
15 Pertanyaan & Jawaban Wawancara Pembelajaran Mesin Untuk 2022
Diterbitkan: 2021-01-08Apakah Anda seseorang yang ingin sukses berkarir di Machine Learning? Jika demikian, bagus untuk Anda!
Tetapi pertama-tama, Anda harus mempersiapkan diri untuk pemecah kebekuan – wawancara ML.
Karena proses persiapan wawancara bisa sangat melelahkan, kami memutuskan untuk turun tangan – inilah daftar 15 pertanyaan yang paling sering diajukan dalam wawancara Pembelajaran Mesin!
- Apa perbedaan antara Pembelajaran Mendalam dan Pembelajaran Mesin?
Sementara Machine Learning melibatkan aplikasi dan penggunaan algoritme canggih untuk mengurai data, mengungkap pola tersembunyi di dalam data dan belajar darinya, dan akhirnya menerapkan wawasan yang dipelajari untuk membuat keputusan bisnis yang tepat. Adapun Deep Learning, itu adalah bagian dari Machine Learning yang melibatkan penggunaan Jaring Saraf Buatan yang mengambil inspirasi dari struktur jaringan saraf otak manusia. Deep Learning banyak digunakan dalam pendeteksian fitur.
- Definisikan – Presisi dan Recall.
Precision atau Positive Predictive Value mengukur atau lebih tepatnya memprediksi jumlah true positive yang diklaim oleh model dibandingkan dengan jumlah positive yang sebenarnya diklaim.
Recall atau True Positive Rate mengacu pada jumlah positif yang diklaim oleh model dibandingkan dengan jumlah positif aktual yang ada di seluruh data.

Bergabunglah dengan Kursus Pembelajaran Mesin online dari Universitas top dunia – Magister, Program Pascasarjana Eksekutif, dan Program Sertifikat Tingkat Lanjut di ML & AI untuk mempercepat karier Anda.
- Jelaskan istilah 'bias' dan 'varians'. '
Selama proses pelatihan, kesalahan yang diharapkan dari algoritma pembelajaran umumnya diklasifikasikan atau didekomposisi menjadi dua bagian – bias dan varians. Sementara 'bias' adalah situasi kesalahan yang disebabkan karena penggunaan asumsi sederhana dalam algoritma pembelajaran, 'varians' menunjukkan kesalahan yang disebabkan karena kompleksitas algoritma pembelajaran itu dalam analisis data. Bias mengukur kedekatan pengklasifikasi rata-rata yang dibuat oleh algoritme pembelajaran dengan fungsi target, dan varians mengukur seberapa banyak prediksi algoritme pembelajaran bervariasi untuk kumpulan data pelatihan yang berbeda.
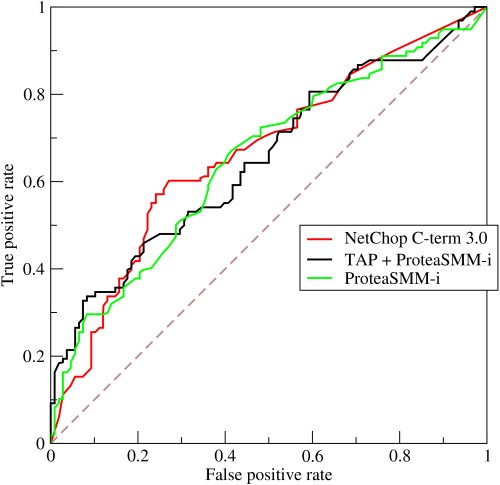
- Bagaimana fungsi kurva ROC?
Kurva ROC atau Receiver Operating Characteristic adalah representasi grafis dari variasi antara tingkat positif benar dan tingkat positif palsu pada berbagai ambang batas. Ini adalah alat dasar untuk evaluasi tes diagnostik dan sering digunakan sebagai representasi dari trade-off antara sensitivitas model (positif benar) vs kemungkinan memicu alarm palsu (positif palsu).
Sumber
- Kurva menggambarkan trade-off antara sensitivitas dan spesifisitas - jika sensitivitas meningkat, spesifisitas akan menurun.
- Jika kurva berbatasan lebih ke arah sumbu kiri dan atas ruang ROC, pengujian biasanya lebih akurat. Namun, jika kurva mendekati diagonal 45 derajat ruang ROC, pengujiannya kurang akurat atau andal.
- Kemiringan garis singgung pada titik potong menunjukkan Rasio Kemungkinan (LR) untuk nilai pengujian tertentu.
- Area di bawah kurva mengukur akurasi pengujian.
- Jelaskan perbedaan antara kesalahan Tipe 1 dan Tipe 2?
