
Apache Kafka: architettura, concetti, funzionalità e applicazioni
Pubblicato: 2021-03-09Kafka è stato lanciato nel 2011, tutto grazie a LinkedIn. Da allora, ha assistito a una crescita incredibile al punto che la maggior parte delle società quotate in Fortune 500 ora lo utilizza. È un prodotto altamente scalabile, durevole e ad alto rendimento in grado di gestire grandi quantità di dati in streaming. Ma è questa l'unica ragione dietro la sua enorme popolarità? Beh no. Non abbiamo nemmeno iniziato a conoscere le sue funzionalità, la qualità che produce e la facilità che offre agli utenti.
Ne parleremo più avanti. Per prima cosa capiamo cos'è Kafka e dove viene utilizzato.
Sommario
Cos'è Apache Kafka?
Apache Kafka è un software di elaborazione del flusso open source che mira a fornire un throughput elevato e una bassa latenza durante la gestione dei dati in tempo reale. Scritto in Java e Scala, Kafka fornisce durabilità tramite microservizi in memoria e ha un ruolo fondamentale da svolgere nel mantenimento degli eventi di fornitura a Servizi di streaming di eventi complessi, altrimenti noti come CEP o Sistemi di automazione.
È un sistema distribuito eccezionalmente versatile e a prova di errore, che consente ad aziende come Uber di gestire l'abbinamento di passeggeri e conducenti. Fornisce inoltre dati in tempo reale e manutenzione proattiva per i prodotti per la casa intelligente di British Gas, oltre ad aiutare LinkedIn a monitorare più servizi in tempo reale.
Spesso impiegato nell'architettura dei dati di streaming in tempo reale per fornire analisi in tempo reale, Kafka è un sistema di messaggistica rapido, robusto, scalabile e con sottoscrizione di pubblicazione. Apache Kafka può essere utilizzato come sostituto del MOM tradizionale grazie alla sua eccellente compatibilità e all'architettura flessibile che gli consente di tenere traccia delle chiamate di servizio o dei dati dei sensori IoT.
Kafka funziona brillantemente con Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink e Apache Spark per l'acquisizione, la ricerca, l'analisi e l'elaborazione dei dati in streaming in tempo reale. Gli intermediari Kafka facilitano anche i rapporti di follow-up a bassa latenza in Hadoop o Spark. Kafka ha anche un progetto sussidiario chiamato Kafka Stream che funziona come uno strumento efficace per l'analisi in tempo reale.

Architettura e componenti Kafka
Kafka viene utilizzato per lo streaming di dati in tempo reale su più sistemi destinatari. Kafka funge da livello centrale per il disaccoppiamento delle pipeline di dati in tempo reale. Non trova molto impiego nei calcoli diretti. È più compatibile con i sistemi di alimentazione in corsia preferenziale, in tempo reale o basati su dati operativi, per lo streaming di una quantità significativa di dati per l'analisi dei dati batch.
I framework Storm, Flink, Spark e CEP sono alcuni sistemi di dati con cui Kafka lavora per eseguire analisi in tempo reale, creare backup, audit e altro ancora. Può anche essere integrato con piattaforme di big data o sistemi di database come RDBMS e Cassandra, Spark, ecc. per analisi, reportistica, ecc.
Il diagramma seguente illustra l'ecosistema Kafka:
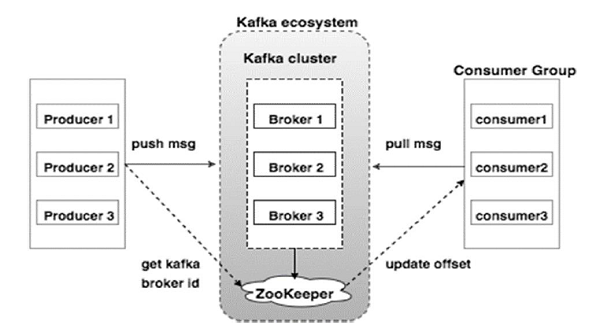
Fonte
Ecco i vari componenti dell'ecosistema Kafka come illustrato nel diagramma dell'architettura di Kafka:
1. Mediatore Kafka
Kafka emula un cluster che comprende più server, ciascuno noto come "broker". Qualsiasi comunicazione tra client e server aderisce a un protocollo TCP ad alte prestazioni. Comprende più di un broker senza stato per gestire carichi pesanti. Un singolo broker Kafka è in grado di gestire diversi lacune di letture e scritture ogni secondo senza compromettere le prestazioni. Usano ZooKeeper per mantenere i cluster ed eleggere il leader del broker.
2. Custode dello zoo di Kafka
Come accennato in precedenza, ZooKeeper si occupa della gestione dei broker Kafka. Qualsiasi nuova aggiunta o guasto di un broker nell'ecosistema Kafka viene segnalato a un produttore o consumatore tramite ZooKeeper.
3. Produttori Kafka
Sono responsabili dell'invio dei dati ai broker. I produttori non si affidano ai broker per confermare la ricezione di un messaggio. Invece, determinano quanto un broker può gestire e inviare messaggi di conseguenza.

