
Regresi Polinomial: Pentingnya, Implementasi Langkah-demi-Langkah
Diterbitkan: 2021-01-29Daftar isi
pengantar
Di bidang Machine Learning yang luas ini, apa algoritma pertama yang akan dipelajari sebagian besar dari kita? Ya, itu adalah Regresi Linier. Sebagian besar menjadi program dan algoritme pertama yang akan dipelajari seseorang di hari-hari awal Pemrograman Pembelajaran Mesin, Regresi Linier memiliki kepentingan dan kekuatannya sendiri dengan tipe data linier.
Bagaimana jika kumpulan data yang kita temui tidak dapat dipisahkan secara linier? Bagaimana jika model regresi linier tidak dapat menurunkan hubungan apa pun antara variabel bebas dan variabel terikat?
Ada jenis regresi lain yang dikenal sebagai Regresi Polinomial. Sesuai dengan namanya, Regresi Polinomial adalah algoritma regresi yang memodelkan hubungan antara variabel dependen (y) dan variabel independen (x) sebagai polinomial derajat ke-n. Pada artikel ini, kita akan memahami algoritma dan matematika di balik Regresi Polinomial beserta implementasinya di Python.
Apa itu Regresi Polinomial?
Seperti yang didefinisikan sebelumnya, Regresi Polinomial adalah kasus khusus dari regresi linier di mana persamaan polinomial dengan derajat (n) tertentu cocok pada data non-linier yang membentuk hubungan lengkung antara variabel dependen dan independen.
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
Di Sini,

y adalah variabel dependen (variabel output)
x1 adalah variabel bebas (prediktor)
b 0 adalah bias
b 1 , b 2 , ….b n adalah bobot dalam persamaan regresi.
Semakin tinggi derajat persamaan polinomial ( n ) maka persamaan polinomial menjadi semakin rumit dan ada kemungkinan model cenderung overfit yang akan dibahas pada bagian selanjutnya.
Perbandingan Persamaan Regresi
Regresi Linier Sederhana ===> y= b0+b1x
Regresi Linier Berganda ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
Regresi Polinomial ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
Dari ketiga persamaan di atas, kita melihat bahwa ada beberapa perbedaan halus di dalamnya. Persamaan Regresi Linier Sederhana dan Berganda berbeda dengan persamaan Regresi Polinomial karena hanya memiliki derajat 1. Regresi Linier Berganda terdiri dari beberapa variabel x1, x2, dan seterusnya. Meskipun persamaan Regresi Polinomial hanya memiliki satu variabel x1, persamaan tersebut memiliki derajat n yang membedakannya dari dua variabel lainnya.
Perlu Regresi Polinomial
Dari diagram di bawah ini kita dapat melihat bahwa pada diagram pertama, garis linier dicoba untuk dicocokkan pada himpunan titik data non-linier yang diberikan. Dapat dipahami bahwa menjadi sangat sulit bagi garis lurus untuk membentuk hubungan dengan data non-linier ini. Karena itu ketika kita melatih model, fungsi kerugian meningkat menyebabkan kesalahan tinggi.
Di sisi lain, ketika kita menerapkan Regresi Polinomial, terlihat jelas bahwa garis tersebut cocok dengan titik-titik data. Ini menandakan bahwa persamaan polinomial yang sesuai dengan titik data memperoleh semacam hubungan antara variabel dalam kumpulan data. Jadi, untuk kasus-kasus di mana titik-titik data disusun secara non-linier, kita memerlukan model Regresi Polinomial.
Implementasi Regresi Polinomial dengan Python
Dari sini, kita akan membangun model Machine Learning dengan Python yang mengimplementasikan Regresi Polinomial. Kami akan membandingkan hasil yang diperoleh dengan Regresi Linier dan Regresi Polinomial. Mari kita pahami terlebih dahulu masalah yang akan kita selesaikan dengan Regresi Polinomial.
Deskripsi Masalah
Dalam hal ini, pertimbangkan kasus Start-up yang ingin merekrut beberapa kandidat dari sebuah perusahaan. Ada lowongan yang berbeda untuk peran pekerjaan yang berbeda di perusahaan. Start-up memiliki rincian gaji untuk setiap peran di perusahaan sebelumnya. Jadi, ketika seorang kandidat menyebutkan gajinya sebelumnya, HR start-up perlu memverifikasinya dengan data yang ada. Dengan demikian, kami memiliki dua variabel independen yaitu Posisi dan Level. Variabel terikat (output) adalah Gaji yang akan diprediksi menggunakan Regresi Polinomial.
