
6 funzionalità che cambiano il gioco di Apache Spark nel 2022 [Come dovresti usare]
Pubblicato: 2021-01-07Da quando i Big Data hanno preso d'assalto il mondo della tecnologia e degli affari, c'è stato un enorme aumento di strumenti e piattaforme per Big Data, in particolare di Apache Hadoop e Apache Spark. Oggi ci concentreremo esclusivamente su Apache Spark e discuteremo a lungo dei vantaggi e delle applicazioni aziendali.
Apache Spark è arrivato alla ribalta nel 2009 e da allora si è gradualmente ritagliato una nicchia nel settore. Secondo Apache org., Spark è un "motore di analisi unificato velocissimo" progettato per l'elaborazione di enormi quantità di Big Data. Grazie a una community attiva, oggi Spark è una delle piattaforme Big Data open source più grandi al mondo.
Sommario
Cos'è Apache Spark?
Sviluppato originariamente nell'AMPLab dell'Università della California (Berkeley), Spark è stato progettato come un robusto motore di elaborazione per i dati Hadoop, con particolare attenzione alla velocità e alla facilità d'uso. È un'alternativa open source a MapReduce di Hadoop. In sostanza, Spark è un framework di elaborazione dati parallelo che può collaborare con Apache Hadoop per facilitare lo sviluppo fluido e veloce di sofisticate applicazioni Big Data su Hadoop.
Spark viene fornito con un'ampia gamma di librerie per algoritmi di Machine Learning (ML) e algoritmi grafici. Non solo, supporta anche lo streaming in tempo reale e le app SQL tramite Spark Streaming e Shark, rispettivamente. La parte migliore dell'utilizzo di Spark è che puoi scrivere app Spark in Java, Scala o persino Python e queste app verranno eseguite quasi dieci volte più velocemente (su disco) e 100 volte più velocemente (in memoria) rispetto alle app MapReduce.
Apache Spark è abbastanza versatile in quanto può essere distribuito in molti modi e offre anche collegamenti nativi per i linguaggi di programmazione Java, Scala, Python e R. Supporta SQL, elaborazione di grafici, streaming di dati e Machine Learning. Questo è il motivo per cui Spark è ampiamente utilizzato in vari settori del settore, comprese banche, società di telecomunicazioni, società di sviluppo di giochi, agenzie governative e, naturalmente, in tutte le migliori aziende del mondo tecnologico: Apple, Facebook, IBM e Microsoft.
6 migliori caratteristiche di Apache Spark
Le caratteristiche che rendono Spark una delle piattaforme Big Data più utilizzate sono:

1. Velocità di elaborazione ultrarapida
L'elaborazione dei Big Data consiste nell'elaborazione di grandi volumi di dati complessi. Pertanto, quando si tratta di elaborazione di Big Data, le organizzazioni e le imprese desiderano tali framework in grado di elaborare enormi quantità di dati ad alta velocità. Come accennato in precedenza, le app Spark possono essere eseguite fino a 100 volte più velocemente in memoria e 10 volte più veloci su disco nei cluster Hadoop.
Si basa su Resilient Distributed Dataset (RDD) che consente a Spark di archiviare i dati in memoria in modo trasparente e di leggerli/scriverli su disco solo se necessario. Questo aiuta a ridurre la maggior parte del tempo di lettura e scrittura del disco durante l'elaborazione dei dati.
2. Facilità d'uso
Spark ti consente di scrivere applicazioni scalabili in Java, Scala, Python e R. In questo modo, gli sviluppatori hanno la possibilità di creare ed eseguire applicazioni Spark nei loro linguaggi di programmazione preferiti. Inoltre, Spark è dotato di un set integrato di oltre 80 operatori di alto livello. Puoi utilizzare Spark in modo interattivo per eseguire query sui dati da shell Scala, Python, R e SQL.
3. Offre supporto per analisi sofisticate
Spark non solo supporta semplici operazioni di "mappa" e "riduzione", ma supporta anche query SQL, streaming di dati e analisi avanzate, inclusi algoritmi ML e grafici. Viene fornito con un potente stack di librerie come SQL & DataFrames e MLlib (per ML), GraphX e Spark Streaming. La cosa affascinante è che Spark ti consente di combinare le capacità di tutte queste librerie all'interno di un unico flusso di lavoro/applicazione.
4. Elaborazione del flusso in tempo reale
Spark è progettato per gestire lo streaming di dati in tempo reale. Sebbene MapReduce sia progettato per gestire ed elaborare i dati già archiviati nei cluster Hadoop, Spark può eseguire entrambe le operazioni e anche manipolare i dati in tempo reale tramite Spark Streaming.
A differenza di altre soluzioni di streaming, Spark Streaming può recuperare il lavoro perso e fornire immediatamente la semantica esatta senza richiedere codice o configurazione aggiuntivi. Inoltre, ti consente anche di riutilizzare lo stesso codice per l'elaborazione in batch e in streaming e persino per unire i dati in streaming ai dati storici.
