
Menjaga Node.js Cepat: Alat, Teknik, Dan Tips Untuk Membuat Server Node.js Berkinerja Tinggi
Diterbitkan: 2022-03-10Jika Anda telah membangun sesuatu dengan Node.js cukup lama, maka Anda pasti mengalami rasa sakit dari masalah kecepatan yang tidak terduga. JavaScript adalah bahasa asinkron yang terjadi. Itu dapat membuat alasan tentang kinerja menjadi rumit , seperti yang akan menjadi jelas. Popularitas Node.js yang melonjak telah mengungkapkan kebutuhan akan perkakas, teknik, dan pemikiran yang sesuai dengan batasan JavaScript sisi server.
Dalam hal kinerja, apa yang berfungsi di browser belum tentu cocok dengan Node.js. Jadi, bagaimana kita memastikan implementasi Node.js cepat dan sesuai dengan tujuan? Mari kita lihat contoh langsung.
Peralatan
Node adalah platform yang sangat serbaguna, tetapi salah satu aplikasi utama adalah membuat proses jaringan. Kami akan fokus pada pembuatan profil yang paling umum: server web HTTP.
Kami akan membutuhkan alat yang dapat meledakkan server dengan banyak permintaan sambil mengukur kinerjanya. Misalnya, kita dapat menggunakan AutoCannon:
npm install -g autocannonAlat pembandingan HTTP bagus lainnya termasuk Apache Bench (ab) dan wrk2, tetapi AutoCannon ditulis dalam Node, memberikan tekanan beban yang serupa (atau terkadang lebih besar), dan sangat mudah dipasang di Windows, Linux, dan Mac OS X.
Setelah kami menetapkan pengukuran kinerja dasar, jika kami memutuskan proses kami bisa lebih cepat, kami memerlukan beberapa cara untuk mendiagnosis masalah dengan proses tersebut. Alat hebat untuk mendiagnosis berbagai masalah kinerja adalah Node Clinic, yang juga dapat diinstal dengan npm:
npm install -g clinicIni sebenarnya menginstal seperangkat alat. Kami akan menggunakan Clinic Doctor dan Clinic Flame (pembungkus sekitar 0x) saat kami pergi.
Catatan : Untuk contoh langsung ini kita membutuhkan Node 8.11.2 atau lebih tinggi.
Kode
Contoh kasus kami adalah server REST sederhana dengan satu sumber daya: muatan JSON besar yang diekspos sebagai rute GET di /seed/v1 . Server adalah folder app yang terdiri dari file package.json (bergantung pada restify 7.1.0 ), file index.js dan file util.js.
File index.js untuk server kami terlihat seperti ini:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Server ini mewakili kasus umum dalam menyajikan konten dinamis yang di-cache klien. Ini dicapai dengan middleware etagger , yang menghitung header ETag untuk status konten terbaru.
File util.js menyediakan bagian implementasi yang biasanya digunakan dalam skenario seperti itu, fungsi untuk mengambil konten yang relevan dari backend, middleware etag, dan fungsi stempel waktu yang memasok stempel waktu setiap menit:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }Jangan sekali-kali mengambil kode ini sebagai contoh praktik terbaik! Ada beberapa bau kode dalam file ini, tetapi kami akan menemukannya saat kami mengukur dan membuat profil aplikasi.
Untuk mendapatkan sumber lengkap untuk titik awal kami, server lambat dapat ditemukan di sini.
membuat profil
Untuk membuat profil, kita memerlukan dua terminal, satu untuk memulai aplikasi, dan yang lainnya untuk pengujian beban.
Di satu terminal, di dalam folder app , kita dapat menjalankan:
node index.jsDi terminal lain kita dapat membuat profil seperti ini:
autocannon -c100 localhost:3000/seed/v1Ini akan membuka 100 koneksi bersamaan dan membombardir server dengan permintaan selama sepuluh detik.
