
Panduan Utama Untuk Membangun Scraper Web yang Dapat Diskalakan Dengan Scrapy
Diterbitkan: 2022-03-10Pengikisan web adalah cara untuk mengambil data dari situs web tanpa memerlukan akses ke API atau database situs web. Anda hanya memerlukan akses ke data situs — selama browser Anda dapat mengakses data, Anda akan dapat mengikisnya.
Secara realistis, sebagian besar waktu Anda hanya dapat membuka situs web secara manual dan mengambil data 'dengan tangan' menggunakan salin dan tempel, tetapi dalam banyak kasus yang akan memakan waktu berjam-jam untuk pekerjaan manual, yang pada akhirnya dapat menghabiskan biaya jauh lebih berharga daripada nilai datanya, terutama jika Anda telah mempekerjakan seseorang untuk melakukan tugas itu untuk Anda. Mengapa mempekerjakan seseorang untuk bekerja pada 1-2 menit per kueri ketika Anda bisa mendapatkan program untuk melakukan kueri secara otomatis setiap beberapa detik?
Misalnya, katakanlah Anda ingin menyusun daftar pemenang Oscar untuk film terbaik, beserta sutradara, aktor yang dibintangi, tanggal rilis, dan waktu tayang. Dengan menggunakan Google, Anda dapat melihat ada beberapa situs yang akan mencantumkan nama film ini, dan mungkin beberapa informasi tambahan, tetapi umumnya Anda harus menindaklanjuti dengan tautan untuk menangkap semua informasi yang Anda inginkan.
Jelas, akan tidak praktis dan memakan waktu untuk menelusuri setiap tautan dari tahun 1927 hingga hari ini dan secara manual mencoba menemukan informasi melalui setiap halaman. Dengan pengikisan web, kita hanya perlu menemukan situs web dengan halaman yang memiliki semua informasi ini, dan kemudian mengarahkan program kita ke arah yang benar dengan instruksi yang benar.
Dalam tutorial ini, kami akan menggunakan Wikipedia sebagai situs web kami karena berisi semua informasi yang kami butuhkan dan kemudian menggunakan Scrapy pada Python sebagai alat untuk mengikis informasi kami.
Beberapa peringatan sebelum kita mulai:
Pengikisan data melibatkan peningkatan beban server untuk situs yang Anda kikis, yang berarti biaya yang lebih tinggi untuk perusahaan yang menghosting situs dan pengalaman kualitas yang lebih rendah untuk pengguna lain dari situs tersebut. Kualitas server yang menjalankan situs web, jumlah data yang Anda coba dapatkan, dan kecepatan pengiriman permintaan ke server akan memoderasi efek yang Anda miliki di server. Dengan mengingat hal ini, kita perlu memastikan bahwa kita mematuhi beberapa aturan.
Sebagian besar situs juga memiliki file bernama robots.txt di direktori utama mereka. File ini menetapkan aturan untuk direktori apa yang tidak ingin diakses oleh scraper. Halaman Syarat & Ketentuan situs web biasanya akan memberi tahu Anda apa kebijakan mereka tentang pengikisan data. Misalnya, halaman ketentuan IMDB memiliki klausa berikut:
Robot dan Screen Scraping: Anda tidak boleh menggunakan data mining, robot, screen scraping, atau alat pengumpulan dan ekstraksi data serupa di situs ini, kecuali dengan persetujuan tertulis dari kami sebagaimana tercantum di bawah ini.
Sebelum kami mencoba mendapatkan data situs web, kami harus selalu memeriksa persyaratan situs web dan robots.txt untuk memastikan kami memperoleh data hukum. Saat membangun scraper kami, kami juga perlu memastikan bahwa kami tidak membanjiri server dengan permintaan yang tidak dapat ditangani.
Untungnya, banyak situs web menyadari kebutuhan pengguna untuk mendapatkan data, dan mereka menyediakan data melalui API. Jika ini tersedia, biasanya merupakan pengalaman yang jauh lebih mudah untuk mendapatkan data melalui API daripada melalui pengikisan.
Wikipedia mengizinkan pengikisan data, selama bot tidak berjalan 'terlalu cepat', seperti yang ditentukan dalam robots.txt . Mereka juga menyediakan kumpulan data yang dapat diunduh sehingga orang dapat memproses data di mesin mereka sendiri. Jika kita pergi terlalu cepat, server akan secara otomatis memblokir IP kita, jadi kita akan menerapkan pengatur waktu agar tetap dalam aturan mereka.
Memulai, Memasang Pustaka yang Relevan Menggunakan Pip
Pertama-tama, untuk memulai, mari kita instal Scrapy.
jendela
Instal versi terbaru Python dari https://www.python.org/downloads/windows/
Catatan: Pengguna Windows juga memerlukan Microsoft Visual C++ 14.0, yang dapat Anda ambil dari "Microsoft Visual C++ Build Tools" di sini.
Anda juga ingin memastikan bahwa Anda memiliki pip versi terbaru.
