
Membangun Layanan Pub/Sub In-House Menggunakan Node.js Dan Redis
Diterbitkan: 2022-03-10Dunia saat ini beroperasi secara real time. Baik itu memperdagangkan stok atau memesan makanan, konsumen saat ini mengharapkan hasil langsung. Demikian juga, kita semua berharap untuk segera mengetahui sesuatu — apakah itu berita atau olahraga. Zero, dengan kata lain, adalah pahlawan baru.
Ini berlaku untuk pengembang perangkat lunak juga — bisa dibilang beberapa orang yang paling tidak sabar! Sebelum masuk ke cerita BrowserStack, saya akan lalai untuk tidak memberikan latar belakang tentang Pub/Sub. Bagi Anda yang terbiasa dengan dasar-dasarnya, silakan lewati dua paragraf berikutnya.
Banyak aplikasi saat ini mengandalkan transfer data waktu nyata. Mari kita lihat lebih dekat sebuah contoh: jejaring sosial. Orang-orang seperti Facebook dan Twitter menghasilkan umpan yang relevan , dan Anda (melalui aplikasi mereka) mengkonsumsinya dan memata-matai teman Anda. Mereka mencapai ini dengan fitur perpesanan, di mana jika pengguna menghasilkan data, itu akan diposting untuk dikonsumsi orang lain dalam waktu singkat. Setiap penundaan yang signifikan dan pengguna akan mengeluh, penggunaan akan turun, dan jika terus berlanjut, keluar. Taruhannya tinggi, dan begitu pula harapan pengguna. Jadi, bagaimana layanan seperti WhatsApp, Facebook, TD Ameritrade, Wall Street Journal, dan GrubHub mendukung transfer data real-time dalam jumlah besar?
Semuanya menggunakan arsitektur perangkat lunak serupa pada tingkat tinggi yang disebut model “Publikasikan-Berlangganan”, yang biasa disebut sebagai Pub/Sub.
Dalam arsitektur perangkat lunak, publish-subscribe adalah pola pesan di mana pengirim pesan, yang disebut penerbit, tidak memprogram pesan untuk dikirim langsung ke penerima tertentu, yang disebut pelanggan, tetapi mengkategorikan pesan yang diterbitkan ke dalam kelas tanpa sepengetahuan pelanggan mana, jika apapun, mungkin ada. Demikian pula, pelanggan menyatakan minatnya pada satu atau lebih kelas dan hanya menerima pesan yang menarik, tanpa mengetahui penerbit mana, jika ada,.”
— Wikipedia
Bosan dengan definisinya? Kembali ke cerita kita.
Di BrowserStack, semua produk kami mendukung (dalam satu atau lain cara) perangkat lunak dengan komponen ketergantungan real-time yang substansial — baik itu mengotomatiskan log pengujian, tangkapan layar browser yang baru dipanggang, atau streaming seluler 15fps.
Dalam kasus seperti itu, jika satu pesan jatuh, pelanggan dapat kehilangan informasi penting untuk mencegah bug . Oleh karena itu, kami perlu melakukan penskalaan untuk kebutuhan ukuran data yang bervariasi. Misalnya, dengan layanan pencatat perangkat pada titik waktu tertentu, mungkin ada 50MB data yang dihasilkan dalam satu pesan. Ukuran seperti ini bisa membuat browser crash. Belum lagi bahwa sistem BrowserStack perlu ditingkatkan untuk produk tambahan di masa mendatang.
Karena ukuran data untuk setiap pesan berbeda dari beberapa byte hingga 100 MB, kami membutuhkan solusi skalabel yang dapat mendukung banyak skenario. Dengan kata lain, kami mencari pedang yang bisa memotong semua kue. Pada artikel ini, saya akan membahas mengapa, bagaimana, dan hasil dari membangun layanan Pub/Sub kami secara in-house.
Melalui lensa masalah dunia nyata BrowserStack, Anda akan mendapatkan pemahaman yang lebih dalam tentang persyaratan dan proses membangun Pub/Sub Anda sendiri .
Kebutuhan Kami Akan Layanan Pub/Sub
BrowserStack memiliki sekitar 100 juta+ pesan, yang masing-masing berukuran antara sekitar 2 byte dan 100+ MB. Ini diedarkan ke seluruh dunia setiap saat, semuanya dengan kecepatan Internet yang berbeda.
