
15 Pertanyaan dan Jawaban Wawancara Hadoop Teratas pada tahun 2022
Diterbitkan: 2021-01-09Dengan analitik data mendapatkan momentum, telah terjadi lonjakan permintaan orang-orang yang baik dalam menangani Big Data. Dari analis data hingga ilmuwan data, Big Data membuat serangkaian profil pekerjaan hari ini. Hal pertama dan terpenting yang harus Anda lakukan adalah Hadoop.
Apa pun peran/profil pekerjaan, Anda mungkin akan mengerjakan Hadoop dengan satu atau lain cara. Jadi, Anda selalu dapat mengharapkan pewawancara untuk menembak beberapa pertanyaan Hadoop dengan cara Anda.
Untuk itu dan lebih banyak lagi, mari kita lihat 15 pertanyaan wawancara Hadoop teratas yang dapat diharapkan dalam wawancara apa pun yang Anda ikuti.
Apa itu Hadoop? Apa saja komponen utama Hadoop?
Hadoop adalah infrastruktur yang dilengkapi dengan alat dan layanan relevan yang diperlukan untuk memproses dan menyimpan Big Data. Tepatnya, Hadoop adalah 'solusi' untuk semua tantangan Big Data. Selain itu, kerangka Hadoop juga membantu organisasi untuk menganalisis Big Data dan membuat keputusan bisnis yang lebih baik.
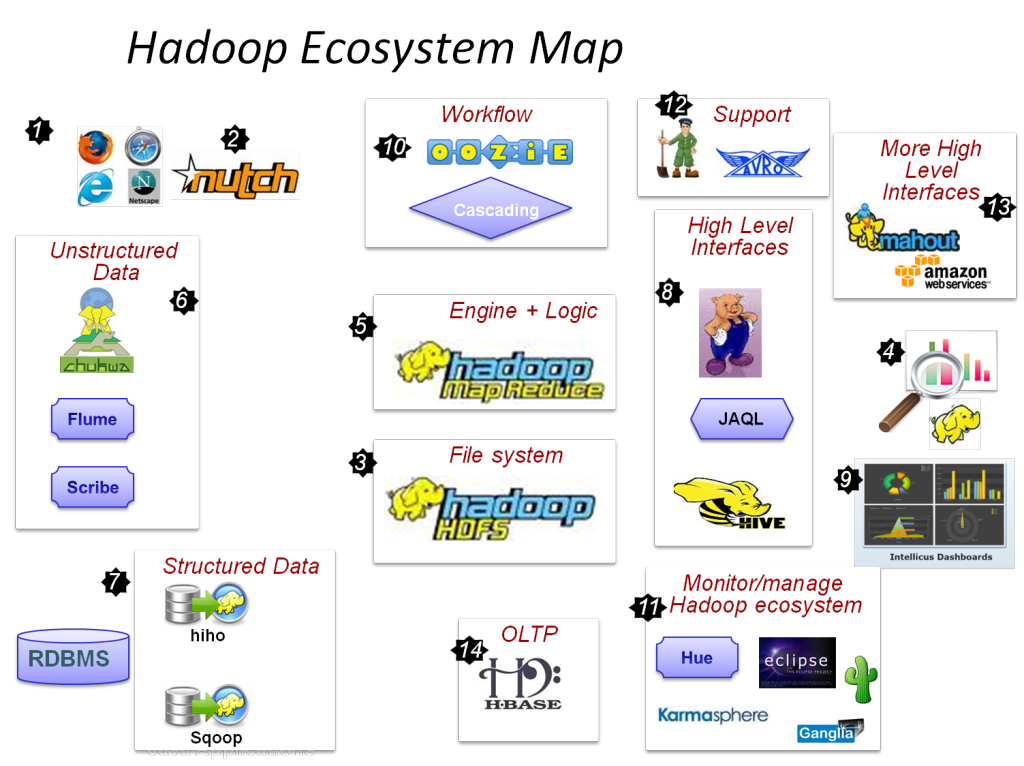
Komponen utama Hadoop adalah:
- HDFS
- Peta Hadoop Kurangi
- Hadoop Umum
- BENANG
- PIG dan HIVE – Komponen Akses Data.