Hasilnya harus seperti berikut (Menjalankan tes 10 detik @ https://localhost:3000/seed/v1 — 100 koneksi):
| status | Rata-rata | Stdev | Maks |
|---|---|---|---|
| Latensi (md) | 3086.81 | 1725.2 | 5554 |
| Permintaan/Detik | 23.1 | 19.18 | 65 |
| Byte/Detik | 237,98 kB | 197,7 kB | 688,13 kB |
Hasil akan bervariasi tergantung pada mesin. Namun, mengingat server Node.js "Hello World" dengan mudah mampu melakukan tiga puluh ribu permintaan per detik pada mesin yang menghasilkan hasil ini, 23 permintaan per detik dengan rata-rata latensi melebihi 3 detik adalah suram.
Mendiagnosis
Menemukan Area Masalah
Kami dapat mendiagnosis aplikasi dengan satu perintah, berkat perintah –on-port Clinic Doctor. Di dalam folder app kami menjalankan:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsIni akan membuat file HTML yang secara otomatis akan terbuka di browser kita saat pembuatan profil selesai.
Hasilnya akan terlihat seperti berikut:
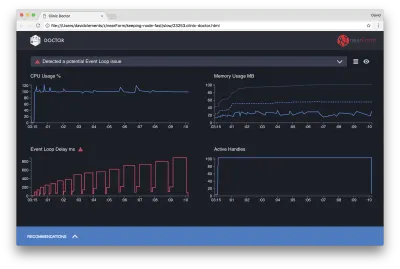
Dokter memberi tahu kami bahwa kami mungkin memiliki masalah Event Loop.
Bersamaan dengan pesan di dekat bagian atas UI, kita juga dapat melihat bahwa bagan Loop Peristiwa berwarna merah, dan menunjukkan penundaan yang terus meningkat. Sebelum kita menggali lebih dalam apa artinya ini, pertama-tama mari kita pahami efek masalah yang didiagnosis terhadap metrik lainnya.
Kita dapat melihat CPU secara konsisten pada atau di atas 100% karena proses bekerja keras untuk memproses permintaan yang antri. Mesin JavaScript Node (V8) sebenarnya menggunakan dua inti CPU dalam hal ini karena mesinnya multi-core dan V8 menggunakan dua utas. Satu untuk Loop Acara dan yang lainnya untuk Pengumpulan Sampah. Ketika kami melihat CPU melonjak hingga 120% dalam beberapa kasus, prosesnya adalah mengumpulkan objek yang terkait dengan permintaan yang ditangani.
Kami melihat ini berkorelasi dalam grafik Memori. Garis solid dalam bagan Memori adalah metrik Heap Used. Setiap kali ada lonjakan CPU, kami melihat penurunan di baris Heap Used, yang menunjukkan bahwa memori sedang tidak dialokasikan.
Handle Aktif tidak terpengaruh oleh penundaan Event Loop. Pegangan aktif adalah objek yang mewakili I/O (seperti soket atau pegangan file) atau pengatur waktu (seperti setInterval ). Kami menginstruksikan AutoCannon untuk membuka 100 koneksi ( -c100 ). Pegangan aktif tetap dalam hitungan 103 yang konsisten. Tiga lainnya adalah pegangan untuk STDOUT, STDERR, dan pegangan untuk server itu sendiri.
Jika kita mengklik panel Rekomendasi di bagian bawah layar, kita akan melihat sesuatu seperti berikut:
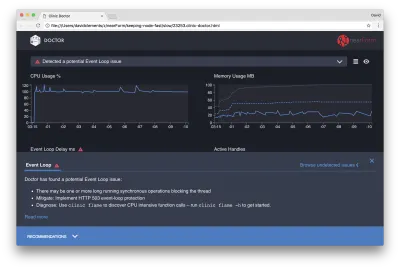
Mitigasi Jangka Pendek
Analisis akar penyebab masalah kinerja yang serius dapat memakan waktu. Dalam kasus proyek yang diterapkan secara langsung, ada baiknya menambahkan perlindungan yang berlebihan ke server atau layanan. Gagasan perlindungan kelebihan beban adalah untuk memantau penundaan loop peristiwa (antara lain), dan merespons dengan "503 Layanan Tidak Tersedia" jika ambang batas dilewati. Ini memungkinkan penyeimbang beban gagal ke instance lain, atau dalam kasus terburuk berarti pengguna harus menyegarkan. Modul perlindungan kelebihan beban dapat menyediakan ini dengan overhead minimum untuk Express, Koa, dan Restify. Kerangka kerja Hapi memiliki pengaturan konfigurasi beban yang memberikan perlindungan yang sama.
