
Una guida alla regressione lineare utilizzando Scikit [con esempi]
Pubblicato: 2021-06-18Gli algoritmi di apprendimento supervisionato sono generalmente di due tipi: Regressione e classificazione con la previsione di output continui e discreti.
Il seguente articolo discuterà la regressione lineare e la sua implementazione utilizzando una delle librerie di apprendimento automatico più popolari di Python, la libreria Scikit-learn. Nella libreria Python sono disponibili strumenti per l'apprendimento automatico e modelli statistici per la classificazione, la regressione, il clustering e la riduzione della dimensionalità. Scritta nel linguaggio di programmazione Python, la libreria è basata sulle librerie Python NumPy, SciPy e Matplotlib.
Sommario
Regressione lineare
La regressione lineare svolge il compito di regressione con il metodo di apprendimento supervisionato. Sulla base di variabili indipendenti, viene previsto un valore target. Il metodo è utilizzato principalmente per la previsione e l'identificazione di una relazione tra le variabili.
In algebra, il termine linearità indica una relazione lineare tra variabili. Si deduce una retta tra le variabili in uno spazio bidimensionale.
Se una linea è un grafico tra le variabili indipendenti sull'asse X e le variabili dipendenti sull'asse Y, si ottiene una linea retta attraverso la regressione lineare che si adatta meglio ai punti dati.
L'equazione di una retta ha la forma di

Y = mx + b
Dove, b= intercettare
m= pendenza della linea
Pertanto, attraverso la regressione lineare,
- I valori più ottimali per l'intercetta e la pendenza sono determinati in due dimensioni.
- Non vi è alcun cambiamento nelle variabili xey in quanto sono le caratteristiche dei dati e quindi rimangono le stesse.
- Possono essere controllati solo i valori di intercetta e pendenza.
- Potrebbero esistere più rette basate sui valori di pendenza e intercetta, tuttavia tramite l'algoritmo della regressione lineare vengono adattate più rette sui punti dati e viene restituita la retta con il minor errore.
Regressione lineare con Python
Per implementare la regressione lineare in Python, devono essere applicati pacchetti appropriati insieme alle sue funzioni e classi. Il pacchetto NumPy in Python è open source e consente diverse operazioni sugli array, sia array singoli che multidimensionali.
Un'altra libreria ampiamente utilizzata in Python è Scikit-learn che viene utilizzata per problemi di apprendimento automatico.
Scikit-learn N
La libreria Scikit-learn offre agli sviluppatori algoritmi basati sia sull'apprendimento supervisionato che non supervisionato. La libreria open source di Python è progettata per attività di apprendimento automatico.
I data scientist possono importare i dati, preelaborarli, tracciarli e prevedere i dati attraverso l'uso di scikit-learn.
David Cournapeau ha sviluppato per la prima volta scikit-learn nel 2007 e la biblioteca ha visto una crescita da decenni.
Gli strumenti forniti da scikit-learn sono:
- Regressione: include la regressione logistica e la regressione lineare
- Classificazione: include il metodo K-Nearest Neighbors
- Selezione di un modello
- Clustering: include sia K-Means++ che K-Means
- Preelaborazione
I vantaggi della libreria sono:
- L'apprendimento e l'implementazione della biblioteca sono facili.
- È una libreria open source e quindi gratuita.
- Gli aspetti dell'apprendimento automatico possono essere nascosti, incluso il deep learning.
- È un pacchetto potente e versatile.
- La biblioteca dispone di una documentazione dettagliata.
- Uno dei toolkit più utilizzati per l'apprendimento automatico.
Importazione di scikit-learn
Lo scikit-learn deve essere installato prima tramite pip o tramite conda.
- Requisiti: versione a 64 bit di python 3 con le librerie installate NumPy e Scipy. Anche per la visualizzazione del tracciato dei dati, è richiesto matplotlib.
