Guida per principianti alla rete neurale convoluzionale (CNN)
Pubblicato: 2021-07-05L'ultimo decennio ha visto un'enorme crescita dell'intelligenza artificiale e delle macchine più intelligenti. Il campo ha dato origine a molte sottodiscipline che si stanno specializzando in aspetti distinti dell'intelligenza umana. Ad esempio, l'elaborazione del linguaggio naturale cerca di comprendere e modellare il linguaggio umano, mentre la visione artificiale mira a fornire una visione simile a quella umana alle macchine.
Dal momento che parleremo di reti neurali convoluzionali, il nostro focus sarà principalmente sulla visione artificiale. La visione artificiale mira a consentire alle macchine di vedere il mondo come noi e risolvere i problemi relativi al riconoscimento delle immagini, alla classificazione delle immagini e molto altro ancora. Le reti neurali convoluzionali vengono utilizzate per ottenere vari compiti di visione artificiale. Conosciuti anche come CNN o ConvNet, seguono un'architettura che ricorda i modelli e le connessioni dei neuroni nel cervello umano e sono ispirati da vari processi biologici che si verificano nel cervello per far sì che la comunicazione avvenga.
Sommario
Il significato biologico di una rete neurale contorta
Le CNN si ispirano alla nostra corteccia visiva. È l'area della corteccia cerebrale coinvolta nell'elaborazione visiva nel nostro cervello. La corteccia visiva ha varie piccole regioni cellulari sensibili agli stimoli visivi.
Questa idea è stata ampliata nel 1962 da Hubel e Wiesel in un esperimento in cui è stato scoperto che diverse cellule neuronali distinte rispondono (vengono attivate) alla presenza di bordi distinti di un orientamento specifico. Ad esempio, alcuni neuroni si attivano rilevando bordi orizzontali, altri rilevando bordi diagonali e altri ancora quando rilevano bordi verticali. Attraverso questo esperimento. Hubel e Wiesel hanno scoperto che i neuroni sono organizzati in modo modulare e tutti i moduli insieme sono necessari per produrre la percezione visiva.
Questo approccio modulare – l'idea che i componenti specializzati all'interno di un sistema abbiano compiti specifici – è ciò che costituisce la base delle CNN.
Detto questo, passiamo al modo in cui le CNN imparano a percepire gli input visivi.

Apprendimento della rete neurale convoluzionale
Le immagini sono composte da singoli pixel, che è una rappresentazione tra i numeri 0 e 255. Quindi, qualsiasi immagine che vedi può essere convertita in una corretta rappresentazione digitale usando questi numeri, ed è così che anche i computer lavorano con le immagini.
Ecco alcune delle principali operazioni che consentono a una CNN di apprendere per il rilevamento o la classificazione delle immagini. Questo ti darà un'idea di come avviene l'apprendimento nelle CNN.
1. Convoluzione
La convoluzione può essere intesa matematicamente come l'integrazione combinata di due diverse funzioni per scoprire come l'influenza della diversa funzione o modificarsi a vicenda. Ecco come può essere definito in termini matematici:
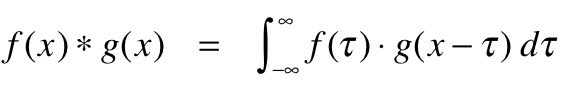
Lo scopo della convoluzione è rilevare diverse caratteristiche visive nelle immagini, come linee, bordi, colori, ombre e altro. Questa è una proprietà molto utile perché una volta che la tua CNN ha appreso le caratteristiche di una particolare caratteristica nell'immagine, può successivamente riconoscere quella caratteristica in qualsiasi altra parte dell'immagine.
Le CNN utilizzano kernel o filtri per rilevare le diverse funzionalità presenti in qualsiasi immagine. I kernel sono solo una matrice di valori distinti (noti come pesi nel mondo delle reti neurali artificiali) addestrati per rilevare caratteristiche specifiche. Il filtro si sposta sull'intera immagine per verificare se viene rilevata o meno la presenza di qualche caratteristica. Il filtro esegue l'operazione di convoluzione per fornire un valore finale che rappresenti la certezza della presenza di una particolare caratteristica.