Memahami Area Masalah
Seperti yang dijelaskan oleh penjelasan singkat di Clinic Doctor, jika Event Loop tertunda ke level yang kita amati, kemungkinan besar satu atau lebih fungsi "memblokir" Event Loop.
Sangat penting bagi Node.js untuk mengenali karakteristik JavaScript utama ini: peristiwa asinkron tidak dapat terjadi hingga kode yang sedang dieksekusi selesai.
Inilah sebabnya mengapa setTimeout tidak bisa tepat.
Misalnya, coba jalankan yang berikut ini di DevTools browser atau Node REPL:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() Pengukuran waktu yang dihasilkan tidak akan pernah 100 ms. Kemungkinan akan berada di kisaran 150ms hingga 250ms. setTimeout menjadwalkan operasi asinkron ( console.timeEnd ), tetapi kode yang dijalankan saat ini belum selesai; ada dua baris lagi. Kode yang sedang dieksekusi dikenal sebagai "centang" saat ini. Agar centang selesai, Math.random harus dipanggil sepuluh juta kali. Jika ini membutuhkan 100 md, maka total waktu sebelum batas waktu diselesaikan adalah 200 md (ditambah berapa lama pun fungsi setTimeout untuk benar-benar mengantri batas waktu sebelumnya, biasanya beberapa milidetik).
Dalam konteks sisi server, jika operasi di centang saat ini membutuhkan waktu lama untuk menyelesaikan permintaan tidak dapat ditangani, dan pengambilan data tidak dapat terjadi karena kode asinkron tidak akan dijalankan sampai centang saat ini telah selesai. Ini berarti bahwa kode yang mahal secara komputasi akan memperlambat semua interaksi dengan server. Jadi disarankan untuk membagi pekerjaan intensif sumber daya ke dalam proses terpisah dan memanggilnya dari server utama, ini akan menghindari kasus di mana pada rute yang jarang digunakan tetapi mahal memperlambat kinerja rute lain yang sering digunakan tetapi murah.
Server contoh memiliki beberapa kode yang memblokir Event Loop, jadi langkah selanjutnya adalah mencari kode tersebut.
Menganalisa
Salah satu cara untuk mengidentifikasi kode yang berkinerja buruk dengan cepat adalah dengan membuat dan menganalisis grafik nyala. Grafik nyala mewakili panggilan fungsi sebagai blok yang duduk di atas satu sama lain — tidak dari waktu ke waktu tetapi secara agregat. Alasan itu disebut 'grafik api' adalah karena biasanya menggunakan skema warna oranye ke merah, di mana semakin merah sebuah blok adalah fungsi yang "lebih panas", artinya, semakin besar kemungkinannya untuk memblokir loop acara. Menangkap data untuk grafik nyala dilakukan melalui pengambilan sampel CPU — yang berarti bahwa snapshot dari fungsi yang sedang dijalankan dan tumpukannya diambil. Panas ditentukan oleh persentase waktu selama pembuatan profil bahwa fungsi yang diberikan berada di bagian atas tumpukan (misalnya fungsi yang sedang dijalankan) untuk setiap sampel. Jika itu bukan fungsi terakhir yang pernah dipanggil dalam tumpukan itu, maka kemungkinan akan memblokir loop acara.