Comando di installazione: pip install -U scikit-learn
Quindi verificare se l'installazione è completa
Installazione di Numpy, Scipy e matplotlib
L'installazione può essere confermata tramite:
Fonte
Regressione lineare attraverso Scikit-learn
L'implementazione della regressione lineare attraverso il pacchetto scikit-learn prevede i seguenti passaggi.
- I pacchetti e le classi richieste devono essere importati.
- I dati sono necessari per lavorare e anche per portare avanti le trasformazioni appropriate.
- Un modello di regressione deve essere creato e adattato ai dati esistenti.
- I dati di adattamento del modello devono essere verificati per analizzare se il modello creato è soddisfacente.
- Le previsioni devono essere fatte attraverso l'applicazione del modello.
Il pacchetto NumPy e la classe LinearRegression devono essere importati da sklearn.linear_model.

Fonte
Le funzionalità richieste per la regressione lineare sklearn sono tutte presenti per implementare finalmente la regressione lineare. La classe sklearn.linear_model.LinearRegression viene utilizzata per eseguire analisi di regressione (sia lineare che polinomiale) ed eseguire previsioni.
Per qualsiasi algoritmo di apprendimento automatico e scikit impara la regressione lineare , il set di dati deve essere prima importato. Sono disponibili tre opzioni in Scikit-learn per ottenere i dati:
- Set di dati come la classificazione dell'iride o l'insieme della regressione per il prezzo delle case di Boston.
- I set di dati del mondo reale possono essere scaricati da Internet direttamente tramite le funzioni predefinite di Scikit-learn.
- Un set di dati può essere generato in modo casuale per la corrispondenza con un modello specifico tramite il generatore di dati Scikit-learn.
Qualunque sia l'opzione selezionata, i dataset del modulo devono essere importati.

importa sklearn.datasets come dataset
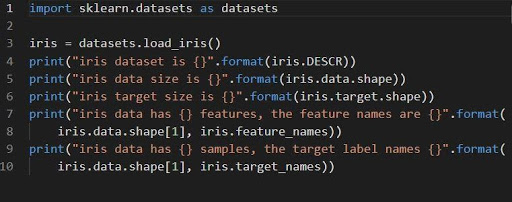
1. L'insieme di classificazione dell'iride
iris = datasets.load_iris()
L'iris del set di dati viene archiviato come campo di dati di array 2D di n_samples * n_features. La sua importazione avviene come oggetto di un dizionario. Contiene tutti i dati necessari insieme ai metadati.
Le funzioni DESCR, shape e _names possono essere utilizzate per ottenere descrizioni e formattazioni dei dati. La stampa dei risultati della funzione visualizzerà le informazioni del set di dati che potrebbero essere necessarie mentre si lavora sul set di dati dell'iride.
Il codice seguente caricherà le informazioni del set di dati dell'iride.
Fonte
2. Generazione di dati di regressione
Se non sono richiesti dati integrati, i dati possono essere generati attraverso una distribuzione che può essere scelta.
Generazione di dati di regressione con un set di 1 caratteristica informativa e 1 caratteristica.
X , Y = datasets.make_regression(n_features=1, n_informative=1)
I dati generati vengono salvati in un dataset 2D con gli oggetti x e y. Le caratteristiche dei dati generati possono essere modificate modificando i parametri della funzione make_regression.
In questo esempio, i parametri delle caratteristiche e delle caratteristiche informative vengono modificati da un valore predefinito di 10 a 1.
Altri parametri presi in considerazione sono i campioni e i target in cui viene controllato il numero di target e le variabili campionarie monitorate.
- Le funzionalità che forniscono informazioni utili agli algoritmi di ML sono denominate funzionalità informative mentre quelle che non sono utili sono denominate funzionalità on-informative.
3. Tracciare i dati
I dati vengono tracciati utilizzando la libreria matplotlib. Innanzitutto, è necessario importare matplotlib.
