
Pohon dalam Struktur Data: 8 Jenis Pohon Yang Harus Diketahui Setiap Ilmuwan Data
Diterbitkan: 2021-05-26Daftar isi
pengantar
Dalam domain komputasi, struktur data mengacu pada pola pengaturan data pada disk, yang memungkinkan penyimpanan dan tampilan yang nyaman. Mereka berkaitan dengan bidang ilmu data, yang telah diprediksi menjadi pilihan karir yang menggiurkan pada tahun 2021. Berdasarkan prediksi untuk beberapa tahun ke depan, model pembelajaran mendalam skala besar dan perangkat pintar generasi berikutnya akan membuka masa depan sektor ini.
Dengan demikian, memperoleh pengetahuan tentang struktur data akan menjadi penting untuk menemukan karir yang cocok di tengah kemajuan teknologi. Sesuai prediksi Industri Ilmu Data tahun 2021, AS dan India akan mempekerjakan sekitar 50.000 ilmuwan data dan 300.000 analis data dalam 2.50.000+ perusahaan mereka. [1]
Struktur data diterapkan untuk merancang jalur untuk alokasi, pengelolaan, dan pengambilan informasi. Struktur data sangat diperlukan untuk menyusun dan meningkatkan efisiensi data yang diproses secara keseluruhan. Mereka mengelola data dengan mengelompokkan dan mengaturnya untuk memfasilitasi pertukaran informasi secara efektif.
Pohon dalam Struktur Data
'Pohon' adalah jenis ADT (Abstract Data Types), yang mengikuti pola hierarkis untuk alokasi datanya. Pada dasarnya, pohon adalah kumpulan beberapa node yang terhubung melalui tepi. 'Pohon' ini membentuk desain struktur data yang menyerupai pohon, di mana node 'root' mengarah ke node 'parent', yang akhirnya mengarah ke node 'children'. Koneksi dibuat dengan garis yang dikenal sebagai 'tepi'.
Node 'Daun' adalah titik akhir tanpa node turunan lebih lanjut yang berasal darinya. Pohon dalam struktur data memainkan peran penting karena sifat pengaturannya yang non-linier. Ini memungkinkan waktu respons yang lebih cepat selama pencarian, bersama dengan kenyamanan selama tahap desain.
