
Teorema di Bayes nell'apprendimento automatico: introduzione, come applicare ed esempio
Pubblicato: 2021-02-04Sommario
Introduzione: cos'è il teorema di Bayes?
Il teorema di Bayes prende il nome dal matematico inglese Thomas Bayes, che lavorò a lungo nella teoria delle decisioni, il campo della matematica che coinvolge le probabilità. Il teorema di Bayes è anche ampiamente utilizzato nell'apprendimento automatico, dove è un modo semplice ed efficace per prevedere le classi con precisione e accuratezza. Il metodo bayesiano di calcolo delle probabilità condizionali viene utilizzato nelle applicazioni di apprendimento automatico che implicano attività di classificazione.
Una versione semplificata del teorema di Bayes, nota come Naive Bayes Classification, viene utilizzata per ridurre i tempi ei costi di calcolo. In questo articolo, ti guideremo attraverso questi concetti e discutiamo le applicazioni del teorema di Bayes nell'apprendimento automatico.
Partecipa al corso di machine learning online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzata in ML e AI per accelerare la tua carriera.
Perché usare il teorema di Bayes in Machine Learning?
Il teorema di Bayes è un metodo per determinare le probabilità condizionali, ovvero la probabilità che si verifichi un evento dato che un altro evento si è già verificato. Poiché una probabilità condizionale include condizioni aggiuntive, in altre parole, più dati, può contribuire a risultati più accurati.
Pertanto, le probabilità condizionali sono un must per determinare previsioni e probabilità accurate in Machine Learning. Dato che il campo sta diventando sempre più onnipresente in una varietà di domini, è importante comprendere il ruolo di algoritmi e metodi come il teorema di Bayes in Machine Learning.
Prima di entrare nel teorema stesso, comprendiamo alcuni termini attraverso un esempio. Supponiamo che un manager di una libreria abbia informazioni sull'età e sul reddito dei suoi clienti. Vuole sapere come sono distribuite le vendite di libri su tre classi di età dei clienti: giovani (18-35), persone di mezza età (35-60) e anziani (60+).

Chiamiamo i nostri dati X. Nella terminologia bayesiana, X è chiamato evidenza. Abbiamo qualche ipotesi H, dove abbiamo qualche X che appartiene ad una certa classe C.
Il nostro obiettivo è determinare la probabilità condizionata della nostra ipotesi H data X, cioè P(H | X).
In parole povere, determinando P(H | X), otteniamo la probabilità che X appartenga alla classe C, dato X. X ha attributi di età e reddito – diciamo, per esempio, 26 anni con un reddito di $2000. H è la nostra ipotesi che il cliente acquisterà il libro.
Prestare molta attenzione ai seguenti quattro termini:
- Evidenza – Come discusso in precedenza, P(X) è noto come evidenza. È semplicemente la probabilità che il cliente, in questo caso, abbia 26 anni e guadagni $ 2000.
- Probabilità a priori – P(H), nota come probabilità a priori, è la semplice probabilità della nostra ipotesi, ovvero che il cliente acquisterà un libro. Questa probabilità non sarà fornita con alcun input aggiuntivo basato sull'età e sul reddito. Poiché il calcolo viene eseguito con informazioni minori, il risultato è meno accurato.
- Probabilità posteriore – P(H | X) è nota come probabilità posteriore. Qui, P(H | X) è la probabilità che il cliente acquisti un libro (H) dato X (che ha 26 anni e guadagna $ 2000).
- Probabilità – P(X | H) è la probabilità di verosimiglianza. In questo caso, dato che sappiamo che il cliente acquisterà il libro, la probabilità di verosimiglianza è la probabilità che il cliente abbia 26 anni e abbia un reddito di $ 2000.
Dati questi, il teorema di Bayes afferma:
P(H | X) = [ P(X | H) * P(H) ] / P(X)
Nota l'aspetto dei quattro termini sopra nel teorema: probabilità a posteriori, probabilità di verosimiglianza, probabilità a priori e prove.
Leggi: Spiegazione di Naive Bayes
Come applicare il teorema di Bayes in Machine Learning
Il Naive Bayes Classifier, una versione semplificata del teorema di Bayes, viene utilizzato come algoritmo di classificazione per classificare i dati in varie classi con precisione e velocità.
Vediamo come il classificatore Naive Bayes può essere applicato come algoritmo di classificazione.
- Si consideri un esempio generale: X è un vettore costituito da 'n' attributi, ovvero X = {x1, x2, x3, …, xn}.
