
Pelajari Algoritma Naive Bayes Untuk Pembelajaran Mesin [Dengan Contoh]
Diterbitkan: 2021-02-25Daftar isi
pengantar
Dalam matematika dan pemrograman, beberapa solusi paling sederhana biasanya yang paling kuat. Algoritma Naive Bayes hadir sebagai contoh klasik dari pernyataan ini. Bahkan dengan kemajuan dan perkembangan yang kuat dan pesat di bidang Machine Learning, Algoritma Naive Bayes ini masih berdiri kokoh sebagai salah satu algoritma yang paling banyak digunakan dan efisien. Algoritma Naive Bayes menemukan aplikasinya dalam berbagai masalah termasuk tugas Klasifikasi dan masalah Natural Language Processing (NLP).
Hipotesis matematis dari Teorema Bayes berfungsi sebagai konsep dasar di balik Algoritma Naive Bayes ini. Pada artikel ini, kita akan membahas dasar-dasar Teorema Bayes, Algoritma Naive Bayes beserta implementasinya di Python dengan contoh masalah waktu nyata. Bersamaan dengan ini, kita juga akan melihat beberapa kelebihan dan kekurangan dari Algoritma Naive Bayes dibandingkan dengan para pesaingnya.
Dasar-dasar Probabilitas
Sebelum kita menjelajah untuk memahami Teorema Bayes dan Algoritma Naive Bayes, mari kita memoles pengetahuan kita yang ada pada dasar-dasar Probabilitas.
Seperti yang kita ketahui dengan definisi, jika diberikan peristiwa A, peluang terjadinya peristiwa itu diberikan oleh P(A). Dalam probabilitas, dua peristiwa A dan B disebut sebagai peristiwa independen jika terjadinya peristiwa A tidak mengubah peluang terjadinya peristiwa B dan sebaliknya. Di sisi lain, jika kejadian yang satu mengubah probabilitas yang lain, maka kejadian itu disebut sebagai kejadian yang Bergantung.
Mari kita mengenal istilah baru yang disebut Probabilitas Bersyarat . Dalam matematika, Peluang Bersyarat untuk dua peristiwa A dan B yang diberikan oleh P (A| B) didefinisikan sebagai peluang terjadinya peristiwa A jika peristiwa B telah terjadi. Bergantung pada hubungan antara dua peristiwa A dan B, apakah mereka bergantung atau bebas, Peluang Bersyarat dihitung dengan dua cara.
- Probabilitas bersyarat dari dua kejadian dependen A dan B diberikan oleh P (A| B) = P (A dan B) / P (B)
- Ekspresi untuk peluang bersyarat dari dua kejadian bebas A dan B diberikan oleh, P (A| B) = P (A)
Mengetahui matematika di balik Probabilitas dan Probabilitas Bersyarat, mari kita beralih ke Teorema Bayes.

Teorema Bayes
Dalam statistik dan teori probabilitas, Teorema Bayes juga dikenal sebagai aturan Bayes digunakan untuk menentukan probabilitas bersyarat dari suatu kejadian. Dengan kata lain, teorema Bayes menggambarkan probabilitas suatu peristiwa berdasarkan pengetahuan sebelumnya tentang kondisi yang mungkin relevan dengan peristiwa tersebut.
Untuk memahaminya secara lebih sederhana, pertimbangkan bahwa kita perlu mengetahui kemungkinan harga rumah yang sangat tinggi. Jika kita mengetahui parameter lain seperti keberadaan sekolah, toko medis, dan rumah sakit terdekat, maka kita dapat membuat penilaian yang lebih akurat tentang hal tersebut. Inilah yang dilakukan oleh Teorema Bayes.
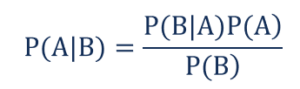
Seperti yang,
- P(A|B) – probabilitas bersyarat dari kejadian A yang terjadi, mengingat kejadian B telah terjadi juga dikenal sebagai Probabilitas Posterior .
- P(B|A) – probabilitas bersyarat dari peristiwa B yang terjadi, mengingat peristiwa A telah terjadi juga dikenal sebagai Peluang Kemungkinan .
