
Alat Data Kuantitatif Untuk Desainer UX
Diterbitkan: 2022-03-10Banyak desainer UX agak takut pada data, percaya bahwa itu membutuhkan pengetahuan statistik dan matematika yang mendalam. Meskipun itu mungkin benar untuk ilmu data tingkat lanjut, itu tidak benar untuk analisis data penelitian dasar yang dibutuhkan oleh sebagian besar desainer UX. Karena kita hidup di dunia yang semakin didorong oleh data, literasi data dasar berguna untuk hampir semua profesional — bukan hanya desainer UX.
Aaron Gitlin, desainer interaksi di Google, berpendapat bahwa banyak desainer belum didorong oleh data:
“Sementara banyak bisnis mempromosikan diri mereka sebagai berbasis data, sebagian besar desainer didorong oleh naluri, kolaborasi, dan metode penelitian kualitatif.”
— Aaron Gitlin, “Menjadi Desainer yang Sadar Data”
Dengan artikel ini, saya ingin memberi desainer UX pengetahuan dan alat untuk memasukkan data ke dalam rutinitas harian mereka.
Tapi Pertama, Beberapa Konsep Data
Pada artikel ini saya akan berbicara tentang data terstruktur, artinya data yang dapat direpresentasikan dalam sebuah tabel, dengan baris dan kolom. Data tidak terstruktur, menjadi subjek tersendiri, lebih sulit untuk dianalisis, seperti yang ditunjukkan oleh Devin Pickell (spesialis pemasaran konten di G2 Crowd, menulis tentang data dan analitik) dalam artikelnya “Data Terstruktur vs Tidak Terstruktur – Apa Perbedaannya?.” Jika data terstruktur dapat direpresentasikan dalam bentuk tabel, konsep utamanya adalah:
Himpunan data
Seluruh rangkaian data yang ingin kami analisis. Ini bisa berupa, misalnya, tabel Excel. Format populer lainnya untuk menyimpan kumpulan data adalah file nilai yang dipisahkan koma (CSV). File CSV adalah file teks sederhana yang digunakan untuk menyimpan informasi seperti tabel. Setiap baris CSV sesuai dengan baris dalam tabel, dan setiap baris CSV memiliki nilai yang dipisahkan (secara alami) dengan koma, yang sesuai dengan sel tabel.
Titik Data
Satu baris dari tabel kumpulan data adalah titik data. Dengan cara itu, dataset adalah kumpulan titik data.
Variabel Data
Nilai tunggal dari baris titik data mewakili variabel data — sederhananya, sel tabel. Kita dapat memiliki dua jenis variabel data: variabel kualitatif, dan variabel kuantitatif. Variabel kualitatif (juga dikenal sebagai variabel kategoris) memiliki kumpulan nilai diskrit, seperti color = red/green/blue . Variabel kuantitatif memiliki nilai numerik, seperti height = 167 . Variabel kuantitatif, tidak seperti variabel kualitatif, dapat mengambil nilai apa pun.
Membuat Proyek Data Kami
Sekarang kita mengetahui dasar-dasarnya, saatnya untuk mengotori tangan kita dan membuat proyek data pertama kita. Ruang lingkup proyek ini adalah untuk menganalisis kumpulan data dengan menelusuri seluruh aliran data dalam mengimpor, memproses, dan merencanakan data. Pertama, kami akan memilih dataset kami, kemudian kami akan mengunduh dan menginstal alat untuk menganalisis data.
Kumpulan Data Mobil
Untuk tujuan artikel ini, saya telah memilih kumpulan data mobil, karena sederhana dan intuitif. Analisis data hanya akan mengkonfirmasi apa yang sudah kita ketahui tentang mobil — yang baik-baik saja, karena fokus kita adalah pada aliran data dan alat.
Kami dapat mengunduh kumpulan data mobil bekas dari Kaggle, salah satu sumber kumpulan data gratis terbesar. Anda harus mendaftar terlebih dahulu.
Setelah mengunduh file, buka dan lihat. Ini adalah file CSV yang sangat besar, tetapi Anda harus mendapatkan intinya. Baris dalam file ini akan terlihat seperti ini:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Seperti yang Anda lihat, titik data ini memiliki beberapa variabel yang dipisahkan dengan koma. Karena kita sekarang memiliki dataset, mari kita bicara sedikit tentang alat.
