
Prediksi Pasar Saham Menggunakan Machine Learning [Implementasi Langkah-demi-Langkah]
Diterbitkan: 2021-02-26Daftar isi
pengantar
Prediksi dan analisis pasar saham adalah beberapa tugas yang paling rumit untuk dilakukan. Ada beberapa alasan untuk ini, seperti volatilitas pasar dan begitu banyak faktor independen dan dependen lainnya untuk menentukan nilai saham tertentu di pasar. Faktor-faktor ini membuat sangat sulit bagi analis pasar saham mana pun untuk memprediksi kenaikan dan penurunan dengan tingkat akurasi yang tinggi.
Namun, dengan munculnya Pembelajaran Mesin dan algoritme yang kuat, analisis pasar terbaru dan perkembangan Prediksi Pasar Saham telah mulai menggabungkan teknik tersebut dalam memahami data pasar saham.
Singkatnya, Algoritma Pembelajaran Mesin digunakan secara luas oleh banyak organisasi dalam menganalisis dan memprediksi nilai saham. Artikel ini akan membahas Implementasi sederhana dari menganalisis dan memprediksi nilai saham Toko Ritel Online Populer di Seluruh Dunia menggunakan beberapa Algoritma Pembelajaran Mesin dengan Python.
Pernyataan masalah
Sebelum kita masuk ke implementasi program untuk memprediksi nilai pasar saham, mari kita visualisasikan data yang akan kita kerjakan. Di sini, kami akan menganalisis nilai saham Microsoft Corporation (MSFT) dari National Association of Securities Dealers Automated Quotations (NASDAQ). Data nilai saham akan disajikan dalam bentuk File Terpisah Koma (.csv), yang dapat dibuka dan dilihat menggunakan Excel atau Spreadsheet.
MSFT memiliki sahamnya yang terdaftar di NASDAQ dan nilainya diperbarui setiap hari kerja di pasar saham. Perhatikan bahwa pasar tidak mengizinkan perdagangan terjadi pada hari Sabtu dan Minggu; maka ada jarak antara dua tanggal. Untuk setiap tanggal, Nilai Pembukaan saham, nilai Tertinggi dan Terendah dari saham tersebut pada hari yang sama dicatat, bersama dengan Nilai Penutupan pada akhir hari.
Nilai Penutupan yang Disesuaikan menunjukkan nilai saham setelah dividen diposting (Terlalu teknis!). Selain itu, total volume saham di pasar juga diberikan. Dengan data ini, tugas seorang Machine Learning/Data Scientist adalah mempelajari data dan menerapkan beberapa algoritme yang dapat mengekstrak pola dari riwayat saham Microsoft Corporation. data.

Memori Jangka Pendek Panjang
Untuk mengembangkan model Machine Learning untuk memprediksi harga saham Microsoft Corporation, kami akan menggunakan teknik Long Short-Term Memory (LSTM). Mereka digunakan untuk membuat modifikasi kecil pada informasi dengan perkalian dan penambahan. Menurut definisi, memori jangka panjang (LSTM) adalah arsitektur jaringan saraf berulang buatan (RNN) yang digunakan dalam pembelajaran mendalam.
Tidak seperti jaringan saraf umpan maju standar, LSTM memiliki koneksi umpan balik. Itu dapat memproses titik data tunggal (seperti gambar) dan seluruh urutan data (seperti ucapan atau video). Untuk memahami konsep di balik LSTM, mari kita ambil contoh sederhana dari ulasan pelanggan online tentang Ponsel.
Misalkan kita ingin membeli Ponsel, kita biasanya mengacu pada review bersih oleh pengguna bersertifikat. Bergantung pada pemikiran dan masukan mereka, kami memutuskan apakah ponsel itu baik atau buruk dan kemudian membelinya. Saat kami terus membaca ulasan, kami mencari kata kunci seperti "luar biasa", "kamera bagus", "cadangan baterai terbaik", dan banyak istilah lain yang terkait dengan ponsel.
Kita cenderung mengabaikan kata-kata umum dalam bahasa Inggris seperti “it”, “give”, “this”, dll. Jadi, ketika kita memutuskan untuk membeli ponsel atau tidak, kita hanya mengingat kata kunci yang didefinisikan di atas. Kemungkinan besar, kita lupa kata-kata lainnya.