Generator terbesar dari pesan-pesan ini, berdasarkan ukuran pesan, adalah produk BrowserStack Automate kami. Keduanya memiliki dasbor waktu nyata yang menampilkan semua permintaan dan respons untuk setiap perintah pengujian pengguna. Jadi, jika seseorang menjalankan pengujian dengan 100 permintaan di mana ukuran rata-rata permintaan-tanggapan adalah 10 byte, ini mentransmisikan 1x100x10 = 1000 byte.
Sekarang mari kita pertimbangkan gambaran yang lebih besar sebagai — tentu saja — kami tidak menjalankan hanya satu tes sehari. Lebih dari sekitar 850.000 tes BrowserStack Automate dan App Automate dijalankan dengan BrowserStack setiap hari. Dan ya, kami rata-rata sekitar 235 permintaan-tanggapan per pengujian. Karena pengguna dapat mengambil tangkapan layar atau meminta sumber halaman di Selenium, ukuran rata-rata permintaan-tanggapan kami adalah sekitar 220 byte.
Jadi, kembali ke kalkulator kami:
850.000×235×220 = 43.945.000.000 byte (perkiraan) atau hanya 43.945GB per hari
Sekarang mari kita bicara tentang BrowserStack Live dan App Live. Tentunya kami memiliki Automate sebagai pemenang kami dalam bentuk ukuran data. Namun, produk Live memimpin dalam hal jumlah pesan yang dikirimkan. Untuk setiap tes langsung, sekitar 20 pesan dilewatkan setiap menit. Kami menjalankan sekitar 100.000 tes langsung, yang setiap tes rata-rata sekitar 12 menit yang berarti:
100.000×12×20 = 24.000.000 pesan per hari
Sekarang untuk bagian yang luar biasa dan luar biasa: Kami membangun, menjalankan, dan memelihara aplikasi untuk pendorong yang disebut ini dengan 6 instans t1.micro dari ec2. Biaya menjalankan layanan? Sekitar $70 per bulan .
Memilih Untuk Membangun vs. Membeli
Hal pertama yang utama: Sebagai startup, seperti kebanyakan perusahaan lainnya, kami selalu bersemangat untuk membangun berbagai hal secara internal. Tapi kami masih mengevaluasi beberapa layanan di luar sana. Persyaratan utama yang kami miliki adalah:
- Keandalan dan stabilitas,
- Performa tinggi, dan
- Efektivitas biaya.
Mari kita tinggalkan kriteria efektivitas biaya, karena saya tidak dapat memikirkan layanan eksternal apa pun yang berharga di bawah $70 per bulan (tweet saya jika tahu Anda yang melakukannya!). Jadi jawaban kami di sana sudah jelas.
Dalam hal keandalan dan stabilitas, kami menemukan perusahaan yang menyediakan Pub/Sub sebagai layanan dengan SLA waktu aktif 99,9+ persen, tetapi ada banyak T&C yang menyertainya. Masalahnya tidak sesederhana yang Anda pikirkan, terutama ketika Anda mempertimbangkan lahan luas Internet terbuka yang terletak di antara sistem dan klien. Siapa pun yang akrab dengan infrastruktur Internet tahu bahwa konektivitas yang stabil adalah tantangan terbesar. Selain itu, jumlah data yang dikirim tergantung pada lalu lintas. Misalnya, pipa data yang nol selama satu menit dapat meledak selama menit berikutnya. Layanan yang menyediakan keandalan yang memadai selama momen burst seperti itu jarang terjadi (Google dan Amazon).
Performa untuk proyek kami berarti memperoleh dan mengirim data ke semua node pendengar dengan latensi mendekati nol . Di BrowserStack, kami menggunakan layanan cloud (AWS) bersama dengan co-location hosting. Namun, penerbit dan/atau pelanggan kami dapat ditempatkan di mana saja. Misalnya, mungkin melibatkan server aplikasi AWS yang menghasilkan data log yang sangat dibutuhkan, atau terminal (mesin tempat pengguna dapat terhubung dengan aman untuk pengujian). Kembali ke masalah Internet terbuka lagi, jika kami ingin mengurangi risiko kami, kami harus memastikan Pub/Sub kami memanfaatkan layanan host terbaik dan AWS.
Persyaratan penting lainnya adalah kemampuan untuk mengirimkan semua jenis data (Byte, teks, data media aneh, dll.). Dengan semua pertimbangan, tidak masuk akal untuk mengandalkan solusi pihak ketiga untuk mendukung produk kami. Pada gilirannya, kami memutuskan untuk menghidupkan kembali semangat startup kami, menyingsingkan lengan baju kami untuk mengkodekan solusi kami sendiri.

