
7 Algoritma Pembelajaran Mesin yang Paling Banyak Digunakan di Python Yang Harus Anda Ketahui
Diterbitkan: 2021-03-04Machine Learning adalah cabang dari Artificial Intelligence (AI) yang berhubungan dengan algoritma komputer yang digunakan pada data apa pun. Ini berfokus pada pembelajaran otomatis dari data yang dimasukkan ke dalamnya dan memberi kami hasil dengan meningkatkan prediksi sebelumnya setiap saat.
Daftar isi
Algoritma Pembelajaran Mesin Teratas yang Digunakan dengan Python
Di bawah ini adalah beberapa algoritme pembelajaran mesin teratas yang digunakan dalam Python, bersama dengan cuplikan kode yang menunjukkan implementasi dan visualisasi batas klasifikasi.
1. Regresi Linier
Regresi linier adalah salah satu teknik pembelajaran mesin terawasi yang paling umum digunakan. Seperti namanya, regresi ini mencoba memodelkan hubungan antara dua variabel menggunakan persamaan linier dan menyesuaikan garis tersebut dengan data yang diamati. Teknik ini digunakan untuk memperkirakan nilai kontinu yang nyata seperti total penjualan yang dilakukan, atau biaya rumah.
Garis yang paling cocok disebut juga garis regresi. Ini diberikan oleh persamaan berikut:
Y = a*X + b
di mana Y adalah variabel terikat, a adalah kemiringan, X adalah variabel bebas dan b adalah nilai intersep. Koefisien a dan b diturunkan dengan meminimalkan kuadrat dari perbedaan jarak antara berbagai titik data dan persamaan garis regresi.

# kumpulan data sintetis untuk regresi sederhana
dari sklearn.datasets impor make_regression
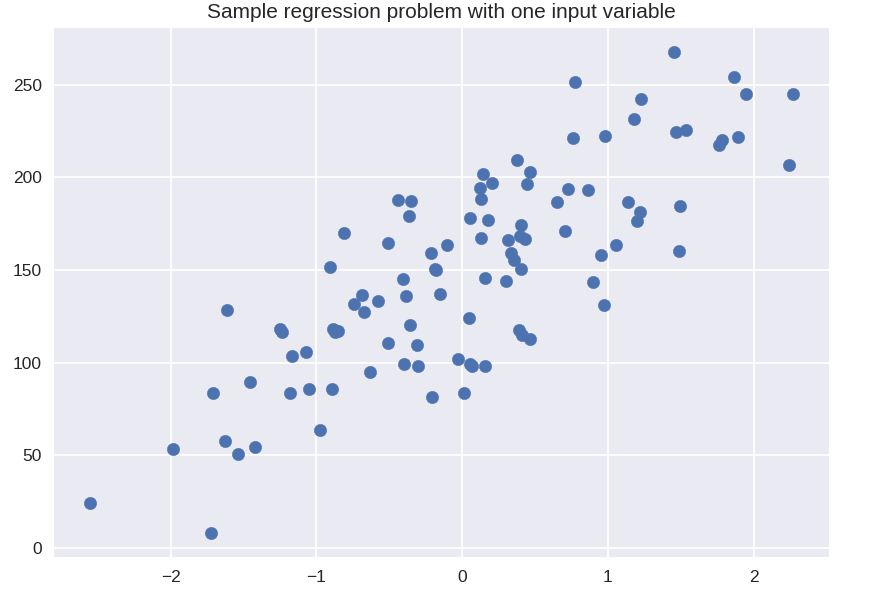
plt.figur()
plt.title( 'Contoh masalah regresi dengan satu variabel input' )
X_R1, y_R1 = make_regression( n_samples = 100, n_features = 1, n_informative = 1, bias = 150.0, noise = 30, random_state = 0 )
plt.scatter( X_R1, y_R1, penanda = 'o', s = 50 )
plt.tampilkan()
dari sklearn.linear_model impor LinearRegression
X_train, X_test, y_train, y_test = train_test_split( X_R1, y_R1,
random_state = 0 )
linreg = LinearRegression().fit( X_train, y_train )
print( 'koeff model linier (w): {}'.format( linreg.coef_ ) )