Se una caratteristica è presente nell'immagine, il risultato dell'operazione di convoluzione è un numero positivo con un valore alto. Se la funzione è assente, l'operazione di convoluzione risulta in 0 o in un numero di valore molto basso.
Capiamolo meglio usando un esempio. Nell'immagine sottostante, un filtro è stato addestrato per rilevare un segno più. Quindi, il filtro viene passato sull'immagine originale. Poiché una parte dell'immagine originale contiene le stesse funzionalità per le quali è stato eseguito il training del filtro, i valori in ciascuna cella in cui esiste la funzionalità è un numero positivo. Allo stesso modo, anche il risultato di un'operazione di convoluzione risulterà in un numero elevato.
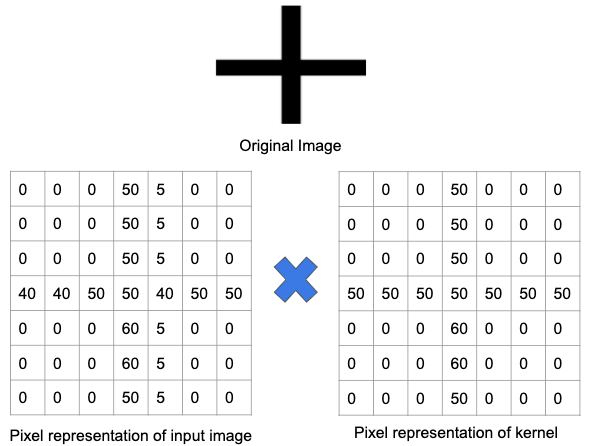
Tuttavia, quando lo stesso filtro viene passato su un'immagine con un diverso insieme di caratteristiche e bordi, l'output di un'operazione di convoluzione sarà inferiore, il che implica che non c'era una forte presenza di alcun segno più nell'immagine.
Quindi, nel caso di immagini complesse con varie caratteristiche come curve, bordi, colori e così via, avremo bisogno di un numero N di tali rilevatori di caratteristiche.
Quando questo filtro viene passato attraverso l'immagine, viene generata una mappa delle caratteristiche che è fondamentalmente la matrice di output che memorizza le convoluzioni di questo filtro su diverse parti dell'immagine. Nel caso di molti filtri, ci ritroveremo con un output 3D. Questo filtro dovrebbe avere lo stesso numero di canali dell'immagine di input affinché l'operazione di convoluzione abbia luogo.
Inoltre, è possibile far scorrere un filtro sull'immagine di input a intervalli diversi, utilizzando un valore di falcata. Il valore del passo indica quanto deve spostarsi il filtro ad ogni passo.
Il numero di strati di output di un dato blocco convoluzionale può quindi essere determinato utilizzando la seguente formula:

2. Imbottitura
Un problema quando si lavora con i livelli convoluzionali è che alcuni pixel tendono a perdersi sul perimetro dell'immagine originale. Poiché generalmente i filtri utilizzati sono piccoli, i pixel persi per filtro potrebbero essere pochi, ma questo si somma quando applichiamo diversi livelli convoluzionali, con conseguente perdita di molti pixel.
Il concetto di riempimento riguarda l'aggiunta di pixel extra all'immagine mentre un filtro di una CNN la sta elaborando. Questa è una soluzione per aiutare il filtro nell'elaborazione delle immagini, riempiendo l'immagine con zeri per consentire più spazio al kernel per coprire l'intera immagine. Aggiungendo zero padding ai filtri, l'elaborazione delle immagini da parte della CNN è molto più accurata ed esatta.
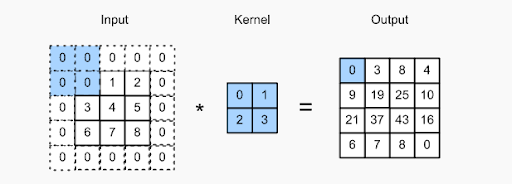

Controlla l'immagine sopra: il riempimento è stato eseguito aggiungendo zeri aggiuntivi al confine dell'immagine di input. Ciò consente l'acquisizione di tutte le caratteristiche distinte senza perdere alcun pixel.