Alat Perdagangan
Kami akan menggunakan bahasa R dan RStudio untuk menganalisis dataset. R adalah bahasa yang sangat populer dan mudah dipelajari, digunakan tidak hanya oleh ilmuwan data, tetapi juga orang-orang di pasar keuangan, kedokteran, dan banyak bidang lainnya. RStudio adalah lingkungan di mana proyek R dikembangkan, dan ada versi gratisnya, yang lebih dari cukup untuk kebutuhan kita sebagai desainer UX.
Sepertinya beberapa desainer UX menggunakan Excel untuk alur kerja data mereka. Jika itu berarti Anda, coba R — kemungkinan besar Anda akan menyukainya, karena mudah dipelajari, dan lebih fleksibel dan kuat daripada Excel. Menambahkan R ke tool kit Anda akan membuat perbedaan.
Memasang Alat
Pertama, kita perlu mengunduh dan menginstal R dan RStudio. Anda harus menginstal R terlebih dahulu, lalu RStudio. Proses instalasi untuk R dan RStudio sederhana dan mudah.
Pengaturan Proyek
Setelah penginstalan selesai, buat folder proyek — saya menyebutnya used-cars-prj . Di folder itu, buat subfolder bernama data , lalu salin file dataset (diunduh dari Kaggle) ke folder itu dan ganti namanya menjadi used-cars.csv . Sekarang kembali ke folder proyek kita ( used-cars-prj ) dan buat file teks biasa bernama used-cars.r . Anda harus berakhir dengan struktur yang sama seperti pada gambar di bawah.
Sekarang kita memiliki struktur folder, kita dapat membuka RStudio dan membuat proyek R baru. Pilih New Project… dari menu File dan pilih opsi kedua, Existing Directory . Kemudian pilih direktori proyek ( used-cars-prj ). Terakhir, tekan tombol Buat Proyek dan selesai. Setelah proyek dibuat, buka mobil bekas.r di RStudio — ini adalah file tempat kita akan menambahkan semua kode R kita.
Mengimpor Data
Kami akan menambahkan baris pertama kami di mobil bekas.r , untuk membaca data dari file mobil bekas.csv . Ingat bahwa file CSV hanyalah file teks biasa yang digunakan untuk menyimpan data. Baris pertama kode R kita akan terlihat seperti ini:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Ini mungkin terlihat sedikit mengintimidasi, tetapi sebenarnya tidak — omong-omong, ini adalah baris paling rumit di seluruh artikel. Apa yang kita miliki di sini adalah fungsi read.csv , yang mengambil tiga parameter.
Parameter pertama adalah file yang akan dibaca, dalam kasus kami used-cars.csv , yang terletak di folder data . Parameter kedua, stringsAsFactors=FALSE diatur untuk memastikan string seperti “BMW” atau “Audi” tidak dikonversi ke faktor (jargon R untuk data kategorikal) — seperti yang Anda ingat, variabel kualitatif atau kategorikal hanya dapat memiliki nilai diskrit seperti red/green/blue . Terakhir, parameter ketiga, sep="," menentukan jenis pemisah yang digunakan untuk memisahkan nilai dalam file CSV: koma.
Setelah membaca file CSV, data disimpan ke dalam objek bingkai data cars . Bingkai data adalah struktur data dua dimensi (seperti tabel Excel), yang sangat berguna dalam R untuk memanipulasi data. Setelah memperkenalkan garis dan menjalankannya, bingkai data cars akan dibuat untuk Anda. Jika Anda melihat di kuadran kanan atas di RStudio, Anda akan melihat bingkai data cars , di bagian Data di bawah tab Lingkungan . Jika Anda mengklik dua kali pada mobil , tab baru akan terbuka di kuadran kiri atas RStudio, dan akan menampilkan bingkai data cars . Seperti yang Anda duga, ini terlihat seperti tabel Excel.
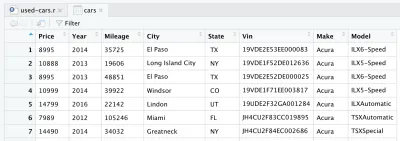
Ini sebenarnya adalah data mentah yang kami unduh dari Kaggle. Tetapi karena kita ingin melakukan analisis data, kita perlu mengolah dataset kita terlebih dahulu.
