
Apa itu Pohon Keputusan dalam Data Mining? Jenis, Contoh & Aplikasi Dunia Nyata
Diterbitkan: 2021-06-15Daftar isi
Pengantar Penambangan Data
Data sering hadir sebagai data mentah yang perlu diproses secara efektif untuk mengubahnya menjadi informasi yang berguna. Prediksi hasil sering bergantung pada proses menemukan pola, anomali, atau korelasi dalam data. Proses itu disebut "penemuan pengetahuan dalam database".
Baru pada tahun 1990-an istilah “data mining” diciptakan. Penambangan data didirikan di atas tiga disiplin ilmu: statistik, kecerdasan buatan, dan pembelajaran mesin. Penambangan data otomatis telah mengubah proses analisis dari pendekatan yang membosankan ke pendekatan yang lebih cepat. Penambangan data memungkinkan pengguna untuk
- Hapus semua data yang berisik dan kacau
- Memahami data yang relevan dan menggunakannya untuk prediksi informasi yang berguna.
- Proses memprediksi keputusan berdasarkan informasi dipercepat .
Data mining juga bisa disebut sebagai proses mengidentifikasi pola tersembunyi dari informasi yang memerlukan kategorisasi. Hanya dengan begitu data dapat diubah menjadi data yang berguna. Data yang berguna dapat dimasukkan ke dalam gudang data, algoritma penambangan data, analisis data untuk pengambilan keputusan.
Pohon keputusan dalam penambangan data
Sebuah jenis teknik data mining, Pohon keputusan dalam data mining membangun model untuk klasifikasi data. Model dibangun dalam bentuk struktur pohon dan karenanya termasuk dalam bentuk pembelajaran terawasi. Selain model klasifikasi, pohon keputusan digunakan untuk membangun model regresi untuk memprediksi label kelas atau nilai yang membantu proses pengambilan keputusan. Baik data numerik dan kategorikal seperti jenis kelamin, usia, dll. Dapat digunakan oleh pohon keputusan.
Struktur pohon keputusan
Struktur pohon keputusan terdiri dari simpul akar, cabang, dan simpul daun. Node bercabang adalah hasil dari pohon dan node internal mewakili tes pada atribut. Node daun mewakili label kelas.
Kerja dari pohon keputusan
1. Sebuah pohon keputusan bekerja di bawah pendekatan pembelajaran terawasi untuk kedua variabel rahasia dan berkelanjutan. Dataset dibagi menjadi subset berdasarkan atribut dataset yang paling signifikan. Identifikasi atribut dan pemisahan dilakukan melalui algoritma.
2. Struktur pohon keputusan terdiri dari simpul akar, yang merupakan simpul prediktor signifikan. Proses splitting terjadi dari node keputusan yang merupakan sub-node dari pohon. Node yang tidak membelah lebih jauh disebut sebagai leaf atau terminal node.
3. Dataset dibagi menjadi wilayah homogen dan tidak tumpang tindih mengikuti pendekatan top-down. Lapisan atas menyediakan pengamatan di satu tempat yang kemudian dibagi menjadi cabang-cabang. Proses ini disebut sebagai "Pendekatan Greedy" karena fokusnya hanya pada node saat ini daripada node masa depan.
4. Sampai dan kecuali kriteria berhenti tercapai, pohon keputusan akan terus berjalan.
5. Dengan membangun pohon keputusan, banyak noise dan outlier yang dihasilkan. Untuk menghapus data outlier dan noise ini, metode “Pemangkasan pohon” diterapkan. Oleh karena itu, akurasi model meningkat.
6. Akurasi model diperiksa pada set tes yang terdiri dari tupel uji dan label kelas. Model yang akurat ditentukan berdasarkan persentase tupel dan kelas set uji klasifikasi oleh model.
