
Un'interfaccia utente vocale alternativa agli assistenti vocali
Pubblicato: 2022-03-10Per la maggior parte delle persone, la prima cosa che viene in mente quando si pensa alle interfacce utente vocali sono gli assistenti vocali, come Siri, Amazon Alexa o Google Assistant. In effetti, gli assistenti sono l'unico contesto in cui la maggior parte delle persone ha mai usato la voce per interagire con un sistema informatico.
Sebbene gli assistenti vocali abbiano portato le interfacce utente vocali nel mainstream, il paradigma dell'assistente non è l'unico, né il modo migliore per utilizzare, progettare e creare interfacce utente vocali.
In questo articolo, esaminerò i problemi di cui soffrono gli assistenti vocali e presenterò un nuovo approccio per le interfacce utente vocali che chiamo interazioni vocali dirette.
Gli assistenti vocali sono chatbot basati sulla voce
Un assistente vocale è un software che utilizza il linguaggio naturale invece di icone e menu come interfaccia utente. Gli assistenti in genere rispondono alle domande e spesso cercano in modo proattivo di aiutare l'utente.
Invece di semplici transazioni e comandi, gli assistenti imitano una conversazione umana e usano il linguaggio naturale in modo bidirezionale come modalità di interazione, il che significa che riceve input dall'utente e risponde all'utente usando il linguaggio naturale.
I primi assistenti erano sistemi di risposta alle domande basati sul dialogo. Uno dei primi esempi è Clippy di Microsoft che, infamemente, ha cercato di aiutare gli utenti di Microsoft Office fornendo loro istruzioni in base a ciò che pensava l'utente stesse cercando di realizzare. Al giorno d'oggi, un tipico caso d'uso per il paradigma dell'assistente sono i chatbot, spesso utilizzati per l'assistenza clienti in una discussione in chat.
Gli assistenti vocali, d'altra parte, sono chatbot che usano la voce invece della digitazione e del testo . L'input dell'utente non è una selezione o un testo, ma una voce e anche la risposta del sistema viene pronunciata ad alta voce. Questi assistenti possono essere assistenti generali come Google Assistant o Alexa che possono rispondere a una moltitudine di domande in modo ragionevole o assistenti personalizzati creati per uno scopo speciale come l'ordinazione di un fast food.
Sebbene spesso l'input dell'utente sia solo una parola o due e possa essere presentato come selezioni anziché come testo, man mano che la tecnologia si evolve, le conversazioni saranno più aperte e complesse . La prima caratteristica distintiva di chatbot e assistenti è l'uso del linguaggio naturale e dello stile di conversazione invece di icone, menu e stile transazionale che definisce un'app mobile tipica o un'esperienza utente del sito web.
Letture consigliate : Costruire un semplice chatbot AI con l'API Web Speech e Node.js
La seconda caratteristica distintiva che deriva dalle risposte del linguaggio naturale è l'illusione di una persona. Il tono, la qualità e il linguaggio utilizzati dal sistema definiscono sia l'esperienza dell'assistente, l'illusione di empatia e suscettibilità al servizio, sia la sua persona. L'idea di una buona esperienza di assistente è come essere coinvolti con una persona reale .
Poiché la voce è il modo più naturale per comunicare, potrebbe sembrare fantastico, ma ci sono due problemi principali nell'uso delle risposte del linguaggio naturale. Uno di questi problemi, relativo al modo in cui i computer possono imitare gli esseri umani, potrebbe essere risolto in futuro con lo sviluppo di tecnologie di intelligenza artificiale conversazionale , ma il problema di come i cervelli umani gestiscono le informazioni è un problema umano, non risolvibile nel prossimo futuro. Esaminiamo questi problemi in seguito.
Due problemi con le risposte in linguaggio naturale
Le interfacce utente vocali sono ovviamente interfacce utente che utilizzano la voce come modalità. Ma la modalità vocale può essere utilizzata per entrambe le direzioni: per inserire le informazioni dall'utente e restituire le informazioni dal sistema all'utente. Ad esempio, alcuni ascensori utilizzano la sintesi vocale per confermare la selezione dell'utente dopo che l'utente ha premuto un pulsante. In seguito parleremo delle interfacce utente vocali che utilizzano solo la voce per immettere informazioni e utilizzano interfacce utente grafiche tradizionali per mostrare le informazioni all'utente.
