
Apa itu Pembelajaran Mesin dengan Java? Bagaimana Menerapkannya?
Diterbitkan: 2021-03-10Daftar isi
Apa itu Pembelajaran Mesin?
Pembelajaran mesin adalah divisi Artificial Intelligence yang belajar dari data, contoh, dan pengalaman yang tersedia untuk meniru perilaku dan kecerdasan manusia. Program yang dibuat menggunakan pembelajaran mesin dapat membangun logikanya sendiri tanpa manusia harus menulis kode secara manual.
Semuanya dimulai dengan Tes Turing pada awal 1950-an ketika Alan Turning menyimpulkan bahwa agar komputer memiliki kecerdasan yang nyata, ia perlu memanipulasi atau meyakinkan manusia bahwa itu juga manusia. Pembelajaran mesin adalah konsep yang relatif lama tetapi baru hari ini bidang yang muncul ini dapat direalisasikan karena komputer sekarang dapat memproses algoritme yang kompleks. Algoritma pembelajaran mesin telah berkembang selama dekade terakhir untuk memasukkan keterampilan komputasi yang kompleks yang pada gilirannya telah menyebabkan peningkatan kemampuan meniru mereka.
Aplikasi pembelajaran mesin juga meningkat pada tingkat yang mengkhawatirkan. Dari perawatan kesehatan, keuangan, analitik, dan pendidikan, hingga manufaktur, pemasaran, dan operasi pemerintah, setiap industri telah melihat peningkatan yang signifikan dalam kualitas dan efisiensi setelah menerapkan teknologi pembelajaran mesin. Ada peningkatan kualitatif yang tersebar luas di seluruh dunia, oleh karena itu, mendorong permintaan akan profesional pembelajaran mesin.
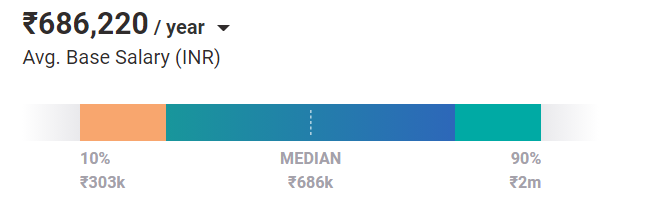
Rata-rata, Insinyur Pembelajaran Mesin bernilai gaji 686.220 / tahun hari ini. Dan itu adalah kasus untuk posisi entry-level. Dengan pengalaman dan keterampilan, mereka dapat menghasilkan hingga 2 juta / tahun di India.
Jenis Algoritma Pembelajaran Mesin
Algoritma pembelajaran mesin terdiri dari tiga jenis:
1. Pembelajaran Terawasi : Dalam jenis pembelajaran ini, set data pelatihan memandu algoritme untuk membuat prediksi yang akurat atau keputusan analitis. Ini menggunakan pembelajaran dari kumpulan data pelatihan sebelumnya untuk memproses data baru. Berikut adalah beberapa contoh model pembelajaran mesin pembelajaran yang diawasi:

- Regresi linier
- Regresi logistik
- Pohon keputusan
2. Pembelajaran Tanpa Pengawasan : Dalam jenis pembelajaran ini, model pembelajaran mesin belajar dari informasi yang tidak berlabel. Ini menggunakan pengelompokan data dengan mengelompokkan objek atau memahami hubungan di antara mereka, atau mengeksploitasi properti statistiknya untuk melakukan analisis. Contoh algoritma pembelajaran tanpa pengawasan adalah:
- K-berarti pengelompokan
- Pengelompokan hierarkis
3. Reinforcement Learning : Proses ini didasarkan pada hit and trial. Belajar dengan cara berinteraksi dengan ruang atau lingkungan. Algoritma RL belajar dari pengalaman masa lalunya dengan berinteraksi dengan lingkungan dan menentukan tindakan terbaik.
Bagaimana Menerapkan Pembelajaran Mesin dengan Java?
