
Architettura Apache Kafka: guida completa per principianti [2022]
Pubblicato: 2021-12-23Prima di approfondire i dettagli dell'architettura di Apache Kafka, è opportuno chiarire il motivo per cui Kafka fa notizia in primo luogo. Per cominciare, Apache Kafka trova impiego principalmente nelle architetture di dati di streaming in tempo reale per fornire analisi in tempo reale. Durevole, veloce, scalabile e tollerante ai guasti, il sistema di messaggistica publish-subscribe di Kafka ha casi d'uso per cose come il monitoraggio dei dati dei sensori IoT o il monitoraggio delle chiamate di servizio.
Aziende come LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal e molte altre utilizzano Apache Kafka per l'elaborazione dei dati in streaming in tempo reale. Ad esempio, LinkedIn, da dove ha avuto origine Kafka, lo utilizza per tenere traccia delle metriche operative e dei dati sulle attività. Allo stesso modo, per Netflix, Apache Kafka è lo standard de facto per le sue esigenze di messaggistica, eventi ed elaborazione del flusso.
Impara la formazione online per lo sviluppo di software dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
L'utilità di Apache Kafka è meglio apprezzata con una comprensione dell'architettura Apache Kafka e dei suoi componenti sottostanti. Quindi, esploriamo i dettagli dell'architettura di Kafka.
Sommario
Concetti fondamentali di architettura Kafka
I seguenti concetti sono fondamentali per comprendere l'architettura di Apache Kafka:
1. Argomenti
Gli argomenti Kafka definiscono i canali attraverso i quali i dati vengono trasmessi. Pertanto, i produttori pubblicano messaggi sugli argomenti e i consumatori leggono i messaggi dagli argomenti a cui si iscrivono. Non ci sono limiti al numero di argomenti creati all'interno di un cluster Kafka e un nome univoco identifica ogni argomento.

2. Broker
I broker sono server in un cluster Kafka che funzionano come contenitori e contengono più argomenti con partizioni distinte. Un ID intero univoco identifica i broker in un cluster Kafka e una connessione con uno qualsiasi di questi broker significa connettersi con l'intero cluster.
3. Partizioni
Gli argomenti di Kafka sono divisi in molte parti note come partizioni. Le partizioni sono separate in ordine e consentono a più consumatori di leggere i dati da un determinato argomento in parallelo. Le partizioni di un argomento sono distribuite su diversi server nel cluster Kafka e ogni server gestisce i dati e le richieste per il proprio lotto di partizioni. I messaggi raggiungono il broker e una chiave e la chiave determina la partizione in cui andrà il messaggio particolare. Quindi, i messaggi con la stessa chiave vanno alla stessa partizione. Nel caso in cui la chiave non sia specificata, la partizione viene decisa seguendo un approccio round robin.
4. Repliche
In Kafka, le repliche sono come i backup delle partizioni per garantire l'assenza di perdita di dati in caso di arresto o guasto pianificato. In altre parole, le repliche sono copie di partizioni.
5. Offset di partizione
Poiché i messaggi oi record in Kafka sono assegnati alle partizioni, a ciascun record viene fornito un offset per specificarne la posizione all'interno della partizione. Pertanto, il valore di offset associato a un record aiuta nella sua facile identificazione all'interno della partizione. Un offset di partizione ha un significato solo all'interno di quella particolare partizione e poiché i record vengono aggiunti alle estremità della partizione, i record più vecchi avranno valori di offset inferiori.
6. Produttori
I produttori Kafka pubblicano messaggi su uno o più argomenti e inviano dati al cluster Kafka. Non appena un produttore pubblica un messaggio su un argomento Kafka, il broker riceve il messaggio e lo aggiunge a una partizione specifica. Quindi, i produttori possono scegliere la partizione in cui vogliono pubblicare il loro messaggio.
7. Consumatori e gruppi di consumatori
I consumatori leggono i messaggi dal cluster Kafka. Quando un consumatore è pronto a ricevere il messaggio, i dati vengono estratti dal broker. I consumatori appartengono a un gruppo di consumatori e ogni consumatore all'interno di un particolare gruppo è responsabile della lettura di un sottoinsieme delle partizioni di ogni argomento a cui è iscritto.