print( 'intersep model linier (b): {:.3f}'z.format( linreg.intercept_ ) )
print( 'R-kuadrat skor (pelatihan): {:.3f}'.format( linreg.score( X_train, y_train ) ) )
print( 'R-kuadrat skor (tes): {:.3f}'.format( linreg.score( X_test, y_test ) ) )
Keluaran
koefisien model linier (w): [ 45.71]
intersep model linier (b): 148.446
Skor R-kuadrat (pelatihan): 0,679
Skor R-kuadrat (tes): 0,492
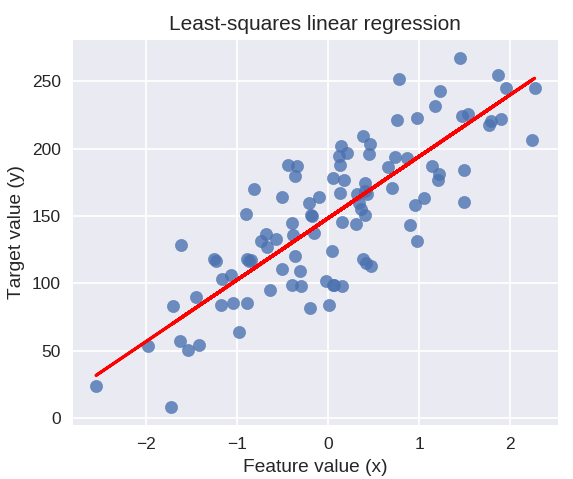
Kode berikut akan menggambar garis regresi yang dipasang pada plot titik data kami.
plt.figure( ukuran gambar = ( 5, 4 ) )
plt.scatter( X_R1, y_R1, penanda = 'o', s = 50, alpha = 0.8 )
plt.plot( X_R1, linreg.coef_ * X_R1 + linreg.intercept_, 'r-' )
plt.title( 'Regresi linier kuadrat terkecil' )
plt.xlabel( 'Nilai fitur (x)')
plt.ylabel( 'Nilai target (y)' )
plt.tampilkan()
Mempersiapkan Kumpulan Data Umum Untuk Menjelajahi Teknik Klasifikasi
Data berikut akan digunakan untuk menunjukkan berbagai algoritma klasifikasi yang paling umum digunakan dalam pembelajaran mesin dengan Python.
Kumpulan Data Jamur UCI disimpan di jamur.csv.
%matplotlib buku catatan
impor panda sebagai pd
impor numpy sebagai np
impor matplotlib.pyplot sebagai plt
dari sklearn.decomposition impor PCA
dari sklearn.model_selection impor train_test_split
df = pd.read_csv( 'readonly/jamur.csv' )
df2 = pd.get_dummies( df )
df3 = df2.sampel( frac = 0,08 )
X = df3.iloc[:, 2:]
y = df3.iloc[:, 1]
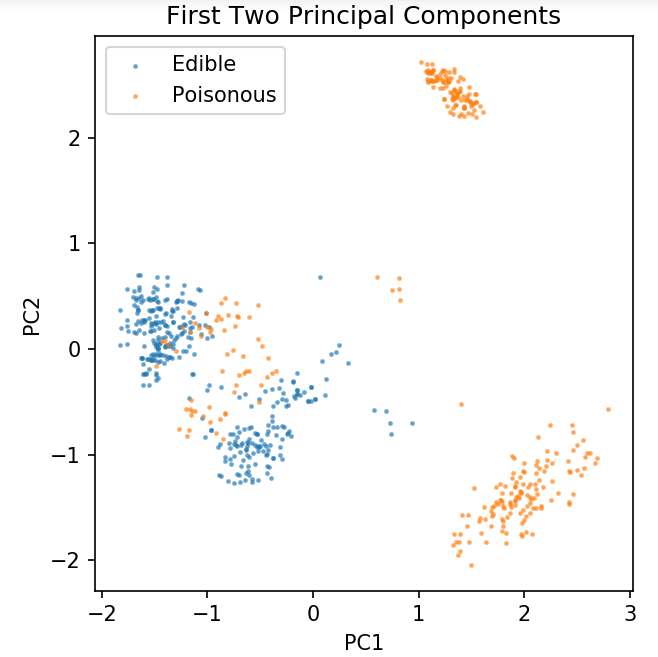
pca = PCA( n_komponen = 2 ).fit_transform( X )
X_train, X_test, y_train, y_test = train_test_split( pca, y, random_state = 0 )
plt.angka( dpi = 120 )
plt.scatter( pca[y.values == 0, 0], pca[y.values == 0, 1], alpha = 0.5, label = 'Dapat dimakan', s = 2 )
plt.scatter( pca[y.values == 1, 0], pca[y.values == 1, 1], alpha = 0.5, label = 'Beracun', s = 2 )
plt.legenda()
plt.title( 'Kumpulan Data Jamur\nDua Komponen Utama Pertama' )
plt.xlabel( 'PC1' )
plt.ylabel( 'PC2' )
plt.gca().set_aspect( 'sama' )
Kami akan menggunakan fungsi yang didefinisikan di bawah ini untuk mendapatkan batasan keputusan dari pengklasifikasi berbeda yang akan kami gunakan pada dataset jamur.