Java adalah salah satu bahasa pemrograman teratas yang digunakan untuk mengimplementasikan algoritma pembelajaran mesin. Sebagian besar perpustakaannya bersifat open-source, menyediakan dukungan dokumentasi yang ekstensif, perawatan yang mudah, daya jual, dan keterbacaan yang mudah.
Bergantung pada popularitasnya, berikut adalah 10 perpustakaan pembelajaran mesin teratas yang digunakan untuk mengimplementasikan pembelajaran mesin di Java.
1. ADAMS
Advanced-Data mining And Machine learning System atau ADAMS berkaitan dengan membangun sistem alur kerja yang baru dan fleksibel serta untuk mengelola proses dunia nyata yang kompleks. ADAMS menggunakan arsitektur seperti pohon untuk mengelola aliran data alih-alih membuat koneksi input-output manual.
Ini menghilangkan kebutuhan untuk koneksi eksplisit. Ini didasarkan pada prinsip "kurang lebih" dan melakukan pengambilan, visualisasi, dan visualisasi berbasis data. ADAMS mahir dalam pemrosesan data, streaming data, pengelolaan basis data, pembuatan skrip, dan dokumentasi.
2. JavaML
JavaML menawarkan berbagai ML dan algoritme penambangan data yang ditulis untuk Java untuk mendukung insinyur perangkat lunak, pemrogram, ilmuwan data, dan peneliti. Setiap algoritma memiliki antarmuka umum yang mudah digunakan dan memiliki dukungan dokumentasi yang luas meskipun tidak ada GUI.
Ini agak sederhana dan mudah untuk diterapkan dibandingkan dengan algoritma pengelompokan lainnya. Fitur intinya meliputi manipulasi data, dokumentasi, manajemen basis data, klasifikasi data, pengelompokan, pemilihan fitur, dan sebagainya.
Bergabunglah dengan Kursus Pembelajaran Mesin online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
3. WEKA
Weka juga merupakan perpustakaan pembelajaran mesin sumber terbuka yang ditulis untuk Java yang mendukung pembelajaran mendalam. Ini menyediakan satu set algoritme pembelajaran mesin dan menemukan penggunaan ekstensif dalam penambangan data, persiapan data, pengelompokan data, visualisasi data, dan regresi, di antara operasi data lainnya.
Contoh: Kami akan mendemonstrasikan ini menggunakan dataset diabetes kecil.
Langkah 1 : Muat data menggunakan Weka
| impor weka.core.Instances; impor weka.core.converters.ConverterUtils.DataSource; kelas publik Utama { public static void main(String[] args) melempar Pengecualian { // Menentukan sumber data DataSource dataSource = new DataSource(“data.arff”); // Memuat kumpulan data Instance dataInstances = dataSource.getDataSet(); // Menampilkan jumlah instance log.info(“Jumlah instance yang dimuat adalah: ” + dataInstances.numInstances()); log.info(“data:” + dataInstances.toString()); } } |
Langkah 2: Dataset memiliki 768 instance. Kita perlu mengakses jumlah atribut, yaitu, 9.
| log.info(“Jumlah atribut (fitur) dalam kumpulan data: ” + dataInstances.numAttributes()); |
Langkah 3 : Kita perlu menentukan kolom target sebelum kita membangun model dan menemukan jumlah kelas.
| // Mengidentifikasi indeks label dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Mendapatkan jumlah log.info(“Jumlah kelas: ” + dataInstances.numClasses()); |
Langkah 4 : Sekarang kita akan membangun model menggunakan pengklasifikasi pohon sederhana, J48.
| // Membuat pengklasifikasi pohon keputusan J48 treeClassifier = J48 baru(); treeClassifier.setOptions(String baru[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
Kode di atas menyoroti cara membuat pohon yang tidak dipangkas yang terdiri dari instance data yang diperlukan untuk pelatihan model. Setelah struktur pohon dicetak setelah pelatihan model, kita dapat menentukan bagaimana aturan dibangun secara internal.