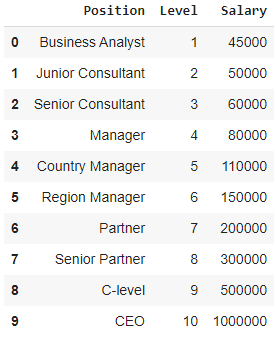
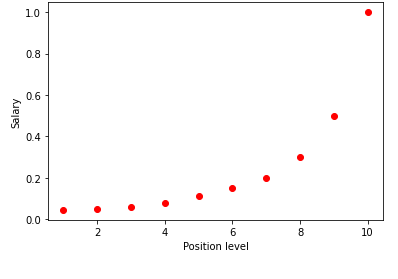
Saat memvisualisasikan tabel di atas dalam grafik, kita melihat bahwa data bersifat non-linier. Dengan kata lain, ketika tingkat meningkat, gaji meningkat pada tingkat yang lebih tinggi sehingga memberi kita kurva seperti yang ditunjukkan di bawah ini.
Langkah 1: Pra-Pemrosesan DataLangkah pertama dalam membangun model Pembelajaran Mesin apa pun adalah mengimpor perpustakaan. Di sini, kami hanya memiliki tiga perpustakaan dasar untuk diimpor. Setelah ini, dataset diimpor dari repositori GitHub saya dan variabel dependen dan variabel independen ditetapkan. Variabel bebas disimpan dalam variabel X dan variabel terikat disimpan dalam variabel y.
impor numpy sebagai np
impor matplotlib.pyplot sebagai plt
impor panda sebagai pd
kumpulan data = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')
X = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].values
Di sini dalam istilah [:, 1:-1], titik dua pertama menyatakan bahwa semua baris harus diambil dan istilah 1: -1 menunjukkan bahwa kolom yang akan dimasukkan adalah dari kolom pertama ke kolom kedua dari belakang yang diberikan oleh -1.
Langkah 2: Model Regresi LinierPada langkah selanjutnya, kita akan membangun model Regresi Linier Berganda dan menggunakannya untuk memprediksi data gaji dari variabel independen. Untuk ini, kelas LinearRegression diimpor dari perpustakaan sklearn. Kemudian dipasang pada variabel X dan y untuk tujuan pelatihan.

dari sklearn.linear_model impor LinearRegression
regresi = LinierRegresi()
regressor.fit(X, y)
Setelah model dibangun, pada visualisasi hasilnya, kita mendapatkan grafik berikut.
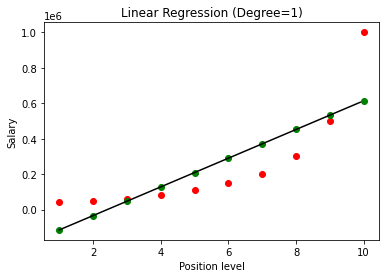
Seperti yang terlihat jelas, dengan mencoba menyesuaikan garis lurus pada dataset non-linear, tidak ada hubungan yang diturunkan oleh model Machine Learning. Jadi, kita perlu menggunakan Regresi Polinomial untuk mendapatkan hubungan antar variabel.
Langkah 3: Model Regresi PolinomialPada langkah berikutnya, kita akan memasukkan model Regresi Polinomial pada dataset ini dan memvisualisasikan hasilnya. Untuk ini, kami mengimpor Kelas lain dari modul sklearn bernama PolynomialFeatures di mana kami memberikan derajat persamaan polinomial yang akan dibangun. Kemudian kelas LinearRegression digunakan untuk menyesuaikan persamaan Polinomial ke dataset.
dari sklearn.preprocessing impor Fitur Polinomial
dari sklearn.linear_model impor LinearRegression
poly_reg = Fitur Polinomial(derajat = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = Regresi Linier()
lin_reg.fit(X_poly, y)
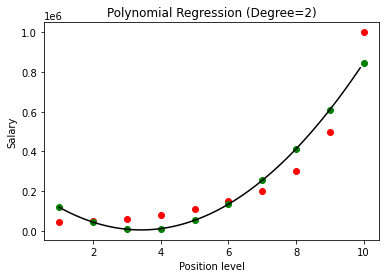
Dalam kasus di atas, kita telah memberikan derajat persamaan polinomial menjadi sama dengan 2. Saat memplot grafik, kita melihat bahwa ada semacam kurva yang diturunkan tetapi masih ada banyak penyimpangan dari data sebenarnya (berwarna merah ) dan titik kurva yang diprediksi (berwarna hijau). Jadi, pada langkah selanjutnya kita akan meningkatkan derajat polinomial ke angka yang lebih tinggi seperti 3 & 4 dan kemudian membandingkannya satu sama lain.