Gli assistenti vocali, d'altra parte, usano la voce sia per l'input che per l'output . Questo approccio presenta due problemi principali:
Problema n. 1: l'imitazione di un essere umano fallisce
Come esseri umani, abbiamo un'inclinazione innata ad attribuire caratteristiche simili a quelle umane a oggetti non umani. Vediamo i lineamenti di un uomo in una nuvola che passa alla deriva o guardiamo un panino e sembra che ci stia sorridendo. Questo si chiama antropomorfismo .

Questo fenomeno si applica anche agli assistenti ed è innescato dalle loro risposte nel linguaggio naturale. Sebbene un'interfaccia utente grafica possa essere costruita in modo alquanto neutro, non è possibile che un essere umano non possa iniziare a pensare se la voce di qualcuno appartiene a una persona giovane o anziana o se è maschio o femmina. Per questo motivo, l'utente inizia quasi a pensare che l'assistente sia davvero un essere umano.
Tuttavia, noi umani siamo molto bravi a rilevare i falsi . Stranamente, più qualcosa si avvicina a somigliare a un essere umano, più le piccole deviazioni iniziano a disturbarci. C'è una sensazione di inquietudine nei confronti di qualcosa che cerca di essere simile a un umano ma non è del tutto all'altezza. Nella robotica e nelle animazioni al computer questa viene definita la "valle misteriosa".

Più proviamo a rendere l'assistente migliore e più umano, più inquietante e deludente può essere l'esperienza dell'utente quando qualcosa va storto. Tutti coloro che hanno provato gli assistenti si sono probabilmente imbattuti nel problema di rispondere con qualcosa che sembra idiota o addirittura scortese.
La misteriosa valle degli assistenti vocali pone un problema di qualità nell'esperienza utente dell'assistente che è difficile da superare. In effetti, il test di Turing (dal nome del famoso matematico Alan Turing) viene superato quando un valutatore umano che esibisce una conversazione tra due agenti non riesce a distinguere tra quale di loro sia una macchina e quale sia un essere umano. Finora non è mai stato superato.
Ciò significa che il paradigma dell'assistente promette un'esperienza di servizio simile a quella umana che non potrà mai essere realizzata e l'utente è destinato a rimanere deluso. Le esperienze di successo non fanno altro che accumulare l'eventuale delusione, poiché l'utente inizia a fidarsi del proprio assistente simile a un umano.
Problema 2: interazioni sequenziali e lente
Il secondo problema degli assistenti vocali è che la natura a turni delle risposte in linguaggio naturale provoca un ritardo nell'interazione. Ciò è dovuto al modo in cui il nostro cervello elabora le informazioni.
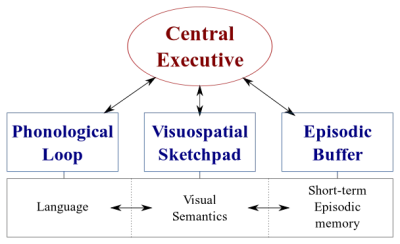
Esistono due tipi di sistemi di elaborazione dati nel nostro cervello:
- Un sistema linguistico che elabora il parlato;
- Un sistema visuospaziale specializzato nell'elaborazione di informazioni visive e spaziali.
Questi due sistemi possono funzionare in parallelo, ma entrambi i sistemi elaborano solo una cosa alla volta . Questo è il motivo per cui puoi parlare e guidare un'auto allo stesso tempo, ma non puoi inviare messaggi e guidare perché entrambe queste attività avverrebbero nel sistema visuospaziale.

Allo stesso modo, quando parli con l'assistente vocale, l'assistente deve rimanere in silenzio e viceversa. Questo crea una conversazione a turni , in cui l'altra parte è sempre completamente passiva.
Tuttavia, considera un argomento difficile che vuoi discutere con il tuo amico. Probabilmente parleresti faccia a faccia piuttosto che al telefono, giusto? Questo perché in una conversazione faccia a faccia utilizziamo la comunicazione non verbale per fornire un feedback visivo in tempo reale al nostro interlocutore. Ciò crea un ciclo di scambio di informazioni bidirezionale e consente a entrambe le parti di essere attivamente coinvolte nella conversazione contemporaneamente.