- HBase – Untuk Penyimpanan Data
- Ambari, Oozie dan ZooKeeper – Manajemen Data dan Komponen Pemantauan
- Hemat dan Avro – Komponen Serialisasi Data
- Apache Flume, Sqoop, Chukwa – Komponen Integrasi Data
- Apache Mahout and Drill – Komponen Kecerdasan Data
Apa konsep inti dari kerangka Hadoop?
Hadoop pada dasarnya didasarkan pada dua konsep inti. Mereka:
- HDFS: HDFS atau Hadoop Distributed File System adalah sistem file andal berbasis Java yang digunakan untuk menyimpan kumpulan data besar dalam format blok. Arsitektur Master-Slave mendukungnya.
- MapReduce: MapReduce adalah struktur pemrograman yang membantu memproses kumpulan data besar. Fungsi ini selanjutnya dipecah menjadi dua bagian – sementara 'peta' memisahkan kumpulan data menjadi tupel, 'mengurangi' menggunakan tupel peta dan membuat kombinasi potongan tupel yang lebih kecil.
Sebutkan format input yang paling umum di Hadoop?
Ada tiga format input umum di Hadoop:
- Format Input Teks: Ini adalah format input default di Hadoop.
- Format Input File Urutan: Format input ini digunakan untuk membaca file secara berurutan.
- Format Input Nilai Kunci: Yang ini digunakan untuk membaca file teks biasa.
Apa itu BENANG?
YARN adalah singkatan dari Yet Another Resource Negotiator. Ini adalah kerangka pemrosesan data Hadoop yang mengelola sumber daya data dan menciptakan lingkungan untuk pemrosesan yang sukses. 
Apa itu "Kesadaran Rak"?
“Rack Awareness” adalah algoritme yang digunakan NameNode untuk menentukan pola di mana blok data dan replikanya disimpan dalam cluster Hadoop. Hal ini dicapai dengan bantuan definisi rak yang mengurangi kemacetan antara node data yang terkandung dalam rak yang sama.

Apa itu NameNodes Aktif dan Pasif?
Sistem Hadoop dengan ketersediaan tinggi biasanya berisi dua NameNodes – Active NameNode dan Passive NameNode.
NameNode yang menjalankan cluster Hadoop disebut Active NameNode dan NameNode standby yang menyimpan data dari Active NameNode adalah Passive NameNode.
Tujuan memiliki dua NameNode adalah jika Active NameNode crash, Passive NameNode dapat memimpin. Dengan demikian, NameNode selalu berjalan di cluster, dan sistem tidak pernah gagal.
Apa penjadwal berbeda dalam kerangka Hadoop?
Ada tiga penjadwal berbeda dalam kerangka Hadoop:
- COSHH – COSHH membantu menjadwalkan keputusan dengan meninjau cluster dan beban kerja yang dikombinasikan dengan heterogenitas.
- FIFO Scheduler – FIFO mengurutkan pekerjaan dalam antrian berdasarkan waktu kedatangannya, tanpa menggunakan heterogenitas.
- Berbagi Adil – Berbagi Adil membuat kumpulan untuk pengguna individu yang berisi banyak peta dan mengurangi slot pada sumber daya yang dapat mereka gunakan untuk menjalankan pekerjaan tertentu.
Apa itu Eksekusi Spekulatif?
Seringkali dalam kerangka Hadoop, beberapa node mungkin berjalan lebih lambat daripada yang lain. Ini cenderung membatasi seluruh program. Untuk mengatasinya, Hadoop pertama-tama mendeteksi atau 'berspekulasi' saat tugas berjalan lebih lambat dari biasanya, lalu meluncurkan cadangan yang setara untuk tugas itu. Jadi, dalam prosesnya, node master menjalankan kedua tugas secara bersamaan dan mana yang selesai lebih dulu diterima sementara yang lain dimatikan. Fitur cadangan Hadoop ini dikenal sebagai Eksekusi Spekulatif.

Sebutkan komponen utama Apache HBase?
Apache HBase terdiri dari tiga komponen:
- Server Wilayah: Setelah tabel dibagi menjadi beberapa wilayah, cluster wilayah ini diteruskan ke klien melalui Server Wilayah.