- P(A) – Probabilitas kejadian A yang juga dikenal sebagai Probabilitas Sebelumnya.
- P(B) – Probabilitas kejadian B yang juga dikenal sebagai Probabilitas Marginal.
Misalkan kita memiliki masalah Machine Learning sederhana dengan 'n' variabel independen dan variabel dependen yang outputnya adalah nilai Boolean (Benar atau Salah). Misalkan atribut independen bersifat kategorikal, mari kita pertimbangkan 2 kategori untuk contoh ini. Oleh karena itu, dengan data tersebut, kita perlu menghitung nilai Peluang Kemungkinan, P(B|A).
Oleh karena itu, dengan mengamati hal di atas, kita menemukan bahwa kita perlu menghitung parameter 2*(2^ n -1 ) untuk mempelajari model Machine Learning ini. Demikian pula, jika kita memiliki 30 atribut independen Boolean, maka jumlah total parameter yang akan dihitung akan mendekati 3 miliar yang merupakan biaya komputasi yang sangat tinggi.
Kesulitan dalam membangun model Machine Learning dengan Teorema Bayes ini menyebabkan lahir dan berkembangnya Algoritma Naive Bayes.
Algoritma Naive Bayes
Agar praktis, kompleksitas Teorema Bayes yang disebutkan di atas perlu dikurangi. Ini persis dicapai dalam Algoritma Naive Bayes dengan membuat beberapa asumsi. Asumsi yang dibuat adalah bahwa setiap fitur memberikan kontribusi yang independen dan setara terhadap hasil.
Algoritma Naive Bayes adalah algoritma pembelajaran terawasi dan didasarkan pada teorema Bayes yang terutama digunakan dalam memecahkan masalah klasifikasi. Ini adalah salah satu Pengklasifikasi paling sederhana dan paling akurat yang membangun model Pembelajaran Mesin untuk membuat prediksi cepat. Secara matematis, ini adalah pengklasifikasi probabilistik karena membuat prediksi menggunakan fungsi probabilitas dari peristiwa.
Contoh Soal
Untuk memahami logika di balik asumsi, mari kita lihat kumpulan data sederhana untuk mendapatkan intuisi yang lebih baik.
| Warna | Jenis | Asal | Pencurian? |
| Hitam | Sedan | Impor | Ya |
| Hitam | SUV | Impor | Tidak |
| Hitam | Sedan | Lokal | Ya |
| Hitam | Sedan | Impor | Tidak |
| cokelat | SUV | Lokal | Ya |
| cokelat | SUV | Lokal | Tidak |
| cokelat | Sedan | Impor | Tidak |
| cokelat | SUV | Impor | Ya |
| cokelat | Sedan | Lokal | Tidak |
Dari kumpulan data yang diberikan di atas, kita dapat memperoleh konsep dari dua asumsi yang kita definisikan untuk Algoritma Naive Bayes di atas.
- Asumsi pertama adalah bahwa semua fitur independen satu sama lain. Di sini, kita melihat bahwa setiap atribut independen seperti warna "Merah" tidak tergantung pada Jenis dan Asal mobil.
- Selanjutnya, setiap fitur harus diberikan kepentingan yang sama. Demikian pula, hanya memiliki pengetahuan tentang Jenis dan Asal-usul Mobil saja tidak cukup untuk memprediksi keluaran masalah. Oleh karena itu, tidak ada variabel yang tidak relevan dan karenanya semuanya memberikan kontribusi yang sama terhadap hasil.
Singkatnya, A dan B bebas bersyarat diberikan C jika dan hanya jika, dengan pengetahuan bahwa C terjadi, pengetahuan tentang apakah A terjadi tidak memberikan informasi tentang kemungkinan B terjadi, dan pengetahuan tentang apakah B terjadi tidak memberikan informasi tentang kemungkinan A terjadi. Asumsi ini membuat algoritma Bayes – Naive . Oleh karena itu namanya, Algoritma Naive Bayes.