Jenis Pohon dalam Struktur Data
Berbagai jenis pohon dalam struktur data dijelaskan secara mendalam di bawah ini:
1. Pohon Umum
Pohon umum dicirikan oleh tidak adanya spesifikasi atau batasan pada jumlah anak yang dapat dimiliki sebuah simpul. Setiap pohon dengan struktur hierarki dapat diklasifikasikan sebagai pohon umum. Sebuah node bisa memiliki banyak anak, dan bisa ada kombinasi apapun untuk orientasi pohon. Node dapat berupa derajat apa pun, dari 0 hingga n.
Berikut ini adalah contoh klasik dari pohon umum dalam struktur data, dengan '2' di bagian atas sebagai simpul akar.
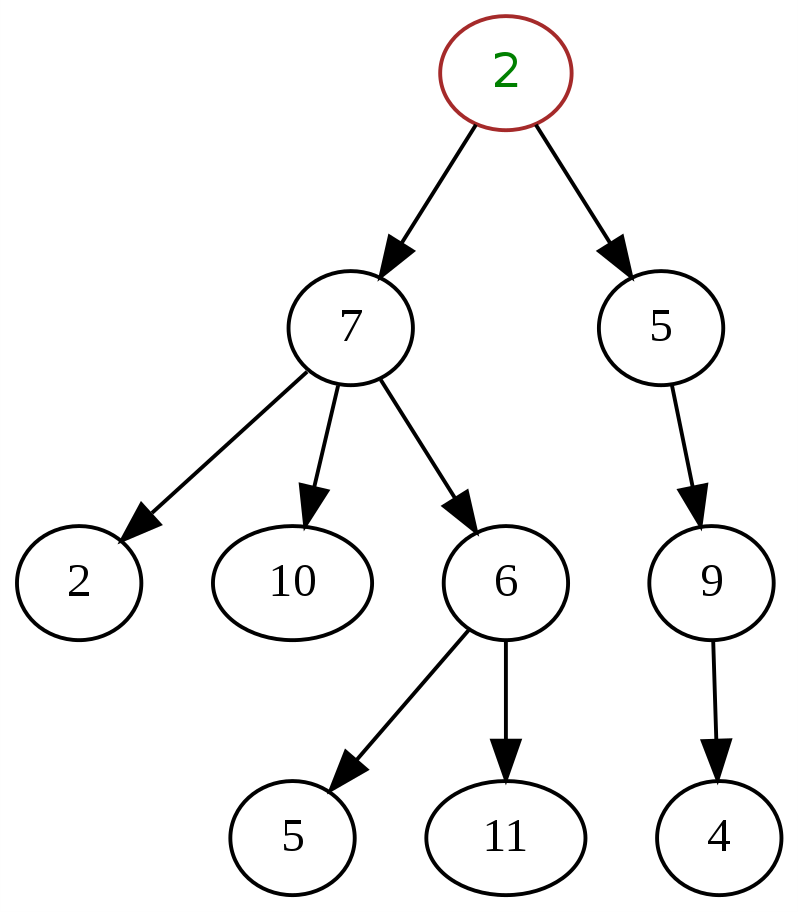
Sumber
2. Pohon Biner
Seperti yang didefinisikan oleh kata 'biner', yang berarti dua angka, pohon biner terdiri dari node yang dapat memiliki 2 node anak. Setiap node dalam pohon biner dapat memiliki paling banyak 0, 1, atau 2 node. Pohon biner dalam struktur data adalah ADT yang sangat fungsional dan dapat dibagi lagi menjadi banyak jenis. Mereka terutama digunakan dalam struktur data untuk dua tujuan:
- Untuk mengakses node dan melabelinya, seperti yang diamati di Binary Search Trees.
- Untuk representasi data melalui struktur bifurcating.
Berikut ini adalah diagram dasar pohon biner dalam struktur data:
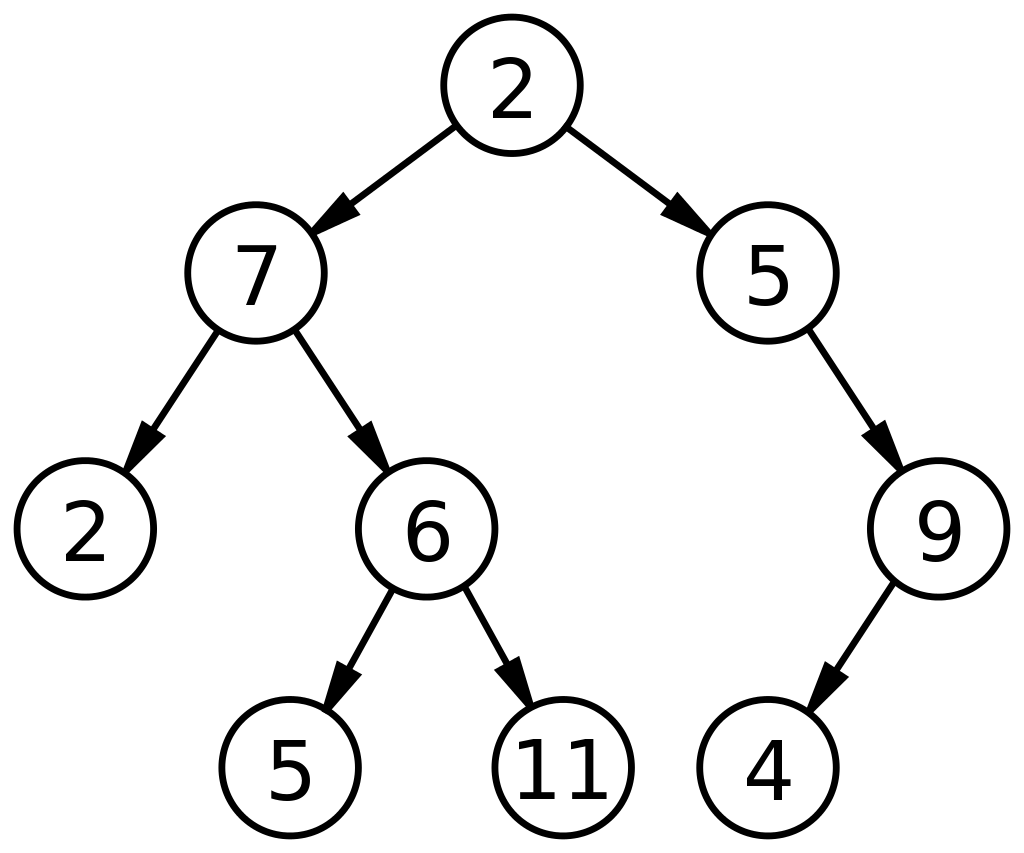
Sumber
3. Pohon Pencarian Biner
Binary Search Tree (BST) adalah subtipe unik dari pohon biner yang disusun sedemikian rupa untuk memfasilitasi pencarian/pencarian atau penambahan/penghapusan data yang lebih cepat. Sebuah BST didefinisikan oleh representasi dari node berdasarkan tiga bidang: data, anak kirinya, dan anak kanannya. Faktor yang mengatur untuk BST adalah:
- Setiap simpul di sisi kiri (anak kiri) harus memiliki nilai yang lebih kecil dari simpul induknya.