3. Mappa di attivazione
Le mappe delle caratteristiche devono essere passate attraverso una funzione di mappatura di natura non lineare. Le mappe delle caratteristiche sono incluse con un termine di bias e quindi passate attraverso la funzione di attivazione (ReLu), che non è lineare. Questa funzione mira a portare una certa non linearità nella CNN poiché anche le immagini che vengono rilevate ed esaminate sono di natura non lineare, essendo composte da oggetti diversi.
4. Fase di raggruppamento
Una volta terminata la fase di attivazione, si passa alla fase di pooling, in cui la CNN effettua il downsampling delle funzionalità convolte, che aiutano a risparmiare tempo di elaborazione. Ciò aiuta anche a ridurre le dimensioni complessive dell'immagine, l'overfitting e altri problemi che si verificherebbero se le reti neurali contorte venissero alimentate con molte informazioni, specialmente se tali informazioni non sono troppo rilevanti per la classificazione o il rilevamento dell'immagine.
Il pooling è fondamentalmente di due tipi: pooling massimo e pooling minimo. Nel primo, una finestra viene passata sull'immagine in base a un valore di falcata impostato e, ad ogni passaggio, il valore massimo incluso nella finestra viene raggruppato nella matrice di output. Nel pooling minimo, i valori minimi vengono raggruppati nella matrice di output.
La nuova matrice che si è formata come risultato degli output è chiamata mappa di funzionalità in pool.
Tra il min e il max pooling, uno dei vantaggi del max pooling è che consente alla CNN di concentrarsi su alcuni neuroni che hanno valori elevati invece di concentrarsi su tutti i neuroni. Un tale approccio rende molto meno probabile l'overfitting dei dati di addestramento e fa andare bene la previsione e la generalizzazione complessive.
5. Appiattimento
Al termine del raggruppamento, la rappresentazione 3D dell'immagine è stata ora convertita in un vettore di caratteristiche. Questo viene quindi passato in un perceptron multistrato per produrre l'output. Guarda l'immagine qui sotto per capire meglio l'operazione di appiattimento:
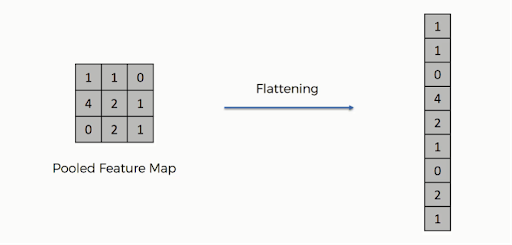
Come puoi vedere, le righe della matrice sono concatenate in un unico vettore di caratteristiche. Se sono presenti più livelli di input, tutte le righe sono collegate per formare un vettore di feature appiattito più lungo.
6. Livello completamente connesso (FCL)
In questo passaggio, la mappa appiattita viene inviata a una rete neurale. La connessione completa di una rete neurale include un livello di input, l'FCL e un livello di output finale. Lo strato completamente connesso può essere inteso come gli strati nascosti nelle reti neurali artificiali, tranne per il fatto che, a differenza degli strati nascosti, questi strati sono completamente connessi. Le informazioni passano attraverso l'intera rete e viene calcolato un errore di previsione. Questo errore viene quindi inviato come feedback (backpropagation) attraverso i sistemi per regolare i pesi e migliorare l'output finale, per renderlo più accurato.