Gambar 1 : Contoh pohon yang tidak dipangkas dan yang dipangkas
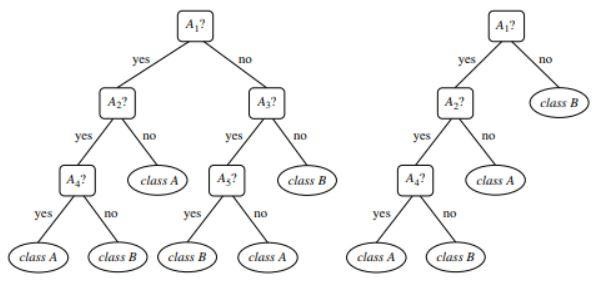
Sumber
Jenis Pohon Keputusan
Pohon keputusan mengarah pada pengembangan model untuk klasifikasi dan regresi berdasarkan struktur seperti pohon. Data dipecah menjadi subset yang lebih kecil. Hasil dari pohon keputusan adalah pohon dengan simpul keputusan dan simpul daun. Dua jenis pohon keputusan dijelaskan di bawah ini:
1. Klasifikasi
Klasifikasi termasuk membangun model yang menggambarkan label kelas penting. Mereka diterapkan di bidang pembelajaran mesin dan pengenalan pola. Pohon keputusan dalam pembelajaran mesin melalui model klasifikasi mengarah pada deteksi Penipuan, diagnosis medis, dll. Proses dua langkah dari model klasifikasi meliputi:
- Pembelajaran: Model klasifikasi berdasarkan data pelatihan dibangun.
- Klasifikasi: Keakuratan model diperiksa dan kemudian digunakan untuk klasifikasi data baru. Label kelas dalam bentuk nilai diskrit seperti "ya", atau "tidak", dll.
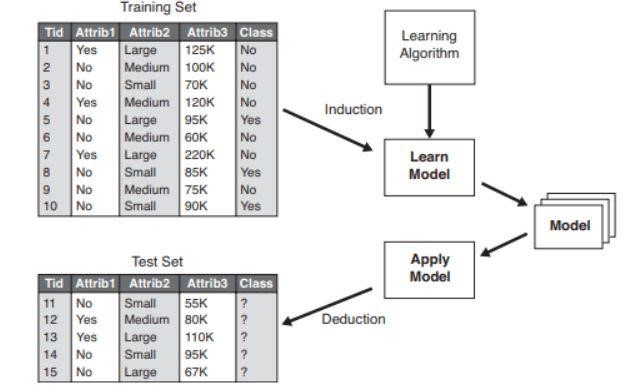
Gambar 2 : Contoh model klasifikasi .
Sumber
2. Regresi
Model regresi digunakan untuk analisis regresi data, yaitu prediksi atribut numerik. Ini juga disebut nilai kontinu. Oleh karena itu, alih-alih memprediksi label kelas, model regresi memprediksi nilai kontinu.
Daftar Algoritma yang Digunakan
Sebuah algoritma pohon keputusan yang dikenal sebagai "ID3" dikembangkan pada tahun 1980 oleh seorang peneliti mesin bernama, J. Ross Quinlan. Algoritma ini digantikan oleh algoritma lain seperti C4.5 yang dikembangkan olehnya. Kedua algoritma menerapkan pendekatan serakah. Algoritma C4.5 tidak menggunakan backtracking dan pohon dibangun dengan cara membagi dan menaklukkan rekursif top-down. Algoritme menggunakan dataset pelatihan dengan label kelas yang dibagi menjadi himpunan bagian yang lebih kecil saat pohon dibangun.
- Tiga parameter dipilih pada awalnya- daftar atribut, metode pemilihan atribut, dan partisi data. Atribut dari set pelatihan dijelaskan dalam daftar atribut.
- Metode pemilihan atribusi meliputi metode pemilihan atribut terbaik untuk diskriminasi antar tupel.
- Struktur pohon tergantung pada metode pemilihan atribut.
- Konstruksi pohon dimulai dengan satu simpul.
- Pemisahan tupel terjadi ketika label kelas yang berbeda direpresentasikan dalam sebuah tupel. Ini akan mengarah pada pembentukan cabang pohon.