def plot_mushroom_boundary( X, y, fit_model ):
plt.figure( ukuran gambar = (9.8, 5), dpi = 100 )
untuk saya, plot_type di enumerate( ['Decision Boundary', 'Decision Probabilities'] ):
plt.subplot( 1, 2, i + 1 )
mesh_step_size = 0,01 # ukuran langkah di mesh
x_min, x_max = X[:, 0].min() – .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() – .1, X[:, 1].max() + .1
xx, yy = np.meshgrid( np.arange( x_min, x_max, mesh_step_size ), np.arange( y_min, y_max, mesh_step_size ) )
jika saya == 0:
Z = fit_model.predict( np.c_[xx.ravel(), yy.ravel()] )
lain:
mencoba:
Z = fit_model.predict_proba( np.c_[xx.ravel(), yy.ravel()] )[:, 1]
kecuali:
plt.text( 0.4, 0.5, 'Probabilities Unavailable', horizontalalignment = 'center', verticalalignment = 'center', transform = plt.gca().transAxes, fontsize = 12 )
plt.axis( 'mati' )
merusak
Z = Z.bentuk ulang( xx.bentuk )
plt.scatter( X[y.values == 0, 0], X[y.values == 0, 1], alpha = 0.4, label = 'Dapat dimakan', s = 5 )
plt.scatter( X[y.values == 1, 0], X[y.values == 1, 1], alpha = 0.4, label = 'Posionous', s = 5 )
plt.imshow( Z, interpolasi = 'terdekat', cmap = 'RdYlBu_r', alpha = 0,15, luas = ( x_min, x_max, y_min, y_max ), asal = 'lebih rendah' )
plt.title( plot_type + '\n' + str( fit_model ).split( '(' )[0] + ' Uji Akurasi: ' + str( np.round( fit_model.score( X, y ), 5 ) ) )
plt.gca().set_aspect( 'sama' );
plt.tight_layout()
plt.subplots_adjust( atas = 0,9, bawah = 0,08, wspasi = 0,02)
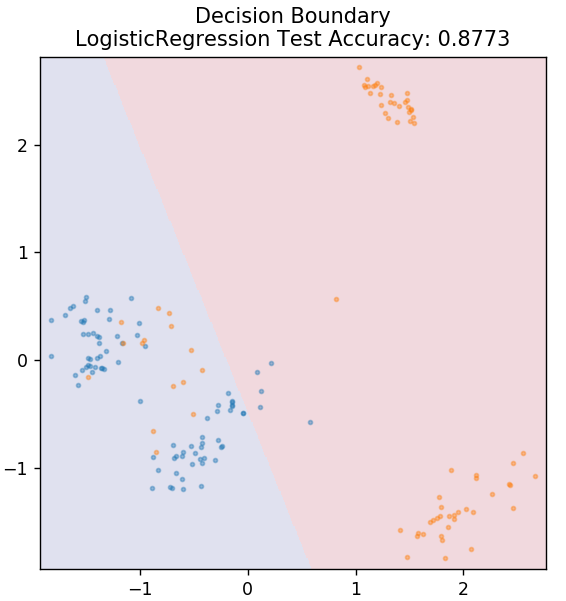
2. Regresi Logistik
Tidak seperti regresi linier, regresi logistik berkaitan dengan estimasi nilai diskrit (nilai biner (0/1, benar/salah, ya/tidak). Teknik ini juga disebut regresi logit. Ini karena memprediksi probabilitas suatu peristiwa dengan menggunakan fungsi logit untuk melatih data yang diberikan. Nilainya selalu terletak antara 0 dan 1 (karena menghitung probabilitas).