Gli assistenti non forniscono feedback visivo in tempo reale. Si affidano a una tecnologia chiamata end-pointing per decidere quando l'utente ha smesso di parlare e risponde solo dopo. E quando rispondono, non ricevono alcun input dall'utente contemporaneamente. L'esperienza è completamente unidirezionale ea turni.
In una conversazione faccia a faccia bidirezionale e in tempo reale, entrambe le parti possono reagire immediatamente sia ai segnali visivi che linguistici. Questo utilizza i diversi sistemi di elaborazione delle informazioni del cervello umano e la conversazione diventa più fluida ed efficiente.
Gli assistenti vocali sono bloccati in modalità unidirezionale perché utilizzano il linguaggio naturale sia come canale di input che di output. Sebbene la voce sia fino a quattro volte più veloce della digitazione per l'input, è significativamente più lenta da digerire rispetto alla lettura. Poiché le informazioni devono essere elaborate in sequenza , questo approccio funziona bene solo per comandi semplici come "spegni le luci" che non richiedono molto output dall'assistente.

In precedenza, ho promesso di discutere le interfacce utente vocali che utilizzano la voce solo per l'immissione di dati dall'utente. Questo tipo di interfacce utente vocali beneficiano delle parti migliori delle interfacce utente vocali - naturalezza, velocità e facilità d'uso - ma non soffrono delle parti negative - valle misteriosa e interazioni sequenziali
Consideriamo questa alternativa.
Una migliore alternativa all'assistente vocale
La soluzione per superare questi problemi negli assistenti vocali è abbandonare le risposte in linguaggio naturale e sostituirle con feedback visivi in tempo reale. Il passaggio da feedback a visivo consentirà all'utente di fornire e ricevere feedback contemporaneamente. Ciò consentirà all'applicazione di reagire senza interrompere l'utente e consentendo un flusso di informazioni bidirezionale. Poiché il flusso di informazioni è bidirezionale, il suo throughput è maggiore.
Attualmente, i principali casi d'uso per gli assistenti vocali sono l'impostazione di sveglie, la riproduzione di musica, il controllo del tempo e le semplici domande. Tutti questi sono compiti a bassa posta in gioco che non frustrano troppo l'utente quando fallisce.
Come scrisse una volta David Pierce del Wall Street Journal :
"Non riesco a immaginare di prenotare un volo o di gestire il mio budget tramite un assistente vocale, o di monitorare la mia dieta gridando ingredienti al mio altoparlante."
— David Pierce del Wall Street Journal
Queste sono attività pesanti di informazioni che devono essere eseguite correttamente.
Tuttavia, alla fine, l'interfaccia utente vocale avrà esito negativo. La chiave è coprirlo il più velocemente possibile. Molti errori si verificano quando si digita su una tastiera o anche in una conversazione faccia a faccia. Tuttavia, questo non è affatto frustrante in quanto l'utente può recuperare semplicemente facendo clic sul backspace e riprovando o chiedendo chiarimenti.
Questo rapido recupero dagli errori consente all'utente di essere più efficiente e non lo costringe a una strana conversazione con un assistente.
Interazioni vocali dirette
Nella maggior parte delle applicazioni, le azioni vengono eseguite manipolando elementi grafici sullo schermo, toccando o scorrendo (sui touchscreen), facendo clic con il mouse e/o premendo i pulsanti su una tastiera. L'input vocale può essere aggiunto come opzione o modalità aggiuntiva per manipolare questi elementi grafici. Questo tipo di interazione può essere chiamata interazione vocale diretta .
La differenza tra interazioni vocali dirette e assistenti è che invece di chiedere a un avatar, l'assistente, di eseguire un'attività, l'utente manipola direttamente l'interfaccia utente grafica con la voce.