- Metode pemisahan menentukan atribut mana yang harus dipilih untuk partisi data. Berdasarkan metode ini, cabang ditumbuhkan dari simpul berdasarkan hasil pengujian.
- Metode pemisahan dan partisi dilakukan secara rekursif, yang pada akhirnya menghasilkan pohon keputusan untuk tupel kumpulan data pelatihan.
- Proses pembentukan pohon terus berlangsung sampai dan kecuali tupel yang tersisa tidak dapat dipartisi lebih lanjut.
- Kompleksitas algoritma dilambangkan dengan
n * |D| * log |D|
Dimana, n adalah jumlah atribut pada dataset pelatihan D dan |D| adalah jumlah tupel.
Sumber
Gambar 3: Pemisahan nilai diskrit
Daftar algoritma yang digunakan dalam pohon keputusan adalah:
ID3
Seluruh kumpulan data S dianggap sebagai simpul akar saat membentuk pohon keputusan. Kemudian dilakukan iterasi pada setiap atribut dan pemecahan data menjadi fragmen-fragmen. Algoritma memeriksa dan mengambil atribut-atribut yang tidak diambil sebelum yang diulang. Memisahkan data dalam algoritme ID3 memakan waktu dan bukan algoritme yang ideal karena melebihi data.
C4.5
Ini adalah bentuk lanjutan dari algoritma karena data diklasifikasikan sebagai sampel. Nilai kontinu dan diskrit dapat ditangani secara efisien tidak seperti ID3. Metode pemangkasan hadir yang menghilangkan cabang yang tidak diinginkan.
KERANJANG
Baik tugas klasifikasi dan regresi dapat dilakukan oleh algoritma. Tidak seperti ID3 dan C4.5, poin keputusan dibuat dengan mempertimbangkan indeks Gini. Algoritma serakah diterapkan untuk metode pemisahan yang bertujuan untuk mengurangi fungsi biaya. Dalam tugas klasifikasi, indeks Gini digunakan sebagai fungsi biaya untuk menunjukkan kemurnian simpul daun. Dalam tugas regresi, kesalahan jumlah kuadrat digunakan sebagai fungsi biaya untuk menemukan prediksi terbaik.
CHAID
Seperti namanya, ini adalah singkatan dari Chi-square Automatic Interaction Detector, sebuah proses yang menangani semua jenis variabel. Mereka mungkin variabel nominal, ordinal, atau kontinu. Pohon regresi menggunakan uji F, sedangkan uji Chi-kuadrat digunakan dalam model klasifikasi.
MARS
Ini adalah singkatan dari Multivariate Adaptive Regression Splines. Algoritme ini diimplementasikan secara khusus dalam tugas regresi, di mana sebagian besar datanya non-linear.

Pemisahan Biner Rekursif Greedy
Metode pemisahan biner terjadi menghasilkan dua cabang. Pemisahan tupel dilakukan dengan perhitungan fungsi biaya split. Pemisahan biaya terendah dipilih dan proses dilakukan secara rekursif untuk menghitung fungsi biaya dari tupel lainnya.
Pohon Keputusan dengan Contoh Dunia Nyata
Memprediksi proses kelayakan pinjaman dari data yang diberikan.
Langkah1: Memuat data
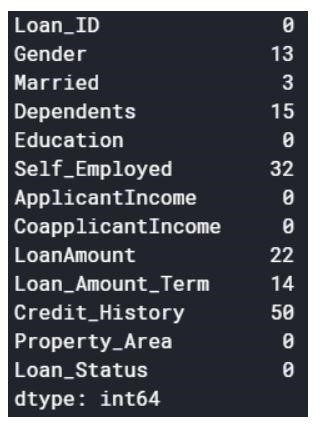
Nilai null dapat diturunkan atau diisi dengan beberapa nilai. Bentuk kumpulan data asli adalah (614,13), dan kumpulan data baru setelah menjatuhkan nilai nol adalah (480,13).