5. È flessibile
Spark può essere eseguito in modo indipendente in modalità cluster e può anche essere eseguito su Hadoop YARN, Apache Mesos, Kubernetes e persino nel cloud. Inoltre, può accedere a diverse fonti di dati. Ad esempio, Spark può essere eseguito sul gestore di cluster YARN e leggere tutti i dati Hadoop esistenti. Può leggere da qualsiasi origine dati Hadoop come HBase, HDFS, Hive e Cassandra. Questo aspetto di Spark lo rende uno strumento ideale per la migrazione di applicazioni Hadoop pure, a condizione che il caso d'uso delle app sia compatibile con Spark.
6. Comunità attiva e in espansione
Gli sviluppatori di oltre 300 aziende hanno contribuito a progettare e realizzare Apache Spark. Dal 2009, più di 1200 sviluppatori hanno contribuito attivamente a rendere Spark quello che è oggi! Naturalmente, Spark è supportato da una comunità attiva di sviluppatori che lavorano per migliorare continuamente le sue funzionalità e prestazioni. Per contattare la community di Spark, puoi utilizzare le mailing list per qualsiasi domanda e puoi anche partecipare a gruppi di incontro e conferenze di Spark.
L'anatomia delle applicazioni Spark
Ogni applicazione Spark comprende due processi principali: un processo driver primario e una raccolta di processi esecutori .
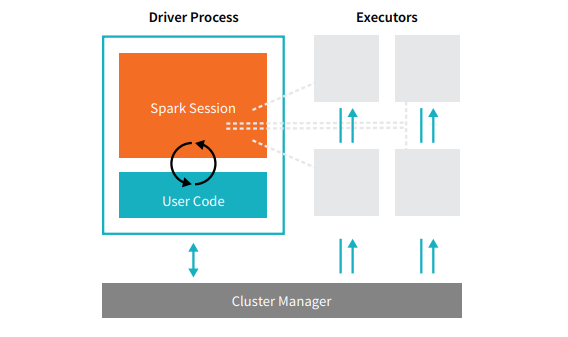
Fonte
Il processo del driver che si trova su un nodo nel cluster è responsabile dell'esecuzione della funzione main(). Gestisce anche altre tre attività: mantenimento delle informazioni sull'applicazione Spark, risposta al codice o input di un utente e analisi, distribuzione e pianificazione del lavoro tra gli esecutori. Il processo del driver costituisce il cuore di un'applicazione Spark: contiene e mantiene tutte le informazioni critiche che coprono la durata dell'applicazione Spark.

Gli esecutori oi processi esecutori sono elementi secondari che devono eseguire il compito loro assegnato dal driver. Fondamentalmente, ogni esecutore svolge due funzioni cruciali: eseguire il codice assegnatogli dal driver e segnalare lo stato del calcolo (su quell'esecutore) al nodo del driver. Gli utenti possono decidere e configurare quanti esecutori dovrebbe avere ogni nodo.
In un'applicazione Spark, il gestore cluster controlla tutte le macchine e alloca le risorse all'applicazione. In questo caso, il gestore del cluster può essere uno qualsiasi dei gestori di cluster principali di Spark, incluso YARN (il gestore di cluster autonomo di Spark) o Mesos. Ciò implica che un cluster può eseguire più applicazioni Spark contemporaneamente.
Applicazioni Apache Spark nel mondo reale
Spark è una piattaforma Big Dara di prim'ordine e ampiamente utilizzata nell'industria moderna. Alcuni degli esempi reali più acclamati di applicazioni Apache Spark sono:
Spark per l'apprendimento automatico
Apache Spark vanta una libreria di Machine Learning scalabile: MLlib. Questa libreria è progettata esplicitamente per semplicità, scalabilità e per facilitare la perfetta integrazione con altri strumenti. MLlib non solo possiede la scalabilità, la compatibilità linguistica e la velocità di Spark, ma può anche eseguire una serie di attività di analisi avanzate come classificazione, clustering e riduzione della dimensionalità. Grazie a MLlib, Spark può essere utilizzato per analisi predittive, analisi del sentiment, segmentazione dei clienti e intelligence predittiva.
Un'altra caratteristica impressionante di Apache Spark risiede nel dominio di sicurezza della rete. Spark Streaming consente agli utenti di monitorare i pacchetti di dati in tempo reale prima di inviarli allo storage. Durante questo processo, può identificare con successo tutte le attività sospette o dannose che derivano da fonti note di minaccia. Anche dopo che i pacchetti di dati sono stati inviati allo storage, Spark utilizza MLlib per analizzare ulteriormente i dati e identificare potenziali rischi per la rete. Questa funzione può essere utilizzata anche per il rilevamento di frodi ed eventi.