- Setiap simpul di sisi kanan (anak kanan) harus memiliki nilai yang lebih tinggi dari simpul induknya.
Susunan seperti itu mengurangi waktu pencarian menjadi setengah dari pencarian linier, seperti yang ditemukan dalam array. Dengan demikian, pohon pencarian biner dalam struktur data dapat diterapkan secara luas untuk pencarian dan pengurutan dibandingkan dengan ADT lainnya.
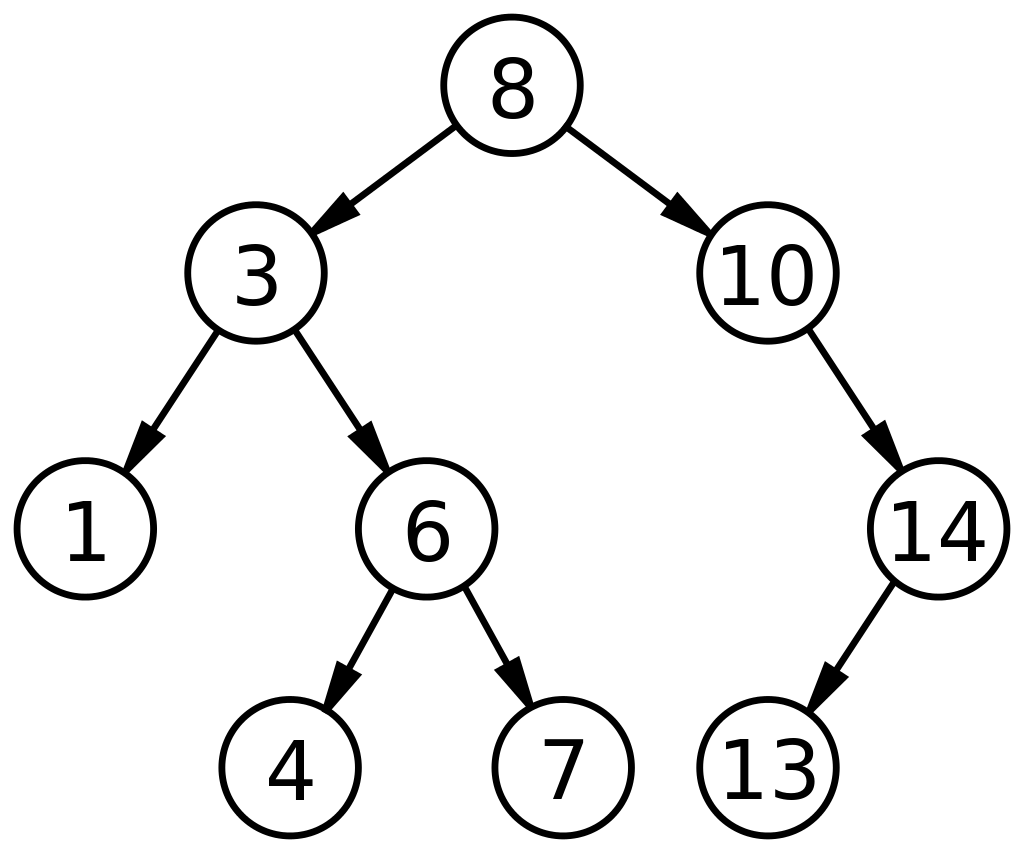
Sumber
Meskipun BT dan BST pada dasarnya adalah pohon dalam struktur data , jangan bingung dengan kesamaan nama mereka. Cari tahu perbedaan antara pohon biner dan pohon pencarian biner secara detail di upGrad.
