
Mencampur Tangible Dan Intangible: Merancang Antarmuka Multimodal Menggunakan Adobe XD
Diterbitkan: 2022-03-10(Artikel ini disponsori oleh Adobe.) Antarmuka pengguna terus berkembang. Antarmuka yang diaktifkan suara menantang dominasi lama antarmuka pengguna grafis dan dengan cepat menjadi bagian umum dari kehidupan kita sehari-hari. Kemajuan signifikan dalam pengenalan ucapan otomatis (APS) dan pemrosesan bahasa alami (NLP), bersama dengan basis konsumen yang mengesankan (jutaan perangkat seluler dengan asisten suara bawaan), telah memengaruhi perkembangan pesat dan adopsi antarmuka berbasis suara.
Produk yang menggunakan suara sebagai antarmuka utama menjadi semakin populer. Di AS saja, 47,3 juta orang dewasa memiliki akses ke speaker pintar (itu seperlima dari populasi orang dewasa AS), dan jumlahnya terus bertambah. Tetapi antarmuka suara memiliki masa depan yang cerah tidak hanya untuk penggunaan pribadi dan di rumah. Ketika orang menjadi terbiasa dengan antarmuka suara, mereka akan mengharapkannya dalam konteks bisnis juga. Bayangkan saja Anda akan segera dapat menyalakan proyektor ruang konferensi dengan mengatakan sesuatu seperti, "Tampilkan presentasi saya".
Jelas bahwa komunikasi manusia-mesin berkembang pesat mencakup interaksi tertulis dan lisan. Tetapi apakah itu berarti bahwa antarmuka masa depan hanya akan menggunakan suara? Terlepas dari beberapa penggambaran fiksi ilmiah, suara tidak akan sepenuhnya menggantikan antarmuka pengguna grafis. Sebagai gantinya, kami akan memiliki sinergi suara, visual, dan gerakan dalam format antarmuka baru: antarmuka multimodal yang diaktifkan dengan suara.
Dalam artikel ini, kami akan:
- jelajahi konsep antarmuka berkemampuan suara dan tinjau berbagai jenis antarmuka berkemampuan suara;
- cari tahu mengapa antarmuka pengguna multimodal yang diaktifkan dengan suara akan menjadi pengalaman pengguna yang disukai;
- lihat bagaimana Anda dapat membangun UI multimodal menggunakan Adobe XD.
Keadaan Antarmuka Pengguna Suara (VUI)
Sebelum masuk ke detail antarmuka pengguna suara, kita harus mendefinisikan apa itu input suara. Input suara adalah interaksi manusia-komputer di mana pengguna mengucapkan perintah alih-alih menulisnya. Keindahan input suara adalah interaksi yang lebih alami bagi orang-orang — pengguna tidak dibatasi pada sintaks tertentu saat berinteraksi dengan sistem; mereka dapat menyusun masukan mereka dengan berbagai cara, seperti yang mereka lakukan dalam percakapan manusia.
Antarmuka pengguna suara memberikan manfaat berikut bagi penggunanya:
- Lebih sedikit biaya interaksi
Meskipun menggunakan antarmuka yang diaktifkan suara memang melibatkan biaya interaksi, biaya ini lebih kecil (secara teori) daripada mempelajari GUI baru. - Kontrol bebas genggam
VUI sangat bagus saat tangan pengguna sibuk — misalnya, saat mengemudi, memasak, atau berolahraga. - Kecepatan
Suara sangat bagus saat mengajukan pertanyaan lebih cepat daripada mengetik dan membaca hasilnya. Misalnya, saat menggunakan suara di dalam mobil, lebih cepat mengucapkan tempat ke sistem navigasi, daripada mengetik lokasi di layar sentuh. - Emosi dan kepribadian
Bahkan ketika kita mendengar suara tetapi tidak melihat gambar pembicara, kita dapat membayangkan pembicara di kepala kita. Ini memiliki peluang untuk meningkatkan keterlibatan pengguna. - Aksesibilitas
Pengguna tunanetra dan pengguna dengan gangguan mobilitas dapat menggunakan suara untuk berinteraksi dengan sistem.
Tiga Jenis Antarmuka Berkemampuan Suara
Tergantung pada bagaimana suara digunakan, itu bisa menjadi salah satu dari jenis antarmuka berikut.
Agen Suara Di Perangkat Pertama Layar
Apple Siri dan Google Assistant adalah contoh utama agen suara. Untuk sistem seperti itu, suara bertindak lebih seperti peningkatan untuk GUI yang ada. Dalam banyak kasus, agen bertindak sebagai langkah pertama dalam perjalanan pengguna: Pengguna memicu agen suara dan memberikan perintah melalui suara, sementara semua interaksi lainnya dilakukan menggunakan layar sentuh. Misalnya, saat Anda mengajukan pertanyaan kepada Siri, itu akan memberikan jawaban dalam format daftar, dan Anda perlu berinteraksi dengan daftar itu. Akibatnya, pengalaman pengguna menjadi terfragmentasi — kami menggunakan suara untuk memulai interaksi dan kemudian beralih ke sentuhan untuk melanjutkannya.