Membangun Solusi Kami
Pub/Sub dengan desain berarti akan ada penerbit, menghasilkan dan mengirim data, dan Pelanggan menerima dan memprosesnya. Ini mirip dengan radio: Saluran radio menyiarkan (menerbitkan) konten di mana-mana dalam suatu jangkauan. Sebagai pelanggan, Anda dapat memutuskan apakah akan menyetel saluran tersebut dan mendengarkan (atau mematikan radio sama sekali).
Tidak seperti analogi radio di mana data gratis untuk semua dan siapa pun dapat memutuskan untuk mendengarkan, dalam skenario digital kami, kami memerlukan otentikasi yang berarti data yang dihasilkan oleh penerbit hanya bisa untuk satu klien atau pelanggan tertentu.
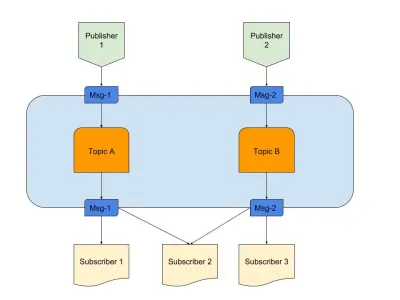
Di atas adalah diagram yang memberikan contoh Pub/Sub yang bagus dengan:
- penerbit
Di sini kami memiliki dua penerbit yang menghasilkan pesan berdasarkan logika yang telah ditentukan sebelumnya. Dalam analogi radio kami, ini adalah radio jockey kami yang membuat konten. - Topik
Ada dua di sini, artinya ada dua jenis data. Kami dapat mengatakan ini adalah saluran radio kami 1 dan 2. - Pelanggan
Kami memiliki tiga yang masing-masing membaca data tentang topik tertentu. Satu hal yang perlu diperhatikan adalah bahwa Pelanggan 2 membaca dari berbagai topik. Dalam analogi radio kami, ini adalah orang-orang yang disetel ke saluran radio.
Mari kita mulai memahami persyaratan yang diperlukan untuk layanan tersebut.
- Komponen kejadian
Ini hanya berlaku ketika ada sesuatu untuk ditendang. - Penyimpanan sementara
Ini membuat data bertahan untuk jangka waktu yang singkat sehingga jika pelanggan lambat, masih memiliki jendela untuk mengkonsumsinya. - Mengurangi latensi
Menghubungkan dua entitas melalui jaringan dengan hop dan jarak minimum.
Kami memilih tumpukan teknologi yang memenuhi persyaratan di atas:
- Node.js
Karena kenapa tidak? Bahkan, kami tidak memerlukan pemrosesan data yang berat, ditambah kemudahan untuk onboard. - Redis
Mendukung data berumur pendek yang sempurna. Ia memiliki semua kemampuan untuk memulai, memperbarui, dan kedaluwarsa otomatis. Ini juga mengurangi beban pada aplikasi.
Node.js Untuk Konektivitas Logika Bisnis
Node.js adalah bahasa yang hampir sempurna dalam hal penulisan kode yang menggabungkan IO dan acara. Masalah khusus kami memiliki keduanya, menjadikan opsi ini yang paling praktis untuk kebutuhan kami.
Tentunya bahasa lain seperti Java bisa lebih dioptimalkan, atau bahasa seperti Python menawarkan skalabilitas. Namun, biaya untuk memulai dengan bahasa ini sangat tinggi sehingga pengembang dapat menyelesaikan penulisan kode di Node dalam durasi yang sama.
Sejujurnya, jika layanan memiliki kesempatan untuk menambahkan fitur yang lebih rumit, kami dapat melihat bahasa lain atau tumpukan yang lengkap. Tapi ini adalah pernikahan yang dibuat di surga. Ini package.json kami:
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }Sederhananya, kami percaya pada minimalis terutama dalam hal menulis kode. Di sisi lain, kita bisa menggunakan perpustakaan seperti Express untuk menulis kode yang dapat diperluas untuk proyek ini. Namun, naluri startup kami memutuskan untuk meneruskan ini dan menyimpannya untuk proyek berikutnya. Alat tambahan yang kami gunakan:
- ioredis
Ini adalah salah satu perpustakaan yang paling didukung untuk konektivitas Redis dengan Node.js yang digunakan oleh perusahaan termasuk Alibaba. - socket.io
Pustaka terbaik untuk konektivitas anggun dan mundur dengan WebSocket dan HTTP.
Redis Untuk Penyimpanan Sementara
Redis sebagai timbangan layanan sangat andal dan dapat dikonfigurasi. Selain itu, ada banyak penyedia layanan terkelola yang andal untuk Redis, termasuk AWS. Bahkan jika Anda tidak ingin menggunakan penyedia, Redis mudah untuk memulai.