| pla <= 127 | massa <= 26,4 | | preg <= 7: diuji_negatif (117.0/1.0) | | hamil > 7 | | | massa <= 0: diuji_positif (2.0) | | | massa > 0: diuji_negatif (13.0) | massa > 26,4 | | usia <= 28: diuji_negatif (180.0/22.0) | | usia > 28 | | | plas <= 99: test_negatif (55.0/10.0) | | | plas > 99 | | | | pedi <= 0,56: diuji_negatif (84.0/34.0) | | | | pedi > 0,56 | | | | | hamil <= 6 | | | | | | usia <= 30: teruji_positif (4.0) | | | | | | usia > 30 | | | | | | | usia <= 34: diuji_negatif (7.0/1.0) | | | | | | | usia > 34 | | | | | | | | massa <= 33.1: diuji_positif (6.0) | | | | | | | | massa > 33.1: diuji_negatif (4.0/1.0) | | | | | kehamilan > 6: test_positif (13.0) plas > 127 | massa <= 29,9 | | plas <= 145: diuji_negatif (41.0/6.0) | | plas > 145 | | | usia <= 25: diuji_negatif (4.0) | | | usia > 25 | | | | usia <= 61 | | | | | massa <= 27.1: diuji_positif (12.0/1.0) | | | | | massa > 27.1 | | | | | | tekan <= 82 | | | | | | | pedi <= 0,396: diuji_positif (8.0/1.0) | | | | | | | pedi > 0,396: diuji_negatif (3,0)  | | | | | | pres > 82: diuji_negatif (4.0) | | | | usia > 61: diuji_negatif (4.0) | massa > 29,9 | | tolong <= 157 | | | pres <= 61: diuji_positif (15.0/1.0) | | | tekan > 61 | | | | usia <= 30: diuji_negatif (40.0/13.0) | | | | usia > 30: teruji_positif (60.0/17.0) | | plas > 157: test_positive (92.0/12.0) Jumlah Daun : 22 Ukuran pohon : 43 |
4. Apache Mahaut
Mahaut adalah kumpulan algoritma untuk membantu mengimplementasikan pembelajaran mesin menggunakan Java. Ini adalah kerangka kerja aljabar linier terukur yang digunakan pengembang untuk melakukan matematika, analitik ahli statistik. Biasanya digunakan oleh ilmuwan data, insinyur penelitian, dan profesional analitik untuk membangun aplikasi yang siap untuk perusahaan. Skalabilitas dan fleksibilitasnya memungkinkan pengguna untuk mengimplementasikan pengelompokan data, sistem rekomendasi, dan membuat aplikasi pembelajaran Mesin yang berkinerja cepat dan mudah.
5. Deeplearning4j
Deeplearning4j adalah pustaka pemrograman yang ditulis dalam Java dan menawarkan dukungan ekstensif untuk pembelajaran mendalam. Ini adalah kerangka kerja sumber terbuka yang menggabungkan jaringan saraf yang dalam dan pembelajaran penguatan yang mendalam untuk melayani operasi bisnis. Ini kompatibel dengan Scala, Kotlin, Apache Spark, Hadoop, dan bahasa JVM lainnya serta kerangka kerja komputasi data besar.
Ini biasanya digunakan untuk mendeteksi pola dan emosi dalam suara, ucapan, dan teks tertulis. Ini berfungsi sebagai alat DIY yang dapat menemukan perbedaan dalam transaksi, dan menangani banyak tugas. Ini adalah perpustakaan terdistribusi kelas komersial yang memiliki dokumentasi API terperinci karena sifatnya yang bersumber terbuka.
Berikut adalah contoh bagaimana Anda dapat menerapkan pembelajaran mesin menggunakan Deeplearning4j.
Contoh : Menggunakan Deeplearning4j, kita akan membangun model Convolution Neural Network (CNN) untuk mengklasifikasikan digit tulisan tangan dengan bantuan library MNIST.