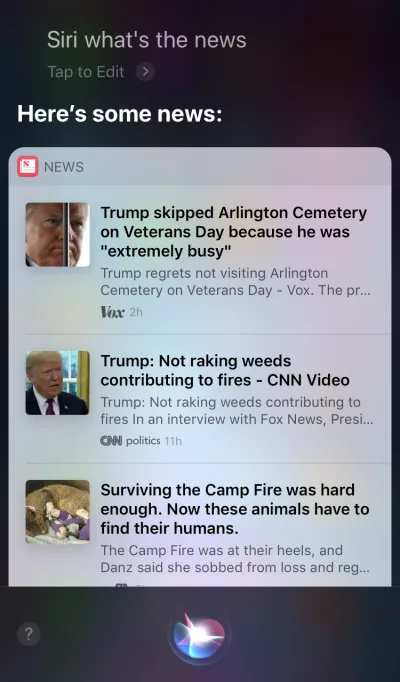
Perangkat Hanya Suara
Perangkat ini tidak memiliki tampilan visual; pengguna mengandalkan audio untuk input dan output. Speaker pintar Amazon Echo dan Google Home adalah contoh utama produk dalam kategori ini. Kurangnya tampilan visual merupakan kendala signifikan pada kemampuan perangkat untuk mengkomunikasikan informasi dan pilihan kepada pengguna. Akibatnya, kebanyakan orang menggunakan perangkat ini untuk menyelesaikan tugas-tugas sederhana, seperti memutar musik dan mendapatkan jawaban atas pertanyaan sederhana.

Perangkat Suara-Pertama
Dengan sistem suara-pertama, perangkat menerima input pengguna terutama melalui perintah suara, tetapi juga memiliki tampilan layar terintegrasi. Ini berarti bahwa suara adalah antarmuka pengguna utama, tetapi bukan satu-satunya. Pepatah lama, "Sebuah gambar bernilai seribu kata" masih berlaku untuk sistem berkemampuan suara modern. Otak manusia memiliki kemampuan pemrosesan gambar yang luar biasa — kita dapat memahami informasi yang kompleks lebih cepat ketika kita melihatnya secara visual. Dibandingkan dengan perangkat yang hanya menggunakan suara, perangkat yang mengutamakan suara memungkinkan pengguna untuk mengakses informasi dalam jumlah yang lebih besar dan membuat banyak tugas menjadi lebih mudah.
Amazon Echo Show adalah contoh utama perangkat yang menggunakan sistem yang mengutamakan suara. Informasi visual secara bertahap digabungkan sebagai bagian dari sistem holistik — layar tidak dimuat dengan ikon aplikasi; sebaliknya, sistem mendorong pengguna untuk mencoba perintah suara yang berbeda (menyarankan perintah verbal seperti, "Coba 'Alexa, tunjukkan cuaca pada 5:00 sore'"). Layar bahkan membuat tugas-tugas umum seperti memeriksa resep saat memasak jauh lebih mudah — pengguna tidak perlu mendengarkan dengan seksama dan menyimpan semua informasi di kepala mereka; ketika mereka membutuhkan informasi, mereka hanya melihat layar.

Memperkenalkan Antarmuka Multimodal
Saat menggunakan suara dalam desain UI, jangan menganggap suara sebagai sesuatu yang dapat Anda gunakan sendiri. Perangkat seperti Amazon Echo Show menyertakan layar tetapi menggunakan suara sebagai metode input utama, membuat pengalaman pengguna yang lebih holistik. Ini adalah langkah pertama menuju generasi baru antarmuka pengguna: antarmuka multimodal.
Antarmuka multimodal adalah antarmuka yang memadukan suara, sentuhan, audio, dan berbagai jenis visual dalam satu UI yang mulus. Amazon Echo Show adalah contoh luar biasa dari perangkat yang memanfaatkan sepenuhnya antarmuka multimodal berkemampuan suara. Saat pengguna berinteraksi dengan Tampilkan, mereka membuat permintaan seperti yang mereka lakukan dengan perangkat suara saja; namun, respons yang mereka terima kemungkinan akan multimodal, berisi respons suara dan visual.
Produk multimodal lebih kompleks daripada produk yang hanya mengandalkan visual atau hanya suara. Mengapa seseorang harus membuat antarmuka multimodal sejak awal? Untuk menjawab pertanyaan itu, kita perlu melangkah mundur dan melihat bagaimana orang memandang lingkungan di sekitar mereka. Orang-orang memiliki panca indera, dan kombinasi dari indera kita yang bekerja bersama adalah cara kita memandang sesuatu. Misalnya, indera kita bekerja sama ketika kita mendengarkan musik di konser live. Hilangkan satu indera (misalnya, pendengaran), dan pengalaman mengambil konteks yang sama sekali berbeda.

Sudah terlalu lama, kami memikirkan pengalaman pengguna sebagai desain visual atau gestural secara eksklusif. Saatnya untuk mengubah pemikiran ini. Desain multimodal adalah cara untuk memikirkan dan merancang pengalaman yang menghubungkan kemampuan sensorik kita bersama.
Antarmuka multimodal terasa seperti cara yang lebih manusiawi bagi pengguna dan mesin untuk berkomunikasi. Mereka membuka peluang baru untuk interaksi yang lebih dalam. Dan hari ini, jauh lebih mudah untuk merancang antarmuka multimodal karena batasan teknis yang di masa lalu membatasi interaksi dengan produk sedang dihapus.