Oleh karena itu untuk masalah yang diberikan di atas, Teorema Bayes dapat ditulis ulang sebagai -
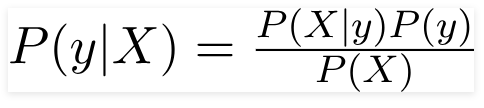
Seperti yang,
- Vektor fitur independen, X = (x 1 , x 2 , x 3 ……x n ) mewakili fitur seperti Warna, Jenis dan Asal Mobil.
- Variabel keluaran, y hanya memiliki dua hasil Ya atau Tidak.
Oleh karena itu, dengan mensubstitusi nilai-nilai di atas, kami memperoleh Rumus Naive Bayes sebagai,
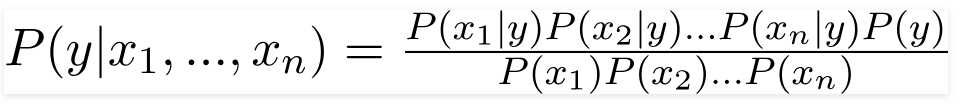
Untuk menghitung probabilitas posterior P(y|X), kita harus membuat Tabel Frekuensi untuk setiap atribut terhadap output. Kemudian mengubah tabel frekuensi menjadi Tabel Kemungkinan setelah itu akhirnya kita menggunakan persamaan Naive Bayesian untuk menghitung probabilitas posterior untuk setiap kelas. Kelas dengan probabilitas posterior tertinggi dipilih sebagai hasil prediksi. Di bawah ini adalah tabel Frekuensi dan kemungkinan untuk ketiga prediktor.
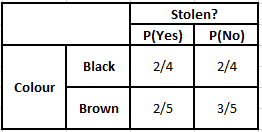
Tabel Frekuensi Warna Tabel Kemungkinan Warna
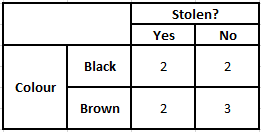
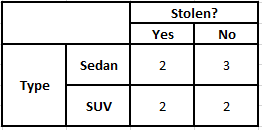
Tabel Frekuensi Jenis Tabel Kemungkinan Jenis
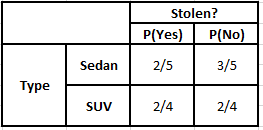

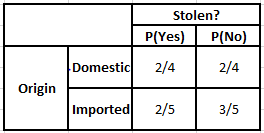
Tabel Frekuensi Asal Tabel Kemungkinan Asal
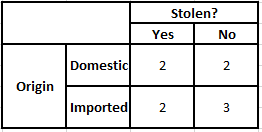
Pertimbangkan kasus di mana kita perlu menghitung probabilitas posterior untuk kondisi yang diberikan di bawah ini –
| Warna | Jenis | Asal |
| cokelat | SUV | Impor |
Jadi, dari rumus yang diberikan di atas, kita dapat menghitung Probabilitas Posterior seperti yang ditunjukkan di bawah ini–
P(Ya | X) = P(Coklat | Ya) * P(SUV | Ya) * P(Impor | Ya) * P(Ya)
= 2/5 * 2/4 * 2/5 * 1
= 0,08
P(Tidak | X) = P(Coklat | Tidak) * P(SUV | Tidak) * P(Impor | Tidak) * P(Tidak)
= 3/5 * 2/4 * 3/5 * 1
= 0,18
Dari nilai perhitungan di atas, karena Probabilitas Posterior untuk Tidak Lebih Besar dari Ya (0,18>0,08), maka dapat disimpulkan bahwa mobil dengan Warna Coklat, Jenis SUV Asal Impor diklasifikasikan sebagai “Tidak”. Karenanya, mobil itu tidak dicuri.
Implementasi dengan Python
Sekarang kita telah memahami matematika di balik algoritma Naive Bayes dan juga memvisualisasikannya dengan sebuah contoh, mari kita lihat kode Machine Learning-nya dalam bahasa Python.