Pengolahan data
Dengan memproses, yang kami maksud adalah menghapus, mengubah, atau menambahkan informasi ke kumpulan data kami, untuk mempersiapkan jenis analisis yang ingin kami lakukan. Kami memiliki data dalam objek bingkai data, jadi sekarang kami perlu menginstal pustaka dplyr , pustaka yang kuat untuk memanipulasi data. Untuk menginstal perpustakaan di lingkungan R kami, kami perlu menulis baris berikut di bagian atas file R kami.
install.packages("dplyr")Kemudian, untuk menambahkan perpustakaan ke proyek kami saat ini, kami akan menggunakan baris berikutnya:
library(dplyr) Setelah pustaka dplyr ditambahkan ke proyek kami, kami dapat mulai memproses data. Kami memiliki kumpulan data yang sangat besar, dan kami hanya memerlukan data yang mewakili pembuat dan model mobil yang sama, untuk menghubungkannya dengan harga. Kami akan menggunakan kode R berikut untuk menyimpan hanya data tentang BMW Seri 3, dan menghapus sisanya. Tentu saja, Anda dapat memilih pabrikan dan model lain dari kumpulan data, dan berharap memiliki karakteristik data yang sama.
cars <- cars %>% filter(Make == "BMW", Model == "3")Sekarang kami memiliki kumpulan data yang lebih mudah dikelola, meskipun masih berisi lebih dari 11.000 titik data, yang sesuai dengan tujuan kami: untuk menganalisis distribusi harga, usia dan jarak tempuh mobil, dan juga korelasi di antara mereka. Untuk itu, kita hanya perlu menyimpan kolom “Harga”, “Tahun” dan “Jarak tempuh” dan menghapus sisanya — ini dilakukan dengan baris berikut.
cars <- cars %>% select(Price, Year, Mileage)Setelah menghapus kolom lain, bingkai data kita akan terlihat seperti ini:

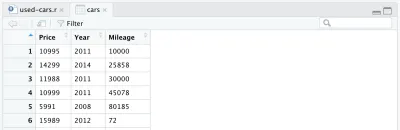
Ada satu lagi perubahan yang ingin kami lakukan pada dataset kami: mengganti tahun pembuatan dengan usia mobil. Kita dapat menambahkan dua baris berikut, yang pertama untuk menghitung usia, yang kedua untuk mengubah nama kolom.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Akhirnya, bingkai data penuh kami yang diproses terlihat seperti ini:
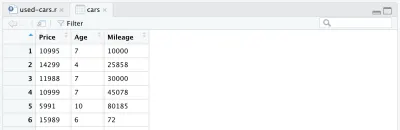
Pada titik ini, kode R kita akan terlihat seperti berikut, dan itu saja untuk pemrosesan data. Sekarang kita dapat melihat betapa mudah dan kuatnya bahasa R. Kami telah memproses dataset awal dengan cukup dramatis hanya dengan beberapa baris kode.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Analisis data
Data kami sekarang dalam bentuk yang benar, jadi kami bisa pergi untuk membuat beberapa plot. Seperti yang telah disebutkan, kami akan fokus pada dua aspek: distribusi variabel individu, dan korelasi di antara mereka. Distribusi variabel membantu kita memahami apa yang dianggap sebagai harga menengah atau tinggi untuk mobil bekas — atau persentase mobil di atas harga tertentu. Hal yang sama berlaku untuk usia dan jarak tempuh mobil. Korelasi, di sisi lain, sangat membantu dalam memahami bagaimana variabel seperti usia dan jarak tempuh terkait satu sama lain.
Karena itu, kami akan menggunakan dua jenis visualisasi data: histogram untuk distribusi variabel, dan plot pencar untuk korelasi.
Distribusi Harga
Memplot histogram harga mobil dalam bahasa R semudah ini:
hist(cars$Price)Tip kecil: jika Anda berada di RStudio, Anda dapat menjalankan kode baris demi baris; misalnya, dalam kasus kami, Anda hanya perlu menjalankan baris di atas untuk menampilkan histogram. Anda tidak perlu menjalankan semua kode lagi karena Anda sudah menjalankannya sekali. Histogramnya akan terlihat seperti ini:
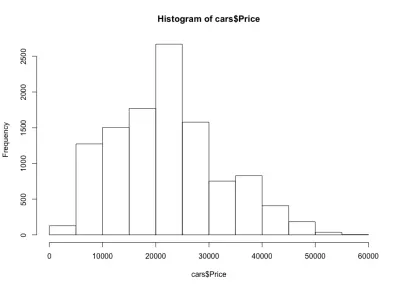
Jika kita melihat histogram, kita melihat distribusi harga mobil seperti lonceng, yang kita harapkan. Sebagian besar mobil jatuh di kisaran tengah, dan kami memiliki semakin sedikit saat kami bergerak ke setiap sisi. Hampir 80% mobil berharga antara $10.000 dan $30.000 USD, dan kami memiliki maksimum lebih dari 2.500 mobil antara $20.000 dan $25.000 USD. Di sisi kiri kami mungkin memiliki sekitar 150 mobil di bawah $5.000 USD, dan di sisi kanan bahkan lebih sedikit. Kita dapat dengan mudah melihat betapa bergunanya plot semacam itu untuk mendapatkan wawasan tentang data.