Perbedaan Antara GUI dan Antarmuka Multimodal
Perbedaan utama di sini adalah bahwa antarmuka multimodal seperti Amazon Echo Show menyinkronkan antarmuka suara dan visual. Akibatnya, saat kami mendesain pengalaman, suara dan visual tidak lagi menjadi bagian yang independen; mereka adalah bagian integral dari pengalaman yang disediakan sistem.
Saluran Visual Dan Suara: Kapan Menggunakan Masing-masing
Penting untuk memikirkan suara dan visual sebagai saluran untuk input dan output. Setiap saluran memiliki kekuatan dan kelemahannya sendiri.
Mari kita mulai dengan visualnya. Jelas bahwa beberapa informasi lebih mudah dipahami ketika kita melihatnya, daripada ketika kita mendengarnya. Visual bekerja lebih baik saat Anda perlu menyediakan:
- daftar pilihan yang panjang (membaca daftar yang panjang akan memakan banyak waktu dan sulit untuk diikuti);
- informasi data-berat (seperti diagram dan grafik);
- informasi produk (misalnya, produk di toko online; kemungkinan besar, Anda ingin melihat produk sebelum membeli) dan perbandingan produk (seperti halnya daftar pilihan yang panjang, akan sulit untuk memberikan semua informasi hanya dengan menggunakan suara) .
Untuk beberapa informasi, bagaimanapun, kita dapat dengan mudah mengandalkan komunikasi verbal. Suara mungkin cocok untuk kasus berikut:
- perintah pengguna (suara adalah modalitas input yang efisien, memungkinkan pengguna untuk memberikan perintah ke sistem dengan cepat dan melewati menu navigasi yang rumit);
- instruksi pengguna yang sederhana (misalnya, pemeriksaan rutin pada resep);
- peringatan dan pemberitahuan (misalnya, peringatan audio yang dipasangkan dengan pemberitahuan suara selama mengemudi).
Meskipun ini adalah beberapa kasus khas gabungan visual dan suara, penting untuk diketahui bahwa kita tidak dapat memisahkan keduanya satu sama lain. Kami dapat menciptakan pengalaman pengguna yang lebih baik hanya jika suara dan visual bekerja sama. Misalnya, kita ingin membeli sepasang sepatu baru. Kita bisa menggunakan suara untuk meminta dari sistem, "Tunjukkan sepatu New Balance." Sistem akan memproses permintaan Anda dan memberikan informasi produk secara visual (cara yang lebih mudah bagi kami untuk membandingkan sepatu).
Apa yang Perlu Anda Ketahui Untuk Mendesain Antarmuka Multimodal yang Diaktifkan dengan Suara
Suara adalah salah satu tantangan paling menarik bagi desainer UX. Terlepas dari kebaruannya, aturan dasar untuk merancang antarmuka multimodal yang mendukung suara adalah sama dengan yang kami gunakan untuk membuat desain visual. Desainer harus peduli dengan penggunanya. Mereka harus bertujuan untuk mengurangi gesekan bagi pengguna dengan memecahkan masalah mereka dengan cara yang efisien dan memprioritaskan kejelasan untuk membuat pilihan pengguna menjadi jelas.
Tetapi ada beberapa prinsip desain unik untuk antarmuka multimodal juga.
Pastikan Anda Memecahkan Masalah yang Tepat
Desain harus memecahkan masalah. Tapi sangat penting untuk memecahkan masalah yang tepat; jika tidak, Anda dapat menghabiskan banyak waktu untuk menciptakan pengalaman yang tidak memberikan banyak nilai bagi pengguna. Jadi, pastikan Anda fokus pada pemecahan masalah yang tepat. Interaksi suara harus masuk akal bagi pengguna; pengguna harus memiliki alasan kuat untuk menggunakan suara di atas metode interaksi lain (seperti mengklik atau mengetuk). Itulah sebabnya, saat Anda membuat produk baru — bahkan sebelum memulai desain — penting untuk melakukan riset pengguna dan menentukan apakah suara akan meningkatkan UX.
Mulailah dengan membuat peta perjalanan pengguna. Analisis peta perjalanan dan temukan tempat yang menyertakan suara sebagai saluran akan bermanfaat bagi UX.
- Temukan tempat dalam perjalanan di mana pengguna mungkin mengalami gesekan dan frustrasi. Apakah menggunakan suara akan mengurangi gesekan?
- Pikirkan tentang konteks pengguna. Apakah suara akan berfungsi untuk konteks tertentu?
- Pikirkan tentang apa yang secara unik diaktifkan oleh suara. Ingat manfaat unik menggunakan suara, seperti interaksi hands-free dan eye-free. Bisakah suara menambah nilai pada pengalaman?
Buat Alur Percakapan
Idealnya, antarmuka yang Anda rancang harus memerlukan biaya interaksi nol: Pengguna harus dapat memenuhi kebutuhan mereka tanpa menghabiskan waktu ekstra untuk mempelajari cara berinteraksi dengan sistem. Ini hanya terjadi ketika interaksi suara menyerupai percakapan nyata, bukan dialog sistem yang dibungkus dalam format perintah suara. Aturan dasar UI yang baik sederhana saja: Komputer harus beradaptasi dengan manusia, bukan sebaliknya.
