione con Webpack, che le funzioni di Netlify utilizzano per compilare. Per aggirare questo problema, dobbiamo definire un file di configurazione per Webpack. Puoi salvare il codice seguente in un nuovo — o esistente — webpack.config.js .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Una volta che questo file esiste, quando usiamo il comando netlify-lambda , dovremo dirgli di essere eseguito da questa configurazione. Questo è il motivo per cui i nostri script "serve" e "build" utilizzano il valore --config per quel comando.
Funzione di pulizia
Per mantenere il nostro file Function principale il più pulito possibile, creeremo le nostre funzioni in una directory di bookmarks separata e le importeremo nel nostro file Function principale.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
La funzione getDetails() prenderà un URL, passato dal nostro gestore esportato. Da lì, contatteremo il sito a quell'URL e prenderemo parti rilevanti della pagina da archiviare come dati per il nostro segnalibro.
Iniziamo richiedendo i pacchetti NPM di cui abbiamo bisogno:
const rp = require('request-promise'); const cheerio = require('cheerio'); Quindi, useremo il modulo request-promise per restituire una stringa HTML per la pagina richiesta e passarla a cheerio per darci un'interfaccia molto jQuery-esque.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }Da qui, dobbiamo ottenere il titolo della pagina e una meta descrizione. Per farlo, useremo i selettori come faresti in jQuery.
Nota: in questo codice, utilizziamo 'head > title' come selettore per ottenere il titolo della pagina. Se non lo specifichi, potresti finire per ottenere i tag <title> all'interno di tutti gli SVG sulla pagina, il che non è l'ideale.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Con i dati in mano, è ora di inviare il nostro segnalibro alla nostra raccolta in FaunaDB!
saveBookmark(details)
Per la nostra funzione di salvataggio, vorremo passare i dettagli che abbiamo acquisito da getDetails e l'URL come oggetto singolare. L'operatore Spread colpisce ancora!
const savedResponse = await saveBookmark({url, ...details}); Nel nostro file create.js , dobbiamo anche richiedere e configurare il nostro driver FaunaDB. Questo dovrebbe sembrare molto familiare dal nostro file di dati 11ty.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Una volta che l'abbiamo tolto di mezzo, possiamo programmare.
Innanzitutto, dobbiamo formattare i nostri dettagli in una struttura di dati che Fauna si aspetta per la nostra query. Fauna si aspetta un oggetto con una proprietà dati contenente i dati che desideriamo memorizzare.
const saveBookmark = async function(details) { const data = { data: details }; ... }Quindi apriremo una nuova query da aggiungere alla nostra raccolta. In questo caso, useremo il nostro Query Helper e useremo il metodo Create. Create() accetta due argomenti. La prima è la raccolta in cui vogliamo archiviare i nostri dati e la seconda sono i dati stessi.
Dopo aver salvato, restituiamo il successo o il fallimento al nostro gestore.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Diamo un'occhiata al file Function completo.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
L'occhio più attento noterà che abbiamo un'altra funzione importata nel nostro gestore: rebuildSite() . Questa funzione utilizzerà la funzionalità Deploy Hook di Netlify per ricostruire il nostro sito dai nuovi dati ogni volta che inviamo un nuovo salvataggio di segnalibro riuscito.
Nelle impostazioni del tuo sito in Netlify, puoi accedere alle impostazioni di Build & Deploy e creare un nuovo "Build Hook". Gli hook hanno un nome che appare nella sezione Distribuisci e un'opzione per un ramo non master da distribuire se lo desideri. Nel nostro caso, lo chiameremo "nuovo_link" e implementeremo il nostro ramo principale.
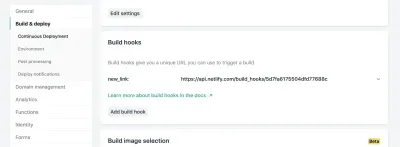
Da lì, dobbiamo solo inviare una richiesta POST all'URL fornito.
Abbiamo bisogno di un modo per fare richieste e poiché abbiamo già installato request-promise , continueremo a utilizzare quel pacchetto richiedendolo nella parte superiore del nostro file.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Configurazione di una scorciatoia iOS
Quindi, abbiamo un database, un modo per visualizzare i dati e una funzione per aggiungere dati, ma non siamo ancora molto facili da usare.
Netlify fornisce URL per le nostre funzioni Lambda, ma non è divertente digitarli su un dispositivo mobile. Dovremmo anche passare un URL come parametro di query al suo interno. Questo è un MOLTO sforzo. Come possiamo fare questo il minor sforzo possibile?
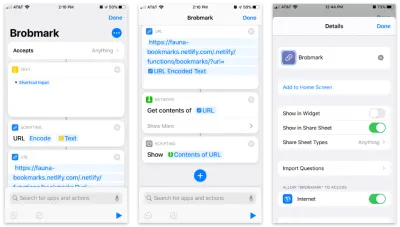
L'app Scorciatoie di Apple consente di creare elementi personalizzati da inserire nel tuo foglio di condivisione. All'interno di queste scorciatoie, possiamo inviare vari tipi di richieste di dati raccolti nel processo di condivisione.
Ecco la scorciatoia passo passo:
- Accetta qualsiasi articolo e memorizza quell'articolo in un blocco di "testo".
- Passa quel testo in un blocco "Scripting" per codificare l'URL (per ogni evenienza).
- Passa quella stringa in un blocco URL con l'URL della nostra funzione Netlify e un parametro di query di
url. - Da "Rete" usa un blocco "Ottieni contenuti" per POST su JSON al nostro URL.
- Opzionale: Da “Scripting” “Mostra” il contenuto dell'ultimo passaggio (per confermare i dati che stiamo inviando).
Per accedervi dal menu di condivisione, apriamo le impostazioni per questo collegamento e attiviamo l'opzione "Mostra nel foglio di condivisione".
A partire da iOS13, queste "azioni" di condivisione possono essere aggiunte ai preferiti e spostate in una posizione alta nella finestra di dialogo.
Ora abbiamo una "app" funzionante per condividere i segnalibri su più piattaforme!
Fai uno sforzo extra!
Se sei ispirato a provarlo tu stesso, ci sono molte altre possibilità per aggiungere funzionalità. La gioia del web fai-da-te è che puoi far funzionare questo tipo di applicazioni per te. Ecco alcune idee:
- Usa una falsa "chiave API" per l'autenticazione rapida, in modo che altri utenti non pubblichino sul tuo sito (il mio usa una chiave API, quindi non provare a postare su di esso!).
- Aggiungi funzionalità di tag per organizzare i segnalibri.
- Aggiungi un feed RSS per il tuo sito in modo che altri possano iscriversi.
- Invia un'e-mail di riepilogo settimanale in modo programmatico per i collegamenti che hai aggiunto.
Davvero, il cielo è il limite, quindi inizia a sperimentare!