Kesalahan tipe 1 adalah kesalahan positif palsu yang 'mengklaim' bahwa suatu insiden telah terjadi, padahal sebenarnya tidak ada yang terjadi. Contoh terbaik dari kesalahan positif palsu adalah alarm kebakaran palsu – alarm mulai berdering saat tidak ada kebakaran. Bertentangan dengan ini, kesalahan Tipe 2 adalah kesalahan negatif palsu yang 'mengklaim' tidak ada yang terjadi ketika sesuatu benar-benar terjadi. Ini akan menjadi kesalahan Tipe 2 untuk memberi tahu seorang wanita hamil bahwa dia tidak mengandung bayi.
- Mengapa Bayes disebut sebagai "Naive Bayes?"
Naive Bayes disebut sebagai "naif" karena meskipun memiliki banyak aplikasi praktis, ini didasarkan pada asumsi yang tidak mungkin ditemukan dalam data kehidupan nyata - semua fitur dalam kumpulan data sangat penting, independen, dan setara. Dalam pendekatan Naive Bayes, probabilitas bersyarat dihitung sebagai produk murni dari probabilitas masing-masing komponen, sehingga menyiratkan independensi fitur yang lengkap. Sayangnya, asumsi ini tidak pernah bisa dipenuhi dalam skenario dunia nyata.
- Apa yang dimaksud dengan istilah 'Overfitting'? Bisakah kamu menghindarinya? Jika demikian, bagaimana?
Biasanya, selama proses pelatihan, model diberi sejumlah besar data. Dalam prosesnya, data mulai belajar bahkan dari informasi yang tidak akurat dan noise yang ada dalam kumpulan data sampel. Ini menciptakan pengaruh negatif pada kinerja model pada data baru, yaitu, model tidak dapat secara akurat mengklasifikasikan instance/data baru selain dari set pelatihan. Ini dikenal sebagai Overfitting.
Ya, adalah mungkin untuk menghindari Overfitting. Berikut caranya:
- Kumpulkan lebih banyak data (dari sumber yang berbeda) untuk melatih model dengan sampel yang berbeda.
- Terapkan metode ensembling (misalnya, Random Forest) yang menggunakan pendekatan bagging untuk meminimalkan variasi dalam prediksi dengan menyandingkan hasil dari beberapa pohon Keputusan pada unit yang berbeda dari kumpulan data.
- Pastikan untuk menggunakan teknik validasi silang.
- Sebutkan dua metode yang digunakan untuk kalibrasi dalam Supervised Learning.
Dua metode kalibrasi dalam Supervised Learning adalah – Kalibrasi Platt dan Regresi Isotonik. Kedua metode ini dirancang khusus untuk klasifikasi biner.
- Mengapa Anda memangkas Pohon Keputusan?
Pohon Keputusan perlu dipangkas untuk menyingkirkan cabang dengan kemampuan prediksi yang lemah. Ini membantu meminimalkan hasil bagi kompleksitas model Pohon Keputusan dan mengoptimalkan akurasi prediksinya. Pemangkasan dapat dilakukan baik dari atas ke bawah maupun dari bawah ke atas. Pengurangan kesalahan pemangkasan, pemangkasan kompleksitas biaya, pemangkasan kompleksitas kesalahan, dan pemangkasan kesalahan minimum adalah beberapa metode pemangkasan Pohon Keputusan yang paling banyak digunakan.

- Apa yang dimaksud dengan skor F1?
Secara sederhana, skor F1 adalah ukuran kinerja model – rata-rata Precision dan Recall model, dengan hasil mendekati 1 sebagai yang terbaik dan yang mendekati 0 adalah yang terburuk. Skor F1 dapat digunakan dalam tes klasifikasi yang tidak mementingkan hasil negatif yang sebenarnya.
- Bedakan antara algoritma Generatif dan Diskriminatif.
Sementara algoritma Generatif mempelajari kategori data, algoritma Diskriminatif mempelajari perbedaan antara berbagai kategori data. Ketika datang ke tugas klasifikasi, model diskriminatif biasanya melebihi model generatif.
- Apa itu Pembelajaran Ensemble?
Ensemble Learning menggunakan kombinasi algoritma pembelajaran untuk mengoptimalkan kinerja prediktif model. Dalam metode ini, beberapa model seperti pengklasifikasi atau pakar keduanya dihasilkan dan digabungkan secara strategis untuk mencegah Overfitting dalam model. Hal ini sebagian besar digunakan untuk meningkatkan prediksi, klasifikasi, pendekatan fungsi, kinerja, dll, dari sebuah model.
- Definisikan 'Trik Kernel'.