Mari kita uraikan bagian yang dapat dikonfigurasi. Kami memulai dengan konfigurasi master-slave biasa, tetapi Redis juga hadir dengan mode cluster atau sentinel. Setiap mode memiliki kelebihannya masing-masing.
Jika kami dapat membagikan data dengan cara tertentu, klaster Redis akan menjadi pilihan terbaik. Tetapi jika kami membagikan data dengan heuristik apa pun, kami memiliki lebih sedikit fleksibilitas karena heuristik harus diikuti . Lebih sedikit aturan, lebih banyak kontrol baik untuk kehidupan!
Redis Sentinel berfungsi paling baik bagi kami karena pencarian data dilakukan hanya dalam satu node, menghubungkan pada titik waktu tertentu saat data tidak di-sharding. Ini juga berarti bahwa meskipun banyak node hilang, data tetap didistribusikan dan ada di node lain. Jadi, Anda memiliki lebih banyak HA dan lebih sedikit kemungkinan kehilangan. Tentu saja, ini menghilangkan pro dari memiliki cluster, tetapi kasus penggunaan kami berbeda.
Arsitektur Pada 30000 Kaki
Diagram di bawah ini memberikan gambaran tingkat tinggi tentang cara kerja dasbor Automate dan App Automate kami. Ingat sistem real-time yang kita miliki dari bagian sebelumnya?
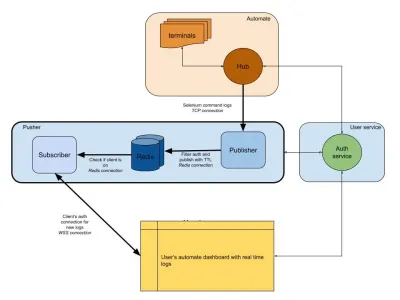
Dalam diagram kami, alur kerja utama kami disorot dengan batas yang lebih tebal. Bagian "otomatisasi" terdiri dari:
- Terminal
Terdiri dari versi murni Windows, OSX, Android atau iOS yang Anda dapatkan saat menguji di BrowserStack. - Pusat
Titik kontak untuk semua pengujian Selenium dan Appium Anda dengan BrowserStack.
Bagian "layanan pengguna" di sini adalah penjaga gerbang kami, memastikan data dikirim ke dan disimpan untuk individu yang tepat. Itu juga penjaga keamanan kami. Bagian "pendorong" menggabungkan inti dari apa yang kita bahas dalam artikel ini. Terdiri dari tersangka biasa termasuk:
- Redis
Penyimpanan sementara kami untuk pesan, di mana dalam kasus kami, log otomatis disimpan sementara. - Penerbit
Ini pada dasarnya adalah entitas yang memperoleh data dari hub. Semua tanggapan permintaan Anda ditangkap oleh komponen ini yang menulis ke Redis dengansession_idsebagai saluran. - pelanggan
Ini membaca data dari Redis yang dihasilkan untuksession_id. Ini juga merupakan server web bagi klien untuk terhubung melalui WebSocket (atau HTTP) untuk mendapatkan data dan kemudian mengirimkannya ke klien yang diautentikasi.
Terakhir, kami memiliki bagian browser pengguna, yang mewakili koneksi WebSocket yang diautentikasi untuk memastikan log session_id terkirim. Ini memungkinkan JS front-end untuk mengurai dan mempercantiknya untuk pengguna.
Mirip dengan layanan log, kami memiliki pendorong di sini yang digunakan untuk integrasi produk lainnya. Alih-alih session_id , kami menggunakan bentuk ID lain untuk mewakili saluran itu. Ini semua bekerja dari pendorong!
Kesimpulan (TLDR)
Kami telah cukup sukses dalam membangun Pub/Sub. Untuk meringkas mengapa kami membangunnya sendiri:
- Timbangan lebih baik untuk kebutuhan kita;
- Lebih murah daripada layanan outsourcing;
- Kontrol penuh atas keseluruhan arsitektur.
Belum lagi bahwa JS sangat cocok untuk skenario semacam ini. Loop peristiwa dan sejumlah besar IO adalah apa yang dibutuhkan masalahnya! JavaScript adalah keajaiban utas semu tunggal.
Acara dan Redis sebagai sistem membuat segalanya tetap sederhana bagi pengembang, karena Anda dapat memperoleh data dari satu sumber dan mengirimkannya ke sumber lain melalui Redis. Jadi kami membangunnya.
Jika penggunaannya cocok dengan sistem Anda, saya sarankan melakukan hal yang sama!