Mari kita gunakan clinic flame untuk menghasilkan grafik nyala dari contoh aplikasi:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsHasilnya akan terbuka di browser kami dengan sesuatu seperti berikut:
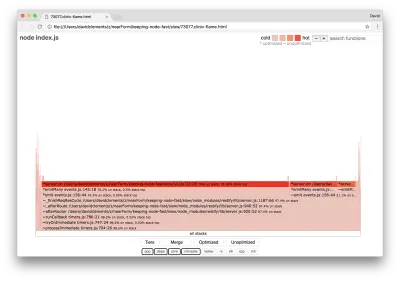
Lebar blok menunjukkan berapa banyak waktu yang dihabiskan untuk CPU secara keseluruhan. Tiga tumpukan utama dapat diamati memakan waktu paling banyak, semuanya menyoroti server.on sebagai fungsi terpanas. Sebenarnya, ketiga tumpukan itu sama. Mereka berbeda karena selama pembuatan profil, fungsi yang dioptimalkan dan yang tidak dioptimalkan diperlakukan sebagai bingkai panggilan terpisah. Fungsi yang diawali dengan * dioptimalkan oleh mesin JavaScript, dan yang diawali dengan ~ tidak dioptimalkan. Jika status yang dioptimalkan tidak penting bagi kami, kami dapat menyederhanakan grafik lebih lanjut dengan menekan tombol Gabung. Ini akan mengarah pada tampilan yang mirip dengan berikut ini:
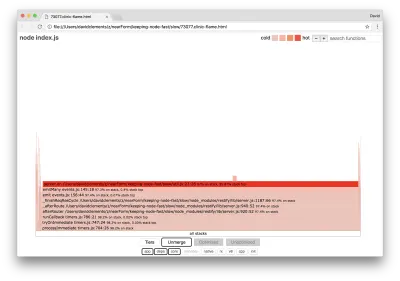
Sejak awal, kita dapat menyimpulkan bahwa kode yang melanggar ada di file util.js dari kode aplikasi.
Fungsi lambat juga merupakan pengendali peristiwa: fungsi yang mengarah ke fungsi tersebut adalah bagian dari modul events inti, dan server.on adalah nama cadangan untuk fungsi anonim yang disediakan sebagai fungsi penanganan peristiwa. Kita juga dapat melihat bahwa kode ini tidak berada di centang yang sama dengan kode yang benar-benar menangani permintaan. Jika ya, fungsi dari modul inti http , net dan stream akan ada di tumpukan.
Fungsi inti seperti itu dapat ditemukan dengan memperluas bagian lain yang jauh lebih kecil dari grafik nyala. Misalnya, coba gunakan input pencarian di kanan atas UI untuk mencari send (nama metode internal restify dan http ). Itu harus di sebelah kanan grafik (fungsi diurutkan menurut abjad):
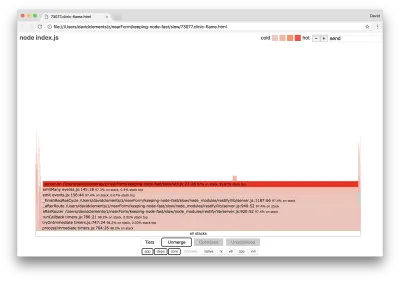
Perhatikan betapa kecilnya semua blok penanganan HTTP yang sebenarnya.

Kita dapat mengklik salah satu blok yang disorot dalam cyan yang akan diperluas untuk menampilkan fungsi seperti writeHead dan write di file http_outgoing.js (bagian dari perpustakaan inti Node http ):
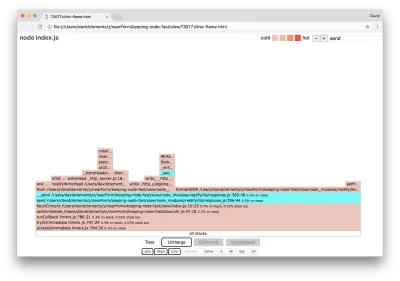
Kita dapat mengklik semua tumpukan untuk kembali ke tampilan utama.