Orang jarang melakukan percakapan datar dan linier (percakapan yang hanya berlangsung satu putaran). Itu sebabnya, untuk membuat interaksi dengan sistem terasa seperti percakapan langsung, desainer harus fokus menciptakan alur percakapan. Setiap alur percakapan terdiri dari dialog — jalur yang terjadi antara sistem dan pengguna. Setiap dialog akan menyertakan perintah sistem dan kemungkinan tanggapan pengguna.
Alur percakapan dapat disajikan dalam bentuk diagram alir. Setiap aliran harus fokus pada satu kasus penggunaan tertentu (misalnya, menyetel jam alarm menggunakan sistem). Untuk sebagian besar dialog dalam sebuah alur, penting untuk mempertimbangkan jalur kesalahan, ketika ada yang keluar jalur.
Setiap perintah suara pengguna terdiri dari tiga elemen kunci: maksud, ucapan, dan slot.
- Intent adalah tujuan interaksi pengguna dengan sistem yang mendukung suara.
Maksud hanyalah cara mewah untuk mendefinisikan tujuan di balik serangkaian kata. Setiap interaksi dengan sistem membawa pengguna beberapa utilitas. Baik itu informasi atau tindakan, utilitas ada dalam niat. Memahami maksud pengguna adalah bagian penting dari antarmuka yang mendukung suara. Saat kami mendesain VUI, kami tidak selalu tahu pasti apa maksud pengguna, tetapi kami dapat menebaknya dengan akurasi tinggi. - Ucapan adalah bagaimana pengguna mengungkapkan permintaan mereka.
Biasanya, pengguna memiliki lebih dari satu cara untuk merumuskan perintah suara. Misalnya, kita dapat mengatur jam alarm dengan mengatakan "Setel jam alarm ke jam 8 pagi", atau "Jam alarm jam 8 pagi besok" atau bahkan "Saya harus bangun jam 8 pagi." Desainer perlu mempertimbangkan setiap kemungkinan variasi ucapan. - Slot adalah variabel yang digunakan pengguna dalam sebuah perintah. Terkadang pengguna perlu memberikan informasi tambahan dalam permintaan. Dalam contoh jam alarm kami, "8 pagi" adalah sebuah slot.
Jangan Memasukkan Kata-kata di Mulut Pengguna
Orang-orang tahu bagaimana berbicara. Jangan mencoba mengajari mereka perintah. Hindari frasa seperti, “Untuk mengirim janji rapat, Anda perlu mengucapkan 'Kalender, rapat, buat rapat baru'.” Jika Anda harus menjelaskan perintah, Anda perlu mempertimbangkan kembali cara Anda mendesain sistem. Selalu arahkan percakapan bahasa alami, dan cobalah untuk mengakomodasi gaya bicara yang beragam).
Berusaha Untuk Konsistensi
Anda perlu mencapai konsistensi dalam bahasa dan suara di seluruh konteks. Konsistensi akan membantu membangun keakraban dalam interaksi.
Selalu Berikan Umpan Balik
Visibilitas status sistem adalah salah satu prinsip dasar desain GUI yang baik. Sistem harus selalu memberi informasi kepada pengguna tentang apa yang terjadi melalui umpan balik yang sesuai dalam waktu yang wajar. Aturan yang sama berlaku untuk desain VUI.
- Buat pengguna sadar bahwa sistem mendengarkan.
Tampilkan indikator visual saat perangkat mendengarkan atau memproses permintaan pengguna. Tanpa umpan balik, pengguna hanya dapat menebak apakah sistem sedang melakukan sesuatu. Itu sebabnya bahkan perangkat yang hanya menggunakan suara seperti Amazon Echo dan Google Home memberi kami umpan balik visual yang bagus (lampu berkedip) ketika mereka mendengarkan atau mencari jawaban. - Berikan penanda percakapan.
Penanda percakapan memberi tahu pengguna di mana mereka berada dalam percakapan. - Konfirmasikan saat tugas selesai.
Misalnya, ketika pengguna meminta sistem rumah pintar yang diaktifkan suara "Matikan lampu di garasi", sistem harus memberi tahu pengguna bahwa perintah telah berhasil dijalankan. Tanpa konfirmasi, pengguna harus masuk ke garasi dan memeriksa lampu. Ini mengalahkan tujuan sistem rumah pintar, yaitu membuat hidup pengguna lebih mudah.
Hindari Kalimat Panjang
Saat merancang sistem berkemampuan suara, pertimbangkan cara Anda memberikan informasi kepada pengguna. Relatif mudah untuk membanjiri pengguna dengan terlalu banyak informasi saat Anda menggunakan kalimat yang panjang. Pertama, pengguna tidak dapat menyimpan banyak informasi dalam memori jangka pendek mereka, sehingga mereka dapat dengan mudah melupakan beberapa informasi penting. Selain itu, audio adalah media yang lambat — kebanyakan orang dapat membaca lebih cepat daripada yang dapat mereka dengarkan.