Ini adalah cara yang sama di mana Algoritma Memori Jangka Pendek Panjang bekerja. Itu hanya mengingat informasi yang relevan dan menggunakannya untuk membuat prediksi dengan mengabaikan data yang tidak relevan. Dengan cara ini, kita harus membangun model LSTM yang pada dasarnya hanya mengenali data penting tentang stok itu dan meninggalkan outlier-nya.
Sumber
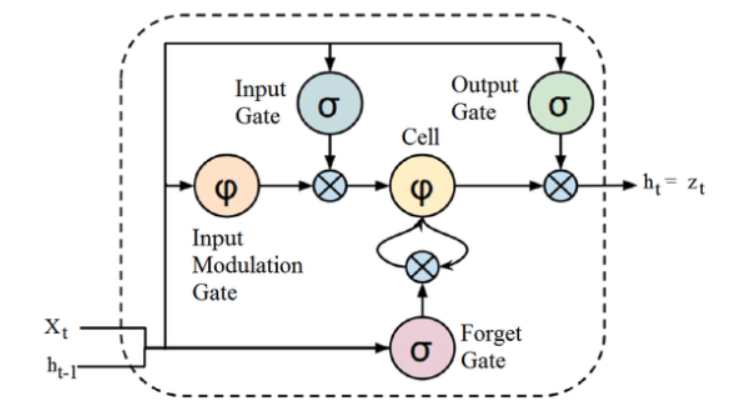
Meskipun struktur arsitektur LSTM yang diberikan di atas mungkin tampak menarik pada awalnya, cukup untuk diingat bahwa LSTM adalah versi lanjutan dari Recurrent Neural Networks yang mempertahankan Memori untuk memproses urutan data. Itu dapat menghapus atau menambahkan informasi ke keadaan sel, diatur dengan hati-hati oleh struktur yang disebut gerbang.
Unit LSTM terdiri dari sel, gerbang input, gerbang keluaran, dan gerbang lupa. Sel mengingat nilai selama interval waktu yang berubah-ubah, dan tiga gerbang mengatur aliran informasi masuk dan keluar sel.
Implementasi Program
Kami akan beralih ke bagian di mana kami menggunakan LSTM dalam memprediksi nilai stok menggunakan Machine Learning dengan Python.
Langkah 1 – Mengimpor Perpustakaan
Seperti yang kita semua tahu, langkah pertama adalah mengimpor perpustakaan yang diperlukan untuk memproses data stok Microsoft Corporation dan perpustakaan lain yang diperlukan untuk membangun dan memvisualisasikan output dari model LSTM. Untuk ini, kita akan menggunakan perpustakaan Keras di bawah kerangka kerja TensorFlow. Modul yang diperlukan diimpor dari perpustakaan Keras satu per satu.
#Mengimpor Perpustakaan
impor panda sebagai PD
impor NumPy sebagai np
%matplotlib sebaris
impor matplotlib. pyplot sebagai plt
impor matplotlib
dari sklearn. Pra-pemrosesan impor MinMaxScaler
dari Keras. lapisan impor LSTM, Padat, Dropout
dari sklearn.model_selection impor TimeSeriesSplit
dari sklearn.metrics impor mean_squared_error, r2_score
impor matplotlib. tanggal sebagai mandat
dari sklearn. Pra-pemrosesan impor MinMaxScaler
dari sklearn impor linear_model
dari Keras. Model impor Sequential
dari Keras. Lapisan impor Padat
impor Keras. Backend sebagai K
dari Keras. Panggilan balik mengimpor EarlyStopping
dari Keras. Pengoptimal mengimpor Adam
dari Keras. Model mengimpor load_model
dari Keras. Lapisan mengimpor LSTM
dari Keras. utils.vis_utils mengimpor plot_model
Langkah 2 – Mendapatkan Visualisasi Data
Dengan menggunakan pustaka pembaca Data Pandas, kita akan mengunggah data stok sistem lokal sebagai file Nilai Terpisah Koma (.csv) dan menyimpannya ke DataFrame pandas. Terakhir, kita juga akan melihat datanya.
#Dapatkan Kumpulan Datanya
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Date',parse_dates=Benar,infer_datetime_format=Benar)
df.head()
Dapatkan sertifikasi AI secara online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
Langkah 3 – Cetak DataFrame Shape dan Periksa Nilai Null.