Spark per il calcolo della nebbia
Apache Spark è uno strumento eccellente per il fog computing, in particolare quando si tratta di Internet of Things (IoT). L'IoT si basa fortemente sul concetto di elaborazione parallela su larga scala. Poiché la rete IoT è composta da migliaia e milioni di dispositivi connessi, i dati generati da questa rete ogni secondo sono oltre la comprensione.
Naturalmente, per elaborare volumi così grandi di dati prodotti dai dispositivi IoT, è necessaria una piattaforma scalabile che supporti l'elaborazione parallela. E cosa c'è di meglio della robusta architettura e delle capacità di fog computing di Spark per gestire quantità così grandi di dati!
Il fog computing decentralizza i dati e l'archiviazione e, invece di utilizzare l'elaborazione cloud, esegue la funzione di elaborazione dei dati ai margini della rete (principalmente incorporata nei dispositivi IoT).
Per fare ciò, il fog computing richiede tre funzionalità, vale a dire, bassa latenza, elaborazione parallela di ML e algoritmi di analisi dei grafici complessi, ognuno dei quali è presente in Spark. Inoltre, la presenza di Spark Streaming, Shark (uno strumento di query interattivo che può funzionare in tempo reale), MLlib e GraphX (un motore di analisi dei grafici) migliora ulteriormente la capacità di calcolo della nebbia di Spark.
Spark per l'analisi interattiva
A differenza di MapReduce, Hive o Pig, che hanno una velocità di elaborazione relativamente bassa, Spark può vantare analisi interattive ad alta velocità. È in grado di gestire query esplorative senza richiedere il campionamento dei dati. Inoltre, Spark è compatibile con quasi tutti i più diffusi linguaggi di sviluppo, inclusi R, Python, SQL, Java e Scala.
L'ultima versione di Spark - Spark 2.0 - presenta una nuova funzionalità nota come Streaming strutturato. Con questa funzione, gli utenti possono eseguire query strutturate e interattive sui dati in streaming in tempo reale.
Utenti di Spark
Ora che conosci bene le caratteristiche e le capacità di Spark, parliamo dei quattro utenti di spicco di Spark!
1. Yahoo
Yahoo utilizza Spark per due dei suoi progetti, uno per personalizzare le pagine di notizie per i visitatori e l'altro per eseguire analisi per la pubblicità. Per personalizzare le pagine delle notizie, Yahoo utilizza algoritmi ML avanzati in esecuzione su Spark per comprendere gli interessi, le preferenze e le esigenze dei singoli utenti e classificare le storie di conseguenza.
Per il secondo caso d'uso, Yahoo sfrutta la capacità interattiva di Hive on Spark (da integrare con qualsiasi strumento che si colleghi ad Hive) per visualizzare e interrogare i dati analitici pubblicitari di Yahoo raccolti su Hadoop.
2. Uber
Uber utilizza Spark Streaming in combinazione con Kafka e HDFS per ETL (estrae, trasforma e carica) grandi quantità di dati in tempo reale di eventi discreti in dati strutturati e utilizzabili per ulteriori analisi. Questi dati aiutano Uber a ideare soluzioni migliori per i clienti.

3. Convive
In qualità di azienda di streaming video, Conviva ottiene una media di oltre 4 milioni di feed video ogni mese, il che porta a un'enorme abbandono dei clienti. Questa sfida è ulteriormente aggravata dal problema della gestione del traffico video in diretta. Per combattere efficacemente queste sfide, Conviva utilizza Spark Streaming per apprendere le condizioni della rete in tempo reale e ottimizzare di conseguenza il proprio traffico video. Ciò consente a Conviva di fornire agli utenti un'esperienza di visualizzazione coerente e di alta qualità.
4. Pinterest
Su Pinterest, gli utenti possono appuntare i loro argomenti preferiti come e quando vogliono mentre navigano sul Web e sui social media. Per offrire un'esperienza cliente personalizzata e migliorata, Pinterest utilizza le capacità ETL di Spark per identificare le esigenze e gli interessi unici dei singoli utenti e fornire loro consigli pertinenti su Pinterest.
Conclusione
Per concludere, Spark è una piattaforma Big Data estremamente versatile con funzionalità create per stupire. Poiché si tratta di un framework open source, è in continuo miglioramento ed evoluzione, con l'aggiunta di nuove funzionalità e funzionalità. Man mano che le applicazioni dei Big Data diventeranno più diversificate ed espansive, lo saranno anche i casi d'uso di Apache Spark.
Se sei interessato a saperne di più sui Big Data, dai un'occhiata al nostro PG Diploma in Software Development Specialization nel programma Big Data, progettato per professionisti che lavorano e fornisce oltre 7 casi di studio e progetti, copre 14 linguaggi e strumenti di programmazione, pratiche pratiche workshop, oltre 400 ore di apprendimento rigoroso e assistenza all'inserimento lavorativo con le migliori aziende.
Controlla i nostri altri corsi di ingegneria del software su upGrad.