Importa matplotlib.pyplot come plt
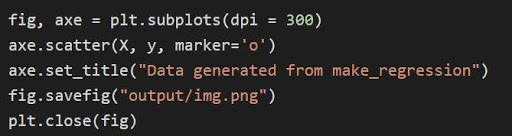
Il grafico sopra è tracciato attraverso matplotlib attraverso il codice
Fonte
Nel codice sopra:
- Le variabili della tupla vengono decompresse e salvate come variabili separate nella riga 1 del codice. Pertanto, gli attributi separati possono essere manipolati e salvati.
- Il set di dati x, y viene utilizzato per generare un grafico a dispersione attraverso la riga 2. Con la disponibilità del parametro marker in matplotlib, gli elementi visivi vengono migliorati contrassegnando i punti dati con un punto (o).
- Il titolo della trama generata viene impostato tramite la riga 3.
- La figura può essere salvata come file immagine .png e quindi la figura corrente viene chiusa.
Il grafico di regressione generato tramite il codice sopra è
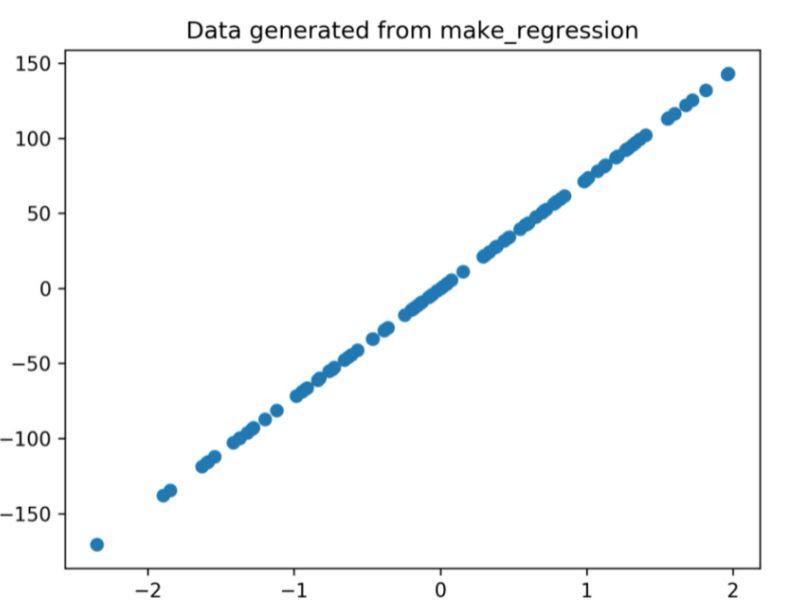
Figura 1: il grafico di regressione generato dal codice sopra.
4. Implementazione dell'algoritmo di regressione lineare
Utilizzando i dati di esempio del prezzo delle abitazioni di Boston, nell'esempio seguente viene implementato l'algoritmo di regressione lineare Scikit-learn . Come altri algoritmi ML, il set di dati viene importato e quindi sottoposto a training utilizzando i dati precedenti.
Il metodo lineare di regressione è utilizzato dalle aziende, in quanto è un modello predittivo che prevede la relazione tra una quantità numerica e le sue variabili al valore di output con un significato che ha un valore nella realtà.
Quando è presente un registro di dati precedenti, il modello può essere applicato al meglio in quanto può prevedere i risultati futuri di ciò che accadrà in futuro se c'è una continuazione del modello.
Matematicamente, i dati possono essere adattati per ridurre al minimo la somma di tutti i residui esistenti tra i punti dati e il valore previsto.
Il frammento di codice seguente mostra l'implementazione della regressione lineare di sklearn.