- Supponiamo di avere 'm' classi {C1, C2, …, Cm}. Il nostro classificatore dovrà prevedere che X appartenga a una certa classe. La classe che offre la probabilità a posteriori più alta sarà scelta come classe migliore. Quindi, matematicamente, il classificatore predice per la classe Ci se P(Ci | X) > P(Cj | X). Applicazione del teorema di Bayes:
P(Ci | X) = [ P(X | Ci) * P(Ci) ] / P(X)
- P(X), essendo indipendente dalla condizione, è costante per ogni classe. Quindi per massimizzare P(Ci | X), dobbiamo massimizzare [P(X | Ci) * P(Ci)]. Considerando che ogni classe è ugualmente probabile, abbiamo P(C1) = P(C2) = P(C3) … = P(Cn). Quindi, in definitiva, dobbiamo massimizzare solo P(X | Ci).
- Poiché è probabile che il tipico set di dati di grandi dimensioni abbia diversi attributi, è computazionalmente costoso eseguire l'operazione P(X | Ci) per ciascun attributo. È qui che entra in gioco l'indipendenza condizionale di classe per semplificare il problema e ridurre i costi di calcolo. Per indipendenza condizionale di classe, intendiamo che consideriamo i valori dell'attributo indipendenti l'uno dall'altro in modo condizionale. Questa è la classificazione Naive Bayes.
P(Xi | C) = P(x1 | C) * P(x2 | C) *… * P(xn | C)
Ora è facile calcolare le probabilità più piccole. Una cosa importante da notare qui: poiché xk appartiene a ciascun attributo, dobbiamo anche verificare se l'attributo di cui abbiamo a che fare è categoriale o continuo .
- Se abbiamo un attributo categoriale , le cose sono più semplici. Possiamo semplicemente contare il numero di istanze della classe Ci costituite dal valore xk per l'attributo k e poi dividerlo per il numero di istanze della classe Ci.
- Se abbiamo un attributo continuo, considerando che abbiamo una funzione di distribuzione normale, applichiamo la seguente formula, con media ? e deviazione standard?:
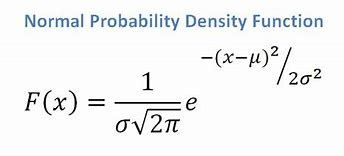

Fonte
In definitiva, avremo P(x | Ci) = F(xk, ?k, ?k).
- Ora, abbiamo tutti i valori di cui abbiamo bisogno per usare il teorema di Bayes per ogni classe Ci. La nostra classe prevista sarà la classe che raggiunge la più alta probabilità P(X | Ci) * P(Ci).
Esempio: Classificazione predittiva dei clienti di una libreria
Abbiamo il seguente set di dati da una libreria:
| Età | Reddito | Alunno | Credit_Rating | Compra_Libro |
| Gioventù | Alto | No | Equo | No |
| Gioventù | Alto | No | Eccellente | No |
| Di mezza età | Alto | No | Equo | sì |
| Anziano | medio | No | Equo | sì |
| Anziano | Basso | sì | Equo | sì |
| Anziano | Basso | sì | Eccellente | No |
| Di mezza età | Basso | sì | Eccellente | sì |
| Gioventù | medio | No | Equo | No |
| Gioventù | Basso | sì | Equo | sì |
| Anziano | medio | sì | Equo | sì |
| Gioventù | medio | sì | Eccellente | sì |
| Di mezza età | medio | No | Eccellente | sì |
| Di mezza età | Alto | sì | Equo | sì |
| Anziano | medio | No | Eccellente | No |
Abbiamo attributi come età, reddito, studente e rating del credito. La nostra classe, buys_book, ha due risultati: Sì o No.
Il nostro obiettivo è classificare in base ai seguenti attributi:
X = {età = gioventù, studente = sì, reddito = medio, credit_rating = discreto}.
Come mostrato in precedenza, per massimizzare P(Ci | X), dobbiamo massimizzare [ P(X | Ci) * P(Ci) ] per i = 1 e i = 2.