Step2: lihat dataset.

Langkah 3: Memisahkan data menjadi set pelatihan dan pengujian.
Langkah 4: Bangun model dan sesuaikan dengan set kereta

Sebelum visualisasi, beberapa perhitungan harus dibuat.
Perhitungan 1: hitung entropi dari total dataset.

Perhitungan 2: Temukan entropi dan keuntungan untuk setiap kolom.
- kolom jenis kelamin
- Kondisi 1: kumpulan data dengan semua laki-laki di dalamnya dan kemudian,
p = 278, n=116 , p+n=489
Entropi(G=Pria) = 0,87
- Kondisi 2: kumpulan data dengan semua perempuan di dalamnya dan kemudian,
p = 54 , n = 32 , p+n = 86
Entropi(G=Wanita) = 0,95
- Informasi rata-rata di kolom jenis kelamin

- kolom menikah
- Kondisi 1: Menikah = Ya(1)
Dalam pembagian ini seluruh kumpulan data dengan status Menikah ya
p = 227 , n = 84 , p+n = 311
E(Menikah = Ya) = 0,84
- Kondisi 2: Menikah = Tidak(0)
Dalam pemisahan ini seluruh kumpulan data dengan status Menikah no
p = 105 , n = 64 , p+n = 169
E(Menikah = Tidak) = 0,957
- Rata-rata Informasi pada kolom Menikah adalah
- kolom pendidikan
- Kondisi 1: Pendidikan = Lulusan(1)
p = 271, n = 112 , p+n = 383
E(Pendidikan = Lulusan) = 0.87
- Kondisi 2: Pendidikan = Bukan Lulusan(0)
p = 61 , n = 36 , p+n = 97
E(Pendidikan = Tidak Lulus) = 0.95
- Rata-rata kolom Informasi Pendidikan = 0,886
Keuntungan = 0,01
4) Kolom Wiraswasta
- Kondisi 1: Wiraswasta = Ya(1)
p = 43 , n = 23 , p+n = 66
E(Wiraswasta=Ya) = 0,93
- Kondisi 2: Wiraswasta = Tidak(0)
p = 289 , n = 125 , p+n = 414
E(Wiraswasta=Tidak) = 0.88
- Rata-rata Informasi Wiraswasta di Kolom Pendidikan = 0,886
Keuntungan = 0,01
- Kolom Skor Kredit: kolom memiliki nilai 0 dan 1.
- Kondisi 1: Skor Kredit = 1
p = 325 , n = 85 , p+n = 410
E(Skor Kredit = 1) = 0,73
- Kondisi 2: Skor Kredit = 0
p = 63 , n = 7 , p+n = 70
E(Skor Kredit = 0) = 0,46
- Rata-rata Informasi pada kolom Skor Kredit = 0.69
Keuntungan = 0,2
Bandingkan semua nilai perolehan

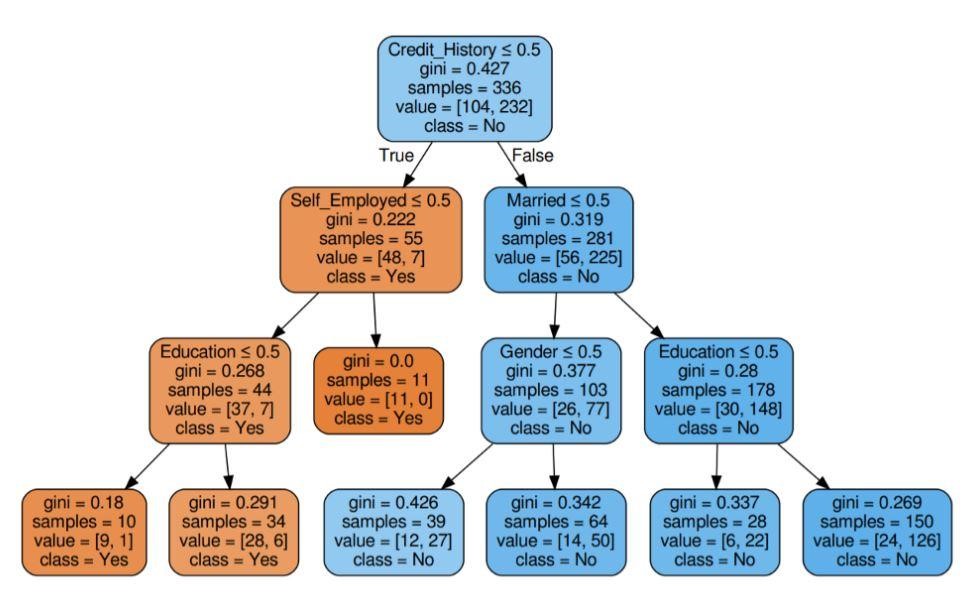
Skor kredit memiliki keuntungan tertinggi. Oleh karena itu, ini akan digunakan sebagai simpul akar.