Di cmd.exe , ketik:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyIni akan menginstal Scrapy dan semua dependensi secara otomatis.
Linux
Pertama, Anda ingin menginstal semua dependensi:
Di Terminal, masukkan:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devSetelah itu semua diinstal, cukup ketik:
pip install --upgrade pipUntuk memastikan pip diperbarui, lalu:
pip install scrapyDan itu semua dilakukan.
Mac
Pertama, Anda harus memastikan bahwa Anda memiliki c-compiler di sistem Anda. Di Terminal, masukkan:
xcode-select --installSetelah itu, instal homebrew dari https://brew.sh/.
Perbarui variabel PATH Anda sehingga paket homebrew digunakan sebelum paket sistem:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcInstal Python:
brew install pythonDan kemudian pastikan semuanya diperbarui:
brew update; brew upgrade pythonSetelah itu selesai, instal saja Scrapy menggunakan pip:
pip install Scrapy > ## Ikhtisar Scrapy, Bagaimana Potongan Cocok Bersama, Pengurai, Laba-laba, DllAnda akan menulis skrip yang disebut 'Laba-laba' untuk dijalankan, tetapi jangan khawatir, laba-laba Scrapy tidak menakutkan sama sekali meskipun namanya. Satu-satunya kesamaan yang dimiliki laba-laba Scrapy dan laba-laba asli adalah mereka suka merangkak di web.
Di dalam laba-laba adalah class yang Anda tentukan yang memberi tahu Scrapy apa yang harus dilakukan. Misalnya, di mana harus mulai merayapi, jenis permintaan yang dibuat, cara mengikuti tautan di halaman, dan cara mem-parsing data. Anda bahkan dapat menambahkan fungsi khusus untuk memproses data juga, sebelum mengeluarkan kembali ke file.
Untuk memulai laba-laba pertama kita, pertama-tama kita harus membuat proyek Scrapy. Untuk melakukan ini, masukkan ini ke baris perintah Anda:
scrapy startproject oscarsIni akan membuat folder dengan proyek Anda.
Kita akan mulai dengan laba-laba dasar. Kode berikut harus dimasukkan ke dalam skrip python. Buka skrip python baru di /oscars/spiders dan beri nama oscars_spider.py
Kami akan mengimpor scrapy.
import scrapyKami kemudian mulai mendefinisikan kelas Spider kami. Pertama, kami menetapkan nama dan kemudian domain yang diizinkan untuk dikikis oleh laba-laba. Akhirnya, kami memberi tahu laba-laba dari mana harus mulai menggores.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Selanjutnya, kita membutuhkan sebuah fungsi yang akan menangkap informasi yang kita inginkan. Untuk saat ini, kami hanya akan mengambil judul halaman. Kami menggunakan CSS untuk menemukan tag yang membawa teks judul, dan kemudian kami mengekstraknya. Terakhir, kami mengembalikan informasi ke Scrapy untuk dicatat atau ditulis ke file.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Sekarang simpan kode di /oscars/spiders/oscars_spider.py
Untuk menjalankan laba-laba ini, cukup buka baris perintah Anda dan ketik:
scrapy crawl oscarsAnda akan melihat output seperti ini:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Selamat, Anda telah membuat scraper Scrapy dasar pertama Anda!

Kode lengkap:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataJelas, kami ingin melakukan sedikit lebih banyak, jadi mari kita lihat cara menggunakan Scrapy untuk mengurai data.
Pertama, mari kita mengenal shell Scrapy. Shell Scrapy dapat membantu Anda menguji kode Anda untuk memastikan bahwa Scrapy mengambil data yang Anda inginkan.
Untuk mengakses shell, masukkan ini ke baris perintah Anda:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Ini pada dasarnya akan membuka halaman yang telah Anda arahkan dan itu akan membiarkan Anda menjalankan satu baris kode. Misalnya, Anda dapat melihat HTML mentah halaman dengan mengetikkan:
print(response.text)Atau buka halaman di browser default Anda dengan mengetik:
view(response)Tujuan kita di sini adalah untuk menemukan kode yang berisi informasi yang kita inginkan. Untuk saat ini, mari kita coba ambil nama judul filmnya saja.
Cara termudah untuk menemukan kode yang kita butuhkan adalah dengan membuka halaman di browser kita dan memeriksa kodenya. Dalam contoh ini, saya menggunakan Chrome DevTools. Cukup klik kanan pada judul film apa saja dan pilih 'inspect':
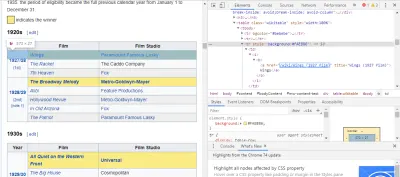
Seperti yang Anda lihat, para pemenang Oscar memiliki latar belakang kuning sedangkan para nominasi memiliki latar belakang polos. Ada juga tautan ke artikel tentang judul film, dan tautan untuk film berakhiran film) . Sekarang kita tahu ini, kita bisa menggunakan pemilih CSS untuk mengambil data. Di shell Scrapy, ketik:
response.css(r"tr[] a[href*='film)']").extract()Seperti yang Anda lihat, Anda sekarang memiliki daftar semua Pemenang Film Terbaik Oscar!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Kembali ke tujuan utama kami, kami ingin daftar pemenang Oscar untuk film terbaik, bersama dengan sutradara mereka, aktor yang dibintangi, tanggal rilis, dan waktu tayang. Untuk melakukan ini, kita perlu Scrapy untuk mengambil data dari masing-masing halaman film tersebut.