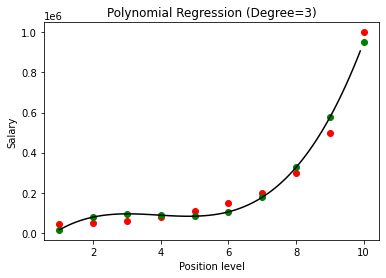
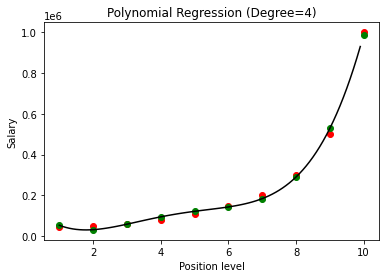
Saat membandingkan hasil Regresi Polinomial dengan derajat 3 dan 4, kita melihat bahwa seiring dengan kenaikan derajat, model berjalan dengan baik dengan data. Dengan demikian, kita dapat menyimpulkan bahwa derajat yang lebih tinggi memungkinkan persamaan Polinomial lebih cocok dengan data pelatihan. Namun, ini adalah kasus overfitting yang sempurna. Dengan demikian, menjadi penting untuk memilih nilai n secara tepat untuk mencegah overfitting.
Apa itu Overfitting?
Seperti namanya, Overfitting disebut sebagai situasi dalam statistik ketika suatu fungsi (atau model Pembelajaran Mesin dalam kasus ini) terlalu cocok dengan sekumpulan titik data terbatas. Hal ini menyebabkan fungsi berkinerja buruk dengan titik data baru.
Dalam Machine Learning jika sebuah model dikatakan overfitting pada kumpulan titik data pelatihan tertentu, kemudian ketika model yang sama diperkenalkan ke kumpulan titik yang sama sekali baru (katakanlah kumpulan data pengujian), maka kinerjanya sangat buruk di atasnya sebagai model overfitting belum digeneralisasi dengan baik dengan data dan hanya overfitting pada titik data pelatihan.
Dalam regresi polinomial, ada kemungkinan model mendapatkan overfit pada data pelatihan karena derajat polinomial meningkat. Dalam contoh yang ditunjukkan di atas, kita melihat kasus tipikal overfitting dalam regresi polinomial yang dapat dikoreksi hanya dengan dasar coba-coba untuk memilih nilai derajat yang optimal.
Baca Juga: Ide Proyek Pembelajaran Mesin
Kesimpulan
Untuk menyimpulkan, Regresi Polinomial digunakan dalam banyak situasi di mana ada hubungan non-linier antara variabel dependen dan independen. Meskipun algoritme ini memiliki sensitivitas terhadap outlier, algoritma ini dapat dikoreksi dengan memperlakukannya sebelum memasang garis regresi. Jadi, dalam artikel ini, kita telah diperkenalkan dengan konsep Regresi Polinomial beserta contoh implementasinya dalam Pemrograman Python pada dataset sederhana.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Pelajari Kursus ML dari Universitas top Dunia. Dapatkan Master, PGP Eksekutif, atau Program Sertifikat Tingkat Lanjut untuk mempercepat karier Anda.
Apakah yang Anda maksud: regresi linier
Regresi linier adalah jenis analisis numerik prediktif di mana kita dapat menemukan nilai variabel yang tidak diketahui dengan bantuan variabel dependen. Ini juga menjelaskan hubungan antara satu variabel dependen dan satu atau lebih variabel independen. Regresi linier adalah teknik statistik untuk menunjukkan hubungan antara dua variabel. Regresi linier memplot garis tren dari sekumpulan titik data. Regresi linier dapat digunakan untuk menghasilkan model prediksi dari data yang tampaknya acak, seperti diagnosis kanker atau harga saham. Ada beberapa metode untuk menghitung regresi linier. Pendekatan kuadrat terkecil biasa, yang memperkirakan variabel yang tidak diketahui dalam data dan secara visual berubah menjadi jumlah jarak vertikal antara titik data dan garis tren, adalah salah satu yang paling umum.
Apa saja kelemahan Regresi Linier?
Dalam kebanyakan kasus, analisis regresi digunakan dalam penelitian untuk menetapkan bahwa ada hubungan antara variabel. Namun, korelasi tidak menyiratkan sebab-akibat karena hubungan antara dua variabel tidak menyiratkan bahwa yang satu menyebabkan yang lain terjadi. Bahkan garis dalam regresi linier dasar yang sesuai dengan titik data mungkin tidak memastikan hubungan antara keadaan dan hasil logis. Dengan menggunakan model regresi linier, Anda dapat menentukan apakah ada korelasi antar variabel atau tidak. Penyelidikan ekstra dan analisis statistik akan diperlukan untuk menentukan sifat pasti dari hubungan dan apakah satu variabel menyebabkan variabel lainnya.
Apa asumsi dasar regresi linier?
Dalam regresi linier, ada tiga asumsi utama. Variabel dependen dan independen harus, pertama dan terutama, memiliki hubungan linier. Sebuah plot pencar dari variabel dependen dan independen digunakan untuk memeriksa hubungan ini. Kedua, harus ada minimal atau nol multi-kolinearitas antara variabel independen dalam dataset. Ini menyiratkan bahwa variabel independen tidak berhubungan. Nilainya harus dibatasi, yang ditentukan oleh persyaratan domain. Homoskedastisitas adalah faktor ketiga. Asumsi bahwa kesalahan terdistribusi secara merata adalah salah satu asumsi yang paling penting.