Hormati waktu pengguna Anda; jangan membaca monolog audio yang panjang. Saat Anda mendesain respons, semakin sedikit kata yang Anda gunakan, semakin baik. Tetapi ingat bahwa Anda masih perlu memberikan informasi yang cukup bagi pengguna untuk menyelesaikan tugasnya. Jadi, jika Anda tidak dapat meringkas jawaban dalam beberapa kata, tampilkan di layar saja.

Berikan Langkah Selanjutnya Secara Berurutan
Pengguna dapat kewalahan tidak hanya oleh kalimat yang panjang, tetapi juga jumlah pilihan mereka pada satu waktu. Sangat penting untuk memecah proses interaksi dengan sistem yang mendukung suara menjadi potongan-potongan kecil. Batasi jumlah pilihan yang dimiliki pengguna pada satu waktu, dan pastikan mereka tahu apa yang harus dilakukan setiap saat.
Saat merancang sistem berkemampuan suara yang kompleks dengan banyak fitur, Anda dapat menggunakan teknik pengungkapan progresif: Hanya menyajikan opsi atau informasi yang diperlukan untuk menyelesaikan tugas.
Miliki Strategi Penanganan Kesalahan yang Kuat
Tentu saja, sistem harus mencegah terjadinya kesalahan sejak awal. Namun, tidak peduli seberapa bagus sistem berkemampuan suara Anda, Anda harus selalu merancang skenario di mana sistem tidak memahami pengguna. Tanggung jawab Anda adalah merancang untuk kasus-kasus seperti itu.
Berikut adalah beberapa tip praktis untuk membuat strategi:
- Jangan salahkan pengguna.
Dalam percakapan, tidak ada kesalahan. Cobalah untuk menghindari tanggapan seperti, “Jawaban Anda salah.” - Menyediakan alur pemulihan kesalahan.
Berikan opsi untuk bolak-balik dalam percakapan, atau bahkan untuk keluar dari sistem, tanpa kehilangan informasi penting. Simpan status pengguna dalam perjalanan, sehingga mereka dapat terlibat kembali dengan sistem langsung dari tempat terakhir mereka tinggalkan. - Biarkan pengguna memutar ulang informasi.
Memberikan pilihan untuk membuat sistem mengulang pertanyaan atau jawaban. Ini mungkin berguna untuk pertanyaan atau jawaban yang kompleks di mana akan sulit bagi pengguna untuk memasukkan semua informasi ke memori kerja mereka. - Berikan kata-kata berhenti.
Dalam beberapa kasus, pengguna tidak akan tertarik untuk mendengarkan opsi dan ingin sistem berhenti membicarakannya. Berhenti mengucapkan kata-kata akan membantu mereka melakukan hal itu. - Tangani ucapan tak terduga dengan anggun.
Tidak peduli berapa banyak Anda berinvestasi dalam desain sistem, akan ada situasi ketika sistem tidak memahami pengguna. Sangat penting untuk menangani kasus seperti itu dengan anggun. Jangan takut untuk membiarkan sistem mengakui kurangnya pemahaman. Sistem harus mengomunikasikan apa yang telah dipahaminya dan memberikan saran yang bermanfaat. - Gunakan analitik untuk meningkatkan strategi kesalahan Anda.
Analytics dapat membantu Anda mengidentifikasi belokan yang salah dan salah tafsir.
Melacak Konteks
Pastikan sistem memahami konteks input pengguna. Misalnya, ketika seseorang mengatakan bahwa mereka ingin memesan penerbangan ke San Francisco minggu depan, mereka mungkin merujuk ke "itu" atau "kota" selama alur percakapan. Sistem harus mengingat apa yang dikatakan dan dapat mencocokkannya dengan informasi yang baru diterima.
Pelajari Tentang Pengguna Anda Untuk Membuat Interaksi yang Lebih Kuat
Sistem berkemampuan suara menjadi lebih canggih saat menggunakan informasi tambahan (seperti konteks pengguna atau perilaku masa lalu) untuk memahami apa yang diinginkan pengguna. Teknik ini disebut interpretasi cerdas, dan itu mengharuskan sistem secara aktif belajar tentang pengguna dan dapat menyesuaikan perilaku mereka. Pengetahuan ini akan membantu sistem untuk memberikan jawaban bahkan untuk pertanyaan kompleks, seperti "Hadiah apa yang harus saya beli untuk ulang tahun istri saya?"
Berikan VUI Anda Kepribadian
Setiap sistem berkemampuan suara memiliki dampak emosional pada pengguna, baik Anda merencanakannya atau tidak. Orang mengasosiasikan suara dengan manusia daripada mesin. Menurut penelitian Speak Easy Global Edition, 74% pengguna reguler teknologi suara mengharapkan merek memiliki suara dan kepribadian yang unik untuk produk yang mendukung suara mereka. Dimungkinkan untuk membangun empati melalui kepribadian dan mencapai tingkat keterlibatan pengguna yang lebih tinggi.
Cobalah untuk mencerminkan merek dan identitas unik Anda dalam suara dan nada yang Anda tunjukkan. Bangun persona agen berkemampuan suara Anda, dan andalkan persona ini saat membuat dialog.