Langkah 5: Visualisasikan Pohon Keputusan

Gambar 5: Pohon keputusan dengan kriteria Gini
 Sumber
Sumber
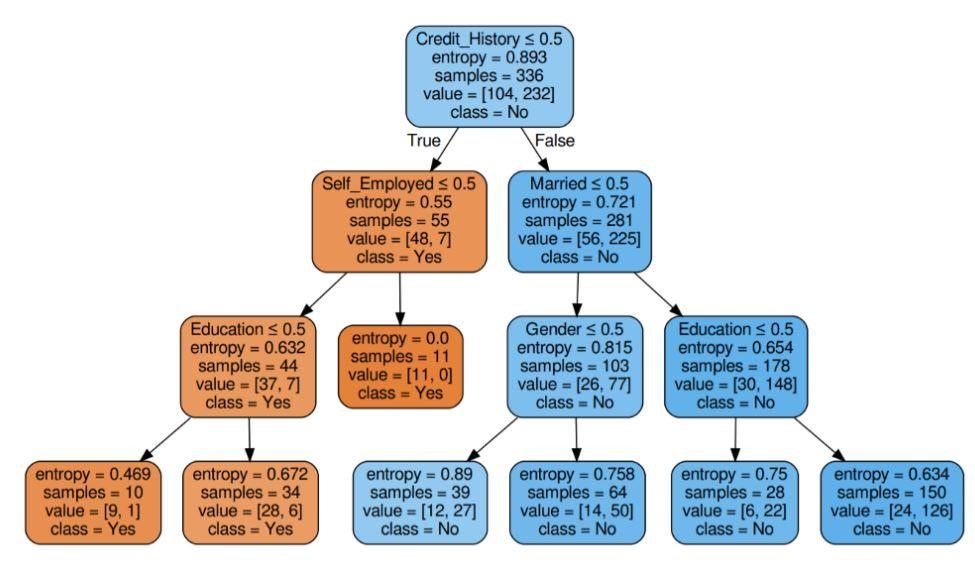
Gambar 6: Pohon keputusan dengan entropi kriteria
Sumber
Langkah 6: Periksa skor model
Hampir 80% persen akurasi mencetak gol.
Daftar Aplikasi
Pohon keputusan sebagian besar digunakan oleh pakar informasi untuk melakukan penyelidikan analitis. Mereka mungkin digunakan secara luas untuk tujuan bisnis untuk menganalisis atau memprediksi kesulitan. Fleksibilitas pohon keputusan memungkinkan mereka untuk digunakan di area yang berbeda:
1. Perawatan Kesehatan
Pohon keputusan memungkinkan prediksi apakah pasien menderita penyakit tertentu dengan kondisi usia, berat badan, jenis kelamin, dll. Prediksi lain termasuk memutuskan efek obat dengan mempertimbangkan faktor-faktor seperti komposisi, periode pembuatan, dll.