- HMaster: Ini adalah alat yang membantu mengelola dan mengoordinasikan server Wilayah.
- ZooKeeper: ZooKeeper adalah koordinator dalam lingkungan terdistribusi HBase. Ini membantu mempertahankan status server di dalam cluster melalui komunikasi dalam sesi.
Apa itu "Poin Pemeriksaan"? Apa manfaatnya?
Checkpointing mengacu pada prosedur di mana FsImage dan Edit log digabungkan untuk membentuk FsImage baru. Jadi, alih-alih memutar ulang log edit, NameNode dapat langsung memuat status terakhir dalam memori dari FsImage. NameNode sekunder bertanggung jawab untuk proses ini.
Manfaat yang ditawarkan Checkpointing adalah meminimalkan waktu startup NameNode, sehingga membuat seluruh proses lebih efisien.
Aplikasi Big Data dalam Budaya Pop
Bagaimana cara men-debug kode Hadoop?
Untuk men-debug kode Hadoop, pertama, Anda perlu memeriksa daftar tugas MapReduce yang sedang berjalan. Maka Anda perlu memeriksa apakah ada tugas yatim piatu yang berjalan secara bersamaan. Jika demikian, Anda perlu menemukan lokasi log Resource Manager dengan mengikuti langkah-langkah sederhana ini:
Jalankan “ps –ef | grep –I ResourceManager” dan pada hasil yang ditampilkan, coba cari apakah ada kesalahan yang terkait dengan id pekerjaan tertentu.
Sekarang, identifikasi node pekerja yang digunakan untuk menjalankan tugas. Masuk ke node dan jalankan “ps –ef | grep –iNodeManager.”
Terakhir, periksa log Node Manager. Sebagian besar kesalahan dihasilkan dari log tingkat pengguna untuk setiap pekerjaan pengurangan peta.
Apa tujuan dari RecordReader di Hadoop?
Hadoop memecah data ke dalam format blok. RecordReader membantu mengintegrasikan blok data ini ke dalam satu catatan yang dapat dibaca. Misalnya, jika data input dibagi menjadi dua blok –
Baris 1 – Selamat datang di
Baris 2 – UpGrad
RecordReader akan membaca ini sebagai "Selamat datang di UpG rad."
Apa saja mode yang dapat dijalankan Hadoop?
Mode di mana Hadoop dapat berjalan adalah:
- Mode mandiri – Ini adalah mode default Hadoop yang digunakan untuk tujuan debugging. Itu tidak mendukung HDFS.
- Mode terdistribusi semu – Mode ini memerlukan konfigurasi file mapred-site.xml, core-site.xml, dan hdfs-site.xml. Baik Master dan Slave Node sama di sini.
- Mode terdistribusi penuh – Mode terdistribusi penuh adalah tahap produksi Hadoop di mana data didistribusikan ke berbagai node pada cluster Hadoop. Di sini, Node Master dan Slave dialokasikan secara terpisah.
Sebutkan beberapa aplikasi praktis Hadoop.
Berikut adalah beberapa contoh kehidupan nyata di mana Hadoop membuat perbedaan:
- Mengatur lalu lintas jalan
- Deteksi dan pencegahan penipuan
- Analisis data pelanggan secara real-time untuk meningkatkan layanan pelanggan
- Mengakses data medis tidak terstruktur dari dokter, HCP, dll., untuk meningkatkan layanan kesehatan.
Apa saja alat Hadoop vital yang dapat meningkatkan kinerja Big Data?
Alat Hadoop yang meningkatkan kinerja Big Data secara signifikan adalah

• Sarang
• HDFS
• HBase
• SQL
• Tanpa SQL
• Oozie
• Awan
• Avro
• Flume
• Penjaga kebun binatang
Insinyur Data Besar: Mitos vs. Realitas
Kesimpulan
Pertanyaan wawancara Hadoop ini akan sangat membantu Anda dalam wawancara berikutnya. Meskipun terkadang pewawancara cenderung memutarbalikkan beberapa pertanyaan wawancara Hadoop, itu seharusnya tidak menjadi masalah bagi Anda jika dasar-dasar Anda telah diurutkan.
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.