Terkait: Pengklasifikasi Naive Bayes
Analisa masalah
Untuk mengimplementasikan program Klasifikasi Naive Bayes dalam Machine Learning menggunakan Python, kita akan menggunakan 'Iris Flower Dataset' yang sangat terkenal”. Kumpulan data bunga Iris atau kumpulan data Iris Fisher adalah kumpulan data multivariat yang diperkenalkan oleh ahli statistik, eugenika, dan biologi Inggris Ronald Fisher pada tahun 1998. Ini adalah kumpulan data yang sangat kecil dan dasar yang terdiri dari data numerik yang sangat sedikit yang berisi informasi tentang 3 kelas bunga milik spesies Iris yang -
- Iris Setosa
- Warna Iris Versi
- Iris Virginica
Ada 50 sampel dari masing-masing tiga spesies dengan total dataset 150 baris. 4 atribut (atau) variabel independen yang digunakan dalam dataset ini adalah –
- panjang sepal dalam cm
- lebar sepal dalam cm
- panjang kelopak dalam cm
- lebar kelopak dalam cm
Variabel terikat adalah " spesies " bunga yang diidentifikasi oleh empat atribut yang diberikan di atas.
Langkah 1 – Mengimpor Perpustakaan
Seperti biasa, langkah utama dalam membangun model Pembelajaran Mesin apa pun adalah mengimpor pustaka yang relevan. Untuk ini, kami akan memuat pustaka NumPy, Mathplotlib dan Pandas untuk pra-pemrosesan data.
impor numpy sebagai np
impor matplotlib.pyplot sebagai plt
impor panda sebagai pd
Langkah 2 – Memuat Dataset
Kumpulan data bunga Iris yang akan digunakan untuk melatih Pengklasifikasi Naive Bayes harus dimuat ke dalam Pandas DataFrame. 4 variabel bebas harus ditetapkan ke variabel X dan variabel spesies keluaran akhir ditetapkan ke y.
dataset = pd.read_csv(' https://raw.githubusercontent.com/mk-gurucharan/Classification/master/IrisDataset.csv' )X = dataset.iloc[:,:4].values
y = dataset['species'].valuesdataset.head(5)>>
sepal_length sepal_width petal_length petal_width spesies
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
4.7 3.2 1.3 0.2 setosa
4.6 3.1 1.5 0.2 setosa
5.0 3.6 1.4 0.2 setosa
Langkah 3 – Memisahkan dataset menjadi Training set dan Test set
Setelah memuat dataset dan variabel, langkah selanjutnya adalah menyiapkan variabel yang akan menjalani proses pelatihan. Pada langkah ini, kita harus membagi variabel X dan y menjadi dataset pelatihan dan pengujian. Untuk ini, kami akan menetapkan 80% data secara acak ke set pelatihan yang akan digunakan untuk tujuan pelatihan dan 20% sisanya sebagai set pengujian di mana Naive Bayes Classifier yang terlatih harus diuji akurasinya.
dari sklearn.model_selection impor train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0,2)
Langkah 4 – Penskalaan Fitur
Meskipun ini adalah proses tambahan untuk kumpulan data kecil ini, saya menambahkan ini agar Anda dapat menggunakannya dalam kumpulan data yang lebih besar. Dalam hal ini, data dalam set pelatihan dan pengujian diperkecil ke kisaran nilai antara 0 dan 1. Hal ini mengurangi biaya komputasi.
dari sklearn.preprocessing impor StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Langkah 5 – Melatih model Klasifikasi Naive Bayes pada Set Pelatihan
Pada langkah ini kita mengimpor kelas Naive Bayes dari perpustakaan sklearn. Untuk model ini kita menggunakan model Gaussian, ada beberapa model lain seperti Bernoulli, Categorical dan Multinomial. Dengan demikian, X_train dan y_train dipasang ke variabel classifier untuk tujuan pelatihan.
dari sklearn.naive_bayes impor GaussianNB
pengklasifikasi = GaussianNB()
classifier.fit(X_train, y_train)
Langkah 6 – Memprediksi hasil set Tes –
Kami memprediksi kelas spesies untuk set Uji menggunakan model yang dilatih dan membandingkannya dengan Nilai Nyata dari kelas spesies.
y_pred = classifier.predict(X_test)
df = pd.DataFrame({'Nilai Nyata':y_test, 'Nilai Prediksi':y_pred})
df>>
Nilai Nyata Nilai Prediksi
setosa setosa
setosa setosa
virginica virginica
versikolor versikolor
setosa setosa
setosa setosa
… … … … …
virginica versikolor
virginica virginica
setosa setosa
setosa setosa
versikolor versikolor
versikolor versikolor
Dalam perbandingan di atas, kita melihat bahwa ada satu prediksi yang salah yang memprediksi Versicolor bukan virginica.