Dalam langkah penting lainnya ini, pertama-tama kita mencetak bentuk dataset. Untuk memastikan bahwa tidak ada nilai nol dalam bingkai data, kami memeriksanya. Kehadiran nilai nol dalam dataset cenderung menyebabkan masalah selama pelatihan karena mereka bertindak sebagai outlier yang menyebabkan varians yang luas dalam proses pelatihan.
#Cetak bentuk Dataframe dan Periksa Nilai Null
print("Bentuk Dataframe: ", bentuk df.)
print(“Nilai Null Hadir: “, df.IsNull().values.any())
>> Bentuk Dataframe: (7334, 6)
>>Nilai Null Present: False
| Tanggal | Membuka | Tinggi | Rendah | Menutup | Aj Tutup | Volume |
| 1990-01-02 | 0,605903 | 0,616319 | 0,5989090 | 0,616319 | 0,447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0,619792 | 0,449788 | 113772800 |
| 1990-01-04 | 0,619792 | 0,638889 | 0,616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0,635417 | 0,638889 | 0.621528 | 0.622396 | 0,451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0,458607 | 58982400 |
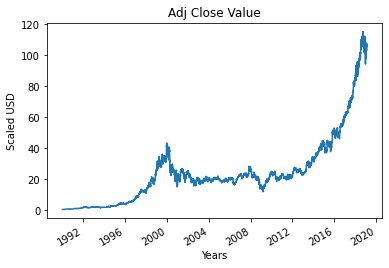
Langkah 4 – Merencanakan Nilai Penutupan yang Disesuaikan dengan Benar
Nilai keluaran akhir yang akan diprediksi menggunakan model Machine Learning adalah Adjusted Close Value. Nilai ini merupakan nilai penutupan saham pada hari tertentu perdagangan pasar saham.
#Plot Nilai Tutup Adj yang Benar
df['Sesuaikan Tutup'].plot()
Langkah 5 – Mengatur Variabel Target dan Memilih Fitur
Pada langkah selanjutnya, kami menetapkan kolom output ke variabel target. Dalam hal ini, ini adalah nilai relatif yang disesuaikan dari Microsoft Stock. Selain itu, kami juga memilih fitur yang bertindak sebagai variabel independen terhadap variabel target (variabel dependen). Untuk menjelaskan tujuan pelatihan, kami memilih empat karakteristik, yaitu:

- Membuka
- Tinggi
- Rendah
- Volume
#Tetapkan Variabel Target
output_var = PD.DataFrame(df['Adj Tutup'])
#Memilih Fitur
fitur = ['Buka', 'Tinggi', 'Rendah', 'Volume']
Langkah 6 – Penskalaan
Untuk mengurangi biaya komputasi data dalam tabel, kami akan menurunkan nilai stok ke nilai antara 0 dan 1. Dengan cara ini, semua data dalam jumlah besar berkurang, sehingga mengurangi penggunaan memori. Selain itu, kita bisa mendapatkan lebih banyak akurasi dengan memperkecil karena data tidak tersebar dalam nilai yang luar biasa. Ini dilakukan oleh kelas MinMaxScaler dari perpustakaan sci-kit-learn.
#Penskalaan
scaler = MinMaxScaler()
fitur_transform = scaler.fit_transform(df[fitur])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
fitur_transform.head()
| Tanggal | Membuka | Tinggi | Rendah | Volume |
| 1990-01-02 | 0,000129 | 0,000105 | 0,000129 | 0,064837 |
| 1990-01-03 | 0,000265 | 0,000195 | 0,000273 | 0.144673 |
| 1990-01-04 | 0,000249 | 0,000300 | 0,000288 | 0.160404 |
| 1990-01-05 | 0,000386 | 0,000300 | 0,000334 | 0,086566 |
| 1990-01-08 | 0,000265 | 0,000240 | 0,000273 | 0,072656 |
Seperti disebutkan di atas, kita melihat bahwa nilai variabel fitur diperkecil ke nilai yang lebih kecil dibandingkan dengan nilai sebenarnya yang diberikan di atas.
Langkah 7 – Memisahkan ke Training Set dan Test Set.