Quindi, P(buys_book = yes) = 9/14 = 0,643
P(acquista_libro = no) = 14/5 = 0,357
P(età = gioventù | buys_book = sì) = 2/9 = 0,222
P(età = gioventù | buys_book = no) =3/5 = 0,600
P(reddito = medio | buys_book = sì) = 4/9 = 0,444
P(reddito = medio | buys_book = no) = 2/5 = 0,400
P(studente = sì | compra_libro = sì) = 6/9 = 0,667
P(studente = sì | compra_libro = no) = 1/5 = 0,200
P(credit_rating = discreto | buys_book = sì) = 6/9 = 0,667
P(credit_rating = discreto | buys_book = no) = 2/5 = 0,400
Usando le probabilità sopra calcolate, abbiamo
P(X | compra_libro = sì) = 0,222 x 0,444 x 0,667 x 0,667 = 0,044
Allo stesso modo,
P(X | compra_libro = no) = 0,600 x 0,400 x 0,200 x 0,400 = 0,019
Quale classe Ci fornisce il massimo P(X|Ci)*P(Ci)? Calcoliamo:
P(X | libro_acquista = sì)* P(libro_acquisto = sì) = 0,044 x 0,643 = 0,028
P(X | libro_acquista = no)* P(libro_acquisto = no) = 0,019 x 0,357 = 0,007
Confrontando i due precedenti, poiché 0,028 > 0,007, il classificatore Naive Bayes prevede che il cliente con gli attributi sopra menzionati acquisterà un libro.
Checkout: idee e argomenti per progetti di apprendimento automatico
Il classificatore bayesiano è un buon metodo?
Gli algoritmi basati sul teorema di Bayes nell'apprendimento automatico forniscono risultati paragonabili ad altri algoritmi e i classificatori bayesiani sono generalmente considerati semplici metodi ad alta precisione. Tuttavia, occorre prestare attenzione a ricordare che i classificatori bayesiani sono particolarmente appropriati laddove l'assunzione dell'indipendenza condizionale di classe è valida e non in tutti i casi. Un'altra preoccupazione pratica è che l'acquisizione di tutti i dati di probabilità potrebbe non essere sempre fattibile.
Conclusione
Il teorema di Bayes ha molte applicazioni nell'apprendimento automatico, in particolare nei problemi basati sulla classificazione. L'applicazione di questa famiglia di algoritmi nell'apprendimento automatico implica la familiarità con termini come probabilità a priori e probabilità a posteriori. In questo articolo, abbiamo discusso le basi del teorema di Bayes, il suo utilizzo nei problemi di apprendimento automatico e abbiamo elaborato un esempio di classificazione.
Poiché il teorema di Bayes costituisce una parte cruciale degli algoritmi basati sulla classificazione in Machine Learning, puoi saperne di più sul programma di certificazione avanzata di upGrad in Machine Learning e NLP . Questo corso è stato creato tenendo a mente vari tipi di studenti interessati all'apprendimento automatico, offrendo tutoraggio 1-1 e molto altro.
Perché utilizziamo il teorema di Bayes in Machine Learning?
Il teorema di Bayes è un metodo per calcolare le probabilità condizionali o la probabilità che un evento si verifichi se un altro si è verificato in precedenza. Una probabilità condizionata può portare a risultati più accurati includendo condizioni extra, in altre parole, più dati. Per ottenere stime e probabilità corrette in Machine Learning, sono necessarie le probabilità condizionali. Data la crescente prevalenza del campo in un'ampia gamma di domini, è fondamentale comprendere l'importanza di algoritmi e approcci come il teorema di Bayes in Machine Learning.
Il classificatore bayesiano è una buona scelta?
Nell'apprendimento automatico, gli algoritmi basati sul teorema di Bayes producono risultati paragonabili a quelli di altri metodi e i classificatori bayesiani sono ampiamente considerati come semplici approcci ad alta precisione. Tuttavia, è importante tenere presente che i classificatori bayesiani sono utilizzati al meglio quando la condizione di indipendenza condizionale di classe è corretta, non in tutte le circostanze. Un'altra considerazione è che l'ottenimento di tutti i dati di probabilità potrebbe non essere sempre possibile.
Come si può applicare praticamente il teorema di Bayes?
Il teorema di Bayes calcola la probabilità che si verifichi sulla base di nuove prove che sono o potrebbero essere correlate ad essa. Il metodo può essere utilizzato anche per vedere in che modo ipotetiche nuove informazioni influiscono sulla probabilità di un evento, supponendo che le nuove informazioni siano vere. Prendi, ad esempio, una singola carta selezionata da un mazzo di 52 carte. La probabilità che la carta diventi un re è 4 diviso per 52, o 1/13, o circa il 7,69%. Tieni presente che il mazzo contiene quattro re. Diciamo che è stato rivelato che la carta scelta è una figura. Poiché ci sono 12 figure in un mazzo, la probabilità che la carta scelta sia un re è 4 diviso 12, ovvero circa il 33,3%.