Membangun kepercayaan
Ketika pengguna tidak mempercayai suatu sistem, mereka tidak memiliki motivasi untuk menggunakannya. Itu sebabnya membangun kepercayaan adalah persyaratan desain produk. Dua faktor memiliki dampak signifikan pada tingkat kepercayaan yang dibangun: kapabilitas sistem dan hasil yang valid.
Membangun kepercayaan dimulai dengan menetapkan harapan pengguna. GUI tradisional memiliki banyak detail visual untuk membantu pengguna memahami kemampuan sistem. Dengan sistem berkemampuan suara, desainer memiliki lebih sedikit alat untuk diandalkan. Namun, sangat penting untuk membuat sistem dapat ditemukan secara alami; pengguna harus memahami apa yang mungkin dan tidak mungkin dengan sistem. Itu sebabnya sistem yang diaktifkan suara mungkin memerlukan orientasi pengguna, di mana ia berbicara tentang apa yang dapat dilakukan sistem atau apa yang diketahuinya. Saat mendesain orientasi, cobalah untuk menawarkan contoh yang berarti agar orang tahu apa yang dapat dilakukannya (contoh bekerja lebih baik daripada instruksi).
Ketika sampai pada hasil yang valid, orang tahu bahwa sistem yang mendukung suara tidak sempurna. Ketika suatu sistem memberikan jawaban, beberapa pengguna mungkin meragukan bahwa jawabannya benar. ini terjadi karena pengguna tidak memiliki informasi tentang apakah permintaan mereka dipahami dengan benar atau algoritme apa yang digunakan untuk menemukan jawabannya. Untuk mencegah masalah kepercayaan, gunakan layar untuk mendukung bukti — tampilkan kueri asli di layar — dan berikan beberapa informasi penting tentang algoritme. Misalnya, ketika pengguna bertanya, "Tampilkan lima film teratas 2018", sistem dapat mengatakan, "Berikut adalah lima film teratas 2018 menurut box office di AS".
Jangan Abaikan Keamanan Dan Privasi Data
Tidak seperti perangkat seluler, yang merupakan milik individu, perangkat suara cenderung milik suatu lokasi, seperti dapur. Dan biasanya, ada lebih dari satu orang di lokasi yang sama. Bayangkan saja orang lain dapat berinteraksi dengan sistem yang memiliki akses ke semua data pribadi Anda. Beberapa sistem VUI seperti Amazon Alexa, Google Assistant, dan Apple Siri dapat mengenali suara individu, yang menambahkan lapisan keamanan ke sistem. Namun, itu tidak menjamin bahwa sistem akan dapat mengenali pengguna berdasarkan tanda tangan suara unik mereka dalam 100% kasus.
Pengenalan suara terus meningkat, dan akan sulit atau hampir tidak mungkin untuk meniru suara dalam waktu dekat. Namun, dalam kenyataan saat ini, sangat penting untuk menyediakan lapisan otentikasi tambahan untuk meyakinkan pengguna bahwa data mereka aman. Jika Anda mendesain aplikasi yang berfungsi dengan data sensitif, seperti informasi kesehatan atau detail perbankan, Anda mungkin ingin menyertakan langkah autentikasi tambahan, seperti kata sandi atau sidik jari atau pengenalan wajah.
Lakukan Pengujian Kegunaan
Pengujian kegunaan adalah persyaratan wajib untuk sistem apa pun. Uji lebih awal, uji sering harus menjadi aturan mendasar dari proses desain Anda. Kumpulkan data riset pengguna sejak awal, dan ulangi desain Anda. Tetapi pengujian antarmuka multimodal memiliki spesifikasinya sendiri. Berikut adalah dua fase yang harus diperhatikan:
- Fase ide
Uji coba dialog sampel Anda. Berlatih membaca contoh dialog dengan lantang. Setelah Anda memiliki beberapa alur percakapan, rekam kedua sisi percakapan (ucapan pengguna dan respons sistem), dan dengarkan rekaman untuk memahami apakah mereka terdengar alami. - Tahap awal pengembangan produk (pengujian dengan prototipe lo-fi)
Pengujian Wizard of Oz sangat cocok untuk menguji antarmuka percakapan. Pengujian Wizard of Oz adalah jenis pengujian di mana peserta berinteraksi dengan sistem yang mereka yakini dioperasikan oleh komputer tetapi sebenarnya dioperasikan oleh manusia. Peserta tes merumuskan kueri, dan orang sungguhan merespons di ujung yang lain. Metode ini mendapatkan namanya dari buku The Wonderful Wizard of Oz oleh Frank Baum. Dalam buku itu, seorang pria biasa bersembunyi di balik tirai, berpura-pura menjadi penyihir yang kuat. Tes ini memungkinkan Anda untuk memetakan setiap kemungkinan skenario interaksi dan, sebagai hasilnya, menciptakan interaksi yang lebih alami. Say Wizard adalah alat yang hebat untuk membantu Anda menjalankan tes antarmuka suara Wizard of Oz di macOS. - Tahap selanjutnya dari pengembangan produk (pengujian dengan prototipe hi-fi)
Dalam pengujian kegunaan antarmuka pengguna grafis, kami sering meminta pengguna untuk berbicara keras ketika mereka berinteraksi dengan suatu sistem. Untuk sistem yang mendukung suara, itu tidak selalu memungkinkan karena sistem akan mendengarkan narasi itu. Jadi, mungkin lebih baik untuk mengamati interaksi pengguna dengan sistem, daripada meminta mereka untuk berbicara dengan lantang.