Sebelum memasukkan data ke dalam model pelatihan, kita perlu membagi seluruh dataset menjadi set pelatihan dan pengujian. Model LSTM Machine Learning akan dilatih pada data yang ada di set pelatihan dan diuji pada set pengujian untuk akurasi dan propagasi balik.
Untuk ini, kita akan menggunakan kelas TimeSeriesSplit dari perpustakaan sci-kit-learn. Kami menetapkan jumlah pemisahan sebagai 10, yang menunjukkan bahwa 10% data akan digunakan sebagai set pengujian, dan 90% data akan digunakan untuk melatih model LSTM. Keuntungan menggunakan pemisahan Deret Waktu ini adalah bahwa sampel data deret waktu pemisahan diamati pada interval waktu yang tetap.
#Pemisahan ke set Pelatihan dan set Tes
timesplit= TimeSeriesSplit(n_splits=10)
untuk train_index, test_index di timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Langkah 8 – Memproses Data Untuk LSTM
Setelah set pelatihan dan pengujian siap, kami dapat memasukkan data ke dalam model LSTM setelah dibuat. Sebelum itu, kita perlu mengubah data training dan test set menjadi tipe data yang akan diterima oleh model LSTM. Kami pertama-tama mengonversi data pelatihan dan data uji ke array NumPy dan kemudian membentuknya kembali ke format (Jumlah Sampel, 1, Jumlah Fitur) karena LSTM mengharuskan data dimasukkan dalam bentuk 3D. Seperti yang kita ketahui jumlah sampel pada training set adalah 90% dari 7334 yaitu 6667, dan jumlah fitur adalah 4, training set tersebut dibentuk kembali menjadi (6667, 1, 4). Demikian pula, set tes juga dibentuk ulang.
#Proses data untuk LSTM
trainX =np.array(X_train)
testX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
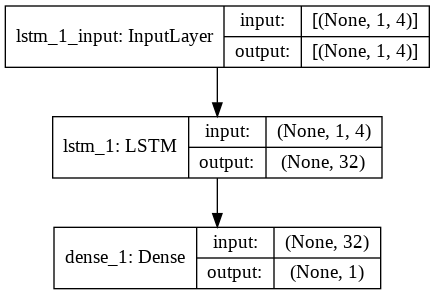
Langkah 9 – Membangun Model LSTM
Akhirnya, kita sampai pada tahap di mana kita membangun Model LSTM. Di sini, kami membuat model Sequential Keras dengan satu lapisan LSTM. Lapisan LSTM memiliki 32 unit, dan diikuti oleh satu Lapisan Padat dari 1 neuron.
Kami menggunakan Adam Optimizer dan Mean Squared Error sebagai fungsi kerugian untuk mengkompilasi model. Keduanya adalah kombinasi yang paling disukai untuk model LSTM. Selain itu, model juga diplot dan ditampilkan di bawah.
#Membangun Model LSTM
lstm = Urutan()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activation='relu', return_sequences=False))
lstm.add(Padat(1))
lstm.compile(loss='mean_squared_error', pengoptimal='adam')
plot_model(lstm, show_shapes=Benar, show_layer_names=Benar)
Langkah 10 – Melatih Model
Terakhir, kami melatih model LSTM yang dirancang di atas pada data pelatihan untuk 100 epoch dengan ukuran batch 8 menggunakan fungsi fit.
#Pelatihan Model
history = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
Zaman 1/100
834/834 [==============================] – 3s 2ms/langkah – kalah: 67.1211
Zaman 2/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 70,4911
Zaman 3/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 48.8155
Zaman 4/100
834/834 [==============================] – 1s 2ms/langkah – kalah: 21.5447
Zaman 5/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 6.1709
Zaman 6/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 1.8726
Zaman 7/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 0,9380
Zaman 8/100
834/834 [==============================] – 2s 2ms/langkah – rugi: 0.6566
Zaman 9/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 0,5369
Zaman 10/100
834/834 [==============================] – 2s 2ms/langkah – rugi: 0,4761
.
.
.
.