Poin kuncinya di sini adalah bahwa meskipun fungsi server.on tidak sama dengan kode penanganan permintaan yang sebenarnya, itu masih memengaruhi kinerja server secara keseluruhan dengan menunda eksekusi kode yang berfungsi.
Men-debug
Kita tahu dari grafik nyala bahwa fungsi yang bermasalah adalah event handler yang diteruskan ke server.on dalam file util.js.
Mari lihat:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) Sudah diketahui bahwa kriptografi cenderung mahal, seperti halnya serialisasi ( JSON.stringify ) tetapi mengapa mereka tidak muncul di grafik nyala? Operasi ini ada dalam sampel yang diambil, tetapi tersembunyi di balik filter cpp . Jika kita menekan tombol cpp kita akan melihat sesuatu seperti berikut:
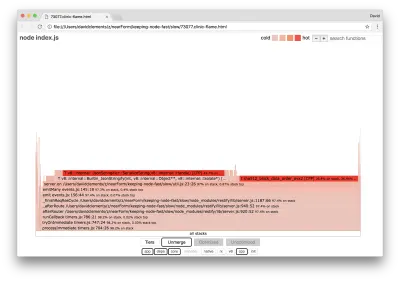
Instruksi V8 internal yang berkaitan dengan serialisasi dan kriptografi sekarang ditampilkan sebagai tumpukan terpanas dan menghabiskan sebagian besar waktu. Metode JSON.stringify secara langsung memanggil kode C++; inilah mengapa kami tidak melihat fungsi JavaScript. Dalam kasus kriptografi, fungsi seperti createHash dan update ada dalam data, tetapi keduanya sejajar (yang berarti menghilang dalam tampilan gabungan) atau terlalu kecil untuk dirender.
Begitu kita mulai mempertimbangkan kode dalam fungsi etagger , dapat dengan cepat menjadi jelas bahwa itu dirancang dengan buruk. Mengapa kita mengambil contoh server dari konteks fungsi? Ada banyak hashing yang terjadi, apakah semua itu perlu? Juga tidak ada dukungan header If-None-Match dalam implementasi yang akan mengurangi beberapa beban di beberapa skenario dunia nyata karena klien hanya akan membuat permintaan utama untuk menentukan kesegaran.
Mari kita abaikan semua poin ini untuk saat ini dan validasi temuan bahwa pekerjaan sebenarnya yang dilakukan di server.on memang menjadi penghambat. Ini dapat dicapai dengan menyetel kode server.on ke fungsi kosong dan menghasilkan flamegraph baru.
Ubah fungsi etagger menjadi berikut:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } Fungsi pendengar acara yang diteruskan ke server.on sekarang tidak dapat dilakukan.
Ayo jalankan clinic flame lagi:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsIni akan menghasilkan grafik nyala yang mirip dengan yang berikut:
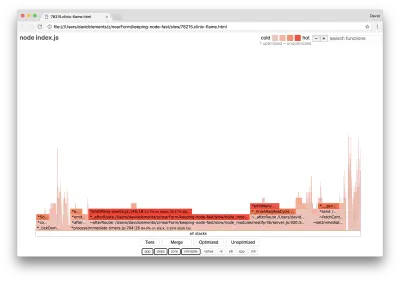
Ini terlihat lebih baik, dan kita seharusnya memperhatikan peningkatan permintaan per detik. Tapi mengapa kode pemancar acara begitu panas? Kami berharap pada titik ini untuk kode pemrosesan HTTP untuk mengambil sebagian besar waktu CPU, tidak ada yang dieksekusi sama sekali di acara server.on .
Jenis kemacetan ini disebabkan oleh fungsi yang dieksekusi lebih dari yang seharusnya.