Langkah 1 : Muat dataset untuk menampilkan ukurannya.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
Langkah 2 : Pastikan bahwa kumpulan data memberi kita sepuluh label unik.
| log.info(“Jumlah total label yang ditemukan dalam dataset pelatihan ” + MNISTTrain.totalOutcomes()); log.info(“Jumlah total label yang ditemukan dalam kumpulan data uji ” + MNISTTest.totalOutcomes()); |
Langkah 3 : Sekarang, kita akan mengkonfigurasi arsitektur model menggunakan dua lapisan konvolusi bersama dengan lapisan yang diratakan untuk menampilkan output.
Ada opsi di Deeplearning4j yang memungkinkan Anda untuk menginisialisasi skema bobot.
| // Membangun model CNN MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(biji) // benih acak .l2(0,0005) // regularisasi .weightInit(WeightInit.XAVIER) // inisialisasi skema bobot .updater(new Adam(1e-3)) // Menyetel algoritme pengoptimalan .Daftar() .layer(ConvolutionLayer.Builder baru(5, 5) //Mengatur langkah, ukuran kernel, dan fungsi aktivasi. .nIn(nChannels) .langkah(1,1) .nKeluar(20) .aktivasi(Aktivasi.IDENTITAS) .membangun()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // mengurangi convolution .kernelSize(2,2) .langkah(2,2) .membangun()) .layer(ConvolutionLayer.Builder baru(5, 5) // Mengatur langkah, ukuran kernel, dan fungsi aktivasi. .langkah(1,1) .nKeluar(50) .aktivasi(Aktivasi.IDENTITAS) .membangun()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // mengurangi convolution .kernelSize(2,2) .langkah(2,2) .membangun()) .layer(DenseLayer.Builder baru().activation(Activation.RELU) .nOut(500).build()) .layer(OutputLayer.Builder baru(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nKeluar(Numkeluaran) .aktivasi(Aktivasi.SOFTMAX) .membangun()) // lapisan keluaran akhir adalah 28x28 dengan kedalaman 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .membangun(); |
Langkah 4 : Setelah kita mengkonfigurasi arsitektur, kita akan menginisialisasi mode dan dataset pelatihan, dan memulai pelatihan model.
| Model MultiLayerNetwork = MultiLayerNetwork baru(conf); // inisialisasi bobot model. model.init(); log.info("Langkah2: mulai melatih model"); //Menetapkan listener setiap 10 iterasi dan mengevaluasi set tes di setiap epoch model.setListeners(New ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Melatih model model.fit(MNISTtrain, nEpochs); |
Saat pelatihan model dimulai, Anda akan memiliki matriks kebingungan dari akurasi klasifikasi.
Berikut keakuratan model setelah sepuluh periode pelatihan:
| ========================= Matriks Kebingungan======================== == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
Lingkungan untuk Mengembangkan Aplikasi KDD yang Didukung oleh Struktur Indeks atau ELKI adalah kumpulan algoritma dan program bawaan yang digunakan untuk penambangan data. Ditulis dalam Java, ini adalah pustaka sumber terbuka yang terdiri dari parameter yang sangat dapat dikonfigurasi dalam algoritme. Ini biasanya digunakan oleh para ilmuwan penelitian dan siswa untuk mendapatkan wawasan tentang kumpulan data. Seperti namanya, ini menyediakan lingkungan untuk mengembangkan program dan database penambangan data yang canggih menggunakan struktur indeks.
7. JSAT
Java Statistical Analysis Tool atau JSAT adalah pustaka GPL3 yang menggunakan kerangka kerja berorientasi objek untuk membantu pengguna mengimplementasikan pembelajaran mesin dengan Java. Ini biasanya digunakan untuk tujuan pendidikan mandiri oleh siswa dan pengembang. Dibandingkan dengan library implementasi AI lainnya, JSAT memiliki jumlah algoritma ML tertinggi dan tercepat di antara semua framework. Dengan nol ketergantungan eksternal, sangat fleksibel dan efisien dan menawarkan kinerja tinggi.