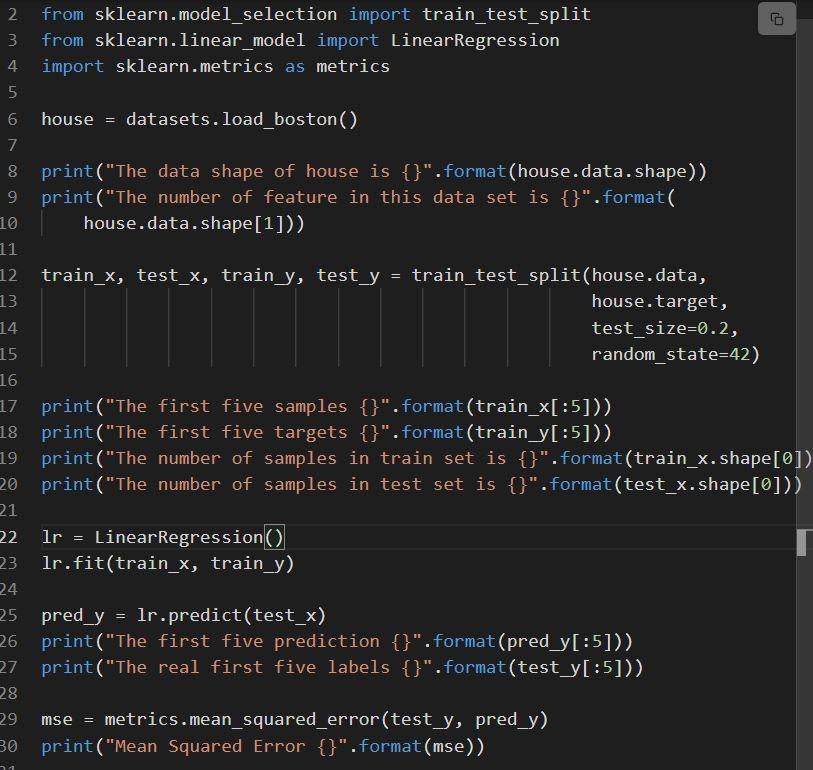
Fonte
Il codice è spiegato come:
- La riga 6 carica il set di dati chiamato load_boston.
- Il set di dati è suddiviso nella riga 12, ovvero il set di allenamento con l'80% di dati e il set di test con il 20% di dati.
- Creazione di un modello di regressione lineare alla riga 23 e poi addestrato a.
- Le prestazioni del modello vengono valutate al lino 29 chiamando mean_squared_error.
Il grafico di regressione lineare di sklearn è mostrato di seguito:
Modello di regressione lineare dei dati campione dei prezzi delle abitazioni di Boston
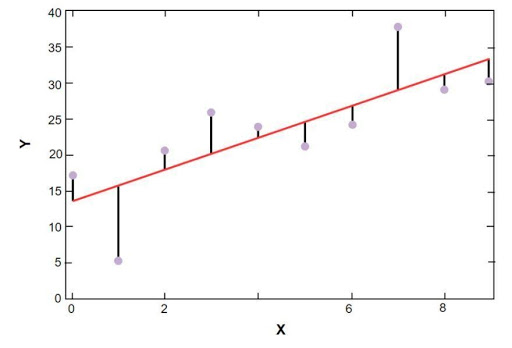
Fonte
Nella figura sopra, la linea rossa rappresenta il modello lineare che è stato risolto per i dati campione del prezzo delle abitazioni di Boston. I punti blu rappresentano i dati originali e la distanza tra la linea rossa ei punti blu rappresentano la somma del residuo. L'obiettivo del modello di regressione lineare scikit-learn è ridurre la somma dei residui.
Conclusione
L'articolo ha discusso la regressione lineare e la sua implementazione attraverso l'uso di un pacchetto Python open source chiamato scikit-learn. A questo punto, sei in grado di ottenere il concetto di come implementare la regressione lineare attraverso questo pacchetto. Vale la pena imparare a utilizzare la libreria per l'analisi dei dati.
Se sei interessato ad approfondire l'argomento, come l'implementazione di pacchetti Python nell'apprendimento automatico e problemi relativi all'IA, puoi consultare il corso Master of Science in Machine Learning & AI offerto da upGrad . Rivolto ai professionisti di livello base di età compresa tra 21 e 45 anni, il corso mira a formare gli studenti all'apprendimento automatico attraverso oltre 650 ore di formazione online, oltre 25 casi di studio e compiti. Certificato da LJMU , il corso offre la guida perfetta e l'assistenza all'inserimento lavorativo. Se hai domande o domande, lasciaci un messaggio, saremo felici di contattarti.