Kode mencurigakan berikut di bagian atas util.js mungkin merupakan petunjuk:
require('events').defaultMaxListeners = Infinity Mari kita hapus baris ini dan mulai proses kita dengan --trace-warnings :
node --trace-warnings index.jsJika kami membuat profil dengan AutoCannon di terminal lain, seperti:
autocannon -c100 localhost:3000/seed/v1Proses kami akan menampilkan sesuatu yang mirip dengan:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node memberi tahu kita bahwa banyak peristiwa sedang dilampirkan ke objek server . Ini aneh karena ada boolean yang memeriksa apakah acara telah dilampirkan dan kemudian kembali lebih awal yang pada dasarnya membuat attachAfterEvent menjadi larangan setelah acara pertama dilampirkan.
Mari kita lihat fungsi attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } Pemeriksaan bersyarat salah! Ia memeriksa apakah attachAfterEvent benar daripada afterEventAttached . Ini berarti peristiwa baru sedang dilampirkan ke instance server pada setiap permintaan, dan kemudian semua peristiwa terlampir sebelumnya dipecat setelah setiap permintaan. Ups!
Mengoptimalkan
Sekarang kita telah menemukan area masalah, mari kita lihat apakah kita dapat membuat server lebih cepat.
Buah Menggantung Rendah
Mari kita kembalikan kode pendengar server.on (bukan fungsi kosong) dan gunakan nama boolean yang benar dalam pemeriksaan bersyarat. Fungsi etagger kami terlihat sebagai berikut:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Sekarang kami memeriksa perbaikan kami dengan membuat profil lagi. Mulai server di satu terminal:
node index.jsKemudian profil dengan AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Kita akan melihat hasil di suatu tempat dalam kisaran peningkatan 200 kali (Menjalankan tes 10 detik @ https://localhost:3000/seed/v1 — 100 koneksi):
| status | Rata-rata | Stdev | Maks |
|---|---|---|---|
| Latensi (md) | 19.47 | 4.29 | 103 |
| Permintaan/Detik | 5011.11 | 506.2 | 5487 |
| Byte/Detik | 51,8 MB | 5,45 MB | 58,72 MB |
Sangat penting untuk menyeimbangkan potensi pengurangan biaya server dengan biaya pengembangan. Kita perlu mendefinisikan, dalam konteks situasional kita sendiri, seberapa jauh kita perlu mengoptimalkan sebuah proyek. Jika tidak, akan terlalu mudah untuk memasukkan 80% upaya ke dalam 20% peningkatan kecepatan. Apakah kendala proyek membenarkan hal ini?
Dalam beberapa skenario, mungkin tepat untuk mencapai peningkatan 200 kali dengan buah gantung rendah dan menyebutnya sehari. Di tempat lain, kami mungkin ingin membuat implementasi kami secepat mungkin. Itu sangat tergantung pada prioritas proyek.
Salah satu cara untuk mengontrol pengeluaran sumber daya adalah dengan menetapkan tujuan. Misalnya, 10 kali peningkatan, atau 4000 permintaan per detik. Mendasarkan ini pada kebutuhan bisnis adalah yang paling masuk akal. Misalnya, jika biaya server 100% melebihi anggaran, kami dapat menetapkan sasaran peningkatan 2x.
Mengambilnya Lebih Jauh
Jika kita menghasilkan grafik nyala baru dari server kita, kita akan melihat sesuatu yang mirip dengan berikut:
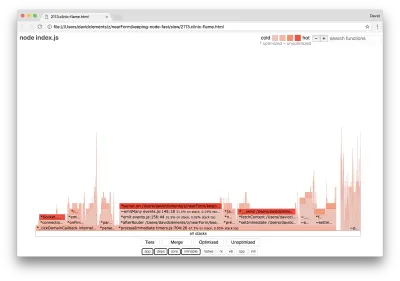
Pendengar acara masih menjadi penghambat, masih menghabiskan sepertiga waktu CPU selama pembuatan profil (lebarnya sekitar sepertiga dari keseluruhan grafik).
Keuntungan tambahan apa yang dapat diperoleh, dan apakah perubahan (bersama dengan gangguan terkaitnya) layak dilakukan?
