
Distribuzione binomiale in Python con esempi del mondo reale [2022]
Pubblicato: 2021-01-09Il valore della probabilità e della statistica nel campo della scienza dei dati è stato immenso, con l'intelligenza artificiale e l'apprendimento automatico che fanno molto affidamento su di essi. Utilizziamo modelli di processo di distribuzione normale ogni volta che conduciamo test A/B e modelli di investimento.
Tuttavia, la distribuzione binomiale in Python viene applicata in più modi per eseguire diversi processi. Ma, prima di iniziare con la distribuzione binomiale in Python , è necessario conoscere la distribuzione binomiale in generale e il suo utilizzo nella vita di tutti i giorni. Se sei un principiante e sei interessato a saperne di più sulla scienza dei dati, dai un'occhiata alla nostra formazione sulla scienza dei dati dalle migliori università.
Sommario
Qual è la distribuzione binomiale ?
Hai mai lanciato una moneta? Se lo hai, allora devi sapere che la probabilità di ottenere testa o croce è uguale. Ma che ne dici della probabilità di ottenere sette croce su un totale di dieci lanci di una moneta? È qui che la distribuzione binomiale può aiutare a calcolare i risultati di ogni lancio, e quindi scoprire la probabilità di ottenere sette croce per dieci lanci di una moneta.
Il punto cruciale della distribuzione di probabilità deriva dalla varianza di qualsiasi evento. Per ogni set di dieci lanci di monete, la probabilità di ottenere testa e croce può variare da una a dieci volte, in modo uguale e probabile. L'incertezza nel risultato (nota anche come varianza) aiuta a generare la distribuzione dei risultati prodotti.
In altre parole, la distribuzione binomiale è un processo in cui ci sono solo due possibili risultati: vero o falso. Pertanto, ha la stessa probabilità di entrambi i risultati su tutti gli eventi, poiché le stesse azioni vengono eseguite ogni volta. C'è solo una condizione... I passaggi devono essere completamente inalterati l'uno dall'altro e i risultati possono o non possono essere ugualmente probabili.
Pertanto, la funzione di probabilità di una distribuzione binomiale è:
f f( k k , n n, p p) = P r Pr( k k; n n, p p) = P r Pr ( X X= k k) =
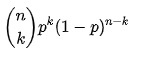
Fonte
Dove,
![]() = n n! k k !( n n!- k k!)
= n n! k k !( n n!- k k!)
Qui, n = numero totale di prove
p = probabilità di successo
k = numero target di successi
Distribuzione binomiale in Python
Per la distribuzione binomiale tramite Python, puoi produrre la variabile casuale distinta dalla funzione binom.rvs(), dove 'n' è definito come la frequenza totale delle prove e 'p' è uguale alla probabilità di successo.
Puoi anche spostare la distribuzione usando la funzione loc e la dimensione definisce la frequenza di un'azione che viene ripetuta nella serie. L'aggiunta di un random_state può aiutare a mantenere la riproducibilità.
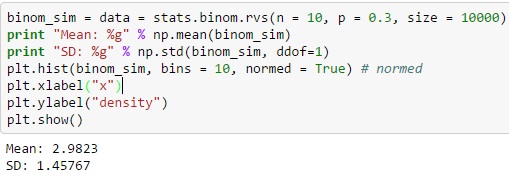
Fonte
Esempi reali di distribuzione binomiale in Python
Ci sono molti più eventi (più grandi dei lanci di monete) che possono essere affrontati dalla distribuzione binomiale in Python. Alcuni dei casi d'uso possono aiutare a monitorare e migliorare il ROI (ritorno sugli investimenti) per grandi e piccole aziende. Ecco come:

- Pensa a un call center in cui ogni dipendente riceve in media 50 chiamate al giorno.
- La probabilità di conversione su ogni call è pari al 4%.
- La generazione media di entrate per l'azienda basata su ciascuna di queste conversioni è di 20 USD.
- Se analizzi 100 di questi dipendenti, che vengono pagati 200 USD al giorno, allora
n = 50
p = 4%
Il codice può generare output come segue:
- Tasso di conversione medio per ogni dipendente = 2,13
- La deviazione standard delle conversioni per ciascun personale del call center = 1,48
- Conversione lorda = 213
- Generazione di entrate lorde = 21.300 USD
- Spesa lorda = 20.000 USD
- Utile lordo = 1.300 USD
I modelli di distribuzione binomiale e altre distribuzioni di probabilità possono solo prevedere un'approssimazione che può avvicinarsi al mondo reale in termini di parametri di azione, 'n' e 'p'. Ci aiuta a comprendere e identificare le nostre aree di interesse e migliorare le possibilità complessive di prestazioni ed efficacia migliori.
Leggi anche: 13 idee e argomenti interessanti per progetti sulla struttura dei dati per principianti
Cosa succede dopo?
Se sei curioso di conoscere la scienza dei dati, dai un'occhiata al programma Executive PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1 -on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Qual è la differenza tra distribuzione di probabilità discreta e distribuzione di probabilità continua?
La distribuzione di probabilità discreta o semplicemente distribuzione discreta calcola le probabilità di una variabile casuale che può essere discreta. Ad esempio, se lanciamo una moneta due volte, i valori probabili di una variabile casuale X che denota il numero totale di teste sarà {0, 1, 2} e non un valore casuale. Bernoulli, Binomiale, Ipergeometrico sono alcuni esempi di distribuzione di probabilità discreta. D'altra parte, la distribuzione di probabilità continua fornisce le probabilità di un valore casuale che può essere qualsiasi numero casuale. Ad esempio, il valore di una variabile casuale X che denota l'altezza dei cittadini di una città potrebbe essere qualsiasi numero come 161,2, 150,9, ecc. Normale, T di Student, Chi quadrato sono alcuni esempi di distribuzione continua.
Qual è il significato della probabilità nella scienza dei dati?
Poiché la scienza dei dati riguarda lo studio dei dati, la probabilità gioca un ruolo chiave qui. I seguenti motivi descrivono come la probabilità sia una parte indispensabile della scienza dei dati: aiuta analisti e ricercatori a fare previsioni a partire da set di dati. Questi tipi di risultati stimati sono la base per un'ulteriore analisi dei dati. La probabilità viene utilizzata anche durante lo sviluppo di algoritmi utilizzati nei modelli di apprendimento automatico. Aiuta nell'analisi dei set di dati utilizzati per l'addestramento dei modelli. Consente di quantificare i dati e derivare risultati come derivati, media e distribuzione. Tutti i risultati ottenuti utilizzando la probabilità alla fine riepilogano i dati. Questo riepilogo aiuta anche nell'identificazione dei valori anomali esistenti nei set di dati.
Spiega la distribuzione ipergeometrica. In quale caso tende ad essere una distribuzione binomiale?
successi nel numero di prove senza alcuna sostituzione. Diciamo che abbiamo un sacco pieno di palline rosse e verdi e dobbiamo trovare la probabilità di prendere una pallina verde in 5 tentativi ma ogni volta che prendiamo una pallina, non la rimettiamo nel sacco. Questo è un esempio appropriato della distribuzione ipergeometrica.
Per N maggiore è molto difficile calcolare la distribuzione ipergeometrica ma quando N è piccolo, in questo caso tende alla distribuzione binomiale.