4. Consumatori Kafka
È responsabilità dei consumatori Kafka tenere un registro del numero di messaggi consumati dall'offset della partizione. La conferma di un messaggio indica che i messaggi inviati prima di essere stati consumati. Per garantire che il broker disponga di un buffer di byte pronto per l'invio al consumatore, il consumatore avvia una richiesta pull asincrona. ZooKeeper ha un ruolo da svolgere nel mantenere il valore di offset di saltare o riavvolgere un messaggio.
Il meccanismo di Kafka prevede l'invio di messaggi tra le applicazioni nei sistemi distribuiti. Kafka utilizza un log di commit, che quando sottoscritto pubblica i dati presenti in una varietà di applicazioni di streaming. Il mittente invia messaggi a Kafka, mentre il destinatario riceve messaggi dallo stream distribuito da Kafka.
I messaggi sono raggruppati in argomenti — un'efficace deliberazione di Kafka. Un determinato argomento rappresenta un flusso organizzato di dati basato su un tipo o una classificazione specifici. Il produttore scrive messaggi che i consumatori possono leggere, basati su un argomento.
Ad ogni argomento viene assegnato un nome univoco. Qualsiasi messaggio inviato da un mittente da un determinato argomento viene ricevuto da tutti gli utenti che si stanno sintonizzando su quell'argomento. Una volta pubblicati, i dati in un argomento non possono essere aggiornati o modificati.
Caratteristiche di Kafka
- Kafka è costituito da un registro di commit perpetuo che consente di iscriversi ad esso e successivamente pubblicare dati su più sistemi o applicazioni in tempo reale.
- Dà alle applicazioni la possibilità di controllare i dati non appena arrivano. L'API Streams in Apache Kafka è una libreria potente e leggera che facilita l'elaborazione di dati batch al volo.
- È un'applicazione Java che ti permette di regolare il tuo flusso di lavoro e riduce notevolmente qualsiasi esigenza di manutenzione.
- Kafka funziona come un "archivio della verità" che distribuisce i dati a più nodi consentendo la distribuzione dei dati tramite più sistemi di dati.
- Il registro dei commit di Kafka lo rende un sistema di archiviazione affidabile. Kafka crea repliche/backup di una partizione che aiutano a prevenire la perdita di dati (le configurazioni corrette possono comportare una perdita di dati pari a zero). Ciò previene anche il guasto del server e migliora la durata di Kafka.
- Gli argomenti in Kafka hanno migliaia di partizioni, il che lo rende in grado di gestire una quantità arbitraria di dati e carichi pesanti.
- Kafka dipende dal kernel del sistema operativo per spostare i dati a un ritmo veloce. Questi cluster di informazioni sono crittografati end-to-end, dal produttore al file system al consumatore finale.
- Il batch in Kafka rende efficiente la compressione dei dati e riduce la latenza di I/O.
Applicazioni di Kafka
Molte aziende che si occupano quotidianamente di grandi quantità di dati utilizzano Kafka.

- LinkedIn utilizza Kafka per monitorare l'attività degli utenti e le metriche delle prestazioni. Twitter lo combina con Storm per abilitare un framework di elaborazione del flusso.
- Square utilizza Kafka per facilitare lo spostamento di tutti gli eventi di sistema verso altri data center Square. Ciò include registri, eventi personalizzati e metriche.
- Altre società famose che si avvalgono dei vantaggi di Kafka includono Netflix, Spotify, Uber, Tumblr, CloudFlare e PayPal.
Perché dovresti imparare Apache Kafka?
Kafka è un'eccellente piattaforma di streaming di eventi in grado di gestire, tracciare e monitorare in modo efficiente i dati in tempo reale. La sua architettura a tolleranza d'errore e scalabile consente l'integrazione dei dati a bassa latenza con conseguente elevato throughput di eventi di streaming. Kafka riduce significativamente il "time-to-value" per i dati.
Funziona come il sistema fondamentale che produce informazioni per le organizzazioni eliminando i "registri" attorno ai dati. Ciò consente a data scientist e specialisti di accedere facilmente alle informazioni in qualsiasi momento.
Per questi motivi, è la migliore piattaforma di streaming preferita da molte grandi aziende e quindi i candidati con una qualifica in Apache Kafka sono molto ricercati.
Se sei interessato a saperne di più su Kafka, Big Data, dovresti dare un'occhiata al Diploma PG di upGrad in specializzazione in sviluppo software in Big Data che offre oltre 7 casi di studio e progetti e tutoraggio da docenti di livello mondiale ed esperti del settore. Il programma di 13 mesi copre 14 linguaggi di programmazione e insegna Elaborazione dati, MapReduce, Data Warehousing, Elaborazione in tempo reale, Elaborazione Big Data sul cloud, tra le altre abilità.
Controlla i nostri altri corsi di ingegneria del software su upGrad.