Dengan implementasi yang dioptimalkan, yang sedikit lebih dibatasi, karakteristik kinerja berikut dapat dicapai (Menjalankan uji 10 detik @ https://localhost:3000/seed/v1 — 10 koneksi):
| status | Rata-rata | Stdev | Maks |
|---|---|---|---|
| Latensi (md) | 0,64 | 0,86 | 17 |
| Permintaan/Detik | 8330.91 | 757,63 | 8991 |
| Byte/Detik | 84,17 MB | 7.64 MB | 92,27 MB |
Meskipun peningkatan 1,6x signifikan, hal itu dapat diperdebatkan tergantung pada situasi apakah upaya, perubahan, dan gangguan kode yang diperlukan untuk membuat peningkatan ini dapat dibenarkan. Terutama jika dibandingkan dengan peningkatan 200x pada implementasi asli dengan satu perbaikan bug.
Untuk mencapai peningkatan ini, teknik berulang yang sama untuk profil, menghasilkan flamegraph, menganalisis, men-debug, dan mengoptimalkan digunakan untuk sampai pada server akhir yang dioptimalkan, kode yang dapat ditemukan di sini.
Perubahan terakhir untuk mencapai 8000 req/s adalah:
- Jangan membuat objek dan kemudian membuat serial, buat string JSON secara langsung;
- Gunakan sesuatu yang unik tentang konten untuk mendefinisikan Etag-nya, daripada membuat hash;
- Jangan hash URL, gunakan langsung sebagai kuncinya.
Perubahan ini sedikit lebih terlibat, sedikit lebih mengganggu basis kode, dan membuat middleware etagger sedikit kurang fleksibel karena memberikan beban pada rute untuk memberikan nilai Etag . Tapi itu mencapai tambahan 3000 permintaan per detik pada mesin profil.
Mari kita lihat grafik nyala untuk perbaikan terakhir ini:
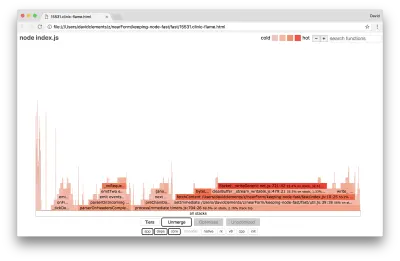
Bagian terpanas dari grafik api adalah bagian dari inti Node, di modul net . Ini sangat ideal.
Mencegah Masalah Kinerja
Untuk melengkapi, berikut adalah beberapa saran tentang cara untuk mencegah masalah kinerja sebelum diterapkan.
Menggunakan alat kinerja sebagai pos pemeriksaan informal selama pengembangan dapat menyaring bug kinerja sebelum mereka membuatnya menjadi produksi. Membuat AutoCannon dan Clinic (atau yang setara) sebagai bagian dari alat pengembangan sehari-hari direkomendasikan.
Saat membeli kerangka kerja, cari tahu apa kebijakan kinerjanya. Jika kerangka kerja tidak memprioritaskan kinerja, maka penting untuk memeriksa apakah itu sejalan dengan praktik infrastruktur dan tujuan bisnis. Misalnya, Restify jelas (sejak rilis versi 7) berinvestasi dalam meningkatkan kinerja perpustakaan. Namun, jika biaya rendah dan kecepatan tinggi adalah prioritas mutlak, pertimbangkan Fastify yang telah diukur 17% lebih cepat oleh kontributor Restify.
Hati-hati dengan pilihan perpustakaan lain yang berdampak luas — terutama pertimbangkan untuk masuk. Saat pengembang memperbaiki masalah, mereka mungkin memutuskan untuk menambahkan keluaran log tambahan untuk membantu men-debug masalah terkait di masa mendatang. Jika logger yang tidak berkinerja baik digunakan, ini dapat mencekik kinerja dari waktu ke waktu setelah mode dongeng katak mendidih. Pino logger adalah logger JSON delimited baris baru tercepat yang tersedia untuk Node.js.
Terakhir, selalu ingat bahwa Event Loop adalah sumber daya bersama. Server Node.js pada akhirnya dibatasi oleh logika paling lambat di jalur terpanas.