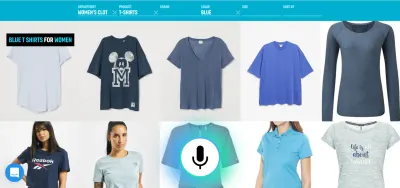
"Non è semantica?", potresti chiedere. Se hai intenzione di parlare al computer, importa davvero se stai parlando direttamente al computer o tramite un personaggio virtuale? In entrambi i casi, stai solo parlando con un computer!
Sì, la differenza è sottile, ma fondamentale. Quando si fa clic su un pulsante o su una voce di menu in una GUI ( G raphical User Interface) è palesemente ovvio che stiamo utilizzando una macchina. Non c'è illusione di una persona. Sostituendo quel clic con un comando vocale, stiamo migliorando l'interazione uomo-computer. Con il paradigma dell'assistente, d'altra parte, stiamo creando una versione deteriorata dell'interazione uomo-uomo e, quindi, viaggiando nella valle misteriosa.
La fusione delle funzionalità vocali nell'interfaccia utente grafica offre anche il potenziale per sfruttare la potenza di diverse modalità. Sebbene l'utente possa utilizzare la voce per utilizzare l'applicazione, ha anche la possibilità di utilizzare l'interfaccia grafica tradizionale. Ciò consente all'utente di passare senza problemi dal tocco alla voce e scegliere l'opzione migliore in base al contesto e all'attività.
Ad esempio, la voce è un metodo molto efficiente per inserire informazioni ricche. Probabilmente è meglio selezionare tra un paio di alternative valide, toccare o fare clic. L'utente può quindi sostituire la digitazione e la navigazione dicendo qualcosa come "Mostrami i voli da Londra a New York in partenza domani" e selezionare l'opzione migliore dall'elenco utilizzando il tocco.
Ora potresti chiedere "OK, sembra fantastico, quindi perché non abbiamo già visto esempi di tali interfacce utente vocali? Perché le principali aziende tecnologiche non creano strumenti per qualcosa del genere?" Bene, ci sono probabilmente molte ragioni per questo. Uno dei motivi è che l'attuale paradigma dell'assistente vocale è probabilmente il modo migliore per sfruttare i dati che ottengono dagli utenti finali. Un altro motivo ha a che fare con il modo in cui è costruita la loro tecnologia vocale.
Un'interfaccia utente vocale ben funzionante richiede due parti distinte:
- Riconoscimento vocale che trasforma il discorso in testo;
- Componenti di comprensione del linguaggio naturale che estraggono significato da quel testo.
La seconda parte è la magia che trasforma le espressioni "Spegni le luci del soggiorno" e "Spegni le luci del soggiorno" nella stessa azione.
Lettura consigliata : Come creare la tua azione per Google Home utilizzando API.AI
Se hai mai utilizzato un assistente con un display (come Siri o Google Assistant), probabilmente avrai notato che ottieni la trascrizione quasi in tempo reale, ma dopo aver smesso di parlare, il sistema impiega alcuni secondi esegue effettivamente l'azione che hai richiesto. Ciò è dovuto al fatto che il riconoscimento vocale e la comprensione del linguaggio naturale avvengono in sequenza.
Vediamo come questo potrebbe essere cambiato.
Comprensione della lingua parlata in tempo reale: la salsa segreta per comandi vocali più efficienti
La velocità con cui un'applicazione reagisce all'input dell'utente è un fattore importante nell'esperienza utente complessiva dell'applicazione. L'innovazione più importante dell'iPhone originale era il touchscreen estremamente reattivo e reattivo. La capacità di un'interfaccia utente vocale di reagire istantaneamente all'input vocale è altrettanto importante.
Per stabilire un rapido ciclo di scambio di informazioni bidirezionale tra l'utente e l'interfaccia utente, la GUI abilitata alla voce dovrebbe essere in grado di reagire istantaneamente, anche a metà frase, ogni volta che l'utente dice qualcosa di perseguibile. Ciò richiede una tecnica chiamata streaming di comprensione della lingua parlata .
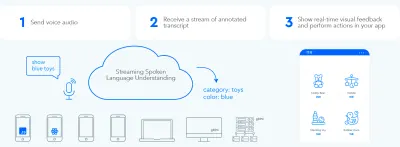
Contrariamente ai tradizionali sistemi di assistente vocale a turni che aspettano che l'utente smetta di parlare prima di elaborare la richiesta dell'utente, i sistemi che utilizzano la comprensione della lingua parlata in streaming cercano attivamente di comprendere l'intento dell'utente dal momento stesso in cui l'utente inizia a parlare. Non appena l'utente dice qualcosa di perseguibile, l'interfaccia utente reagisce immediatamente.