8. Leader e seguace
Ogni partizione Kafka ha un server che svolge il ruolo di leader. Il leader esegue tutte le attività di lettura e scrittura per quella particolare partizione. D'altra parte, il compito del follower è replicare i dati del leader. Quando un leader in una partizione specifica si guasta, uno dei nodi follower assume il ruolo di leader. Una partizione può avere nessuno o molti follower.
Il diagramma seguente è una presentazione semplificata delle interrelazioni tra i componenti dell'architettura Apache Kafka discussi sopra.
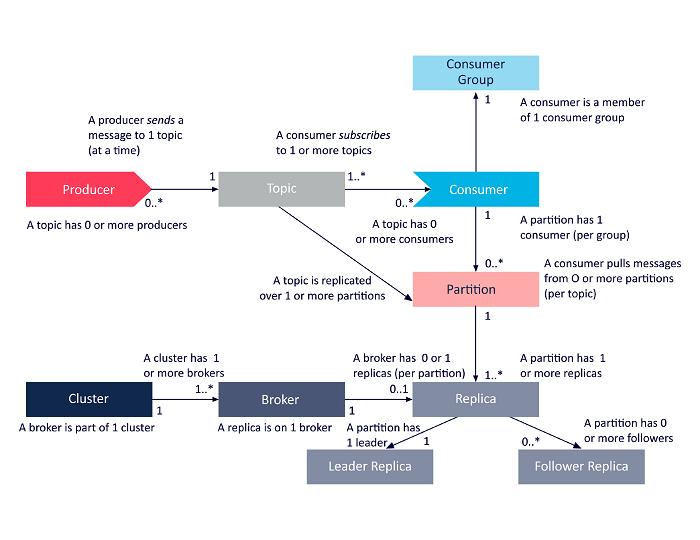
Fonte
Architettura del cluster Apache Kafka
Ecco uno sguardo dettagliato ai principali componenti dell'architettura Kafka:

1. Broker Kafka
I cluster Kafka in genere contengono più nodi noti come broker. I broker mantengono il bilanciamento del carico. Ogni broker Kafka può gestire centinaia e migliaia di letture e scritture ogni secondo. Un broker funge da leader per una particolare partizione. Il leader ha uno o più follower, con i dati sul leader replicati tra i follower di quella particolare partizione.
I follower devono rimanere aggiornati con i dati del leader. Il leader, a sua volta, tiene traccia dei follower che sono sincronizzati con esso. Se un follower non raggiunge il leader o non è più in vita, viene rimosso dall'elenco delle repliche sincronizzate associato al leader specifico. Un nuovo leader viene eletto tra i seguaci alla morte del leader e ZooKeeper supervisiona l'elezione. Poiché i broker sono senza stato, ZooKeeper mantiene il suo stato di cluster. I nodi in un cluster inviano messaggi heartbeat a ZooKeeper per informare quest'ultimo che sono attivi.
2. Produttori Kafka
I produttori Kafka inviano direttamente i dati ai broker che svolgono il ruolo di leader per una particolare partizione. I broker o nodi dei cluster Kafka aiutano i produttori a inviare messaggi diretti. Lo fanno rispondendo alle richieste di metadati su cui i server sono attivi e lo stato live dei leader della partizione di un argomento, consentendo al produttore di indirizzare le sue richieste di conseguenza. Il produttore decide quale partizione vuole pubblicare i messaggi. I messaggi in Kafka vengono inviati in batch, chiamati batch di record. I produttori raccolgono i messaggi in memoria e li inviano in batch dopo che è trascorso un periodo fisso o dopo che un certo numero di messaggi si è accumulato.
3. Consumatori Kafka
I consumatori Kafka inviano richieste ai broker indicando le partizioni che desidera consumare. Il consumatore specifica l'offset della partizione nella sua richiesta e riceve un pezzo di log (a partire dalla posizione di offset) dal broker. Un registro contiene i record per un periodo configurabile noto come periodo di conservazione.
I consumatori possono anche riutilizzare i dati purché il registro contenga i dati. I consumatori Kafka lavorano su un approccio basato sul pull, il che significa che i broker non inviano immediatamente i dati ai consumatori. Invece, in primo luogo, i consumatori inviano richieste ai broker segnalando che sono pronti a consumare dati. Pertanto, il sistema basato su pull garantisce che i consumatori non siano sopraffatti dai messaggi e possano recuperare se rimangono indietro.