4. Pohon AVL
Pohon AVL mendapatkan namanya dari penemunya: Adelson-Velsky dan Landis. Pohon AVL dicirikan oleh sifat self-balancing. Ketinggian dua subpohon dari simpul akarnya dibatasi hingga kurang dari dua. Ketika perbedaan ketinggian meningkat di atas 1, node anak diseimbangkan kembali.
Pohon AVL memiliki keseimbangan tinggi, dan penyeimbangan kembali ini terjadi melalui rotasi tunggal atau ganda. Faktor penyeimbang adalah selisih antara ketinggian subpohon kiri dan subpohon kanan, dan nilainya adalah -1, 0, dan 1.
5. Pohon Hitam Merah
Jenis ini menyerupai pohon AVL karena pohon merah hitam juga memiliki tinggi yang seimbang. Yang membedakannya adalah tidak diperlukan lebih dari dua putaran untuk menyeimbangkannya. Mereka berisi bit tambahan yang mendefinisikan warna merah atau hitam dari sebuah node, yang memastikan bahwa pohon seimbang selama penghapusan dan penyisipan. Pengkodean warna merah hitam juga dicat ulang selama perubahan tetapi hampir tanpa biaya memori tambahan.

6. Splay Pohon
Subtipe lain dari pohon pencarian biner, pohon splay, memiliki properti unik dalam melakukan operasi rotasi untuk menyesuaikan node terbaru. Node yang diakses baru-baru ini diatur sebagai root node dengan melakukan rotasi. Ini adalah pohon yang seimbang, tetapi bukan pohon yang seimbang.
Tindakan 'melebarkan' dilakukan setelah pencarian pohon biner awal, karena rotasi pohon dilakukan dengan cara tertentu. Setelah setiap operasi, pohon diputar untuk menyeimbangkan dirinya sendiri, dan elemen yang dicari diatur ke atas sebagai simpul akar.
7. Trap
'Treaps' dalam struktur data adalah kombinasi dari pohon dan tumpukan. Dalam BST, nilai anak kiri harus lebih kecil dari simpul akar, dan nilai anak kanan harus lebih tinggi. Dalam struktur data heap, simpul akar memiliki nilai terendah, dan simpul turunannya (kiri dan kanan) memiliki nilai lebih besar.
Jadi, treap memegang nilai dalam bentuk kunci (menyerupai BST) dan prioritas (seperti tumpukan). Node dengan prioritas tertinggi dimasukkan terlebih dahulu ke dalam pohon pencarian biner dengan cara bahwa nomor prioritas adalah nomor acak independen. Mereka memelihara satu set dinamis kunci yang dipesan dan memungkinkan pencarian biner di dalam kunci mereka.
8. B-Pohon
Sebagai jenis pohon penyeimbang diri dalam struktur data, B-Tree mengurutkan data untuk memungkinkan pencarian, akses berurutan, penghapusan, dan penyisipan dalam waktu logaritmik. Tidak seperti pohon biner, pohon B memungkinkan simpulnya memiliki lebih dari dua anak. Mereka kompatibel dengan database dan sistem file yang membaca dan menulis blok data yang lebih besar.
B-tree dalam struktur data digunakan untuk sistem penyimpanan yang lebih besar, seperti disk. Semua daun tidak membawa informasi, dan mereka muncul dalam tingkat yang sama. Node internal dari B-tree dapat memiliki ukuran variabel node anak yang terikat oleh suatu rentang.
Ini adalah pohon dalam struktur data , yang diimplementasikan oleh programmer yang merancang aliran data. Mempelajari karakteristik dan aplikasi unik mereka sangat penting untuk perjalanan Anda menjadi ilmuwan data. Metode lain untuk meningkatkan keterampilan Anda adalah dengan berlatih melalui berbagai proyek yang memerlukan pengetahuan tentang pohon dalam struktur data dan bentuk ADT lainnya.
Untuk menerapkan pengetahuan Anda untuk proyek DS, tautan blog berikut memiliki 13 ide dan topik proyek struktur data yang menarik untuk pemula [2021] .