Zaman 95/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 0,4542
Zaman 96/100
834/834 [==============================] – 2s 2ms/langkah – rugi: 0,4553
Zaman 97/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 0,4565
Zaman 98/100
834/834 [==============================] – 1s 2ms/langkah – kerugian: 0.4576
Zaman 99/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 0.4588
Zaman 100/100
834/834 [==============================] – 1s 2ms/langkah – rugi: 0.4599
Akhirnya, kami melihat bahwa nilai kerugian telah menurun secara eksponensial dari waktu ke waktu selama proses pelatihan 100 epoch dan telah mencapai nilai 0,4599
Langkah 11 – Prediksi LSTM
Dengan model kami siap, sekarang saatnya untuk menggunakan model yang dilatih menggunakan jaringan LSTM pada set pengujian dan memprediksi Nilai Tutup Berdekatan dari saham Microsoft. Hal ini dilakukan dengan menggunakan fungsi prediksi sederhana pada model lstm yang dibangun.
#Prediksi LSTM
y_pred= lstm.predict(X_test)
Langkah 12 – True vs Predicted Adj Close Value – LSTM
Terakhir, karena kami telah memperkirakan nilai set pengujian, kami dapat memplot grafik untuk membandingkan nilai sebenarnya dari Adj Close dan nilai prediksi Adj Close dengan model Machine Learning LSTM.
#True vs Predicted Adj Close Value – LSTM
plt.plot(y_test, label='Nilai Sebenarnya')
plt.plot(y_pred, label='LSTM Nilai')
plt.title("Prediksi oleh LSTM")
plt.xlabel('Skala Waktu')
plt.ylabel('Berskala USD')
plt.legenda()
plt.tampilkan()
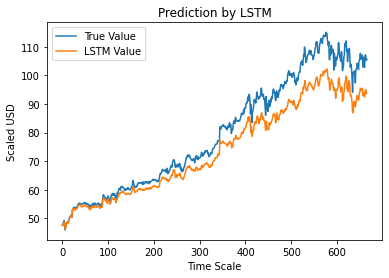
Grafik di atas menunjukkan bahwa beberapa pola terdeteksi oleh model jaringan LSTM tunggal yang sangat dasar yang dibangun di atas. Dengan menyempurnakan beberapa parameter dan menambahkan lebih banyak lapisan LSTM ke model, kami dapat mencapai representasi yang lebih akurat dari nilai saham perusahaan mana pun.
Kesimpulan
Jika Anda tertarik untuk mempelajari lebih lanjut tentang contoh kecerdasan buatan, pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & penugasan, status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Bisakah Anda memprediksi pasar saham menggunakan pembelajaran mesin?
Hari ini, kami memiliki sejumlah indikator untuk membantu memprediksi tren pasar. Namun, kita harus melihat tidak lebih dari komputer bertenaga tinggi untuk menemukan indikator yang paling akurat untuk pasar saham. Pasar saham adalah sistem terbuka, dan dapat dilihat sebagai jaringan yang kompleks. Jaringan terdiri dari hubungan antara saham, perusahaan, investor dan volume perdagangan. Dengan menggunakan algoritme penambangan data seperti mesin vektor pendukung, Anda dapat menerapkan rumus matematika untuk mengekstrak hubungan di antara variabel-variabel ini. Pasar saham sekarang di luar prediksi manusia.
Algoritma mana yang terbaik untuk prediksi pasar saham?
Untuk hasil terbaik, Anda harus menggunakan Regresi Linier. Regresi Linier adalah pendekatan statistik yang digunakan untuk mengetahui hubungan antara dua variabel yang berbeda. Dalam contoh ini, variabelnya adalah harga dan waktu. Dalam prediksi pasar saham, harga adalah variabel independen, dan waktu adalah variabel dependen. Jika hubungan linier antara dua variabel ini dapat ditentukan, maka dimungkinkan untuk memprediksi secara akurat nilai saham pada titik mana pun di masa depan.
Apakah prediksi pasar saham merupakan masalah klasifikasi atau regresi?
Sebelum menjawab, kita perlu memahami apa yang dimaksud dengan prediksi pasar saham. Apakah ini masalah klasifikasi biner atau masalah regresi? Misalkan kita ingin memprediksi masa depan suatu saham, di mana masa depan berarti hari, minggu, bulan, atau tahun berikutnya. Jika kinerja saham di masa lalu pada beberapa titik waktu adalah input dan masa depan adalah output, maka itu adalah masalah regresi. Jika kinerja saham di masa lalu dan masa depan saham independen, maka itu adalah masalah klasifikasi.