Odds log dari hasil dibangun sebagai kombinasi linier dari variabel prediktor sebagai berikut:
peluang = p / (1 – p) = peluang terjadinya peristiwa atau peluang tidak terjadinya peristiwa
ln( peluang ) = ln( p / (1 – p) )
logit( p ) = ln( p / (1 – p) ) = b0 + b1X1 + b2X2 + b3X3 + … + bkXk
di mana p adalah probabilitas kehadiran suatu karakteristik.
dari sklearn.linear_model impor LogisticRegression
model = LogistikRegresi()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
Dapatkan sertifikasi kecerdasan buatan secara online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
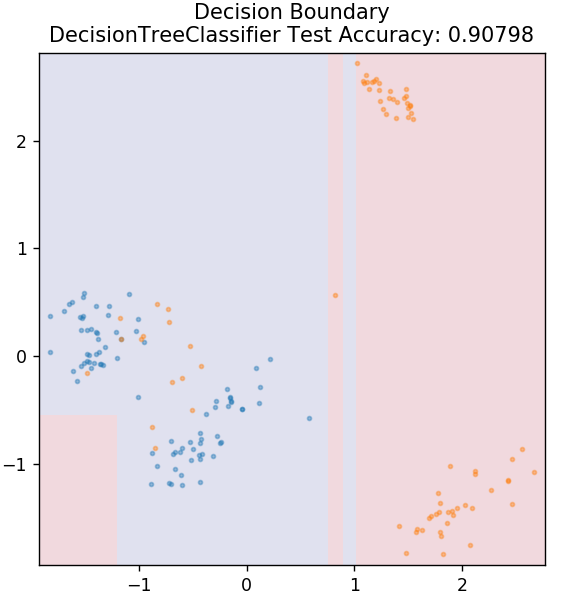
3. Pohon Keputusan
Ini adalah algoritma yang sangat populer yang dapat digunakan untuk mengklasifikasikan variabel data kontinu dan diskrit. Pada setiap langkah, data dipecah menjadi lebih dari satu set homogen berdasarkan beberapa atribut/kondisi yang memisahkan.

dari sklearn.tree impor DecisionTreeClassifier
model = DecisionTreeClassifier( max_depth = 3 )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
4. SVM
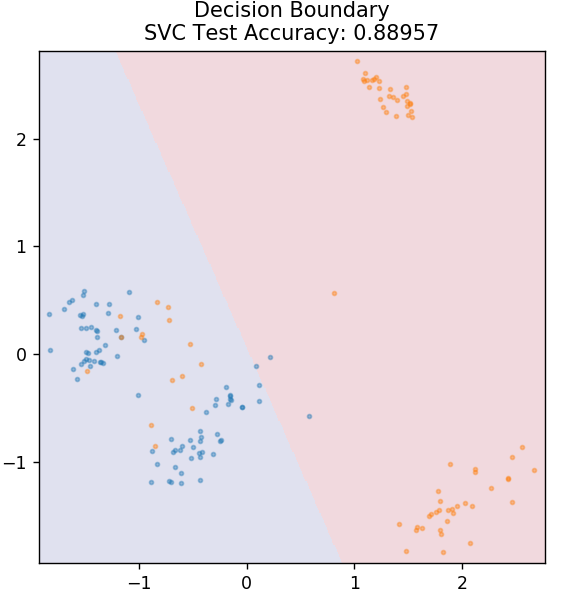
SVM adalah kependekan dari Support Vector Machines. Di sini ide dasarnya adalah mengklasifikasikan titik data dengan menggunakan hyperplanes untuk pemisahan. Tujuannya adalah untuk menemukan hyperplane yang memiliki jarak (atau margin) maksimum antara titik-titik data baik kelas atau kategori.