2. Sektor perbankan
Pohon keputusan membantu dalam memprediksi apakah seseorang memenuhi syarat untuk mendapatkan pinjaman dengan mempertimbangkan status keuangan, gaji, anggota keluarga, dll. Pohon keputusan juga dapat mengidentifikasi penipuan kartu kredit, default pinjaman, dll.
3. Sektor Pendidikan
Daftar pendek siswa berdasarkan nilai prestasinya, kehadiran, dll. dapat diputuskan dengan bantuan pohon keputusan.
Daftar Keuntungan
- Hasil yang dapat diinterpretasikan dari model keputusan dapat direpresentasikan kepada manajemen senior dan pemangku kepentingan.
- Saat membangun model pohon keputusan, pra-pemrosesan data, yaitu normalisasi, penskalaan, dll. tidak diperlukan.
- Kedua jenis data numerik dan kategorikal dapat ditangani oleh pohon keputusan yang menampilkan efisiensi penggunaan yang lebih tinggi dibandingkan algoritma lain.
- Nilai yang hilang dalam data tidak mempengaruhi proses pohon keputusan sehingga menjadikannya algoritma yang fleksibel.
Apa selanjutnya?
Jika Anda tertarik untuk mendapatkan pengalaman langsung dalam penambangan data dan dilatih oleh para ahli di bidangnya, Anda dapat melihat Program PG Eksekutif upGrad dalam Ilmu Data. Kursus ini ditujukan untuk semua kelompok usia dalam usia 21-45 tahun dengan kriteria kelayakan minimum 50% atau nilai kelulusan yang setara dalam kelulusan. Setiap profesional yang bekerja dapat bergabung dengan program PG eksekutif yang disertifikasi dari IIIT Bangalore.
Pohon Keputusan dalam Data mining memiliki kemampuan untuk menangani data yang sangat rumit. Semua pohon keputusan memiliki tiga simpul atau bagian penting. Mari kita bahas masing-masing di bawah ini. Sekarang setelah kita memahami cara kerja pohon keputusan, mari kita coba melihat beberapa keuntungan menggunakan pohon keputusan dalam penambangan dataApa itu Pohon Keputusan dalam Data Mining?
Pohon keputusan adalah cara untuk membangun model di Data mining. Ini dapat dipahami sebagai pohon biner terbalik. Ini termasuk simpul akar, beberapa cabang, dan simpul daun di ujungnya.
Setiap node internal dalam pohon Keputusan menandakan studi tentang atribut. Masing-masing divisi menandakan konsekuensi dari studi atau pemeriksaan tertentu. Dan akhirnya, setiap simpul daun mewakili tag kelas.
Tujuan utama dari pembuatan pohon keputusan adalah untuk membuat suatu ideal yang dapat digunakan untuk meramalkan kelas tertentu dengan menggunakan prosedur penilaian pada data sebelumnya.
Kita mulai dengan simpul akar, membuat beberapa hubungan dengan variabel akar, dan membuat pembagian yang sesuai dengan nilai-nilai tersebut. Berdasarkan pilihan dasar, kami melompat ke node berikutnya. Apa saja node penting yang digunakan dalam Pohon Keputusan?
Ketika kita menghubungkan semua node ini, kita mendapatkan pembagian. Kita dapat membentuk pohon dengan berbagai kesulitan menggunakan simpul dan divisi ini untuk waktu yang tidak terbatas. Apa keuntungan menggunakan Pohon Keputusan?
1. Ketika kita membandingkannya dengan metode lain, Pohon keputusan tidak memerlukan banyak komputasi untuk pelatihan data selama pra-pemrosesan.
2. Stabilisasi informasi tidak dilibatkan dalam Pohon keputusan.
3. Juga, mereka bahkan tidak memerlukan penskalaan informasi.
4. Bahkan jika beberapa nilai dihilangkan dalam dataset, ini tidak mengganggu konstruksi pohon.
5. Model-model naluriah ini identik. Mereka bebas stres untuk deskripsi juga.