Cara Membuat Antarmuka Multimodal Menggunakan Adobe XD
Sekarang setelah Anda memiliki pemahaman yang kuat tentang apa itu antarmuka multimodal dan aturan apa yang harus diingat saat mendesainnya, kita dapat mendiskusikan cara membuat prototipe antarmuka multimodal.
Prototyping adalah bagian mendasar dari proses desain. Mampu mewujudkan ide dan membaginya dengan orang lain sangat penting. Sampai saat ini, desainer yang ingin memasukkan suara ke dalam prototyping hanya memiliki sedikit alat untuk diandalkan, yang paling kuat adalah diagram alur. Membayangkan bagaimana pengguna akan berinteraksi dengan sistem membutuhkan banyak imajinasi dari seseorang yang melihat diagram alur. Dengan Adobe XD, desainer sekarang memiliki akses ke media suara dan dapat menggunakannya dalam prototipe mereka. XD menghubungkan prototyping layar dan suara dengan mulus dalam satu aplikasi.
Pengalaman Baru, Proses yang Sama
Meskipun suara adalah media yang sama sekali berbeda dari visual, proses pembuatan prototipe untuk suara di Adobe XD hampir sama dengan pembuatan prototipe untuk GUI. Tim Adobe XD mengintegrasikan suara dengan cara yang akan terasa alami dan intuitif untuk setiap desainer. Desainer dapat menggunakan pemicu suara dan pemutaran ucapan untuk berinteraksi dengan prototipe:
- Pemicu suara memulai interaksi ketika pengguna mengucapkan kata atau frasa tertentu (ucapan).
- Pemutaran ucapan memberi desainer akses ke mesin text-to-speech. XD akan mengucapkan kata dan kalimat yang ditentukan oleh seorang desainer. Pemutaran suara dapat digunakan untuk berbagai tujuan. Misalnya, ini dapat bertindak sebagai pengakuan (untuk meyakinkan pengguna) atau sebagai panduan (sehingga pengguna tahu apa yang harus dilakukan selanjutnya).
Hal yang hebat tentang XD adalah tidak memaksa Anda untuk mempelajari kompleksitas setiap platform suara.
Kata-kata yang cukup — mari kita lihat cara kerjanya dalam tindakan. Untuk semua contoh yang akan Anda lihat di bawah, saya telah menggunakan artboard yang dibuat menggunakan kit Adobe XD UI untuk Amazon Alexa (ini adalah tautan untuk mengunduh kit). Kit ini berisi semua gaya dan komponen yang diperlukan untuk menciptakan pengalaman bagi Amazon Alexa.
Misalkan kita memiliki artboards berikut:
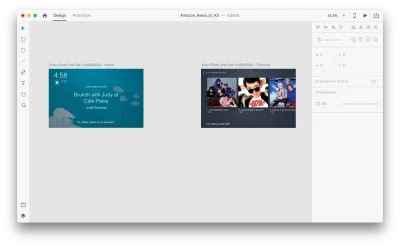
Mari masuk ke mode prototipe untuk menambahkan beberapa interaksi suara. Kami akan mulai dengan pemicu suara. Seiring dengan pemicu seperti ketuk dan seret, kami sekarang dapat menggunakan suara sebagai pemicu. Kita dapat menggunakan lapisan apa saja untuk pemicu suara selama mereka memiliki pegangan yang mengarah ke artboard lain. Mari kita hubungkan artboards bersama-sama.
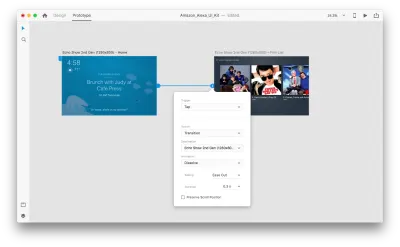
Setelah kami melakukannya, kami akan menemukan opsi "Suara" baru di bawah "Pemicu". Saat memilih opsi ini, kita akan melihat bidang "Perintah" yang dapat kita gunakan untuk memasukkan ucapan — inilah yang sebenarnya akan didengarkan oleh XD. Pengguna perlu mengucapkan perintah ini untuk mengaktifkan pemicu.
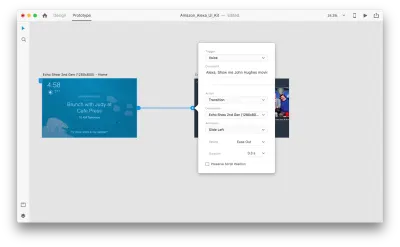
Itu saja! Kami telah mendefinisikan interaksi suara pertama kami. Sekarang, pengguna dapat mengatakan sesuatu, dan prototipe akan meresponsnya. Tapi kita bisa membuat interaksi ini jauh lebih kuat dengan menambahkan pemutaran ucapan. Seperti yang saya sebutkan sebelumnya, pemutaran ucapan memungkinkan sistem untuk mengucapkan beberapa kata.