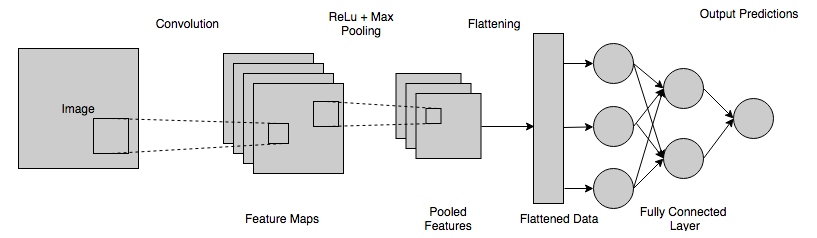
L'output finale ottenuto dallo strato sopra della rete neurale generalmente non è uno. Questi output devono essere ridotti a numeri nell'intervallo [0,1], che rappresenteranno quindi le probabilità di ciascuna classe. Per questo viene utilizzata la funzione Softmax.
L'uscita ottenuta dallo strato denso viene alimentata alla funzione di attivazione di Softmax. Attraverso questo, tutti gli output finali vengono mappati su un vettore in cui la somma di tutti gli elementi risulta essere uno.
Il livello completamente connesso funziona esaminando l'output del livello precedente e quindi determinando quale caratteristica è maggiormente correlata a una classe specifica. Pertanto, se il programma prevede se un'immagine contiene o meno un gatto, avrà valori elevati nelle mappe di attivazione che rappresentano caratteristiche come quattro zampe, zampe, coda e così via. Allo stesso modo, se il programma prevede qualcos'altro, avrà diversi tipi di mappe di attivazione. Un livello completamente connesso si occupa delle diverse caratteristiche che sono fortemente correlate a classi e pesi particolari in modo che il calcolo tra i pesi e il livello precedente sia accurato e si ottengano probabilità corrette per classi di output distinte.
Un breve riassunto del funzionamento delle CNN
Ecco un breve riassunto dell'intero processo di come funziona la CNN e aiuta nella visione artificiale:
- I diversi pixel dell'immagine vengono inviati allo strato convoluzionale, dove viene eseguita un'operazione di convoluzione.
- Il passaggio precedente risulta in una mappa contorta.
- Questa mappa viene passata attraverso una funzione raddrizzatore per dare origine a una mappa rettificata.
- L'immagine viene elaborata con diverse convoluzioni e funzioni di attivazione per individuare e rilevare diverse caratteristiche.
- I livelli di raggruppamento vengono utilizzati per identificare parti specifiche e distinte dell'immagine.
- Il livello in pool viene appiattito e utilizzato come input per il livello completamente connesso.
- Lo strato completamente connesso calcola le probabilità e fornisce un output nell'intervallo [0,1].
In conclusione
Il funzionamento interno della CNN è molto eccitante e apre molte possibilità per l'innovazione e la creazione. Allo stesso modo, altre tecnologie sotto l'ombrello dell'Intelligenza Artificiale sono affascinanti e stanno cercando di lavorare tra le capacità umane e l'intelligenza artificiale. Di conseguenza, persone provenienti da tutto il mondo, appartenenti a domini diversi, stanno realizzando il loro interesse in questo campo e stanno muovendo i primi passi.
Fortunatamente, l'industria dell'IA è eccezionalmente accogliente e non fa distinzione in base al tuo background accademico. Tutto ciò di cui hai bisogno è una conoscenza pratica delle tecnologie insieme alle qualifiche di base e sei pronto!
Se desideri padroneggiare il nocciolo della questione di ML e AI, la linea d'azione ideale sarebbe iscriverti a un programma di AI/ML professionale. Ad esempio, il nostro programma esecutivo in Machine Learning e AI è il corso perfetto per gli aspiranti alla scienza dei dati. Il programma copre argomenti come la statistica e l'analisi dei dati esplorativi, l'apprendimento automatico e l'elaborazione del linguaggio naturale. Inoltre, include oltre 13 progetti di settore, oltre 25 sessioni dal vivo e 6 progetti capstone. La parte migliore di questo corso è che puoi interagire con colleghi di tutto il mondo. Facilita lo scambio di idee e aiuta gli studenti a costruire connessioni durature con persone di diversa estrazione. La nostra assistenza professionale a 360 gradi è proprio ciò di cui hai bisogno per eccellere nel tuo percorso ML e AI!
Guida la rivoluzione tecnologica guidata dall'intelligenza artificiale