Kesimpulan
Mempelajari konsep seperti pohon dalam struktur data bisa jadi rumit, dan calon pemrogram membutuhkan bimbingan ahli untuk mendidik diri mereka sendiri. Untuk mempelajari lebih lanjut tentang pohon dalam struktur data, lihat kursus online oleh upGrad . Program PG Eksekutif dalam Pengembangan Perangkat Lunak – Spesialisasi dalam DevOps dengan DevOps oleh IIIT-B & upGrad dapat membantu Anda membangun karir sebagai programmer.
Karena kemahiran struktur data merupakan bagian integral dari proses pengkodean, ini dapat membantu siswa menjadi programmer ahli dan pengembang perangkat lunak. Pemrogram dan ilmuwan data pasti akan dibutuhkan selama beberapa dekade mendatang.
Kami memiliki 500 juta pengguna internet di India, menghasilkan dan menggunakan data dalam jumlah besar, yang membutuhkan ribuan ilmuwan data untuk dipekerjakan untuk memenuhi permintaan. [2] Ilmuwan data ini membutuhkan pendidikan yang tepat, dengan keahlian teknologi yang relevan, untuk mencari pekerjaan di sektor ini.
Program PG Eksekutif dalam Pengembangan Perangkat Lunak – Spesialisasi dalam Pengembangan Full Stack , dikuratori oleh upGrad & IIIT-Bangalore, dapat membantu Anda meningkatkan profil dan mengamankan peluang kerja yang lebih baik sebagai programmer.
- Pohon pencarian adalah struktur data yang digunakan untuk menemukan kunci tertentu dalam satu set data. Setiap kunci simpul harus lebih besar daripada kunci apa pun di subpohon di sebelah kiri tetapi lebih kecil dari kunci di subpohon di sebelah kanan agar pohon bertindak sebagai pohon pencarian. Data hierarki, seperti struktur folder, struktur organisasi, dan data XML/HTML, harus disimpan dalam pohon. Pohon biner sempurna adalah pohon di mana setiap simpul interior memiliki dua keturunan dan setiap daun memiliki kedalaman atau tingkat yang sama. Bagan leluhur (non-incest) seseorang hingga kedalaman tertentu adalah contoh pohon biner sempurna, karena setiap orang memiliki dua orang tua biologis (ibu dan ayah).Jenis pohon apa yang bisa digunakan untuk pencarian?<br />
- Ketika pohon cukup seimbang, yaitu daun di kedua ujung memiliki kedalaman yang setara, pohon pencarian memiliki keuntungan dalam hal waktu pencarian. Ada berbagai struktur data pohon pencarian, beberapa di antaranya juga memungkinkan penyisipan dan penghapusan elemen yang efisien, yang tindakannya kemudian harus menjaga keseimbangan pohon.
- Array asosiatif sering diimplementasikan menggunakan pohon pencarian. Algoritme pohon pencarian menempatkan suatu tempat menggunakan kunci dari pasangan nilai kunci, dan kemudian aplikasi menyimpan pasangan kunci-nilai lengkap di lokasi itu.
- Pohon pencarian biner, pohon B, (a,b)-pohon, dan pohon pencarian Ternary adalah contoh pohon pencarian. Apa aplikasi utama dari struktur data pohon?
1. Pohon Pencarian Biner adalah pohon yang memungkinkan Anda mencari, menyisipkan, dan menghapus data yang telah diurutkan dengan cepat. Ini juga membantu Anda menemukan barang yang paling dekat dengan Anda.
2. Heap adalah struktur data pohon yang menggunakan array dan digunakan untuk membangun antrian prioritas.
3. B-Tree dan B+ Tree adalah dua jenis pohon pengindeksan yang digunakan dalam database.
4. Compiler menggunakan pohon sintaks.
5. Pohon partisi ruang yang digunakan untuk mengatur titik-titik dalam ruang dimensi K dikenal sebagai Pohon KD.
6. Trie adalah struktur data yang digunakan untuk membangun kamus yang memiliki prefix lookup.
7. Suffix Tree digunakan untuk mencari pola dalam teks tetap dengan cepat.
8. Dalam jaringan komputer, router dan jembatan menggunakan pohon rentang serta pohon jalur terpendek, masing-masing. Apa itu pohon yang sempurna?