Langkah 7 – Matriks Kebingungan dan Akurasi
Saat kita berurusan dengan Klasifikasi, cara terbaik untuk mengevaluasi model pengklasifikasi kami adalah dengan mencetak Matriks Kebingungan beserta akurasinya pada set pengujian.
dari sklearn.metrics mengimpor kebingungan_matrix
cm = confusion_matrix(y_test, y_pred)dari sklearn.metrics mengimpor akurasi_score
print (“Akurasi : “, akurasi_score(y_test, y_pred))
cm>>Akurasi : 0.966666666666666667
>>array([[14, 0, 0],
[ 0, 7, 0],
[ 0, 1, 8]])
Kesimpulan
Jadi, dalam artikel ini, kita telah membahas dasar-dasar Algoritma Naive Bayes, memahami matematika di balik Klasifikasi bersama dengan contoh yang diselesaikan dengan tangan. Terakhir, kami menerapkan kode Machine Learning untuk memecahkan kumpulan data populer menggunakan algoritma Klasifikasi Naive Bayes.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang AI, pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, Status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Bagaimana kemungkinan membantu dalam Machine Learning?
Kita mungkin harus membuat keputusan berdasarkan informasi sebagian atau tidak lengkap dalam skenario dunia nyata. Probabilitas membantu kami mengukur ketidakpastian dalam sistem tersebut dan mengelola risiko untuk tugas tersebut. Metode tradisional hanya bekerja untuk hasil deterministik untuk tindakan tertentu, tetapi selalu ada beberapa ruang lingkup ketidakpastian dalam model prediksi apa pun. Ketidakpastian ini dapat berasal dari banyak parameter dari input data, seperti Noise pada data. Juga, pandangan bayesian dari teorema probabilitas dapat membantu pengenalan pola dari data input. Untuk ini, probabilitas menggunakan konsep estimasi kemungkinan maksimum dan karenanya sangat membantu untuk menghasilkan hasil yang relevan.
Apa gunanya Matriks Kebingungan?
Confusion matrix adalah matriks 2x2 yang digunakan untuk menginterpretasikan performansi model klasifikasi. Nilai sebenarnya untuk data input harus diketahui agar ini berfungsi, sehingga tidak dapat direpresentasikan untuk data yang tidak berlabel. Ini terdiri dari jumlah positif palsu (FP), positif benar (TP), negatif palsu (FN), dan negatif benar (TN). Prediksi diklasifikasikan ke dalam kelas-kelas ini menggunakan hitungan dari set pelatihan dan set tes. Ini membantu kita memvisualisasikan parameter yang berguna seperti akurasi, presisi, recall, dan spesifisitas. Ini relatif mudah dipahami dan memberi Anda gambaran yang jelas tentang algoritme.
Apa saja jenis model Naive Bayes yang berbeda?
Semua jenis terutama didasarkan pada Teorema Bayes. Model Naive Bayes umumnya memiliki tiga jenis: Gaussian, Bernoulli, dan Multinomial. Gaussian Naive Bayes membantu dengan nilai kontinu dari parameter input, dan memiliki asumsi bahwa semua kelas data input terdistribusi secara seragam. Naive Bayes Bernoulli adalah model berbasis peristiwa di mana fitur data independen dan hadir dalam nilai boolean. Multinomial Naive Bayes juga didasarkan pada model berbasis peristiwa. Ini memiliki fitur data dalam bentuk vektor, yang mewakili frekuensi yang relevan berdasarkan terjadinya peristiwa.