Kami memilih pesawat sedemikian rupa untuk menjaga klasifikasi titik yang tidak diketahui di masa depan dengan keyakinan tertinggi. SVM terkenal digunakan karena memberikan akurasi tinggi sambil menggunakan daya komputasi yang sangat sedikit. SVM juga dapat digunakan untuk masalah regresi.
dari sklearn.svm impor SVC
model = SVC( kernel = 'linier' )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
Checkout: Proyek Python di GitHub
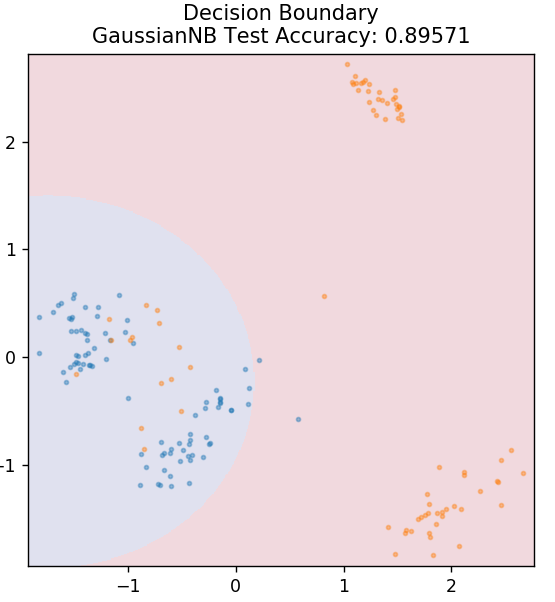
5. Naif Bayes
Seperti namanya, algoritma Naive Bayes adalah algoritma pembelajaran terawasi berdasarkan Teorema Bayes . Teorema Bayes menggunakan probabilitas bersyarat untuk memberi Anda probabilitas suatu peristiwa berdasarkan beberapa pengetahuan yang diberikan.
Di mana, 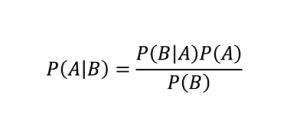
P (A | B): Probabilitas bersyarat bahwa peristiwa A terjadi, mengingat peristiwa B telah terjadi. (Juga disebut probabilitas posterior)
P(A): Peluang kejadian A.
P(B): Peluang kejadian B.
P (B | A): Probabilitas bersyarat bahwa peristiwa B terjadi, mengingat peristiwa A telah terjadi.
Mengapa algoritma ini bernama Naive, Anda bertanya? Ini karena mengasumsikan bahwa semua kejadian peristiwa independen satu sama lain. Jadi setiap fitur secara terpisah mendefinisikan kelas tempat titik data berada, tanpa memiliki ketergantungan di antara mereka sendiri. Naive Bayes adalah pilihan terbaik untuk kategorisasi teks. Ini akan bekerja cukup baik bahkan dengan sejumlah kecil data pelatihan.
dari sklearn.naive_bayes impor GaussianNB
model = GaussianNB()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
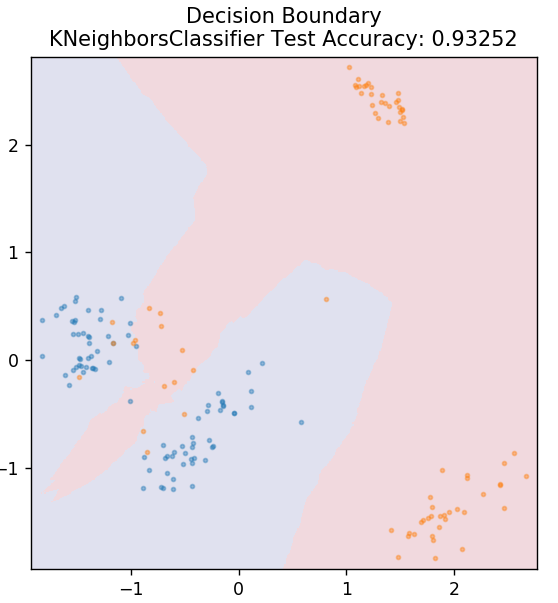
5. KNN
KNN adalah singkatan dari K-Nearest Neighbours. Ini adalah algoritma pembelajaran terawasi yang sangat luas digunakan yang mengklasifikasikan data uji sesuai dengan kesamaannya dengan data pelatihan yang diklasifikasikan sebelumnya. KNN tidak mengklasifikasikan semua titik data selama pelatihan. Sebagai gantinya, itu hanya menyimpan kumpulan data dan ketika mendapat data baru, itu kemudian mengklasifikasikan titik data tersebut berdasarkan kesamaannya. Ia melakukannya dengan menghitung jarak Euclidean dari jumlah K tetangga terdekat (di sini, n_neighbors ) dari titik data tersebut.