Kita harus menulis ulang beberapa hal dan menambahkan fungsi baru, tetapi jangan khawatir, ini cukup mudah.
Kita akan mulai dengan memulai scraper dengan cara yang sama seperti sebelumnya.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Tapi kali ini, dua hal akan berubah. Pertama, kita akan mengimpor time bersama dengan scrapy karena kita ingin membuat timer untuk membatasi seberapa cepat bot menggores. Juga, ketika kami mengurai halaman untuk pertama kalinya, kami hanya ingin mendapatkan daftar tautan ke setiap judul, jadi kami dapat mengambil informasi dari halaman tersebut sebagai gantinya.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Di sini kami membuat loop untuk mencari setiap tautan pada halaman yang berakhiran film) dengan latar belakang kuning di dalamnya dan kemudian kami menggabungkan tautan tersebut menjadi daftar URL, yang akan kami kirim ke fungsi parse_titles untuk diteruskan lebih lanjut. Kami juga menyelipkan penghitung waktu agar hanya meminta halaman setiap 5 detik. Ingat, kita bisa menggunakan shell Scrapy untuk menguji field response.css kita untuk memastikan kita mendapatkan data yang benar!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data Pekerjaan sebenarnya diselesaikan dalam fungsi parse_data kami, di mana kami membuat kamus yang disebut data dan kemudian mengisi setiap kunci dengan informasi yang kami inginkan. Sekali lagi, semua pemilih ini ditemukan menggunakan Chrome DevTools seperti yang ditunjukkan sebelumnya dan kemudian diuji dengan shell Scrapy.
Baris terakhir mengembalikan kamus data kembali ke Scrapy untuk disimpan.
Kode lengkap:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataTerkadang kami ingin menggunakan proxy karena situs web akan mencoba memblokir upaya kami untuk menggores.
Untuk melakukan ini, kita hanya perlu mengubah beberapa hal. Menggunakan contoh kita, dalam def parse() kita, kita perlu mengubahnya menjadi berikut:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqIni akan merutekan permintaan melalui server proxy Anda.
Deployment Dan Logging, Tunjukkan Cara Sebenarnya Mengelola Laba-laba Dalam Produksi
Sekarang saatnya untuk menjalankan laba-laba kita. Untuk membuat Scrapy mulai menggores dan kemudian menghasilkan file CSV, masukkan perintah berikut ke prompt perintah Anda:
scrapy crawl oscars -o oscars.csvAnda akan melihat output besar, dan setelah beberapa menit, itu akan selesai dan Anda akan memiliki file CSV di folder proyek Anda.
Hasil Kompilasi, Tunjukkan Cara Menggunakan Hasil yang Dikompilasi Pada Langkah Sebelumnya
Saat Anda membuka file CSV, Anda akan melihat semua informasi yang kami inginkan (diurutkan berdasarkan kolom dengan judul). Ini sangat sederhana.
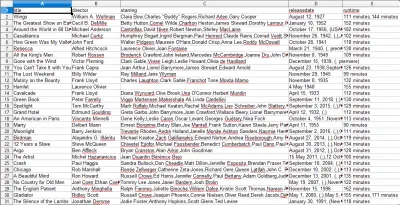
Dengan pengikisan data, kami dapat memperoleh hampir semua kumpulan data khusus yang kami inginkan, selama informasi tersebut tersedia untuk umum. Apa yang ingin Anda lakukan dengan data ini terserah Anda. Keterampilan ini sangat berguna untuk melakukan riset pasar, memperbarui informasi di situs web, dan banyak hal lainnya.
Ini cukup mudah untuk mengatur scraper web Anda sendiri untuk mendapatkan dataset kustom Anda sendiri, namun, selalu ingat bahwa mungkin ada cara lain untuk mendapatkan data yang Anda butuhkan. Bisnis banyak berinvestasi untuk menyediakan data yang Anda inginkan, jadi wajar saja jika kami menghormati syarat dan ketentuan mereka.
Sumber Daya Tambahan Untuk Mempelajari Lebih Banyak Tentang Scrapy Dan Web Scraping Secara Umum
- Situs Web Resmi Scrapy
- Halaman GitHub Scrapy
- “10 Alat Scraping Data Terbaik dan Alat Scraping Web,” Scraper API
- “5 Tips Untuk Mengikis Web Tanpa Diblokir atau Masuk Daftar Hitam,” Scraper API
- Parsel, library Python untuk menggunakan ekspresi reguler untuk mengekstrak data dari HTML.