Distribusi umur
Sama seperti harga mobil, kita akan menggunakan garis yang sama untuk memplot histogram umur mobil.
hist(cars$Age)Dan inilah histogramnya:
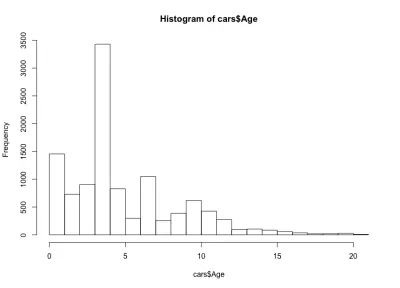
Kali ini histogram terlihat berlawanan dengan intuisi — alih-alih bentuk lonceng sederhana, kami memiliki empat lonceng di sini. Pada dasarnya, distribusi memiliki tiga maksimum lokal dan satu global, yang tidak terduga. Akan menarik untuk melihat apakah distribusi usia mobil yang aneh ini tetap berlaku untuk pembuat dan model mobil lain. Untuk tujuan artikel ini, kami akan tetap menggunakan dataset BMW Seri 3, tetapi Anda dapat menggali lebih dalam data jika Anda penasaran. Mengenai distribusi usia mobil kami, kami melihat bahwa lebih dari 90% mobil berusia kurang dari 10 tahun, dan lebih dari 80% berusia kurang dari 7 tahun. Juga, kami melihat bahwa sebagian besar mobil berusia kurang dari 5 tahun.
Distribusi Mileage
Sekarang, apa yang bisa kita katakan tentang jarak tempuh? Tentu saja, kami berharap memiliki bentuk lonceng yang sama dengan harga yang kami miliki. Berikut adalah kode R dan histogramnya:
hist(cars$Mileage) 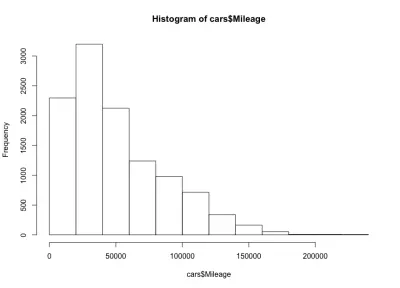
Di sini kita memiliki bentuk lonceng miring ke kiri, artinya ada lebih banyak mobil dengan jarak tempuh lebih sedikit di pasaran. Kami juga memperhatikan bahwa sebagian besar mobil memiliki jarak kurang dari 60.000 mil, dan kami memiliki jarak maksimum sekitar 20.000 hingga 40.000 mil.
Korelasi Usia–Harga
Mengenai korelasi, mari kita lihat lebih dekat korelasi usia-harga mobil. Kita mungkin berharap harga berkorelasi negatif dengan usia — seiring bertambahnya usia mobil, harganya akan turun. Kami akan menggunakan fungsi plot R untuk menampilkan korelasi harga-usia sebagai berikut:
plot(cars$Age, cars$Price)Dan plotnya terlihat seperti ini:
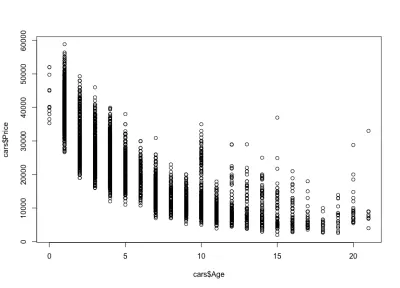
Kami memperhatikan bagaimana harga mobil turun seiring bertambahnya usia: ada mobil baru yang mahal, dan mobil tua yang lebih murah. Kita juga dapat melihat interval variasi harga untuk usia tertentu, variasi yang menurun seiring dengan usia mobil. Variasi ini sebagian besar didorong oleh jarak tempuh, konfigurasi, dan keadaan mobil secara keseluruhan. Misalnya, dalam kasus mobil berusia 4 tahun, harganya bervariasi antara $10.000 dan $40.000 USD.