dari sklearn.neighbors impor KNeighborsClassifier
model = KNeighborsClassifier( n_neighbors = 20 )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
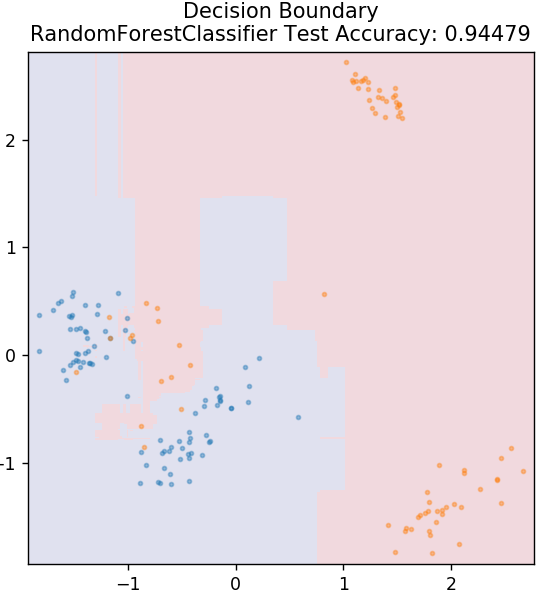
6. Hutan Acak
Hutan acak adalah algoritma pembelajaran mesin yang sangat sederhana dan beragam yang menggunakan teknik pembelajaran terawasi. Seperti yang bisa Anda tebak dari namanya, hutan acak terdiri dari sejumlah besar pohon keputusan, bertindak sebagai ansambel. Setiap pohon keputusan akan menentukan kelas keluaran dari titik data dan kelas mayoritas akan dipilih sebagai keluaran akhir model. Idenya di sini adalah bahwa lebih banyak pohon yang mengerjakan data yang sama akan cenderung lebih akurat dalam hasil daripada pohon individu.
dari sklearn.ensemble impor RandomForestClassifier
model = RandomForestClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
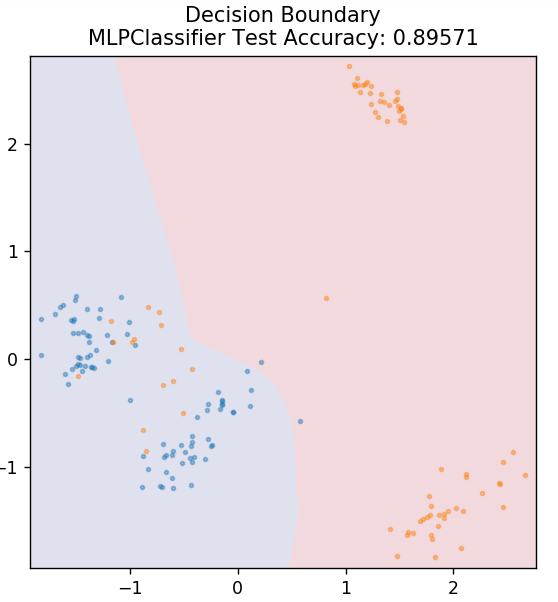
7. Perceptron Multi-Lapisan
Multi-Layer Perceptron (atau MLP) adalah algoritma yang sangat menarik yang berada di bawah cabang pembelajaran mendalam. Lebih khusus lagi, itu milik kelas jaringan saraf tiruan feed-forward (ANN). MLP membentuk jaringan beberapa perceptron dengan setidaknya tiga lapisan: lapisan input, lapisan output dan lapisan tersembunyi. MLP mampu membedakan antara data yang tidak dapat dipisahkan secara linier.