La risposta immediata conferma immediatamente che il sistema sta capendo l'utente e incoraggia l'utente ad andare avanti. È analogo a un cenno del capo oa un breve "ah-ah" nella comunicazione da uomo a uomo. Ciò si traduce in espressioni più lunghe e complesse supportate. Rispettivamente, se il sistema non comprende l'utente o se l'utente parla male, il feedback istantaneo consente un ripristino rapido . L'utente può correggere immediatamente e continuare, o anche correggersi verbalmente: "Voglio questo, no volevo dire, voglio quello". Puoi provare tu stesso questo tipo di applicazione nella nostra demo di ricerca vocale.
Come puoi vedere nella demo, il feedback visivo in tempo reale consente all'utente di correggersi in modo naturale e lo incoraggia a continuare con l'esperienza vocale. Poiché non sono confusi da un personaggio virtuale, possono riferirsi a possibili errori in modo simile agli errori di battitura, non come insulti personali. L'esperienza è più veloce e naturale perché le informazioni fornite all'utente non sono limitate dalla velocità tipica del parlato di circa 150 parole al minuto.
Lettura consigliata : Designing Voice Experiences di Lyndon Cerejo
Conclusioni
Sebbene finora gli assistenti vocali siano stati di gran lunga l'uso più comune per le interfacce utente vocali, l'uso di risposte in linguaggio naturale li rende inefficienti e innaturali. La voce è un'ottima modalità per inserire informazioni, ma ascoltare una macchina che parla non è molto stimolante. Questo è il grande problema degli assistenti vocali.
Il futuro della voce non dovrebbe quindi essere nelle conversazioni con un computer ma nel sostituire le noiose attività dell'utente con il modo più naturale di comunicare: la parola . Le interazioni vocali dirette possono essere utilizzate per migliorare l'esperienza di compilazione dei moduli nelle applicazioni Web o mobili, per creare esperienze di ricerca migliori e per consentire un modo più efficiente di controllare o navigare in un'applicazione.
Designer e sviluppatori di app sono costantemente alla ricerca di modi per ridurre l'attrito nelle loro app o nei loro siti Web. Migliorare l'attuale interfaccia utente grafica con una modalità vocale consentirebbe interazioni utente più volte più veloci, soprattutto in determinate situazioni, ad esempio quando l'utente finale è su un dispositivo mobile e in movimento e la digitazione è difficile. In effetti, la ricerca vocale può essere fino a cinque volte più veloce di un'interfaccia utente di filtraggio della ricerca tradizionale, anche quando si utilizza un computer desktop.
La prossima volta, quando stai pensando a come rendere una determinata attività utente nella tua applicazione più facile da usare, più piacevole da usare o sei interessato ad aumentare le conversioni, considera se tale attività utente può essere descritta accuratamente nel linguaggio naturale. Se sì, completa la tua interfaccia utente con una modalità vocale ma non forzare i tuoi utenti a conversare con un computer.
Risorse
- "La voce prima di tutto rispetto alle interfacce utente multimodali del futuro", Joan Palmiter Bajorek, UXmatters
- "Linee guida per la creazione di app produttive abilitate alla voce", Hannes Heikinheimo, Speechly
- "6 motivi per cui le tue app touch-screen dovrebbero avere capacità vocali", Ottomatias Peura, UXmatters
- Mescolare tangibile e immateriale: progettare interfacce multimodali utilizzando Adobe XD, Nick Babich, Smashing Magazine
( Adobe XD può essere per la prototipazione qualcosa di simile ) - "Efficienza alla velocità del suono: la promessa di operazioni abilitate alla voce", Eric Turkington, RAIN
- Una demo che mostra il feedback visivo in tempo reale nel filtraggio della ricerca vocale dell'eCommerce (versione video)
- Speechly fornisce strumenti di sviluppo per questo tipo di interfacce utente
- Alternativa open source: voice2json