Korelasi Mileage–Umur
Mempertimbangkan korelasi jarak tempuh-usia, kami berharap jarak tempuh meningkat seiring bertambahnya usia, yang berarti korelasi positif. Berikut kodenya:
plot(cars$Mileage, cars$Age)Dan inilah plotnya:
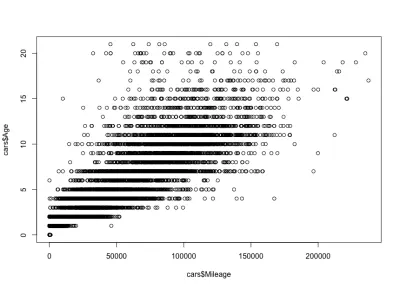
Seperti yang Anda lihat, usia dan jarak tempuh mobil berkorelasi positif, tidak seperti harga dan usia mobil, yang berkorelasi negatif. Kami juga memiliki variasi jarak tempuh yang diharapkan untuk usia tertentu; yaitu, mobil dengan usia yang sama memiliki jarak tempuh yang bervariasi. Misalnya, sebagian besar mobil berusia 4 tahun memiliki jarak tempuh antara 10.000 dan 80.000 mil. Tapi ada juga outlier, dengan jarak tempuh yang lebih besar.
Mileage–Korelasi Harga
Seperti yang diharapkan, akan ada korelasi negatif antara jarak tempuh mobil dan harga, yang berarti bahwa peningkatan jarak tempuh mengurangi harga.
plot(cars$Mileage, cars$Price)Dan inilah plotnya:
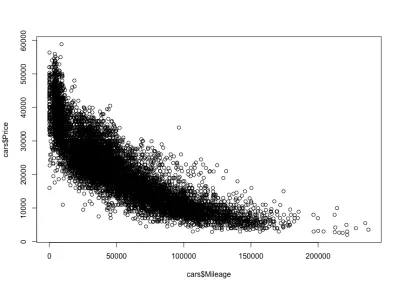
Seperti yang kami harapkan, korelasi negatif. Kami juga dapat melihat interval harga kotor antara $3.000 dan $50.000 USD, dan jarak tempuh antara 0 dan 150.000. Jika kita melihat lebih dekat pada bentuk distribusi, kita melihat bahwa harga turun jauh lebih cepat untuk mobil dengan jarak tempuh lebih sedikit daripada mobil dengan jarak tempuh lebih. Ada mobil dengan jarak tempuh hampir nol, di mana harganya turun drastis. Juga, di atas kisaran 200.000 mil — karena jarak tempuhnya sangat tinggi — harganya tetap konstan.
Dari Angka Hingga Visualisasi Data
Dalam artikel ini, kami menggunakan dua jenis visualisasi: histogram untuk distribusi data, dan plot sebar untuk korelasi data. Histogram adalah representasi visual yang mengambil nilai dari variabel data ( angka sebenarnya) dan menunjukkan bagaimana mereka didistribusikan di seluruh rentang. Kami menggunakan fungsi R hist() untuk memplot histogram.
Plot pencar, di sisi lain, mengambil pasangan angka dan mewakili mereka pada dua sumbu. Plot pencar menggunakan fungsi plot() dan menyediakan dua parameter: variabel data pertama dan kedua dari korelasi yang ingin kita selidiki. Jadi, dua fungsi R, hist() dan plot() membantu kami menerjemahkan kumpulan angka dalam representasi visual yang bermakna.
Kesimpulan
Setelah mengotori seluruh aliran data dalam mengimpor, memproses, dan merencanakan data, segalanya terlihat lebih jelas sekarang. Anda dapat menerapkan aliran data yang sama ke set data baru yang mengkilap yang akan Anda temui. Dalam riset pengguna, misalnya, Anda dapat membuat grafik waktu pada tugas atau distribusi kesalahan, dan Anda juga dapat memplot waktu pada tugas vs. korelasi kesalahan.
Untuk mempelajari lebih lanjut tentang bahasa R, Quick-R adalah tempat yang baik untuk memulai, tetapi Anda juga dapat mempertimbangkan R Blogger. Untuk dokumentasi paket R, seperti dplyr , Anda dapat mengunjungi RDocumentation. Bermain dengan data bisa menyenangkan, tetapi juga sangat membantu desainer UX mana pun di dunia yang digerakkan oleh data. Karena lebih banyak data dikumpulkan dan digunakan untuk menginformasikan keputusan bisnis, ada peningkatan peluang bagi desainer untuk mengerjakan visualisasi data atau produk data, di mana pemahaman tentang sifat data sangat penting.