Pilih seluruh artboard kedua, dan klik pada pegangan biru. Pilih pemicu "Waktu" dengan penundaan dan setel ke 0,2 detik. Di bawah tindakan, Anda akan menemukan "Pemutaran Ucapan". Kami akan menuliskan apa yang dikatakan asisten virtual kepada kami.
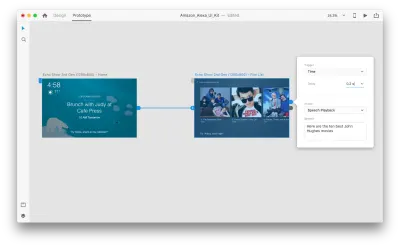
Kami siap untuk menguji prototipe kami. Pilih artboard pertama, dan mengklik tombol putar di kanan atas akan meluncurkan jendela pratinjau. Saat berinteraksi dengan pembuatan prototipe suara, pastikan mikrofon Anda aktif. Kemudian, tahan bilah spasi untuk mengucapkan perintah suara. Masukan ini memicu tindakan selanjutnya dalam prototipe.
Gunakan Auto-Animate Untuk Membuat Pengalaman Lebih Dinamis
Animasi membawa banyak manfaat untuk desain UI. Ini melayani tujuan fungsional yang jelas, seperti:
- mengomunikasikan hubungan spasial antar objek (Dari mana objek itu berasal? Apakah objek-objek tersebut terkait?);
- mengkomunikasikan keterjangkauan (Apa yang dapat saya lakukan selanjutnya?)
Tapi tujuan fungsional bukan satu-satunya manfaat animasi; animasi juga membuat pengalaman lebih hidup dan dinamis. Itu sebabnya animasi UI harus menjadi bagian alami dari antarmuka multimodal.
Dengan "Auto-Animate" yang tersedia di Adobe XD, membuat prototipe dengan transisi animasi yang imersif menjadi lebih mudah. Adobe XD melakukan semua kerja keras untuk Anda, jadi Anda tidak perlu khawatir. Yang perlu Anda lakukan untuk membuat transisi animasi antara dua artboard hanyalah menduplikasi artboard, memodifikasi properti objek di klon (properti seperti ukuran, posisi, dan rotasi), dan menerapkan tindakan Auto-Animate. XD akan secara otomatis menganimasikan perbedaan properti antara masing-masing artboard.
Mari kita lihat cara kerjanya dalam desain kita. Misalkan kita memiliki daftar belanja yang ada di Amazon Echo Show dan ingin menambahkan objek baru ke daftar menggunakan suara. Gandakan artboard berikut:
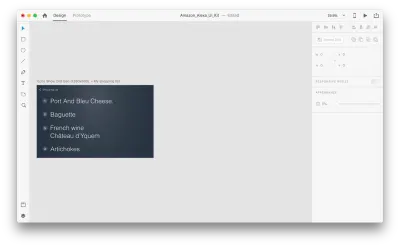
Mari kita perkenalkan beberapa perubahan dalam tata letak: Tambahkan objek baru. Kami tidak dibatasi di sini, jadi kami dapat dengan mudah memodifikasi properti apa pun seperti atribut teks, warna, opacity, posisi objek — pada dasarnya, setiap perubahan yang kami buat, XD akan menganimasikan di antara mereka.
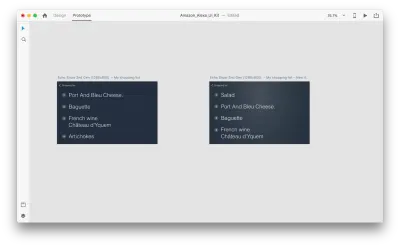
Saat Anda menyambungkan dua artboard bersama-sama dalam mode prototipe menggunakan Auto-Animate di "Action", XD akan secara otomatis menganimasikan perbedaan properti di antara setiap artboard.
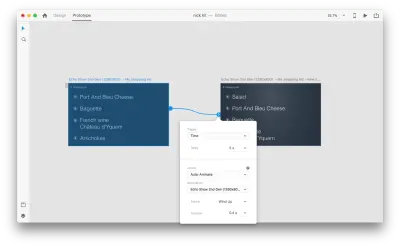
Dan inilah tampilan interaksi bagi pengguna:

Satu hal penting yang perlu disebutkan: Jaga agar nama semua lapisan tetap sama; jika tidak, Adobe XD tidak akan dapat menerapkan animasi otomatis.
Kesimpulan
Kami berada di awal revolusi antarmuka pengguna. Antarmuka generasi baru — antarmuka multimodal — tidak hanya akan memberi pengguna lebih banyak kekuatan, tetapi juga akan mengubah cara pengguna berinteraksi dengan sistem. We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
Artikel ini adalah bagian dari seri desain UX yang disponsori oleh Adobe. Alat Adobe XD dibuat untuk proses desain UX yang cepat dan lancar, karena memungkinkan Anda beralih dari ide ke prototipe lebih cepat. Rancang, buat prototipe, dan bagikan — semuanya dalam satu aplikasi. Anda dapat melihat lebih banyak proyek inspiratif yang dibuat dengan Adobe XD di Behance, dan juga mendaftar ke buletin desain pengalaman Adobe untuk tetap mendapatkan informasi terbaru dan terinformasi tentang tren dan wawasan terbaru untuk desain UX/UI.