8. Kerangka Pembelajaran Mesin Encog
Encog ditulis dalam Java dan C# dan terdiri dari pustaka yang membantu mengimplementasikan algoritme pembelajaran mesin. Ini digunakan untuk membangun algoritme genetika, Bayesian Networks, model statistik seperti Model Markov Tersembunyi, dan banyak lagi.
9. Palu
Machine Learning for Language Toolkit atau Mallet digunakan dalam Natural Language Processing (NLP). Seperti kebanyakan kerangka implementasi ML lainnya, Mallet juga menyediakan dukungan untuk pemodelan data, pengelompokan data, pemrosesan dokumen, klasifikasi dokumen, dan sebagainya.
10. Spark MLlib
Spark MLlib digunakan oleh bisnis untuk meningkatkan efisiensi dan skalabilitas manajemen alur kerja. Ini memproses sejumlah besar data dan mendukung algoritme ML yang sarat muatan.
Lihat: Ide Proyek Pembelajaran Mesin
Kesimpulan
Ini membawa kita ke akhir artikel. Untuk informasi lebih lanjut tentang konsep Pembelajaran Mesin, hubungi fakultas top IIIT Bangalore dan Liverpool John Moores University melalui program Master of Science dalam Pembelajaran Mesin & AI upGrad.
Mengapa kita harus menggunakan Java bersama dengan Machine Learning?
Profesional Pembelajaran Mesin akan merasa lebih mudah untuk berinteraksi dengan repositori kode saat ini jika mereka memilih Java sebagai bahasa pemrograman untuk proyek mereka. Ini adalah bahasa preferensi Machine Learning karena fitur seperti kemudahan penggunaan, layanan paket, interaksi pengguna yang lebih baik, debugging cepat, dan ilustrasi grafis data. Java memudahkan pengembang Machine Learning untuk menskalakan sistem mereka, menjadikannya pilihan yang sangat baik untuk membangun aplikasi Machine Learning yang besar dan canggih dari awal. Java Virtual Machine (JVM) mendukung sejumlah lingkungan pengembangan terintegrasi (IDE) yang memungkinkan pembelajar mesin merancang alat baru dengan cepat.
Apakah belajar Java itu mudah?
Karena Java adalah bahasa tingkat tinggi, bahasa ini mudah dipahami. Sebagai pelajar, Anda tidak perlu membahas terlalu detail karena ini adalah bahasa berorientasi objek yang terstruktur dengan baik yang cukup sederhana untuk dipahami oleh pemula. Karena ada banyak prosedur yang beroperasi secara otomatis, Anda dapat menguasainya dengan cepat. Anda tidak perlu terlalu detail tentang bagaimana segala sesuatunya beroperasi di sana. Java adalah bahasa pemrograman platform-independen. Ini memungkinkan programmer untuk membuat aplikasi seluler yang dapat digunakan di perangkat apa pun. Ini adalah bahasa pilihan Internet of Things, serta alat terbaik untuk mengembangkan aplikasi tingkat perusahaan.
Apa itu ADAMS, dan apa manfaatnya dalam Pembelajaran Mesin?
Advanced Data Mining And Machine Learning System (ADAMS) adalah mesin alur kerja berlisensi GPLv3 untuk membuat dan mengelola alur kerja reaktif berbasis data yang dapat dengan mudah dimasukkan ke dalam proses bisnis. Mesin alur kerja, yang mengikuti prinsip kurang lebih, terletak di jantung ADAMS. ADAMS menggunakan struktur seperti pohon alih-alih mengizinkan pengguna untuk mengatur operator (atau aktor dalam jargon ADAMS) di atas kanvas dan kemudian secara manual menautkan input dan output. Tidak diperlukan koneksi eksplisit karena struktur ini dan aktor kontrol menentukan bagaimana data mengalir dalam proses. Representasi objek internal dan sub-operator yang bersarang di dalam penangan operator menghasilkan struktur seperti pohon. ADAMS menyediakan beragam set agen untuk pengambilan data, pemrosesan, penambangan, dan tampilan.