Di seguito è riportato un diagramma dell'architettura Apache Kafka semplificato:
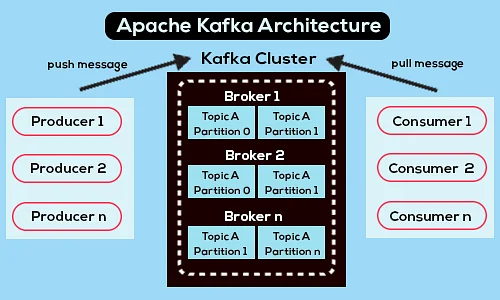
Fonte
Ulteriori informazioni su Apache Kafka.
Architettura dell'API Apache Kafka
Apache Kafka ha quattro API chiave: l'API Streams, l'API Connector, l'API Producer e l'API Consumer. Vediamo quale ruolo deve svolgere ciascuno nel migliorare le capacità di Apache Kafka:
1. Stream API
L'API Streams di Kafka consente a un'applicazione di elaborare i dati utilizzando un algoritmo di elaborazione dei flussi. Utilizzando l'API Streams, le applicazioni possono consumare flussi di input da uno o più argomenti, elaborarli con operazioni di flusso, produrre flussi di output ed eventualmente inviarli a uno o più argomenti. Pertanto, l'API Streams facilita la trasformazione dei flussi di input in flussi di output.
2. API del connettore
L'API Connector di Kafka è utile per creare, eseguire e gestire produttori e consumatori riutilizzabili che collegano argomenti Kafka a sistemi di dati o applicazioni esistenti. Ad esempio, un connettore a un database relazionale potrebbe acquisire tutti gli aggiornamenti e assicurarsi che le modifiche siano disponibili all'interno di un argomento Kafka.

3. API del produttore
L'API Producer di Kafka consente alle applicazioni di pubblicare un flusso di record su argomenti Kafka.
4. API di consumo
L'API consumer di Kafka Consente alle applicazioni di iscriversi agli argomenti di Kafka. Consente inoltre alle applicazioni di elaborare flussi di record prodotti per quegli argomenti Kafka.
Via avanti
L'architettura Apache Kafka è solo una piccola parte del vasto repertorio di strumenti e linguaggi che trattano gli sviluppatori di software. Supponiamo che tu sia uno sviluppatore di software in erba con un'inclinazione verso i Big Data. In tal caso, puoi fare il primo passo verso i tuoi obiettivi con l'Executive PG Program di upGrad in Software Development – Specialization in Big Data .
Ecco una panoramica del programma con alcuni punti salienti:
- Executive PGP di IIIT Bangalore con certificazioni in Data Science e Cloud Infrastructure
- Sessioni online e lezioni dal vivo con oltre 400 ore di contenuti
- 7+ casi di studio e progetti
- Oltre 14 linguaggi e strumenti di programmazione
- Supporto professionale a 360 gradi
- Rete tra pari e settore
Iscriviti per maggiori dettagli sul corso!
A cosa serve Kafka?
Apache Kafka viene utilizzato principalmente per creare pipeline di dati in streaming in tempo reale e applicazioni che si adattano a tali flussi di dati. Consente sia l'archiviazione che l'analisi di dati storici e in tempo reale attraverso una combinazione di messaggistica, archiviazione ed elaborazione del flusso.
Kafka è una struttura?
Apache Kafka è un software open source che fornisce un framework per l'archiviazione, la lettura e l'analisi dei dati in streaming. Poiché è open source, Kafka può essere utilizzato gratuitamente con molti sviluppatori e utenti che contribuiscono a nuove funzionalità, aggiornamenti e supporto per i nuovi utenti.
Perché abbiamo bisogno dei flussi Kafka?
Kafka Streams è una libreria client per la creazione di microservizi e applicazioni di streaming in cui i dati di input e di output sono archiviati nel cluster Apache Kafka. Da un lato, offre i vantaggi della tecnologia cluster lato server di Apache Kafka. Dall'altro, semplifica la scrittura e la distribuzione di applicazioni standard Scala e Java lato client.