Setiap neuron di lapisan tersembunyi menggunakan fungsi aktivasi untuk melanjutkan ke lapisan berikutnya. Di sini, algoritma backpropagation digunakan untuk benar-benar menyetel parameter dan karenanya melatih jaringan saraf. Ini sebagian besar dapat digunakan untuk masalah regresi sederhana.
dari sklearn.neural_network impor MLPClassifier
model = MLPClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
Baca Juga: Ide & Topik Proyek Python
Kesimpulan
Kita dapat menyimpulkan bahwa algoritma pembelajaran mesin yang berbeda menghasilkan batas keputusan yang berbeda dan karenanya akurasi yang berbeda menghasilkan klasifikasi dataset yang sama.
Tidak ada cara untuk mendeklarasikan algoritma siapa pun sebagai algoritma terbaik untuk semua jenis data secara umum. Pembelajaran mesin memerlukan percobaan dan kesalahan yang ketat untuk berbagai algoritme guna menentukan apa yang terbaik untuk setiap kumpulan data secara terpisah. Daftar algoritme ML jelas tidak berakhir di sini. Ada banyak sekali teknik lain yang menunggu untuk dijelajahi di perpustakaan Scikit-Learn Python. Silakan dan latih kumpulan data Anda menggunakan semua itu dan bersenang-senanglah!
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pohon keputusan, pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa asumsi utama dari regresi linier?
Ada 4 asumsi penting untuk regresi linier: linieritas, homoskedastisitas, independensi, dan Normalitas. Linieritas berarti bahwa hubungan antara variabel bebas (X) dan rata-rata variabel terikat (Y) dianggap linier ketika kita menggunakan regresi linier. Homoskedastisitas berarti bahwa varians kesalahan titik-titik sisa grafik dianggap konstan. Independensi mengacu pada semua pengamatan dari data input yang dianggap independen satu sama lain. Normalitas berarti bahwa distribusi data input dapat seragam atau tidak seragam, tetapi dianggap terdistribusi seragam dalam kasus regresi linier.
Apa perbedaan antara pohon Keputusan dan Hutan Acak?
Pohon keputusan mengimplementasikan proses pengambilan keputusannya, menggunakan struktur seperti pohon yang mewakili kemungkinan hasil untuk tindakan tertentu. Hutan acak menggunakan bundel pohon keputusan tersebut untuk menganalisis data. Dengan proses ini, lebih banyak data akan digunakan oleh hutan Acak, tetapi membantu mencegah overfitting dan memberikan hasil yang akurat. Ada ruang lingkup overfitting dalam algoritma pohon keputusan dan dapat memberikan hasil yang kurang akurat. Pohon keputusan mudah diinterpretasikan karena memerlukan lebih sedikit perhitungan, sedangkan hutan acak sulit untuk diinterpretasikan karena analisisnya yang kompleks.
Apa saja pustaka standar yang digunakan untuk algoritma pembelajaran mesin dengan Python?
Python telah menggantikan hampir semua bahasa lain dalam pembelajaran mesin karena ketersediaan sejumlah besar perpustakaan dan aturan sintaks yang mudah. Ada banyak pustaka Python untuk pembelajaran mesin seperti Numpy, Scipy, Scikit-learn, Theono, TensorFlow, PyTorch, Matplotlib, Keras, Pandas, dll. Menggunakan fungsi dari pustaka ini menghemat banyak waktu untuk menulis algoritme untuk setiap tugas; prosesnya lebih sedikit memakan waktu dan memberikan hasil yang efisien. Pustaka ini memiliki aplikasi seperti pemrosesan matriks, masalah optimisasi, penambangan data, analisis statistik, komputasi yang melibatkan tensor, deteksi objek, jaringan saraf, dan banyak lagi.