Metode Kernel Trick melibatkan penggunaan fungsi kernel yang dapat beroperasi dalam ruang fitur berdimensi lebih tinggi dan implisit tanpa harus menghitung koordinat titik dalam dimensi tersebut secara eksplisit. Fungsi kernel menghitung produk dalam antara gambar dari semua pasangan data yang ada dalam ruang fitur. Prosedur ini secara komputasi lebih murah dibandingkan dengan komputasi eksplisit dari koordinat dan dikenal sebagai Trik Kernel.
- Bagaimana seharusnya Anda menangani data yang hilang atau rusak dalam kumpulan data?
Untuk menemukan data yang hilang/rusak dalam kumpulan data, Anda harus menghapus baris dan kolom atau menggantinya dengan nilai lain. Pustaka Pandas memiliki dua metode hebat untuk menemukan data yang hilang/rusak – isnull() dan dropna(). Kedua fungsi ini secara khusus dirancang untuk membantu Anda menemukan baris/kolom data dengan data yang hilang/rusak dan menghapus nilai tersebut.
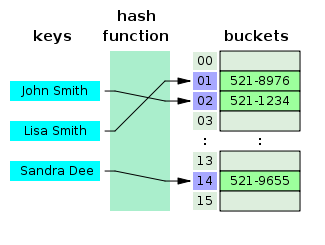
- Apa itu Tabel Hash?
Tabel Hash adalah struktur data yang membuat array asosiatif, di mana kunci dipetakan ke nilai tertentu dengan menggunakan fungsi hash. Tabel hash sebagian besar digunakan dalam pengindeksan basis data.
Sumber
Daftar pertanyaan ini hanya dimaksudkan untuk memperkenalkan Anda pada dasar-dasar Machine Learning, dan sejujurnya, dua puluh pertanyaan ini hanyalah setetes air. Pembelajaran Mesin semakin maju saat kita berbicara, dan karenanya, seiring waktu, konsep-konsep baru akan muncul. Kunci untuk memaku wawancara ML Anda, dengan demikian, terletak pada dorongan terus-menerus untuk belajar dan meningkatkan keterampilan. Jadi, mulailah dan menjelajahi Internet, membaca jurnal, bergabung dengan komunitas online, menghadiri konferensi dan seminar ML – ada banyak cara untuk belajar.
Untuk masuk ke dalam organisasi besar, sertifikat dari institusi ternama sangatlah penting. Lihat Program PG Eksekutif IIIT-B dalam Pembelajaran Mesin & AI dan dapatkan bantuan pekerjaan dari perusahaan ML & AI teratas.
Apa keterbatasan Ensemble Learning?
Pendekatan ensemble dapat membantu dalam pengurangan varians dan pengembangan model yang lebih kuat. Namun, ada beberapa kelemahan dalam menggunakan teknik ensemble, seperti kurangnya kemampuan untuk menjelaskan dan kinerja. Lebih jauh, perlu diingat bahwa kemanjuran ansambel berasal dari kemampuan mereka untuk menggabungkan beberapa model yang berfokus pada berbagai aspek masalah. Namun, mereka memiliki periode perkiraan yang lebih panjang karena Anda mungkin memerlukan perkiraan dari ratusan model. Bahkan jika mereka memiliki proyeksi yang lebih baik, perolehan akurasi mungkin tidak sepadan.
Berapa lama waktu yang dibutuhkan untuk mempelajari Machine Learning?
Ketika berbicara tentang Pembelajaran Mesin, teknologi kompleks yang digunakan untuk hal yang sama dapat dengan mudah menakuti orang. Namun, memahaminya sedikit demi sedikit tidaklah sulit. Pengalaman sebelumnya dalam statistik, matematika tingkat lanjut, dan sebagainya pasti akan membantu Anda dalam memahami semua konsep dengan cepat. Namun, karena latar belakang pendidikan dan keterampilan bervariasi dari orang ke orang, satu orang dapat belajar ML dalam tiga minggu sementara yang lain mungkin membutuhkan satu tahun.
Bagaimana Machine Learning digunakan dalam kehidupan kita sehari-hari?
Gmail mengategorikan email sebagai penting dengan mengurutkannya sebagai Utama, Promosi, Sosial, dan Pembaruan menggunakan Machine Learning. Perusahaan memanfaatkan jaringan saraf untuk mendeteksi transaksi penipuan berdasarkan data seperti frekuensi transaksi terbaru, jumlah transaksi, dan jenis pedagang. Detektor plagiarisme juga memanfaatkan pembelajaran mesin. Untuk rekayasa ML, dibutuhkan sekitar enam bulan untuk menyelesaikannya.